1. Anatomia
Rozważymy
nieco inną (niż wykorzystywana dotąd w przykładach)
konstrukcję klasy Para, tak by na jej przykładzie móc
dokładnie prześledzić
co dzieje się przy tworzeniu obiektów i wywoływaniu metod.
public class Para {
private int a; // To są "dane" (zwane polami klasy).
// Określają one z jakich elementów składać się
private int b; // będą obiekty tej klasy.
// a = pierwszy składnik pary, b - drugi
public Para(int x, int y) { // konstruktor: nadaje wartość parze
a = x ; // na podstawie przekazanych wartości x i y
b = y;
}
public void set(Para p) { // metoda ustalenia wartości pary
a = p.a; // na podstawie składników przekazanej pary
b = p.b;
}
public Para add(Para p) { // metoda dodawania dwóch par
Para wynik = new Para(a, b);
wynik.a += p.a;
wynik.b += p.b;
return wynik;
}
// metoda pokazująca parę
public void show(String s) {
System.out.println(s + " ( " + a + " , " + b + " )" );
}
}
W
innej klasie możemy użyć klasy Para, np. tak:
class ParaTest {
public static void main(String[] args) {
Para para1 = new Para(1, 5);
Para para2 = new Para(2, 4);
para1.show("Para 1 =");
para2.show("Para 2 =");
Para sumaPar = para1.add(para2);
sumaPar.show("Suma par =");
para1.set(para2);
para1.show("Teraz para 1 = ");
}
}
Powyższy
program wyprowadzi na konsolę następujące wyniki.
Para 1 = ( 1 , 5 )
Para 2 = ( 2 , 4 )
Suma par = ( 3 , 9 )
Teraz para 1 = ( 2 , 4 )
Zobaczmy
co się naprawdę dzieje.
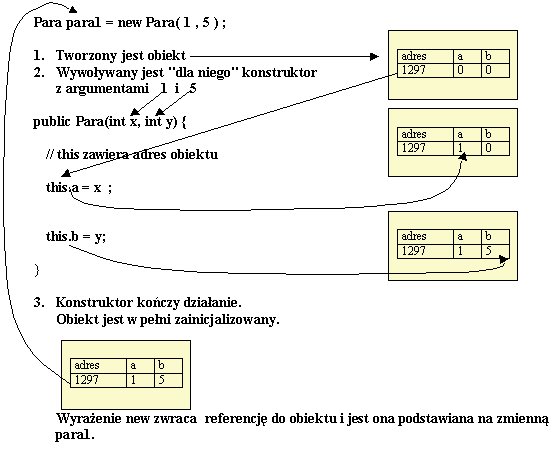
Gdy piszemy:
Para para1 = new Para(1, 5);
wyrażenie new tworzy
obiekt, tzn.:
- wydziela miejsce w pamięci do przechowania
obiektu-pary (miejsce na dwie liczby całkowite),
- elementy
pary odpowiadają polom a i b zadeklarowanym w klasie,
- elementy
te otrzymają wartość 0 (domyślna inicjacja),
- wywoływany
jest konstruktor klasy Para z argumentami 1 i 5, a jego
wykonanie powoduje, że elementy utworzonej pary odpowiadające polom a i
b
otrzymują odpowiednio wartości 1 i 5 ,
- wyrażenie
new zwraca referencję do nowoutworzonego obiektu,
- referencja
ta podstawiana jest na zmienną para1 (w tej chwili zmienna
para1 zawiera referencję - inaczej odniesienie - do nowoutworzonej pary).
Podobnie możemy napisać:
Para para2 = new Para(2,4);
Mamy teraz dwa obiekty para1 i para2.
para1 "wygląda" tak: para2 "wygląda" tak:
Pola: Pola:
int a; ( = 1) int a; ( = 2)
int b; ( = 5) int b; ( = 4)
----------------------------------------------------
Metody: Metody:
void set(...) void set(...)
Para add(...) Para add(...)
void show(...) void show(...)
Identyfikatory
pól i metod są takie same!
Zatem trzeba ich używać "na rzecz" konkretnego obiektu (para1 albo
para2).
Do tego rozróżniania służy kropka (nareszcie naocznie widać
jej użyteczność):
para1.a - oznacza element a obiektu para1
para2.a - oznacza element a obiektu para2
To samo z metodami:
para1.show(); // obiektowi oznaczonemu para1
wysyłamy komunikat show (pokaż się)
// co oznacza wywołanie metody show na rzecz
obiektu
para1
para2.show(); // obiektowi oznaczonemu para2
wysyłamy komunikat show (pokaż się)
// co oznacza wywołanie metody show na rzecz
obiektu
para2
Uwagi:
- o
ile elementy obiektów (odpowiadające polom) są zawarte
w obiektach, to metody - są "wspólne" dla wszystkich obiektów klasy;
podpisanie
ich pod każdym obiektem oznacza tylko, że mogą one być używane dla tego
obiektu,
a nie, że zajmują jakieś miejsce "w obiekcie"
- w
opisie użyto "skrótu myślowego" dla uproszczenia tekstu
mówiąc o obiektach para1 i para2; pamiętamy, że tak naprawde zmienne te
są
referencjami do obiektów.
Zajrzyjmy teraz do wnętrza klasy. Skąd wiadomo co
konkretnie oznacza a
i b w konstruktorze albo w metodzie set?
Rozważmy
konstruktor
class Para {
int a, b;
public Para(int x, int y) {
a = x
;
b = y;
}
....
}
Słowo this
jest
słowem kluczowym języka
Wyrażenie new najpierw
tworzy obiekt, a później wywoływany jest konstruktor. Zatem w momencie
rozpoczęcia
działania konstruktora obiekt już istnieje (jest mu przydzielona pamięć
na
przechowanie dwóch liczb całkowitych, ich wartości
zostały inicjalnie określone,
w naszym przypadku jako zera). Wykonanie konstruktora dotyczy właśnie
tego
nowoutworzonego obiektu. W konstruktorze dostępna jest
referencja do tego
obiektu w postaci niejawnie zdefiniowanej zmiennej o nazwie this.
(this = TEN).
Zatem this.a i this.b - zgodnie z interpretacją znaczenia kropki to
pola
a i b tego obiektu, którego dotyczą inicjacje
wykonywane przez konstruktor.
Ponieważ i tak wiadomo, że samo a i
b dotyczy pól (elementów) tego obiektu,
dla którego akurat wołany jest konstruktor, to słowo this
możemy pominąć.
To samo dotyczy metod wywoływanych na rzecz
obiektów.
Wyobraźmy sobie, że na rzecz obiektu para1 wywołano metodę set z
argumentem para2.
Działanie metody set ma polegać na przepisaniu zawartości pary para2 do
pary para1.
"Algorytm" metody set jest taki:
- polu a tego obiektu na rzecz którego wywołano
metodę przypisz wartość pola a obiektu przekazanego jako argument,
- polu
b tego obiektu na rzecz którego wywołano metodę przypisz wartość pola b
obiektu przekazanego jako argument.
TEN obiekt na rzecz którego wywołano metodę jest wewnątrz metody
reprezentowany słowem kluczowym this.
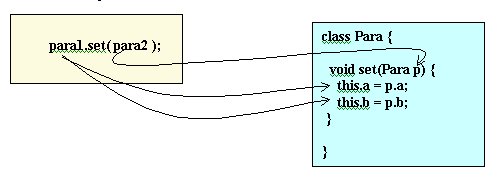
I znowu możemy pominąć słówko this, bo tu jasne jest z kontekstu.
void set(Para p) {
a = p.a;
b = p.b;
}
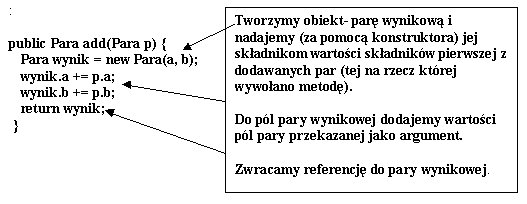
Zobaczmy teraz jak działa metoda dodawania dwóch
par.
Po pierwsze: mamy dwie
pary, które chcemy dodać – wobec tego silna jest
pokusa by użyć metody z dwoma argumentami. Ale przecież programujemy
obiektowo:
pierwsza z par do której dodajemy drugą będzie obiektem do którego
poślemy
polecenie add:
para1.add(para2);
Po drugie: co zrobić z wynikiem dodawania?
W rezultacie dodawania powinna powstać nowa para – suma dwóch dodanych
par.
Ta nowa para winna być stworzona w metodzie add, a referencja do niej
zwrócona jako wynik tej metody. Dlatego:
Zauważmy też, że wszystko co analizowaliśmy dotąd na przykładzie pól -
dotyczy również metod.
Gdybyśmy w klasie Para mieli na przykład dwie metody getA() i getB(),
które
zwracają odpowiednie składniki pary, to w innej metodzie klasy (np.
metodzie
sumującej składniki pary) moglibyśmy się do nich odwołać:
class Para {
int a, b;
...
int getA() { return a; }
int getB() { return b; }
int sum() {
int
pierwsza = this.getA();
int druga
= this.getB();
return
pierwsza + druga;
}
}
co oznaczałoby, że wywołujemy metody getA i getB na rzecz
tego obiektu, na rzecz którego została wywywołana metoda sum.
Ponieważ jest to jasne z kontekstu, możemy napisac prościej:
int sum() {
return getA() + getB();
}
Są przypadki, kiedy użycie slowa kluczowego this jest
istotne. Na przykład, gdy identyfikatory
parametrów przesłaniają (są takie same jak) identyfikatory pól klasy.
class Para {
int a, b;
Para (int a, int b) {
a = ... // o które a chodzi: parametr czy pole???
...
}
void set(int a, int b) {
a = ... // o
które a chodzi: parametr czy pole???
}
}
Dla rozróżnienia należy użyć słowa this.
Zapis this.a zawsze oznacza pole a obiektu
inicjowanego przez konstruktor
lub tego na rzecz którego wywołano metodę. Zatem w powyższym kontekście
piszemy:
class Para {
int a;
int b;
Para(int a, int b) {
this.a = a; // polu a obiektu przypisz wartość parametru a
this.b = b; // polu b obiektu przypisz wartość parametru b
}
void set(int a, int b) {
this.a = a;
this.b = b;
}
}
Słowa
this użyjemy również w
sytuacji, gdy metoda powinna zwrócić referencję do obiektu na rzecz
którego została wywołana.
Np. metodę add(,,,) dodającą pary moglibyśmy zdefiniować w taki sposób,
by
para podana jako argument była "dosumowywana" do pary, na rzecz której
wywołano
metodę (zmieniając wartość tej pary, tak by stanowiła ona sumę par), a
wynik
był zwracany:
Para add(Para p) {
a += p.a;
b += p.b;
return this;
}Dzięki
temu możemy łatwo zapisywać "kumulatywne" sumowanie. Np. w kontekście:
Para suma = new Para(0,0);
Para p1 = new Para(1, 2);
Para p2 = new Para(3, 4);
Para p3 = new Para(5, 6);
zamiast:
suma.add(p1);
suma.add(p2);
suma.add(p3);
możemy napisać:
suma.add(p1).add(p2).add(p3);
2. Zasięg identyfikatorów. Zmienne lokalne. Czas życia danych.
Gdy definiujemy jakąś klasę niebagatelną kwestią okazuje się
pytanie o
możliwości działania na określonych zmiennych. Zwykle sprawia
to początkującym
w Javie programistom wiele trudności.
Zacznijmy od pewnego banalnego (ale wcale nie tak oczywistego
dla kogoś kto zaczyna przygodę z Javą) stwierdzenia.
Wszystkie instrukcje
(oprócz deklaracji pól) można umieszczać wyłącznie w metodach klasy
(jest od tego wyjątek: blok statyczny, ale w tym momencie go
pominiemy)
W samych metodach możemy mieć jednak pewne niejasności:
kiedy
możemy się odwoływać do określonych zmiennych i innych metod?
Jak pamiętamy - nazwy zmiennych, stałych, metod, klas są
identyfikatorami.
Zasięgiem
identyfikatora jest fragment programu, w którym może on
być używany (w którym identyfikator jest rozpoznawany przez kompilator).
W każdej
metodzie klasy możemy
zawsze odwołać się do identyfikatorów składowych klasy (pól i metod), niezależnie
od tego w którym miejscu klasy występuje deklaracja tych pól i metod.
Przypomnijmy:
cialo metody
czyli jej kod ujmowany jest w nawiasy klamrowe. Ujęty w nawiasy
klamrowe kod nazywa się również blokiem.
W każdej metodzie możemy deklarować nowe zmienne (lub stałe). Zasięg
ich identyfikatorów jest lokalny - rozciąga się od
miejsca deklaracji do końca metody (końca bloku stanowiącego
ciało metody), w której zostały zadeklarowane. Mówimy o nich zmienne
(stałe) lokalne
. Dotyczy to również parametrów (których deklaracje występują w
nagłówku
metody). Tak naprawdę, parametry są zmiennymi lokalnymi o zasięgu od
miejsca
deklaracji do końca bloku obejmującego cialo metody.
Również wewnatrz bloków lokalnych (zestawu
instrukcji ujętych w nawiasy
klamrowe wewnątrz metody) możemy wprowadzać deklaracje zmiennych. Ich
zasięg
obejmuje obszar od miejca deklaracji do końca bloku w którym zostały
zadeklarowane.
Zatem, jeśli mamy następującą klasę:
class A {
int a;
void metoda1() {
int b;
...
}
void metoda2() {
int c;
...
}
}
to
w metodzie metoda1 możemy odwoływać się do zmiennej a, zmiennej b, oraz
metody metoda2(), a w metodzie metoda2() możemy odwoływac się do
zmiennej
a, zmiennej c i metody metoda1. Blędem natomiast będzie próba odwołania
się
z metody1 do zmiennej c i z metody2 do zmiennej b.
Jak już widzieliśmy, W konstruktorach i metodach możemy
przesłaniać identyfikatory pól klasy.
Np.
class A {
int a;
void metoda() {
int a = 0; // przesłonięcie identyfikatora pola
a = a + 10; // dotyczy zmiennej lokalnej;
this.a++; // dotyczy pola
}
}
Tutaj
w metodzie metoda() wprowadziliśmy zmiennę lokalną o
tej samej nazwie
co pole klasy (przesłonięcie identyfikatora). Samo odwołanie a
będzie dotyczyć tej zmiennej lokalnej. Jak pamiętamy, przy takim
przesłonięciu
możemy odwolać się do pola używając zmiennej this.
Natomiast:
W Javie nie
wolno przesłaniać
zmiennych lokalnych w blokach wewnętrznych.
Np. konstrukcja:
class A {
....
void metoda() {
int a;
{
int a;
...
}
}
}
jest niedopuszczalna.
Ważna kwestia dotyczy inicjacji zmiennych
lokalnych. Otóż w
przeciwieństwie
do pól klasy, zmienne lokalne nie mają zagwarantowanej inicjacji i
jeśli
nie nadamy im wartości (czy to w jawnej inicjacji, czy za pomocą
przypisania)
ich wartość jest nieokreślona.
Zmienne lokalne muszą mieć na
pewno nadane wartości. W przeciwnym razie wystąpi błąd w
kompilacji, związany z naruszeniem tzw. "definite assignment rule"
Rozważmy przykład kolejnych kroków w pisaniu
programu.
public class DefAsgn {
public static void main(String[] args) {
int a = 3, b = 4, c; // zmienna c jest niezainicjowana
if (a < b) c = 7; // ale tu zapewne dostanie wartość
}
}W
tym momecie kompilator jeszcze nie będzie się skarżył, ponieważ nie
używamy zmiennej c w programie (nie odwołujemy się do jej wartości w
innych instrukcjach).
Jednak po sięgnięciu do
wartości zmiennej c:
public class DefAsgn {
public static void main(String[] args) {
int a = 3, b = 4, c;
if (a < b) c = 7;
System.out.println(c); // tu będzie błąd w kompilacji
}
}kompilator
wykryje błąd i zgłosie, że:
The local variable c may
not have been initialized
(warto
zwrócić uwagę, że kompilator nie analizuje treści programu, tak
naprawdę, przy konkretnych wartościsch a i b zmienna c uzyska przecież
wartość).
Rozwiązaniem problemu jest albo inicjacja
zmiennej c przy deklaracji np.
int a = 3, b = 4, c = 0;
albo
w inny sposób składniowe gwarantowanie jej inicjacji:
public static void main(String[] args) {
int a = 3, b = 4, c;
if (a < b) c = 7;
else c = 8 // użycie else gwarantuje nadanie wartosci zmiennej c
System.out.println(c);
}
Z zasięgiem identyfikatorów wiąże się w pewnym sensie czas
życia danych, ale nie są to pojęcia tożsame.
Czas życia danych to okres od momentu
wydzielenia pamięci dla ich przechowywania do momentu zwolnienia tej
pamięci.
Zmienne lokalne są powoływane do życia w momencie
deklaracji
(automatyczne
wydzielenie pamięci na stosie) i likwidowane przy wyjściu sterowania z
bloku
w którym zostału zadeklarowane (automatyczne zwolnienie pamięci).
Dotyczy
to również tych zmiennych, które są referencjami do obiektów.
Wartości zmiennych
lokalnych są tracone po wyjściu sterowania z bloku - np. zakończeniu
działania metody
Ta oczywista prawda niekiedy jest niedostrzegana i
niektórzy starają
się
np. za pomocą zmiennych lokalnych zliczać liczbę wywołań jakiejś metody
(usiłują
wymyślić sposob na to, a przecież to niemożliwe).
Natomiast niestatyczne pola klasy zachowują się inaczej.
Stanowią one przecież elementy
obiektów. Obiekty zaś są tworzone w momencie wykonania operacji new.
Pamięć
dla nich wydzielana jest dynamicznie – na stercie i zostanie zwolniona
automatycznie
tylko wtedy gdy żadna referencja nie odnosi się już do danego obiektu.
Zatem
niestatyczne pola klasy zachowują swoje wartości pomiędzy wywołaniami
metod (stanowią swoistą globalną pamięć jednego obiektu, dzieloną
pomiędzy różnymi metodami). Zawsze jednak przy tworzeniu obiektów są
one inicjowane od nowa, zatem nie mogą przechować informacji wspólnej
dla wszystkich obiektów klasy. Tę ostatnią rolę (globalnej pamięci,
dzielonej pomiędzy różne obiekty) spełniają natomiast pola statyczne.
Pokazuje
to następujący program:
public class Counter {
private static int objectCount;
private int counter;
public Counter() {
objectCount++;
}
private void increase() {
counter++;
}
public void report() {
System.out.println("Stworzono obiektów " + objectCount);
System.out.println("Licznik w obiekcie " + counter);
}
public static void main(String[] args) {
Counter s1 = new Counter();
s1.increase();
s1.increase();
s1.report();
Counter s2 = new Counter();
s2.report();
}
}
który wyprowadzi w wyniku:
Stworzono
obiektów 1
Licznik w obiekcie 2
Stworzono obiektów 2
Licznik
w obiekcie 0
Warto
zwrócić uwagę, że zaraz po stworzeniu drugiego obiektu (s2) pole
counter w tym obiekcie (licznik w obiekcie) ma wartość 0 i nie ma nic
wspólnego z wartością tego pola z pierwszego obiektu (s1), która jest
równa 2 na skutek dwóch wywołań metody increase. Natomiast pole
statyczne objectCount przy tworzeniu obiektu s1 uzyskało wartość 1 i
wartość ta była zachowana i dostępna w trakcie tworzeniu obiektu s2.
Dlatego przy tworzeniu obiektu s2, w konstruktorze udało się zwiększyć
tę wartość z 1 na 2. W ten sposób policzyliśmy stworzone obiekty klasy
Counter.
3. Pakiety i importy
3.1. Pojęcie pakietu
Pakiety są swoistymi bibliotekami klas. Każda taka
biblioteka (pakiet) grupuje
klasy, które mają jakąś wspólną funkcjonalność np. służą do operacji
we-wy,
budowy aplikacji sieciowych itp.
Każda klasa należy do jakiegoś pakietu.
Klasy kompilowane z deklaracją pakietu package ...
należą do pakietu o nazwie podanej w deklaracji.
Klasy kompilowane bez deklaracji pakietu należę do pakietu "bez nazwy"
(domyślnego).
Pakiet bez nazwy jest definiowany przez środowisku w którym działa Java
(zwykle
jest to bieżący katalog, ale może to być też jakaś tablica w bazie
danych).
Pakiety mają hierarchiczną strukturę:
Pakiet
podpakiet
podpakiet
Np. pakiet o nazwie java.awt zawiera
podpakiet o nazwie java.awt.event.
Pakiet jest pojęciem logicznym. Hierarchiczna struktura
pakietów może być
odwzorowywana w różny fizyczny sposób. Typowym jest struktura katalogów
(kolejne
poziomy hierarchii katalogów odpowiadają kolejnym poziomom hierarchii
pakietów).
W katalogach "terminalnych" znajdują się pliki klasowe (.class)
stanowiące
użytkowe klasy danej "biblioteki". Ponieważ struktury katalogowe dają
się
łatwo archiwizować, to pakiety klas są zwykle przechowywane w plikach
JAR (Java Archive)
lub ZIP.
Java wyposażona jest w setki pakietów (o
których możemy myśleć jak o bibliotekach standardowych), które z kolei
zawierają
tysiące klas. Pakiety są umieszczone w plikach JAR, zawartych
w dystrybucjach Javy.
Po co są pakiety?
Zadaniem pakietów jest nie tylko grupowanie klas według ich
funkcjonalności.
Rozważmy przykład:
File f = new
File("test.txt"); // tworzymy obiekt klasy File
Możliwe
są dwa przypadki: klasa File jest zdefiniowana w tym samym pliku
lub w pliku z katalogu bieżącego ALBO klasa File jest zewnętrzna.
W pierwszym przypadku kompilator (i JVM) mogą odnaleźć potrzebną klasę.
W drugim – powstaje problem gdzie jej szukać.
Co więcej, użycie nazwy File może być niejednoznaczne (może chodzi o
File
z bieżącego pliku, a może o File skądś z zewnątrz).
Zatem pakiety, których zadaniem jest grupowanie klas pełnią
rolę porządkującą
względem przestrzeni nazw klas i chronią przed kolizjami nazw.
Nazwy kwalifikowane
Kwalifikowana nazwa klasy (typu) znajdującej się w nazwanym
pakiecie ma postać:
nazwa_pakietu.nazwa_klasy
np. java.io.File
java.io.File f = new
java.io.File("test.txt");
Klasy zdefiniowane w nienazwanym pakiecie (tj. bez użycia dyrektywy package) mają swoje proste nazwy (czyli np. Para).
Uwaga: przy tworzeniu choć trochę większych projektów należy umieszczać klasy w nazwanych pakietach, stosując dyrektywę package.
W środowisku Eclipse jest to bardzo łatwe - wystarczy podać nazwę pakietu w dialogu definiowania klasy:

Struktura katalogowa projektu PrzykladowyProjekt będzie teraz miała następująca postać:
a automatycznie wygenerowany plik źródłowy MojaKlasa.java będzie zawierał odpowiednią dyrektywę package:
package mojpakiet;
public class MojaKlasa {
public static void main(String[] args) {
}
}
3.2. Import
Generalnie wszystkie nazwy klas użytych w programie winny być
kwalifikowane.
Na szczęście, deklaracja
importu pozwala na użycie nazw uproszczonych
import java.io.File; // importuje nazwę klasy java.io.File
class A {
File f = new File("test.txt");
java.io.FileReader fr = java.io.new FileReader(f);
// ...
}
Powyżej
po importowaniu nazwy klasy java.io.File możemy użyć jej uproszczonej
nazwy File. Ale ponieważ nie importowaliśmy nazwy klasy
java.io.FileReadre
jesteśmy zmuszeni używać jej pełnej kwalifikowanej nazwy.
Oczywiście, można importować dowolnie wiele nazw klas za pomocą
kolejnych deklaracji importu np.:
import
java.io.File;
import java.io.FileReader;
import
java.io.FileWriter;
Wygodna forma
deklaracji importu pozwala importować nazwy wszystkich klas danego
pakietu. Do tego służy gwiazdka:
import java.io.*; // importuje wszystkie nazwy klas pakietu java.io.*
class A {
File f = new File("test.txt");
FileReader fr = new FileReader(f); // teraz możemy też użyć prostej nazwy klasy java.io.FileReader
// ...
}
A
co z klasami String i System, których nazw często używamy w przykladach?
One też stanowią standardowe klasy Javy. I znajdują się w określonym
pakiecie (java.lang).
Pakiet java.lang
nie wymaga importu (m.in zawiera klasy String i System)
Nazwy klas tego pakietu są importowane domyślnie.
Uwaga. Importowanie
nazw klas nie
oznacza "wstawiania" ich definicji
do naszego programu źródłowego. Wielkość programu nie zależy od liczby
importowanych
nazw, a import służy tylko i wyłącznie umożliwieniu posługiwania się
skróconymi
nazwami klas i stanowi sygnał dla kompilatora i JVM gdzie, w jakich
pakietach
szukać definicji tych klas.
3.3. Importy statyczne
Statyczny import umożliwia odwołania do
składowych statycznych bez
kwalifikowania ich nazwą klasy.
Import
składowej
statycznej:
import static TypeName.Identifier;
Import
wszystkich składowych statycznych:
import static TypeName.*;
Przykładowo, możemy importować nazwę System.out i posługiwać
się skróconym zapisem: zamiast System.out.println(...)-
out.println(...):
import static java.lang.System.out;
public class MojaKlasa {
public static void main(String[] args) {
out.println("Trochę krócej");
}
}albo importować wszystkie nazwy składowych statycznych klasy System i wygodnie się do nich odwoływać:
import static java.lang.System.*;
public class MojaKlasa {
public static void main(String[] args) {
long time = nanoTime(); // wywołanie statycznej metody System.nanoTime()
out.println(time); // uzycie statycznej stałej System.out
exit(1); // wywołanie statycznej metody System.exit(..)
}
}
4. Struktura programu
Jak wiemy, program w Javie jest zestawem definicji klas.
Poza ciałem klasy nie
może być żadnego kodu programu - oprócz dyrektywy package, dyrektyw
importu oraz komentarzy.
Strukturę programu obrazuje poniższy schemat.
package ... // deklaracja pakietu (niekonieczna)
import ... // deklaracje importu; zwykle, ale nie zawsze potrzebne
import ...
// To jest klasa A
public class A {
...
}
// To jest klasa B
class B {
...
}
...
Dyrektywa
package służy do "umieszczenia" kompilowanych klas w nazwanym
pakiecie.
Znaczenie importów
- poznaliśmy przed chwilą.
Program może być zapisany w jednym lub wielu plikach
źródłowych (.java)
(w szczególności: wszystkie klasy składające się na program można
umieścić
w jednym pliku albo każdą klasę można umieścić w odrębnym pliku).
Działając w środowiskach uruchomieniowych (IDE) warto umieszczać każdą
klasę w odrębnym pliku, tym bardziej, że w jednym pliku może być tylko
jedna klasa publiczna.
Nie ma kodu poza klasą... A z drugiej strony wiemy też, że
klasa jest swoistym
wzorcem, szablonem określającym właściwości obiektów.
Jak zatem możliwe jest w ogóle działanie programu napisanego
w Javie? Gdzie i jak zaczyna się wykonanie?
Powtórzmy sobie najpierw to wszystko co już wiemy
Oczywiście, najpierw jest kompilacja do B-kodu.
Wszystkie wybrane pliki źródłowe .java podlegają kompilacji za pomocą
kompilatora
Javy (javac.exe). Z każdej klasy w pliku(ach) źródłowym powstaje plik
B-kodu
o rozszerzeniu .class
Jeżeli nasz program jest aplikacją (a nie apletem lub
serwletem), to jedna z klas musi zawierać metodę:
public static void
main(String[] args)
Np. spójrzmy na klasę Work i klasę Inna zdefiniowane w pliku
Work.java
public class Work {
public static void main(String[] args) {
...
}
...
}
class Inna {
...
}
// Koniec pliku Work.java
Po kompilacji (javac Work.java) powstają dwa pliki:
Work.class
Inna.class
Maszyna wirtualna Javy jest wywołana za pomocą polecenia java z
argumentami:
- nazwa_pliku_class_zawierającego_metodę_main (bez
rozszerzenia .class)
- argumenty_wołania
Czyli:
java Work [ew. argumenty przekazywane do main jako String[] args]
Klasa
Work zostaje załadowana przez JVM i sterowanie zostaje przekazane
do metody main. W tej metodzie zaczyna się "życie": tworzenie obiektów,
odwołania
do innych klas aplikacji.
Zauważmy jednak szczególnie jedną ważną rzecz: metoda main jest metodą
statyczną.
Wobec tego - działanie (jakiegoś) programu nie wymaga wcale by istniały
lub
były tworzone obiekty (o ile posługujemy się w metodzie main tylko
zmiennymi
typów prostych).
Nawet jeśli posługujemy się obiektami (takimi jak łańcuchy znakowe) -
nie
musimy tworzyć obiektu klasy, w której zawarta jest metoda main.
Takie podejście jest jednak możliwe tylko wtedy, gdy nasz
program jest stosunkowo
niewielki. Większe programy powinniśmy co najmniej dobrze
strukturyzować
(rozbić na funkcje - metody).
Zobaczmy bardzo prosty przyklad. Mamy trzy liczby i
powinniśmy policzyć i
wyprowadzić ich sumę oraz średnią, po czym wszystkie trzy liczby dwa
razy
zwiększyć o 1, za każdym razem wyprowadzając nową sumę i średnią.
Bardzo zle rozwiązanie tego problemu może wyglądac tak.
public class Main1 {
public static void main(String[] args) {
double a = 12.0,
b = 14.0,
c = 4.0;
double sum = a + b + c;
double avg = (a + b + c)/3;
System.out.println("Suma " + sum);
System.out.println("Srednia " + avg);
a++;
b++;
c++;
sum = a + b + c;
avg = (a + b + c)/3;
System.out.println("Suma " + sum);
System.out.println("Srednia " + avg);
a++;
b++;
c++;
sum = a + b + c;
avg = (a + b + c)/3;
System.out.println("Suma " + sum);
System.out.println("Srednia " + avg);
}
Oczywiście
na myśl przychodzi od razu podział programu na metody.
Być może, długo nie zastanawiając się napiszemy tak:
public class Main2 {
double sum(double a, double b, double c) {
return a + b + c;
}
double average(double a, double b, double c) {
return (a + b + c)/3;
}
void report(double a, double b, double c) {
System.out.println("Suma " + sum(a, b, c));
System.out.println("Srednia " + average(a, b, c));
}
public static void main(String[] args) {
double a = 12.0,
b = 14.0,
c = 4.0;
report(a, b, c);
a++;
b++;
c++;
report(a, b, c);
a++;
b++;
c++;
report(a, b, c);
}
} Chociaż
wielkość programu zmieniła się nieznacznie, to jednak klarowne
wyodrębnienie
pewnych powtarzalnych czynności w postaci metod czyni go bardziej
czytelnym
i elastycznym (latwiej modyfikowalnym).
Niestety, spotka nas rozczarowanie...
Kompilator zgłosi:
Main2.java:21:
non-static method report(double,double,double) cannot be referenced
from a static context
report(a, b, c);
^
Main2.java:25: non-static method report(double,double,double) cannot be
referenced from a static context
report(a, b, c);
^
Main2.java:29: non-static method report(double,double,double) cannot be
referenced from a static context
report(a, b, c);
^
3 errors
Aha, przecież metoda main jest statyczna! Nie
możemy odwoływac się z
jej
wnętrza do niestatycznych składowych klasy Main2 (a taką jest metoda
report).
Gdy uczynimy ją statyczną:
static void
report(...)
problem przeniesie się w inne miejsce: ze statycznej metody
report nie możemy wywołać niestatycznych metod sum i average.
Możemy uczynić je wszystkie statycznymi - i wtedy nasz program zadziała.
Albo - pozostawiając wszystkie metody niestatycznymi - w
metodzie main utworzyć
obiekt klasy i na jego rzecz wywołać metodę report().
Może to wyglądać tak:
public class Main3 {
double sum(double a, double b, double c) {
return a + b + c;
}
double average(double a, double b, double c) {
return (a + b + c)/3;
}
void report(double a, double b, double c) {
System.out.println("Suma " + sum(a, b, c));
System.out.println("Srednia " + average(a, b, c));
}
public static void main(String[] args) {
double a = 12.0,
b = 14.0,
c = 4.0;
Main3 m = new Main3(); // utworzenie obiektu
m.report(a, b, c);
a++;
b++;
c++;
m.report(a, b, c);
a++;
b++;
c++;
m.report(a, b, c);
}
}
Ale
skoro już tworzymy obiekt klasy, to nadajmy jej jakiś istotny sens.
Na
przyklad - niech jej obiekty będą trójkami liczb rzeczywistych.
public class Trojka {
private double a, b, c;
public Trojka(double x, double y, double z) {
a = x;
b = y;
c = z;
}
public double sum() {
return a + b + c;
}
public double average() {
return (a + b + c)/3;
}
public void increase() {
a++;
b++;
c++;
}
public void report() {
System.out.println("Suma " + sum());
System.out.println("Srednia " + average());
}
public static void main(String[] args) {
Trojka t = new Trojka(12, 14, 4);
t.report();
t.increase();
t.report();
t.increase();
t.report();
}
}
Główna
"procedura" main (zauważmy zresztą, że umieszczona w klasie
Trojka;
metoda main może przecież znajdowac się w dowolnej klasie) stała sie
dzięki
temu jeszcze bardziej klarowna, a cały program jeszcze łatwiejszy do
modyfikacji
i uzupełnień, bowiem dane (zmienne a, b, c - zdefiniowane jako pola)
stały
się teraz dostępne dla wszystkich metod klasy i jednocześnie zachowują
swoje
wartości pomiędzy wywołaniami metod, co wykorzystaliśmy definiując
metodę
increase(), zwiększającą o 1 wszystkie trzy dane.
Naturalnie, tę metodę main można też umieścić w innej klasie. Np.
public class Test {
public static void main(String[] args) {
Trojka t = new Trojka(12, 14, 4);
t.report();
t.increase();
t.report();
t.increase();
t.report();
}
}Rozpatrując różne warianty strukturyzacji program warto
podkreślić, że bardzo
często obiekt klasy programu nie jest nam wcale potrzebny. "Praca"
zapisywana
jest w konstruktorze i w metodzie main (rozpoczynającej dzialanie
programu)
wystarczy samo wywolanie konstruktora. Czyni się tak szczególnie
często,
gdy konstruktor tworzy graficzny interfejs użytkownika.
W naszym przypadku sumowania i uśredniania trzech liczb takie
rozwiązanie jest raczej sztuczne, ale dla porządku można je podać.
public class Main4 {
private double a = 12, b = 14, c = 4;
Main4() {
report();
increase();
report();
increase();
report();
}
double sum() {
return a + b + c;
}
double average() {
return (a + b + c)/3;
}
void increase() {
a++; b++; c++;
}
void report() {
System.out.println("Suma " + sum());
System.out.println("Srednia " + average());
}
public static void main(String[] args) {
new Main4();
}
}Zauważmy:
- ponieważ odwołania do metod report i
increase umieściliśmy w konstruktorze,
to nie musimy specyfikowac obiektu do którego się odnoszą (niejawnie
jest
to obiekt oznaczany przez this)
- metoda
main służy tylko do utworzenia obiektu (i wywołania konstruktora);
niepotrzebna jest nam tu żadna do niego referencja - dlatego wynik
opracowania
wyrażenia new nie podstawiamy na żadną zmienną.
5. Pojęcie o dziedziczeniu
Zajmiemy się teraz krótko pojęciem dziedziczenia. Pełna dyskusja tej
tematyki zawarta jest w dalszej częsci tekstu. Tutaj zwrócimy uwagę na
te elementy, które
będą nam potrzebne w najbliższych wykladach.
Dziedziczenie
polega na przejęciu właściwości i funkcjonalności
obiektów innej klasy i ewentualnej ich modyfikacji
i/lub uzupelnieniu w taki sposób, by były
one bardziej wyspecjalizowane.
Omawiana wcześniej klasa Publication opisuje właściwości
publikacji, które
kupuje i sprzedaje księgarnia. Zauważmy, że za pomocą tej klasy nie
możemy
w pełni opisać książek. Książki są szczególną, "wyspecjalizowaną"
wersją
publikacji, oprócz tytułu, wydawcy, ceny itd - mają jeszcze jedną
właściwość
- autora (lub autorów).
Gdybyśmy w programie chcieli opisywać zakupy i sprzedaż książek - to
powinniśmy
stworzyć nową klasę opisującą książki, o nazwie np. Book.
Moglibyśmy to robić od podstaw (definiując w klasie Book pola author,
title,
ident, price i wszystkie metody operujące na nich, jak również metody
sprzedaży
i kupowania).
Ale po co? Przecież klasa Publication dostarcza już większości
potrzebnych nam pól i metod.
Odziedziczymy ją zatem w klasie Book i dodamy tylko te nowe właściwości
(pola
i metody), których nie ma w klasie Publication, a które powinny
charakteryzować
książki.
Słowo kluczowe
extends służy do wyrażenia relacji dziedziczenia jednej
klasy przez drugą.
Piszemy:
class B
extends A {
...
}
co oznacza, że klasa B dziedziczy (rozszerza) klasę A.
Mówimy:
- klasa A jest bezpośrednią nadklasą,
superklasą, klasą bazową klasy B
- klasa B jest
bezpośrednią podklasą, klasą pochodną klasy A
Zapiszmy zatem:
public class Book extends Publication {
// definicja klasy Book
}
Co
należy podać w definicji nowej klasy?
Takie właściwości jak tytuł, wydawca, rok wydania, identyfikator, cena,
liczba
publikacji "na stanie", metody uzyskiwania informacji o tych cechach
obiektów
oraz metody sprzedaży i zakupu - przejmujemy z klasy Publication. Zatem
nie
musimy ich na nowo definiować.
Pozostało nam tylko zdefiniować nowe pole, opisujące autora (niech
nazywa
się author) oraz metodę, która umożliwia uzyskanie informacji o autorze
(powiedzmy
getAuthor()).
class Book extends Publication {
private String author;
public String getAuthor() {
return author;
}
}
Czy
to wystarczy?
Nie, bo jeszcze musimy powiedzieć w jaki sposób mają być inicjowane
obiekty klasy Book. Aha, potrzebny jest konstruktor.
Naturalnie, utworzenie obiektu-książki wymaga podania:
- autora,
- tytułu,
- wydawcy,
- roku
wydania,
- identyfikatora (numeru ISBN)
- ceny,
- liczby
książek aktualnie "na stanie".
Czyli konstruktor powinien mieć postać:
public Book(String aut, String tit, String pub, int y, String id,
double price, int quant) {
....
}
Zwróćmy
jednak uwagę: pola tytułu, wydawcy, roku, identyfikatora, ceny i
ilości - są prywatnymi polami klasy Publication. Z klasy Book nie mamy
do
nich dostępu. Jak je zainicjować?
Pola nadklasy (klasy
bazowej) inicjujemy za pomocą wywołania z konstruktora
klasy pochodnej konstruktora klasy bazowej (nadklasy)
Użycie w
konstruktorze następującej konstrukcji składniowej:
super(lista_argumentów);
oznacza wywołanie konstruktora klasy bazowej z
argumentami
lista_argumentów.
Jeśli występuje - MUSI być pierwszą instrukcją konstruktora klasy
pochodnej.
Jeśli nie występuje - przed utworzeniem obiektu klasy pochodnej
zostanie wywołany konstruktor bezparametrowy klasy bazowej.
Konstruktor klasy Book musi
więc wywołać konstruktor
nadklasy, po to by zainicjować
jej pola, a następnie zainicjować pole author.
// Konstruktor klasy Book
// argumenty: aut - autor, tit - tytuł, pub - wydawca, y - rok wydania
// id - ISBN, price - cena, quant - ilość
public Book(String aut, String tit, String pub, int y, String id,
double price, int quant) {
super(tit, pub, y, id, price, quant);
author = aut;
}
Teraz można podać już pelną definicję klasy Book.
public class Book extends Publication {
private String author;
public Book(String aut, String tit, String pub, int y, String id,
double price, int quant) {
super(tit, pub, y, id, price, quant);
author = aut;
}
public String getAuthor() {
return author;
}
}
Zwróćmy
uwagę: wykorzystanie klasy Publication (poprzez jej
odziedziczenie)
oszczędziło nam wiele pracy. Nie musieliśmy ponownie definiować pól i
metod
z klasy Publication w klasie Book.
Przy tak zdefiniowanej klasie Book możemy utworzyć jej obiekt:
Book b = new Book("James Gossling", "Moja Java", "WNT", 2002,
"ISBN6893", 51.0, 0);
Ten
obiekt zawiera:
- elementy określane przez pola klasy dziedziczonej
(Publication) - czyli: title, publisher, year, ident, price, quantity,
- element
określany przez pole klasy Book - author.
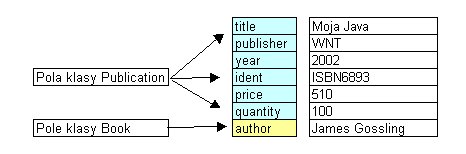
Podkreślmy: jest to jeden obiekt klasy Book.
Wiemy na pewno, że możemy użyć na jego rzecz metody z klasy Book -
getAuthor().
Ale ponieważ klasa Book
dziedziczy klasę Publication to obiekty klasy Book
mają również wszelkie właściwości obiektów klasy Publication, a zatem
możemy
na ich rzecz używać również metod zdefiniowanych w klasie Publication.
.
Nic zatem nie stoi na przeszkodzie, by napisać taki program:
class TestBook {
public static void main(String[] args) {
Book b = new Book("James Gossling", "Moja Java", "WNT", 2002,
"ISBN6893", 51.0, 0);
int n = 100;
b.buy(n);
double koszt = n * b.getPrice();
System.out.println("Na zakup " + n + " książek:");
System.out.println(b.getAuthor());
System.out.println(b.getTitle());
System.out.println(b.getPublisher());
System.out.println(b.getYear());
System.out.println(b.getIdent());
System.out.println("---------------\nwydano: " + koszt);
b.sell(90);
System.out.println("---------------");
System.out.println("Po sprzedaży zostało " + b.getQuantity() + " pozycji");
}
}
który
skompiluje się i wykona poprawnie, dając w wyniku pokazany listing.
Na zakup 100 książek:
James Gossling
Moja Java
WNT
2002
ISBN6893
---------------
wydano: 5100.0
---------------
Po sprzedaży zostało 10 pozycji
Możemy
powiedzieć, że obiekty klasy
Book są również obiektami klasy Publication
(w tym sensie, że mają wszelkie właściwości obiektów klasy Publication)
Dzięki temu referencje do obiektów klasy Book
możemy przypisywać zmiennym,
oznaczającym obiekty klasy Publication (zawierającym referencje do
obiektów
klasy Publication). Np.
Book b = new Book(...);
Publication p = b;
Nazywa się to referencyjną konwersją rozszerzającą
(ang. widening reference
conversion). Słowo konwersja oznacza, że dochodzi do
przekształcenia z jednego
typu do innego typu (np. z typu Book do typu Publication). Konwersja
jest
rozszerzająca, bowiem, przekształcamy typ "pochodny"
(referencja do
obiektu podklasy) do typu "wyższego" (referencja do obiektu nadklasy).
A
ponieważ chodzi o typy referencyjne - mówimy o referencyjnej
konwersji rozszerzającej.
Nieco mniej precyzyjnie, ale
za to podkreślając, że chodzi o operowanie
na obiektach, będziemy mówić o takich konwersjach jako o obiektowych
konwersjach rozszerzających (ang. "upcasting" - up - bo w
górę hierarchii dziedziczenia).
Obiektowe konwersje rozszerzające dokonywane są automatycznie
przy:
- przypisywaniu zmiennej-referencji
odniesienia do obiektu klasy pochodnej,
- przekazywaniu
argumentów metodzie, gdy parametr metody jest typu "referencja do
obiektu nadklasy argumentu",
- zwrocie wyniku, gdy
wynik podstawiamy na zmienną będącą referencją do
obiektu nadklasy zwracanego wyniku
Ta zdolność obiektów Javy do "stawania się" obiektem swojej
nadklasy jest niesłychanie użyteczna.
Wyobraźmy sobie np. że oprócz klasy Book - z klasy
Publication wyprowadziliśmy jeszcze klasę Journal
(czasopisma).
Klasa Journal dziedziczy klasę Publication i dodaje do niej - zamiast
pola,
opisującego autora - pola opisujące wolumin i numer wydania danego
czasopisma.
Być może będziemy mieli jeszcze inne rodzaje publikacji - np. muzyczne,
wydane
na płytach CD (powiedzmy klasę CDisk, znowu dziedziczącą klasę
Publication,
i dodającą jakieś właściwe dla muzyki informacje, np. czas odtwarzania).
Możemy teraz np. napisać uniwersalną metodę pokazującą
różnicę w dochodach
ze sprzedaży wszystkich zapasów dowolnych dwóch publikacji.
public double incomeDiff(Publication p1, Publication p2) {
double income1 = p1.getQuantity() * p1.getPrice();
double income2 = p2.getQuantity() * p2.getPrice();
return income1 - income2;
}
i
wywoływać ją dla dowolnych (różnych rodzajów) par publikacji:
Book b1 = new Book(...);
Book b2 = new Book(...);
Journal j = new Journal(...);
CDisk cd1 = new CDisk(...);
CDisk cd2 = new CDisk(...);
double diff = 0;
diff = incomeDiff(b1, b2);
diff = incomeDifg(b1, j);
diff = incomeDiff(cd1, b1);
Gdyby nie było obiektowych konwersji rozszerzających, to dla każdej
mozliwej
kombinacji "rodzajowej" par - musielibyśmy napisać inną metodę
incomeDiff
np.
double incomeDiff(Book, Book), double incomeDiff(Book, Journal), double
incomeDiff(Book, CDisk) itd.
Zwróćmy uwagę, że w przedstawionej metodzie
incomeDiff można wobec p1 i
p2
użyć metod klasy Publication (bo tak są zadeklarowane parametry), ale
nie
można używać metod klas pochodnych, nawet wtedy, gdy p1 i p2 wskazują
na
obiekty klas pochodnych. Np.
....
{
Book b1 = new Book(...);
Book b2 = new Book(...);
jakasMetoda(b1,b2);
....
}
void jakasMetoda(Publication p1) {
String autor = p1.getAuthor(); // Błąd kompilacji -
niezgodność typów
...
// na rzecz obiektu klasy
Publication
...
// nie wolno użyć metody
getAuthor()
}
// bo takiej metody nie ma w klasie
Publication
Zaradzić temu możemy stosując referencyjną
konwersję zawężającą,
przy czym konieczne jest jawne zastosowanie operatora rzutowania do
typu Book:
void jakasMetoda(Publication p1) {
String
autor = (Book)
p1.getAuthor();
// ...
}
Teraz
kompilator nie będzie się skarżył, ponieważ wyraźnie daliśmy do
zrozumienia, że chcemy potraktować obiekt p1 jako obiekt klasy Book, a
w klasie Book jest metoda getAuthor().
Na koniec krótkiego, wstępnego, mającego raczej
instrumentalny
charakter, wprowadzenia do dziedziczenia, należy podkreślić
bardzo ważną właściwość Javy.
W Javie każda klasa może
bezpośrednio odziedziczyć tylko jedną klasę.
Ale pośrednio może mieć dowolnie wiele nadklas, co wynika z hierarchii
dziedziczenia.
Ta hierarchia zawsze zaczyna się na klasie Object (której definicja
znajduje się w zestawie stanardowych klas Javy).
Zatem w Javie wszystkie klasy pochodzą pośrednio od klasy Object.
Jeśli definiując klasę nie użyjemy słowa extends (nie zażądamy jawnie
dziedziczenia),
to i tak nasza klasa domyślnie będzie dziedziczyć klasę Object (tak
jakbyśmy
napisali class A extends Object).
Wobec tego hierarchia dziedziczenia omawianych tu klas wygląda
następująco:
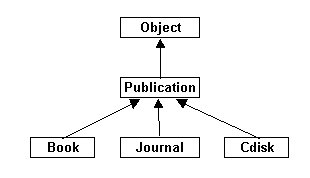
Z tego wynika, że:
referencję do obiektu dowolnej klasy można przypisać zmiennej
typu Object (zawierającej referencję do obiektu klasy Object).
Z właściwości tej korzysta wiele "narzędziowych" metod
zawartych w klasach standardu Javy.