4. Architektura SZBD włączająca przetwarzanie zapytań
Termin "architektura" nie jest w informatyce jednoznacznie określony. Istnieje wiele spojrzeń na budowę tego samego systemu, w zależności od aspektu, który dany autor chciałby wyróżnić. Częsty jest aspekt funkcjonalny, czyli wzajemne zależności pomiędzy funkcjami danego systemu. Równie istotny jest aspekt strukturalny, tj. podział systemu na części składowe, niekoniecznie zgodny z aspektem funkcjonalnym. Jeszcze inna wizja architektury uwzględnia przepływ danych, tj. przedstawia architekturę z punktu widzenia tego, w jaki sposób i w jakich formach dane są przekazywane od jednostki do innej jednostki. Inny aspekt dotyczy przepływu komend, komunikatów i sterowania, tj. w jaki sposób sterowanie programu jest przekazywane pomiędzy jednostkami architektury. Jeszcze inny aspekt dotyczy geograficznego rozproszenia zasobów i/lub przetwarzania. Każdy z tych aspektów może być reprezentowany na różnym poziomie abstrakcji, od poziomu pojęciowego, do poziomu konkretnych decyzji programistycznych.
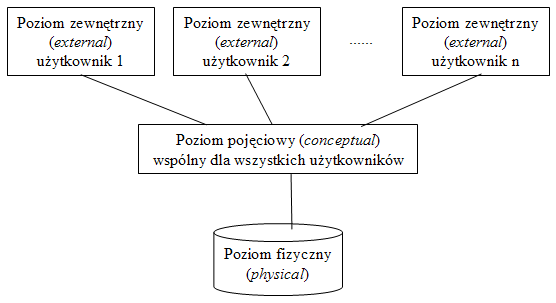
Rys.5. Trzypoziomowa architektura ANSI-SPARC
Dość często w ramach jednego rysunku prezentującego architekturę przemieszane są różne aspekty i poziomy abstrakcji. Stosowana notacja jest na ogół daleka od precyzji. Celem tego rodzaju rysunków jest odwołanie się do wyobraźni czytelnika i spowodowanie, aby wyobrażenie autora było identyczne z wyobrażeniem czytelnika. Niestety, wskutek braku wspólnej podstawy semantycznej te wyobrażenia dość często znacznie się różnią, powodując błędy w interpretacji lub niezrozumienie myśli autora. Popularny termin "boksologia" (boxology) oznacza rodzaj wypowiedzi mający postać rysunków zawierających prostokąty, linie, strzałki, kółka i inne oznaczenia z napisami w środku lub obok. Boksologia często zaciemnia sprawę zamiast ją objaśnić. Część informatyków odnosi się do tej twórczości dość negatywnie, szczególnie, gdy rzecz dotyczy problemu banalnego, który można objaśnić w dwóch zdaniach. Zdania te traktujemy jako ostrzeżenie czytelnika przed bezkrytycznym odbiorem "architektur" prezentowanych w różnych publikacjach. Mamy jednak nadzieję, że prezentowane niżej architektury nie będą dziedziczyć wspomnianych wad.
Historycznie, najbardziej znaną ramową architekturą baz danych jest propozycja komitetu ANSI SPARC. Posiada ona trzy poziomy: poziom fizyczny bazy danych, poziom pojęciowy wspólny dla wszystkich użytkowników oraz poziom zewnętrzny, Rys.5.
Rys.6. Architektura klient-serwer
Architektura ANSI SPARC została w naturalny sposób rozwinięta w architekturę klient-serwer. Poziom pojęciowy i poziom fizyczny zostały zastąpione przez element architektoniczny zwany serwerem. Z serwerem komunikują się klienci, przy czym każdy z nich ma swój schemat danych ustalony przez prawa dostępu i perspektywy.
Architektura klient-serwer oznacza podział aplikacji na dwie części: część realizowaną na kliencie oraz część realizowaną na serwerze. Terminem "cienki klient" (thin client) oznacza się sytuację, w której większość przetwarzania odbywa się na serwerze; z reguły klient jest wtedy ograniczony do interfejsu użytkownika. Terminem "mocny klient" (fat client) określa się sytuację, gdy znaczna część przetwarzania odbywa się po stronie klienta. W sytuacji, gdy serwer jest podłączony do wielu klientów, jest pożądane przesunięcie przetwarzania na stronę klienta ze względu na minimalizację obciążenia serwera, i co za tym idzie, lepszą ogólną wydajność. Z drugiej strony, oznacza to większe wymagania w zakresie sprzętu i oprogramowania po stronie klienta.
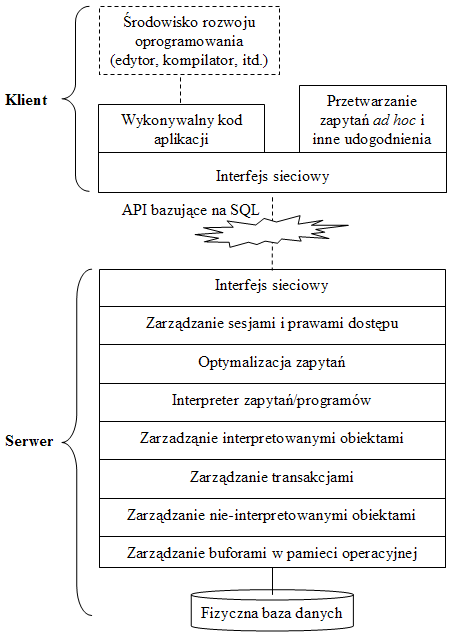
Rys.7. Uwarstwowiona architektura klient-serwer
Z punktu widzenia języka zapytań istotny jest stosunek zapytań do mechanizmu komunikacji pomiędzy klientem a serwerem. W systemach relacyjnych opartych na SQL przyjęto rozwiązanie, w którym serwer otrzymuje od klienta zapytania SQL i przekazuje z powrotem odpowiedzi na te zapytania. Oprócz zapytań w SQL, klient kieruje do serwera zlecenia aktualizacyjne (również w SQL), zlecenia dotyczące przetwarzania transakcji, zlecenia tworzenia tabel i perspektyw, i wiele innych komend. Przykładem takiego interfejsu jest ODBC, który zawiera całość interfejsu do programowania aplikacji (API, Application Programming Interface), włączając niskopoziomowe przetwarzanie za pomocą kursorów. Ta filozofia podziału przetwarzania i komunikacji pomiędzy klientami a serwerem jest bezpośrednią pochodną faktu wyodrębnienia zapytania jako specjalnej abstrakcji programistycznej niezależnej od języka programowania. Zaletą tej architektury jest skoncentrowanie przetwarzania i optymalizacji zapytań na serwerze, co umożliwia nieinstalowanie tego modułu po stronie klienta. Inną zaletą jest minimalizacja liczby komunikatów pomiędzy klientem i serwerem. Niekiedy podkreślaną zaletą jest uniezależnienie klienta od języka programowania, jakkolwiek w naszej opinii ta własność nie jest do końca prawdziwa, gdyż każdy taki język musi być dodatkowo wyposażony w specyficzny interfejs umożliwiający zagnieżdżanie zdań SQL. Ponadto takie rozwiązanie przyjmuje niezgodność impedancji nie jako wadę, ale jako coś, co jest dane z definicji.
Architektura uwzględniająca więcej aspektów przetwarzania zapytań jest przedstawiona na Rys.7. Idea tej architektury polega na jej uwarstwowieniu w taki sposób, aby każda warstwa komunikowała się tylko z warstwami sąsiednimi. Po stronie klienta jest tylko wykonywalny kod aplikacji oraz pewne udogodnienia dla użytkowników końcowych. Serwer zawiera zarządzanie sesjami i prawami dostępu, moduł optymalizacji zapytań/programów oraz interpreter zoptymalizowanych zapytań i programów. Warstwa interpretowanych obiektów oznacza poziom, na którym obiekty są specjalizowane (obiekty właściwe, klasy, powiązania, role, metaobiekty, indeksy itd.). Interpreter zapytań i programów odwołuje się wyłącznie do tej warstwy. Poniżej jest przetwarzanie transakcji, które zajmuje się nieinterpretowanymi obiektami, gdzie każdy obiekt jest po prostu ciągiem bajtów, niezależnie od tego, jaką jednostkę semantyczną reprezentuje. Niekiedy (w systemach relacyjnych) przetwarzanie transakcji jest przesunięte jeszcze niżej, do warstwy zarządzania fizycznymi stronami dyskowymi. Na Rys.7 jest to warstwa zarządzania buforami w pamięci operacyjnej.
Jakkolwiek podana architektura znalazła szerokie zastosowanie w systemach relacyjnych, ma ona także istotne wady. Jedną z nich jest to, że cała pracochłonność związana z ewaluacją zapytań jest przesunięta na stronę serwera, co oznacza zwiększone zapotrzebowanie na jego moc obliczeniową. Przy niewystarczającej mocy skutkuje to spowolnieniem wszystkich aplikacji.
Dla nas zasadnicza jest jednak inna wada: architektura ta nie pasuje do języka zapytań w pełni zintegrowanego z językiem programowania. W tym przypadku trudno powiedzieć, gdzie kończy się zapytanie, a zaczyna program aplikacyjny. Zapytanie może włączać złożone zmienne lokalne, odwoływać się do lokalnych klas, wywoływać lokalne metody, procedury, funkcje i perspektywy itd. Przyjmując, że jednostką komunikacji pomiędzy klientem a serwerem jest zapytanie i jego wynik, oddzielenie części zapytania wykonywanej na serwerze i części wykonywanej na kliencie przypomina problem z kwadraturą koła. Rys.8 przedstawia architekturę bardziej odpowiednią dla przypadku języka zapytań całkowicie zintegrowanego z imperatywnymi konstrukcjami i abstrakcjami języka programowania. W tym przypadku "inteligencja" serwera, polegająca na "rozumieniu" zapytań klienta, jest nie do utrzymania. Przetwarzanie zapytań klienta odbywa się na jednostce klienta.
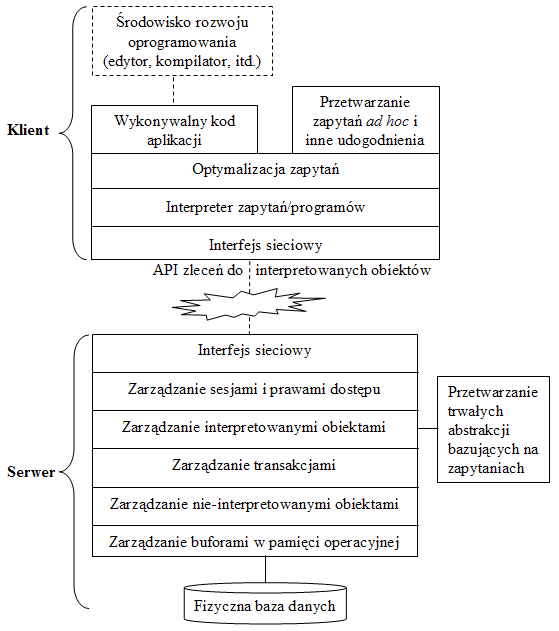
Rys.8. Architektura klient-serwer umożliwiająca integrację języka zapytań z językiem programowania
Ze względu na zapamiętane w bazie danych trwałe abstrakcje bazujące na zapytaniach, takie jak perspektywy (views), zapamiętane procedury i funkcje, zapamiętane klasy i metody, aktywne i dedukcyjne reguły, więzy integralności (integrity constraints), przetwarzanie zapytań powinno także odbywać się na serwerze. Dotyczy to zapytań występujących w tych trwałych abstrakcjach.
Klient komunikuje się z serwerem poprzez interfejs programistyczny określany jako CRUD (Create, Retrieve, Update, Delete), znacznie niższego poziomu niż język zapytań. Optymalizacja zapytań odbywa się po stronie klienta. Oznacza to, że klient musi mieć możliwości odzyskania wszelkiej metainformacji znajdującej się na serwerze niezbędnej do przetwarzania i optymalizacji zapytań. Podstawowe metainformacje przechowywane na serwerze, niezbędne dla realizacji języka zapytań na kliencie, są następujące:
-
Informacja ze schematu bazy danych, lub bardziej precyzyjnie, z jego metamodelu, określająca obiekty korzeniowe, tj. obiekty znajdujące się na najwyższym poziomie hierarchii obiektów. Informacja ta jest niezbędna do inicjalizacji stosu środowiskowego po stronie klienta.
-
Informacja o wszystkich korzeniowych abstrakcjach zapamiętanych w bazie danych, takich jak procedury, funkcje i perspektywy. Dla celów optymalizacyjnych może być konieczne odzyskanie tekstu lub pełnego drzewa rozbioru syntaktycznego tych abstrakcji. Jak wyżej, informacja ta jest niezbędna do inicjalizacji stosu środowiskowego.
-
Informacja o stanach środowiska bazy danych i środowiska komputerowego, takie jak np. liczność obiektów każdej klasy, ich bieżąca dostępność, stan obciążenia serwera bazy danych, stan obciążenia systemu komputerowego, ilość wolnej pamięci dyskowej itd.
-
Informacja o aktualnie dostępnych indeksach w bazie danych oraz innych strukturach lub mechanizmach wspomagających wydajność przetwarzania zapytań. Informacja ta jest istotna dla optymalizacji. Indeksy te powinny być oczywiście dostępne dla klienta w ramach jego API do serwera.
-
Informacje o stanie aktualnie wykonywanych transakcji w ramach sesji klienta.
- Inne informacje z metamodelu, takie jak klasy, typy itd. które mogą być niezbędne do realizacji i kontroli poprawności zapytań.
Dalsze wizje architektur uwzględniających język zapytań mogą być związane z rozproszeniem i/lub z integracją heterogenicznych zasobów. W takich wizjach pojawiają się nowe elementy architektoniczne, takie jak perspektywy, mediatory, osłony (wrappers), kanoniczny model obiektowy, pośrednik w wymianie zleceń do obiektów (ORB, Object Request Broker), protokół komunikacyjny na poziomie obiektów itd. Rys.9 przedstawia taką wizję architektury bazującą na kanonicznym modelu danych, umożliwiającym bezpośrednie odwzorowanie wszystkich innych modeli danych (relacyjnego, XML-owego, obiektowego itd.) i zunifikowanego języka zapytań działającego na kanonicznym modelu danych. Zasoby wielu serwerów są dostępne dla klienta poprzez mechanizm składający się z osłony, modułu przetwarzania zapytań oraz perspektywy.
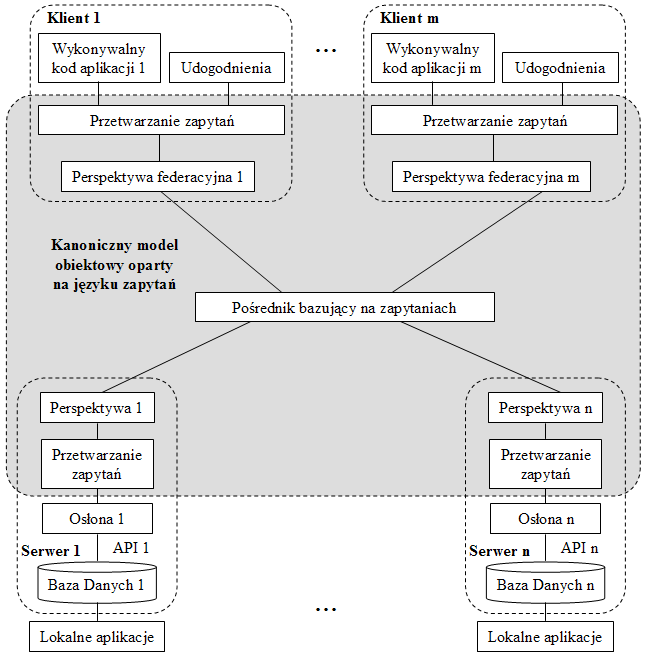
Rys.9. Rozproszona architektura federacyjnej bazy danych
Osłona przystosowuje lokalne API danego serwera do modelu kanonicznego i wspólnego języka zapytań. W ten sposób heterogeniczne dane znajdujące się na różnych serwerach są przystosowane do przetwarzania za pomocą języka zapytań. Osłona dokonuje prostego odwzorowania struktur danych nie zmieniając ich schematu pojęciowego. Moduł przetwarzania zapytań zainstalowany na serwerze umożliwia definiowanie perspektyw. Perspektywa na danym serwerze przystosowuje obiekty danego serwera do schematu federacyjnej bazy danych opartego na modelu kanonicznym, czyli zmienia schemat pojęciowy lokalnych danych danego serwera widziany z punktu widzenia federacji. Lokalne aplikacje działające na lokalnym serwerze pozostają oczywiście bez zmian.
Po stronie klienta mamy perspektywy federacyjne, których głównym zadaniem jest scalenie fragmentów rozproszonych zbiorów (np. obiektów Pracownik trzymanych na różnych serwerach) w jedną całość. Pośrednik w wymianie zleceń i ich rezultatów jest przedstawiony jako szyna a la CORBA, łącząca klientów i serwery. Jest on instalowany na każdej z tych jednostek, a poszczególne kopie tego pośrednika komunikują się ze sobą za pomocą odpowiedniego protokołu. Prezentowana wizja architektury jest spekulacyjna, jak dotąd nie istnieje system, który byłby na niej oparty. Oczywiście takich wizji może być więcej.
Inna wizja architektury przedstawia szczegółowe mechanizmy i struktury danych uczestniczące w przetwarzaniu zapytań. Włącza ona takie pojęcia, jak stos środowiskowy, stos rezultatów, metabaza, statyczny stos środowiskowy, statyczny stos rezultatów, rejestr indeksów w bazie danych i inne. Architektura taka zostanie objaśniona w rozdziale poświęconym optymalizacji zapytań.
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.