Wprowadzenie do rozproszonych baz danych (2)
- Główne aspekty rozproszenia baz danych
- Przezroczystość
- Współdziałanie i heterogeniczność
- Przenaszalność
- Autonomia
- Niezależność danych
- Ontologia
- Metadane
- Modelowanie pojęciowe
- Rozproszone obiektowe bazy danych
- Główne aspekty rozproszenia baz danych
- Przezroczystość (transparency)
- Rozproszony SZBD powinien podtrzymywać rozproszenie danych przy założeniu odizolowania programisty/użytkownika od większości aspektów rozproszenia.
- Współdziałanie (interoperability)
- Oznacza współpracę zbudowanych niezależnie od siebie heterogenicznych systemów (heterogeneous systems).
- Aspektem współdziałania jest przyłączenie do rozproszonej BD starych systemów, tzw. spadkowych (legacy)
- Przenaszalność (portability)
- Własność języka programowania i jego kompilatorów/interpreterów umożliwiająca przenoszenie programów na różne platformy.
- Autonomia (autonomy)
- Lokalne bazy danych podlegają własnym lokalnym regułom.
Tylko określona część lokalnych zasobów i usług jest udostępniana na zewnątrz.
- Niezależność danych (data independence)
- Możliwość projektowania, utrzymywania, udostępniania, zmiany nośników, zmiany reprezentacji, itp. działań na danych niezależnie od programów, które na nich operują.
- Ontologia (ontology), często w kontekście ontologia biznesowa
- Formalny opis wszystkich tych własności lokalnej bazy danych, które są niezbędne do tego, aby projektant/programista mógł prawidłowo zaprogramować nową aplikację (np. mobilnego agenta).
- Niekiedy ontologia jest określana jako metadane.
- Przezroczystość
- Rozproszona BD musi spełniać warunki komfortu pracy programistów, administratorów i użytkowników, jak również niezawodności, bezpieczeństwa danych, zwiększenie odporności na błędy programistów.
- To oznacza konieczność redukcji złożoności przy pracy z rozproszoną bazą danych, co jest określane jako "przezroczystość".
- Ma ona następujące formy:
- Przezroczystość położenia: Umożliwienie jednorodnych metod operowania na lokalnych i odległych danych. Tego warunku nie spełnia np. system, w którym lokalna baza danych jest obsługiwana przez pewien język 4GL, zaś odległa - przez specjalny zestaw procedur (API).
- Przezroczystość dostępu: Uwolnienie użytkowników od konieczności(a niekiedy również uniemożliwienie) korzystania z informacji o aktualnym położeniu danych.
- Przezroczystość współbieżności: Umożliwia wielu użytkownikom jednoczesny dostęp do danych bez konieczności uzgodnień i porozumiewania się, przy zapewnieniu pełnej spójności danych i przetwarzania.
- Przezroczystość skalowania: Umożliwienie dodawania nowych elementów bazy danych bez wpływu na działanie starych aplikacji i pracę użytkowników.
- Przezroczystość replikacji: Umożliwienie tworzenia i usuwania kopii danych w innych miejscach geograficznych z bezpośrednim skutkiem dla efektywności przetwarzania, ale bez skutków dla postaci programów użytkowych lub pracy użytkownika końcowego.
- Przezroczystość wydajności: Umożliwienie dodawania nowych elementów systemu komputerowego (np. serwerów,) bez wpływu na pracę większości użytkowników rozproszonej bazy danych.
- Przezroczystość fragmentacji (podziału): automatyczne scalanie obiektów, tabel lub kolekcji, których fragmenty są przechowywane w różnych miejscach.
- Przezroczystość awarii: Umożliwienie nieprzerwanej pracy większości użytkowników rozproszonej bazy danych w sytuacji, gdy niektóre z jej węzłów lub linie komunikacyjne uległy awarii.
- Przezroczystość migracji: Umożliwienie przenoszenia zasobów danych do innych miejsc bez wpływu na pracę użytkowników.
- W praktyce spełnienie wszystkich wymienionych warunków jest ideałem, który prawdopodobnie nie został zrealizowany w żadnym ze znanych systemów.
- Współdziałanie i heterogeniczność
- Umożliwienie współdziałania heterogenicznych systemów baz danych jest drugim ważnym aspektem rozproszenia.
- Heterogeniczność jest nieodłączną cechą dużych sieci komputerowych, takich jak Internet, WWW, sieci intranetowych, rozproszonych baz danych, systemów przepływu prac, zasobów WWW opartych na plikach HTML i XML, itd.
- Heterogeniczność (niejednorodność)
- Np. system Intranetowy może składać się ze sprzętu:
- komputerów klasy mainframe
- stacji roboczych UNIX
- komputerów PC pracujących pod MS Windows
- komputerów Apple Macintosh
- central telefonicznych, robotów, zautomatyzowanych linii produkcyjnych
- ...włączać różnorodne protokoły komunikacyjne: Ethernet, FDDI, ATM, TCP/IP, Novell Netware, protokoły oparte na RPC,...
- ...bazować na różnych systemach zarządzania bazą danych/dokumentów: Oracle,SQL Server, DB2, Lotus Notes,....
- ...oraz wymieniać pomiędzy sobą niejednorodne dane, podlegające różnym modelom danych, schematom, semantyce, mechanizmom dostępu,...
- Przyczyny heterogeniczności
- Niezależność działania: wytwórcy systemów nie uzgadniają między sobą ich cech. Standardy, o ile się pojawiają, są spóźnione, niekompletne i nie przestrzegane w 100%.
- Konkurencja: wytwórcy systemów starają się wyposażyć systemy w atrakcyjne cechy, których nie posiadają konkurujące systemy
- Różnorodność pomysłów: Nie zdarza się, aby było jedno rozwiązanie dla złożonego problemu. Różne zespoły znajdują różne rozwiązania, bazujące często na odmiennych celach i założeniach.
- Efektywność finansowa i kompromisy: Wytwórcy oferują produkty o różnej cenie, funkcjonalności i jakości, zgodnie z wyczuciem potencjalnych potrzeb klientów i maksymalizacją swoich zysków.
- Systemy spadkowe (legacy): Systemy, które dawno zostały wdrożone i działają efektywnie, nie mogą być z tego działania wyłączone. Nie jest możliwe (lub jest bardzo kosztowne) zastąpienie ich nowymi systemami. Nowe systemy, o podobnym przeznaczeniu, posiadają inne założenia, cechy i funkcjonalności
- Przenaszalność
- Typy przenaszalności:
- Na poziomie składni, koncepcji języka i edukacji (np. SQL-92).
- Na poziomie kodu źródłowego (np. C++ (?), JDBC).
- Na poziomie interpretowanego kodu skryptowego lub pośredniego (np. Java).
- Na poziomie kodu binarnego (? - trudno podać przykład).
- Przenaszalność wymaga precyzyjnej specyfikacji składni i semantyki języka, oraz wyeliminowania z niego własności specyficznych dla poszczególnych platform.
- Wiele standardów nie spełnia kryterium przenaszalności z powodu niedospecyfikowania i/lub nie spełniania standardu przez wytwórców systemów.
- Przenaszalność jest celem standardów SQL, CORBA, ODMG, WebServices - niekoniecznie celem już osiągniętym.
- Przenaszalność realizuje kod pośredni języka Java, ale dotyczy to funkcjonalności niskiego poziomu, np. nie dotyczy API do baz danych.
- Autonomia
- Autonomia lokalnej bazy danych w federacji baz danych oznacza, że:
- Lokalne dane podlegają lokalnym priorytetom, regułom własności, autoryzacji dostępu, bezpieczeństwa, itd.
- Lokalna BD może udostępniać aplikacjom działającym na federacji baz danych tylko określoną część swoich danych i usług.
- Włączenie lokalnej BD do federacji nie może powodować konieczności zmiany programów aplikacyjnych działających na lokalnej BD.
- Federacja może przetwarzać lokalne zasoby tylko poprzez interfejs programowania aplikacji (API) specyficzny dla lokalnego systemu. Inne metody (np. bezpośredni dostęp do plików) są niedozwolone.
- Federacja nie może żądać od lokalnej bazy danych zmiany/rozszerzenia jej usług (np. udostępnienia lokalnego dziennika transakcji).
- Możliwa jest pewna skala autonomii. Pojęcie autonomii jest raczej intuicyjne.
- Autonomia jest także spekulacyjnym ideałem.
- Współdziałanie może oznaczać również konieczność dostosowania się lokalnego serwera, czyli rezygnację z części autonomii.
- Niezależność danych
- Oznacza, że nie ma potrzeby zmiany kodu programów aplikacyjnych mimo zmian organizacji lub schematów danych.
- Jest osiągana poprzez interfejsy programistyczne umożliwiające dostęp do danych na odpowiednim poziomie abstrakcji, gdy niewidoczne są szczegóły organizacji i implementacji danych.
- Fizyczna niezależność danych: ukrycie detali organizacji fizycznej i technik dostępu, dzięki czemu możliwa jest ich zmiana bez wpływu na kod aplikacji.
- Logiczna niezależność danych: umożliwienie niektórych zmian schematu logicznego bez wpływu na kod aplikacji, np. dodanie atrybutów do relacji, zmiana kolejności atrybutów, zmiana ich typów, utworzenie nowych relacji, itd.
- Ewolucja schematu (schema evolution): umożliwienie daleko idących zmian schematu danych.
- Implikuje konwersję danych i konwersję (poprawienie) aplikacji.
- Idealistycznie, może polegać na utworzeniu perspektyw (views) dla starych lub nowych danych.
- Ontologia
- W filozofii: nauka o bytach, teoria bytu, opis charakteru i struktury rzeczywistości, specyfikacja konceptualizacji.
- W sztucznej inteligencji: formalna specyfikacja (przy użyciu logiki matematycznej) obiektów, pojęć i innych bytów, które istnieją w pewnej dziedzinie, oraz formalna specyfikacja związków, które pomiędzy tymi bytami zachodzą.
Podejście sztucznej inteligencji jest naiwne.
Np. Giełda Papierów Wartościowych: wiele tysięcy stron aktów prawnych, zarządzeń, regulacji, itd. Jako (dożywotnia) kara dla sztucznego (ćwierć-) inteligenta wypisującego bzdury na temat "formalnej ontologii": niech to zapisze przy użyciu formuł rachunku predykatów.
- W biznesie (ontologia biznesowa, business ontology): wszystko to, co projektanci systemów informatycznych powinni wiedzieć o biznesie, aby poprawnie napisać aplikacje wspomagające ten biznes.
- Wiedza ta powinna być formalnie zapisana w pewnym standardowym i uzgodnionym język, np. XML/RDF.
- Ontologia jest też rozumiana jako społeczna umowa / kontrakt / standard / regulacja prawna i nie ma nic wspólnego z logiką.
- Ontologia i metadane
- Głównym celem prac na biznesową ontologią jest standardyzacja następujących elementów:
- Gramatyki opisów poszczególnych bytów,
- Nazw i znaczeń nazw obowiązujących w ramach danego biznesu (np. co oznaczają słowa "autor", "klient", "instrument", "akcja", itd.),
- Ograniczeń związanych z opisywanymi bytami,
- Metadanych związanych z bytami (autor opisu, data stworzenia opisu, data ostatniej aktualizacji, itd.),
- Dopuszczalnych operacji na bytach.
- W tym zakresie zapis ontologii jest pewną meta-bazą danych, w które ustala się zarówno strukturę samej bazy danych, jak i pewne dodatkowe informacje (meta-atrybuty) będące podstawą przetwarzania bazy danych.
- Nieco inne podejście prezentuje standard RDF opracowany przez W3C, gdzie ontologię reprezentują wyrażenia RDF.
- Metadane
- Metadane są kluczowe dla wielu rozproszonych aplikacji, ponieważ umożliwiają rozpoznanie z zewnętrz własności lokalnego zasobu danych
- Ogólna definicja: są to dane o danych - co dane zawierają, jaką mają budowę, jakie jest ich znaczenie, jakim podlegają ograniczeniom, jak są zorganizowane, przechowywane, zabezpieczane, udostępniane, itd.
- Metadane są pewnym rozszerzeniem pojęcia schematu bazy danych, albo też pewną implementacją tego schematu w postaci katalogów.
- Metadane przykrywają także informację niezależną od treści samych danych, np. kiedy pewna dana została utworzona, w jakim jest formacie, kto jest jej autorem, do kiedy jest ważna, itd.
- Opisy danych zawarte w metadanych mają dwie podstawowe zalety:
- Zawierają wspólne abstrakcje dotyczące reprezentacji danych, takie jak format; ogólnie "wyciągają przed nawias" wszystkie wspólne informacje, co redukuje znacznie objętość samych danych;
- Reprezentują wiedzę dziedzinową (ontologię); umożliwiają wnioskowanie o danych, mogą być przez to użyte do redukowania dostępu do samych danych.
- Klasyfikacja metadanych
- Metadane niezależne od treści danych: lokacja danych, data modyfikacji, typ kamery służącej do sporządzenia zdjęcia, itd. Mimo, że nie składają się bezpośrednio na treść danych, mogą być ważnym kryterium wyszukiwania.
- Metadane zależne od treści danych: rozmiar dokumentu, liczba kolorów, liczba wierszy, liczba kolumn w tabeli. Metadane zależne od treści mogą być dalej podzielone na:
- Bezpośrednie metadane dotyczące treści, np. indeksy, klasyfikacje, itd.
- Metadane opisujące treść: adnotacje o zawartości zdjęcia, np. opis zapachu kwiatu przedstawionego na zdjęciu.
- Metadane niezależne od dziedziny biznesowej, której dotyczy treść, np. definicje typu dokumentu HTML/SGML
- Metadane zależne od dziedziny biznesowej, np. schemat danych lub opis ontologii biznesowej
- Podział na dane i metadane nie jest do końca jasny i silnie zależy od nastawienia projektanta i podziału zadań podczas redakcji treści danych.
- Protokół wymiany informacji w rozproszonej BD
- Protokół wymiany informacji pomiędzy rozproszonymi miejscami musi uwzględniać:
- przesyłanie danych z jednego miejsca do drugiego miejsca
- przesyłanie zleceń (np. zapytań) do odległych miejsc celem przetwarzania danych
- zwrotne przesyłanie wyników tych zleceń do zlecającego klienta
- automatyczną dystrybucję niektórych metadanych (np. schematu BD) pomiędzy uczestników rozproszonej bazy danych.
- przesyłanie zapytań dotyczących metadanych
- przekazywanie wyników zapytań dotyczących metadanych do pytającego
- Aktualnie, protokoły takie istnieją w bardzo uproszczonej lub silnie wyspecjalizowanej formie
- IIOP (Internet Inter-Orb Protocol) - bardzo uproszczony
- LDAP (Lightweight Directory Access Protocol) - silnie wyspecjalizowany
- Wiele ośrodków prowadzi prace badawcze nad uniwersalnymi protokołami, opartymi o różnorodne języki zapytań.
- Migracje obiektów
- Migracja: przemieszczanie się obiektów między węzłami sieci, przy czym obiekty muszą być skojarzone (statycznie lub dynamicznie związane) ze swoimi klasami i przechowywanymi w ramach tych klas metodami. Problemy:
- Określenie jednostki migracji
- Śledzenie obiektów
- Utrzymywania porządku w katalogu systemu bazy danych
- Okresowa kondensacja łańcuchów obiektów pośrednich
- Przemieszczanie obiektów złożonych
- Zapewnienie globalnej przestrzeni nazw
- Zapewnienie właściwych mechanizmów zakresu i wiązania
- Dostępność metod umożliwiających przetwarzanie obiektów
- Jak dotąd, metody są najczęściej składowymi aplikacji, a nie bazy danych. Konsekwencją jest to, że po przemieszczeniu obiektu aplikacja działająca w jego nowym miejscu musi mieć wbudowane (powielone, skompilowane, zlinkowane) metody do jego przetwarzania.
- Oprogramowanie komponentowe
- Komercyjny buzzword, marzenie informatyków od 30 lat.
- Oznacza technologie zmierzające do budowy standardów oraz wspomagającego je oprogramowania, które pozwoliłoby na składanie dużych aplikacji lub systemów z komponentów, na zasadzie podobnej do składania komputera z podzespołów.
- Inne terminy: mega-programming, programming-in-the-large.
- Jako przykłady wymienia się teraz: OMG CORBA, OpenDoc firm Apple, IBM i innych, technologia .NET/COM/DCOM, Java Beans i Enterprise Java Beans.
- Komponenty mają wiele sukcesów.
Istnieją jednak problemy utrudniające szerokie ich stosowanie
- problemy z osiągnięciem akceptowalnej wydajności,
- trudności w precyzyjnym a jednocześnie dostatecznie abstrakcyjnym wyspecyfikowaniu interfejsów pomiędzy komponentami,
- dynamiczny postęp w informatyce, powodujący pojawianie się coraz to nowych wymagań na interfejsy.
- Obiektowość w rozproszonych bazach danych
- Obiektowość zakłada zwiększenie stopnia abstrakcji, przystosowanie modeli realizacyjnych systemów informatycznych do naturalnych konstrukcji i obrazów myślowych projektantów, programistów i użytkowników.
- Główny problem - opanowanie złożoności przy wytwarzaniu oprogramowania.
- Punktem zainteresowania twórców narzędzi informatycznych stają się procesy myślowe zachodzące w umysłach osób pracujących nad oprogramowaniem => modelowanie pojęciowe.
- Obiektowość przerzuca ciężar problemu z kwestii narzędziowej (jak mam to zrobić?) na kwestię merytoryczną (co mam zrobić i po co?).
- Źródła złożoności projektu oprogramowania
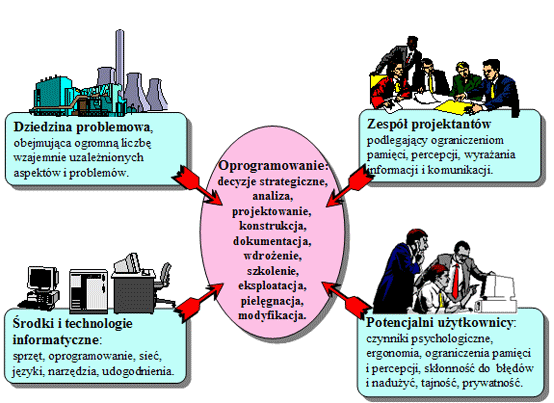
- Jak walczyć ze złożonością ?
- Zasada dekompozycji: rozdzielenie złożonego problemu na podproblemy, które można rozpatrywać i rozwiązywać niezależnie od siebie i niezależnie od całości.
- Zasada abstrakcji: eliminacja, ukrycie lub pominięcie mniej istotnych szczegółów rozważanego przedmiotu lub mniej istotnej informacji; wyodrębnianie cech wspólnych i niezmiennych dla pewnego zbioru bytów i wprowadzaniu pojęć lub symboli oznaczających takie cechy.
- Zasada ponownego użycia: wykorzystanie wcześniej wytworzonych schematów, metod, wzorców, komponentów projektu, komponentów oprogramowania, itd.
- Zasada sprzyjania naturalnym ludzkim własnościom: dopasowanie modeli pojęciowych i modeli realizacyjnych systemów do wrodzonych ludzkich własności psychologicznych, instynktów oraz mentalnych mechanizmów percepcji i rozumienia świata.
- Zasada hierarchicznej klasyfikacji bytów dziedziny przedmiotowej, dla lepszego jej rozumienia
- Modelowanie pojęciowe
- Projektant i programista muszą dokładnie wyobrazić sobie problem oraz metodę jego rozwiązania. Zasadnicze procesy tworzenia oprogramowania zachodzą w ludzkim umyśle i nie są związane z jakimkolwiek językiem programowania.
- Pojęcia modelowania pojęciowego (conceptual modeling) oraz modelu pojęciowego (conceptual model) odnoszą się procesów myślowych i wyobrażeń towarzyszących pracy nad oprogramowaniem.
- Modelowanie pojęciowe jest wspomagane przez środki wzmacniające ludzką pamięć i wyobraźnię. Służą one do przedstawienia rzeczywistości opisywanej przez dane, procesów zachodzących w rzeczywistości, struktur danych oraz programów składających się na konstrukcję systemu.
- Perspektywy w modelowaniu pojęciowym
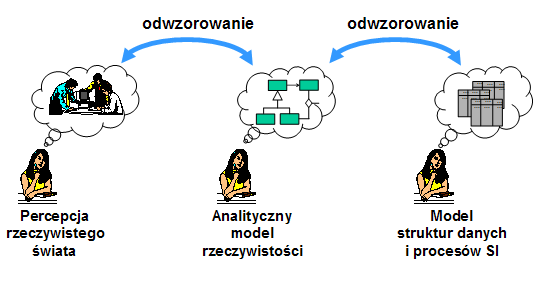
- Trwałą tendencją w rozwoju metod i narzędzi projektowania oraz konstrukcji SI jest dążenie do minimalizacji luki pomiędzy myśleniem o rzeczywistym problemie a myśleniem o danych i procesach zachodzących na danych.
- Przykład: pojęciowy schemat obiektowy w UML
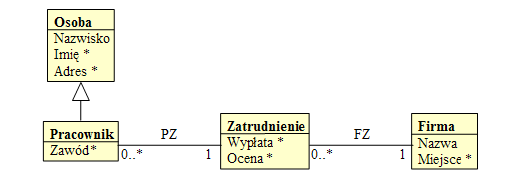
- Nie więcej niż 10 sekund zastanawiania się, co ten diagram przedstawia i jak jest semantyka jego elementów.
- Potem można już programować np. w C++ lub Java.
- Co otrzymamy po odwzorowaniu tego schematu na schemat relacyjny?
- Schemat relacyjny
-
pokaż animację
- Jest to jedno z kilku możliwych rozwiązań.
- Schemat relacyjny jest trudniejszy do odczytania i zinterpretowania.
- Programista będzie musiał co najmniej 10 minut zastanawiać się, jaką semantykę mają tabele, atrybuty i zaznaczone powiązania.
- Efektem jest zwiększona skłonność do błędów (mylnych interpretacji).
- Skutki niezgodności modelu pojęciowego i realizacyjnego
- Programy odwołujące się do schematu relacyjnego są dłuższe od programów odwołujących się do schematu obiektowego (30% - 70%).
- Ma to ogromne znaczenie dla tempa tworzenia oprogramowania, jego jakości, pielęgnacyjności, itd.
- Programy te są też zwykle znacznie wolniejsze.
- Mini przykład: Podaj adresy pracowników pracujących w firmach zlokalizowanych w Radomiu

- Zapytanie w SQL jest znacznie dłuższe wskutek tego, że w SQL konieczne są "złączeniowe" predykaty (takie jak k.NrF=z.NrF i następne) kojarzące informację semantyczną "zgubioną" w relacyjnej strukturze danych.
- Rozproszone obiektowe bazy danych
- Problemy są podobne jak w przypadku rozproszonych relacyjnych BD.
- Nie jest jednak pewne czy do przetwarzania zapytań w tych systemach będą się odnosić te same metody.
- Problemy, różniące przetwarzanie zapytań w rozproszonych obiektowych BD i w rozproszonych relacyjnych BD:
- Obiekty nie zawsze są implementowane jako "płaskie" zapisy.
- Obiekty mogą mieć referencje do obiektów zlokalizowanych w innych węzłach sieci.
- Przetwarzanie zapytań może dotyczyć kolekcji złożonych obiektów
- Zapytania mogą mieć odwołania do metod.
- Przetwarzanie zapytań w rozproszonych systemach obiektowych jest tematem bardzo istotnym. Standard ODMG tym się nie zajmuje.
- Jak dotąd, w zakresie przetwarzania rozproszonych zapytań nie rozwiązano podstawowych problemów koncepcyjnych.
- Niektóre z problemów mogą nie mieć ogólnego rozwiązania.
- Rozproszona obiektowa baza danych
- Przedmiotem przetwarzania i wymiany informacji w obiektowej rozproszonej bazie danych są obiekty. Zarządzanie rozproszonymi obiektami ma na celu utrzymywanie spójności i przezroczystości (niewidoczności) geograficznego rozproszenia obiektów.
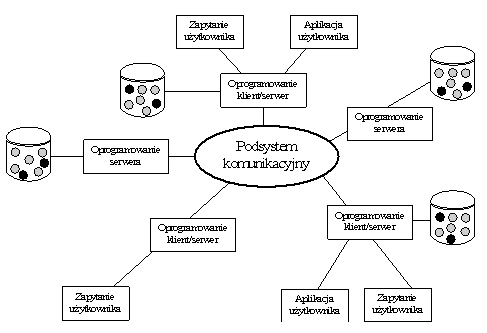
- Zalety rozproszonych obiektów
- Zgodność z logiką biznesu - bezpośrednia implementacja obiektów biznesowych.
- Umożliwienie projektantom opóźnienie decyzji - gdzie i jakie usługi powinny być zapewnione.
- Skalowalność aplikacji: mała zależność czasu reakcji systemu od zwiększenia ilości danych, liczby użytkowników, liczby węzłów.
- Dekompozycja aplikacji na elementy wykonawcze (obiekty, metody,...).
- Przyrostowe dodawanie/odejmowanie funkcjonalności ("płacę tylko za to, czego używam").
- Podział zasobów i zbalansowanie obciążeń.
- Współbieżność i asynchroniczne przetwarzanie.
- Elastyczność zmian w oprogramowaniu (konserwacja), w szczególności, przenoszenie obiektów i usług do innych miejsc.
- Możliwość przyłączania aplikacji spadkowych (funkcjonujących wcześniej jako scentralizowane).
 Info
Info Wykłady
Wykłady Skorowidz
Skorowidz