2. Procedury w SBQL
Przyjmiemy następującą składnię deklaracji procedury (nie uwzględniającą kontroli typologicznej):
procedura ::= procedure nazwaProc( ){instrukcje}
procedura ::= procedure nazwaProc ( parFormalne){instrukcje}
nazwaProc ::= nazwa
parFormalne ::= parFormalny | parFormalny; parFormalne
parFormalny ::= nazwa |in nazwa | out nazwa
instrukcja ::= return [zapytanie]
Wywołanie procedury:
zapytanie ::= nazwaProc | nazwaProc( ) | nazwaProc ( parAktualne )
parAktualne ::= parAktualny | parAktualny ; parAktualne
parAktualny ::= zapytanie
Semantyka:
Jak widać z powyższej składni, nie rozróżniamy procedur właściwych i procedur funkcyjnych. Procedura funkcyjna musi zawierać wewnątrz instrukcję return, z parametrem będącym zapytaniem. Instrukcja ta kończy działanie procedury. Taka procedura może być wywołana jako zapytanie. Jeżeli procedura funkcyjna jest wywołana jako instrukcja (poza zapytaniem), wówczas zwracany przez nią wynik jest ignorowany (jest kasowany ze stosu QRES). Jeżeli napotkana instrukcja return nie ma parametru w postaci zapytania, to jej wykonanie kończy działanie procedury, ale nic nie zwraca (wobec czego nie jest procedurą funkcyjną).
Przyjęliśmy, że formalne parametry procedury mogą być pozbawione kwalifikatora; wówczas oznacza to ścisłe wołanie przez wartość (strict-call-by-value). Kwalifikator in oznacza zwykłe wołanie przez wartość, zaś kwalifikator out oznacza wołanie przez referencję. Semantyka tych metod transmisji parametrów zostanie objaśniona nieco dalej.
Procedura jest bytem ponownego użycia, zatem istotne jest, jak i gdzie będzie zapamiętana. Ta cecha może być elementem języka programowania, ale wtedy odpowiednia instrukcja tworzenia procedury będzie miała jej źródłowy tekst jako parametr. Częstszym rozwiązaniem jest uwzględnienie deklaracji procedury w środowisku rozwoju oprogramowania. Miejsce ulokowania procedury wynika wtedy z innych czynników, np. miejscem jest moduł lub klasa, jeżeli dana procedura jest składową kodu źródłowego tego modułu lub klasy.
Ponieważ w przypadku baz danych procedury są bytami pierwszej kategorii programistycznej, mogą być potrzebne specjalne udogodnienia administracyjne dla ich tworzenia, wstawiania w odpowiednie miejsce składu obiektów, kompilowania, usuwania, zabezpieczania, optymalizacji itd. W tym zakresie możliwe jest wiele rozwiązań. W tym wykładzie nie zajmujemy się specyfikacją środowiska rozwoju oprogramowania i środowiska administracyjnego, zatem ten temat jest dla nas uboczny. Nie wydaje się trudny od strony koncepcyjnej. W systemie Loqis przyjęliśmy, że procedury są składowymi modułów źródłowych lub klas, które po kompilacji stają się modułami lub klasami bazy danych. Procedury takie mogą być przenoszone pomiędzy modułami lub klasami poprzez instrukcję insert.
Procedurę można zapamiętać w dowolnym środowisku składu obiektów, w szczególności:
- W bazie danych po stronie serwera na najwyższym poziomie hierarchii obiektów.
- W środowisku lokalnym sesji użytkownika, po stronie klienta, czyli programu aplikacyjnego i środowiska jego wykonania.
- Wewnątrz dowolnego obiektu, w szczególności, modułu bazy danych, o ile takie pojęcie będzie wprowadzone.
- Wewnątrz klasy, zarówno umieszczonej po stronie serwera bazy danych, jak i po stronie aplikacji klienta. Umieszczenie procedury wewnątrz klasy powoduje, że staje się tym, co powszechnie jest określane w obiektowości jako "metoda".
- Wewnątrz specjalnej biblioteki procedur po stronie serwera lub pewnej struktury takich bibliotek.
Zależnie od miejsca umieszczenia procedur w składzie, bindery zawierające referencje do procedur i ich nazwy muszą być umieszczone w odpowiednich sekcjach stosu ENVS. W ten sposób nazwy procedur będą dostępne dla wiązania. Semantyka wywołania procedury jest następująca:
- Najpierw wiąże się jej nazwę występującą w zapytaniu/programie na stosie ENVS. Wynikiem wiązania jest referencja do procedury.
- Po związaniu nazwy następuje automatyczne uruchomienie procedury, czego skutkiem jest pojawienie się na stosie ENVS nowej sekcji z binderami (zwanej zapisem aktywacyjnym). Zapis aktywacyjny zawiera trzy rodzaje bytów:
- bindery aktualnych parametrów procedury (zostaną objaśnione dalej);
- bindery do lokalnych obiektów procedury;
- ślad powrotu, umożliwiający przekazanie sterowania do kodu wywołującego procedurę po zakończeniu jej działania. Ślad ten w tym kroku jest wstawiany do zapisu aktywacyjnego.
- bindery aktualnych parametrów procedury (zostaną objaśnione dalej);
- Jeżeli procedura była umieszczona wewnątrz klasy (tj. była metodą), to poniżej zapisu aktywacyjnego umieszcza się sekcję z binderami do wszystkich prywatnych własności tej klasy. Zwrócimy uwagę, że nie umieszcza się tam binderów do własności publicznych, gdyż spowodowałoby to pewien konflikt nazw (który dalej będzie objaśniony).
- Następuje ewaluacja zapytań będących parametrami procedury; wynik tej ewaluacji znajduje się na stosie QRES.
- Po ewaluacji parametrów tworzy się z nich bindery (i ewentualnie obiekty) i wstawia do sekcji ENVS zawierającej zapis aktywacyjny procedury. Parametry te usuwa się ze stosu QRES.
- Jeżeli procedura miała zadeklarowane obiekty, to są one tworzone w składzie, zaś ich bindery są umieszczone wewnątrz zapisu aktywacyjnego.
- Sterowanie jest przekazywane do ciała procedury, w tym ewentualnie do zapytań i podstawień inicjujących wartości zadeklarowanych obiektów.
- Wiązanie wszystkich nazw wewnątrz ciała procedury odbywa się na stosie ENVS, ale wszystkie sekcje procedur, które wywołały bezpośrednio lub pośrednio daną procedurę (wraz z towarzyszącymi im sekcjami obiektów, zapytań, klas itd.) są niedostępne dla wiązania. Widoczne są tylko sekcje związane z dana procedurą oraz sekcje bazowe stosu (bazy danych, sesji użytkownika itd.).
- Jeżeli sterowanie osiągnie końcowy nawias ciała procedury lub napotka instrukcję return, to procedura kończy swoje działanie. Jeżeli instrukcja return miała parametr w postaci zapytanie, to ewaluuje się je w środowisku tej procedury, jak zwykle. Wynik, jak zwykle, znajdzie się na wierzchołku QRES jako wynik działania procedury funkcyjnej.
- Zakończenie działania procedury oznacza zdjęcie ze stosu wszystkich sekcji, które były tam włożone w momencie jej startu, ewentualne usunięcie zadeklarowanych lub utworzonych lokalnych obiektów oraz powrót sterowania do programu wywołującego, zgodnie z zapamiętanym w zapisie aktywacyjnym śladem powrotu.
| P14.1. | Procedura ZmieńDział zmienia dział dla pracowników komunikowanych jako parametr P na dział komunikowany jako parametr D.
|
| P14.2. | Procedura funkcyjna MałoZarabiający zwraca nazwisko, zarobek
i nazwę działu dla pracowników określonych stanowisk zarabiających mniej niż średnia. Wynik jest strukturą z nazwami N, Z, D.
|
2.1. Procedury funkcyjne a perspektywy
| P14.3. | Procedura BogatyPrac zwraca informacje o pracownikach, który zarabiają brutto co najmniej 3000. Informacja zawiera nazwisko pracownika jako Nazwisko, nazwisko jego szefa jako Szef oraz zarobek netto jako Zarobek. |
Procedura BogatyPrac została użyta w taki sposób, że użytkownik może rozumieć nazwę BogatyPrac jako nazwę obiektów posiadających trzy atrybuty: Nazwisko, Szef i Zarobek. Są to obiekty "wirtualne", istniejące w postaci definicji (i w wyobraźni programisty), ale nieobecne w składzie danych. Procedura BogatyPrac przypomina więc pojęcie z baz danych znane jako perspektywa (view).
W istocie, jeżeli pominąć różnice składniowe, specjalną terminologię, różnorodne ograniczenia i drugorzędne opcje, to wszystkie znane autorowi propozycje dotyczące perspektyw, włączając perspektywy w SQL, są po prostu procedurami funkcyjnymi zapamiętanymi w bazie danych (z zastrzeżeniem dotyczącym aktualizacji perspektyw, o którym dalej). Ten fakt został dawno rozpoznany przez niektórych autorów (m.in. przez M.Atkinsona i P.Bunemana [Atki87]), ale wydaje się, że do dzisiaj nie dotarł do powszechnej świadomości społeczności baz danych.
Przyjęcie założenia, że zdefiniowane przez nas procedury funkcyjne są znanymi z baz danych perspektywami, ma szereg pozytywnych konsekwencji:
- Moc obliczeniowa i moc pragmatyczna takich perspektyw jest nieograniczona. Ponieważ w perspektywach SQL ciało jest ograniczone do pojedynczego zapytania, moc ich jest ograniczona ze względu na obliczeniową i pragmatyczną niekompletność SQL. W naszym przypadku funkcja będąca perspektywą może mieć dowolnie złożone wnętrze, może korzystać z efektów ubocznych, może wywoływać inne funkcje itd.
- Semantyka oparta na stosie środowiskowym jest w pełni przygotowana do perspektyw rekurencyjnych.
- Perspektywy mogą posiadać parametry w postaci dowolnych zapytań, komunikowanych dowolną techniką (patrz przykład P14.2).
- Nie ma potrzeby podziału perspektyw na "zachowujące obiekty" (object preserving) i "generujących obiekty" (object generating). Podział ten jest konsekwencją powierzchownych podejść do semantyki języków zapytań
i perspektyw. Będziemy stać na stanowisku, że wirtualne obiekty istnieją wyłącznie w wyobraźni programisty, wobec czego jest rzeczą drugorzędną, czy mają one identyfikatory i jakie. Istotne jest to, aby we wszystkich manipulacjach na wirtualnych obiektach programista nie dostrzegał syntaktycznych i pragmatycznych różnic z manipulacjami na rzeczywistych obiektach. W zakresie operacji wyszukiwawczych funkcje SBQL spełniają ten warunek w 100%.
- Wirtualne obiekty są automatycznie podłączone do klas, o ile funkcja zwróci referencje do obiektów tych klas.
- Automatycznie dostarczone są środki do aktualizacji perspektyw, gdyż procedury mogą zwrócić referencje do obiektów, atrybutów itd.
Ostatni punkt wymaga dłuższej dyskusji. Uznaliśmy za konieczne wyraźne rozróżnienie pomiędzy procedurą funkcyjną a perspektywą; perspektywom poświęcimy następny rozdział. Zgodnie z tym rozróżnieniem, perspektywy znane z SQL są funkcjami, ale nie są perspektywami, gdyż nie zapewniają przezroczystości operacji aktualizacyjnych. Podobnie z prawie wszystkimi innymi podejściami do perspektyw, w tym perspektyw obiektowych: w istocie, ich autorzy definiują pewną odmianę procedur funkcyjnych raczej niż perspektyw. Nie jest to wyłącznie sprawa terminologii, gdyż wymóg przezroczystości (transparency) jest podstawowy dla pojęcia perspektywy. Oznacza on, że programista aplikacyjny nie jest w stanie odróżnić - w jakikolwiek sposób - czy ma do czynienia z obiektem rzeczywistym, czy też z wirtualnym. Ten wymóg jest m.in. podstawą zarządzania obiektami w standardzie CORBA. Prawie wszystkie podejścia do perspektyw, włączając perspektywy w SQL, tego wymogu nie spełniają w zakresie aktualizacji perspektyw. Istnieje, jak dotąd, tylko jeden zaimplementowany wyjątek: perspektywy definiowane poprzez instead of trigger systemów Oracle i SQL Server.
Dotychczasowy wysiłek badawczy związany z aktualizacją witalnych perspektyw dotyczył dodatkowych ograniczeń na definicje perspektyw i ich aktualizacje, aby zapobiec anomaliom aktualizacyjnym. W przypadku perspektyw obiektowych te ograniczenia są tak silne, że praktycznie nie zezwalają na tworzenie cokolwiek bardziej skomplikowanych perspektyw, co oczywiście silnie zawęża zakres ich stosowalności. Będziemy trzymać się stanowiska, że całość bogatej literatury dotyczącej tego problemu dotyczy rozwiązywania problemu zastępczego (jak ograniczyć aktualizację), a nie problemu zasadniczego (jak zrobić całkowicie przezroczystą perspektywę). Z naszego punktu widzenia, cała ta licząca setki pozycji literatura jest więc praktycznie bezwartościowa.
W tym wykładzie przyjmiemy następującą filozofię. Jeżeli programista lub projektant definiuje funkcję, to powinien być w pełni świadomy, że jest to funkcja, a nie perspektywa. Jeżeli mimo tej świadomości decyduje się na aktualizację poprzez referencje zwracane przez tę funkcję (tak jak w przykładzie P14.2.), to wolno mu to zrobić, ale ponosi za to pełną odpowiedzialność. Wszelkie ograniczanie jego swobody w tym zakresie będziemy uważać za niewłaściwe. Nie dopuszczamy w tym względzie żadnych protez, w rodzaju opcji sprawdzania (check option), niezezwalania na aktualizację po stronie klucza głównego perspektyw powstałych poprzez złączenie lub innych ograniczeń (znanych m.in. z systemu Oracle). Wszystkie te ograniczenia mają przybliżyć pojęcie procedury funkcyjnej do pojęcia perspektywy, ale naszym zdaniem to się nigdy w pełni nie uda, wobec czego na tym nam nie zależy. Zależy nam na prostocie pojęcia funkcji, a wszelkie dodatkowe ograniczenia temu nie służą.
Jeżeli programista lub projektant chce, aby funkcja była rzeczywiście perspektywą o pełnych walorach przezroczystości, wówczas musi stworzyć taką perspektywę explicite, według koncepcji opisanej w następnym rozdziale. Koncepcja ta rozwiązuje problem aktualizacji perspektyw. Perspektywa jest jednak bytem odmiennym i znacznie bardziej wyrafinowanym semantycznie w stosunku do procedury funkcyjnej. Definicja takich perspektyw nie odwołuje się do aktualizacji przez jakiekolwiek efekty uboczne, m.in. przez referencje zwrócone przez procedurę funkcyjną, jak w przykładzie P14.2. Aktualizacja poprzez efekty uboczne jest więc zabroniona, natomiast programista dostaje do ręki inne środki, za pomocą których będzie w stanie precyzyjnie określić semantykę aktualizacji.
2.2. Metody w SBQL
Metoda jest procedurą umieszczoną wewnątrz klasy i traktowaną jako inwariant obiektów będących członkami tej klasy. Metoda w SBQL jest zawsze wywoływana w kontekście obiektu, na którym działa; ten kontekst jest określony poprzez umieszczenie binderów do własności obiektu na stosie ENVS i następnie wywołanie metody. Moglibyśmy oczywiście zróżnicować syntaktycznie procedury i metody, ale ze względu na brak istotnych różnic semantycznych w tym wykładzie uznaliśmy, że nie warto tego robić.
| P14.4. | Metoda ZarobekNetto umieszczona wewnątrz klasy Pracownik zwraca zarobek netto dla pracownika, obliczając go według pewnej formuły (patrz Rys.55): |
W przykładzie wykorzystaliśmy nazwę self zwracającą referencję do aktualnie przetwarzanego obiektu. Tego rodzaju predefinowana nazwa (self, this, itp.) występuje w większości obiektowych języków programowania. W naszym przypadku nie jest niezbędna. Z technicznego punktu widzenia, wszystkie bindery do wewnętrznych własności przetwarzanego obiektu znajdują się w odpowiedniej sekcji ENVS, zatem poprawna jest również następująca postać powyższej procedury:
| P14.5. | procedure ZarNetto { |
Niemniej istnieją powody, dla których taką nazwę warto wprowadzić. Jednym z nich jest modelowanie pojęciowe: nazwa self pozwala programiście widzieć wyraźnie w kodzie metody wszystkie odwołania do przetwarzanego obiektu. Drugim powodem jest to, że w niektórych sytuacjach (np. porównanie referencji) referencja do przetwarzanego obiektu ułatwia napisanie metody.
Z drugiej strony, jak zwykle w przypadku predefiniowanych nazw, w niektórych sytuacjach predefinowana nazwa self może prowadzić do niejednoznaczności i wymagać większej uwagi od programisty, szczególnie w przypadku zmian już napisanego kodu.
Proponowany przez nas sposób wprowadzenia predefinowanej nazwy self jest dość oczywisty i ma tylko pośredni związek z samym tematem metod w SBQL. Taka nazwa mogłaby się przydać również w innych kontekstach. Nazwę self wprowadzimy poprzez poprawienie funkcji nested. Jeżeli argumentem tej funkcji jest pojedyncza referencja r do obiektu, który jest podłączony do klasy, to wynik tej funkcji, oprócz binderów do podobiektów tego obiektu, zawierać będzie binder self(r). Przyjmując to założenie, sytuacja na stosie ENVS w momencie przetwarzania ciała metody ZarNetto dla obiektu Nowaka posiadającego identyfikator i4 jest przedstawiona na Rys.73. Zwrócimy uwagę na pojawienie się w sekcji przetwarzanego obiektu bindera self(i4).
Do rozważenia jest również sytuacja, gdy ciało metody widzi wyłącznie binder self, zaś bindery do wnętrza przetwarzanego obiektu są dla metod przesłonięte. Oznaczałoby to, że dostęp do wszelkich własności przetwarzanego obiektu następowałby wyłącznie poprzez nazwę self.
Zwrócimy uwagę, że w modelu składu M3 dostęp do prywatnych własności danej klasy następuje wyłącznie w momencie wywołania metody tej klasy.
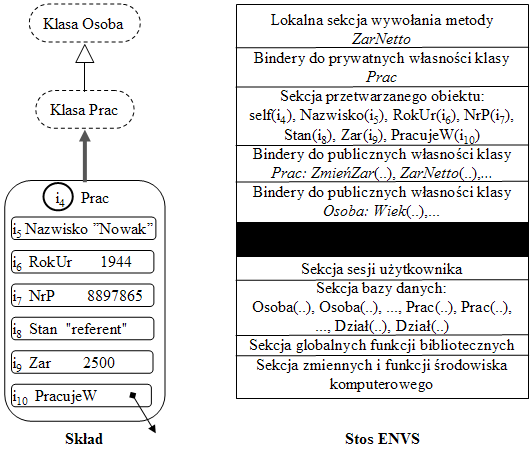
Rys.73. Stan stosu ENVS dla ciała metody ZarNetto z uwzględnieniem bindera self
Jeżeli dana metoda jest procedurą funkcyjną, wówczas pełni rolę "wirtualnego atrybutu", czyli rodzaju perspektywy umieszczonej wewnątrz klasy. Przykładem są metody Wiek i ZarNetto. Taki atrybut będzie zachowywać się przy wyszukiwaniu jak normalny atrybut, ale aktualizacja poprzez taki atrybut jest związana z identycznymi problemami, jak aktualizacja poprzez wynik procedury funkcyjnej (omawianymi poprzednio). Rozwiązanie tego problemu wymaga aktualizowalnych perspektyw będących składnikami klas. Perspektywy omawiane w następnym rozdziale mogą pełnić tę rolę.
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.