Architektury rozproszonych baz danych
- Projektowanie rozproszonej BD
- Fragmentacja RBD
- Architektura klient-serwer
- Logiczna architektura oprogramowania
- Architektura rozproszonych obiektów
- Struktura logiczna rozproszonych obiektów
- Podejścia do projektowania rozproszonych BD: top-down i bottom-up
- Od ogółu do szczegółów (top-down): Odgórne zaprojektowanie całej bazy danych, z uwzględnieniem optymalizacji przechowywanych danych, narzuconej przez fakt geograficznego rozproszenia producentów i konsumentów informacji przechowywanej w bazie danych.
- Od szczegółów do ogółu (bottom-up): Zintegrowanie już istniejących (spadkowych) lub zaprojektowanych lokalnych baz danych w jedną globalną rozproszoną bazę danych.
- Projektowanie: podejście top-down
- Analiza systemowa: rozpoznanie wymagań, precyzowanie kontekstu przyszłej bazy danych.
- Projektowanie schematu pojęciowego
- Projektowanie struktury logicznej
- Kryteria rozproszenia są związane z faktem fizycznego rozproszenia źródeł i odbiorców danych oraz autonomii lokalnych baz danych.
- Ustalają one decyzje, które fragmenty projektu pojęciowego będą przechowywane w poszczególnych miejscach, a także jak należy zdekomponować schemat logiczny na poszczególne miejsca
-
pokaż animację
- Dalsze fazy postępowania w podejściu top-down
- Określenie danych podlegających replikacjom (lokalnych kopii) oraz strategii replikacji.
- Zróżnicowanie logicznego schematu danych w zależności od typu SZBD w poszczególnych miejscach.
- Określenie lokalnych schematów dla poszczególnych miejsc.
- Określenie danych autonomicznych dla poszczególnych miejsc, nie uczestniczących w rozproszonej bazie danych; co prowadzi do określenia schematu pojęciowego i logicznego dla danych widzianych z zewnątrz.
- Podział schematu logicznego: Wg różnych reguł związanych na ogół z fizycznym ulokowaniem obiektów rzeczywistych (np. osób zatrudnionych, sprzętu, co pociąga za sobą odpowiedni podział schematu logicznego) lub też z fizycznym ulokowaniem programów aplikacyjnych działających na tych obiektach.
- Podstawowe metody fragmentacji schematu
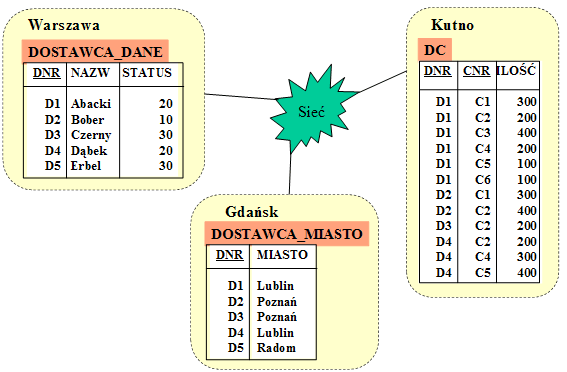
- Fragmentacja pionowa oznacza przyporządkowanie poszczególnych klas obiektów do poszczególnych miejsc, lub rozbicie obiektów danej klasy na dwa lub więcej podobiektów, przy czym takie podobiekty są przechowywane w różnych miejscach.
- Fragmentacja pionowa może oznaczać konieczność odpowiedniego podziału informacji zawartych w klasach obiektów oraz ustalenia środków podtrzymania jednoznacznej tożsamości obiektów.
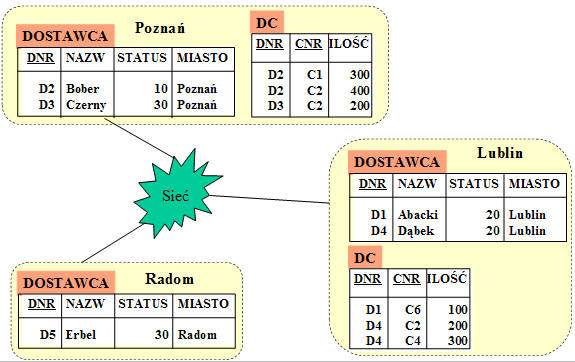
- Fragmentacja pozioma oznacza rozbicie populacji obiektów danej klasy na dwa lub więcej miejsc geograficznych.
Fragmentacja pozioma może być dokonywana na podstawie różnych kryteriów, które często wiązane są z geograficznym ulokowaniem obiektów rzeczywistych, lub też z geograficznym ulokowaniem przetwarzania tych obiektów.
- Fragmentacja pionowa relacyjnej bazy danych
- Fragmentacja pozioma relacyjnej bazy danych
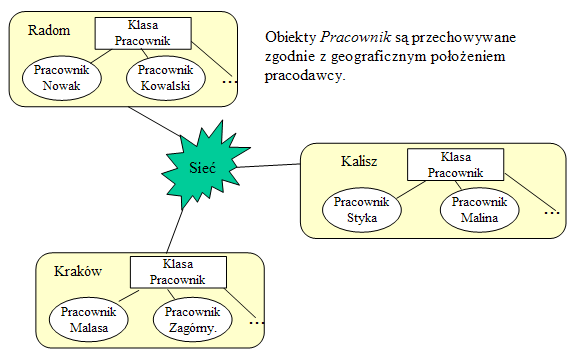
- Fragmentacja pozioma obiektów Pracownik
- Inne fragmentacje danych w rozproszonej BD
- Możliwe są inne, bardziej złożone fragmentacje danych, które łączą fragmentacje pionowe, fragmentacje poziome oraz redundantne dane (replikacje).
- Bardziej złożone fragmentacje rodzą trudności z:
- zarządzaniem metadanymi: gdzieś muszą być ulokowane informacje odnośnie tego w jaki sposób podzielone dane mają być scalone w kompletne obiekty lub kolekcje w ramach rozproszonej bazy danych. Jest to rola metadanych oraz mechanizmu właściwej dystrybucji metadanych pomiędzy uczestników rozproszonej bazy danych.
- przetwarzaniem zapytań: dekompozycja zapytania na pod-zapytania adresowane do poszczególnych miejsc staje się znacznie bardziej kłopotliwa. Przesyłanie fragmentów obiektów celem ich zmaterializowania po stronie klienta może być zbyt kosztowne.
- Bardziej złożone fragmentacje mogą być nie do uniknięcia w rozproszonej bazie danych integrującej istniejące bazy danych (podejście bottom-up). Ma to konsekwencje dla zarządzania metadanymi.
- Projektowanie: podejście bottom-up
- Podejście ad hoc: Budowa uniwersalnych lub specyficznych dla danego zastosowania pomostów (gateways) umożliwiających dostęp z danego systemu bazy danych do innych baz danych. Pomost może (nie musi) zapewniać przezroczystość rozproszenia.
- Podejście oparte o globalny schemat: Wszystkie składniki rozproszonej BD są objęte jednym globalnym schematem, jednakowym dla każdego miejsca i zapewniającym przezroczystość rozproszenia. Istotną wadą podejścia opartego na globalnym schemacie jest brak możliwości sterowania zakresem autonomii każdego lokalnego systemu.
- Federacyjna baza danych: Każda lokalna baza danych zachowuje swoją autonomię, udostępniając tylko część danych dla innych miejsc w RBD. Podejście federacyjne zakłada, że każda lokalna baza danych jest widziana poprzez pewną perspektywę (view), ukrywającą niektóre dane dla rozproszonych aplikacji.
- Federacyjna BD tworzona metodą bottom-up
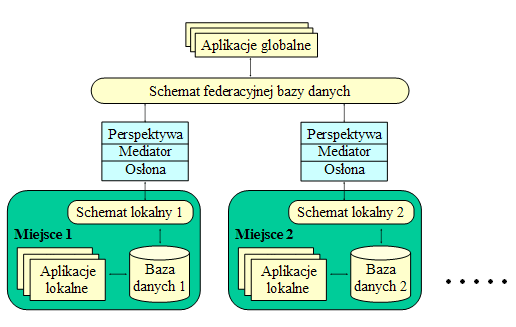
- Podejście federacyjne okazało się skuteczne ze względu na zapewnienie autonomii, bezpieczeństwa i efektywności. Rodzi jednak dużo problemów, m.in. z zapewnieniem jednolitej ontologii biznesowej, uniwersalnością aplikacji, wydajnością, itd.
- Architektura klient-serwer
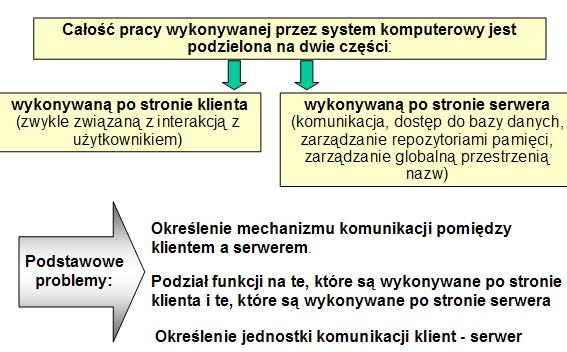
- Reguły architektury klient-serwer (1)
- Zachowanie autonomii serwera. Klienci powinni zachowywać reguły wykorzystania serwera, nie powinni powodować jego niedostępność (np. zamykać duże ilości danych), nie powinni łamać ograniczeń integralności.
- Zachowanie autonomii klienta. Klienci nie powinni zachowywać się różnie w zależności od tego, czy serwer jest lokalny czy odległy. Powinni być odizolowani od kwestii fizycznego ulokowania danych.
- Wspomaganie dla aplikacji niezależnych od serwera.
- Dostęp do własności (danych, usług) serwera. Klienci mogą żądać od serwera wykonanie przewidzianych dla niego funkcji.
- Wspomaganie dla bieżącego dostępu do danych. Dostęp ten powinien być bezpośredni, bez pośrednictwa plików przekazywanych do/od klienta.
- Minimalny wpływ architektury K/S na wymagania dla klienta. Oprogramowanie klienta w architekturze K/S nie powinno wykazywać znacznego zwiększenia zapotrzebowania na RAM lub objętość dysku.
- Reguły architektury klient-serwer (2)
- Kompletność opcji niezbędnych do połączenia. Oprogramowanie klienta nie powinno zawierać kodu realizującego połączenie z serwerem.Powinien to zapewniać serwer komunikacyjny.
- Możliwość budowy lokalnych prototypów. Programista powinien mieć możliwość budowy i testowania aplikacji K/S wyłącznie na stacji klienta.
- Kompletność narzędzi użytkownika końcowego. Projektowanie ekranów, generacja zapytań, itd. powinny być częścią środowiska.
- Kompletność środowiska budowy aplikacji. Powinno przewidywać możliwość łączenia się w sieci, dostęp do usług globalnych w zakresie nazw, lokacji danych, itd.
- Otwarte środowisko języka-gospodarza. Powinno zapewniać możliwość użycia uniwersalnego języka programowania do budowy aplikacji.
- Szczególna troska o standardy. Im bardziej będą one przestrzegane, tym mniej będzie późniejszych kłopotów ze współdziałaniem.
- Przykład architektury SZBD typu klient-serwer
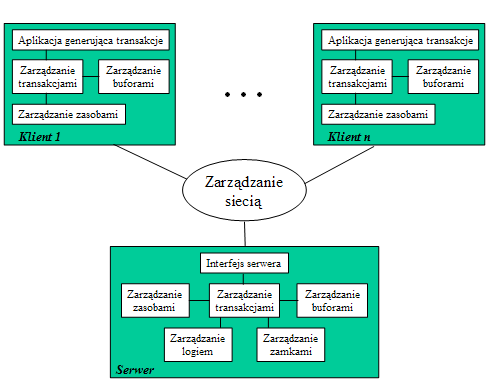
- Architektura klient-(multi) serwer (1)
- Połączenia bezpośrednie:
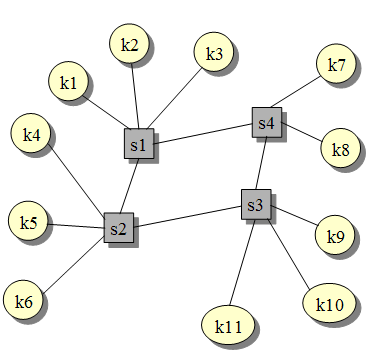
- Architektura klient-(multi) serwer (2)
- Połączenia poprzez sieć: nie ma bezpośrednich połączeń, zarówno serwery jak i klienci są przyłączani w jednakowy sposób do wspólnej sieci komputerowej.
- Architektura trzywarstwowa i wielowarstowa
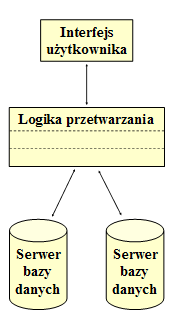
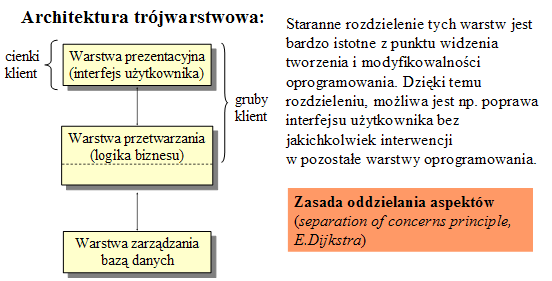
- Architektura klient-serwer podzielona na trzy warstwy:
- interfejs użytkownika,
- logikę przetwarzania (reguły biznesu, logikę biznesu)
- serwer (serwery) bazy danych.
- Warstwy są zaprojektowane i istnieją niezależnie, co ma duże znaczenie dla pielęgnacyjności systemu ze względu na możliwość zmian w dowolnej warstwie bez konieczności zmian w pozostałych warstwach.
- Często warstwy są zrealizowane na odrębnych platformach: interfejs na MS Windows, logika przetwarzania na serwerze aplikacji i baza danych na serwerze bazy danych.
- Środkowa warstwa może składać się z wielu warstw, co jest określane jako architektura wielowarstwowa.
- Logiczna architektura oprogramowania
- Architektura klient-serwer powinna odzwierciedlać logiczny podział oprogramowania na części. Nie jest to tak istotne w systemie scentralizowanym.
- Cienki i gruby klient
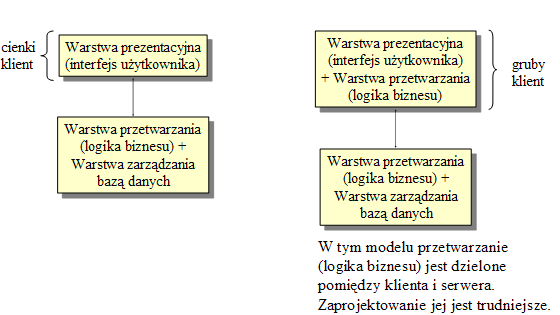
- Terminy cienki klient (thin client) oraz gruby klient (fat client) odnoszą się do mocy i jakości przetwarzania po stronie klienta w architekturze klient-serwer.
- Model cienkiego klienta: klient posiada niezbyt wielką moc przetwarzania, ograniczoną do prezentacji danych na ekranie. Przykładem jest klient w postaci przeglądarki WWW.
- Model grubego klienta: klient posiada znacznie bogatsze możliwości przetwarzania, w szczególności może zajmować się nie tylko warstwą prezentacji, lecz także warstwą przetwarzania aplikacyjnego (logiki biznesu).
- Powyższy podział posiada oczywiście pewną gradację.
- Model cienkiego klienta jest najczęstszym rozwiązaniem w sytuacji, kiedy system scentralizowany jest zamieniany na architekturę klient-serwer. Wadą jest duże obciążenie serwera i linii komunikacyjnych.
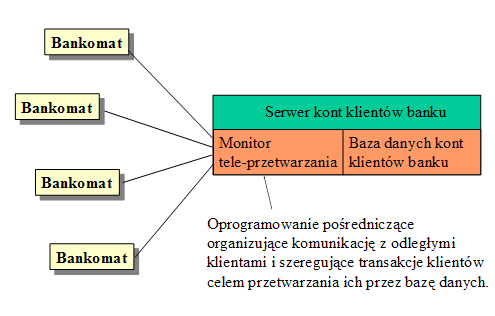
- Model grubego klienta używa większej mocy komputera klienta do przetwarzania zarówno prezentacji jak i logiki biznesu. Serwer zajmuje się tylko obsługą transakcji bazy danych. Popularnym przykładem grubego klienta jest bankomat. Zarządzanie w modelu grubego klienta jest bardziej złożone.
- Architektury dwuwarstwowe
- Uproszczone architektury trójwarstwowe z cienkim lub grubym klientem
- Przykład architektury K/S - sieć bankomatów
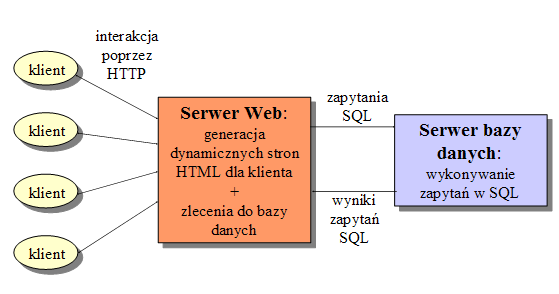
- Przykład architektury K/S - portal WWW
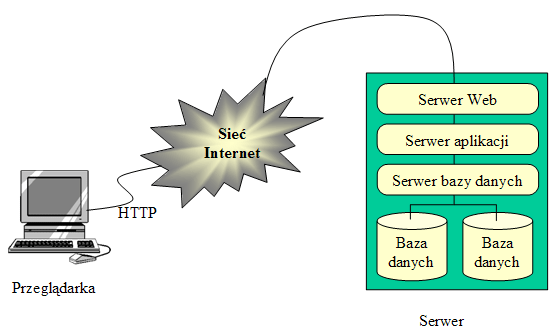
- 3-warstwowa architektura aplikacji Web
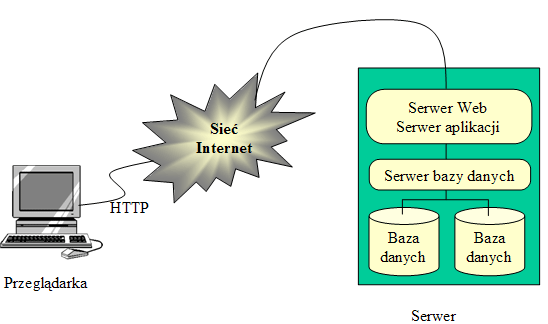
- 2-warstwowa architektura aplikacji Web
- Wiele warstw pośredniczących powoduje dodatkowe obciążenie.
- Zastosowanie różnych architektur K/S
- Dwuwarstwowa architektura K/S z cienkim klientem
- Systemy spadkowe (legacy), gdzie oddzielenie przetwarzania i zarządzania danymi jest niepraktyczne.
- Aplikacje zorientowane na obliczenia, np. kompilatory, gdzie nie występuje lub jest bardzo mała interakcja z bazą danych.
- Aplikacje zorientowane na dane (przeglądanie i zadawanie pytań) gdzie nie występuje lub jest bardzo małe przetwarzanie.
- Dwuwarstwowa architektura K/S z grubym klientem
- Aplikacje w których przetwarzanie jest zapewnione przez wyspecjalizowane oprogramowanie klienta, np. MS Excel.
- Aplikacje ze złożonym przetwarzaniem (np. wizualizacją danych, przetwarzaniem multimediów).
- Aplikacje ze stabilną funkcjonalnością dla użytkownika, użyte w środowisku z dobrze określonym zarządzaniem.
- Trzywarstwowa lub wielowarstwowa archiktektura K/S
- Aplikacje o dużej skali z setkami lub tysiącami klientów.
- Aplikacje gdzie zarówno dane jak i aplikacje są ulotne (zmienne).
- Aplikacje integrujące dane z wielu rozproszonych źródeł.
- Architektura rozproszonych obiektów (1)
- W architekturze klient-serwer istnieje wyraźna asymetria pomiędzy klientem i serwerem; w szczególności, nie występuje tam komunikacja bezpośrednio pomiędzy klientami. Model taki dla wielu zastosowań jest mało elastyczny i zapewnia zbyt małą skalowalność.
- Architektura rozproszonych obiektów znosi podział na klientów i serwery. Każde miejsce w rozproszonym systemie jest jednocześnie klientem i serwerem.
- Konieczne jest sprowadzenie wszystkich danych i usług do jednego standardu.
- Taki standard obejmuje:
- Model (pojęciowy i logiczny) danych i usług, który jest w stanie "przykryć" wszystkie możliwe dane i usługi, które mogą kiedykolwiek pojawić się w systemie rozproszonym;
- Specjalne oprogramowanie zwane pośrednikiem (broker), które akceptuje wspólny model danych i usług umożliwiając ich udostępnienie dla dowolnych miejsc w systemie rozproszonym.
- Specjalne oprogramowanie, zwane osłoną, adapterem lub mediatorem, które przystosowuje konkretne miejsce do modelu przyjętego przez pośrednika.
- Architektura rozproszonych obiektów (2)
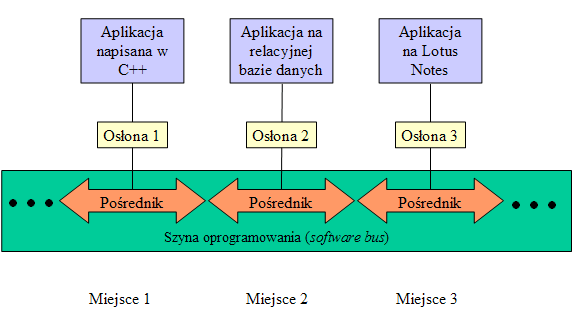
- Struktura logiczna rozproszonych obiektów
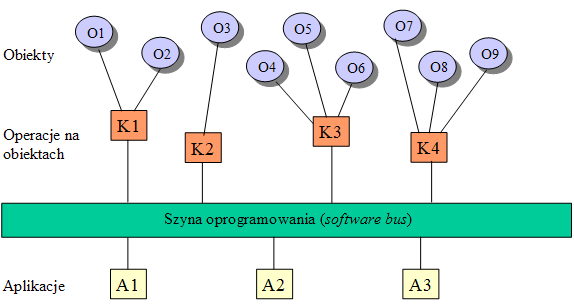
- Szyna oprogramowania tworzy jedną przestrzeń obiektów. Obiekty te są dostępne dla dowolnego miejsca poprzez operacje (zgrupowane w klasach). Miejsca i sposoby implementacji obiektów są niewidoczne. Aplikacje korzystają z całej puli obiektów.
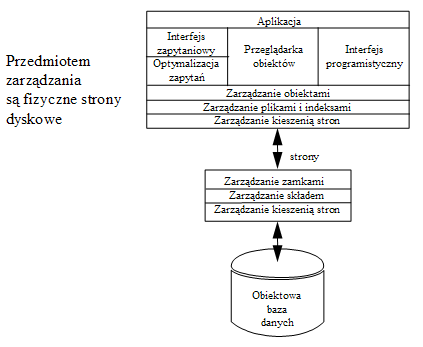
- Architektura serwera stron
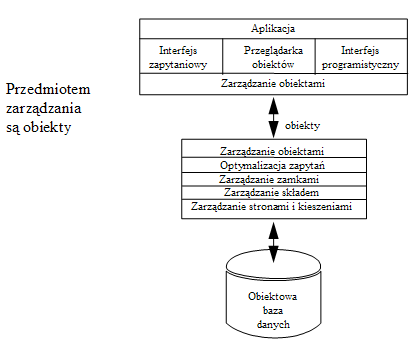
- Architektura serwera obiektów
 Info
Info Wykłady
Wykłady Skorowidz
Skorowidz