
Tematem wykładu są metody modelowania danych (konstruowania algorytmów klasyfikujących) oparte na regułach decyzyjnych. Przedstawiono metody oceny reguł, budowę algorytmu klasyfikującego, a także najbardziej znane heurystyki tworzenia zbiorów reguł: algorytmy AQ i CN2. Zaprezentowano też podstawowe metody tworzenia reguł oparte na teorii zbiorów przybliżonych.
Reguły decyzyjne są jednym z narzędzi reprezentacji wiedzy (modelowania danych). Opisują one związki między atrybutami warunkowymi (zwykle wieloma), a atrybutem decyzyjnym, za pomocą implikacji: po lewej stronie znajdują się warunki wyrażone pewną formułą logiczną, po prawej - wartość atrybutu decyzyjnego. Systemy klasyfikujące oparte na regułach zawierają zwykle wiele (np. tysiące) reguł, z których każda może być oparta na innym zstawie artybutów warunkowych.
Reguły decyzyjne stanowią łatwy do interpretacji opis regularności zawartych w danych, dzięki czemu, prócz zadań automatycznej klasyfikacji, nadają się też do tworzenia zrozumiałych dla człowieka raportów. Ich zaletą jest łatwość przełożenia ich na język naturalny.
Najpopularniejsza postać reguły to koniunkcja deskryptorów (selektorów postaci np. ai=vj) opartych na wybranych atrybutach. W zależności od rodzaju danych i algorytmu, najczęstsze rodzaje deskryptorów (selektorów) to:
stosowane w przypadku danych dyskretnych (np. symbolicznych), oraz
stosowane rzadziej, w przypadku danych ciągłych (liczby rzeczywiste).
Zbiór reguł zwykle konstruujemy tak, żeby pokrywał wszystkie przypadki treningowe, tzn. żeby każdy obiekt testowy pasował do którejś z reguł. To nie znaczy, że pokryje również wszystkie przypadki testowe.
 |
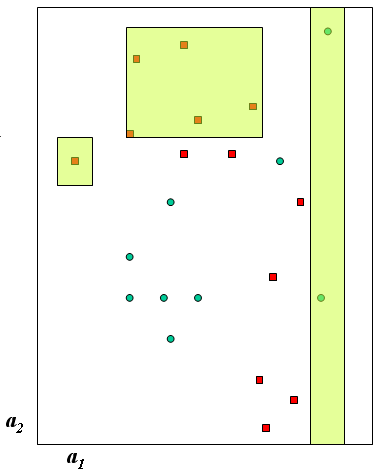 |
| W tym przykładzie mamy do czynienia z dwiema klasami decyzyjnymi i z deskryptorami reguł typu ciągłego. Każda reguła wycina z przestrzeni cech pewien newielki podzbiór - należące do tego podzbioru obiekty pasują do reguły. Zauważmy, że krótka reguła zwykle pokrywa więcej obiektów, ale bywa niedokładna (ma wyjątki nawet na zbiorze treningowym). |
Klasyfikacja nowych przypadków na podstawie zbioru reguł polega na tym, że znany opis (wartości atrybutów warunkowych) obiektów testowych podstawiany jest do warunków opisanych lewymi stronami reguł. Jeśli obiekt spełniate warunki, oznaczamy daną regułę jako pasującą do niego. Dla każdego z obiektów testowych zachodzi jeden z trzech przypadków:
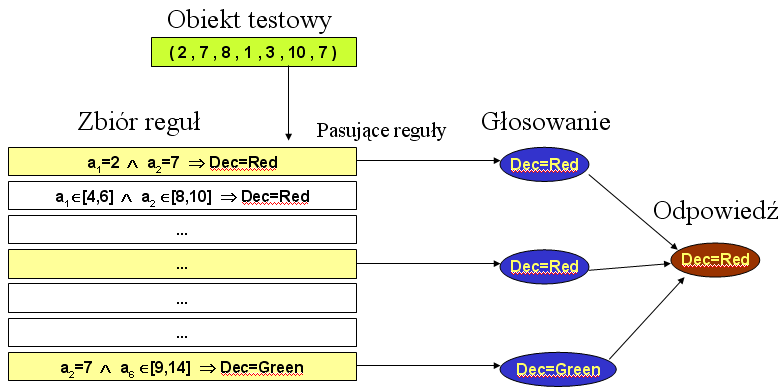
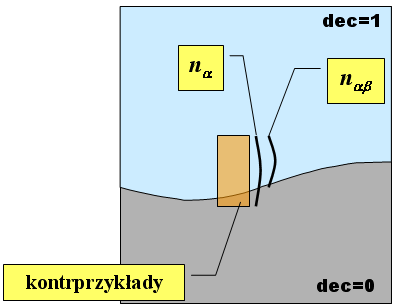 Oznaczmy symbolicznie rozpatrywaną regułę jako a => b, gdzie a jest formułą logiczną opisującą warunki, natomiast b - formułą określającą przynależność do klasy decyzyjnej. Przez nab oznaczmy liczbę obiektów spełniających obie strony reguły, przez n – liczbę wszystkich obiektów treningowych, przez na - liczbę obiektów spełniających lewą stronę reguły (pasujących do reguły), przez nb - liczbę obiektów spełniających prawą stronę reguły (czyli w praktyce - liczność klasy decyzyjnej, na którą wskazuje reguła). Dobra reguła to taka, która ma jak najmniej kontrprzykładów, czyli obiektów pasujących do lewej strony, ale niepasujących do prawej.
Oznaczmy symbolicznie rozpatrywaną regułę jako a => b, gdzie a jest formułą logiczną opisującą warunki, natomiast b - formułą określającą przynależność do klasy decyzyjnej. Przez nab oznaczmy liczbę obiektów spełniających obie strony reguły, przez n – liczbę wszystkich obiektów treningowych, przez na - liczbę obiektów spełniających lewą stronę reguły (pasujących do reguły), przez nb - liczbę obiektów spełniających prawą stronę reguły (czyli w praktyce - liczność klasy decyzyjnej, na którą wskazuje reguła). Dobra reguła to taka, która ma jak najmniej kontrprzykładów, czyli obiektów pasujących do lewej strony, ale niepasujących do prawej.
Do opisu i oceny reguł stosuje się następujące parametry liczbowe:
wsparcie (support):
| supp( a => b ) = | nab |
| nb |
dokładność (accuracy):
| acc( a => b ) = | nab |
| na |
Wsparcie reguły mówi nam o tym, ile obiektów (treningowych) do niej pasuje. Wyrażone jest ono w wartościach względnych (w stosunku do wielkości klasy decyzyjnej), dzięki temu możemy porównywać reguły wskazujące na klasy znacznie różniące się wielkością. Np. jeśli opisujemy zbiór danych na temat oszustw kredytowych (10000 obiektów), w których klasa decyzyjna "oszustwo" obejmuje tylko 100 przypadków, wówczas reguła wskazująca na oszustwo poparta 10 przykładami jest o wiele więcej warta, niż reguła wskazująca na brak oszustwa poparta 20 przykładami.
Dokładność reguły mówi nam o jej wiarygodności - jak bardzo możemy liczyć na to, że opisywana przez nią zależność rzeczywiście zachodzi. Należy pamiętać, że dokładność liczona jest na zbiorze treningowym, a więc nawet reguła o dokładności 1 może nie sprawdzić się na obiektach testowych.
Obie wielkości chcemy maksymalizować, przy czym zwykle są one przeciwstawne, tzn. zwiększając dokładność reguły (np. poprzez dokładanie warunków) zmniejsza nam liczbę zarówno kontrprzykładów, jak i przykładów pozytywnych (więc ogólnie zmniejsza wsparcie reguły).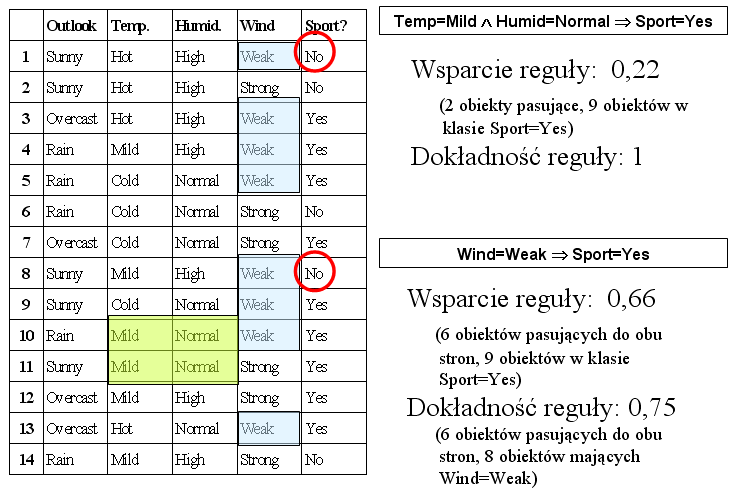
Naszym głównym zadaniem jest znalezienie zbioru reguł najlepiej klasyfikujących zbiór testowy. Powinniśmy więc dbać z jednej strony o poprawność reguł (dokładność), a z drugiej o ich ogólność (stosowalność w przyszłych, nieznanych sytuacjach). Pierwszy z tych parametrów przybliżamy dokładnością liczoną na zbiorze treningowym, licząc na to, że im reguła dokładniejsza na obiektach treningowych, tym będzie dokładniejsza również dla danych testowych. Natomiast drugi kierunek optymalizacji ma zapobiegać sytuacji, w której obiekt testowy pozostanie niesklasyfikowany z powodu nieznalezienia żadnej reguły do niego pasującej. Ten parametr trudniej oszacować na podstawie zbioru treningowego, gdyż nawet jeśli reguły potrafią rozpoznać wszystkie obiekty treningowe, to nie mamy żadnej gwarancji, że podobnie będzie z testowymi. To jest jeden z powodów, dla których staramy się maksymalizować wsparcie reguł. Im reguła ma większe wsparcie na zbiorze treningowym, tym większa jest szansa, że nieznane, nowe obiekty będą do niej pasować (tzn. że reguła uchwyciła rzeczywistą, istotną zależność zawartą w danych - o tym mówi zasada minimalnego opisu). Inny powód jest taki, że dokładność reguły można bardziej wiarygodnie oszacować, jeśli ma wysokie wsparcie (np. reguła wspierana przez jeden obiekt treningowy jest praktycznie bezużyteczna, choć oczywiście ma zawsze dokładność 1). Ponadto, jeśli reguły mają pokrywać wszystkie przypadki treningowe, to reguł o dużym wsparciu wystarczy zgromadzić mniej, co przyspiesza działanie systemu klasyfikującego.
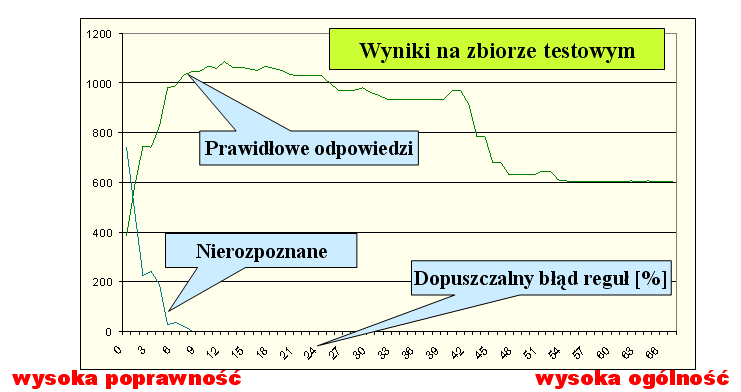
Reguły krótkie (złożone z niewielkiej liczby deskryptorów) zwykle mają większe wsparcie. Poniżej zaprezentowano zależność pomiędzy dokładnością reguł (odpowiadającą ich długości) a ich praktyczną użytecznością, obliczoną na rzeczywistych danych poprzez zbadanie skuteczności algorytmu na danych testowych. Eksperyment polegał na tym, że wyliczano zestaw reguł pokrywających wszystkie obiekty treningowe i tak dobranych, by ich dokładność nie była niższa, niż zadany próg, a długość - jak najmniejsza. Np. wartość 15 na osi x oznacza eksperyment, w którym dopuszczaliśmy 15% błędów (czyli dokładność każdej reguły musiała być co najmniej 0,85). Na osi y odłożono liczbę obiektów testowych nierozpoznanych przez zbiór reguł w danym eksperymencie, oraz ogólną skuteczność (liczbę obiektów rozpoznanych prawidłowo). Widzimy typową zależność: im większy błąd dopuścimy, tym reguły mogły być krótsze i objąć więcej obiektów testowych. Jednocześnie rosła też liczba kontrprzykładów. Optymalny okazał się poziom około 12% dopuszczalnych błędów - reguły były wówczas na tyle ogólne, że potrafiły rozpoznać wszystkie obiekty testowe, a jednocześnie jeszcze na tyle dokładne, by to rozpoznanie wskazywało na prawidłową klasę decyzyjną. System klasyfikujący skonstruowany z reguł poprawnych w 100% okazał się niezbyt skuteczny na danych testowych, gdyż wiele obiektów nie pasowało do żadnej z reguł (jest to przykład zjawiska zwanego overfitting, zbyt dokładne dopasowanie modelu do danych treningowych). Eksperyment przeprowadzono przy użyciu algorytmu opartego na zbiorach przybliżonych - por. ostatni rozdział.
Heurystyki tworzenia zbiorów reguł zwykle starają się znaleźć złoty środek pomiędzy dokładnością i ogólnością (wsparciem) reguł. Poniższe algorytmy najczęściej spowadzają się do znajdowania możliwie najprostszych (czyli najogólniejszych) reguł przy zadanym minimalnym poziomie dokładności.
Algorytm AQ oparty jest na pokrywaniu sekwencyjnym, według schematu:
Kryterium oceny reguły decyzyjnej jest jej wysokie wsparcie (liczba pasujących obiektów) przy założonym progu dokładności reguły (np. nie więcej, niż 1% kontrprzykładów). Pod tym kątem będziemy wybierać takie reguły, które pokrywają rozpatrywany obiekt. Wsparcie liczy się często jako liczbę takich obiektów pasujących do reguły, które nie były pokryte przez poprzednio znalezione reguły (dzięki temu preferujemy szybsze pokrywanie nowych rejonów przestrzeni cech).
W przypadku, gdy algorytm daje kilka alternatywnych (zbliżonych pod względem jakości) ścieżek – stosujemy przeszukiwanie wiązkowe, tzn. wybieramy k najlepszych sposobów specjalizacji reguły i badamy je równolegle.
Opis algorytmu
Uwaga: Czasem wygodnie jest przedstawiać lewe strony reguł w postaci wzorców. Jeśli mamy 5 atrybutów a1, ..., a5, to regułę a1=2 & a2=7 => ... zapisujemy jako (2, 7, *, *, *).
Wejście: cały zbiór danych.
Algorytm CN2 podchodzi do problemu szukania reguł w sposób bardziej systematyczny, przeglądając różne możliwości od strony najkrótszych reguł. Ogólny schemat algorytmu jest następujący:
Elementem algorytmu jest decydowanie o przyjęciu lub odrzuceniu reguły na podstawie jej miary jakości. Przykładowe kryteria jakości reguł to:
Opis algorytmu
Wejście: cały zbiór danych, minimalny próg wsparcia t, zbiór wzorców atomowych (jednodeskryptorowych) S.
Teoria zbiorów przybliżonych operuje pojęciem górnej i dolnej aproksymacji zbiorów. Załóżmy, że pewien nieznany zbiór X możemy opisać jedynie w sposób przybliżony, określając pewną rodzinę zbiorów w całości zawartych w X (dolna aproksymacja), a także rodzinę zbiorów mających z X niepuste przecięcie (órna aproksymacja). W języku analizy danych, zbiór X jest klasą decyzyjną (której w całości nie znamy, gdyż znamy tylko jej przedstawicieli zawartych w zbiorze treningowym), którą opisujemy za pomocą wartości atrybutów warunkowych. Zauważmy, że każda reguła (tzn. jej lewa strona) wyznacza pewien zbiór obiektów, który może w całości być zawarty w klasie decyzyjnej (reguła dokładna), w całości leżeć poza klasą decyzyjną, lub mieć z nią pewne niepuste przecięcie (reguła o dokładności poniżej 1).
Zadanie budowy algorytmu klasyfikującego można w języku zbiorów przybliżonych przedstawić następująco: znaleźć i opisać taką rodzinę podzbiorów (czyli reguł), które pozwalają możliwie dokładnie przybliżyć badany zbiór (czyli klasę decyzyjną). W idealnym przypadku dolna i górna aproksymacja klasy decyzyjnej powinna być jednakowa; w praktyce - problem optymalizacyjny dotyczy minimalizacji różnicy między górną i dolną aproksymacją. Zauważmy, że nie wystarczy przyjąć reguł całkowicie dokładnych na danych treningowych, gdyż często nie są one równie dokładne na obiektach testowych. W praktyce (por. rozdział "Parametry reguł") korzystamy z zasady minimalnego opisu, która każe nam dobierać reguły dokładne, ale jednocześnie jak najkrótsze.
Praktyczna realizacja tych idei prowadzi nas do pojęcia reduktu. Załóżmy, że będziemy próbowali opisać na raz wszystkie klasy decyzyjne i że użyjemy do tego zbioru reguł opartych na pewnym podzbiorze cech. Nasuwa się pytanie, jaki podzbiór zapewni jednocześnie pełną rozróżnialność klas decyzyjnych (na zbiorze treningowym) i jednocześnie da najbardziej ogólne reguły (co jest zapowiedzią dużej skuteczności na zbiorze testowym)? Takie zbiory atrybutów nazwiemy reduktami, a algorytm ich znajdowania jest następujący:
Wynikiem działania algorytmu jest zbiór R będący reduktem. Możemy następnie wygenerować zbiór reguł, gromadząc lewe strony (ograniczone do atrybutów z R) wszystkich obiektów treningowych. W praktyce wymaganą ogólność algorytmu osiągniemy po rozbudowaniu zbioru reguł o kolejne redukty, a także stosując skracanie reguł (tzn. usuwanie z nich atrybutów w ten sposób, by nie stracić ich dokładności). Dzięki definicji reduktu mamy gwarancję, że przynajmniej na ziorze teningowym reguły będą dokładne (wszystkie będą miały dokładność 1). Odpowiednią ogólność systemu klasyfikującego zapewnia się również poprzez odpowiedni dobór reduktów, mających być podstawą reguł - powinny by one jak najkrótsze.
11.1. Czy każde drzewo decyzyjne można przedstawić jako pewien system regułowy? Uzasadnij, lub podaj kontrprzykład.
11.2. Czy każdy system klasyfikujący ze zbiorem reguł można przedstawić jako drzewo decyzyjne? Uzasadnij, lub podaj kontrprzykład.