Programowanie polega na posługiwaniu się strukturami danych i algorytmami.
Reprezentowanie struktur danych w programie nie jest łatwe, jeśli wszystko
musimy oprogramować sami. Dlatego w wielu językach programowania istnieję
swoiste biblioteki gotowych do wykorzystania konkretnych realizacji abstrakcyjnych
struktur danych. W Javie nazywa się to Java Collections Framework.
1. Architektura kolekcji (JCF). Interfejsy i implementacje
Zapoznaliśmy się już trochę z kolekcjami (zob. kurs "Podstawy
programowania w Javie"). Pora na pogłębienie wiadomości, a także
wyrobienie
własciwego stylu programowania operacji na kolekcjach.
Przypomnijmy najpierw podstawową definicję.
Kolekcja jest obiektem, który grupuje elementy danych (inne obiekty)
i pozwala traktować je jak jeden zestaw danych, umożliwiając jednocześnie
wykonywanie operacji na zestawie danych np. dodawania i usuwania oraz przeglądania
elementów zestawu
W pakiecie java.util, zdefiniowano narzędzia, służące
do tworzenia i posługiwania się róznymi rodzajami kolekcji.
W
materiale wprowadzającym - i później w róznych przykładowych programach
- widzielismy np. zastosowanie klasy ArrayList, HashSet, TreeSet... Ale
różnych rodzajów kolekcji jest więcej. Standardowe klasy Javy
dostarczają środków do posługiwania się:
- listami,
- kolejkami,
- zbiorami (w tym: zbiorami uporządkowanymi),
- mapami (odwzorowania: klucz -> wartość ).
Każda z tych abstrakcyjnych struktur danych ma pewne właściwości, które wyróżniają
ją od innych struktur danych. Mówimy, że są to abstrakcyjne struktury danych,
bowiem w opisie tych właściwości nie przesądza się o tym w jaki sposób konkretnie
je zrealizować.
Abstrakcyjne wlaściwości struktur danych opisywane są przez interfejsy, a konkretne realizacje - inaczej implementacje - tych właściwości znajdujemy w konkretnych klasach.
Zatem ważnym elementem architektury kolekcji w Javie są interfejsy.
Interfejsy kolekcyjne - określają abstrakcyjne typy danych będące
kolekcjami i pozwalają na niezalezne od szczegółów realizacyjnych operowanie
na kolekcjach. Deklarują one metody, które mogą być uzyte wobec danego rodzaju kolekcji.
Konkretne kolekcje, obiekty na których operujemy są obiektami klas implementujących interfejsy kolekcyjne.
Zatem, drugim ważnym elementem architektury kolekcji są implementacje.
Implementacja kolekcji jest konkretną realizacją funkcjonalności,
określanej przez interfejs kolekcyjny. Takie realizacje mogą być różne w
szczegółach technicznych, np. realizacja listy jako dynamicznej tablicy lub
jako listy z dowiązaniami.
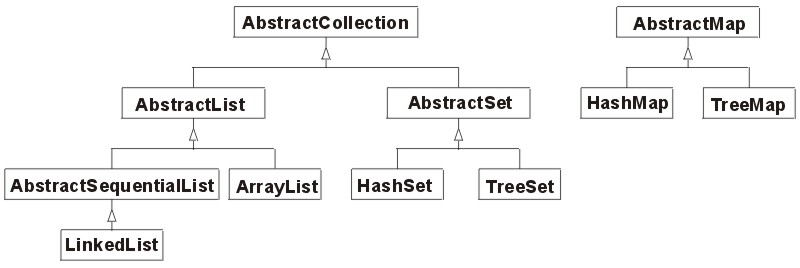
Na przykład, intefejs List określa ogólne właściwości listy (to, że
każdy element zestawu danych znajduje się na określonej pozycji) oraz możliwe
operacje na liście. Właściwości te i operacje można zrealizować w różny sposób:
poprzez użycie tablicy z dynamicznie zmieniającymi się rozmiarami (implementacja tablicowa) lub poprzez implementację podwójnie-dowiązaniową
(w której kolejny element listy umieszczony jest w strukturze, która oprócz
referencji do samego elementu zawiera dowiązania, czyli odniesienia, wskaźniki do następnego
i poprzedniego elementu listy).
Odpowiednio do tego mamy dwie klasy: ArrayList (implementacja tablicowa) i LinkedList (implementacja podwójnie dowiązaniowa), każda z których realizuje koncepcję listy.
W obu przypadkach mamy do czynienia z listą, ale pewne operacje na liście
w każdej z tych implementacji mają inną efektywność (czas wykonania). Zatem
w zależności od potrzeb możemy wybierać odpowiednią implementację listy.
Oprócz
tego stadardowe klasy Javy dostarczają gotowych środków użycia
rozlicznych algorytmów na kolekcjach (np. sortowania i binarnego
wyszukiwania).
Zatem trzecim ważnym elementem architektury kolekcji są algorytmy.
Algorytmy kolekcyjne są metodami wykonującymi użyteczne operacje obliczeniowe
na kolekcjach (np. sortowanie i wyszukiwanie). Metody te są polimorficzne
tzn. ta sama metoda może być użyta dla wielu róznych implementacji tego samego
interfejsu kolekcyjnego
W sumie te trzy elmenty: interfejsy, implementacje i algorytmy stanowią tzw. architekturę kolekcji.
|
Architektura kolekcji (Collections Framework)
|
Zunifikowana architektura, służąca do reprezentacji kolekcji i operowania na nich,
Składa się z:
- interfejsów,
- implementacji,
- algorytmów.
Najbardziej znane architektury kolekcji to: STL (Standard Templates Library)
w C++, klasy kolekcyjne w SmallTalk'u oraz JCF (Java Collections Framework).
|
Java Collections Framework
(JCF) jest niezwykle użyteczną składową środowiska Javy. Mamy do dyspozycji
wiele gotowych, efektywnych, klas i metod, pozwalających łatwo rozwiązywać
wiele problemów związanych z reprezentacją w programie bardziej zaawansowanych
struktur danych i operowaniem na nich.
Ale nie tylko na tym polega siła Java Collections Framework. Zastosowana
architektura kolekcji sprawia, że można tworzyć metody i programy o uniwersalnym
charakterze, operujące na kolekcjach (reprezentujących abstrakcyjne typy danych)
w sposób niezależny od implementacji. I, co więcej, architektura kolekcji
jest otwarta: korzystając z jej elementów możemy łatwo sami tworzyć nowe
rodzaje abstrakcyjnych struktur danych lub nowe implementacje, niejako wbudowane
w istniejącą strukturę kolekcji, co czyni nasze nowe interfejsy i klasy proste
w ponownym użytku zgodnie z jednolitymi regułami użycia klas i interfejsów
kolekcyjnych.
W
tablicy pokazano hierarchię dziedziczenia interfejsó kolekcyjnych oraz
ich znaczenie (czyli istotę abstrakcyjnych struktur danych,
definiowanych przez te interfejsy)..
Podstawowe interfejsy JCF
|
Collection | dowolna kolekcja nie będącą mapą |
| List | zestaw
elementów, z których każdy znajduje się na określonej pozycji; do listy
można wielokrotnie dodać ten sam element i mozna sięgnąc po
element na dowolnej pozycji. |
| Queue | kolejka,
czyli sekwencja elementów, do której dodawanie i sięganie po
elementy odbywa się na pozycjach, określonych przez zadany porządek
(najczęsciej FIFO - first in first out). Nie ma bezpośredniego dostępu do dowolnej pozycji. |
|
|
Deque
| rozszerza
Queue: kolejka podwójna, do której dodawanie i sięganie może odbywać
się na obu końcach (np. dodaj na początku, dodaj na końcu, usuń z
pocżatku, susń z końca) |
|
Set
| zestaw niepowtarzających się elementów, pozycje elementów są nieokreślone |
| |
SortedSet
| rozszerza
Set: zbiór uporządkowany
|
| | NavigableSet | rozszerza SortedSet: zbiór uporządkowany, dla którego możliwe są operacje uzyskiwania elementów "bliskich" danemu. |
Map
| mapa - zestaw par: klucz-wartość, przy czym odwzorowanie kluczy w wartości jest jednoznaczne
|
|
SortedMap
| mapa z uporządkowanymi kluczami (typu SortedSet)
|
| |
NavigableMap
| mapa, w której klucze są typu NavigableSet |
Uwagi:
- w
tablicy pokazano relacje dziedziczenia interfejsów (np. wszystkie
interfejsy dziedzicżą, rozszerzają interfejs Collection),
- wszystkie interfejsy kolekcyjne sa sparametryzowane, dla wygody pominięto parametry typu.
Wybrane podstawowe konkretne implementacje pokazuje poniższa tablica.
| Sposób realizacji właściwości okreslanych przez interfejs | Implementujące klasy | Implementowany
interfejs | Właściwości implementacji |
Dynamicznie rozszerzalna tablica
|
ArrayList
|
List
|
szybki bezpośredni dostęp
|
Lista liniowa z podwójnymi dowiązaniami
|
LinkedList
|
List, Deque
|
szybkie wpisywanie i usuwanie elementów poza końcem listy; wolny dostęp bezpośredni;
implementacja operacji na kolejkach
|
| Kolejka podwójna | ArrayDeque | Deque | kolejka podwójna zrealizowana jako rozszerzalna tablica; szybki dostęp do obu końców, brak dostępu do dowolnej pozycji. |
| Kolejka z priorytetami | PriorityQueue | Queue | kolejka,
w której pierwszy i ostatni elment jest określany na podstawie
ustalonego porządku (porównania elmentó wg jakichś kryteriów) |
Tablica mieszania
(tablica haszująca)
|
HashSet
HashMap
|
Set
Map
|
szybkie wpisywanie i odnajdywanie elementów; kolejność elementów nieokreślona
|
Drzewo
czerwono-czarne
|
TreeSet
TreeMap
|
NavigableSet
NavigableMap
|
uporządkowanie elementów; dostęp i wyszukiwanie wolniejsze niż w implementacji mieszającej
|
Tablica mieszania
i lista liniowa
|
LinkedHashSet
LinkedHashMap
|
Set
Map
|
jak w implememntacji mieszającej, z zachowaniem porządku wpisywania elementów |
Uwagi:
- Wszystkie klasy są sparametryzowane.
- Pominięto klasy kolekcyjne z pakietu java.util.concurrent, służące programowaniu współbieznemu.
- Użyte w tablicy pojęcia, dotyczące sposobu implementacji, zostaną wyjasnione w trakcie omawiania konkretnych struktur danych.
Jak widać, mamy np. dwie implementacje dla listy i po trzy implementacje dla zbioru i mapy.
Wybór implementacji zależy od potrzeb naszego programu (w tablicy pokazano podstawowe właściwości implementacji).
Oczywiście, jeśli nasz program tworzy konkretne obiekty klas kolekcyjnych,
to zawsze musimy dokonać takiego wyboru. Ale ważną rzeczą jest, by wszelkie
inne działania na kolekcjach wykonywać w kategoriach interfejsów, a nie konkretnych
klas.
Ponadto należy używać kolekcji sparametryzowanych, a nie surowych typów (List czy ArrayList).
Znaczenie tych dwóch ważnych zasad ilustrują poniższe fragmenty kodu.

Mamy tu klasę ListUtils, która dostarcza statycznych metod tworzenia listy z
elementów tablicy (metoda create), dodawania do końca istniejącej listy elementów
tablicy (append) oraz wypisywania na konsoli elementów listy (show).
W innej klasie (tu nazywa się - na razie niesłusznie - Independence) posługujemy się metodami klasy ListUtils.
Zobaczmy co jest złego we fragmentach kodu z obu klas.
Metoda append
z klasy ListUtils jest przystosowana wyłącznie do tablicowej implementacji
listy (bo jej parametrem jest ArrayList). Zatem nie będzie działać dla list
z dowiązaniami (LinkedList), ani też dla jakichkolwiek innych konkretnych
implementacji listy. A przecież ta metoda nie wymaga przesądzania o implementacji.
Co więcej ten sposób programowania jest niebezpieczny, ponieważ
pozwala dodawać do list dowolne elementy, bez kontroli w fazie
kompilacji i niewygodny, bo przy wyciaganiu elementów musimy używać jawnych konwersji zawężających.. Użycie parametrów typu
pozwoli uniknąc sytuacji, w której np. do listy osób przypadkowo dodamy
liczbę, a także zaoszczędzi nam kodowania, bo zapewnione będą
automatyczne konwersje zawężające do konkretnego typu przy sięganiu po elmenty listy.
Wobec każdej kolekcji możemy użyć metody add, w szczegolności taką metodę
zawiera również interfejs List. Powinniśmy zatem w sposób ogólniejszy podać
typ parametru metody append. Ma ona dodawać elementy tablicy do dowolnej
listy elementów podanego typu T, winna zatem wyglądać tak:
class ListUtils {
static <T> void append(List<T> list, T[] items) {
for (T item : items)
list.add(item);
}
// ...
}
Uwaga: mamy tu metodę sparametryzowaną typem T (zob. materiał, dotyczący generics).
To samo dotyczy metody show: również powinniśmy w niej podać jako typ parametru nazwę interfejsu List, a nie konkretnej klasy.
static void show(List<?> list) {
for (Object o : list)
System.out.println(o);
}
Tutaj
posłuzylismy się uniwersalnym parametrem typu <?>, co oznacza
dowolny typ i sprawia, że metoda będzie dobra dla list elementów
dowolnego typu.
Teraz fragment innej klasy (w naszym przypadku pokazanej klasy Indepedence)
może elastycznie i uniwersalnie korzystać z tych metod. Możemy użyć ich na
rzecz listy napisów implementowanej jako rozszerzalna tablica:
String[] items = { "Kot", "Pies", "Zebra", "Tygrys" };
List<String> list1 = new ArrayList<String>();
ListUtils.append(list1, items);
ListUtils.show(list1);
a jeśli trzeba - dla zmienionej implementacji listy (listy z dowiązaniami - LinkedList) i innego typu elementów:
Integer[] arr = {1, 2, 3};
List<Integer> list1 = new LinkedList<Integer>();
ListUtils.append(list1, arr);
ListUtils.show(list1);
Przypomnienie:
kolekcje mogą zawierać wyłacznie referencje do obiektów; zatem
musieliśmy użyć tablicy Integer[], a nie int[], jednak - dzięki
autoboxingowi- inicjacja tablicy nie nastręczała kłopotów (automatyczne
opakowywanie danych typu int w obiektu klasy Integer).
Zwróćmy uwagę, że całkiem świadomie napisaliśmy tu:
List<String> list1 = new ...
a nie
ArrayList<String> list1 = new ...
czy
LinkedList<Integer> list1 = new ...
Jeśli zdecydujemy się na zmianę implementacji (np. z ArrayList na LinkedList
lub odwrotnie), to modyfikacja dotknie tylko jednego miejsca kodu (wywołania
konstruktora w wyrażeniu new) i mniejsze będzie prawdopodobieństwo popełnienia
błędu.
Gdy w innej klasie (w naszym przypadku - klasie Independence) korzystamy
z metody create (klasy ListUtils), która zwraca nowoutworzoną listę z dodanymi
do niej elementami przekazanymi w tablicy, również nie powinniśmy "przywiązywać"
się do konkretnej implementacji listy zwracanej przez metodę create().
Zamiast pisać:
ArrayList list2 = ListUtils.create(
new String[] { "Truskawki", "Banany"}
);
powinniśmy napisać:
List<String> list2 = ListUtils.create(
new String[] { "Truskawki", "Banany"}
);
Metoda create(...) tworzy nową listę. musi zatem posłużyć się konkretną
implementacją. W omawianym tu przypadku jest to klasa ArrayList. Być może nie byłoby
błędu, gdybyśmy napisali:
ArrayList<String> list2 = ListUtils.create(...)
Ale gdyby twórca klasy ListUtils (może my sami) - z jakichś powodów - zmienił
implementację nowotworzonej listy w metodzie create(..) z ArrayList na jakąś
inną, to nasza klasa korzystająca z metody create(...) musialaby być zmodyfikowana
i rekompilowana. Dzięki temu, że napisaliśmy:
List<String> list2 = ListUtils.create(...)
nasza klasa (tu: klasa Independence) jest gotowa do korzystania z dowolnych
implementacji list zwracanych przez metodę create(..) i nie musi być rekompilowana
przy zmianie tych implementacji.
A czy metoda create() może być przygotowana na inny typ elementów listy (np. Integer)?
Oczywiście - w tym celu nalezy ją sparametryzować, co może wyglądac tak:
static <T> List<T> create(T[] items) {
ArrayList<T> list = new ArrayList<T>();
append(list, items);
return list;
}Konkretny typ elementu (podstawiany pod parametr typu T) będzie dedukowany z wywołania.
Pisząc
metodę create użyliśmy jako typu wyniku interfejsu. Jest to sygnał dla
użytkownika klasy ListUtils, że tworzona lista może być dowolnego typu
i np. implementacja może być zmieniona.
Ogólnie więc, przy deklaracji parametrów metod oraz przy deklaracji zmiennych,
których wartość jest referencją do kolekcji zwracaną przez jakąś metodę,
użycie typu, wyznaczanego przez interfejs kolekcyjny, zamiast typu wyznaczanego
przez implementację (klasę implementującą ten interfejs), pozwala na uniknięcie
modyfikacji i rekompilacji klasy przy zmianie implementacji kolekcji.
Ale zapisów "w terminach" interfejsów nie należy absolutyzować ani stosować "na ślepo".
Wyobraźmy sobie, że zbudowaliśmy klasę NumberedList, reprezentującą listę
z numerami elementów. Klasa ta zawiera m.in. metodę addAuto dodającą do listy
napisową reprezentację argumentu, poprzedzoną kolejnym numerem. Metoda ma
zwracać tę listę na rzecz ktorej została wywołana (po to, by umożliwić "lańcuchowe"
wywolania: list.addAuto(...).addAuto(...).addAuto(...)). Nie ma to może za
wiele sensu, ale dobrze ilustruje zagadnienie.
Metoda addAuto(..) może wyglądać tak:
import java.util.*;
class NumberedList extends ArrayList<String> {
// ...
public NumberedList addAuto(Object o) {
super.add("Nr." + (size()+1) + " " +o);
return this;
}
// ...
}
Zwróćmy uwagę: typem zwracanego wyniku jest NumberedList, a nie List.
To bardzo słuszne, daje bowiem wołającemu tę metodę odpowiednią elastyczność.
Nic nie stoi na przeszkodzie, by użyć jej wyniku w miejscu gdzie wymagane
jest wyrażenie typu List (bo NumberedList dziedziczy ArrayList, a przez to
implementuje interfejs List). A jednocześnie możliwe jest użycie na rzecz
wyniku metody addAuto:
list.addAuto(..).addAuto(...), czego nie moglibyśmy zrobić, gdyby typem wyniku
był "tylko" List (bo interfejs List nie zawiera metody addAuto()).
Podobnie, w programie korzystającym z tej klasy napiszemy raczej:
NumberedList nls = new NumberedList();
a nie:
List nls = new NumberedList();
po to by móc korzystać z metody addAuto(...). Co w niczym nie przeszkadza
podać nls jako argument dowolnej metody przyjmującej List.
Np.
NumberedList nls = new NumberedList();
nls.addAuto("Pies").addAuto("Kot").addAuto("Wilk");
ListUtils.show(nls);
Omawiane zagadnienie wyboru deklarowanego typu zmiennej oznaczającej kolekcję
uzyskuje nowy wymiar, jeśli uwzględnimy fakt, że w Javie istniejące interfejsy
kolekcyjne tworzą hierarchiczne struktury i że struktury te możemy rozbudowywać
tworząc własne interfejsy i klasy implementujące.
Kolekcje listowe i zbiorowe różnią się od kolekcji słownikowych (map):
w pierwszym przypadku do kolekcji dodawany jest element-obiekt, w drugim
para obiektów klucz-wartość. Nie da się zatem w naturalny, prosty dla użytkownika
sposób, uogólnić funkcjonalności kolekcji listowych i zbiorowych z jednej
strony oraz map z drugiej. Dlatego interfejsy kolekcyjne tworzą dwie rozłączne
hierarchie: jedna dla kolekcji listowych, kolejkowych i zbiorowych, druga - dla map.
Hierarchie interfejsów listowych, kolejkowych i zbiorowych pokazuje rysunek (o interfejsach map - zob. dalej).
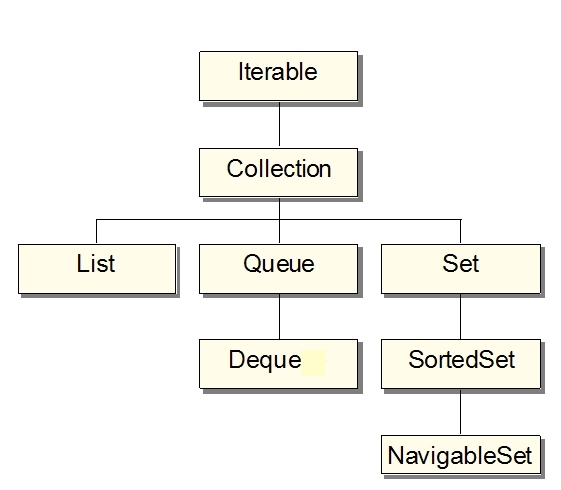
Jak widać, wszystkie kolekcje listowe, kolejkowe i zbiorowe dają się przedstawić jako
typu Collection. Pozwala to wykonywać pewne ogólne operacje na kolekcjach
bez względu na ich rodzaj i - tym bardziej - implementację.
Zanim dokładniej przyjrzymy się tym możliwościom, warto zwrócić uwagę, że przy deklarowaniu typów parametrów metod, służących do operowania na kolekcjach, powinniśmy wybierać typy określane przez interfejsy znajdujące się możliwie
najwyżej w hierarchii dziedziczenia. To oczywiście zawsze zależy od kontekstu,
od funkcjonalności dostarczanej przez nasze metody. Jeśli przeznaczeniem
metody jest operowanie na listach - typem parametru powinno być List, ale
jeśli dotyczy ona dowolnych kolekcji - to raczej typem powinno być Collection. Zauwazmy też
I odwrotnie, typy wyników zwracanych przez metody powinny być jak
najbardziej specyficzne, do konkretnej implementacji włącznie. Jeśli np.
nasza metoda tworzy zbiór uporządkowany - obiekt klasy TreeSet (co jest bardziej
kosztowne niż stworzenie zwykłego zbioru), to powinna zwracać wynik typu
TreeSet, po to by użytkownik mógł skorzystać z dodatkowej funkcjonalności
(uporządkowania), już przecież okupionej kosztem czasu działania programu.
2. Ogólne operacje na kolekcjach. Operacje opcjonalne i grupowe.
Interfejs Collection definiuje ogólne, wspólne właściwości i funkcjonalność
wszystkich kolekcji (poza mapami).
W szczególności, dotyczy to dowolnych kolekcji listowych i zbiorowych, ale
nie tylko: możemy mieć kolekcje, które nie są ani listami, ani zbiorami (sami
możemy takie definiować, a w JCF przykładem takiej kolekcji jest zestaw wartości
mapy (spod kluczy), który nie jest listą, ponieważ elementy w zestawie
nie mają pozycji, ani nie jest zbiorem, bowiem te same
elementy mogą występować w kolekcji więcej niż jeden raz).
Typ Collection jest zatem swoistym "najmniejszym wspólnym mianownikiem"
wszystkich rodzajów kolekcji i używamy go (szczególnie przy przekazywaniu
argumentów) wtedy, gdy potrzebna jest największa ogólność działań.
Bardzo podstawowe, ale zawsze mające sens, operacje na kolekcjach to:
- uzyskanie liczby elementów w kolekcji - metoda int size(),
- stwierdzenie czy kolekcja jest pusta - metoda boolean isEmpty(),
- stwierdzenie, czy kolekcja zawiera podany obiekt - metoda boolean contains(obiekt).
Większą operacyjność dają metody dodawania elementów do kolekcji (metoda add(...)) i usuwania elementów z kolekcji (metoda remove(...)
). Są one zawarte w interfejesie Collection, ale ich działanie musi być zdefiniowane
tu bardzo ogólnie, z uwzględnieniem rożnych możliwych rodzajów kolekcji.
Mamy przy tym dwa problemy:
- kolekcje mogą być modyfikowalne lub niemodyfikowalne,
- kolekcje mogą dopuszczać duplikaty bądź nie.
Kolekcja jest modyfikowalna, jeśli można dodawać do niej elemementy, usuwać z niej elementy oraz zmieniać wartości elementów. Niemodyfikowalne kolekcje nie pozwalają na dodawanie, usuwanie, zmianę wartości elementów.
Wobec tego twórcy Java Collection Framework stanęli przed wyborem:
- albo nie dostarczać metod add i remove w interfejsie Collection,
- albo stworzyć dwa interfejsy dla modyfikowalnych i niemodyfikowalnych kolekcji i odpowiednie hierarchie dziedziczenia,
- albo dostarczając metod dodawania i usuwania elementów w interfejsie
Collection, zapewnić jakieś środki decydowania w konkretnych implementacjach
czy metody te są dopuszczalne.
Pierwsze rozwiązanie podważyłoby sens istnienia interfejsu Collection (bylby
zapewne zbyt ubogi). Drugie było nie do przyjęcia ze względu na to, iż powodowałoby
dalszą rozbudowę i tak już skomplikowanej hierarchii interfejsów i klas kolekcyjnych
(a weźmy jeszcze pod uwagę różne możliwe warianty "niemodyfikowalności" np.
tylko dodawanie bez usuwania, tylko usuwanie bez dodawania, tylko zabronione
zmiany rozmiarów, ale zmiany wartości elementów możliwe itp.)
Wybrano zatem rozwiązanie trzecie.
Mianowicie niektóre metody (operacje) zawarte w interfejsach kolekcyjnych określone są jako operacje opcjonalne
. Konkretne klasy kolekcyjne mogą dopuszczać lub nie wykonanie takich operacji.
Np. klasa definiująca jakąś kolekcję niemodyfikowalną nie może pozwolić na
wykonanie operacji dodawania i usuwania elementów.
Ale ponieważ każda klasa kolekcyjna musi implementować interfejs Collection,
to musi też zdefiniować metody add i remove. Zdefiniować coś - co, z punktu
widzenia dostępnych w danym przypadku operacji, nie powinno być zdefiniowane!
Sprzeczność tę rozwiązano, przyjmując zasadę, że jeśli operacja opcjonalna
dla danej implementacji nie jest dopuszczalna, to odpowiednia metoda zglasza
wyjątek UnsupportedOperationException.
Np. dla klas, które implementują kolekcje niemodyfikowalne, metody add i
remove z interfejsu Collection powinny być zdefiniowane jako:
public boolean add(T o) {
throw new UnsupportedOperationException();
}
public boolean remove(T o) {
throw new UnsupportedOperationException();
}
Uwaga: ponieważ kolekcje są sparametryzowane, T oznacza parametr typu.
Czy zamiast tego nie można byłoby dostarczyć po prostu takich definicji metod add i remove, które nie modyfikują kolekcji?
Niestety, nie. Genaralny kontrakt dla metody add brzmi następująco:
Metoda add gwarantuje, że zaraz po jej użyciu podany jako argument obiekt
znajduje się w kolekcji. Zwraca true jeśli kolekcja została zmodyfikowana
(obiekt dodano) i false w przeciwnym razie (co oznacza, że obiekt już był
w kolekcji typu zbiór, czyli takiej, ktora nie dopuszcza duplikatów).
Zatem w przypadku innego od UnsupportedOperationException rozwiązania nie
moglibyśmy wiedzieć, czy false zwrócone przez add oznacza, że obiekt jest
w zbiorze, czy też, że zbiór jest niemodyfikowalny.
W tym kontekście należy podkreslić, że wynik zwracany przez metodę add(...)
jest rozwiazaniem drugiego, wcześniej wspomnianego, problemu: generalizacji
operacji dodawania elementów do kolekcji bez duplikatów.
Podobnie jest z metodą remove. Ma ona usunąć podany jako argument obiekt. Zwraca
true, jeśli obiekt był w kolekcji i został usunięty (kolekcja zmodyfikowana)
oraz false, gdy podanego obiektu w kolekcji nie bylo. Zatem jedynym sposobem
zasygnalizowania, że próbowano usunąć jakiś obiekt z kolekcji niemodyfikowalnej
pozostaje zgłoszenie wyjątku.
W interfejsach kolekcyjnych występuje szereg innych operacji opcjonalnych.
Opcjonalnośc ich wszystkich ma takie samo znaczenie jak w przypadku omówionych
operacji add i remove tzn. wszystkie one zgłaszają wyjątek UnsupportedOperationException,
jeśli operacja nie jest dozwolona.
Przy dodawaniu elementów do kolekcji mogą powstać i inne
wyjątki, zależne od implementacji kolekcji. Implementacje, które nie
dopuszczają dodawania elementów o pewnych właściwościach (np. elementów
null) będą zgłaszać wyjątek IllegalArgumentException.
Te
zaś, które np. czasowo nie dopuszczają dodania elementu (np. w tym
momecie jest przekroczony maksymalny limit wielkości kolekcji)
zgłaszają wyjątek IllegalStateException.
Interfejs Collection określa również tzw. grupowe operacje na kolekcjach, polegające na wykonywaniu "za jednym razem" pewnych operacji na całych kolekcjach.
Należą do nich:
- dodawanie do dowolnej kolekcji wszystkich elementów innej dowolnej kolekcji - metoda addAll(Collection),
- usuwanie z kolekcji wszystkich elementów, które są zawarte w innej kolekcji - metoda removeAll(Collection),
- pozostawienie w kolekcji tylko tych elementów, które są zawarte w innej kolekcji - metoda retainAll(Collection),
- stwierdzanbia czy obie kolekcje zawierają identyczne elementy,
- usunięcie wszystkich elementów kolekcji - metoda clear().
Ponieważ niektóre z tych operacje te mogą modyfikować kolekcje (a o tym czy naprawdę nastąpiła
modyfikacja - świadczą wyniki zwracane przez metody - true albo false), to
- oczywiście - są one operacjami opcjonalnymi.
UWAGA!
Operacje, które wymagają porównywania elementów np.
contains(jakis_obiekt), containsAll(Collection}, removeAll(..),
retainAll(...) używają do tego metody equals() zdefiniowanej w klasach
obiektów.
Operacje grupowe są często bardzo użyteczne: zastępuja one drobne (ale zawsze)
fragmenty kodu, które przy braku operacji grupowych musielibyśmy pisać sami.
W przypadku zbiorów są one bezpośrednim odzwierciedleniem operacji na zbiorach:
sumy zbiorów, wspólnej częsci itp.
A - co ważniejsze - są one z reguły bardziej efektywne od tego co moglibyśmy
napisać sami, bowiem ich implementacje uwzględniają specyficzne cechy implementacji
kolekcji, przy zachowaniu polimorficznego charakteru odwolań.
Niejako kontynuacją operacji grupowych jest możliwość przekształcenia kolekcji
danego rodzaju w dowolną inną kolekcję dowolnego innego rodzaju. Np. listy
w zbiór uporządkowany. Co prawda, w interfejsie Collection nie znajdziemy
żadnych po temu metod ( i nic dziwnego), ale samo jego istnienie daje taką
możliwość.
We wszystkich konkretnych implementacjach kolekcji dostarczono bowiem konstruktorów,
mających jako parametr dowolną inną kolekcję (czyli parametr typu Collection).
Jeśli zatem mamy listę, a chcemy z niej zrobić zbiór uporządkowany (w konkretnej
implementacji - np. drzewa zrównoważonego), to wystarczy użyć konstruktora
odpowiedniej klasy (tu: TreeSet):
List lista;
//... utworzenie listy w konkretnej implementacji np.ArrayList lub LinkedList
Set tset = new TreeSet(lista);
W ten sposób uzyskamy zbiór (a więc bez powtórzeń elementów), uporządkowany
(w naturalnym porządku elementów), którego elementy będą pobrane z dostarczonej
listy.
Oczywiście,
jeśli nie stosujemy typów surowych (jak wyżej), ale kolekcje
sparametryzowane, kompilator zabroni nam dokonywania pewnych
przekształceń (np. uzyskania listy napisów List<String> ze zbioru
liczb Set<Integer>).
Interfejs List dostarcza także metod, służących do uzyskiwania z kolekcji
tablic (to jest interfejs List, a nie Collection, bo tablice są listami). Ich głównym przeznaczeniem jest zapewnienie komunikacji pomiędzy
kolekcjami, a tymi fragmentami kodu, które kolekcji nie wykorzystują (zapewne
najczęsciej będą to programy, które powstały przed wprowadzeniem Java Collection
Framework).
Metoda toArray() zwraca tablicę obiektów (typu Object), będących elementami kolekcji.
Typ wynku - Object[] - nie zawsze będzie nam odpowiadał. Dodatkowym ułatwieniem
(a zarazem ograniczeniem dowolności) jest zatem możliwośc użycia metody o
tej samej nazwie, która - poprzez parametr - specyfikuje typ (ustalany w
fazie wykonania) zwracanej tablicy - toArray(new Typ[n]).
Różnicę w zastosowaniu obu metod pokazuje poniższy fragment kodu:
List<String> list = new ArrayList<String>()
// ... tu dodawanie elementów do listy
// Pierwszy sposób
Object[] tab1 = list.toArray();
for (int i=0; i<tab1.length; i++) {
int len = ((String) tab1[i]).length();
System.out.println(len);
}
// Drugi sposób
String[] tab2 = (String[]) list.toArray(new String[0]);
for (int i=0; i<tab2.length; i++) {
int len = tab2[i].length();
System.out.println(len);
}
} Odwrotnego przekształcenia dostarcza metoda List<T> asList(T ... args) z klasy Arrays, Może ona przyjmować zmienną liczbę argumentów lub tablicę elementów typu T. Wynikiem jest lista niemodyfikowalna.
Np. możemy łatwo uzyskac listę złożoną z kilku napisów:
List<String> lista = Arrays.asList("Ala", "ma", "kota");Podsumowaniem podanych treści może być następujący programik testowy:
import java.util.*;
public class GroupOp {
List<String> list1 = new ArrayList<String>();
Set<String> set1 = new HashSet<String>();
void add(String ...strings ) {
for (String s : strings) {
list1.add(s);
set1.add(s);
}
}
public GroupOp() {
add("Pies", "Kot", "Tygrys", "Zebra", 'Z' + "ebra");
System.out.println(list1);
list1.removeAll(set1);
System.out.println("Usunięte będą wszystkie elementy, bo działa equals:\n"+ list1);
list1.addAll(set1);
System.out.println(list1);
//List<Integer> list2 = new ArrayList<Integer>(list1); // błąd w kompilacji
// Zastosowanie Arrays.asList();
List<Integer> list2 = Arrays.asList(1,2,3,4,5);
System.out.println(list2);
// ale teraz list2 jest fixed-size
try {
list2.add(35);
} catch(Exception exc) {
System.out.println("Wystąpił wyjątek: " + exc);
System.out.println("bo lista niemodyfikowalna:\n" + list2);
}
System.out.println("Możemy zrobić, aby była modyfikowalna:");
list2 = new ArrayList<Integer>(Arrays.asList(1,2,3,4,5));
System.out.println("Teraz możemy dodać coś");
list2.addAll(Arrays.asList(35, 1, 2, 3));
System.out.println(list2);
System.out.println("Gdy chcemy usunąć duplikaty:");
Set<Integer> set2 = new HashSet<Integer>(list2);
System.out.println(set2);
System.out.println("A czy możemy połączyć kolekcje z różnymi typami elementów?\nTak.");
// Nalezy uzyć typu Object
List<Object> list3 = new ArrayList<Object>(list1);
list3.addAll(set2);
System.out.println(list3);
// Tyle, że przy iteracjach już musimy posługiwać się typem Object
// i ew. robić konwersje zawężające
int sum = 0;
String txt = "";
for(Object o : list3) {
if (o instanceof Integer) sum += (Integer) o;
else txt += (String) o;
}
System.out.println("Suma liczb: " + sum);
System.out.println("Napis: " + txt);
// A na koniec sprawdzimy jak z listy zrobić tablicę
// Najlepiej tak, bo będzie uwzględniony typ elementów
System.out.println("Tablica z listy");
String[] tab = (String[]) list1.toArray(new String[0]);
for (String string : tab) {
System.out.println(string + " " + string.length());
}
}
public static void main(String[] args) {
new GroupOp();
}
}da w wyniku:
[1, 2, 3, 4, 5]
Wystąpił wyjątek: java.lang.UnsupportedOperationException
bo lista niemodyfikowalna:
[1, 2, 3, 4, 5]
Możemy zrobić, aby była modyfikowalna:
Teraz możemy dodać coś
[1, 2, 3, 4, 5, 35, 1, 2, 3]
Gdy chcemy usunąć duplikaty:
[35, 1, 2, 3, 4, 5]
A czy możemy połączyć kolekcje z różnymi typami elementów?
Tak.
[Zebra, Kot, Pies, Tygrys, 35, 1, 2, 3, 4, 5]
Suma liczb: 50
Napis: ZebraKotPiesTygrys
Tablica z listy
Zebra 5
Kot 3
Pies 4
Tygrys 6
3. Iteratory
Bardzo ważną metodą interfejsu Collection (tak naprawdę dzidziczoną z interfejsu Iterable) jest metoda iterator(), ktora zwraca iterator.
Iterator jest obiektem klasy implementującej interfejs Iterator
i służy do przeglądania elementów kolekcji oraz ew. usuwania ich przy przeglądaniu
|
Metody interfejsu Iterator
|
T next()
|
Zwraca
kolejny element kolekcji lub sygnalizuje wyjątek NoSuchElementExcption,
jeśli osiągnięto koniec kolekcji. T jest typem elementów kolekcji.
|
void remove()
|
Usuwa element kolekcji, zwrócony przez ostatnie odwolanie do next() Operacja opcjonalna.
|
boolean hasNext()
|
Zwraca true, jeśli ożliwe jest odwołanie do next() zwracające jakiś element kolekcji.
|
Klasy iteratorów są definiowane w klasach kolekcyjnych jako klasy wewnętrzne,
implementujące interfejs Iterator<T>. Implementacja metody iterator() z interfejsu
Collection zwraca obiekt takiej klasy. Dzięki temu od każdej kolekcji możemy
uzyskać iterator za pomocą odwolania:
Iterator<T> iter = c.iterator();
gdzie: c - dowolna klasa implementująca interfejs Collection, T - typ elmentów kolekcji.
Dla tych kolekcji, w których elementy nie zajmują ściśle określonych
pozycji iteratory są jedynym sposobem na "przebieganie" po kolekcji. Co więcej,
dla kolekcji listowych - niezależnie od implementacji - iteratory są efektywnym
narzędziem iterowania, czego nie da się powiedzieć we wszystkich przypadkach
o pętlach iteracyjnych pobierających elementy z pozycji wyznaczanych przez
podane indeksy.
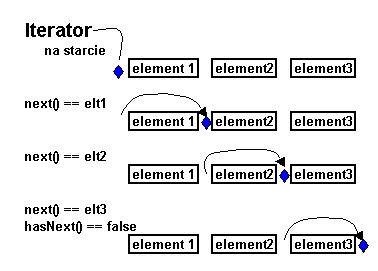
Warto zauważyć, że narzucająca się analogia pomiędzy kursorem i iteratorem
może być myląca. O iteratorze należy raczej myśleć jako o wskaźniku ustawianym
nie na elemencie kolekcji, ale pomiędzy elementami. Na początku iterator
ustawiony jest przed pierwszym elementem. Odwolanie next() jednocześnie
przesuwa iterator za pierwszy element i zwraca ten element. Każde kolejne
next() przeskakuje kolejny element i zwraca ten "przeskoczony" element. Zob. rysunek.
Metoda iteratora remove() może być bardzo użyteczna: najczęściej stosowana
jest do usuwania z kolekcji elementów, które spełniają (nie spełniają) jakichś
warunków. Inne sposoby usuwania takich elementów często mogą okazać się bardziej kosztowne.
Szablon użycia remove() w trakcie iteracji:
Iterator<T> iter = c.iterator(); // c - dowolna kolekcja, typ Collection, T - typ elementów kolekcji
while (iter.hasNext()) {
Object o = iter.next();
if (warunek_usunięcia(o)) iter.remove();
}
Powyższy kod jest polimorficzny: nadaje się do zastosowania wobec dowolnych
kolekcji dowolnych obiektów. Pod koniec tego punktu zobaczymy nieco bardziej
zaawansowany przykład takiego polimorficznego wykorzystania iteratora.
Należy pamiętać, że metoda remove() może usunąć tylko element zwrócony przez next(), i wobec tego może być zastosowana tylko raz dla każdego next().
Zatem nie możemy w jednej iteracji usunąć kilku elementów:

W tym przypadku zostanie zgłoszony wyjątek IllegalStateException.
Istnieją też inne istotne ograniczenia dotyczące modyfikacji kolekcji w trakcie iteracji.
W trakcie iteracji za pomocą iteratora nie wolno modyfikować kolekcji
innymi sposobami niż użycie metody remove() na rzecz iteratora. Wyniki takich
modyfikacji są nieprzewidywalne
Modyfikacje strukturalne (dodanie, usunięcie elementu) są w trakcie iteracji
sprawdzane i wykrywane. Jeżeli w trakcie iteracji zostanie dokonana modyfikacja
strukturalna za pomocą innych od remove() dla bieżącego iteratora metod - powstanie wyjątek ConcurrentModificationException.
Dotyczu to zarówno użycia metod add i remove interfejsu Colection, jak i metody remove, aktywowanej na rzecz innego iteratora.
Zatem w takich sytuacjach:
List<String> l = new ArrayList<String>();
// .. dodanie do listy jakichś elementów
Iterator<String> it1 = l.iterator();
while (it1.hasNext()) {
it1.next();
l.add("Coś"); // Błąd fazy wykonania
}
List<String> l = new ArrayList<String>();
// dodanie do listy jakichś elementów
Iterator<String> it1 = l.iterator();
Iterator<String> it2 = l.iterator();
while (it1.hasNext()) {
it1.next();
it2.next();
it2.remove(); // Błąd fazy wykonania
}
w fazie wykonania zostanie zgłoszony wyjątek ConcurrentModificationException.
Jak
pamiętamy, rozszerzona instrukcja for ("for-each") pozwala łatwiej
iterować po elementach kolekcji, bo jest wygodnym skrótem od:
Iterable<Typ> classObject = ....;
....
for ( Iterator<Typ> $i =
classObject.iterator(); $i.hasNext(); ) {
Typ id = $i.next();
stmt
}
Ponieważ interfejs Collection rozszeraz Iterable, to wszystkie kolekcje są Iterable.
Ale
"for-each" nie we wszystkich przypadkach nadaje się do przeglądania
kolekcji. Bez bezposredniego zastosowania iteratora nie uzyskamy np.
możliwości usuwania elementów z kolekcji przy ich przeglądaniu.
4. Przykład: uniwersalne działania na kolekcjach
Spójrzmy teraz na nieco bardziej rozbudowane i zaawansowany przykład, pokazujące silę interfejsu Collection i iteratorów.
Stworzymy uniwersalną klasy MKolekt, której metody pozwalają zapelniać dowolne kolekcje obiektami dowolnych
klas, tworzonymi na podstawie informacji z plików tekstowych,
zapisywać lementy dowolnych kolekcji dowolnych obiektów do plików
tekstowych, wypisywać na konsoli
elementy dowolnych kolekcji oraz usuwać z dowolnych kolekcji elementy
spelniające
warunki "do usunięcia".
Zadanie jest trudne, bo różnorodność możliwych elementów kolekcji jest
nieograniczona.
Potrzebna jest zatem swoista współpraca naszej uniwersalnej klasy
MKolekt
z klasami konretnych obiektów - elementow kolekcji. Umówmy się więc, że
każda
z klas konkretnych elementów (dowolnych) kolekcji przetwarzanych przez
metody
klasy MKolekt musi zdefiniować trzy metody: metodę tworzenia swojego
obiektu
z podanego napisu (informacje o obiekcie będą w klasie MKolekt
pobierane z pliku tekstowego), metodę określającą czy obiekt spełnia
warunki umożliwiające usunięcie go z kolekcji i metodę tworzenia napisu
z obiektu (być może toString nie wsytarczy, bo przy zapisie do plików
będziemy chcieli inaczej formatować informacje o obiektach.
Naturalnym sposobem zapewnienia tego jest zdefiniowanei odpowiedniego interfejsu
i implementowanie go w klasach obiektów-elementów kolekcji. Nazwijmy ten
interfejs CHelper.
public interface CHelper<T> {
// Tworzy obiekt z podanego napisu s i zwraca go
T makeObject(String s);
// Tworzy String z obiektu - możliwe, że w altrnatywny sposób niż toString
String makeString();
// Zwraca true, jeśli dane obiektu są uznane za nieaktualne
boolean isNotUpToDate();
}Uwaga: interfejs jeste sparametryzowany (parametr typu T). W ten sposób uzyskamy wszystkie zalety generics.
Zatem elementy kolekcji przetwarzanych przez metody klasy MKolekt "będą typu" CHelper.
Klasa MKolekt może wyglądać tak.
import java.io.*;
import java.util.*;
public class MKolekt {
// Tworzy obiekty klasy
// określonej przez klasę klasOb
// na podstawie informacji z pliku tekstowego o nazwie fname
// i dodaje je do kolekcji col
public static <T extends CHelper<T>>
void makeCollectionFromFile(Collection<T> col, String fname,
Class<T> klasaOb) {
try {
CHelper<T> mgr = klasaOb.newInstance();
Scanner in = new Scanner(new File(fname));
while(in.hasNextLine()) {
T obj = mgr.makeObject(in.nextLine());
col.add(obj);
}
in.close();
} catch (Exception exc) {
exc.printStackTrace();
System.exit(1);
}
}
// Usuwa z kolekcji c obiekty przeznaczone do usunięcia
// na podstawie wyniku metodu isNotUpToDate
public static <T extends CHelper<T>> void iterRemove(Collection<T> c) {
Iterator<T> iter = c.iterator();
while (iter.hasNext()) {
CHelper<T> elt = iter.next();
if (elt.isNotUpToDate()) iter.remove();
}
}
// Zapisuje do pliku fname, w kolejnych wierszach,
// kolejne elementy kolekcji col
public static <T extends CHelper<T>>
void writeToFile(Collection<T> col, String fname) throws Exception {
Formatter out = null;
try {
out = new Formatter(new File(fname));
for (T obj : col) {
String line = obj.makeString();
out.format("%s%n", line);
}
} finally {
if (out != null) out.close();
}
}
public static void show(Collection<?> col) {
for (Object o : col) System.out.println(o);
}
}
Jest ona uniwersalna, bowiem będzie działać dla obiektów dowolnych klas
implementujących CHelper i dla dowolnych kolekcji tych obiektów.
Warto zauwazyć:
- sposób
zastosowania sparametryzowanych metod i użycie ograniczeń parametrów
typu (T extends CHelper) - dzieki temu zapewniona jest zgodność typów w
fazie kompilacji i bez konwersji zawęzających możemy stosować metody
deklarowane w interfejsie CHelper,
- metoda
makeCollectionFromFile jako ostatni argument uzyskuje obiekt klasy
Class<T>, gdzie T jest konkretnym typem (nazwą klasy). Obiekt ten
reprezentuje klasę obiektó dodawanych do kolekcji. Jest on nam
potrzebny, bo używając metody newInstance() klasy Class tworzymy (za
pomoca konstruktora bezparametrowego) obiekt klasy elementów , a ten z
kolei jest niezbędny by polimorficznie na jego rzezc wywołać metodę
makeObject(...).
- metoda show(...) pozwala wypisac elementy dowolnej kolekcji, bowiem użyto parametru uniwersalnego <?>.
Szczególnej uwadze można polecić metodę iterRemove, która w pełni polimorficzny
sposób korzysta z całej mocy koncepcji "usuwania elementów podczas iterowania kolekcji".
Aby przetestowac działanie klasy MKolekt wyobraźmy sobie na przykład, że chcemy stworzyć dwie kolekcje: gazet i studentów.
Elementy kolekcji (obiekty klas Journal i Student) będą tworzone na podstawie
informacji zawartych w plikach (gazet i studentów). W pliku gazet podano
tytuł i rok wydania, plik studentow zawiera nazwisko i ocenę.
Po stworzeniu kolekcji (gazet i studentów) będziemy chcieli usunąć z nich
wszystkie elementy, które spelniają warunek: dla gazet - rok wydania mniejszy
od 2003, dla student/ow - ocena mniejsza od 3, a następnie
Program, który wykonuje te działania może wyglądać następująco:
import java.util.*;
public class Test {
public static void main(String[] args) {
List<Journal> gazety = new ArrayList<Journal>();
Set<Student> studenci = new HashSet<Student>();
MKolekt.makeCollectionFromFile(gazety, "Journal.in", Journal.class);
MKolekt.makeCollectionFromFile(studenci, "Student.in", Student.class);
System.out.println("Oryginalna zawartość kolekcji");
MKolekt.show(gazety);
MKolekt.show(studenci);
// ustalenie minimalnego roku wydania
// gazety wydane wczesniej będą usunięte z kolekcji
Journal.setLimitYear(2004);
MKolekt.iterRemove(gazety);
// ustalenie minimalnej oceny
// studenci z oceną niższą będa usunięci z kolekcji
Student.setLimitMark(3);
MKolekt.iterRemove(studenci);
// Pokazujemy po usunięciu
System.out.println("Nowa zawartość kolekcji");
MKolekt.show(gazety);
MKolekt.show(studenci);
// I zapisujemy do pliku
try {
MKolekt.writeToFile(gazety, "Journal.out");
MKolekt.writeToFile(studenci, "Student.out");
} catch (Exception exc) {
exc.printStackTrace();
}
}
}
Wynik działania tego programu może być następujący.
Oryginalna zawartość kolekcji
Polityka 2001
Polityka 2002
Polityka 2003
Polityka 2004
Polityka 2005
Polityka 2006
Polityka 2007
Polityka 2008
New Scientist 2003
New Scientist 2004
New Scientist 2005
New Scientist 2006
New Scientist 2007
New Scientist 2006
Kowalski Jan 5.0
Babacki Bronek 2.0
Dadacki Damian 3.0
Cabacki Czesław 2.0
Abacka Anna 4.0
Malinowski Stefan 3.0
Nowa zawartość kolekcji
Polityka 2004
Polityka 2005
Polityka 2006
Polityka 2007
Polityka 2008
New Scientist 2004
New Scientist 2005
New Scientist 2006
New Scientist 2007
New Scientist 2006
Kowalski Jan 5.0
Dadacki Damian 3.0
Abacka Anna 4.0
Malinowski Stefan 3.0
Dzięki wykorzystaniu ogólności architektury kolekcji oraz polimorficznych
odwołań podobny - krotki - program możemy napisać dla dowolnych innych klas
(nie tylko studentow czy gazet).
Klasy Journal i Student przedstawiają poniższe wydruki (potrzeba implementacji
interfejsu Comparable oraz zdefiniowania metod equals() i hashCode zostanie
wyjaśniona za chwilę, w tym momencie nie ma to znaczenia):
import java.util.*;
public class Journal implements CHelper<Journal>, Comparable<Journal> {
private String title;
private int year;
private static int retainAfter = 0; // rok wydania,
// od ktorego ew. zostawiać gazety
//konstruktor brzparametrowy (wg kontraktu potrzebny do newInstance w MKolekt)
public Journal() { }
public Journal(String t, int y) {
title = t;
year = y;
}
// Implementacja metody stwierdzającej czy Journal można uznać za aktualny
@Override
public boolean isNotUpToDate() {
return year < retainAfter;
}
// Tworzy Journal ze Stringu, w którym tytuł jest ujęty w cudzysłow
// a za tytułem znajduje się rok wydania. Dodaje do kolekcji.
@Override
public Journal makeObject(String s){
String title = "";
int year = -1;
try {
StringTokenizer st = new StringTokenizer(s, "\"");
title = st.nextToken();
year = Integer.parseInt(st.nextToken().trim());
} catch (Exception exc) { }
Journal j = new Journal(title, year);
return j;
}
// Tworzy String z obiektu
// inna forma niż toString (dla zapisu do pliku)
@Override
public String makeString() {
return '"' + title + '"' + " " + year;
}
public static void setLimitYear(int y) { retainAfter = y; }
@Override
public int hashCode() {
return this.toString().hashCode();
}
@Override
public boolean equals(Object obj) {
return toString().equals(obj.toString());
}
@Override
public int compareTo(Journal j) {
return toString().compareTo(j.toString());
}
@Override
public String toString() { return title + " " + year; }
}
import java.util.*;
public class Student implements CHelper<Student>, Comparable<Student> {
private String name;
private double mark; // ocena
private static double minMark; // minimalna ocena
public Student() {}
public Student(String nam, double m) {
name = nam;
mark = m;
}
public void setMark(double m) { mark = m; }
public boolean isNotUpToDate() {
return mark < minMark;
}
// Tworzy obiekt Student i dodaje do kolekcji
// format napisy: nazwisko tab ocena
public Student makeObject(String s) {
Scanner sc = new Scanner(s).useDelimiter("\t");
String name = sc.next();
double mark = 0;
try {
mark = sc.nextDouble();
} catch (Exception exc) {
exc.printStackTrace();
}
Student stud = new Student(name, mark);
return stud;
}
@Override
public String makeString() {
return name + '\t' + mark;
}
// Ustalenie minimalnej oceny.
// Studenci z niższą oceną mogą być usunięci z kolekcji.
public static void setLimitMark(double m) {
minMark = m;
}
public boolean equals(Object obj) {
return name.equals(obj);
}
public int compareTo(Student s) {
return this.toString().compareTo(s.toString());
}
public int hashCode() { return this.toString().hashCode(); }
public String toString() { return name + " " + mark; }
}
Warto jeszcze raz zwrócić uwagę, że metody klasy MKolekt dzialają dla różnego
rodzaju kolekcji (ArrayList i HashSet) elementów dwóch bardzo róznych klas
(Student i Journal).
Będą też działać dla dowolnych innych rodzajów kolekcji (byleby implementowaly
interfejs Collection) i dowolnych innych klas elementów (byleby implementowaly
interfejs CHelper) i definiowały konstruktor bezparametrowy.
5. Listy i iteratory listowe
Lista jest ciągiem elementów uporządkowanych w tym sensie, że każdy
element zajmuje określoną pozycję na liście.
JCF dostarcza dwoch implemantacji listy: tablicowej (klasa ArrayList) i liniowej z podwójnymi dowiązaniami (klasa LinkedList).
Implementacja tablicowa polega na realizacji listy w postaci tablicy z dynamicznie
(w miare potrzeby) zwiększającymi się rozmiarami. Elementy listy są zapisywane
jako elementy takiej tablicy.
Ponieważ tablice w Javie mają określone (niezmienne po utworzeniu) rozmiary
utworzenie listy tablicowej wymaga alokacji tablicy z jakimś zadaną rozmiarem.
Jest on specyfikowany przez initialCapacity (domyślnie 10), który to parametr
możemy podać w konstruktorze ArrayList, jeśli inicjalna pojemnośc nam nie
odpowiada. Przy dodawaiuu elementow do listy sprawdzane jest czy pojemność
tablicy jest wystarczająca, jeśli nie to rozmiar tablicy jest zwiększany,
Służy temu metoda ensureCapacity(minCapacity), któeą zresztą możemy wywolać
sami, aby w trakcie działania programu zapewnić podaną jako minCapacity pojemność
listy.
Uproszczone fragmenty realizacji klasy ArrayList (autorem jest
Josh Bloch, główny twórca JCF oraz Neal Gafter) przedstawiono poniżej.
public class ArrayList<E> implements List<E> // , ...
{
private transient Object elementData[];
private int size;
public ArrayList(int initialCapacity) {
this.elementData = new Object[initialCapacity];
}
public ArrayList() {
this(10);
}
public void ensureCapacity(int minCapacity) {
// ...
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1;
if (newCapacity < minCapacity) newCapacity = minCapacity;
elementData = new Object[newCapacity];
System.arraycopy(oldData, 0, elementData, 0, size);
}
}
public boolean add(Object o) {
ensureCapacity(size + 1);
elementData[size++] = o;
return true;
}
// ...
}
Źrodło: Josh Bloch, Neal Gafter, klasa ArrayList (źródła)
Jak widać, w przypadku braku miejsca na dodanie nowego elementu rozmiary
tablicy zwiększają się nie o 1, ale o pewien współczynnik. Dzięki temu realokacje
tablicy i przepisywanie jej elementów nie muszą być wykonywane zbyt często.
Implementacja liniowa z podwójnymi dowiązaniami umieszcza dane w strukturach danych - nazwiemy je wiązaniami (link
) - które zawierają wskaźniki do poprzedniego i następnego elementu listy
(dlatego dowiązania są "podwójne", niejako dwukierunkowe). Zatem elementy
listy, które z punktu widzenia programisty są elementami umieszczanych danych
(np. nazwisk lub jakichś innych obiektów), technicznie są "linkami", zawierającymi
nie tylko dane, ale również wskaźniki na następny i poprzedni element na
liście.
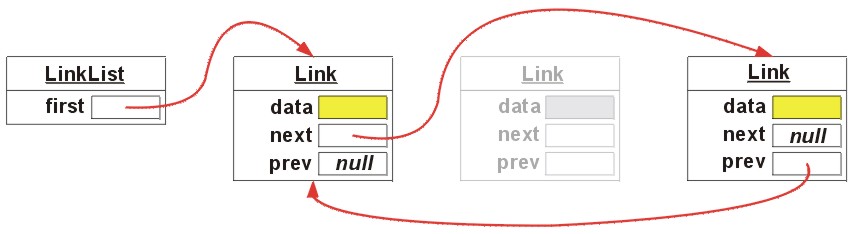
Początek listy dowiązaniowej, zwany głową lub wartownikiem zawiera wskazanie na pierwszy element listy (null, jeśli lista jest pusta).
Ilustruje to poniższy rysunek:
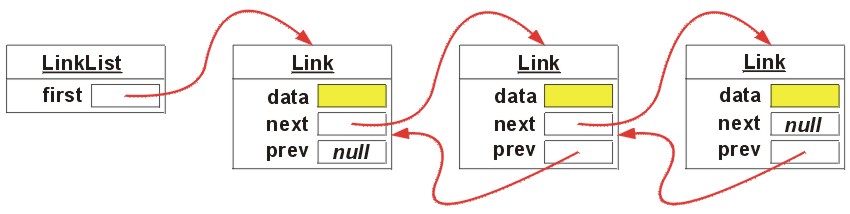
Objaśnienia:
first - wskazanie na pierwszy element listy,
data - refrencja do obiektu (dane elementu),
next - wskazanie na następny element na liście
prev - wskazanie na poprzedni element lsity
Każda lista (niezależnie od implementacji) umożliwia wykonywanie następujących
operacji (ktore są specyfikowane przez interfejs List).
|
Operacje na liście
|
wszystkie metody interfejsu Collection
|
Ogóne operacje właściwe dla wszelkich kolekcji (np. add, remove, contains, operacje gupowe)
|
| boolean add(int p, T elt) | Dodaje element typu T na pozycji p. Zwraca true jeśli lista została zmodyfikowana.
|
| boolean addAll(int p, Collection c)
| Dodaje wszystkie elementy kolekcji c do listy poczynając od pozycji p. Zwraca true jeśli lista została zmodyfikwoana.
|
| T get(int p) | Zwraca element na pozycji p (T jest typem elmentu)
|
| int indexOf(T elt) | Zwraca pozycję (indeks) piewrszego wystapienia elementu elt
|
| int lastIndexOf(T elt) | Zwraca indeks ostatniego wystąpienia elementu elt
|
| ListIterator<T> listIterator() | Zwraca iterator listowy, ustawiony na początku listy (przed pierwszym elementem).
|
| ListIterator<T> listIterator(int p) | Zwraca iterator listowy ustawiony przed elementem o indeksie p.
|
| boolean remove(int p) | Usuwa element na pozycji p. Zwraca true jeśli lista została zmodyfikwoana.
|
| T set(int p, T val) | Zastępuje element na pozycji p podanym elementem elt. Zwraca poprzednio znajdujący się na liście element.
|
| List<T> subList(int f, int l) | Zwraca podlistę zawierającą elementy listy od pozycji f włacznie do pozycji l (wyłącznie).
|
Uwagi:
- wszystkie operacje modyfikującę listę strukturalnie lub pod względem zawartości są opcjonalne,
- pozycje na liście numerowane są od 0 (tak jak indeksy w tablicy).
Jak widać, operacje na liście rozszerzają możliwości operowania na kolekcjach o operacje pozycyjne - takie, które uzwględniają pozycję elementów.
Ze względu na znajomość pozycji elementów w kolekcji możliwe staje się iterowanie
po kolekcji w obie strony: od początku i od końca. Można też ustawić iterator
w taki sposób, by iteracje rozpoczynały się od podanej pozycji, a znając
pozycję elementu zwracanego przez iterator można nie tylko go usunąc, ale
zamienić lub dodać nowy element na pozycji wyznaczanej przez stan iteratora.
Dlatego właśnie oprócz zwyklego (ogólnego dla wszystkich kolekcji) iteratora, listy udostępniają iteratory listowe, które są obiektami klas implementujących interfesj ListIterator. Ten ostatni jest rozszerzeniem interfejsu Iterator.
|
Operacje iteratora listowego
|
| void | add(T o)
Dodaje podany
element do listy na pozycji wyznaczanej przez iterator. (operacja
opcjonalna). |
| boolean | hasNext()
Zwraca true,
jeśli są jeszcze elementy na liście, w sytuacji iterowania od początku
do końca. |
| boolean | hasPrevious()
Zwraca true,
jeśli są jeszcze elementy na liście w sytuacji iterowania od końca
do początku. |
| Object | next()
Zwraca następny element na liście i przesuwa iterator. |
| int | nextIndex()
Zwraca indeks elementu, który byłby zwrócony przez odwołanie do next(). |
| Object | previous()
Zwraca poprzedni element na liście i przesuwa iterator. |
| int | previousIndex()
Zwraca indeks elementu, któy byłby zwrócony przez odwolanie previous. |
| void | remove()
Usuwa z
listy ostatni element który byl zwrocony przez ostatnie odwołanienext lub previous (operacja opcjonalna). |
| void | set(T o)
Zastępuje element zwrocony prez next lub
previous podanym elementem (operacja opcjonalna). |
Uwagi:
- konkurencyjne modyfikacje wartości elementów listy w trakcie iteracji za pomocą iteratora listowego nie są wykrywane,
- w przeciwieństwie do metody add z interefejsu
Collection metoda add iteratora listowego nie zwraca żadnego wyniku: na liście
operacja dodawania zawsze jest skuteczna.
Jak pamiętamy, iterator zajmuje pozycję pomiędzy elementami. Kolejne odwołanie
do next() lub previous() powoduje, że iterator "przeskakuje" zwrócony element.
W tym miejscu wlaśnie zostanie wpisany element, jeśli użyjemy metody add.
Natomiast metoda remove() usuwa zawsze element zwrócony przez ostatnie odwolanie do next() lub previous().
Szczególnie przy stosowaniu iteratora listowego należy pamiętać o tym, że iterator "zajmuje pozycję" pomiędzy elementami
Ilustruje to poniższy program, który pokazuje kolejne postępy iteracji i
zmiany na liście na skutek zastosowania metod add i remove.
import java.util.*;
class ListIter1 {
static <T> void state(ListIterator<T> it) {
int pi = it.previousIndex(),
ni = it.nextIndex();
System.out.println("Iterator jest pomiędzy indeksami: " + pi + " " + ni);
}
public static void main(String args[]) {
List<String> list = new LinkedList<String>(Arrays.asList(
new String[] { "E0","E1", "E2", "E3" }
));
ListIterator<String> it = list.listIterator();
it.next();
state(it);
it.add("nowy1");
System.out.println(list);
it.next();
it.next();
it.previous();
state(it);
it.add("nowy2");
System.out.println(list);
it.previous();
it.previous();
state(it);
it.remove();
System.out.println(list);
}
}
Wydruk:
Iterator jest pomiędzy indeksami: 0 1
[E0, nowy1, E1, E2, E3]
Iterator jest pomiędzy indeksami: 2 3
[E0, nowy1, E1, nowy2, E2, E3]
Iterator jest pomiędzy indeksami: 1 2
[E0, nowy1, nowy2, E2, E3]
Mimo, że w programach działających na listach posługiwać się będziemy metodami
interfejsu List (niejako niezależnie od implementacji), to wybór implementacji
listy nie jest obojętny dla efektywności dzialania naszego programu.
Praktycznie implementację liniową z podwójnymi dowiązaniami (LinkedList) powinniśmy wybierać tylko wtedy, gdy na liście będą wykonywane częste operacje wstawiania i/lub usuwania elementów w środku listy (poza końcem listy).
Istotnie na liście typu LinkedList takie operacje polegają na zmianie dwóch
dowiązań (prowadzącego do poprzedniego i do następnego elementu) - są więc
bardzo szybkie, zaś w implementacji tablicowej (ArrayList) wiążą się z przepisywaniem
elementów tablicy, co (zwykle) zabiera więcej czasu.
Usunięcie elementu na liście LinkedList:
Dodanie elementu na liście LinkedList:
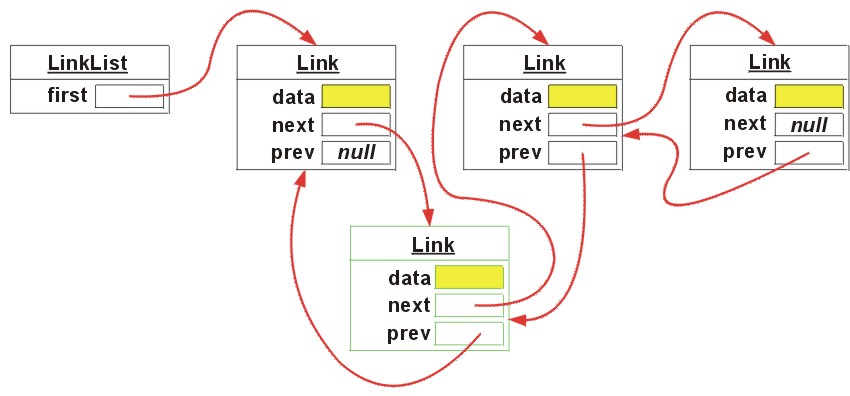
Taka sama operacja dodania elmentu na ArrayList jest znacznie bardziej kosztowna,
o czym przekonuje nas (uproszczony) fragment realizacji klasy ArrayList:
public void add(int index, Object element) {
// ...
ensureCapacity(size+1);
// Przesunięcie - czyli przekopiowanie elementów tablicy!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
Źrodło: Josh Blosh, Neal Gafter, klasa ArrayList (źródła)
Z kolei, operacje bezpośredniego dostępu do elementów listy są w implementacji
tablicowej ArrayList natychmiastowe (polegają na indeksowaniu tablicy), natomiast
w implementacji LinkedList są bardzo nieefektywne, gdyż technicznie wymagają
przebiegania po elementach listy od samego jej początku lub od końca w kierunku
początku (ten ostatni przypadek jest jedyną optymalizacją dostępu w klasie
LinkedList, dokonywaną wtedy, gdy indeks znajduje się "w drugiej polowie"
listy).
Poniższy program mierzy czas poszczegolnych operacji dla dwóch implementacji list.
import java.util.*;
import javax.swing.*;
public class Lists {
long start;
void setTimer() { start = System.currentTimeMillis(); }
long elapsed() { return System.currentTimeMillis() - start; }
public Lists(int n) {
ArrayList<String> aList = new ArrayList<String>(n);
for (int i=0; i < n; i++) aList.add("a");
LinkedList<String> lList = new LinkedList<String>(aList);
setTimer();
randomAccess(aList);
System.out.println("Swobodny dostęp do ArrayList: " + elapsed() + " ms");
setTimer();
randomAccess(lList);
System.out.println("Swobodny dostęp do LinkedList: " + elapsed() + " ms");
setTimer();
insert(aList);
System.out.println("Wpisywanie na ArrayList: " + elapsed() + " ms");
setTimer();
insert(lList);
System.out.println("Wpisywanie na LinkedList: " + elapsed() + " ms");
}
void randomAccess(List<String> l) {
Random rand = new Random();
for (int i=0; i<10000; i++) {
int index = rand.nextInt(l.size());
String s = l.get(index);
s = s + "a";
l.set(index, s);
}
}
void insert(List<String> l) {
ListIterator<String> iter = l.listIterator();
int i = 0;
while (iter.hasNext()) {
iter.next();
if (i % 2 != 0) iter.add("b");
i++;
}
}
public static void main(String args[]) {
new Lists(new Scanner(JOptionPane.showInputDialog("Ile elementó na liście?")).nextInt());
}
}
Metoda randomAccess() 10000 razy zmienia elementy pod losowo wybranymi indeksami,
a metoda insert() po każdym elemencie o nieparzystym indeksie dopisuje jakiś
nowy element.
Wynik dzialania programu (dla list 100000 elementów) pokazano poniżej.
Swobodny dostęp do ArrayList: 31 ms
Swobodny dostęp do LinkedList: 10125 ms
Wpisywanie na ArrayList: 7829 ms
Wpisywanie na LinkedList: 46 ms
Na listach LinkedList nie należy nigdy stosować operacji get(int index) i set(int index, Object value)
Skoro jednak powinniśmy pisać nasze kody (szczególnie metody) w kategoriach
interfejsów kolekcyjnych, a nie konkretnych implementacji, to jak rozpoznać
z jaką implementacją mamy do czynienia i czy można wykorzystać jej zalety
i uniknąć wad?
Służy temu interfejs znacznikowy RandomAccess. Wszystkie implementacje list, które umozliwiają swobodny dostęp w czasie stałym. a więc szybsze wykonanie pętli:
for (int i=0, n = list.size(); i<n; i++) list.get(i);
niż pętli:
for (Iterator iter = list.iterator(); iter.hasNext(); ) iter.next();
powinny go implementować (np. klasa ArrayList implementuje ten interfejs, a LinkedList - nie)
W naszych kodach możemy sprawdzić, czy implementacja umożliwia efektywny dostęp swobodny poprzez użycie konstrukcji list instanceof RandomAccess.
Wyszukiwanie elementów na listach (czy to klasy ArrayList czy LinkedList) za pomocą ogólnych metod interfejsu Collection (contains(Object)) oraz interfejsu List indexOf(Object)) nie jest efektywne.
Jeśli zależy nam na szybkim odnajdywaniu elementów - powinniśmy albo zastosować
inny rodzaj kolekcji (np. zbiory w implementacji tablic mieszania), albo
posortować listę (metoda sort) i zastosować wyszukiwanie binarne (metoda
binarySearch). Obie te metody są implementacjami algorytmów kolekcyjnych,
dostarczanych w klasie Collections.
Obie implementacje list - ArrayList i LinkedList nie są przeznaczone do użycia współbieżnego (nie są wielowątkowo bezpieczne). Zapewnienie możliwości współdzielenia kolekcji przez wiele wątków wymaga synchronizacji, co jest czasowo kosztowne.
Zatem tylko na wyraźne życzenie programisty - poprzez stworzenie synchronizowanego
widoku kolekcji (zob. punkt o widokach kolekcji) - można uzyskać listy wielowątkowo
bezpieczne.
Istnieje również możliwość wykorzystania klasy Vector, która - od dawna obecna
w Javie - jest obecnie niczym innym jak synchronizowaną wersją klasy ArrayList.
6. Kolejki
Stosując kolejki - w przeciwieństwie do list - nie
możemy bezposrednio sięgać po dowolne elementy (na dowolnych pozycjach)
ani też wstawiać elementów na dowolnych pozycjach.
Kolejka (ang. queue, wym. k:ju)
jest sekwencją elementów, na której operacje wstawiania,
pobierania i usuwania elementów są możliwe tylko w określonym porządku.
Najczęściej porządkiem tym jest FIFO - first in - first out, co odpowiada intuicyjnemu pojmowaniu kolejki: pierwszy przyszedł, pierwszy zostanie obsłuzony.
W kolejkach FIFO możliwe są tylko następujące operacje wstawiania, pobierania i usuwania elementów:
- wstawienie elementu na końcu liniowej sekwencji elementów,
- pobrania elementu z początku liniowej sekwencji elementów,
- usunięcia elementu z początku liniowej sekwencji elementów.
Kolejki LIFO - last-in - first-out (inaczej zwane stosami - ang. stack) dopuszczają operacje:
- wstawienie elementu na początku liniowej sekwencji elementów,
- pobrania elementu z początku liniowej sekwencji elementów,
- usunięcia elementu z początku liniowej sekwencji elementów.
Jest to niejako porządek odwrotny od FIFO: ten kto przyszedł ostatni, będzie obsłużony pierwszy.
Kolejki z priorytetami
pobierają i usuwają elementy z pocżątku, ale początek okreslany jest
przez kryteria porównywania obiektów. Sekwencja elementów nie musi być
liniowa (a porządek elmentów zwracany przez iterator jest nie określony)
Kolejki mogą być nieograniczone (nie ma limitu na miejsce) lub ograniczone (mieszczące jakąś określoną liczbę elementów).
Wszystkie kolejki oferują następujące operacje, określane przez interfejs Queue.
| Operacja |
Metody zgłaszające wyjątki
przy braku miejsca lub elementów
|
Metody nie zgłaszające wyjątków
przy braku miejscalub elementów |
| Wstawianie |
boolean add(T e)
zwraca true gdy sukces
lub zgłasza wyjątek
IllegalStateException
przy braku miejsca
|
boolean offer(T e)
zwraca:
true - gdy sukces,
false - gdy nie ma miejsca.
Zgłasza wyjątek
IllegalArgumentException,
jesli nie dopuszcza wstawienia
danego rodzaju elementu |
| Usuwanie |
T remove()
zwraca usunięty z początku element typu T
lub zgłasza wyjątek:
NoSuchElementException
jeśli kolejka jest pusta |
T poll()
zwraca usunięty z pocżatku element typu T
lub null, jesli kolejka jest pusta
|
Pobieranie
bez usuwania |
T element()
zwraca element z początku
lub zgłasza wyjątek:
NoSuchElementException
jeśli kolejka jest pusta |
T peek()
zwraca element z pocżatku
lub null, jesli kolejka jest pusta
|
Kolejka podwójna (ang. deque, wym. dek)
jest liniową sekwencją elementów, na której operacje wstawiania, pobierania i
usuwania elementów są możliwe na obu końcach sekwencji.
Operacje na kolejce podwójnej są określane przez interfejs Deque, który dodaje do Queue metody o samoobjaśniajacych się nazwach:
|
Na początku |
Na końcu |
|
Z wyjątkiem
przy braku miejsca lub elementów |
Bez tego wyjątku |
Z wyjątkiem
przy braku miejsca lub elementów |
Bez tego wyjątku |
| Wstawianie |
boolean addFirst(e) |
boolean offerFirst(e) |
boolean addLast(e) |
boolean offerLast(e) |
| Usuwanie |
T removeFirst() |
T pollFirst() |
T removeLast() |
T pollLast() |
Pobieranie
bez usuwania |
T getFirst() |
T peekFirst() |
T getLast() |
T peekLast() |
Wśród gotowych implementacji kolejek w JCF są dostępne następujące klasy:
- LinkedList - lista, która jest jednocześnie kolejką podwójną (bez ograniczeń na miejsce),
- ArrayDeque - kolejka podwójna, zrealizowana jako rozszerzalna tablica
- PriorityQueue - kolejka z priorytetami.
Działania na kolejkach ilustruje poniższy program:
import java.util.*;
public class Kolejki {
public static void main(String[] args) {
ArrayDeque<Integer> deq = new ArrayDeque<Integer>();
// Działa jak kolejka FIFO
deq.offer(1);
deq.add(20);
deq.add(12);
System.out.println("FIFO: " + deq);
System.out.println("Podglądamy (z początku): " + deq.peek());
// Działa jak kolejka LIFO
deq.clear();
deq.addFirst(1);
deq.addFirst(20);
deq.addFirst(12);
System.out.println("LIFO: " + deq);
System.out.println("Podglądamy (z początku): " + deq.peek());
// Kolejka z priorytetami
PriorityQueue<Integer> pq = new PriorityQueue<Integer>();
pq.add(1);
pq.add(20);
pq.add(12);
System.out.println("PRIOR QUE: " + pq);
System.out.println("Z kolejki z priorytami pobieramy\nkolejne elementy\nzawsze z początku");
System.out.println("Początek - domyślnie najmniejszy element");
Integer n;
while((n = pq.poll()) != null) {
System.out.println(n);
}
}
}który da w wyniku:
FIFO: [1, 20, 12]
Podglądamy (z początku): 1
LIFO: [12, 20, 1]
Podglądamy (z początku): 12
PRIOR QUE: [1, 20, 12]
Z kolejki z priorytami pobieramy
kolejne elementy
zawsze z początku
Początek - domyślnie najmniejszy element
1
12
20
7. Zbiory. Haszowanie i porządkowanie.
Zbiór jest kolekcją elementów bez ustalonego porządku ich występowania
w kolekcji oraz bez duplikatów, tj. kolekcja nie zawierającą dwóch takich
samych elementów
Z punktu widzenia operowania na zbiorach mamy do dyspozycji metody interfejsu
Set (które są takie same jak omówione wcześniej metody interfejsu Collection).
Jedyne uszczegółowienie polega na tym, że w przypadku zbiorów, metody dodające
elementy do zbiorów zwracają wartość false, jeśli dodawane elementy już w
zbiorze występują.
Zatem przy dodawaniu elementu do zbioru musi nastąpić sprawdzenie
czy zbiór nie zawiera już dodawanego elementu.
Słowo "mieszanie"
używane w polskiej literaturze jako tłumaczenie słowa "hash" jest w tej chwili
stosowane równolegle lub nawet wypierane przez słowo "haszowanie"
Są przynajmniej
dwa sposoby efektywnego sprawdzania tego. Pierwszy (użycie tablicy mieszającej)
jest zrealizowany w klasie HashSet, drugi (wyszukiwanie binarne z użyciem
drzewa czerwono-czarnego) - w klasie TreeSet.
Tablica mieszania (hashtable) jest strukturą danych specjalnie
przystosowaną do szybkiego odnajdywania elementów. Dla każdego elementu danych
wyliczany jest kod numeryczny (liczba całkowita) nazywany kodem mieszania
(hashcode), na podstawie którego obliczany jest indeks w tablicy,
pod którym będzie umieszczony dany element. Może się zdarzyć, że kilka elementów
otrzyma ten sam indeks, zatem elementy tablicy mieszającej stanowią listy,
na których znajdują się elementy danych o takim samym indeksie, wyliczonym
na podstawie ich kodów mieszania.
Każda lista - element tablicy mieszania nazywa się kubełkiem (bucket).
Aby umieścić nowy element w tablicy mieszania, wyliczany jest jego hashcode
, po czym na podstawie jego wartości obliczany jest indeks w tablicy mieszania.
Indeks taki stanowi resztę z dzielenia wartości kodu mieszania przez liczbę
kubełków. Element umieszczany jest w kubełku pod tym indeksem.
Istotne jest w tej procedurze, by:
- wyliczanie kodu mieszania było szybkie,
- kody mieszania dla rożnych elementów zależały tylko od ich wartości i były (możliwie) różne dla różnych wartości elementów,
- wynikowe indeksy dawały możliwie równomierną dystrybucję elementów danych po elmentach tablicy mieszania.
W Javie można wyliczyć kod mieszania dla każdego obiektu za pomocą zastosowania metody hashCode()
. Metoda ta, zdefiniowana w klasie Object, daje - ogólnie - jako wynik adresy
obiektów. To, oczywiście, nie jest zbyt użyteczne, bowiem nie bierze pod
uwagę zawartości obiektów (wszystkie obiekty mają rożne kody mieszania).
Ale w standardowych klasach Javy metoda hashCode() została przedefiniowana,
tak, by zwracała kod na podstawie "treści" obiektu, np. napisu stanowiącego
"zawartość" obiektu klasy String. Dwa takie same napisy będą miały te same
kody mieszania.
Zobaczmy na przykładzie jak wygląda umieszczanie i wyszukiwanie elementow
w tablicy mieszania. Napisy "a", "b", "c", "d", "e", "f'", "g", "h", "i"
będą umieszczone w tablicy o 7 kubełkach w następujacy sposób.
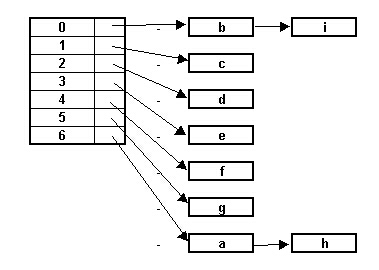
Odpowiednie kody mieszania dla kolejnych napisów, oraz odpowiadające im indeksy
tablicy (reszta z dzialenia kodu przez liczbę kubełków) są następujące:
a kod: 97 indeks: 6
b kod: 98 indeks: 0
c kod: 99 indeks: 1
d kod: 100 indeks: 2
e kod: 101 indeks: 3
f kod: 102 indeks: 4
g kod: 103 indeks: 5
h kod: 104 indeks: 6
i kod: 105 indeks: 0
Jak widać, indeksy dla 'b' oraz 'i', a także dla 'a' oraz 'h' są takie same,
wobec tego napisy znajdują się pod tym samym indeksem (w tym samym kubelku)
jako kolejne elementy listy.
Łatwo zauważyć, że wyszukanie elementu w tablicy mieszania jest bardzo efektywne.
Wystarczy obliczyć indeks tablicy na podstawie kodu mieszania szukanego elementu
i jeżeli w danym kubełku jest tylko jeden element, to - nawet nie wykonując
żadnych porównań - zwrócić ten element (lub wartość true - że jest). Jeżeli
w kubełku jest kilka elementów, to musimy wykonać ich porównanie z szukanym
elementem, ale i tak liczba porównań będzie zwykle bardzo niewielka w stosunku
do liniowego czy nawet binarnego wyszukiwania.
Prostą, ilustracyjną implementację zbioru jako tablicy mieszania pokazuje
poniższy program, będący jednocześnie narzędziem do śledzenia co dzieje się
z elementami, jakie mają kody mieszania, jak są wstawiane i jak mogą być
odszukane.
import java.util.*;
public class Hash {
final int NB = 7; // liczba kubełków
LinkedList[] hashTab = new LinkedList[NB]; // tablica mieszania
public Hash() {
for (int i=0; i<NB; i++) hashTab[i] = new LinkedList();
String[] napisy = { "a", "b", "c", "d", "e", "f", "g", "h", "i", "a" };
for (int i=0; i<napisy.length; i++) insert(napisy[i]);
for (int i=0; i<NB; i++) {
String report = i + " - ";
Iterator it = hashTab[i].iterator();
while (it.hasNext()) {
report += " - " + it.next();
}
System.out.println(report);
}
System.out.println("Czy zawiera *a* ? - " + contains("a"));
System.out.println("Czy zawiera *k* ? - " + contains("k"));
}
public void insert(String s) {
int hashCode = s.hashCode();
int index = hashCode % NB;
boolean isThere = isThere(index, s);
if (!isThere) hashTab[index].add(s);
System.out.println(s + " kod: " + hashCode +
" indeks: " + index +
(isThere ? " już tam jest" : " został dodany") );
}
public boolean contains(String s) {
return isThere(s.hashCode() % NB, s);
}
private boolean isThere(int index, String s) {
for (Iterator i = hashTab[index].iterator(); i.hasNext(); )
if (s.equals(i.next())) return true;
return false;
}
public static void main(String args[]) {
new Hash();
}
}
Uwaga:
w programie użyto typów surowych (LinkedList i Iterator), ponieważ w
Javie nie można tworzyć tablic elementó typów sparametryzowanych; dla
szybkiej ilustracji wybrano tablicę list, mniej klarowną alternatywą
byłaby lista list..
Wyniki działania programu:
a kod: 97 indeks: 6 został dodany
b kod: 98 indeks: 0 został dodany
c kod: 99 indeks: 1 został dodany
d kod: 100 indeks: 2 został dodany
e kod: 101 indeks: 3 został dodany
f kod: 102 indeks: 4 został dodany
g kod: 103 indeks: 5 został dodany
h kod: 104 indeks: 6 został dodany
i kod: 105 indeks: 0 został dodany
a kod: 97 indeks: 6 już tam jest
0 - - b - i
1 - - c
2 - - d
3 - - e
4 - - f
5 - - g
6 - - a - h
Czy zawiera *a* ? - true
Czy zawiera *k* ? - false
W podobny sposób mógłby być implementowany HashSet (tak naprawdę mamy tam
listę liniową z pojedyńczymi dowiązaniami, w programie ilustracyjnym skorzystaliśmy
dla wygody z gotowej klasy LinkedList).
Zwróćmy szczególną uwagę (również na przykładzie ilustracyjnego programu),
że oprócz wyliczania kodów mieszania do prawidłowego dodawania i odnajdywania
elementów potrzebne jest odpowiednie zdefiniowanie metody equals(), porownującej "treść" dwóch obiektów.
Jeżeli prawdziwe jest a.equals(b),
to musi być spełniony warunek a.hashCode() == b.hashCode().
Oczywiście, zarowno hashCode() jak i equals() są dobrze zdefiniowane w standardowych klasach Javy.
Tworząc wlasne klasy musimy sami zadbać o właściwe zdefiniowanie metod hashCode() i equals().
Należy pamiętać, że przedefiniowujemy metodę equals z klasy Object. A
tam jej parametrem jest Object. Użycie innego typu parametru prowadzi do
przeciążenia (a nie przedefiniwonia) metody i uniemożliwia polimorficzne
do niej odwołania.
Metodę hashCode definiujemy w klasie jako:
public int hashCode() {
// obliczenie kodu mieszania na podstawie wartości pól klasy (elementów obiektu)
// dla pól obiektowych użyjemy metody hashCode() z ich klas
// staramy się przy tym zapewnić odpowiednie zróżnicowanie kodów
}
Metodę equals definiujemy w następujący sposób:
public boolean equals(Object obj) {
// jeżeli porównywane obiekty należą do różnych klas - nie są równe!
if (obj == null || getClass() != obj.getClass()) return false;
// tu porównujemy zawartość obiektów i zwracamy true lub false
}
Uwaga.
Przynależność do różnych klas jest - w programowaniu obiektowym - pojęciem
względnym, Mówimy przecież, że jeśli klasa B dziedziczy klasę A to jej obiekty
są również obiektami klasy A. Jeśli teraz dodatkowo C dziedziczy A, to -
zgodnie z przyjętą konwencją - obiekty klasy C są również
obiektami klasy A, czyli tej samej klasy co obiekty klasy B. Zatem
ogólniejsza konstrukcja metody equals wygląda tak:
class JakasKlasa {
public boolean equals(Object obj) {
// jeżeli porównywane obiekty należą do różnych klas - nie są równe!
if (!(obj instanceof JakasKlasa)) return false;
// tu porównujemy zawartość obiektów i zwracamy true lub false
}
//...
}
Teraz (w następujących przykładach) przyjmiemy jej bardzą ścisłą intrepretację (na poziomie dokładnej zgodności klas).
Również definiowanie metody hashcode() ma swoje niuanse. Istotna jest nie
tylko wspomniana wcześniej zgodność z equals, ale również to, by całkowitoliczbowy
kod zwracany prze tę metodę był (możliwie najbardziej) unikalny dla róznych
(pod względem zawartości) obiektów. Nie wchodząc w szczegóły, możemy podać
tu swoisty przepis na dobrą metodę hascode().
- Ustal wartość stałej całkowitoliczbowej wynik (liczba całkowita, najlepiej pierwsza np 19) .
- Dla każdego pola klasy, branego pod uwagę przy porównywaniu obiektów, wylicz całkowitoliczbowy kod c:
- jeżeli pole f jest typu boolean: c = (f ? 0 : 1).
- jeżeli pole f jest typu byte, char, short, albo int: c = (int)f.
- jeżeli pole f jest typu long: c = (int)(f ^ (f >>> 32)).
- jeżeli pole f jest typu float: c = Float.floatToIntBits(f).
- jeżeli pole f jest typu double, wylicz long l = Double.doubleToLongBits(f), a następnie zastosuje przekształcenie c = (int)(l ^ (l >>> 32)).
- jeżeli pole f jest referencją, zastosuj (jeśli trzeba rekursywnie,
albo po odpowiednim przekształceniu referencji) metodę hashcode() z klasy
obiektu wskazywanegop przez tę referencję, najprościej c = f.hashcode(),
- jeżeli pole f oznacza tablicę, zastosuj opisaną wyżej procedutę rekursywnie
(dla każdego elementu tablicy) i wylicz kod wynikowy jak poniżej (następny
punkt)
- Składaj wyniki powyższych obliczeń w formule: wynik = 37*wynik + c;
- Zwróć ten wynik (jako wynik metody hashcode())
Środowiska uruchomieniowe (m.in. Eclipse)
dają możliwość automatycznej generacji kodów metod hashCode() i
equals() poprzez wybór opcji z menu.
Podkreślmy jezcze raz: wynik metody hashcode musi być zgodny z equals. Równość obiektów implikuje równość hash-kodów.
Przykład.
import java.util.*;
class Worker {
private String lname;
private String fname;
private int salary;
public Worker(String fn, String ln, int sal) {
lname = ln;
fname = fn;
salary = sal;
}
public int hashCode() {
int wynik = 17;
wynik = 37*wynik + lname.hshcode();
wynik = 37*wynik + fname.hashcode();
return wynik;
}
public boolean equals(Object obj) {
if (obj == null || getClass() != obj.getClass()) return false;
Worker w = (Worker) obj;
return fname.equals(w.fname) && lname.equals(w.lname);
}
public String toString() {
return fname + " " + lname + " " + salary;
}
public static void main(String args[]) {
Worker[] p = { new Worker("Jan", "Kowalski", 1000),
new Worker("Jan", "Malinowski", 1200),
new Worker("Jan", "Kowalski", 1400)
};
Set set = new HashSet();
for (int i=0; i < p.length; i++) set.add(p[i]);
System.out.println(set.toString());
}
}
Obiekty klasy Worker różnią się, jeśli robotnicy mają inne imiona i/lub nazwiska
(w realnym programowaniu powinniśmy użyć jakiejś bardziej jednoznacznej identyfikacji).
Kod mieszania jest zgodny z equals(), bo równe kody implikują true jako wynik
equals. To jednak nie znaczy, że rózne obiekty nie mogą mieć takich samych
kodów mieszania. O przynależności do zbioru ostatecznie decyduje metoda equals(),
hashcode() jest tylko po to, by umieścić obiekt w tablicy mieszania.
Program da następujący wynik:
[Jan Malinowski 1200, Jan Kowalski 1000]
Widzimy, że do zbioru nie zostały dodane "duplikaty" (dwa obiekty "Jan Kowalski"), i że o tym zdecydowała metoda equals.
A czy to naprawdę są duplikaty? Może to dwóch róznych Kowalskich (przecież pensje są różne).
Gdyby equals() była zdefiniowana tak, że porównuje również pensje otrzymalibyśmy w zbiorze wszystkich trzech robotników.
Porządek elementów kolekcji HashSet nie jest okreslony
(w innym przebiegu. programu moglibyśmy uzyskać najpierw Kowalskiego, a później
Malinowskiego).
Klasa LinkedHashSet, dziedzicząc klasę HashSet udostępnia wygodną często
właściwość: zachowania porządku, w jakim elementy dodane były do zbioru.
Gdybyśmy zatem w poprzednim programie zmienili kod na:
Set set = new LinkedHashSet();
for (int i=0; i < p.length; i++) set.add(p[i]);
System.out.println(set.toString());
to otrzymalibyśmy wynik odtwarzający "historię" zapełniania zbioru:
[Jan Kowalski 1000, Jan Malinowski 1200]
Inna podstawowa implementacja koncepcji zbioru - klasa TreeSet, opiera
się na strukturze danych zwanej drzewem czerwono-czarnym. Dla potrzeb korzystania
z klasy TreeSeet wystarczy wiedzieć, że zapewnia ona szczególne uporządkowanie
elementów zbioru, które pozwala szybko odnajdywać w nim podany element.
Sczegółowe omówienie tej struktury danych wykracza poza ramy niniejszego
materiału, nie ma też miejsca by przedstawić tu pojęcie drzewa (zainteresowanym
można polecić książkę L. Banachowskiego, K.Diksa, W. Ryttera. Algorytmy
i struktury danych, WNT 2001).
Zwróćmy tylko uwagę (dla zainteresowanych), że drzewo
czerwono-czarne jest drzewem wyszukiwań binarnych (BST) o następujących właściwościach:
- Z każdym węzłem drzewa związana jest wartość
- Wartość ta jest większa od wartości lewego potomka i mniejsza od wartości prawego potomka
- Z każdym węzłem związany jest atrybut koloru - czerwony lub czarny
- Każdy czerwony węzeł, ktory nie jest liściem ma tylko czarnych potomków
- Każda ścieżka od korzenia do liścia zawiera tyle samo czarnych węzłów
- Korzeń jest czarny.
Dzięki tym właściwościom drzewo czerwono-czarne może zachowywać właściwość
zrównoważenia przy modyfikacjach (tzn. równoważenie nie jest kosztowne),
co w konsekwencji daje szybkie operacje dodawania i wyszukiwania elementów.
Inaczej mówiąc, elementy są dodawane do drzewa w określony sposób, taki mianowicie,
że wysokość drzewa nie jest zbyt wielka (zrównoważenie), a jednocześnie wyszukiwanie
może korzystać z "porządku symetrycznego", okreslanego przez punkt 2 w/w
właściwości drzewa czerwono-czarnego.
Na przykładzie z poniższego rysunku dla odnalezienia elementu 7 potrzebne są tylko 3 porównania.
Źrodło: John Morris, Data Structures and Algorithms, University of Western Australia, 1998
Jak widać, struktura ta pozwala na "odtwarzanie" danych w określonym porządku elementów.
Dlatego klasa TreeSet realizuje nie tylko koncepję zbioru "w ogóle" , ale
również zbioru uporządkowanego, implementując interfejs SortedSet (ściślej NavigableSet), który
rozszerza interfejs Set.
Widzieliśmy już jak iterowanie po TreeSet zwraca elementy w porządku rosnącym.
Np. poniższy fragment:
String[] s = {"ala", "pies", "kot" };
Set set = new TreeSet();
for (int i=0; i < p.length; i++) set.add(s[i]);
System.out.println(set.toString());
wypisze:
[ala, kot, pies]
Ale skąd wiadomo jaki ma być porządek elementów? Zapewne zależy to
od klasy obiektów, będących elementami zbioru. Dla klasy String było wszystko
w porządku (uzyskaliśmy alfabetyczny porządek elementów zbioru). Ale co by
się np. stało, gdyby w poprzednim programie (przykład klasy Worker) zmienić
implementację zbioru z HashSet na TreeSet?
Cóż, spotkałaby nas niemiła niespodzianka: wyjątek ClassCastException.
Widać czegoś naszej kalsie Worker brakuje.
Dochodziimy w ten sposób do ważnego tematu - porównywania obiektów przy porządkowaniu kolekcji.
8. Porównywanie obiektów
Dodawanie elementów do zbiorów uporządkowanych (np. TreeSet),
iterowanie po
kolekcjach uporządkowanych, pobieraniee elementó z kolejek z
priorytetami, a także sortowanie kolekcji i tablic algorytmami
kolekcyjnymi
odbywa się w oparciu o:
- naturalny porządek obiektów,
- lub reguły porównywania obiektów określane przez komparator - obiekt klasy implementującej interfejs Comparator.
Naturalny porządek określany jest przez implementację interfejsu Comparable<T>
w klasie obiektów i dostarczenie definicji metody compareTo tego interfejsu,
porównującej dwa obiekty typu T.
Metoda compareTo ma następującą sygnaturę:
public int compareTo(T otherObject)
gdzie T jest typem obiektu,
i zwraca:
- liczbę < 0, jeżeli ten obiekt (this) znajduje (w porządku) przed obiektem otherObject,
- liczbę > 0, jeżeli ten obiekt (this) znajduje (w porządku) po obiekcie otherObject,
- 0, jeśli obiekty są takie same.
Wiele klas standardu Javy implementuje interfejs Comparable (np. klasa String,
Date, klasy opakowujące typy proste). We własnych klasach musimy o to
zadbać sami.
Zatem, każda nasza klasa, której obiekty mogą być elementami kolekcji uporządkowanych
powinna określać naturalny porządek swoich obiektów.
Np. w klasie Worker moglibyśmy ustalić, że naturalną kolejnością obiektów
jest alfabetyczna kolejność nazwisk w porządku rosnącym poprzez dostarczenie
definicji metody compareTo :
class Worker implements Comparable<Worker> {
private String lname;
private String fname;
// ...
public int compareTo(Worker otherObj) {
return this.lname.compareTo(otherObj.lname);
}
// ...
}
Po tej modyfikacji klasy i jej wykorzystaniu w poniższym fragmencie:
Worker[] p = { new Worker("Jan", "Kowalski", 1000),
new Worker("Jan", "Malinowski", 1200),
new Worker("Jan", "Kowalski", 1400),
new Worker("Jab", "Kowalewski", 2000),
};
Set<Worker> set = new TreeSet<Worker>();
for (int i=0; i < p.length; i++) set.add(p[i]);
System.out.println(set.toString());
otrzymamy (naturalnie) uporządkowany wynik:
[Jab Kowalewski 2000, Jan Kowalski 1000, Jan Malinowski 1200]
No, dobrze, ale jak uzyskać różne zbiory, uporządkowane wedlug różnych kryteriów,
np. według nazwisk lub według pensji? Albo porządek odwrotny (np. w malejącym alfabetycznym porządku nazwisk) ?
Tu przychodzi na pomoc koncepcja komparatora.
Komparator jest obiektem porównującym inne obiekty
Komparatory w Javie są realizowane jako obiekty klas implementujących
interfejs Comparator<T>, gdzie T jest typem porównywanych obiektów
Interfejs ten zawiera ważną metodę:
int compare(T o1, T o2)
której implementacja winna porównywać dwa swoje argumenty i zwracać wynik
0 jeśli oba obiekty są równe, liczbę mniejszą od 0, jeśli o1 jest "mniejszy"
od o2 oraz liczbę większą od 0, jeśli o1 jest "większy" od o2.
Obiekt komparator może być podany jako argument konstruktora klasy TreeSet
(i wtedy to on, a nie naturalny porządek, decyduje o sposobie wpisywania
elementów do zbioru) , może rownież występowac jako argument metod sortowania
z klasy Collections i Arrays, konstruktorów klasy PriorityQueue oraz konstruktorów innych kolekcji uporządkowanych (np.
TreeMap).
Specjalny komparator, odwracający naturalny porządek, uzyskiwany jest za
pomocą statycznej metody klasy Collections - Collections.reverseOrder().
Zobaczmy przykład różnego porządkowania zbioru robotników (klasa Worker).
import java.util.*;
class Worker implements Comparable<Worker> {
private String lname;
private String fname;
private int salary;
public Worker(String fn, String ln, int sal) {
lname = ln;
fname = fn;
salary = sal;
}
public int getSalary() { return salary; }
public int compareTo(Worker otherObj) {
return this.lname.compareTo(otherObj.lname);
}
public String toString() {
return fname + " " + lname + " " + salary;
}
public static void main(String args[]) {
Worker[] workers = { new Worker("Jan", "Kowalski", 1000),
new Worker("Jan", "Malinowski", 1200),
new Worker("Jan", "Kowalski", 1400),
new Worker("Jan", "Kowalewski", 2000),
new Worker("Stefan", "Zwierz", 2000),
};
// Ziór uporządkowany wg porządku naturalnego (rosnąca kolejność nazwisk)
Set<Worker> set = new TreeSet<Worker>();
for (Worker w : workers) set.add(w);
System.out.println(set);
// Zbiór uporządkowany wg rosnących pensji
Set<Worker> set2 = new TreeSet<Worker>(new Comparator<Worker>() {
public int compare(Worker o1, Worker o2) {
// różnica pensji wystarczy do porownania?:
return o1.getSalary() - o2.getSalary();
}
});
for (Worker w : workers) set2.add(w);
System.out.println(set2);
// Zbiór uporządkowany w malejącym porządku naturalnym (malejące nazwiska)
Set<Worker> set3 = new TreeSet<Worker>(Collections.reverseOrder());
for (Worker w : workers) set3.add(w);
System.out.println(set3);
}
}
Program wyprowadzi:
[Jan Kowalewski 2000, Jan Kowalski 1000, Jan Malinowski 1200, Stefan Zwierz 2000]
[Jan Kowalski 1000, Jan Malinowski 1200, Jan Kowalski 1400, Jan Kowalewski 2000]
[Stefan Zwierz 2000, Jan Malinowski 1200, Jan Kowalski 1000, Jan Kowalewski 2000]
Ciekawe, że w powyższym przykładzie w klasie Worker nie było metody equals()
ani hashCode(). Po prostu, TreeSet ich nie potrzebuje.
Zwróćmy też uwagę, że komparator przesądza nie tylko o kolejności iterowania
po zbiorze, ale również o tym, czy obiekty uznawane są za nierówne i czy
wobec tego mogą stanowić elementy zbioru (przykład z powtórzeniem nazwiska
Jan Kowalski i - bolesna - utrata Stefana Zwierza, gdy komparator porównywał pensje),
Należy pamiętać, że:
- Operacje na zbiorze HashSet używają (i wymagają) metod hashCode() i
equals(), a dodawanie i wyszukiwanie elementów odbywa się w oparciu o wyniki
metody equals().
- Operacje na zbiorze TreeSet odbywają się w oparciu o wyniki metody compareTo() lub metody compare() komparatora.
Oczywiście, nasze klasy powinny być przygotowane do tego, że ich obiekty
mogą znaleźć się w zbiorach typu HashSet albo TreeSet, zatem powinny definiować
wszystkie wspomniane metody. A do tego w sposob spójny: jeśli equals zwraca
true, to compareTo winno zwracać zero, a hashCode te same wartości dla obu
porównywanych obiektów.
Warto zauważyć, że dla zbiorów uporządkowanych (naturalnie lub za pomocą
komparatora) dostępna jest możliwośc uzyskiwania "pierwszego" lub "ostatniego"
(w zdefiniowanym porządku) elementu, a także podzbiorów, które zawierają
elementy "od" - "do" (w zdefiniowanym porządku). Służą temu metody interfejsu
SortedSet (pośrednio implementowanego przez TreeSet) m.in. headSet(), tailSet() i subSet(),
Interfejs NavigableSet bezpośrednio implementowany przez TreeSet dostarcza dodatkowych metod m.in.
higher(...),
lower(...), ceiling(...), floor(....), które pozwalają uzyskiwac
elmenty "bliskie" w porządku wobec danego (porszę zobaczyć
dokumentację).
Należy też zauważyć ciekawe możliwości jakie daje metoda comparator(). Nie
mamy co prawda możliwości dynamicznych zmian komparatora (już po utworzeniu
obiektu klasy TreeSet), ale dzięki dostępowi do obiektu-komparatora i odpowiedniej
konstrukcji jego klasy możemy zmieniać charakterystyki jego działania niejako
"w locie" (już po utworzeniu obiektu TreeSet i związaniu go z tym komparatorem).
9. Mapy
Mapa jest jednoznacznym odwzorowaniem zbioru kluczy w zbiór wartości.
Słowo mapa kojarzy się raczej z mapą geograficzną. Również w języku angielskim znaczenie rzeczownika map jest ograniczone do geografii. Idąc śladem twórców JCF, którzy słowu map przypisują znaczenie wywodzące się od mapping (odwzorowanie), również tutaj zastosujemy zgrabne słowo mapa
na oznaczenie odwzorowania zbioru kluczy w zbiór wartości
O mapach możemy
myśleć jako o takich kolekcjach par: klucz - wartość, które zapewniają odnajdywanie
wartości związanej z podanym kluczem.
Przykladem takiej kolekcji może być zestaw danych, który zawiera nazwiska
i numery telefonów i pozwala na odnajdywanie numeru telefonu (poszukiwanej
wartości) po nazwisku (kluczu).
Zarówno klucze, jak i wartości mogą być referencjami do dowolnych obiektów (jak również wartościami null).
Oczywiście, wartości kluczy nie mogą się powtarzać (odwzorowanie musi być
jednoznaczne). Natomiast pod różnymi kluczami można zapisać te same wartości
(odwzorowanie nie musi być wzajemnie jednoznaczne).
Aby lepiej zrozumieć możliwe zastosowania map w tablicy podano kilka przykładów.
|
Klucz
|
Wartość
|
NIP
|
Dane o podatniku
|
Nazwisko
|
Numer telefonu
|
Alias
|
e-mail
|
Kraj
|
Stolica
|
Port lotniczy, data i pora dnia wylotu (obiekt hipotetycznej klasy Departure)
|
Lista możliwych polączeń (obiekt klasy, definiującej
listę, której elementami są obiekty klasy opisującej połączenia - linie lotnicze,
przesiadki, taryfy)
|
Mapy są niezwykle użytecznym narzędziem programistycznym, pozwalają bowiem
prosto i efektywnie programować wiele realnych problemów.
Istotą zastosowania map jest możliwość łatwego i jednocześnie szybkiego odnajdywania informacji w powiązanych zestawach danych
Weźmy najprostszy przyklad: program, który ma pokazywać stolicę podanego przez użytkownika kraju.
Nie stosując w ogóle JFC moglibyśmy napisać go tak (zakładamy, że zestaw
krajów i stolic zawarty jest w pliku, a nazwy krajów i stolic oddzielone
są znakiem /).
import javax.swing.*;
import java.io.*;
import java.util.*;
class CapitalsNoJFC {
private final int NC = 300;
String[] country = new String[NC],
capital = new String[NC];
public CapitalsNoJFC() {
readInfo();
String in;
while ((in = JOptionPane.showInputDialog("Kraj")) != null) {
String cap = getCapital(in);
if (cap == null) cap = "Brak danych";
JOptionPane.showMessageDialog(null, "Kraj: " + in + " Stolica: " + cap);
}
}
private void readInfo() {
try {
BufferedReader in = new BufferedReader(
new FileReader("stolice.txt"));
String line;
int i=0;
while((line = in.readLine()) != null) {
StringTokenizer st = new StringTokenizer(line, "/");
country[i] = st.nextToken();
capital[i] = st.nextToken();
i++;
}
in.close();
} catch (Exception exc) {
System.out.println(exc.toString());
System.exit(1);
}
}
private String getCapital(String kraj) {
for (int i=0; i<country.length && country[i] != null; i++)
if (kraj.equals(country[i])) return capital[i];
return null;
}
public static void main(String args[]) {
new CapitalsNoJFC();
}
}
To podejście nie nadaje się do uogólnienia: metoda wyszukiwania informacji
(getCapital) zwraca String i ma parametr String (zatem przy innych zestawach
danych musimy ją modyfikować), operujemy tablicami, których rozmiary są ustalone,
a wyszukiwanie jest niefektywne (bo liniowe).
Zaważmy jednak przede wszystkim, że w tym rozwiązaniu musieliśmy trochę
czasu poświęcić na oprogramowanie metody getCapital(String kraj), która
zwraca stolicę podanego kraju.
Zastosowanie list zamiast tablic zwiększa możliwości uniwersalizacji kodu
i nieco oszczędza kodowania (poniżej pokazano tylko fragmenty różniące się
od poprzedniego kodu):
class CapitalsList {
List country = new ArrayList(),
capital = new ArrayList();
// ...
private void readInfo() {
// ...
String line;
while((line = in.readLine()) != null) {
StringTokenizer st = new StringTokenizer(line, "/");
country.add(st.nextToken());
capital.add(st.nextToken());
}
// ...
}
private String getCapital(String kraj) {
int index = country.indexOf(kraj);
if (index != -1) return (String) capital.get(index);
else return null;
}
Ale to rozwiązanie nadal wymaga dostarczenia własnej metody, która
pozwala myśleć w kategoriach klucze-wartości (chodzi o metodę getCapital),
a także mnoży struktury danych (mamy dwie listy, powiązane ze sobą tylko
dzięki "dobrej woli" programisty), co nie sprzyja zapewnieniu spójności danych.
Rozwiązanie listowe nie usuwa też problemu niefektywności wyszukiwania (metoda
indexOf stosuje wyszukiwanie liniowe). Moglibysmy co prawda uzyskać poprawę
efektywności wyszukiwania, ale wymaga to już znaczących nakładów dodatkowej
pracy.
Tymczasem wszystko już jest gotowe: uniwersalna struktura danych - mapa
- pozwalająca na jednolite, spójne programowanie w kategoriach klucze-wartości
i - co również ważne - efektywne odnajdywanie wartości na podstawie podawanych
kluczy.
W JCF ze względy na specyfikę dzialania na mapach (jako zestawach par klucze-wartości) implementują one interfejs Map, a nie Collection.
Podstawowe operacje na mapie (niezależnie od jej implementacji) są określone
przez metody tego interfejsu. Należą do nich: dodawanie pary klucz-wartość
do mapy (metoda put), uzyskiwanie wartości "pod" podanym kluczem (metoda
get) oraz usuwanie pary klucz-wartośc z mapy (metoda remove).
Zanim przyjzrymy się hierarchii dostępnych map, zobaczmy najpierw jak wyglądałby
nasz poprzedni program, gdybyśmy zastosowali mapę (w implementacji HashMap).
import javax.swing.*;
import java.io.*;
import java.util.*;
class CapitalsMap {
// Mamy teraz jeden spójny zestaw danych: kraje-stolice
Map<String, String> countryCapital = new HashMap<String, String>();
public CapitalsMap() {
readInfo();
String in;
while ((in = JOptionPane.showInputDialog("Kraj")) != null) {
// Uzyskiwanie wartości po kluczu
String cap = countryCapital.get(in);
if (cap == null) cap = "Brak danych";
String msg = "Kraj: " + in + "\nStolica: " + cap;
System.out.println(msg);
JOptionPane.showMessageDialog(null, msg);
}
}
private void readInfo() {
try {
Scanner in = new Scanner(new File("stolice.txt"));
while(in.hasNextLine()) {
Scanner line = new Scanner(in.nextLine()).useDelimiter("/");
// Dodawanie do mapy pary: kraj - stolica
countryCapital.put(line.next(),line.next());
}
in.close();
} catch (Exception exc) {
exc.printStackTrace();
System.exit(1);
}
}
public static void main(String args[]) {
new CapitalsMap();
}
}
Programowanie jest dużo łatwiejsze i mniej zawodne niż poprzednio, a uzyskiwanie informacji bardziej efektywne.
Wynik programu (na podstawie zapytań wprowadzanych w dialogach):
Kraj: Polska
Stolica: Warszawa
Kraj: Pppolska
Stolica: Brak danych
Uwaga: przy tworzeniu map podajemy dwa argumenty typu (typ klucza i typ wartości) np.
Map<String, Integer>
W tym przypadku metoda get(...) zwróci obiekt właściwego typu i nie będą potrzebne konwersje zawęzające.
Jesli używamy surowego typu Map lub argumenty typu są Object, to metoda get(...) będzie zwracać Object, zatem uzyskując wartość
"po kluczu" musimy dokonać konwersji zawężającej do odpwiedniego typu.
Hierarchie dostępnych map (interfejsy i gotowe implementacje) pokazuje poniższy rysunek:
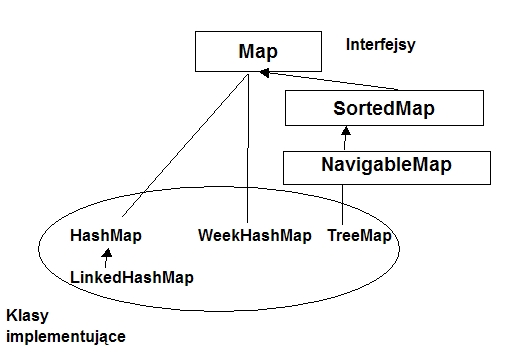
W mapach istotne jest szybkie odnajdywanie kluczy. Klucze (poprzez umieszczenie
ich razem z wartościami w odpowiednie strukturach danych) związane są już
bezposrednio i niejako natychniastowo z wartościami.
Podobnie zatem jak w przypadku zbiorów istnieją dwie podstawowe implementacje,
pozwalające na szybkie wyszukiwanie kluczy - implementacja oparta na tablicy
mieszającej (HashMap) oraz na drzewie czerwono-czarnym (TreeMap).
Niejako ubocznym skutkiem zastosowania tej ostatniej jest możliwość przeglądania kluczy
mapy w naturalnym porządku rosnącym lub w porządku, określanym przez komparator
podany przy konstrukcji mapy. Reguły stosowania komparatorów są takie same
jak w przypadku zbiorów uporządkowanych. Mówimy, że mamy do czynienia z mapą
uporządkowaną, a zatem mamy - tak jak w przypadku zbiorów uporządkowanych
- dodatkowe właściwości takie jak "pierwszy" i "ostatni" klucz lub ich podzbiór
"od" -"do" (określane przez metody interfejsu SortedMap) oraz operacje znajdowania bliskich kluczy (z interfejsy NavigableMap).
Implementacja LinkedHashMap pozwala na odtworzenie kolejności
dodawania elementów do mapy, natomiast WeekHashMap (oparta na implementacji mieszającej) ma pewne specyficzne właściwości, o których za chwilę.
Jak już wspomniano, wszystkie w/w klasy implementują interfejs Map. Niewątpliwie warto przyjrzeć się dokładniej jego metodom.
|
Podstawowe metody interfejsu Map.
|
| void | clear()
Usuwa wszystkie elementy mapy (operacja opcjonalna). |
| boolean | containsKey(Object key)
Zwraca true
jeżeli mapa zawiera podany klucz (i związaną z nim wartość). |
| boolean | containsValue(Object value)
Zwraca true
jeśli mapa zawiera podaną wartość (do ktorej może prowadzić wiele
kluczy). |
| Set<Map.Entry<K,V>> | entrySet()
Zwraca widok na
zbiór par klucze-wartości jako zbiór obiektów typu
Map.Entry<K,V>. K jest typem klucza, V - typem wartości |
| V | get(Object key)
Zwraca wartość
pod podanym kluczem (lub null, co może oznaczać, że odwzorowania dla
podanego klucza w mapie nie ma). V jest typem wartości. |
| boolean | isEmpty()
Czy pusta? |
| Set<K> | keySet()
Zwraca widok na zbiór kluczy. |
| V | put(K key, V value)
Dodaje od mapy
klucz-wartość (lub zastępuje poprzednie odwzorowanie tego klucza w
wartość - podanym), zwraca
obiekt, który uprzednio znajdował się pod danym kluiczem lub null
(operacja opcjonalna). |
| void | putAll(Map<...> t)
Wszystkie elementy mapy t dodaje do tej mapy
(operacja opcjonalna). |
| V | remove(Object key)
Usuwa odwzorowanie: klucz-wartość z tej mapy
(operacja opcjonalna). Zwraca starą wartość. |
| int | size()
Zwraca liczbę par klucz-wartość w mapie |
| Collection<V> | values()
Zwraca widok na kolekcję wartości. |
Uwaga. Metody put... powodują zastąpienie istniejących w mapie odwzorowań,
które mają takie same klucze jak dodawane odwzorowania. Istotnie - przecież
odwzorowania muszą być jednoznaczne!
Jeszcze przed stworzeniem JCF w Javie istniała klasa Hashtable, będąca
w zasadzie mapą. Obecnie implementuje ona interfejs Map, ale różni się od
innych gotowych implementacji tego interfejsu dwoma właściwościami:
- nie dopuszcza ani kluczy, ani wartości null,
- jest synchronizowana.
Drugim ciekawym elementem są tu metody do uzyskiwania widoków na klucze, wartości oraz pary klucze-wartości.
Ze względu na to, że mapy nie implementują interfejsu Collection, nie można
od nich uzyskać bezpośrednio iteratorów. Można natomiast uzyskać kolekcje,
które są widokami na zestawy kluczy (Set, bo bez powtórzeń), zestawy wartości (Collection,
bo bez porządku i z możliwością powtórzeń elementów), oraz par klucze-wartośći
(Set, bo bez powtórzeń). Od tych kolekcji - naturalnie - możemy uzyskać iteratory,
Zobaczmy te metody w dzialaniu, przyglądając się jednocześnie różnicom pomiędzy
różnymi implementacjami map, zastosowaniu komparatora dla map uporządkowanych
oraz - analogicznej jak dla list i zbiorów - możliwości uzyskiwania dowolnej
implementacji mapy z jakiejś innej implementacji mapy (poprzez wykorzystanie
argumentu konstruktora).
import java.io.*;
import java.util.*;
class CapitalsMap2 {
Map<String, String> countryCapital = new HashMap<String, String>();
public CapitalsMap2() {
readInfo();
show("Mapa inicjalna - HashMap", countryCapital);
show("Mapa w porządku naturalnym - TreeMap",
new TreeMap<String, String>(countryCapital)
);
// Pusta mapa z komparatorem odwracającym naturalny porządek
Map<String, String> mapRo = new TreeMap<String, String>(Collections.reverseOrder());
// Wpisujemy do niej pary z mapy countryCapital
mapRo.putAll(countryCapital);
show("Mapa w porządku odwrotnym (komparator reverseOrder)",
mapRo
);
// Uzyskanie iteratora po zestawie kluczy
// Pokazanie wszystkich par, których klucze zawierają r
// Usunięcie ich
Iterator<String> it = countryCapital.keySet().iterator();
while (it.hasNext()) {
String key = it.next();
if (key.indexOf("r") != -1) {
System.out.println(key + " " + countryCapital.get(key));
it.remove();
}
}
show("Mapa po zmianach", countryCapital);
}
public void show(String msg, Map<String, String> map) {
System.out.println(msg);
Set<String> keys = map.keySet();
System.out.println("Klucze: " + keys);
Collection<String> vals = map.values();
System.out.println("Wartości: " + vals);
Set entries = map.entrySet();
System.out.println("Pary: " + entries);
}
private void readInfo() {
try {
Scanner in = new Scanner(new File("stolice.txt"));
while(in.hasNextLine()) {
Scanner line = new Scanner(in.nextLine()).useDelimiter("/");
// Dodawanie do mapy pary: kraj - stolica
countryCapital.put(line.next(),line.next());
}
in.close();
} catch (Exception exc) {
exc.printStackTrace();
System.exit(1);
}
}
public static void main(String[] args) {
new CapitalsMap2();
}
}
Ten fragment kodu wyprowadzi następujące informacje:
Mapa inicjalna - HashMap
Klucze: [Malezja, Bali, Polska, Hiszpania, Rosja, Francja]
Wartości: [Kuala Lumpur , Denpasar, Warszawa, Madryt, Moskwa, Paryż]
Pary: [Malezja=Kuala Lumpur , Bali=Denpasar, Polska=Warszawa, Hiszpania=Madryt, Rosja=Moskwa, Francja=Paryż]
Mapa w porządku naturalnym - TreeMap
Klucze: [Bali, Francja, Hiszpania, Malezja, Polska, Rosja]
Wartości: [Denpasar, Paryż, Madryt, Kuala Lumpur , Warszawa, Moskwa]
Pary: [Bali=Denpasar, Francja=Paryż, Hiszpania=Madryt, Malezja=Kuala Lumpur , Polska=Warszawa, Rosja=Moskwa]
Mapa w porządku odwrotnym (komparator reverseOrder)
Klucze: [Rosja, Polska, Malezja, Hiszpania, Francja, Bali]
Wartości: [Moskwa, Warszawa, Kuala Lumpur , Madryt, Paryż, Denpasar]
Pary: [Rosja=Moskwa, Polska=Warszawa, Malezja=Kuala Lumpur , Hiszpania=Madryt, Francja=Paryż, Bali=Denpasar]
Francja Paryż
Mapa po zmianach
Klucze: [Malezja, Bali, Polska, Hiszpania, Rosja]
Wartości: [Kuala Lumpur , Denpasar, Warszawa, Madryt, Moskwa]
Pary: [Malezja=Kuala Lumpur , Bali=Denpasar, Polska=Warszawa, Hiszpania=Madryt, Rosja=Moskwa]
Widok na klucze jest typu wyznaczanego przez klasę, implementującą interfejs
Set, ale jest to inna klasa niż znane nam HashSet i TreeSet
Jak widać, uzyskana
kolekcja kluczy jest istotnie widokiem (a nie jakimś nowym obiektem)
na klucze mapy. Możemy nie tylko po nich iterować, ale za pomocą metody remove
iteratora usuwać odwzorowania z mapy.
Kolekcja par klucze-wartości (widok na klucze-wartości) jest typu wyznaczanego przez klasę implementującą interfejs Map.Entry (wewnętrzny interfejs interfejsu Map). Dzięki temu - ale tylko w trakcie iteracji po elementach tej kolekcji
- mamy dodatkowe możliwości działania, a mianowicie: uzyskanie klucza dla
danej pary (metoda getKey()), uzyskanie wartości dla danej pary (metoda getValue()),
zmiana wartości dla danej pary (metoda setValue(Object).
Przykładowy fragment kodu, który - w trakcie iteracji - zmienia wielkość
liter w pisowni stolic, pokazuje sposób zastosowania Map.Entry.
// Zmiana wielkości liter w pisowni stolic
Iterator<Map.Entry<String, String>> pit = countryCapital.entrySet().iterator();
while (pit.hasNext()) {
// To jedyny sposób uzyskania dostępu do obiektu Map.Entry !!!
Map.Entry<String, String> entry = pit.next();
String cap = entry.getValue();
entry.setValue(cap.toUpperCase());
}
show("Po zmianie wielkości liter", countryCapital);
}
Dostaniemy w wyniku:
Po zmianie wielkości liter
Klucze: [Malezja, Bali, Polska, Rosja, Hiszpania]
Wartości: [KUALA LUMPUR , DENPASAR, WARSZAWA, MOSKWA, MADRYT]
Pary: [Malezja=KUALA LUMPUR , Bali=DENPASAR, Polska=WARSZAWA, Rosja=MOSKWA, Hiszpania=MADRYT]
I na koniec omawiania map - dwa słowa o klasie WeekHashMap.
Jej zadaniem jest współpraca z odśmiecaczem (garbage collcctor), która może
nam pomóc w następującej sytuacji. Wyobraźmy sobie, że referencja do klucza,
który związany jest z jakąś wartością w mapie zniknęła z naszego programu.
Nie mamy więc żadnego sposobu, by dostać się do tej wartości. Ta para w mapie
jest już praktycznie bezużyteczna i powinna być usunięta. Ale ponieważ nie
mamy klucza nie możemy tego zrobić, a odśmiecacz nie może usunąć tego elementu
mapy, bowiem struktura, ktora go opisuje nadal w mapie "żyje".
Właśnie w takiej sytuacji pomocna jest klasa WeekHashMap: pary w takiej mapie
są automatycznie usuwane przez odśmiecacz wtedy, gdy w innych częściach programu
nie ma już żadnej referencji wskazującej na klucze tych par.
Klasy WeekHashMap powinniśmy używać przy potencjalnie dużych mapach, kiedy
struktura fragmentów programu, operujących na mapie jest złożona i nie bardzo
potrafimy zagwarantować usuwania odwzorowań z mapy, gdy klucze prowadzące
do tych odwzorowań przestają istnieć.
10. Algorytmy, widoki, fabrykatory kolekcji
Java Collection Framework
zawiera dwie użyteczne klasy, wspomagające dzialania na kolekcjach (a także
tablicach) - klasę Collections i klasę Arrays.
Klasa Collections dostarcza statycznych metod, operujących na kolekcjach lub zwracających kolekcje. Do metod tych należą:
- algorytmy kolekcyjne,
- metody zwracające widoki kolekcji,
- metody tworzące specjalne kolekcje.
|
Wybrane algorytmy kolekcyjne
|
| static int | binarySearch(List< ... > list, K key)
Wyszukiwanie binarne na liście.
Zwraca indeks elementu, który jest równy podanemu obiektowi key (wedle metody
compareTo z klas(y) elementów listy, przy czym zarówno elementy listy, jak
i obiekt key muszą być porównywalne). Lista musi być najpierw posortowana
według naturalnego porządku np. metodą sort(List). Przy braku elementu zwraca
wartość < 0 ( a nie -1 !) |
| static int | binarySearch(List <...>, K,
Comparator<...> c)
Wyszukiwanie binarne według
podanego komparatora (porównywanie obiektu key z elementami listy następuje
za pomocą metody compare komparatora). Lista musi być posortowana zgodnie
z porządkiem definiowanym przez komparator np. metodą sort(List, Comparator).
Zwraca indeks odnalezionego elementu lub wartość < 0, gyd elementu brak.
|
| static void | sort(List<T> list)
Sortowanie listy według naturalengo porządku elementów (rosnąco) |
| static void | sort(List<T> list,
Comparator<...> c)
Sortowanie listy wedle porządku określanego przez komparator. |
Uwaga: wszystko o czym mowa była przy okazji przedstawiania pojęć naturalnego
porządku oraz komparatorów - stosuje się do w/w algorytmów.
W klasie Arrays dostarczono statycznych metod, m.in. implementujących algorytmy
sortowania i binarnego wyszukiwania dla tablic zarówno typów pierwotnych,
jak i obiektów (w tym ostatnim przypadku również z możliwością użycia komparatorów).
Metody klasy Collections zwracające widoki kolekcji nakladają na kolekcje
"opakowania" w celu zmiany ich niektórych właściwościi.
W szczególności możemy uzyskać niemodyfikowalne oraz synchronizowane widoki dowolnej kolekcji.
Przypomnijmy, że niemodyfikowalność kolekcji oznacza niemożliwość wszelkich
modyfikacji (zarówno strukturalnych - dodawanie usuwanie elementów, jak i
zmian wartości elementó).
Czasami jest to potrzebne, gdy chcemy zagwarantować, by po utworzeniu kolekcja
w ogóle nie mogła podlegać zmianom, lub gdy chcemy zróżnicować prawa dostępu
do kolekcji dla różnych grup użytkowników naszej aplikacji (ktoś może zmieniać
kolekcje, kto inny - tylko przeglądać).
Gotowe implementacje kolekcji w JCF są modyfikowalne.
Niemodyfikowalne widoki kolekcji możemy uzyskać za pomocą metod (dla ułatwienia pominięto parametry typu):
public static Collection unmodifiableCollection(Collection c);
public static Set unmodifiableSet(Set s);
public static List unmodifiableList(List list);
public static Map unmodifiableMap(Map m);
public static SortedSet unmodifiableSortedSet(SortedSet s);
public static SortedMap unmodifiableSortedMap(SortedMap m); |
Szczególnym rodzajem niemodyfikowalności jest brak możliwości zmian rozmiaru
kolekcji. Takich kolekcji (których elementy możemy zmieniać, ale nie możemy
do nich dodawać nowych elementów ani usuwać istniejących) dostarcza statyczna
metoda asList z klasy Arrays, zwracająca listę, elementami której są elementy tablicy przekazanej jako argument.
Metoda ta może służyć nie tylko do łatwego tworzenia list z istniejących
tablic, ale również do tworzenia nowych, pustych list o niezmiennych rozmiarach:
// Tworzy listę o ustalonym (i niezmiennym) rozmiarze 1000 elementów
List l = Arrays.asList(new Object[1000]);
Gotowe kolekcje w JCF (za wyjątkiem "starych" Vector i Hashtable) nie są synchronizowane.
Poprawia to efektywność korzystania z kolekcji (jak pamiętamy, synchronizacja
jest kosztowna), ale jednocześnie unniemożliwia bezpieczny dostęp do nich
przez kilka wątków naraz. Jeśli chcemy udostępnić kolekcje w środowisku wielowątkowym,
powinniśmy utworzyć ich synchronizowane widoki. Służą temu metody:
| public static Collection synchronizedCollection(Collection c); |
| public static Set synchronizedSet(Set s); |
| public static List synchronizedList(List list); |
| public static Map synchronizedMap(Map m); |
| public static SortedSet synchronizedSortedSet(SortedSet s); |
| public static SortedMap synchronizedSortedMap(SortedMap m); |
Uwaga: dla ułatwienia pominięto argumenty typu.
Podkreślmy raz jeszcze, że gdy mowa o widokach (lub "opakowaniach") kolekcji,
to tak naprawdę kolekcja jest jedna (nie jest tworzony nowy obiekt, nie są
kopiowane wartości elementów). Wszystkie operacje wykonywane są na tej jednej
kolekcji,
Jeśli zatem mamy np. listę i jej synchronizowany widok:
List list1 = new ArrayList();
List list2 = Collections.synchronizedList(list1);
to zmienne list1 i list2 oznaczają tę samą (co do treści) kolekcję.
A przy współbieżności ważne jest, by dostęp z każdego wątku był synchronizowany.
Nie powinniśmy zatem pozostawiać możliwości niesynchronizowanego dostępu
poprzez referencję do kolekcji z niesynchronizowanym dostępem (referencję
list1 w powyższym przykładzie). Powinniśmy raczej napisać:
List list = Collections.synchronizedList(new ArrayList());
Same synchronizowane widoki nie zapewniają jednak bezpieczeństwa przy iterowania
po kolekcjach. Iterowanie składa się z wielu operacji, które winny być potraktowane
atomistycznie (w przeciwnym razie - przy użyciu iteratora przez inny wątek
- wystąpi wyjątek ConcurrentModificationException). Zatem zarówno uzyskanie
iteratora jak i jego użycie winno być umieszczone w bloku synchronizowanym:
Collection c = Collections.synchronizedCollection(jakasKol);
synchronized(c) {
Iterator i = c.iterator();
while (i.hasNext()) {
// ... i.next() itp.;
}
}
Nieco inaczej wygląda sprawa z synchronizowanymi mapami. Tutaj synchronizacja
powinna dotyczyć samej mapy - a nie jej widoków: kluczy, wartości, czy par
(mimo, że własnie na tych kolekcjach wykonywane są iteracje).
Map map = Collections.synchronizedMap(new HashMap());
// ...
Set keys = map.keySet(); // Nie musi być w bloku synchronizowanym
//...
synchronized(map) { // Synchronizacja na map, a nie na keys
Iterator i = keys.iterator(); // Musi być w bloku synchronizowanym!
while (i.hasNext()) {
// ... i.next() itp.
}
}
I jeszcze dwie ważne uwagi, dotyczące widoków kolekcji:
- widoki (jak widać z sygnatur metod) są formułowane w terminach
interfejsów, a nie klas; zatem używając synchronizowanych lub niemodyfikowalnych
widoków kolekcji nie mamy dostępu do specyficznych metod klas, takich jak
np. getFirst czy getLast z klasy LinkedList,
- dla najogólniejszych widoków kolekcji (uzyskiwanych metodami
unmodifiableCollection i synchronizedCollection) metody equals i hashCode
używane wobec elementów kolekcji nie są polimorficzne (ich wywolanie nie powoduje
wywołania odpowiednich metod z odpowiednich podklas, zamiast tego używane są
metody z klasy Object); dopiero przy konkretyzacji w konkretnych klasach (np. kiedy prosimy o niemodyfikowalną
listę czy synchronizowany zbiór) zyskują one sens i mogą być dobrze zdefiniowane
- wtedy odwolania są w pełni polimorfczne.
W klasie Collections znajdziemy także wygodne metody fabrykujące
specjalne kolekcje np. z powielonym n razy podanym elementem.
Prosże zapoznać się z dokumentacją klasy Collections.
11. Własne implementacje kolekcji
Architektura kolekcji jest pomyślana również pod kątem tworzenia nowych własnych rodzajów i implementacji kolekcji.
Ułatwieniem jest przy tym możliwość skorzystania z gotowych klas abstrakcyjnych,
implementujących wszystkie interfejsy kolekcyjne, co upraszcza tworzenie
implementacji, bowiem nie trzeba definiować wszystkich metod interfejsów
(częsć z tych metod została w klasach abstrakcyjnych zdefiniowana, pozostaje nam tylko zdefiniowanie metod abstrakcyjnych).
Wszystkie te klasy znajdują się w pakiecie java.util, a ich nazwy zaczynają się słowem Abstract...
Oczywiście, gotowe implementacje różnych rodzajow kolekcji dziedziczą te
abstrakcyjne klasy, co przedstawia poniższy rysunek (pokazujący częsciową hierarchię dziedziczenia).