5. Operatory algebraiczne
Cechą podstawową dowolnej algebry jest m.in. to, że w wyrażeniu x1 D x2 (gdzie D jest operatorem algebry) kolejność ewaluacji argumentów x1 oraz x2 tego operatora nie ma znaczenia. Jest to zasadnicza różnica w stosunku do operatorów niealgebraicznych. Operatory algebraiczne można więc zdefiniować wyłącznie przy użyciu stosu QRES, poprzez odpowiednio rozszerzoną procedurę eval:
procedure eval( q : zapytanie )
begin
.....
case q jest rozpoznane jako D( q1 ) lub D q1:
// gdzie q1 jest zapytaniem, D jest
// operatorem algebraicznym unarnym
begin
wynik_q1: Rezultat; // lokalna zmienna typu Rezultat
eval( q1 ); // rezultat q1 na wierzchołku stosu QRES
wynik_q1 :=top( QRES ); pop( QRES );
push( QRES, D ( wynik_q1 );
end;
case q jest rozpoznane jako q1 D q2 : // gdzie q1 , q2 są zapytaniami, D jest
// operatorem algebraicznym binarnym
begin
wynik_q1, wynik_q2: Rezultat; // lokalne zmienne typu Rezultat
eval( q1 ); // rezultat q1 na wierzchołku stosu QRES
eval( q2 ); // rezultat q2 na wierzchołku stosu QRES
wynik_q2 :=top( QRES ); pop( QRES );
wynik_q1 := top( QRES ); pop( QRES );
push( QRES, wynik_q1 D wynik_q2 );
end;
case .....
.....
end;
Przyjęliśmy, że D jest bytem matematycznym (relacją lub funkcją) oznaczonym przez symbol D. W bardziej matematycznym (denotacyjnym) sformułowaniu wynik zapytań D( q1 ) oraz q1 D q2 można zapisać jako:
- wynik( D( q1 ) ) = D ( wynik( q1 ) )
- wynik( q1 D q2 ) = wynik( q1 ) D wynik( q2 )
Funkcja wynik jest implicite parametryzowana stanem (składem obiektów oraz stosem środowisk), ale nie zmienia tego stanu. W podanych wyżej zapisach stos QRES nie występuje, gdyż na tym poziomie rozważań jest on wyłącznie cechą implementacyjną, wbudowaną implicite w rekurencyjną definicję funkcji wynik.
Języki zapytań wprowadzają wiele operatorów, które moglibyśmy określić jako algebraiczne. Istnieje nieco rozmyta granica pomiędzy operatorami "wbudowanymi" w dany język (zwanymi operatorami generycznymi) a operatorami bibliotecznymi, czyli funkcjami "dobudowanymi" na wierzchołku danego języka. Ogólne zalecenie mówi, że liczba operatorów "wbudowanych" powinna być minimalna. Prawie wszystkie operatory powinny wchodzić w skład bibliotek, które nie należą do definicji języka, ale raczej uzupełniają pewien jego aspekt lub dziedzinę zastosowań. To zalecenie nie jest zawsze przestrzegane. Przykładem może być SQL, a szczególnie SQL-99, posiadający ogromną liczbę "wbudowanych" operatorów, które rozszerzają definicję języka. Nie będziemy jednak starali się zajmować stanowiska, które z operatorów mają być "wbudowane", a które "dobudowane" - jest to raczej kwestia techniczna oraz komercyjna (biblioteki mogą być przedmiotem odrębnej sprzedaży). Ponadto, może być duża liczba operatorów bibliotecznych przywiązanych do specyficznych dziedzin zastosowań, np. operatory obsługujące hurtownie danych, systemy geograficzne, systemy temporalne, systemy przestrzenne, systemy oparte o XML, systemy przetwarzania języka naturalnego itd.
Ze względu na różnorodność operatorów algebraicznych nie będziemy przesądzać, które z nich należą do języka SBQL, a które do niego nie należą. Przyjmiemy, że do SBQL należy dowolny operator, o ile w danej chwili wykładu jest on nam potrzebny. Z implementacyjnego punktu widzenia, po zaimplementowaniu 50-ciu operatorów implementacja każdego następnego jest zwykle banalna i zajmuje kilka lub kilkadziesiąt minut. Mogą oczywiście trafić się operatory niebanalne, np. skomplikowane obliczenia statystyczne, ale wtedy tak czy inaczej problem nie jest po stronie języka zapytań, a implementacji konkretnej wyspecjalizowanej funkcji.
5.1. Typowe operatory algebraiczne
Interesować nas będą głównie operatory generyczne, niezależne od dziedziny zastosowań. Niżej przeliczymy najbardziej charakterystyczne ich grupy oraz podamy przykłady ich użycia.
- Generyczny operator porównania na równość, oznaczany zwykle =, oraz operator odwrotny oznaczany ¹. Np. Nazwisko = "Kowalski", x = y, Zarobek ¹ 2000 itd. Operatory te są zwykle zdefiniowane dla wszystkich typów wprowadzanych w danym języku, włączając liczby całkowite, liczby rzeczywiste, stringi, struktury, zbiory, sekwencje, identyfikatory obiektów itd.;
- Porównania i operatory dotyczące liczb całkowitych i rzeczywistych: <, >, +, -, *, /. Np. Zarobek < 3000, 2+2, -(głebokosc + x) itd.
- Funkcje liczbowe: część całkowita liczby, zaokrąglenie liczby, wartość bezwzględna liczby, sinus, kosinus, tangens, kotangens, logarytm dziesiętny, logarytm naturalny, funkcja wykładnicza, pierwiastek kwadratowy itd.; Np. sqrt(x2 + y2), sin(x+45) itd.;
- Porównania, operatory i funkcje na stringach znaków: porównanie na porządek leksykograficzny stringów, zawieranie się stringów, obcięcie stringów, konkatenacja stringów, zamiana wszystkich liter na wersaliki i odwrotnie, określenie długości stringu itd.
- Porównanie, operatory i funkcje na datach i czasie godzinowym: porównanie dat, porównanie czasu, zmiana czasu na liczbę sekund itd.
- Funkcje arytmetyczne zagregowane: sum (suma liczb), avg (średnia), min (liczba minimalna), max (liczba maksymalna) itd. Argumentem takiej funkcji jest kolekcja liczb, zaś wynikiem - pojedyncza liczba. W SQL funkcje te nie są ortogonalne (niezależne), gdyż są powiązane z operatorem group by. To powiązanie jest konsekwencją wadliwej koncepcji, która owocuje niedogodnościami i niepotrzebnymi ograniczeniami. Jak zobaczymy, w naszym ujęciu takie powiązanie jest zbędne. Przykłady:
| P8.3. | sum( Pracownik.zarobek ) |
- Funkcja zliczająca liczbę elementów w kolekcji (w SQL - funkcja count), funkcja usuwająca duplikaty z kolekcji (w SQL - distinct), funkcja sprawdzająca, czy kolekcja nie jest pusta (w SQL - exists), która zwraca true, jeżeli kolekcja będąca jej argumentem nie jest pusta, oraz false w przeciwnym wypadku. Jak poprzednio, w SQL funkcje te nie są ortogonalne i związane specyficzną nieortogonalną składnią. Będziemy tego rodzaju ograniczeń unikać. Przykłady:
| P8.4. | count(Pracownik) |
- Konstruktory wartości złożonych: zmiana pewnej liczby wartości na strukturę z etykietowanymi polami, zmiana pewnej liczby wartości na bag (lub sekwencję) itd.
5.2.
Koercje
Koercjami będziemy nazywać funkcje dokonujące zmiany typu i/lub reprezentacji pewnej wartości czasu wykonania. Niekiedy funkcje te występują implicite, tj. użytkownik nie jest zmuszany do ich pisania w tekście zapytania lub programu, gdyż zastosowanie takiej funkcji bezpośrednio wynika z kontekstu. Z tego względu pojęcie koercji ma pewne przecięcie z pojęciem elipsy i tzw. polimorfizmu ad hoc. Języki programowania oraz SQL używają dość dużo różnych jawnych lub niejawnych koercji. Niżej przeliczymy najbardziej typowe.
- Funkcja dereferencji; zwykle występuje implicite. Funkcja ta wywoływana jest wtedy, gdy pewną referencję trzeba zamienić na wartość. Np. w zapytaniu
| P8.5. | Pracownik where Zarobek > 2000 |
nazwa Zarobek zwróci referencję do danej Zarobek w pewnym obiekcie Pracownik. Funkcja dereferencji jest wymuszona przez operator >. W wyniku referencja do danej Zarobek zostanie zastąpiona przez wartość tego zarobku dla konkretnego pracownika. Dla umożliwienia sformułowania pewnych zapytań funkcja dereferencji może być wprowadzona explicite, np. w postaci słowa kluczowego deref. Operator dereferencji można również zdefiniować dla identyfikatorów obiektów złożonych (definicja będzie podana dalej).
- Operatory zmiany typu lub reprezentacji wartości atomowej. Przykładem jest zmiana liczby rzeczywistej na string (i odwrotnie), zmiana liczby całkowitej na rzeczywistą (i odwrotnie) itd. W zależności od liczby typów wprowadzonych do języka liczba tych operatorów może być znaczna. W wielu przypadkach koercja występuje implicite. Np. w wyrażeniu x + y, jeżeli x jest typu integer, zaś y jest typu real, to operator + wymusza funkcję koercji zmieniającą typ x na real. W systemie Loqis tego rodzaju koercja jest stosowana również dla stringów. Np. w wyrażeniu x + y, jeżeli x jest typu integer, zaś y jest stringiem, to następuje próba konwersji y do typu integer; jeżeli jest udana, to operacja zwraca liczbę typu integer, jeżeli nie, to następuje próba konwersji y do typu real; jeżeli jest udana, to następuje konwersja x do real i operacja zwraca typ real; jeżeli nie, to sygnalizowany jest błąd. Analogicznie dla stringów: w wyrażeniu
| P8.6. | Prac.(Nazwisko o " " o Zar) |
następuje konkatenacja stringu zwracanego przez Nazwisko (po wcześniejszym wymuszeniu dereferencji), stringu zawierającego jedną spację oraz liczby zwracanej przez Zar (po wcześniejszym wymuszeniu dereferencji); w tym przypadku liczba ta jest wcześniej konwertowana do stringu.
- Operatory rzutowania (cast). Operatory te mogą mieć znaczenie w modelach M1 i M2 (oraz pochodnych). Polegają one na zmianie typu referencji lub samej referencji. Operatory te mają zazwyczaj postać (nowy typ) zapytanie, gdzie zapytanie zwraca referencję (referencje) do obiektu. W tym przypadku taki operator informuje kompilator o zmianie typu referencji i/lub dokonuje fizycznej zmiany tej referencji. Np. zapytanie
| P8.7. | (Student) (Prac where Zar > 3000) |
oznacza zidentyfikowanie odpowiednich pracowników i następnie konwersję ich typów i/lub identyfikatorów do typu Student. W odróżnieniu od C/C++, gdzie taka konwersja jest czysto formalistyczna i nie interesuje się zgodnością reprezentacji wartości (co jest oczywiście błędogenne), będziemy przyjmować, że taka konwersja jest możliwa tylko wtedy, gdy typy są zgodne. Dla niezgodnych typów konwersja zwraca np. pusty bag. W powyższym przykładzie, rezultatem zapytania będą identyfikatory obiektów (ról) typu Student, którzy są jednocześnie pracownikami i zarabiają więcej od 3000. (Oznacza to wielodziedziczenie w modelu składu M1 lub dynamiczne role w M2).
- Zmiany rodzaju kolekcji. Są to operatory podobne do rzutowania, ale nie zmieniają typu elementów kolekcji, lecz jej rodzaj. Np.
| P8.8. | (sequence) (Prac where Zar > 3000) |
oznacza zmianę kolekcji bag na kolekcję sequence (z dowolnym porządkiem elementów). Operatory takie mogą występować implicite, tj. ich zastosowanie wynika z kontekstu.
- Zmiana elementu na bag jednoelementowy (zawierający ten element) i odwrotnie. Jest to popularna koercja występująca z reguły implicite (wyznaczona kontekstem); występuje np. w SQL. Przykładem jest zagnieżdżone zapytanie (podaj pracowników zarabiających więcej od Kima):
| P8.9. | Prac where Zar > ((Prac where Nazwisko = "Kim"). Zar) |
gdzie formalnie podzapytanie (Prac where Nazwisko = "Kim").Zar zwraca bag. Jest on implicite konwertowany do pojedynczego elementu - referencji do zarobku Kima, która jest następnie konwertowana implicite przez operator > do wartości zapisanej pod tą referencją. Jeżeli konwersja bagu lub sekwencji do pojedynczego elementu jest nieudana, to sygnalizowany jest błąd.
5.3. Operatory algebraiczne na strukturach i kolekcjach
Są to operatory działające na bagach: suma, przecięcie, iloczyn kartezjański, różnica, równość, zawieranie się. Podobne operatory są zwykle definiowane dla zbiorów, ale w tym wykładzie będziemy trzymać się poglądu, że dla obiektowych języków zapytań pojęcie zbioru jest nadmiarowe (jest szczególnym przypadkiem bagu), wobec czego jest zbędne. Przykłady:
| P8.10. | (Pracownik.Nazwisko) È (Emeryt.Nazwisko) |
| P8.11. | ("analityk") Ì (Pracownik.Stan) |
Analogiczne do powyższych można zdefiniować operatory na sekwencjach: konkatenacja sekwencji, obcięcie sekwencji poprzez usunięcie elementów z przodu lub z tyłu, porównanie sekwencji na równość, zawieranie się sekwencji, pobranie i-tego elementu sekwencji itd.
Uogólnieniem operatorów iloczynu kartezjańskiego, sumy bagów i konkatenacji sekwencji są konstruktory struktur, bagów i sekwencji określone składnią:
- struct( q1, q2, q3, ...); forma równoważna: ( q1, q2, q3, ...)
- bag( q1, q2, q3, ...)
- sequence( q1, q2, q3, ...).
Przykłady:
| P8.12. | (Nazwisko, Zarobek, Stan) |
| P8.13. | bag((Pracownik where Stan="analityk"), |
Istnieją niuanse semantyczne dotyczące tych operatorów. W szczególności, przyjmujemy, że jeżeli argumentem bag lub sequence jest pojedynczy element, to jest on automatycznie traktowany jako zbiór/ciąg jednoelementowy (jest to automatyczna koercja). Przydaje się to m.in. w sytuacji, gdy chcemy wyliczyć elementy pewnej kolekcji, np.
| P8.14. | sequence( "kapitan", "major", "podpułkownik", "pułkownik") |
Dla operatora struct, jeżeli któryś z argumentów jest bagiem, to pozostałe argumenty indywidualne są traktowane jak jednoelementowe bagi. Podobnie, jeżeli argumentem takiego operatora jest sekwencja, to jest ona automatycznie rozumiana jako bag. Będziemy również przyjmować następujące własności operatora struct:
- struct(struct(q1, q2,...)) = struct(q1, q2,...)
- struct(struct(q1, q2,...), struct(r1, r2,...), ...) = struct(q1, q2,..., r1, r2,..., ...)
- itd.
Przyjmiemy ponadto, że struktura posiadająca dokładnie jeden element jest równoważna temu elementowi, zaś struktura posiadająca zero elementów nie istnieje. Analogiczne własności można przyjąć dla operatorów bag i sequence (z zastrzeżeniem, że mogą istnieć puste bagi i sekwencje).
Podobnie jak w SQL, możliwe jest zdefiniowanie operatora gwiazdki, który w SQL jest skrótem (elipsą) oznaczającą listę wszystkich atrybutów danej relacji. Przenosząc to rozwiązanie na grunt SBQL można przyjąć, że operator gwiazdki zwraca strukturę zawierającą bindery znajdujące się aktualnie na czubku stosu ENVS. Przykładowo (patrz schemat z Rys.24), zapytanie Prac.* zwracałoby bag zawierający struktury z binderami
| P8.15. | struct{ Nazwisko(...), Zar(...), Adres(...), PracujeW(...) } |
dla wszystkich pracowników. Taka interpretacja operatora gwiazdki wydaje się jednak mało użyteczna. Znacznie bardziej przydatny byłby operator zwracający bag wartości wszystkich binderów znajdujących się na czubku stosu ENVS. Umożliwiłby zapytania nieosiągalne w inny sposób, np. "ile atrybutów ma dany obiekt?". Umożliwiłby także pomijanie pewnych nazw w zapytaniach, gdyż w istocie oznaczałby wiązanie do dowolnej nazwy. Przyjmując interpretację, w której operator gwiazdki zwraca bag z wartościami do wszystkich binderów znajdujących się na stosie ENVS, możemy zadawać następujące zapytania:
| P8.16. | Podaj średnią liczbę atrybutów w obiektach Prac: |
| P8.17. | Odszukaj wszystkie obiekty Prac, w których jakikolwiek atrybut do trzeciego poziomu hierarchii ma wartość "Nowacka": |
Przyjmujemy tu oczywiście, że operator = nie podniesie wyjątku, jeżeli typy będą niezgodne, zwracając w takich sytuacjach false.
| P8.18. | Od obiektu Kowalskiego przejdź do obiektów Dział po jakimkolwiek powiązaniu: |
Powyższe zapytanie nie będzie miało jednak poprawnej interpretacji, gdyż może nastąpić wiązanie nazwy Dział na dole stosu. Jednym z rozwiązań tej sytuacji jest zróżnicowanie syntaktyczne przejścia wzdłuż pointera (czyli zamiast drugiej kropki zastosować np. nowy symbol ->).
5.4. Operatory definiowania pomocniczej nazwy
Pomocnicze nazwy pojawiły się w językach zapytań w związku z koncepcją ich semantyki określaną jako "rachunek relacyjny". W rachunku tym pomocnicze nazwy są określone jako "zmienne". Są definiowane na pewnych dziedzinach (np. relacjach); przyjmuje się, że "przebiegają" iteracyjnie te dziedziny. Po zdefiniowaniu można ich użyć do definiowania warunków selekcji, warunków złączeń oraz do definiowania rezultatów pośrednich i końcowych rezultatów zapytań. Podobne znaczenie "zmiennych" występowało w rachunku predykatów. Zmienne rozróżniano na "wolne", czyli takie, których zakres widoczności wykracza poza dane wyrażenie, oraz "związane", czyli takie, których zakres widoczności ogranicza się do danego wyrażenia (np. zmienne związane kwantyfikatorami). Podobny charakter miały zmienne w notacji lambda (i odpowiadającemu jej rachunku lambda.
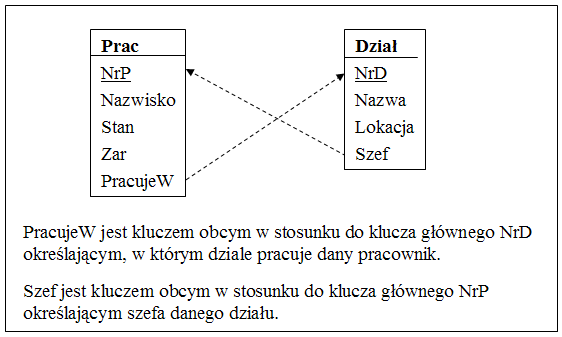
Rys.47. Schemat prostej relacyjnej bazy danych
W relacyjnych językach zapytań zmienne te znalazły zastosowanie w postaci tzw. zmiennych krotkowych (tuple variables) oraz zmiennych dziedzinowych (domain variables). Różnica polegała na tym, czy wartością tej zmiennej jest pojedyncza krotka relacji czy też pojedyncza wartość kolumny relacji. Różnicę tę można objaśnić na przykładzie SQL (opartym na zmiennych krotkowych) oraz na pewnej hipotetycznej modyfikacji tego języka SQLD opartej na zmiennych dziedzinowych. Schemat relacyjnej bazy danych jest przedstawiony na Rys.47.
Przykładem użycia zmiennych krotkowych jest następujące zapytanie w SQL:
| P8.19. SQL | Nazwiska projektantów zarabiających więcej od swojego szefa: |
Zmienne x, y, z przebiegają odpowiednio tabele Prac, Dział i Prac, przy czym intencją zmiennej z jest wyznaczenie krotki kierownika danego pracownika. Zauważmy, że w podanym przykładzie użycie zmiennych jest celowe, gdyż tabela Prac jest użyta dwa razy. W komercyjnej literaturze tego rodzaju zmienne są określane niekiedy jako "synonimy" tabel, ale jest to niewłaściwe z semantycznego punktu widzenia: nazwy x, y, z są wiązane do pojedynczych krotek, a nie do całych tabel. Niekiedy używa się także "zmiennych korelacyjnych" (correlation variables); etymologia tego terminu jest niejasna. W zakresie różnicy pomiędzy "zmiennymi" a "relacjami" nastąpiło pewne zamieszanie, gdyż oficjalnie zdanie w SQL:
| P8.20. SQL |
select Nazwisko from Prac where Stan = "projektant" |
(gdzie "zmienne" nie występują) ma być rozumiane jako:
| P8.21. SQL | select Prac.Nazwisko from Prac as Prac |
gdzie pierwsze Prac jest odwołaniem się do zmiennej Prac, drugie Prac jest odwołaniem się do tabeli Prac, trzecie Prac jest definicją zmiennej Prac, zaś czwarte Prac jest ponownym odwołaniem się do zmiennej Prac. Oczywiście, tego rodzaju podejście stwarza szerokie pole do mylnych interpretacji i błędów, a przede wszystkim zwiększa objętość dokumentacji niezbędnej do dokładnego objaśnienia semantyki.
W hipotetycznym języku SQLD opartym na rachunku dziedzinowym nasz początkowy przykład przyjąłby postać:
| P8.22. SQLD | select np from |
W tym przykładzie zmienne rx, nx, sx, zx, dx, ry, sy, rz, zz przebiegają odpowiednie kolumny tabel. Jakkolwiek oparcie języka na zmiennych dziedzinowych wydaje się gorsze niż oparcie go na zmiennych krotkowych (jak obecnie w SQL), koncepcja ta znalazła swoje odbicie w niegdyś popularnych wizyjnych językach relacyjnych, takich jak Query-By-Example. Obecnie niektórzy autorzy uważają, że obiektowe języki zapytań, takie jak OQL, są oparte na zmiennych dziedzinowych. Twierdzenie to jest słabo uzasadnione.
"Zmienne", jak przedstawiono wyżej, znalazły dalsze zastosowanie, np. jako "zmienne iteracyjne" w iteratorach "for each...do..." jako zmienne definiowane w klauzulach group by i order by. Koncepcje te istotnie wykraczają poza rachunek relacyjny i ich semantyka nie może być objaśniona na tym gruncie.
Koncepcja "zmiennych" i związanych z nimi "rachunków" jest kontynuowana przez zwolenników podejścia obiektowego. Ta kontynuacja jest najczęściej niespójna semantycznie, co uniemożliwia efektywną implementację. Posłużymy się tu przykładem z aktualnego standardu ODMG 3.0. Rozważmy przykład zapytania OQL podany w [ODMG00]:
| P8.23. OQL |
select * from Studenci as x, |
Baza danych dotyczy obiektów Studenci, którzy związkiem uczęszcza są powiązani z obiektami Wykład, a te obiekty z kolei są powiązane związkiem prowadzony_przez z obiektami Profesor. Zapytanie definiuje trzy nazwy x, y, z, określane jako "zmienne iteracyjne". Zmienne te są zdefiniowane w ramach operatora OQL znanego jako "zależne złączenie". Zgodnie z regułami zakresu określonymi w tym samym dokumencie, zakres tych zmiennych jest ograniczony do powyższego zapytania; poza tym zapytaniem zmienne te są niewidoczne. Okazuje się jednak, że typ wartości zwracanej przez to zapytanie jest następujący:
| P8.24. | bag<struct (x:Student, y:Wykład, z:Profesor)> |
Semantyczna kwalifikacja tych nazw została zmieniona: zamiast oznaczać "zmienne iteracyjne" oznaczają teraz etykiety elementów struktury. W tej sytuacji mogą być użyte na zewnątrz tego zapytania, np. w zapytaniu (podaj nazwiska studentów uczęszczających na jakikolwiek wykład profesora zwyczajnego Bryły):
| P8.25. OQL |
select x.Nazwisko from ( q ) where z.Nazwisko = "Bryła" |
gdzie q należy zastąpić tekstowo przez podane wcześniej zapytanie. Możliwość użycia tych zmiennych na zewnątrz zapytania, w którym są zdefiniowane, jest niezgodna z podanymi regułami zakresu. Nie ma wątpliwości, że autorzy standardu ODMG całkowicie utracili kontrolę nad spójnością definicji.
Podany przykład stawia zasadnicze pytania: który model formalny pozwala na zmianę roli nazw oznaczających "zmienne iteracyjne" w taki sposób, aby oznaczały etykiety pól struktur? Jaki jest rzeczywisty zakres widoczności dla x, y, z? Jak tego rodzaju kwestie należałoby poprawnie sformalizować?
Te oraz inne wątpliwości prowadzą do odrzucenia koncepcji interpretacji semantycznej odziedziczonych z rachunku relacyjnego. Nasze założenie (sformułowane już w pracy [Subi85] z 1985 roku) polegało na tym, aby "zmienne" gładko zintegrować z opisanym wyżej mechanizmem wiązania. To prowadzi do następującej zasady:
Konsekwencje tej zasady są następujące: jeżeli wewnątrz zapytania jest zastosowana pewna nazwa x, to aby ją poprawnie związać za pomocą mechanizmu stosu środowiskowego, stos ten musi zawierać binder z nazwą x.
Problem zdefiniowania reguł tego mechanizmu dla takich nazw nie był łatwy. Pierwsze nasze próby polegały na tym, że wprowadziliśmy obiekt nazwany x do składu obiektów, a następnie odpowiedni binder na stos środowiskowy. Rozwiązanie to oznaczało, że zmienne definiowane w zapytaniach zostały potraktowane tak samo jak zmienne programistyczne. Jak się okazało, rozwiązanie to prowadzi do anomalii; w szczególności, nie można było znaleźć efektywnego kryterium ustalającego, kiedy te zmienne należy usuwać. Po kilku próbach (i po dwóch zaimplementowanych prototypach) zostało przez nas odkryte rozwiązanie, które okazało się proste, uniwersalne i pozbawione wad. Rozwiązanie to może być zaskakujące dla osób przywiązanych do rachunku relacyjnego.
Elementem tego rozwiązania jest operator definiowania pomocniczej nazwy. Okazało się, że:
Operator definiowania pomocniczej nazwy (wzorem OQL) będziemy oznaczać as. Niech q będzie zapytaniem, które zwraca pewną kolekcję bag{x1, x2, x3, ...}, gdzie xi są dowolnymi elementami tej kolekcji. Wówczas zapytanie
q as n
(gdzie n Î N) zwróci kolekcję binderów bag{ n(x1), n(x2), n(x3), ...}. Operator as etykietuje określoną nazwą każdą wartość zwróconą przez zapytanie będące jego argumentem. Operator ten nie zmienia charakteru kolekcji: w szczególności, jeżeli q zwraca sequence{x1, x2, x3, ...}, to q as n zwraca sequence{ n(x1), n(x2), n(x3), ...}. Operator as może być zagnieżdżany: np. jeżeli q zwraca bag{x1, x2, x3, ...}, to (q as n1) as n2 zwraca bag{ n2( n1(x1) ), n2( n1(x2) ), n2( n1(x3) ), ...}. Operator jest zilustrowany na Rys.48.
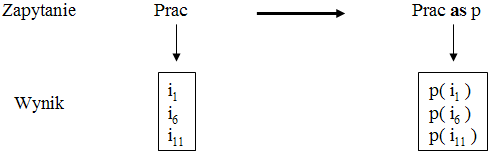
Rys.48. Przykład zastosowania operatora as
Pokażemy, że ten prosty operator w połączeniu z pozostałymi operatorami języka SBQL jest w pełni uniwersalny i może być wykorzystany we wszystkich sytuacjach, w których języki takie jak SQL i OQL deklarują pomocnicze nazwy. (Nieco dalej operator ten będzie uzupełniony podobnym operatorem group as.) Dotyczy to w szczególności następujących sytuacji:
- "Zmienne" (krotkowe, dziedzinowe itd.) definiowane w ramach klauzul from w językach, takich jak SQL i OQL; np. Prac as p. Pokażemy, że operator zależnego złączenia znany z OQL i SQL-99 jest ortogonalny w stosunku do operatora as, wobec czego nie zachodzi potrzeba definiowania go w tym szczególnym kontekście;
- Zmienna związana kwantyfikatorem, np.
| P8.26. | $Prac as p (p.Zar > 10000) |
- Etykiety składników struktur zwracanych przez zapytanie, np.
| P8.27. | Prac.( Nazwisko as n, Zar as z ) |
- Kursor w zdaniu for each; np.
| P8.28. | for each Prac as p do p.Zar := p.Zar +100; |
- Definicja nowych nazw atrybutów dla wirtualnej perspektywy (view); np.:
| P8.29. | create view BogatyProjektant |
W pewnych sytuacjach będzie nam potrzebny nieco inny operator definiowania pomocniczej nazwy, określony przez nas jako group as. Operator pojawił się podczas analizy przykładów wymagającej klauzuli group by języka SQL. W wyniku zdecydowaliśmy, że specjalnego operatora group by nie będziemy wprowadzać. Operator ten w SQL prowadzi do znanych raf semantycznych, wymaga dodatkowych opcji w języku (klauzula having), jest semantycznie nieregularny, jest nieortogonalny w stosunku do innych operatorów i jest poważnym utrudnieniem dla optymalizacji zapytań. Jak się okazuje, w naszym przypadku taki operator jest zbędny, gdyż może być zastąpiony przez zależnie złączenie i inne operatory, w szczególności group as.
Definicja operatora group as jest bardzo prosta: jeżeli q zwraca pewną wartość r (w szczególności, kolekcję), to q group as n zwraca pojedynczy binder n(r). W odróżnieniu od operatora as, operator group as przypisuje nazwę n do całości rezultatu zapytania, a nie do poszczególnych elementów kolekcji zwracanej przez to zapytanie. Rezultatem operatora jest zawsze pojedynczy binder. Będziemy go używać w sytuacjach, kiedy nie zależy nam na powoływaniu "zmiennej", lecz wtedy, gdy chcemy nazwać cały wynik zapytania. Ilustruje to Rys.49.
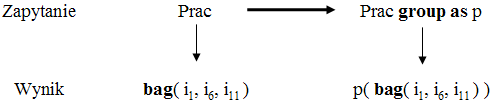
Rys.49. Przykład zastosowania operatora group as
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.