1. Przegląd instrukcji sterujących
W anglojęzycznej literaturze informatycznej pojęcie instrukcji określa się slowem statement
Zanim zaczniemy omawiać instrukcje sterujące, warto wyraźnie powiedzieć
co w ogóle znaczy pojęcie instrukcja, tym bardziej, że w większości instrukcji
sterujących występują inne instrukcje "do wykonania".
Np. z opisu instrukcji if :
if (war) ins;
dowiemy się, że zostanie wykonana instrukcja ins, jeśli warunek war jest prawdziwy.
Czym zatem może być ins ?
W różnych językach programowania jako instrukcje traktowane są różne
konstrukcje gramatyczne - różne składniowo i semantycznie zapisy w programie
Dotąd używaliśmy tego terminu nieco intuicyjnie (traktując instrukcje jako "coś", co w trakcie
działania programu "jest wykonywane"). Instrukcje stanowią "motor" działania
programu. Ich wykonanie powoduje odpowiednie przetwarzanie danych.
Zamiast
kusić się o bardziej precyzyjną definicję powiemy raczej co w Javie jest
instrukcją, a co nie.
W Javie instrukcjami są:
Rodzaj instrukcji
| Instrukcja
| Przykład
|
Instrukcja pusta
| pojedynczy średnik
| ;
|
Instrukcje wyrażeniowa
uwaga: instrukcją
wyrażeniową jest jedno
z wymienionych obok wyrażeń
zakończone średnikiem
| przypisanie;
| a=b;
|
preinkrementacja;
| ++a;
|
postinkremetacja;
| a++;
|
predekrementacja;
| --a;
|
postdekrementacja;
| a--;
|
wywołanie metody;
| x.met();
met();
|
wyrażenie new;
| new Para();
|
Instrukcja grupująca
uwaga:
po zamykającym nawiasie nie stawiamy średnika
| dowolne instrukcje (i deklaracje zmiennych) ujęte w nawiasy klamrowe
| {
a=b;
c=b;
}
|
Instrukcja etykietowana
| etykieta: dowolna instrukcja
|
Konkretne
formy składniowe
i przykłady
poznamy zaraz.
|
Instrukcje sterujące
| if
|
if .. else
|
switch
|
while
|
do ... while
|
|
| for |
| break |
continue
|
return
|
|
Instrukcja throw
| Zob. punkt na temat wyjątków
|
Instrukcja synchronized
| Wsparcie dla programowania współbieżnego
|
Żadna inna konstrukcja składniowa nie jest w Javie instrukcją.
Szczególnym rodzajem instrukcji są instrukcje sterujące.
Instrukcje sterujące odgrywają w programowaniu bardzo istotną rolę, bowiem
pozwalają na zmianę sekwencji (kolejności) wykonania instrukcji programu.
Poniżej przedstawiono szybki przegląd instrukcji sterujących. Dalej omówimy je dokładnie.
Instrukcje sterujące
|
| if (wyr) ins | Jeżeli wyrażenie wyr daje w wyniku true, to wykonywana jest
instrukcja ins |
if (wyr) ins1
else ins2 | Jeżeli wyrażenie wyr daje w wyniku true, to wykonywana jest
instrukcja ins1, w przeciwnym razie wykonywana jest instrukcja
ins2 |
switch (wyr) {
case ws1 : ins1
[ break;]
case ws2 : ins2
[ break;]
....
case wsN : insN
[ break;]
default : insDef
[ break;]
} | Instrukcja przeznaczona do wyboru z wielu wariantów. Wyrażenie wyr musi być wyrażeniem całkowitym lub wyliczeniowym. Jego wynik jest porównywany po
kolei z wyrażeniami stałymi (np. literałami lub stałymi), w przypadku
zgodności wykonywana jest odpowiednia instrukcja po dwukropku. Jeśli żadne ze
stałych wyrażeń nie pasuje do wyr wykonywana jest instrukcja w klauzuli
default. |
while (wyr) ins | Instrukcja ins wykonywana jest w pętli dopóki wartość wyrażenia wyr jest
true |
do ins while
(wyr); | Wykonywana jest instrukcja ins, następnie wyliczane wyrażenie wyr; jeśli
daje wartość true - cały proces zaczyna się od nowa. |
1 forma
for (init; wyr; upd) ins
2 forma
for (Typ zm : zestaw) ins
| Dokonywana jest inicjacja init (może to być deklaracja zmiennej
lub opracowanie listy wyrażeń, rozdzielonych przecinkami ); następnie w pętli
wykonywane są następujące czynności: wyliczane jest wyrażenie wyr i jeśli
jego wartość jest true wykonywana jest instrukcja ins, po czym wykonywana
jest modyfikacja mod (opracowanie wyrażenia lub listy wyrażeń rozdzielonych
przecinkami).
Elementy init, wyr, upd są opcjonalne. 2 forma - "for-each" - wykonuje instrukcję ins dla każdego elementu zestawu zestaw kolejno przypisanego na zmienną zm. Zastosowanie poznamy w części o tablicach i kolekcjach.
|
| continue [ etykieta ];
| Instrukcja ta przerywa wykonanie bieżącego kroku pętli for, while lub do..
while i rozpoczyna wykonanie kroku następnego, lub też przekazuje sterowanie do instrukcji opatrzonej
etykietą (jesli etykieta występuje) |
break [ etykieta ];
| Instrukcja powoduje przerwanie wykonania pętli, oprócz tego stosowana jest w
ramach instrukcji switch |
return wyr; | Instrukcja powoduje powrót z metody, zwracając wartość wynikającą z
wyliczenia wyrażenia wyr; wyrażenie wyr może być opuszczone jeśli metoda nie
zwraca żadnych wartości |
Instrukcje (i deklaracje) mogą być grupowane w bloki poprzez
ujęcie w nawiasy klamrowe { i }. Jest to tak zwana instrukcja
grupująca.
W każdym miejscu programu, gdzie może wystąpić pojedyncza instrukcja,
może
również wystąpić blok - instrukcja grupująca (np. we wszystkich
miejscach
instrukcji sterujących, gdzie przewiduje się użycie instrukcji). Jest
ona
wtedy traktowany jak pojedyncza instrukcja. Przykładowo możemy grupować
instrukcje,
które mają być wszystkie wykonane w przypadku wystąpienia jakiegoś
warunku:
if (a > b) {
c = a + b;
d = a - b;
e = a*b;
}
Jak widać, po nawiasie klamrowym, zamykającym grupowanie instrukcji nie potrzebny jest średnik.
2. Operatory i wyrażenia porównania
W wielu instrukcjach sterujących będą występować warunki podane jako wyrażenie relacyjne, konstruowane z zastosowaniem operatorów relacyjnych oraz operatorów równości - nierówności.
Np. w nawiasach instrukcji if występuje warunek, który może być wyrażeniem relacyjnym:
if (a > b) ...
Po części już omawialiśmy te operatory. Warto jednak usystematyzować podane wcześniej informacje oraz uzupelnić je o nowe fakty.
Operatory relacyjne (<, <=, >, >=):
- są operatorami dwuargumentowymi
- ich argumentami mogą być wyłącznie wyrażenia typów numerycznych (byte, char, short, int, long, float, double)
- wyrażenia relacyjne (konstruowane z pomocą tych operatorów) dają zawsze w wyniku wartości typu boolean (true lub false)
Operatory relacyjne
|
Wyrażenie
(a i b - dowolne wyrażenia,
ale koniecznie
typu numerycznego)
| Wynik
|
a > b
| true jeśli wartość a jest większa od b
false w przeciwnym razie
|
a >= b
| true jeśli wartość a jest większa lub równa b
false w przeciwnym razie
|
a < b
| true jeśli wartość a jest mniejsza od b
false w przeciwnym razie
|
a <= b
| true jeśli wartość a jest mniejsza lub równa b
false w przeciwnym razie
|
Przykłady:
int a =1, b = 3;
if (a > b) System.out.println("Większe");
else System.out.println("Mniejsze");
| Wyprowadzi napis:
Mniejsze
|
int a =1, b = 3;
if (a + 1 > b/3) System.out.println("Większe");
else System.out.println("Mniejsze");
uwaga: priorytet operatorów relacyjnych jest niższy od priorytetu operatorów arytmetycznych - dzięki temu nie musimy pisać:
if ( (a + 1) > (b/3) ) ...
| Wyprowadzi napis:
Większe
|
int a = 1, b = 3;
boolean wynik1 = a <= b;
boolean wynik2 = 1 >= a;
boolean wynik3 = a < 1;
uwaga: priorytet operatorów relacyjnych jest wyższy od priorytetu operatora przypisania - dzięki temu nie musimy pisać:
boolean wynik = (a <= b);
| Zmienne będą miały następujące wartości:
wynik1 == true
wynik2 == true
wynik3 == false
|
Częstym błędem jest stosowanie zamiast operatora równości == znaku =.
Należy się go wystrzegać, choć zwykle kompilator wykryje ten błąd i zwróci
nam na niego uwagę.
Od grupy operatorów relacyjnych odróżnia się dwuargumentowe operatory równości (==) i nierówności (!=) - z dwóch powodów:
- mają one niższy priorytet niż operatory relacyjne
- ich argumentami mogą być wartości wszystkich typów (numerycznych, logicznych, referencyjnych), pod warunkiem jednak, że:
- jeżeli jeden z argumentów jest typu numerycznego - to drugi też musi być typu numerycznego,
- jeżeli jeden z argumentów jest typu boolean - to i drugi musi być tego typu,
- jeżeli jeden z argumentów jest typu referencyjnego, to drugi musi
być typu referencyjnego dającego się przekształcić do typu pierwszego albo
literałem null (o przekształceniach typów będziemy mówić później;
na razie możemy przyjąć, że obowiązuje nas ograniczenie porównywania na równość
- nierówność tych samych typów referencyjnych np. referencji typu String
lub referencji typu Para)
Konstruowane za pomocą operatorów równości-nierówności wyrażenia mają zawsze wynik typu boolean.
Operatory równości - nierówności
|
Wyrażenia
| a == b
| a != b
|
a i b dowolnego typu numerycznego
| true jesli wartość a jest równa wartości b
false w przeciwnym razie
| true jeśl
i wartość a nie jest równa wartości b
false w przeciwnym razie
|
a i b typu boolean
| true jeśli a i b oba mają wartość true lub wartość false
false w przeciwnym razie
| true jeśli a jest true, b false lub odwrotnie
false, jeśli a i b są oba true lub oba false
|
a i b typu referencyjnego
| true jeśli obie referencje wskazują
ten sam obiekt lub jeśli obie mają wartość null
false jeśli referencje odnoszą się do różnych obiektów, lub jedna z nich ma wartość null, a druga - nie
| true jeśli obie referencje odnoszą się do innych obiektów lub jeśli jedna z nich jest null, a druga nie
false jeśli obie referencje wskazują ten sam obiekt lub jeśli obie mają wartość null
|
Przykład:
int a = 2, b = a + 1;
if ( a == b) System.out.println("tak");
else System.out.println("nie");
if ( a != --b) System.out.println("tak"); // 2
else System.out.println("nie");
int c = 4;
if ( a < b + 1 == b < c) System.out.println("tak"); //3
else System.out.println("tak");
nie
nie
tak
Ten fragment kodu wypisze na konsoli dane podane obok.
Uwagi:
- przedrostkowa forma operatora -- zapewnia, że wartość b w przykładzie
2 będzie zmieniona przed użyciem w wyrażeniu porownania na nierówność;
-
w przykladzie 3 korzystamy z tego, że priorytet operatora == jest niższy od
priorytetu operatorów relacyjnych, a te z kolei są niższe od priorytetów operatorów
arytmetycznych (+); na równość porównywane są zatem dwie wartości typu boolean,
a ponieważ obie są true, to wynik porównania też jest true
Jednak - w zasadzie - złożonych wyrażeń nie należy zapisywać w taki sposób jak w przykładzie
oznaczonym // 3 . Raczej warto użyć nawiasów, które zwiększą
czytelność kodu.
Zresztą porównywanie wartości boolowskich jest mało użyteczne, bo - w większości
przypadków - zamiast niego należy stosować logiczne operatory koniunkcji
czy alternatywy.
Przykład porównywania referencji:
// Klasa Para - to znana nam już klasa par liczb całkowitych
Para p1 = new Para(1,1);
Para p2 = new Para(1,1);
Para p3 = p1;
p1 == p2 // false, mimo że skladniki par są takie same
p1 == p3 // true, bo wskazują na ten sam obiekt
String s1 = "1,1";
p1 == s1 // bląd w kompilacji, bo p1 jest typu Para, a s1 typu String
String s2 = "1," + 1;
s1 == s2 // false, bo są to referencje do różnych obiektów
s1 == null // false, bo s1 wskazuje na jakiś obiekt
s1.equals(s2) // true, bo zawartość łańcuchów znakowych jest taka sama.
Przypomnienie: porównywanie zawartości obiektów (na równość - nierówność)
odbywa się zawsze za pomocą metody equals, zdefiniowanej w klasie obiektów.
Na koniec omawiania porównań warto zwrócić uwagę na liczby rzeczywiste. Otóż wszystkie porównania są zawsze dokładne. Ale reprezentacja liczb rzeczywistych w komputerze nie jest dokładna
. Dlatego przy porównaniu liczb rzeczywistych powinniśmy sprawdzać nie tyle
czy są one dokładnie równe, ale czy ich wartości są dostatecznie sobie bliskie.
3. Operatory i wyrażenia logiczne
Do zapisywania złożonych warunków służą warunkowe operatory logiczne:
- jednoargumentowy operator negacji logicznej oznaczany przez ! ("nie"),
- dwuargumentowy operator koniunkcji oznaczany przez && ("i"),
- dwuargumentowy operator alternatywy oznaczany przez || ("albo").
Przypuśćmy, że chcemy sprawdzić czy zachodzi warunek: wielkość n znajduje
się w przedziale [1, 10] - to znaczy, czy n jest większe lub równe 1 i jednocześnie
mniejsze lub równe 10.
Jak już wiemy, zapis: if (1 <= n <= 10) będzie błędny (bo operatory
relacyjne są stosowane tylko wobec typów numerycznych, a wyrażenie 1 <=
n ma wynik typu boolean).
Nie znając operatorów logicznych i wiedząc, że w instrukcji if możemy umieścić
inną instrukcję if, warunek moglibyśmy sprawdzić za pomocą takiego zapisu:
if (n >= 1)
if (n <= 10) ... ;
Nie jest to jednak ani elegancka, ani zbyt czytelna forma.
Na szczęście mamy operator koniunkcji logicznej,
Chodzi nam o to czy równocześnie spelnione są dwa warunki
n >= 1 I n <= 10.
W Javie zapisujemy to jako:
n >= 1 && n <= 10
i stosujemy np. w instrukcji if:
if (n >= 1 && n <= 10) ...;
Podobnie możemy chcieć sprawdzić czy wartość n znajduje się poza przedziałem [1, 10]. Aby tak było n musi być mniejsze od 1 lub większe od 10.
Do zapisu takiego warunku stosuje się operator logicznej alternatywy ||:
if (n < 1 || n > 10) ..
Trzeci operator logiczny - negacji - służy do zaprzeczania warunkom.
Na przykład, jeżeli chcemy podjąć jakieś działania, jeżeli łańcuch znakowy txt nie jest napisem "Ala", to piszemy:
if (!txt.equals("Ala")) ... ;
Argumentami operatorów logicznych mogą być tylko wyrażenia typu boolean, zaś rezultatem jest wartość typu boolean, która może być równa true lub false, zgodnie z następującą tablicą:
Warunkowe operatory logiczne
|
a
| b
| a && b
| a || b
| !a
|
true
| true
| true
| true
| false
|
false
| true
| false
| true
| true
|
true
| false
| false
| true
|
|
false
| false
| false
| false
|
|
Operator && daje wartość true tylko wtedy, gdy oba jego argumenty są wartościami true, a wartość false zawsze, gdy którykolwiek z argumentów jest false.
Operator || daje wartość true zawsze, gdy którykolwiek z jego argumentów jest true i wartość false tylko wtedy, gdy oba argumenty są false
Operatory logiczne mają niższy priorytet od operatorów relacyjnych i równości-nierówności,
zatem bez użycia dodatkowych nawiasów możemy pisać np:
if ( a == 1 && b > 3) c = a + b;
uzyskując efekt, o który nam chodzi (tu: wyliczenie c, gdy a równe 1 i b > 3).
Uwaga: operator negacji logicznej ma wyższy priorytet niż inne operatory
logiczne, wobec tego należy używać nawiasów dla zapewnienia właściwej kolejności obliczania wartości wyrażeń
Sprawne posługiwanie się warunkami logicznymi wymaga podstawowej
wiedzy z zakresu logiki matematycznej. Warto więc sięgnąć po jakiś prosty,
początkowy opis rachunku zdań logicznych i przeczytać z niego kilka pierwszych
stron.
Nota bene, zadziwiająco często mylone są w programowaniu operacje koniunkcji i alternatywy
logicznej. Zawsze więc - wybierając operację do zastosowania - zastanówmy
się troszkę dłużej nad tym czy ma to być koniukcja czy alernatywa
Np. jeżeli
chcemy wykonać jakieś czynności jeżeli nie zachodzi warunek:
"łańcuch znakowy nie jest napisem "Ala" i - jednocześnie - zmienna lata ma
wartość większą od 1", to nie wolno nam napisać:
if (! txt.equals("Ala") && lata > 1) ...
bo to oznaczałoby konieczność równoczesnego spełnienia dwóch warunków:
- napis txt nie jest ala,
- i lata są większe od 1
(a przecież nie o to nam chodziło)
Piszemy za to:
if (!( txt.equals("Ala") && lata > 1)) ...
Użycie dodatkowych nawiasów zmienia kolejność opracowania wyrażenia i uzyskujemy pożądany efekt
Omawiane dotąd operatory nazywają się warunkowymi operatorami logicznymi, bowiem
obliczanie wartości wyrażeń logicznych, konstruowanych za ich pomocą ma bardzo ważną
właściwość: obliczane są one od lewej do prawej (wiązania operatorów logicznych
- oprócz operatora negacji - są lewostronne), ale proces obliczeń kończy
się już w momencie gdy tylko wiadomo jaki będzie rezultat całego wyrażenia.
Oznacza to, że wyrażenie nie musi być wcale opracowywane do końca; wystarczy,
że jego część jednoznacznie wskazuje wynik. Na przykład w wyrażeniu:
a && (b > 0 || c == 1)
jeśli a jest równe false, to wyrażenie w nawiasach nie będzie obliczone,
bowiem wynik całego wyrażenia nie zależy już od tego co jest w nawiasach
(przy a = false zawsze będzie false).
Ma to ogromnie ważne konsekwencje, bowiem jeśli oprzemy logikę programu na
efektach ubocznych generowanych przy obliczaniu wyrażeń, które - właśnie
ze względu na tę właściwość operatorów logicznych - mogą w ogóle nie podlegać
opracowaniu, to może nas spotkać bardzo przykra niespodzianka.
Zobaczmy to na przykładzie poniższego programu.
Programista, który go napisał chciał osiągnąć następujący efekt: zapytać
w dialogach wejściowych o nazwisko i imię użytkownika, jeśli podano obie
informacje - wyprowadzić połączone nazwisko i imię, jeśli zaś zabrakło którejś
z nich - wyprowadzić napis "Niepełna informacja"; następnie pokazać dokładnie
co jest nazwiskiem (może być null) a co imieniem (też może być null, jeśli
nie wprowadzone). Pokusa zwięzłego napisania kodu sprawiła, że nasz programista
sięgnął po połączenie warunków za pomocą operatora &&: jeżeli wprowadzono
nazwisko i wprowadzono imię to txt = nazwisko + imie.
import javax.swing.*;
public class EfUb {
public static void main(String[] args) {
String nazwisko;
String imie = null;
String txt;
if ((nazwisko = JOptionPane.showInputDialog("Podaj nazwisko")) != null
&& (imie = JOptionPane.showInputDialog("Podaj imie")) != null
)
txt = nazwisko + " " + imie;
else txt = "Niepelna informacja";
System.out.println(txt);
System.out.println("Imie :" + imie);
System.out.println("Nazwisko :" + nazwisko);
System.exit(0);
}
}
Jednak raczej wbrew intencjom programisty w tym programie może nie dojść do zapytania o imię (bowiem
wartość pierwszego składnika wyrażenia połączonego koniunkcją &&
może być false - jeśli przy pytaniu o nazwisko użytkownik anulował dialog).
W Javie są również bezwarunkowe operatory logiczne (zwane czasem po prostu operatorami logicznymi):
- & koniunkcja
- | alternatywa
- ^ "wyłączające albo"
- ~ negacja
Bezwarunkowe operatory logicznej koniunkcji (&) i alternatywy ( |) mają
te same właściwości co operatory && i || z jednym wyjątkiem: oba
wyrażenia-argumenty operatorów są zawsze opracowywane (dlatego mówimy, że
operatory są bezwarunkowe).
Dodatkowo, wśród logicznych operatorów bezwarunkowych, zdefiniowano
operator "wykluczające albo" (znak ^), który daje wynik true gdy wartości obu argumentów operatora są różne (czyli true i false lub false i true) oraz false w każdym innym przypadku.
Operatory logiczne (bezwarunkowe) są stosowane wyłącznie wobec argumentów typu boolean.
Niestety, te same symbole operatorów ( &, |, ^, ~) sa również używane
w operatorach bitowych, stosowanych wobec liczb całkowitych (i umożliwiających
operowanie na bitach liczb całkowitych), co powoduje trochę zamieszania.
Problemem są także błędy: np. często początkujący (i nie tylko) programiści
zamiast && piszą &, a zamiast || - |. Kompilator nie wykryje
takich błędów, a efekt opracowywania takich wyrażeń logicznych może być inny
od spodziewanego przez programistę.
Generalnie więc:
nie należy mieszać w wyrażeniach użycia operatorów
warunkowych i bezwarunkowych (ze względu na inny sposób dzialania oraz inne
priorytety (por. tablicę priorytetów operatorów)).
Dobrą regułą "na początek" jest stosowanie wyłącznie operatorów warunkowych.
4. Podejmowanie decyzji: instrukcje if oraz if-else
Znana nam już instrukcja if ma postać:
if (
wyr)
ins
gdzie:
- wyr - warunek - dowolne wyrażenie, mające typ wyniku boolean
- ins - dowolna instrukcja (w tym grupująca)
Działanie: instrukcja
ins jest wykonywana wtedy i tylko wtedy, gdy wartością wyrażenia
war jest true
Instrukcja if -else rozszerza dzialanie instrukcji if. Ma ona postać.
if (
war)
ins1
else ins2
gdzie:
- wyr - warunek - dowolne wyrażenie, mające typ wyniku boolean
- ins1, ins2 - dowolne instrukcje (w tym grupujące)
Działanie: instrukcja
ins1 jest wykonywana wtedy i tylko wtedy, gdy wartością wyrażenia
war jest true. Jeżeli wartością wyrażenia
war jest
false - wykonywana jest instrukcja
ins2
Różnica pomiędzy zastosowaniem instrukcji if oraz if-else można zobaczyć wyraźnie na
poniższych fragmentach kodu:
if (a == b) c = d;
c = e;
System.out.println( a + " " + b + " " + c + " " + d);
oraz
if (a == b) c = d;
else c = e;
System.out.println( a + " " + b + " " + c + " " + d);
W pierwszym fragmencie instrukcja c = d; wykonana zostanie tylko wtedy, gdy
wartość zmiennej a będzie równa wartości zmiennej b. Niezależnie jednak od
tego, czy warunek ten zajdzie czy nie - bezpośrednio po wykonaniu instrukcji
if zmiennej c zostanie przypisana wartość zmiennej e (if jest więc tu bez
sensu!). Następnie wyniki zostaną wyprowadzone na standardowe wyjście.
W drugim fragmencie zmienna c będzie miała rzeczywiście wartość zależną od
tego czy a == b czy też nie (wykonane zostanie przypisanie albo c = d albo
c = e). Potem wyniki powędrują na wyjście.
Przykład ten nie znaczy oczywiście, że zawsze trzeba stosować instrukcję if-else, a samo if ma mniejsze znaczenie.
Warto zauważyć, że instrukcjami ins1 i ins2 (w opisie składni instrukcji
if-else) mogą być również instrukcje if. Pozwala to sprawdzać rozgałęzione
warunki np.
char op;
double a, b, r;
...
if (op == '+') r = a + b;
else if (op == '-') r = a - b;
else if (op == '*') r = a*b;
else if (op == '/') r = a/b;
else System.out.println("Błędny kod operacji");
Przy takich okazjach powstaje kwestia: które else odpowiada któremu if ?
Zasada jest prosta: danemu else odpowiada pierwsze poprzedzające go i znajdujące
się w tym samym bloku if nie mające jeszcze swojej "pary" w postaci else.
Wcięcia - poprawiające czytelność - programu w żaden sposób nie decydują
o odpowiedniości if i else.
Jeśli ktoś na przykład napisze:
if (a >= 0) if (a <= 100) System.out.println( "a w przedziale od 0 do 100");
else System.out.println("a mniejsze od 0");
to będzie to oczywisty błąd.
Taką konstrukcje można i należy oczywiście oprogramować inaczej ( if (a
>= 0 && a <= 100) ... ), ale gdyby się ktoś uparł przy zastosowaniu
podwójnego if, to należałoby to zapisać tak
if (a >= 0) {
if (a <= 100) System.out.println("a w przedziale od 0 do 100");
}
else System.out.println("a mniejsze od 0");
Zastosowanie nawiasów klamrowych (uczynienie bloku z drugiej instrukcji if)
rozwiązuje problem, bowiem dopasowanie if i else odbywa się zawsze tylko
w ramach tego samego bloku.
Częste błędy przy stosowaniu instrukcji if oraz if-else, na które trzeba zwracać szczególną uwagę.
A. Złe dopasowanie if i else w przypadku kilku instrukcji if (omówione przed chwilą)
B. Stawianie średnika po nawiasie zamykającym warunek instrukcji if np. :
if (a > b);
System.out.println("a > b"); // niezaleznie od tego czy a>b !
C. Zapomnienie nawiasu zamykającego instrukcję grupującą np.
if (a > b) {
c = a + b;
d = e + f;
else c = d + f;
Szczególnie częstymi błędami przy sprawdzaniu wielu warunków (które mogą
się na siebie "nakładać" lub wykluczać) są
- stosowanie instrukcji if bez else,
- nie uwzględnienie
wszystkich możliwości
- lub nieprawidłowa kolejność sprawdzania warunków.
Błędy te są szczególnie niebezpieczne, gdyż dotyczą logiki programu i nie mogą być wykryte przez kompilator
Np. jeśli ktoś chciałby powiedzieć coś o liczbie a (czy jest duża, średnia, mala) to mógłby zapisać to w ten sposób:
if (a >= 1000) System.out.println("Duża liczba")
if (a >= 100) System.out.println("Średnia liczba")
if (a >= 10) System.out.println("Mała liczba")
co jest oczywistym błędem, bo jesli a = 1000, ten fragment
wyprowadzi na konsolę wzajemnie wykluczającą się informację:
Duża liczba
Średnia liczba
Mała liczba
Ach, potrzebne jest else, ale uwaga - kolejność sprawdzania warunków jest ważna.
Gdyby ktoś nie przywiązywał do niej istotnej wagi, mógłby zapisać:
if (a >= 10) System.out.println("Mała liczba");
else if (a >= 100) System.out.println("Średnia liczba");
else if (a >= 1000) System.out.println("Duża liczba");
co znowu daje całkiem niepoprawny wynik dla a = 1000: napis "Mała liczba"
Dopiero zastosowanie else przy właściwej kolejności warunków da (przy a = 1000) właściwy wynik "Duża liczba".
if (a >= 1000) System.out.println("Duża liczba");
else if (a >= 100) System.out.println("Średnia liczba");
else if (a >= 10) System.out.println("Mała liczba");
Zauważmy jednak, że temu fragmentowi brakuje "zupełności": co się stanie
jesli a równa się np. 1? Nie dostaniemy żadnej informacji! Potrzebne jest
zatem jeszcze jedno ("zamykające") else, które będzie obsługiwać wszystkie
nie uwzględnione warunki.
Na przykład:
if (a >= 1000) System.out.println("Duża liczba");
else if (a >= 100) System.out.println("Średnia liczba");
else if (a >= 10) System.out.println("Mała liczba");
else System.out.println("Liczba mikra, bo mniejsza od 10")
Czasem nie stosowanie else przy wykluczających się warunkach nie prowadzi
do błędów w programie, ale - na pewno należy do złego stylu i powoduje niepotrzebne
sprawdzanie warunków, o których już wiadomo, że są fałszywe.
Na przykład jeśli txt jest typu String, to poniższy fragment programu:
if (txt.equals("Ala")) a = 1;
if (txt.equals("kot")) a = 2;
if (txt.equals("koń")) a = 3;
wykona się bezbłędnie i da prawidlowe wyniki, ale jeśli txt jest "Ala", to
niepotrzebnie sprawdzane są pozostałe warunki ("kot" i "koń").
Należało napisać:
if (txt.equals("Ala")) a = 1;
else if (txt.equals("kot")) a = 2;
else if (txt.equals("koń")) a = 3;
Istnieją
przypadki, gdy niestosowanie else przy sprawdzaniu sekwencji
wykluczających się warunków jest całkowicie zasadne, a nawet należy do
dobrego stylu programowania. Jest tak zawsze wtedy, gdy przy
prawdziwości któregoś z warunków, kolejny warunek w sekwencji nie
będzie już sprawdzany.
Np.
int podajKod() {
if (txt.equals("Ala")) return 1;
if (txt.equals("kot")) return 2;
if (txt.equals("koń")) return 3;
return -1;
}
Praktycznych przykładów zastosowania instrukcji if oraz if-else
dostarcza niemal każdy program, nie będziemy więc tu się nad tym
dalej rozwodzić.
5. Wielowariantowe wybory za pomocą instrukcji switch
Zamiast wielokrotnych if - else if w niektórych przypadkach można zastosować
instrukcję wyboru wielowariantowego switch. Ma ona następującą ogólną postać
switch (
wyr)
blok_switch
gdzie:
- wyrażenie wyr może mieć jeden z następujących typów
char, byte, short, int, Character, Byte, Short, Integer lub typ wyliczeniowy (enum) - blok_switch ma szczególną postać. W jego wnętrzu (pomiędzy nawiasami klamrowymi) można używać etykiet o postaci:
case wyr_stałe : ins
oraz
default : ins // UWAGA. Etykieta default może być tylko jedna
Wyrażenie w nawiasach switch jest wyliczane, a jego wartość porównywana z
wartościami wyrażeń stałych (zawartych w częściach oznaczanych przez etykiety
case). Sterowanie jest przekazywane do tej instrukcji, którą poprzedza etykieta
case z wyrażeniem stałym równym co do wartości wyrażeniu w nawiasach switch.
Od tego miejsca wykonanie programu przebiega dalej sekwencyjnie (po to by
nie wykonywały się inne instrukcje oznaczone przez inne etykiety case, następujące
po wybranej w rezultacie porównania, trzeba zastosować instrukcję break lub
return).
Jeśli nie znajdzie się żadna etykieta "pasująca" do wartości wyrażenie w
nawiasach switch, to sterowanie jest przekazywane do części oznaczanej przez
etykietę default, a jeśli jej nie ma, to - do instrukcji następującej w programie
po switch.
Rozważmy przykład klasy, która udostępnia metodę makeOp wykonania operacji
arytmetycznych na elementach swoich obiektów - dwóch liczbach rzeczywistych.
public class SimpleCalc {
private double a;
private double b;
public SimpleCalc(double x, double y) {
a = x;
b = y;
}
public double makeOp(char op) {
double r = 0;
switch(op) {
case '+' : r = a + b; break;
case '-' : r = a - b; break;
case '*' : r = a * b; break;
case '/' : r = a / b; break;
default : System.out.println("Nieznany kod operacji");
}
return r;
}
}
class SimplecalcTest {
public static void main(String[] args) {
SimpleCalc sc = new SimpleCalc(1.2, 3.7);
System.out.println( sc.makeOp('+'));
System.out.println( sc.makeOp('-'));
System.out.println( sc.makeOp('*'));
System.out.println( sc.makeOp('/'));
}
}
W metodzie makeOp wartość zmiennej op (typu char) steruje obliczeniami (np. jeśli
zawiera znak '+' to sterowanie jest przekazywane do miejsca oznaczonego etykietą
case '+', wartość r jest wyliczana jako suma a i b, a instrukcja break pozwala
opuścić dalsze instrukcje zawarte w bloku switch).
Taki sam program, stosując typ wyliczeniowy, można zapisać tak:
public class SimpleCalc {
private static enum Op { PLUS, MINUS, MULT, DIV };
private double a;
private double b;
public SimpleCalc(double x, double y) {
a = x;
b = y;
}
public double makeOp(Op op) {
double r = 0;
switch(op) {
case PLUS : r = a + b; break;
case MINUS : r = a - b; break;
case MULT : r = a * b; break;
case DIV : r = a / b; break;
default : System.out.println("Nieznany kod operacji");
}
return r;
}
public static void main(String[] args) {
SimpleCalc sc = new SimpleCalc(1.2, 3.7);
System.out.println( sc.makeOp(Op.PLUS));
System.out.println( sc.makeOp(Op.MINUS));
System.out.println( sc.makeOp(Op.MULT));
System.out.println( sc.makeOp(Op.DIV));
}
}
Warto szczególnie podkreślić, że etykiety case są tworzone przez wyrażenia
stałe.
Wyrażenie stałe to takie, którego wartość jest znana w fazie kompilacji
i nie może być zmieniona w fazie wykonania programu. Będzie to np. literał
(taki jak '+'. '*' czy 1), nazwa stałej (zadeklarowanej jako final), wyrażenie
składające się z literałów i nazw stałych połączonych operatorami języka
(np. LMAX + 3/LMIN, gdzie LMAX i LMIN - nazwy stałych) lub wartość stałej wyliczenia (z bloku enum). Wartość wyrażenia
stałego musi być typu całkowitego i dać się przekształcić do typu wyrażenia
w nawiasach switch, lub też typu wyliczeniowego i tego samego co typ wyrażenia w nawiasach switch.
Nie należy tez zapominać o umieszczeniu instrukcji we właściwym momencie
przerywających sekwencje operacji zawartych w bloku switch.
Np. poniższa sekwencja:
double a = 0.1;
switch(n) {
case 1 : a = a + 1;
case 2 : a = a + 2;
case 3 : a = a + 3;
}
System.out.prinln(a);
wypisze: 6.1 (dla n = 1), 5.1 (dla n = 2) i 3.1 (dla n = 3), zaś dla innych
wartości n inicjalną wartość zmiennej a (0.1). Jeśli chcemy uzyskać 1.1 dla
n =1, 2.1 dla n=2 i 3.1 dla n=3 to po każdym wyliczeniu a należy wstawić
instrukcję break, przerywającą sekwencyjne wykonywanie instrukcji zawartych
w bloku i przekazującą sterowanie do pierwszej instrukcji poza switch.
Etykiety case i default mogą występować w dowolnej kolejności, ale w ramach
jednego switch nie może być dwóch takich samych etykiet (nie może być dwóch
wyrażeń stałych, które dają w rezultacie tę samą wartość np. 3 i 1 + 2 lub
dwóch etykiet default).
Co jednak, jeśli instrukcje switch są zagnieżdżone ? Okazuje się, że etykiety
case i default są kojarzone zawsze ze "swoim" switch, możemy więc pisać np.
tak:
import javax.swing.*;
public class Test {
public static void main(String[] args) {
int i = Integer.parseInt(JOptionPane.showInputDialog("Liczba"));
switch(i) {
case 1 : switch(testNum(i)) {
case 1 : System.out.println("same one"); break;
case 2 : System.out.println("double one"); break;
default: System.out.println("other one"); break;
}
break;
case 2 : System.out.println("two"); break;
default: System.out.println("other two"); break;
}
System.out.println("Koniec");
}
static int testNum(int n) {
return n*2;
}
}
(w tym fragmencie np. wprowadzenie
1 da na wyjściu napis "double one", zaś 2 - napis "two")
Zwykła instrukcja break przerywa wykonanie tego bloku switch, w którym jest umieszczona.
Etykieta w programie jest identyfikatorem z następującym po nim znakiem :. Nie
nalezy mylić ogólnego pojęcia etykiety ze specjalnym przypadkiem "etykiety"
case
Np. gdyby w poprzednim przykładzie pominąć break po pierwszym case 1:
switch(i) {
case 1 : switch(testNum(i)) {
case 1 : System.out.println("same one"); break;
case 2 : System.out.println("double one"); break;
default: System.out.println("other one"); break;
}
// pominięte break
case 2 : System.out.println("two"); break;
default: System.out.println("other two"); break;
}
System.out.println("Koniec");
to po wprowadzeniu 1 uzyskalibyśmy wynik:
double one
two
Koniec
Natomiast wprowadzenie etykiety i użycie jej w instrukcji break w następujący sposób:
outerSwitch:
switch(i) {
case 1 : switch(testNum(i)) {
case 1 : System.out.println("same one"); break;
case 2 : System.out.println("double one");
break outerSwitch;
default: System.out.println("other one"); break;
}
case 2 : System.out.println("two"); break;
default: System.out.println("other two"); break;
}
System.out.println("Koniec");
umożliwi "wyjście" z zewnętrznego bloku switch za pomocą break użytego w bloku wewnętrznym i da wynik (przy 1 na wejściu):
double one
Koniec
Uwaga: stosowanie etykiet w instrukcji break dla wychodzenia z zagnieżdżonych
bloków dotyczy rózwnież instrukcji sterujących for, while i do...while. (o czym w następnym rozdziale). Stosowanie
etykiet podlega pewnym ograniczeniom - zob. opis języka na stronie sun.java,com.
6. Operator warunkowy ?:
Operator warunkowy ?: ma trzy argumenty - wyrażenia i stosowany jest do konstrukcji wyrażenia warunkowego w następujący sposób:
e1 ? e2 : e3
Typ wyrażenia e1 musi być boolean. Typy pozostałych wyrażeń (e2 i
e3) muszą być takie same lub dopuszczające przekształcenie do tego samego
typu.
Zastosowania operatora ?: tworzy wyrażenie warunkowe.
Wyrażenie warunkowe obliczane jest w następujący sposób. Obliczane jest wyrażenie e1. Jeśli jego wartością jest true
to obliczane jest wyrażenie e2 i jego wartość staje się wartością całego
wyrażenia warunkowego, natomiast wyrażenie e3 jest ignorowane. W przeciwnym
razie ignorowane jest wyrażenie e2, a wartością wyrażenia warunkowgo staje
się - po obliczeniu - wartość wyrażenia e3.
Priorytet operatora ?: jest niski (wyższy tylko od priorytetów operatorów
przypisań i połączenia), wiązanie zaś - prawostronne. Niski priorytet operatora
warunku pozwala unikać nawiasów, choć często warto je zastosować dla większej
czytelności programu.
Wyrażenia warunkowe mogą zastępować proste instrukcje if .. else np.
W kontekście:
int a = 1, d;
double b = 0.7, c;
.....
int func1() {...}
int func2(int) { ...}
void func4() { ... }
|
| Instrukcja if |
Odpowiednik - wyrażenie
warunkowe
|
if (a > b) c = a + 2;
else c = b; | c = a > b ? a + 2 : b; |
if (a < b) c = a + 2;
else d = b + 2; | a < b ? c = a + 2 : d = b + 2; |
if (b>0) d= func2(a) + 2;
else b *= 3.3; | b > 0 ? d = func2(a) + 2 : b *=
3.3; |
if (b > 0) d = func1();
else a++; | b > 0 ? d = func1() : a++; |
if (b > 0) func4();
else d = a + 7; | Nie da się tego zapisać w
postaci wyrażenia warunkowego.
gdyż operand e2 miałby typ void,
a operand e3 int. |
Jak widać zastępowanie instrukcji if operatorem warunkowym nie zawsze jest możliwe.
Jednak nie na zastępowaniu instrukcji if polega wartość operatora warunkowego.
Podstawową jego zaletą jest to, że może on być stosowany w wyrażeniach i
w takich sytuacjach, w których if nie może być zastosowane, lub jego zastosowanie
wymaga - w sumie - trochę sztucznych zabiegów.
Dotyczy to np. inicjacji zmiennnych np.:
int x = (a > b ? 1 : 0);
7. Wyjątki
7.1. Obsługa wyjątków
Swoistym rodzajem podejmowania decyzji w programie jest obsługa i zgłaszanie wyjatków.
Wyjątek - to sygnał o błędzie w trakcie wykonania programu
Wyjątek powstaje na skutek jakiegoś nieoczekiwanego błędu.
Wyjątek jest zgłaszany (lub mówiąc inaczej - sygnalizowany).
Wyjątek jest (może lub musi być) obsługiwany.
Prosty schemat obslugi wyjątków
try {
// ... w bloku
try ujmujemy instrukcje, które mogą spowodować wyjątek
} catch(
TypWyjątku exc) {
// ... w klauzuli catch umieszczamy obsługę wyjątku
}
Gdy w wyniku wykonania instrukcji w bloku try powstanie wyjątek typu
TypWyjatku to sterowanie zostanie przekazane do kodu umieszczonego w w/w klauzuli catch
Przykłady.
a) Brak jawnej obsługi wyjątku - powstały błąd (wyjątek) powoduje zakończenie
programu, a JVM wypisuje komunikat o jego przyczynie.
public class NoCatch {
public static void main(String[] args) {
int a = 1, b = 0, c = 0;
c = a/b;
System.out.println(c);
}
}
Exception in thread "main" java.lang.ArithmeticException: / by zero
at NoCatch.main(NoCatch.java:6)
b) Zabezpieczamy się przed możliwymi skutkami całkowitoliczbowego dzielenia przez zero, obsługując wyjątek ArithmeticException
public class Catch1 {
public static void main(String[] args) {
int a = 1, b = 0, c = 0;
String wynik;
try {
c = a/b;
wynik = "" + c;
} catch (ArithmeticException exc) {
wynik = "***";
}
System.out.println(wynik);
}
}
W tym przypadku, wykonanie instrukcji c = a/b; spowoduje powstanie wyjątku
(dzielenie przez zero), a ponieważ instrukcja ta znajduje się w bloku try,
do którego "podczepiona" jest klauzula catch z odpowiednim typem wyjątku,
to sterowanie zostanie przekazane do kodu w catch, zmienna wynik uzyska wartość
"***", i wynik ten zostanie wyprowadzony na konsolę. Gdyby zmienna b nie
miała wartości zero, wyjątek by nie powstał, kod w klauzuli catch nie został
by wykonany i na konsolę wyprowadzony by został wynik dzielenia a/b.
Mechanizm obsługi wyjątków może być wykorzystywany w bardzo różny i elastyczny sposób.
Typowym przykładem jest weryfikacja wprowadzanych przez użytkownika danych.
Wielokrotnie w dotąd omawianych przykładowych programach żądaliśmy od użytkownika
wprowadzania liczb całkowitych, a następnie za pomocą metody parseInt
przekształcaliśmy ich znakową reprezentację na binarną. Jak wiemy, jeśli
przy tym wprowadzony napis nie reprezentuje liczby całkowitej, to powstaje
wyjątek NumberFormatException. Powinniśmy go zawsze obsługiwać.
Pokazuje to poniższy program.
public static void main(String[] args) {
String s1 = JOptionPane.showInputDialog("Podaj pierwszą liczbę");
if (s1 != null) {
String s2 = JOptionPane.showInputDialog("Podaj drugą liczbę");
if (s2 != null) {
int n1;
int n2;
try {
n1 = Integer.parseInt(s1);
n2 = Integer.parseInt(s2);
} catch (NumberFormatException exc) {
System.out.println("Błędne dane - kończę działanie");
return;
}
JOptionPane.showMessageDialog(null, "Suma: " + (n1 + n2));
}
}
}
Tutaj obsługa wyjątku polega na wypisaniu
komunikatu i zakończeniu dzialania programu. Program jest niedoskonały,
choćby dlatego, że nie pozwla na poprawienie błędów, tylko kończy
dizałanie.
W przytoczonych przykładach na pewno dość tajemniczo wyglądają napisy NumberFormatException
czy ArithmeticException.
I co oznacza użycie w nawiasach klauzuli catch
tych nazw z dodatkiem czegoś co wygląda jak zmienna np.
catch (NumberFormatException exc) ...
Otóż wyjątki są obiektami klas wyjątków.
Zatem nazwy NumberFormatException, ArithmeticException itd. sa nazwami
klas, a zmienna exc we wcześniejszych przykładach jest faktycznie zmienną
- zawiera referencję do obiektu odpowiedniej klasy wyjątku.
Wobec takiej
zmiennej możemy użyć rozlicznych metod, które dostarczą nam informacji o
przyczynie powstania wyjątku. Oto niektóre z nich.
String | getMessage()
Zwraca napis, zawierający informację o wyjątku (np. błędne dane lub indeks). |
void | printStackTrace()
Wypisuje na konsoli informacje o wyjątku oraz sekwencje wywołań
metod, która doprowadziła do powstania wyjątku (stos wywołań). Wersje tej
metody pozwalają te informacje zapisywac do plików (logów) |
String | toString()
Zwraca
informację o wyjątku (zazwyczaj nazwę klasy wyjątku oraz dodatkową
informację uzyskiwaną przez getMessage()) |
Throwable | getCause()
Zwraca wyjątek
niższego poziomu, który spowodował powstanie tego wyjątku albo null
jeśli takiego wyjątku niższego poziomu nie było lub nie jest
zidentyfikowany (zastosowaniem tej metody nie będziemy się teraz
zajmować - przydaje się ona np. przy obsłudze wyjątków SQL, o czym w
przyszłym semestrze). |
Zobaczmy na przykładzie jakie informacje możemy uzyskać o wyjątku:
import java.util.*;
class ReportExc {
public ReportExc() {
wykonaj();
}
public void wykonaj() {
try {
int num = Integer.parseInt("1aaa");
} catch (NumberFormatException exc) {
System.out.println("Co podaje getMessage()");
System.out.println( exc.getMessage());
System.out.println("Co podaje toString()");
System.out.println(exc);
System.out.println("Wydruk śladu stosu (kolejność wywołań metod)");
exc.printStackTrace();
System.exit(1);
}
}
public static void main(String[] args) {
new ReportExc();
}
}
Program ten wyprowadzi:
Co podaje getMessage()
For input string: "1aaa"
Co podaje toString()
java.lang.NumberFormatException: For input string: "1aaa"
Wydruk śladu stosu (kolejność wywołań metod)
java.lang.NumberFormatException: For input string: "1aaa"
at java.lang.NumberFormatException.forInputString(Unknown Source)
at java.lang.Integer.parseInt(Unknown Source)
at java.lang.Integer.parseInt(Unknown Source)
at ReportExc.wykonaj(ReportExc.java:11)
at ReportExc.<init>(ReportExc.java:6)
at ReportExc.main(ReportExc.java:24)
Warto zwrócić uwagę, że wydruk "śladu" stosu (stack trace)
odtwarza całą sekwencję wywołań metod, ktora doprowadziła do powstania wyjątku.
Czytamy od góry: wyjątek został zgłoszony przez instrukcję w wierszu 435
pliku z definicją klasy Integer w metodzie parseInt() klasy java.lang.Integer,
do którego to miejsca sterowanie przyszło z wiersza 476. Ta informacja dotyczy klas standardowych
pakietów Javy, a nie naszego kodu, ale może okazać się czasem pomocna. Metoda
parseInt została wywołana przez metodę wykonaj() z klasy ReportExc w wierszu
11 pliku źródłowego (tu po raz piewrszy widzimy nasz plik źródłowy na wydruku
- zatem tu, w linii 11, tkwi przyczyna błędu). Jaki to błąd ? Błędny format
danych. Jakich? 1aaa. To wszystko mamy podane.
Zauważmy jeszcze, że słowo <init> oznacza konstruktor, że metoda wykonaj()
została wywołana z tego konstruktora (w wierszu 6) klasy ReportExc, a konstruktor
był wywołany z metody main w wierszu 24 pliku źródłolwego.
Klasy wyjątków tworzą dość rozbudowaną hierarchię dziedzczenia (zob. rysunek, na którym pokazano jej fragmenty).
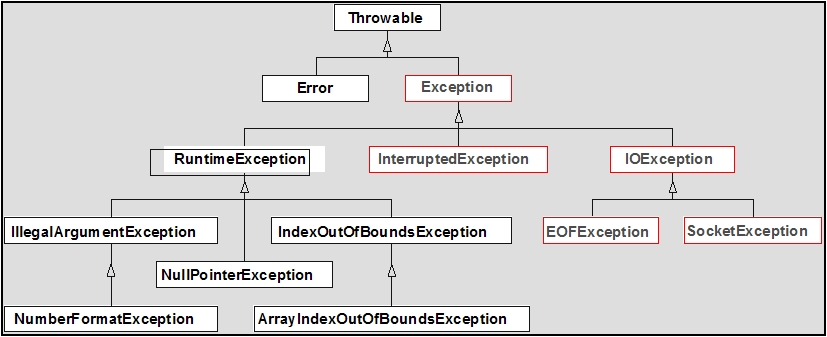
Wszystkie klasy wyjątków pochodzą od klasy Throwable. Mamy następnie dwie wyróżnione
klasy Error i Exception. Od klasy Exception pochodzi klasa RuntimeException
oraz wiele innych.
Podstawowa
różnica pomiędzy tymi klasami polega na tym, że wyjątki klas pochodnych
od Exception. ale nie RuntimeException (klasy zaznaczone na rysunku na czerwono) są tzw. wyjątkami kontrolowanymi,
co oznacza, że musimy zapewnić ich obsługę (kompilator zgłosi błąd,
jeśli tego nie zrobimy). Pozostałych wyjątków obsługiwać nie musimy
(ale możemy) - co już widzieliśmy na przykładzie NumberFormatException
czy ArithmeticException.
Zapewnienie obsługi wyjątku oznacza:
- albo ujęcie instrukcji, która może go spowodować w blok try-catch,
- albo przesunięcie obsługi do kodu, który wywołuje ten blok, w którym zawarta jest ta instrukcja.
Zobaczmy
przykład. W poniższym programie chcemy wypisać jakiś tekst, wstrzymać
wykonanie programu na 2 sekundy i następnie wypisać inny tekst. W
celu uśpienia programu zastosujemy statyczną metodę sleep z
klasy Thread z argumentem, równym liczbie milisekund, którą program ma
odczekać przed podjęciem dalszego wykonania.
public class ControlledExc {
public void printWaitAndPrint() {
System.out.println("Za 2 sekundy wypiszę następny tekst");
Thread.sleep(2000);
System.out.println("Następny tekst");
}
public static void main(String[] args) {
new ControlledExc().printWaitAndPrint();
}
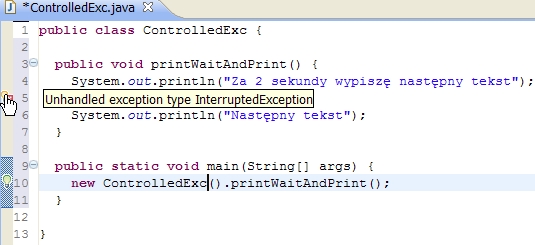
}Niestety,
ten kod się nie skompiluje poprawnie, ponieważ metoda sleep może zgłosić
kontrolowany wyjątek klasy InterruptedException (przerwanie stanu
oczekiwania).
Rysunek pokazuje błąd kompilacji sygnalizowany w Eclipse.
Po kliknięciu w ikonkę błędu Eclipse zaproponuje dwa możliwe rozwiązania problemu:
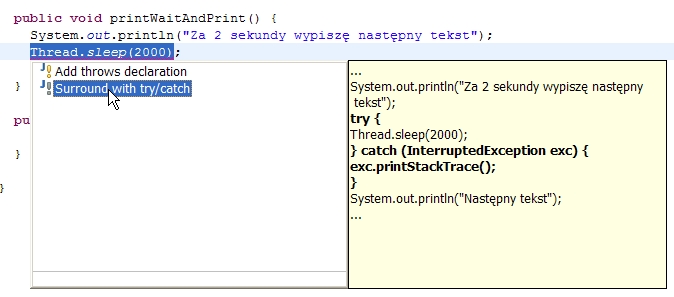
Wybranie
opcji "Surround .." spowoduje dopisanie bloku try-catch wokół wywołania
metody sleep() (propozycja widoczna na żółtym tle).
Wybranie opcji "Add throws declaration" spowoduje natomiast dopisanie deklaracji throws InterruptedException
do nagłówka metody printWaitAndPrint() i oznacza, że przy
powstaniu tego wyjątku zamiast jego obsługi w kodzie metody
printWaitAndPrint() zostanie on przez nią zgłoszony. To z kolei
przeniesie obowiązek obsługi do miejsca, które wywołuje metodę
printWaitAndPrint().
Deklaracja
throws uzywana jest w nagłówku definicji metody (lub konstruktora) i ma postać:
throws
TypWyj1, TypWyj2, ... , TypWyjNOznacza to, że dana metoda może zgłaszać wyjątki podanych typów.
Np.
public void metoda() throws InterruptedException {
// ... ciało metody
// ... może tu powstać wyjątek InterruptedException
}
Po wyborze opcji "Add throws declaration" metoda printWaitAndPrint będzie miała postać:
public void printWaitAndPrint() throws InterruptedException {
System.out.println("Za 2 sekundy wypiszę następny tekst");
Thread.sleep(2000);
System.out.println("Następny tekst");
}
i kompilator nie będzie się czepiał jej kodu. Ale ponieważ metodę tę wywołujemy z main:
public static void main(String[] args) {
new ControlledExc().printWaitAndPrint();
}to
problem przeniesie się w miejsce wywolania (wyjątki kontrolowane - tak
czy inaczej, tu czy gdzie indziej muszą być obsługiwane):
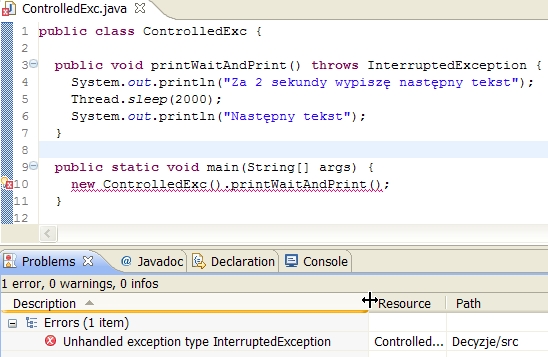
Poprawny kod będzie zatem wyglądał tak:
public class ControlledExc {
public void printWaitAndPrint() throws InterruptedException {
System.out.println("Za 2 sekundy wypiszę następny tekst");
Thread.sleep(2000);
System.out.println("Następny tekst");
}
public static void main(String[] args) {
try {
new ControlledExc().printWaitAndPrint();
} catch (InterruptedException exc) {
exc.printStackTrace();
}
}
}
Naturalnie,
moglibyśmy też obsłuzyć ten wyjątek w samej metodzie
printWaitAndPrint() i wtedy niepotrzebna by była deklaracja
throws, ani też obsługa w main(..).
Z obsługą wyjatków wiążą się jeszcze dwie ważne kwestie.
Po pierwsze,
w bloku try { ... } może powstać (być zgłoszonych) wiele wyjątków
różnych typów. Dlatego możemy mieć wiele klauzul catch. A dodatkowo
możemy (ale nie musimy) zapisać klauzulę finally,
w której zawrzemy jakiś kod, który ma się wykonać niezależnie od
tego czy przy wykonaniu bloku try jakiś wyjątek powstał czy nie. Kod w
klauzuli finally służy zwykle do porządkowania zasobów (np. zamykania
połączeń bazodanowych czy sieciowych). Zatem ogólna postać bloku try {
.. } jest następująca:
try {
// instrukcje wykonywane w bloku try
} catch (TypWyj1 exc) {
// obsluga wyjątku typu TypWyj1
} catch (TypWyj2 exc) {
// obsluga wyjątku typu TypWyj2
}
// ...
} catch (TypWyjN exc) {
// obsluga wyjatku typu TypWyjN
} [ finally {
// kod wykonywany niezaleznie do tego czy wyjatek powstał czy nie
} ]
Uwaga: nawiasy kwadratowe wskazuję na opcjonalność klauzuli finally
Sekwencja dzialania jest następująca.
-
Wykonywane są kolejne instrukcje bloku try.
-
Jeśli przy wykonaniu którejś z instrukcji zostanie zgłoszony wyjątek,
wykonanie bloku try jest przerywane w miejscu zgłoszenia wyjatku,
-
Sterowanie przekazywane jest do pierwszej w kolejności klauzuli
catch, w której podana w nawiasach okrągłych po słowie catch klasa wyjątku pasuje
do typu powstalego wyjątku. Słowko "pasuje" oznacza tu, że podana w klauzuli
klasa wyjatku jest taka sama jak klasa powstałego wyjątku lub jest jej dowolną
nadklasą.
-
Stąd ważny wniosek: należy najpierw zapisywać kluazule catch z BARDZIEJ SZCZEGÓŁOWYMI TYPAMI WYJĄTKÓW np. najpierw FileNotFoundException, a później IOException, bo klasa FileNotFoundException jest pochodna od IOException
-
Inne klauzule catch nie są wykonywane.
-
Obsługująca wyjątek klauzula catch może zrobić wiele rzeczy: m.in. zmienić
sekwencję sterowania (np. poprzez return). Jeśli nie zmienia sekwencji sterowania
to wykonanie programu będzie kontynuowane od następnej instrukcji po bloku try.
- Ale
niezaleznie od tego czy wyjątek powstał czy nie i niezależnie od tego
czy ew. obsługująca go klauzula catch zwraca sterowanie czy nie zawsze
zaraz po zakończeniem działania bloku try wykonana zostanie
klauzula finally (o ile jest).
I druga wazna kwestia:
Jeśli
obsługujemy wyjątek za pomocą try-catch, to albo w klauzuli catch
powinniśmy poprawić błąd, albo wypisać informację o błędzie. Nigdy nie
pozostawiajmy catch pustym!
Zobaczmy przykład programu, który
na podstawie dwóch wprowadzonych w dialogach wejściowych napisów,
reprezentujących liczby całkowitych podaje sumę tych liczb oraz
sumę długości wprowadzonych napisów (długość napisu s uzyskamy za
pomocą odwołania s.length()).
Sumowanie realizuje metoda sumStrings, której przekazujemy wprowadzone napisy. Metoda zwraca tekst opisujący wynik.
Może
się okazać, że metodzie przekazano wartość null - wtedy w odwołaniu
s.length() wystąpi wyjątek NullPointerExceptiom. Może się też zdarzyć,
że napis nie daje się zinterpretować jako znakowa reprezentacja liczby
(wtedy wystąpi NumberFormatException). Obsługujemy oba te wyjątki,
zwracając informację o zaistniałym błędzie. Na końcu dodaliśmy obsługę
dowolnego wyjątku pochodnego od klasy Exception ("jakiś błąd") oraz
klauzulę finally.
import javax.swing.*;
public class StringCalc {
public String sum(String s1, String s2) {
int sum = 0,
sumLen = 0;
try {
sum = Integer.parseInt(s1) + Integer.parseInt(s2);
sumLen = s1.length() + s2.length();
} catch(NullPointerException exc) {
return "Któryś z napisów jest null";
} catch (NumberFormatException exc) {
return "Któryś z napisów nie jest liczbą";
} catch (Exception exc) {
return "Wystąpił jakis błąd";
} finally {
JOptionPane.showMessageDialog(null, "Jestem finally!");
}
return "Suma: " + sum + '\n' + "Suma długości: " + sumLen;
}
public static void main(String[] args) {
String s1 = JOptionPane.showInputDialog("Podaj pierwszą liczbę");
String s2 = JOptionPane.showInputDialog("Podaj drugą liczbę");
StringCalc calc = new StringCalc();
JOptionPane.showMessageDialog(null, calc.sum(s1, s2));
}
}
Uruchomienie programu pokaże, że dostajemy właściwe wyniki, a
przy wadliwych danych (np. po Cancel w dialogu wejściowym lub podaniu
napisu, nie dającego się potraktować jako liczba) odpowiednie
informacje o błędach. Niezależnie od tego czy wystąpił błąd w danych
czy nie, za każdym razem zadziała klauzula finally i to jeszcze przed
zwróceniem sterowania.
Moglibyśmy jednak popełnić dwa błędy w kodowaniu.
Nie
umieszczając kodu obsługi w klauzulach catch (pozostawiając je puste)
nie dostalibyśmy żadnej informacji o błędzie, a jedynie nieprawidłowy
wynik.
Z kolei przestawiając klauzulę catch(Exception exc) na
początek nie uzyskalibyśmy informacji o przyczynach wadliwości danych
(czy null czy nie-liczba), tylko enigmatyczny komunikat ("Wystąpił
jakiś błąd"). Dzieje się tak dlatego, gdyż Exception jest nadklasą
pozostałych obsługiwanych wyjątków i wobec tego "jego" catch pasuje do
obu rodzajów błędów w danych i jako pierwszemu pasującemu (w
kolejności zapisów) jemu to właśnie zostanie przekazane sterowanie.
7.2. Zgłaszanie wyjątków
Do zgłaszania wyjątków służy instrukcja sterująca throw.
Instrukcja sterująca throw ma postać:
throw excref;
gdzie:
excref - referencja do obiektu klasy wyjątku.
Np.
throw new NumberFormatException("Wadliwy format liczby: " + liczba);
W istocie, instrukcja throw jest niczym innym jak sposobem specyficznego
przekazywania sterowania do jakichś punktów programu (do miejsc obsługi wyjątku).
Należy jednak korzystać z niej wyłącznie w celu sygnalizowania błędów.
Zwykle w naszym kodzie będziemy sprawdzać warunki powstania błędu i jeśli są spełnione (wystąpił błąd) - zgłaszać wyjątek.
Jak zobaczymy w następnym punkcie możemy tworzyć własne klasy wyjątków i
zgłaszać własne wyjątki. Nie należy jednak tego nadużywać, w istocie w Javie
dostępna jest duża liczba gotowych, standardowo nazwanych, klas wyjątków
i warto z nich właśnie korzystać.
Typowe, gotowe do wykorzystania, klasy wyjątków opisujących częste rodzaje błędów fazy wykonania programu pokazuje tabela.
| Klasa wyjątku | Znaczenie
|
|---|
| IllegalArgumentException | Przekazany metodzie lub konstruktorowi argument jest niepoprawny,
|
| IllegalStateException | Stan obiektu jest wadliwy w kontekście wywołania danej metody |
| NullPointerException | Referencja ma wartość null w kontekście, który tego zabrania.
|
| IndexOutOfBoundsException | Indeks wykracza poza dopuszczalne zakresy |
| ConcurrentModificationException | Modyfikacja obiektu jest zabroniona |
| UnsupportedOperationException | Operacja (na obiekcie) jest niedopuszczalna (obiekt nie udostępnia tej operacji). |
Możemy także wykorzystywać inne klasy, takie jak NumberFormatException (błąd
formatu liczby) czy NoSuchElementException (wyjątek sygnalizowany, gdy w
kolekcjach danych staramy się sięgnąc do nieistniejącego elementu).
Zwróćmy uwagę, że wszystkie wymienione wyżej wyjątki są
niekontrolowane,
bowiem pochodzą od klasy RuntimeException, co ułatwia ich
wykorzystanie,
bowiem nie zmusza programisty do ich obsługi. Nie musimy też takich
wyjątków
podawać w klauzuli throws w deklaracji metody, które je zgłasza (ale
możemy,
co sprzyja lepszej dokumentacji kodu). Ważne jednak jest, by tworząc i
zgłaszając wyjątek jakiejś standardowej klasy podać przy wywołaniu konstruktora
informację o przyczynie wyjątku.
Przykładowo
w klasie definiującej konta bankowe możemy mieć metodę withdraw(double
d), za pomocą której jest dokonywana wypłata z konta w wielkości d.
Oczywiście
nie można wypłacić sumy mniejszej lub równej 0. Załóżmy, że nie można
też wypłacić więcej niż wynosi aktualny stan konta.
Oba błędy możemy sygnalizować za pomocą zgłoszenia wyjątku IllegalArgumentException:
public class Account {
// ...
private double balance;
// ...
public void withdraw(double d) {
if (d <= 0) throw new IllegalArgumentException("Withdrawal should be > 0");
if (balance - d < 0)
throw new IllegalArgumentException("Withdrawal exceeding balance not allowed");
balance -= d;
}
Nic nie stoi na przeszkodzie, by definiować własne klasy wyjątków i posługiwać się nimi w naszych programach.
Żeby stworzyć własny wyjątek należy zdefiniować odpowiednią klasę.
Zgodnie z konwencją dziedziczymy podklasę Throwable - klasę Exception.
class NaszWyj extends Exception {
...
}
Zwykle w naszej klasie wystarczy umieścić dwa konstruktory: bezparametrowy
oraz z jednym argumentem typu String (komunikat o przyczynie powstania wyjątku).
W konstruktorach tych należy wywołać konstruktor nadklasy (za pomocą odwołania
super(...), w drugim przypadku z argumentem String).
Obowiązują następujące zasady zgłaszania wyjątków:
- gdy jakaś nasza metoda może zgłosić kontrolowany wyjątek klasy NaszWyj -- musi podać
w deklaracji, w klauzuli throws klasę zgłaszanego wyjątku lub dowolną jej nadklasę
- void naszaMetoda() throws NaszWyj
-
nasza metoda sprawdza warunki powstania błędu
-
jeśli jest błąd - tworzy wyjątek (new NaszWyj(...)) i sygnalizuje go za
pomocą instrukcji throw :
- throw new NaszWyj(ew_param_konstruktora_z_info_o_błędzie)
Oczywiście, nie musimy tworzyć wyłącznie kontrolowanych własnych
wyjątków (a tak się dzieje, gdy odziedziczymy klasę Exception).
Możemy przecież dziedziczyć klasę RuntimeException.
Podejmując decyzje w tym względzie warto jednak posługiwać się przyjętymi
konwencjami: te wyjątki, które mogą powstawać w różnych miejscach kodu i wymuszanie
obowiązkowej obsługi których byłoby dla użytkowników naszych klas bardzo
uciążliwe - uczyńmy niekontrolowanymi, inne, szczególnie takie, z których
aplikacja powinna prawie zawsze "się podnosić" (jak np. koniec pliku) - programujmy
jako kontrolowane.
Przykładowo możemy obok klasy Account dostarczyć własnej klasy kontrolowanego wyjątku AccountException:
public class AccountException extends Exception {
public AccountException() {
}
public AccountException(String msg) {
super(msg);
}
}i zmienić metodę withdraw w następujący sposób:
public void withdraw(double d) throws AccountException {
if (d < 0) throw new AccountException("Withdrawal should be >= 0");
if (balance - d < 0)
throw new AccountException(
"Withdrawal exceeding balance not allowed");
balance -= d;
}W
takim przypadku (wyjatek niekontrolowany) użycie klauzuli throws jest
opcjonalne, możemy ją pominąć, ale zazwyczaj umieszcza się ją ze
względów informacyjnych i dokumentacyjnych.
Klasie Account przyjrzymy się dokładnie w następnym wykładzie.
8. Podsumowanie
Wykład poświęcony był przede wszystkim szczegółowemu omówieniu instrukcji
i operatorów przeznaczonych do podejmowania decyzji w programie.
W tej chwili instrukcje if, if-else, switch oraz operator warunkowy nie mają przed nami tajemnic.
Omówiono też szczególny rodzaj podejmowania decyzji w programie jakim jest obsługę i zgłaszanie wyjątków .
Prawidłowe
użycie instrukcji sterujących, jak i konstrukcji związanych z obsługą i
zgłaszaniem wyjątków jest ważnym czynnikiem sprawnego programowania.