6. Wartości domyślne
Wartości domyślne (default values) zostały zaproponowane przez Ch.Date [Date86] jako alternatywa dla wartości zerowych, przy czym w założeniu miały one być wpisywane fizycznie do relacyjnych tabel. Jest to dobre rozwiązanie w większości przypadków, ale ma także wady. Mogą być typy, dla których nie znajdziemy żadnej dobrej wartości zastępującej wartość zerową. Np. jeżeli jedna liczba reprezentowałaby bilans naszych rocznych dochodów i wydatków (ujemne liczby dla reprezentacji ujemnego bilansu), wówczas żadna z wartości nie mogłaby reprezentować faktu, że stan bilansu jest nieznany. Ponadto pojawia się problem np. z funkcjami agregowanymi, które wartości domyślne potraktują jak normalne wartości dając (przy braku dostatecznej uwagi ze strony programisty) błędny wynik. Wartości domyślne mogą mieć także inne zastosowania, np. mogą stanowić początkowe wartości przy tworzeniu obiektów lub mogą być typowymi wartościami, które tylko w wyjątkowych przypadkach będą zmieniane.
Modele składu obiektów M1-M3 pozwalają na inne potraktowanie wartości domyślnych, mianowicie przechowywanie ich jako inwariantów obiektów w ramach klas. Jeżeli dla każdego atrybutu o nazwie n danego obiektu klasa zawierałaby podobiekt z tą samą nazwą, to reguły zarządzania stosem spowodują, że jeżeli atrybut o nazwie n nie wystąpi w przetwarzanym obiekcie, to n zostanie związane do podobiektu z nazwą n występującego w jego klasie. Wartością takiego podobiektu mógłby być zbiór pusty, co rozwiązuje problem z fałszywym wiązaniem poruszony w poprzedniej sekcji.
Na Rys.69 pokazaliśmy sytuacje na stosie (patrz Rys.61) w momencie wiązania nazwy Zar i RokUr w zapytaniu
| P12.18. | (Prac where Nazwisko = "Nowak").(Zar, RokUr) |
W stosunku do Rys.61 przyjęliśmy tu, że atrybuty Zar i RokUr są opcyjne, wobec czego odpowiednie klasy zawierają dla nich wartości domyślne: klasa Prac zawiera wartość domyślną w postaci pustego zbioru dla nazwy Zar, zaś klasa Osoba zawiera wartość domyślną 1900 dla nazwy RokUr. Na samej górze znajdują się bindery do wnętrza przetwarzanego obiektu Nowaka, wśród których nie ma bindera dla Zar. Wobec tego ta nazwa nie będzie związana w górnej sekcji stosu, lecz odpowiedni binder zostanie wykryty niżej, w sekcji klasy Prac. Wiązanie Zar zwróci zatem pusty zbiór, zgodnie z przyjętą semantyką. Przy wiązaniu nazwy RokUr odpowiedni binder jest tym razem na czubku stosu, wobec czego binder z nazwą RokUr w sekcji klasy Osoba nie będzie użyty; stanowi tylko zabezpieczenie przed niepotrzebnym przeszukiwaniem stosu w sytuacji, gdy dla pewnego obiektu atrybut RokUr nie występuje. Wartości domyślne wstawione w ten sposób jako inwarianty do odpowiednich klas majęą więc podwójną rolę: podstawienia odpowiedniej wartości w przypadku nieobecności pewnego podobiektu oraz zapobieganie fałszywemu wiązaniu.
Zwrócimy uwagę na niuanse semantyczne związane z wartościami domyślnymi. Można zauważyć, że binder taki jak Zar(Æ) pojawił się na stosie nieco wbrew objaśnianym dotąd regułom. Mianowicie, wewnątrz klasy Prac powinien być przechowywany obiekt o postaci <izar, Zar, Æ> i zgodnie z dotychczas określoną definicją funkcji nested, na stosie powinien pojawić się binder Zar(izar) raczej niż Zar(Æ). Binder Zar(izar) nie spełniałby jednak wymaganej przez tę własność roli. Sugerujemy więc, aby obiekty przechowujące wartości domyślne w klasach były dekorowane specjalną flagą, umożliwiającą wymaganą zmianę funkcji nested. Ta zmiana oznaczałaby jednak, że takich obiektów nie można byłoby aktualizować poprzez język zapytań. Wartości domyślne, jak wszystkie wartości, mogą podlegać działaniom administracyjnym, np. usuwaniu lub zmianie. Zatem system, oprócz wspomnianej flagi, musiałby rozróżniać intencje i/lub uprawnienia użytkowników: np. intencja "administracyjna" oznaczałaby normalne działanie funkcji nested, zaś intencja "aplikacyjna" oznaczałaby nieco zmienione działanie funkcji nested, w którym funkcja ta dokonuje automatycznie dereferencji.
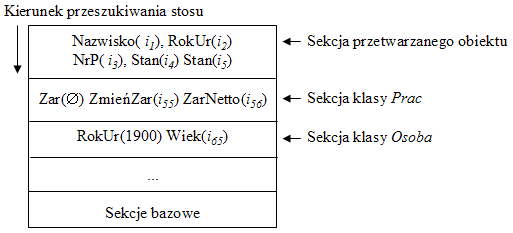
Rys.69. Wartości domyślne umieszczone w klasach
Kolejne niuanse semantyczne dotyczą operacji aktualizacyjnych: podstawienia, usuwania i wstawiania. Jak poprzednio, aby umożliwić takie operacje na wartościach domyślnych, potrzebne będzie rozróżnienie intencji na administracyjną i aplikacyjną. Przy intencji administracyjnej działania te dotyczyłyby samych wartości domyślnych i działałyby na ich referencjach i wartościach. Przy intencji aplikacyjnej aktualizacje wartości domyślnych byłyby niedozwolone albo miałyby inną semantykę. Np. podstawienie na RokUr wartości 1951 w sytuacji, gdy dany obiekt nie posiada takiego atrybutu, nie może być wykonane jako klasyczna operacja podstawienia, lecz oznaczałoby wstawienie do obiektu nowego atrybutu <inowy, RokUr, 1951>, z nowym identyfikatorem. Podobnie z innymi operacjami. Nie jest jednak pewne, czy takie operacje byłyby całkowicie przezroczyste dla użytkowników we wszystkich sytuacjach i czy nie zwiększałyby skłonności do błędów.
Objaśniona przez nas metoda automatycznie jest przystosowana do wartości domyślnych, które są obiektami złożonymi. Jest również przystosowana do wartości domyślnych w postaci rezultatów wywoływanych funkcji. W tym przypadku wartością domyślną dla nieobecnego atrybutu o nazwie atr jest metoda (jej wywołanie) o nazwie atr. Wartość domyślna może więc być nie tylko wpisana przez projektanta bazy danych lub administratora, ale może być także dynamicznie wyliczona.
Kolejna uwaga dotyczy modelu M3, który dzieli własności klas i obiektów na publiczne i prywatne. Własności prywatne danej klasy i obiektów tej klasy mogą być używane wyłącznie przez ciała metod zdefiniowanych w tejże klasie. Przy wywołaniu metody m wierzchołek ENVS powinien mieć następujące sekcje:
- Najwyżej: lokalną sekcję metody m, czyli jej zapis aktywacyjny;
- Poniżej: własności prywatne klasy, do której metoda m należy;
- Poniżej: własności prywatne i publiczne aktualnie przetwarzanego obiektu;
- Poniżej: własności publiczne klasy, do której należy metoda m i przetwarzany obiekt;
- Poniżej: własności publiczne nadklas, w odpowiedniej kolejności;
- ... dalej jak zwykle;
Wartości domyślne są oczywiście publiczne. To gwarantuje, że wewnątrz ciała metody wartości domyślne nie przesłonią rzeczywistych wartości wpisanych explicite do obiektu.
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.