3. Funkcja nested
W poprzedniej sekcji staraliśmy się pokazać, że wewnętrzne środowisko pojedynczego obiektu powinno być w pewnych sytuacjach umieszczone na ENVS po to, aby istniała możliwość spójnego i jednorodnego wiązania nazw występujących w zapytaniach, w szczególności nazw atrybutów. Obecnie sformalizujemy i uogólnimy to pojęcie oraz określimy sposób jego wyznaczania. Naszą intencją jest zdefiniowanie funkcji, której argumentem jest referencja (identyfikator) do obiektu, zaś wynikiem jest wewnętrzne środowisko tego obiektu, które ma być umieszczone na ENVS. Jak zdefiniowaliśmy poprzednio, takie środowisko jest zbiorem binderów. Funkcję nazwaliśmy nested. Funkcja nested odnosi się do danego składu obiektów; inaczej mówiąc, skład obiektów jest jej parametrem implicite. Funkcja została zilustrowana na Rys.39.
Funkcję nested musimy uogólnić w taki sposób, aby jej argumentem był dowolny rezultat zapytania. Wiąże się to z tym, że operatory języka zapytań (np. operator selekcji where) będą przetwarzały dowolne kolekcje element po elemencie i w każdym z tych kroków będą zmieniały wierzchołek stosu ENVS. Definicja funkcji powinna więc uwzględniać dowolne wartości zwracane przez zapytania. Odpowiednio więc do rekurencyjnej definicji zbioru rezultatów zapytań zdefiniujemy funkcję nested:
-
Dla obiektu złożonego <i, n, {<i1, n1, v1>, <i2, n2, v2>, ... , <ik, nk, vk> }> zachodzi nested( i ) = { n1(i1), n2(i2), ... , nk(ik) }.
-
Jeżeli i jest identyfikatorem obiektu pointerowego <i, n, i1> oraz istnieje w składzie obiekt < i1, n1, v1>, wówczas nested( i ) = { n1(i1)}. Inaczej mówiąc, "wewnętrzne" środowisko obiektu pointerowego jest binderem do pojedynczego obiektu, na który ten pointer wskazuje. Taka definicja będzie zgodna z ideą nawigacji w obiektowej bazie danych "wzdłuż" przechowywanych w niej pointerów. Jest to podstawa m.in. tzw. wyrażeń ścieżkowych (path expressions).
-
Dla dowolnego bindera n(x) zachodzi nested( n(x) ) = { n(x) }. Inaczej mówiąc, lokalne środowisko bindera jest utożsamiane z nim samym. Jak się dalej przekonamy, taka definicja jest spójna z semantyką pomocniczych nazw, takich jak "zmienne korelacyjne", synonimy i zmienne związane kwantyfikatorami.
-
Jeżeli argumentem funkcji nested jest struktura, wówczas wynik jest sumą teorio-mnogościową rezultatów funkcji nested dla pojedynczych elementów struktury: nested( struct{ x1, x2, x3, ...}) = nested( x1 ) È nested( x2 ) È nested( x3 ) È ...
- Dla dowolnych innych argumentów wynik funkcji nested jest pusty. Dotyczy to w szczególności dowolnej wartości atomowej v Î V, identyfikatora obiektu atomowego, identyfikatora metody, procedury, funkcji, perspektywy itd. Powyższe byty nie posiadają wewnętrznego środowiska rozpoznawalnego przez funkcję nested (jakkolwiek niektóre z nich zyskują lokalne środowisko po ich wywołaniu).
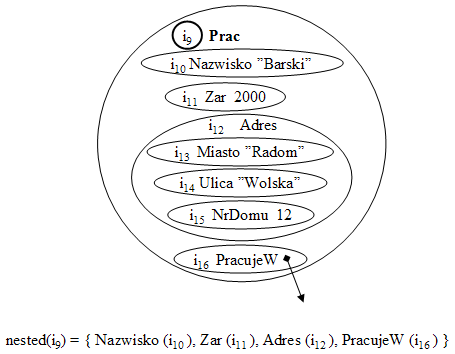
Rys.39. Obiekt i odpowiadająca mu wartość funkcji nested
Funkcję nested będziemy także stosować do identyfikatorów klas. W tym przypadku przyjmujemy, że klasa jest obiektem, wobec tego funkcja nested zwróci bindery do wszystkich własności tego obiektu, np. do metod, typów itd.
Może się zdarzyć, że w pewnym modelu składu (różnym od M0-M3) przy obliczaniu nested(i) nie można zwrócić bindera z referencją do podobiektu, gdyż ta referencja nie istnieje lub jest niedostępna. Przykładem jest sytuacja, kiedy w obiekcie z identyfikatorem i pewien atrybut jest stałą lub jest wyliczany na bieżąco. W takich sytuacjach funkcja nested może zwrócić po prostu binder n(v), gdzie n jest nazwą atrybutu z obiektu i, zaś v jest wartością (a nie referencją do) tego atrybutu. Jedynym skutkiem takiej zmiany modelu składu i funkcji nested jest to, że dla takiego atrybutu nie można będzie stosować operacji aktualizacyjnych, które wymagają referencji do atrybutu. Zapytania wyszukujące będą oczywiście bez problemów działać przy tak zmodyfikowanej funkcji nested.
Zwrócimy uwagę, że funkcja nested nie dokonuje operacji na stosie środowiskowym. Jest ona funkcją w sensie matematycznym, parametryzowaną stanem składu i nie posiadającą efektów ubocznych. Fizyczne umieszczenie rezultatu funkcji nested odbywa się poprzez procedurę eval (od ang. evaluation) dokonującą ewaluacji zapytania, która wykorzystuje funkcję nested w ramach pewnego mechanizmu. Sposób wykorzystania tej funkcji może być bardziej złożony niż mechaniczne przeniesienie wyniku funkcji nested na stos środowiskowy.
Przykłady działania funkcji nested (patrz skład z Rys.23 i Rys.24):
| P7.5. | nested( struct{i9, 55, i16, "Maria"} ) = |
| P7.6. | nested( struct{n("Kowalski"), Zarobek(2500), d(i22)}) = |
| P7.7. | nested( bag{ i1, i5, i9 }) = Æ |
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.