Wykład 3
Modele logiczne hurtowni danych.
Streszczenie
Na poprzednim wykładzie przedstawiono ogólny schemat hurtowni danych. Realizacja hurtowni może
jednak od tego schematu znacznie odbiegać.
Typowe modele hurtowni danych
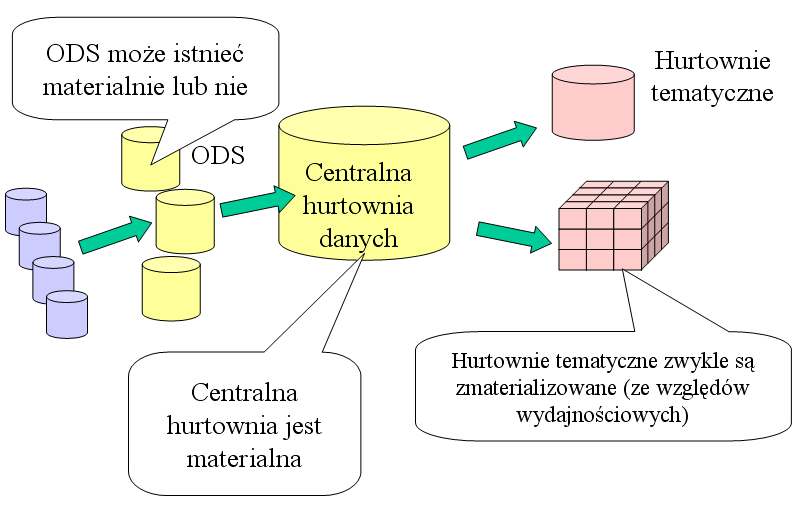
Architektura scentralizowana to najczęściej stosowany
schemat dużych hurtowni danych. Składa się ze wszystkich opisanych na
poprzednim wykładzie części (warstwa ODS jest opcjonalna).
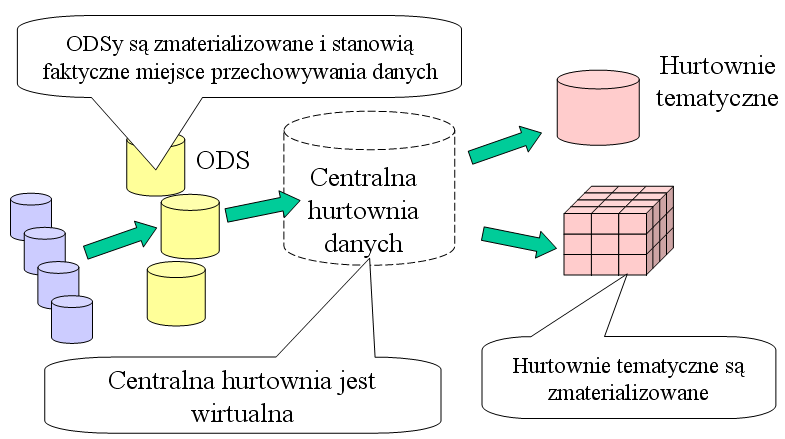
Architektura federacyjna stosowana jest w przypadku,
gdy z różnych powodów nie może powstać centralna, wielka hurtownia danych,
gromadząca wszystkie dane. Wtedy miejscem przechowywania danych są magazyny
danych operacyjnych, a hurtownia istnieje jedynie wirtualnie - jako wspólny
schemat logiczny i pojęciowy (czyli jako niezmaterializowana perspektywa).
Zapytania kierowane do hurtowni muszą być automatycznie przetłumaczane na język
danych w ODS i policzone w sposób rozproszony. Wadą tego rozwiązania jest
mniejsza wydajność, natomiast może się ono okazać wystarczające, jeśli hurtownie
tematyczne (zmaterializowane ze względu na wydajność) obsługują wszystkie
wymagane funkcje analityczne.
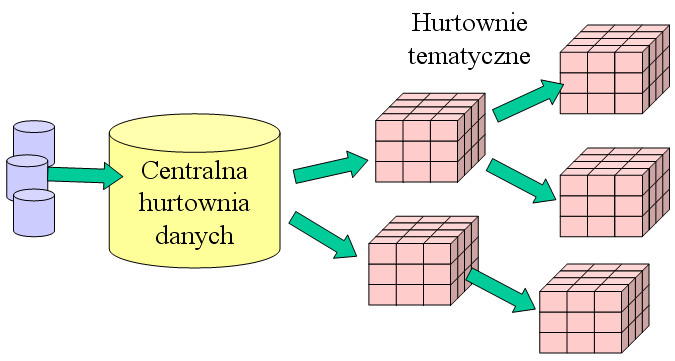
Architektura warstwowa to odmiana jednej z
poprzednich dwóch architektur, w których budujemy wiele warstw hurtowni
tematycznych zawierających coraz wyższe stopnie agregacji danych. Dane z
kolejnych warstw są obliczane na podstawie poprzednich. Ze względu na
wydajność, wszystkie warstwy są zmaterializowane. Zaletą odpowiednio
zaprojektowanej architektury warstwowej jest optymalizacja wielkości danych w
hurtowniach tematycznych (możliwość szybkiego obliczenia mniej szczegółowych
zestawień, przy jednoczesnym pozostawieniu możliwości sięgnięcia po bardziej
szczegółowe, ale również zagregowane, dane w poprzedniej warstwie), a także skrócenie
czasu aktualizacji (dzięki większemu rozproszeniu obliczeń i unikaniu
redundancji).
Struktura logiczna poszczególnych elementów hurtowni
Centralna hurtownia danych projektowana jest jak zwykła baza danych.
Elementem wyjściowym są dane, które mamy przechowywać - ich schemat logiczny
(podział na tablice itp.) może odzwierciedlać strukturę danych źródłowych, o
ile jest ona jednolita. Jeśli nie, dane muszą podlegać integracji pojęciowej i
logicznej (por. następny wykład), by mogły znaleźć się w centralnej hurtowni
danych. Ponadto często musimy dane wzbogacić o dodatkowe elementy logiczne
związane z osługą hurtowni danych. Często jest to dodatkowa kolumna, wskazująca
datę wprowadzenia danego rekordu do hurtowni danych. Dodatkowe struktury
dotyczące czasu i zmian danych w czasie bywają rozbudowane - por. problem
retrospekcji opisany w następnym rozdziale.
Hurtownie tematyczne projektowane są pod kątem zadań OLAP. W systemach typu
ROLAP (relational OLAP) dominują schematy logiczne zwane modelem gwiazdy lub
płatka śniegu. W przypadku implementacji czysto wielowymiarowej (MDDB) modele
te mogą nie być jawnie dostępne, jednak nadal dobrze jest myśleć o nich jako o
źródle danych dla kostek wielowymiarowych.
Przypomnijmy podstawowe terminy dotyczące danych wielowymiarowych:
- Fakt - pojedyncze zdarzenie będące
podstawą analiz (np. sprzedaż). Fakty opisane są przez wymiary i miary.
- Wymiar - cecha opisująca dany fakt,
pozwalająca powiązać go z innymi pojęciami modelu przedsiębiorstwa (np.
klient, data, miejsce, produkt). Wymiary są opisane atrybutami.
- Atrybut - cecha wymiaru, przechowująca
dodatkowe informacje na temat faktu (np. wymiar data może mieć atrybuty:
miesiąc, kwartał, rok; wymiar klient może mieć atrybuty: nazwisko, region
zmieszkania).
- Miara - wartość liczbowa przyporządkowana
do danego faktu (np. wartość sprzedaży, liczba sztuk).
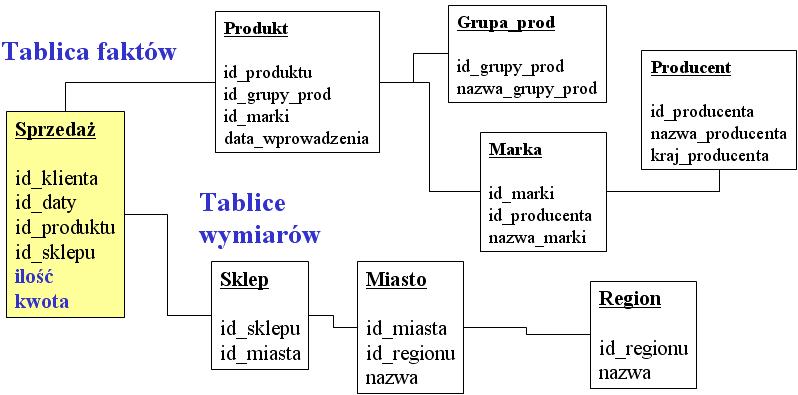
Model gwiazdy wygląda następująco:
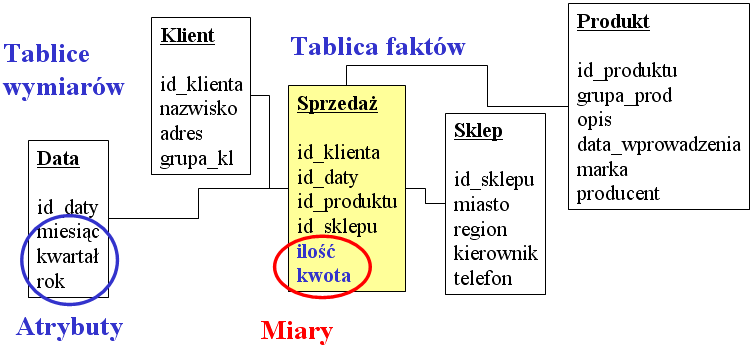
Centralna tablica faktów zawiera rekordy oznaczające poszczególne fakty
podlegające analizom i podsumowaniom. Wokół tej centralnej tablicy znajdują się
(zwykle znacznie mniejsze) tablice opisujące poszczególne wymiary. Atrybuty
wymiarów to kolumny tablic wymiarów, natomiast tablica faktów zasadniczo
zawiera tylko miary faktów (czyli wielkości podlegające podsumowaniom) i klucze
do tablic wymiarów.
Z zasady tablica faktów jest największa (miliony rekordów) i szybko
przyrastająca, natomiast tablice wymiarów podlegają niewielkim zmianom. Są to
zwykle przyrosty danych; w przypadku konieczności zmiany opisu elementu danego
wymiaru stosujemy zasady retrospekcji - por. następny rozdział. Warto zauważyć,
że czas to również wymiar wyrażony tablicą. Tablica zawierająca kolejne dni z
kalendarza może wydawać się mało użyteczna, ale często ułatwia budowę hurtowni
i zapewnia przejrzystość schematu. Ponadto pozwala na nadawanie własnych
atrybutów poszczególnym dniom (np. dzień wolny od pracy w danej instytucji).
Normalizacja schematu gwiazdy poprzez modelowanie atrybutów za pomocą
kolejnych tablic prowadzi do modelu płatka śniegu. Model płatka śniegu odtwarza
hierarchię wymiarów, czyli sytuację, w której pewien
wymiar ma wiele różnych poziomów szczegółowości. Np. wymiar "produkt"
może mieć atrybut "producent", modelowany oddzielną tablicą, a
równolegle - atrybut "grupa produktów", również modelowany tablicą.
Projektowanie
hurtowni - model punktowy
Modelowanie wielowymiarowe danych (gwiazda, płatek śniegu) wykonywane jest
w celu dokonywania analiz typu OLAP. Projektując tę część hurtowni danych, warto
zastanowić się nad uzasadnieniem biznesowym tworzenia hurtowni tematycznych. Przykładowe (zakładane)
efekty i środki do ich uzyskania to:
- Wzrost sprzedaży, zwiększenie udziału
w rynku, zmniejszenie odsetka odchodzących klientów.
- Środek: analiza zachowania klientów,
lokalizacja słabych punktów, śledzenie trendów.
- Narzędzie: analiza gromadzonych w
hurtowni (zintegrowanych i oczyszczonych) danych, budowa hurtowni
tematycznej. To ostatnie zadanie polega również na maksymalnym
ograniczeniu ilości danych w hurtowni tematycznej (ze względu na szybkość
wykonywania obliczeń i ograniczenia techniczne i finansowe).
Projektując hurtownię tematyczną, dokonujemy najpierw pojęciowego
modelowania potrzeb analityków, by następnie wybrać odpowiednią część
centralnej hurtowni danych i zaprojektować proces tworzenia i aktualizacji
hurtowni tematycznej. Model pojęciowy odzwierciedla związki między pojęciami
związanymi z działalnością przedsiębiorstwa, np.:
- Kto to jest „klient” i co o nim
wiemy?
- Jak opisywana jest sprzedaż w różnych
oddziałach firmy?
- Co pod pojęciem „fakt sprzedaży”
chciałby rozumieć analityk?
- Jaki model wielowymiarowy danych może
nam pomóc w tworzeniu raportów biznesowych?
Przykładowa technika modelowania pojęciowego hurtowni tematycznej to modelowanie punktowe. Informacje na temat pojęć, do których dostęp ma analityk, przedstawiane
są w postaci diagramu, gdzie:
- Fakty reprezentowane są
punktami
- Wymiary reprezentowane są przez
nazwy
- Podobnie reprezentujemy kolejne
poziomy hierarchii
- Model może obejmować wiele (konstelację)
faktów, korzystających częściowo ze wspólnej hierarchii wymiarów
W modelu punktowym zapisujemy ponadto obok informacje na temat m.in.:
- Nazw atrybutów
- Typów danych
- Więzów integralności
- Retrospekcji (zmienności wartości
atrybutów w czasie)
- Częstości odświeżania
- Pochodzenia danych (źródło,
transformacje)
- Metadanych biznesowych (opis w języku
naturalnym lub sformalizowanym)
Retrospekcja to pojęcie dotyczące sposobu
traktowania zmian w danych. Przypomnijmy, że hurtownia danych z założenia ma charakter
nieulotny, tzn. informacja, która do niej trafi, nie powinna być usuwana ani
zmieniana. Źródła danych jednak są zmienne w czasie i może się zdarzyć, że
zachodzi konieczność zmiany informacji (np. o adresie zamieszkania klienta). W
zależności od sposobu traktowania takich zmian, retrospekcja może być:
- „prawdziwa” – zapisujemy wszelkie
zmiany wartości wraz z dokładnym czasem ich dokonania,
- „fałszywa” – nowe wartości rekordów
zastępują stare,
- „trwała” – nie przewidujemy zmiany
wartości.
Teoretycznie wszystkie dane powinny podlegać retrospekcji prawdziwej.
Prowadzi to jednak do znacznych utrudnień technicznych: proste zapytania stają
się skomplikowane, gdyż muszą uwzględnić informacje z tabel pomocniczych
zapisujących historię zmian. Z drugiej strony, fałszywa retrospekcja może nam
zaburzyć wyniki analiz. Jeśli np. analizujemy obroty klientów w zależności od
ich adresu zamieszkania, to przeprowadzka danego klienta spowoduje nagłe
przypisanie wszystkich jego transakcji do nowego miejsca zamieszkania (co jest
nieprawdą).
Literatura
- Ch. Todman. Projektowanie hurtowni
danych. WNT,
Warszawa 2003.
- M. Jarke, M. Lenzerini, Y.
Vassiliou, P. Vassiliadis. Hurtownie danych. Podstawa organizacji i funkcjonowania. WSiP, Warszawa 2003.
- V. Poe, P. Klauer, S. Brobst. Tworzenie
hurtowni danych. WNT, Warszawa 2000.
Strona przygotowana
przez Jakuba Wróblewskiego, 2006.
Modyfikacje dokonane
przez Dominika Ślęzaka, 2008/09.