5. Problem z fałszywym wiązaniem
Jeżeli język zapytań nie ma kontroli typów, nieobecne obiekty w połączeniu z pełną ortogonalnością języka (nieograniczoną możliwością zagnieżdżania zapytań) prowadzą do błędu semantycznego powstającego w wyniku fałszywego wiązania. Rozpatrzmy zapytanie:
| P12.16. | Podaj pracowników zarabiających tyle samo co Nowak: |
Interesuje nas wiązanie drugiej występującej w tym zapytaniu nazwy Zar, w sytuacji, gdy obiekt Nowaka nie posiada takiego atrybutu. Wiązanie powinno zwrócić pusty zbiór, co spowoduje błąd wykonania. Rys. 68 pokazuje sytuację na stosie środowiskowym podczas wiązania tej nazwy, jeżeli pierwszy operator where działa na obiekcie Kowalskiego, w którym atrybut Zar występuje.
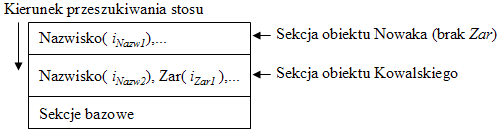
Rys.68. Sytuacja na stosie ENVS podczas wiązania nazwy Zar
Jak widać, wbrew naszym założeniom druga nazwa Zar zostanie związana, ale do zarobku Kowalskiego, a nie Nowaka. W efekcie, zapytanie nie wykaże błędu wykonania i zwróci referencje do wszystkich obiektów pracowników posiadających atrybut Zar. Wynik ten jest oczywiście błędny.
Przyczyną jest to, że w zapytaniu i w całym mechanizmie stosu nie ma informacji o tym, do którego bindera Zar ma być wiązana występująca w zapytaniu druga nazwa Zar. Uniknięcie tego błędu zmusza do jednego z następujących rozwiązań:
- Zabronienie zagnieżdżania zapytań. Rozwiązanie jest sprzeczne z całą ideą podejścia stosowego.
- Ustalenie bardziej rygorystycznej reguły wiązania, np. po operatorze kropki wiązanie następuje wyłącznie na wierzchołku stosu. Dla większości zapytań rozwiązanie to jest akceptowalne, ale spora część zapytań stanie się niewyrażalna.
- Rozwiązanie to nie daje oczywiście gwarancji, że podobny błąd nie wystąpi dla innego operatora niealgebraicznego.
- Doprowadzenie wiedzy programistów do stanu, w którym są oni w pełni świadomi, że mogą popełnić taki błąd i wobec tego zmuszanie ich do sformułowania tego zapytania tak, aby ten błąd nie mógł wystąpić. Np. inne (poprawne w każdym przypadku) sformułowanie tego zapytania jest następujące:
| P12.17. | (Prac where Nazwisko = "Nowak").(Zar as x). |
Jeżeli Nowak nie ma określonego zarobku, to powyższe zapytanie zwróci pusty wynik. Powyższe założenie jest jednak nieakceptowalne ze względów ergonomicznych, gdyż zmusza programistów do zbyt drobiazgowej analizy formalnej semantyki każdego zapytania.
- Określenie typów dla wszystkich obiektów i następnie połączenie mechanizmu wiązania z przechowywaną informacją o typie. Dzięki temu można będzie wnioskować, że wprawdzie w danym obiekcie Zar nie występuje, ale w typie tego obiektu jest to opcyjne, zatem będziemy jednak wiązać Zar w tym obiekcie, co oczywiście da poprawny wynik w postaci pustego zbioru.
- Skorzystanie z rozwiązania opartego na wartościach domyślnych przechowywanych w ramach klas (patrz następna sekcja).
Tylko dwa ostatnie rozwiązania są akceptowalne. Radykalnym rozwiązaniem jest zastosowanie typów obiektów. Technicznie można to zrobić na wiele sposobów. Np. można zmodyfikować funkcję nested w taki sposób, aby dla danej referencji i zwracała (jak zwykle) bindery do wnętrza obiektu i, ale potem sprawdzała jeszcze typ obiektu i. Jeżeli ten typ przewidywałby opcyjną daną
o nazwie n, której w danym obiekcie nie ma, funkcja zwracała dodatkowo binder n(Æ), z wartością będącą zbiorem pustym. W ten sposób nieobecny podobiekt o nazwie n byłby reprezentowany we właściwej mu sekcji na stosie środowiskowym przez binder n(Æ). Nie byłoby zatem fałszywego wiązania, zaś wynik wiązania nazwy n zwróciłby zbiór pusty.
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.