1. Formatowanie, lokalizacja i internacjonalizacja
Programy powinny prezentować wartości liczb, dat, czasu w określonych formatach,
Formaty te zależą od kraju lub regionu (języka używanego w kraju/regionie
oraz innych kulturowo utrwalonych reguł). Krótko mówiąc zależą od lokalizacji
. Również treść komunikatów wyświetlanych przez program lub opisów jakichś
elementów GUI (a nawet ikon czy dźwięków używanych w programie) jest zależna
od lokalizacji. Zatem - z jednej strony - programy powinny być dostosowane
do konkretnych lokalizacji. Z drugiej strony często powstaje potrzeba przygotowania
programów w taki sposób, by - bez rekompilacji - mogły działać w różnych lokalizacjach.
Tym właśnie zagadnieniom - szczególnie istotnym w takich krajach jak Polska
- poświęcony jest niniejszy rozdział. Równoczesnie warto zaznaczyć,
że także poza sferą internacjonalizacji i bez specjalnego zajmowania się
ustawieniami regionalnymi prezentowane tu narzędzia stanowią istotny element
warstzatu programistycznego. Bez nich niemożliwe jest bowiem odpowiednie
formatowanie liczb i operowanie na datach.
1.1. Lokalizacje
W języku angielskim okreslane jest to terminem
locale. Po polsku nie ma dobrego odpowiednika, używamy więc słowa lokalizacja
zarówno w znaczeniu locale jak i dla określenia sposobu oprogramowania aplikacji
w taki sposób, by działała ona własciwie dla danych ustawień regionalnych
Specyficzne
dla danego języka, regionu/kraju - reguły, dotyczące prezentacji różnych
informacji (np.formatowania liczb i dat, pisowni tekstów, porządku alfabetycznego)
nazwiemy lokalizacją.
Do rozwiązywania zagadnień lokalizacyjnych służy w Javie cały zestaw klas
(skupiony przede wszystkim w pakiecie java.text, ale nie tylko). Zestaw ten
został opracowany przez firmę Taligent, wchodzącą w skład koncernu
IBM i wdrożony przez Sun w Javie w wersji 1.1, Bez większych zmian przetrwał
on w kolejnych wersjach Javy do dziś, natomiast zespół lokalizacyjny z Taligent
przekształcił się w Unicode group w IBM Globalization Center of Competency
w Cupertino i zajął się doskonaleniam i rozwijaniem swojego pierwotnego produktu
oraz przenoszeniem go do języków C++ i C, a wszystko na zasadach "open source".
W efekcie powstała biblioteka o nazwie International Components for Unicode,
obejmujący poszerzone wersje klas lokalizacyjno-internacjonalizacyjnych,
a także pewne dodatkowe klasy, których w standardzie Javy brak. Biblioteka
wdraża najnowsze standardy Unicode (w tej chwili Unicode 4.0) i jest dostępna
w wersjach dla języków Java (ICU4J), C++ i C (ICU4C) na stronie http://oss.software.ibm.com/icu/.
Generalnie będziemy się tu zajmować standardowymi klasami Javy, gdzieniegdzie tylko przywołując dodatki i rozszerzenia z ICU4J
W Javie lokalizacje reprezentowane są przez obiekty klasy Locale z pakietu java.util.
Lokalizacja określana jest przez kombinację:
- kodu języka,
- kodu kraju,
- kodu wariantu.
Kody te - wartości typu String - podajemy przy tworzeniu obiektu klasy Locale
jako argumenty konstruktora tej klasy, przy czym mamy do dyspozycji trzy
przeciążone konstruktory:
Locale(String language) |
Locale(String language,
String country) |
Locale(String language,
String country,
String variant) |
Kod języka - to kombinacja dwóch małych liter, określająca język wg standardu
ISO-639 (zob dostępne kody : http://www.ics.uci.edu/pub/ietf/http/related/iso639.txt)
Kod kraju - to dwuliterowa kombinacja dwóch dużych liter, określająca kraj
wg standardu ISO-3166 (http://www.chemie.fu-berlin.de/diverse/doc/ISO_3166.html)
Kod wariantu - jest dodatkową informacją, którą możemy dodać i która nie
musi spełniać żadnych standardów, wobec czego jest specyficzna w danych warunkach (np. pakietu lokalizacyjnego) lub dla danej
aplikacji.
Przykłady:
Locale a = new Locale("en", "GB"); // język angielski, kraj Wielka Brytania
Locale b = new Locale("en", "US"); // język angielski, kraj Stany Zjednoczone
Locale c = new Locale("en"); // język angielski, kraj nieokreślony
Locale d = new Locale("pl", "PL", "Zakopane");
// Powyżej definiujemy wariant lokalizacyjny - "Zakopane"
// język jest polski, kraj - Polska
// ale dodatkowo nasza aplikacja może skorzystać ze zdefiniowanego wariantu
// jednak tylko nasze programy będą wiedziały co z takim wariantem należy robić
// może np. wyświetlać komunikaty w gwarze?
Uwaga: dla niektórych lokalizacji
w Javie są określone warianty. Np. tradycyjny Tajski, albo - w pakietach
ICU4J - dla krajów Europejskiej Unii Monetarnej warianty PREEURO (przed
wprowadzeniem euro).
Obiekt klasy Locale określa lokalizację (czyli wspomniane wcześniej reguły),
Zastosowanie tych reguł - przy przetwarzaniu i formatowaniu informacji -
spoczywa na obiektach innych klas. Te klasy, które biorą pod uwagę wymagania
lokalizacyjne nazywają się czułymi na lokalizację (locale-sensitive).
Należą do nich:
|
Klasa
|
Przeznaczenie
|
NumberFormat (i pochodne)
|
Do formatowania liczb
|
Calendar (i pochodne)
|
Do operowania na datach i czasie
|
DateFormat (i pochodne)
|
Do formatowania dat i czasu
|
Collator
|
Do określania porządku alfabetycznego
|
BreakIterator
|
Do zlokalizowanego rozbioru tekstu
|
Każdy program w Javie - przy uruchomieniu, na podstawie właściwości ustalonych dla platformy systemowej - uzyskuje tzw. domyślną lokalizację
. Możemy się dowiedzieć jaka to jest lokalizacja za pomocą odwołania Locale.getDefault()
i możemy zmienić tę lokalizację używając metody Locale.setDefault(Locale).
Aby przetwarzać informacje w zlokalizowanej formie posługujemy się obiektami
klas czułych na lokalizację. Dla zastosowania domyślnych reguł lokalizacyjnych
uzyskujemy te obiekty za pomocą statycznych metod get...Instance() bez argumentu, określającego lokalizację.
Np. kod na listingu pokazuje domyślną lokalizację i zgodnie z tą lokalizacją
wypisuje bieżącą datę oraz liczbę 1234567.1, przy czym w trakcie działania
zmienia domyślną lokalizację i ponawia wyprowadzanie informacji.
import java.text.*;
import java.util.*;
public class DefLok {
static public void report() {
Locale defLoc = Locale.getDefault();
System.out.println("Domyślna lokalizacja : " + defLoc);
DateFormat df = DateFormat.getDateInstance(DateFormat.LONG);
NumberFormat nf = NumberFormat.getInstance();
System.out.println(df.format(new Date()));
System.out.println(nf.format(1234567.1));
}
public static void main(String[] args) {
report();
Locale.setDefault(new Locale("en"));
report();
}
}
Wydruk programu:
Domyślna lokalizacja : pl_PL
12 lipiec 2003
1_234_567,1
Domyślna lokalizacja : en
July 12, 2003
1,234,567.1
Zwróćmy uwagę:
- formaty dat i liczb dla różnych lokalizacji różnią się,
- zmiana domyślnej lokalizacji dotyczy wszystkich klas czułych na lokalizację.
Klasy lokalizacyjnie-czułe pozwalają również na uzyskiwanie ich obiektów
przetwarzających informacje w sposób wymagany przez konkretną (nie domyślną)
lokalizację, W tym celu używamy statycznych metod get...Instance(...) z argumentem
typu Locale - określającym konkretną lokalizację.
Np. poniższy program wyprowadz datę w lokalizacji domyślnej, a liczbę - najpierw
w domyślnej, a później zgodnej z językiem angielskim.
import java.text.*;
import java.util.*;
public class MiscLok {
public static void main(String[] args) {
System.out.println("Domyślna lokalizacja : " + Locale.getDefault());
DateFormat df = DateFormat.getDateInstance(DateFormat.LONG);
System.out.println(df.format(new Date()));
double num = 123.4;
NumberFormat nf = NumberFormat.getInstance();
System.out.println("Liczba " + num +
" w lokalizacji domyślnej: " + nf.format(num));
nf = NumberFormat.getInstance(new Locale("en"));
System.out.println("Liczba " + num +
" w lokalizacji angielskiej: " + nf.format(num));
}
}
Domyślna lokalizacja : pl_PL
12 lipiec 2003
Liczba 123.4 w lokalizacji domyślnej: 123,4
Liczba 123.4 w lokalizacji angielskiej: 123.4
Uwaga: liczby różnią się separatorem miejsc dziesiętnych (przecinek dla Polski, kropka dla krajów anglojęzycznych).
Zatem możemy - w trakcie działania programu - ustalać lokalizacje zarówno
ogólnie (dla wszystkich klas lokalizacyjnie-czułych), jak i dla każdego konkretnego
obiektu tych klas.
Jednak nie wszystkie możliwe lokalizacje (określone w standardzie ISO) są
przez Javę podtrzymywane (nie dla wszystkich zdefiniowano reguły formatowania liczb i czasu
czy też traktowania tekstów).
Dostępne z poziomu Javy lokalizacje można uzyskać za pomocą metod Locale[] getAvailableLocales()
, zdefiniowanych w klasach Locale oraz wszystkich klasach czułych na lokalizację.
Metody te zwracają tablice dostępnych lokalizacji. Generalnie, będą to te
same zestawy lokalizacji.
Poniższy program wypisuje wszystkie dostępne lokalizacje.
import java.util.*;
import java.text.*;
public class Lokal1 {
public static void main(String[] args) {
// Tablica dostępnych lokalizacji
Locale[] loc = Locale.getAvailableLocales();
System.out.println("Kod języka" + "#" +
"Kod kraju" + "#" +
"Kod wariantu" + "#" +
"Język" + "#" +
"Kraj" + "#" + "Wariant"
);
for (int i=0; i<loc.length; i++) {
String countryCode = loc[i].getCountry(); // kod kraju
String langCode = loc[i].getLanguage(); // kod języka
String varCode = loc[i].getVariant(); // wariant
// lokalizacja opisana w języku domyślnej lokalizacji (polskim)
String kraj = loc[i].getDisplayCountry();
String jezyk = loc[i].getDisplayLanguage();
String wariant = loc[i].getDisplayVariant();
System.out.println(langCode + "#" +
countryCode + "#" +
varCode + "#" +
jezyk + "#" + kraj + "#" + wariant);
}
}
}
Uwaga: warto w tym programie zwrócić uwagę na użycie różnych metod wobec obiektów klasy Locale.
Wynik działania programy pokazuje tablica (będąca jednocześnie przewodnikeim po aktualnie dostępnych w Javie lokalizacjach).
| Kod języka | Kod kraju | Kod wariantu | Język | Kraj | Wariant |
| ar |
|
| arabski |
|
|
| ar | AE |
| arabski | Zjednoczone Emiraty Arabskie |
|
| ar | BH |
| arabski | Bahrajn |
|
| ar | DZ |
| arabski | Algeria |
|
| ar | EG |
| arabski | Egipt |
|
| ar | IQ |
| arabski | Irak |
|
| ar | JO |
| arabski | Jordan |
|
| ar | KW |
| arabski | Kuwejt |
|
| ar | LB |
| arabski | Liban |
|
| ar | LY |
| arabski | Libia |
|
| ar | MA |
| arabski | Maroko |
|
| ar | OM |
| arabski | Oman |
|
| ar | QA |
| arabski | Katar |
|
| ar | SA |
| arabski | Arabia Saudyjska |
|
| ar | SD |
| arabski | Sudan |
|
| ar | SY |
| arabski | Syria |
|
| ar | TN |
| arabski | Tunezja |
|
| ar | YE |
| arabski | Jemen |
|
| be |
|
| białoruski |
|
|
| be | BY |
| białoruski | Białoruś |
|
| bg |
|
| bułgarski |
|
|
| bg | BG |
| bułgarski | Bułgaria |
|
| ca |
|
| kataloński |
|
|
| ca | ES |
| kataloński | Hiszpania |
|
| cs |
|
| czeski |
|
|
| cs | CZ |
| czeski | Republika Czeska |
|
| da |
|
| duński |
|
|
| da | DK |
| duński | Dania |
|
| de |
|
| niemiecki |
|
|
| de | AT |
| niemiecki | Austria |
|
| de | CH |
| niemiecki | Szwajcaria |
|
| de | DE |
| niemiecki | Niemcy |
|
| de | LU |
| niemiecki | Luksemburg |
|
| el |
|
| grecki |
|
|
| el | GR |
| grecki | Grecja |
|
| en | AU |
| angielski | Australia |
|
| en | CA |
| angielski | Kanada |
|
| en | GB |
| angielski | Wielka Brytania |
|
| en | IE |
| angielski | Irlandia |
|
| en | IN |
| angielski | Indie |
|
| en | NZ |
| angielski | Nowa Zelandia |
|
| en | ZA |
| angielski | Republika Południowej Afryki |
|
| es |
|
| hiszpański |
|
|
| es | AR |
| hiszpański | Argentyna |
|
| es | BO |
| hiszpański | Boliwia |
|
| es | CL |
| hiszpański | Chile |
|
| es | CO |
| hiszpański | Kolumbia |
|
| es | CR |
| hiszpański | Kostaryka |
|
| es | DO |
| hiszpański | Republika Dominikany |
|
| es | EC |
| hiszpański | Ekwador |
|
| es | ES |
| hiszpański | Hiszpania |
|
| es | GT |
| hiszpański | Gwatemala |
|
| es | HN |
| hiszpański | Honduras |
|
| es | MX |
| hiszpański | Meksyk |
|
| es | NI |
| hiszpański | Nikaragua |
|
| es | PA |
| hiszpański | Panama |
|
| es | PE |
| hiszpański | Peru |
|
| es | PR |
| hiszpański | Portoryko |
|
| es | PY |
| hiszpański | Paragwaj |
|
| es | SV |
| hiszpański | Salwador |
|
| es | UY |
| hiszpański | Urugwaj |
|
| es | VE |
| hiszpański | Wenezuela |
|
| et |
|
| estoński |
|
|
| et | EE |
| estoński | Estonia |
|
| fi |
|
| fiński |
|
|
| fi | FI |
| fiński | Finlandia |
|
| fr |
|
| francuski |
|
|
| fr | BE |
| francuski | Belgia |
|
| fr | CA |
| francuski | Kanada |
|
| fr | CH |
| francuski | Szwajcaria |
|
| fr | FR |
| francuski | Francja |
|
| fr | LU |
| francuski | Luksemburg |
|
| hi | IN |
| hindi | Indie |
|
| hr |
|
| chorwacki |
|
|
| hr | HR |
| chorwacki | Chorwacja |
|
| hu |
|
| węgierski |
|
|
| hu | HU |
| węgierski | Węgry |
|
| is |
|
| islandzki |
|
|
| is | IS |
| islandzki | Islandia |
|
| it |
|
| włoski |
|
|
| it | CH |
| włoski | Szwajcaria |
|
| it | IT |
| włoski | Włochy |
|
| iw |
|
| hebrajski |
|
|
| iw | IL |
| hebrajski | Izrael |
|
| ja |
|
| japoński |
|
|
| ja | JP |
| japoński | Japonia |
|
| ko |
|
| koreański |
|
|
| ko | KR |
| koreański | Korea Południowa |
|
| lt |
|
| litewski |
|
|
| lt | LT |
| litewski | Litwa |
|
| lv |
|
| łotewski |
|
|
| lv | LV |
| łotewski | Łotwa |
|
| mk |
|
| macedoński |
|
|
| mk | MK |
| macedoński | Macedonia |
|
| nl |
|
| holenderski |
|
|
| nl | BE |
| holenderski | Belgia |
|
| nl | NL |
| holenderski | Holandia |
|
| no |
|
| norweski |
|
|
| no | NO |
| norweski | Norwegia |
|
| no | NO | NY | norweski | Norwegia | Nynorsk |
| pl |
|
| polski |
|
|
| pl | PL |
| polski | Polska |
|
| pt |
|
| portugalski |
|
|
| pt | BR |
| portugalski | Brazylia |
|
| pt | PT |
| portugalski | Portugalia |
|
| ro |
|
| rumuński |
|
|
| ro | RO |
| rumuński | Rumunia |
|
| ru |
|
| rosyjski |
|
|
| ru | RU |
| rosyjski | Rosja |
|
| sh |
|
| serbo-chorwacki |
|
|
| sh | YU |
| serbo-chorwacki | Jugosławia |
|
| sk |
|
| słowacki |
|
|
| sk | SK |
| słowacki | Słowacja |
|
| sl |
|
| słoweński |
|
|
| sl | SI |
| słoweński | Słowenia |
|
| sq |
|
| albański |
|
|
| sq | AL |
| albański | Albania |
|
| sr |
|
| serbski |
|
|
| sr | YU |
| serbski | Jugosławia |
|
| sv |
|
| szwedzki |
|
|
| sv | SE |
| szwedzki | Szwecja |
|
| th |
|
| tajlandzki |
|
|
| th | TH |
| tajlandzki | Tajlandia |
|
| th | TH | TH | tajlandzki | Tajlandia | TH |
| tr |
|
| turecki |
|
|
| tr | TR |
| turecki | Turcja |
|
| uk |
|
| ukraiński |
|
|
| uk | UA |
| ukraiński | Ukraina |
|
| zh |
|
| chiński |
|
|
| zh | CN |
| chiński | Chiny |
|
| zh | HK |
| chiński | Hong Kong |
|
| zh | TW |
| chiński | Tajwan |
|
| en |
|
| angielski |
|
|
| en | US |
| angielski | Stany Zjednoczone Ameryki |
|
Uwaga: tabela pokazuje lokalizacje dostępne w Javie 1.4.1. Przy
użyciu biblioteki ICU4J uzyskamy większy zestaw dostępnych lokalizacji.
Należy tu zaobserwować następujące cechy:
- możemy formować lokalizacje tylko na podstawie języka,
- dodatkowa specyfikacja kraju może różnicować formaty językowe zgodnie z tradycjami kulturowymi danego kraju,
- istnieją kraje z kilkoma obowiązującymi językami,
- dla niektórych lokalizacji podano dodatkowe warianty.
Poniższy przykładowy program pokazuje wykorzystanie prostej klasy Locale w celu tłumaczenia nazw krajów na różne języki.
import java.util.*;
import java.text.*;
import javax.swing.*;
class CountryTranslator {
public static void main(String[] args) {
Locale[] loc = Locale.getAvailableLocales();
Map map = new HashMap();
String kraj;
// Dodanie dostępnych lokalizacji do mapy
// klucz: nazwa kraju po polsku, wartośc - lokealizacja
for (int i=0; i<loc.length; i++) {
String countryCode = loc[i].getCountry(); // kod kraju
if (countryCode.equals("")) continue;
kraj = loc[i].getDisplayCountry();
map.put(kraj, loc[i]);
}
String msg = "Podaj kraj";
String in = "";
while((kraj = JOptionPane.showInputDialog(msg)) != null ) {
// Pobieramy lokalizację dla podanego kraju
Locale savedLoc = (Locale) map.get(kraj);
if (savedLoc == null) continue;
msg = "Podaj kody języków, rozdzielone spacjami";
while((in = JOptionPane.showInputDialog(null, msg, in)) != null ) {
StringTokenizer st = new StringTokenizer(in);
if (st.countTokens() == 0) continue;
String rep = "Nazwa kraju " + kraj + ":\n";
// Dla kolejnych kodów języków
// uzyskujemy nazwę kraju w języku odpowiadającym
// lokalizacji związanej z kodem jęsyka
while(st.hasMoreTokens()) {
Locale lang = new Locale(st.nextToken());
rep += lang.getDisplayLanguage() + " = " +
savedLoc.getDisplayCountry(lang) + "\n";
}
JOptionPane.showMessageDialog(null,rep);
}
msg = "Podaj kraj";
}
System.exit(0);
}
}
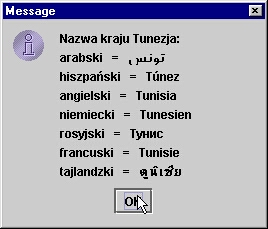 W tym programie wykorzystaliśmy fakt, iż metody getDisplay... użyte bez argumentów
zwracają opisy w języku lokalizacji domyślnej (np. loc.getDisplayLanguage()
zwróci opis języka po polsku), a użyte z argumentem-lokalizacją zwracają
opis w języku podanej lokalizacji (np. loc1.getDisplayCountry(loc2) zwróci
nazwę kraju, związanego z lokalizacją loc1 w języku lokalizacji loc2).
W tym programie wykorzystaliśmy fakt, iż metody getDisplay... użyte bez argumentów
zwracają opisy w języku lokalizacji domyślnej (np. loc.getDisplayLanguage()
zwróci opis języka po polsku), a użyte z argumentem-lokalizacją zwracają
opis w języku podanej lokalizacji (np. loc1.getDisplayCountry(loc2) zwróci
nazwę kraju, związanego z lokalizacją loc1 w języku lokalizacji loc2).
Przykładowy wynik działania programu pokazano na rysunku.
1.2. Formatowanie liczb
Gdy wyprowadzamy liczby rzeczywiste w postaci znakowej np. za pomocą metody
System.out.println(...), to nie mamy wpływu na ich formatowanie (np. ile
jest pokazywanych miejsc dziesiętnych). Np. wynikiem takiego fragmentu programu:
double d = 10/3.0;
System.out.println(d);
będzie:
3.3333333333333335
Bardzo często będziemy potrzebować "sformatowanego" wydruku liczby (np. z trzema miejscami dziesiętnymi)
W pakiecie java.text znajdziemy klasy, które umożliwiają formatowanie liczb.
Aby w powyższym przykładzie uzyskać trzy miejsca dziesiętne możemy np. użyć klasy NumberFormat:
NumberFormat nf = NumberFormat.getInstance();
nf.setMaximumFractionDigits(3);
String wynik = nf.format(d);
System.out.println(wynik);
Tutaj:
- statyczna metoda getInstance() zwraca obiekt formatujący - formator,
- za pomocą metody setMaximumFractionDigits(..) ustalamy, że ten formator
ma formatować liczby w taki sposób, by maksymalna liczba cyfr po przecinku
wynosiła 3,
- po czym za pomocą metody format uzyskujemy napis reprezeentujący liczbę
d, z maksymalnie trzema miejscami po przecinku i wypisujemy wynik, który
teraz będzie wyglądał tak: 3,333
- podkreślmy jeszcze raz (omawialiśmy
to w poprzednim punkcie), że sposób formatowania liczb jest zależny od lokalizacji;
zastosowana tu lokalizacja domyślna (polska) używa jako separatora miejsc
dziesiętnych przecinka.
Wygodniejszy i bardziej uniwersalny sposób formatowania liczb polega na specyfikowaniu
wzorców formatu. Mogą one być stosowane wobec formatorów, które są obiektami
klasy DecimalFormat.
Klasa DecimalFormat jest podklasą klasy NumberFormat, a metoda getInstance()
z klasy NumberFormat tak naprawdę zwraca referencję do obiektu tej właśnie
podklasy.
Możemy postąpić tak:
- stworzyć obiekt klasy DecimalFormat, podając jako argument konstruktora wzorzec formatowania,
- wywołać metodę format na rzecz tego obiektu.
Na przykład:
double d = 10/3.0;
DecimalFormat dform = new DecimalFormat("###.###");
String wynik = dform.format(d);
System.out.println(wynik);
Tutaj otrzymamy wynik: 3,333, bowiem zastosowany wzorzec formatowania
mówi o tym, że napis reprezentujący liczbę ma zawierać cyfry na pozycjach
calkowitych (przy czym wiodące zera nie będą pokazywane, a liczba cyfr będzie
odpowiednia dla wyniku), znak reprezentujący separator miejsc dziesiętnych
oraz co najwyżej trzy cyfry po przecinku (przy czym nieznaczące zera nie
będą pokazywane, a ostatnia pokazana cyfra będzie zaokrąglona).
Wzorce formatowania są łańcuchami znakowymi i mają następującą postać:
[prefiks][częśc_całkowita][.część_dziesiętna][sufiks]
gdzie:
- prefiks i sufiks - dowolny ciąg znaków oprócz znaków specjalnych,
- część całkowita i część dziesiętna - zero lub więcej znaków specjalnych
'#' albo zero lub więcej znaków specjalnych '0' oraz ew. pojedyncze inne
znaki specjalne.
Uwagi:
- nawiasy kwadratowe oznaczają opcjonalność elememetu wzorca, z tym, że co najmniej jeden z elementów musi wystąpić;
- jako wzorzec formatujący można podac dwa wzorce w powyższej postaci,
rozdzielone średnikiem; pierwszy z nich będzie dotyczył liczb dodatnich,
drugi - ujemnych.
Najważniejsze znaki specjalne używane we wzorcach formatujących podaje tabela.
| Symbol | Opis |
|---|
| 0 | cyfra, jeśli jest nieznaczącym zerem pokazywana jako 0 |
| # | cyfra, nieznaczące zera nie są pokazywane |
| . | miejsce separatora dziesiętnego |
| , | miejsce separatora grup cyfr (np. tysięcy) |
| E | miejsce separatora dla notacji inżynieryjnej lub naukowej ( np. 1E-11) |
| ; | separator formatu dla liczb dodatnich i formatu dla liczb ujemnych
<
/td> |
| - | znak minus |
| % | powoduje mnożenie liczby przez 100 i pokazanie jej w postaci procentowej
|
| ¤ | symbol waluty (np. zł); użyty dwukrotnie daje międzynarodowy symbol waluty |
| ' | ujęte w apostrofy znaki specjalne mogą być pokazywane w części prefiks lub sufiks
|
Program na wydruku pokazuje jak można korzystać z różnych formatów.
import java.text.*;
import java.math.*;
public class Format1 {
public static void show(double n1, Double n2, BigDecimal n3,
String format) {
DecimalFormat df = new DecimalFormat(format);
System.out.println("Format " + format);
System.out.println("Liczba: " + n1 + " wygląda tak: " + df.format(n1));
System.out.println("Liczba: " + n2 + " wygląda tak: " + df.format(n2));
System.out.println("Liczba: " + n3 + " wygląda tak: " + df.format(n3));
}
public static void main(String[] args) {
double num1 = 1.346;
Double num2 = new Double(0.765474);
BigDecimal num3 = new BigDecimal("100.2189091");
show(num1, num2, num3, "#.##");
show(num1, num2, num3, "#.## %");
show(num1, num2, num3, "#.0000");
show(num1, num2, num3, "#.00 ¤");
show(num1, num2, num3, "#.00 ¤¤");
show(num1, num2, num3, "[ 000.0 ]");
}
}
Wyniki jego dzialania pokazuje wydruk.
Format #.##
Liczba: 1.346 wygląda tak: 1,35
Liczba: 0.765474 wygląda tak: 0,77
Liczba: 100.2189091 wygląda tak: 100,22
Format #.## %
Liczba: 1.346 wygląda tak: 134,6 %
Liczba: 0.765474 wygląda tak: 76,55 %
Liczba: 100.2189091 wygląda tak: 10021,89 %
Format #.0000
Liczba: 1.346 wygląda tak: 1,3460
Liczba: 0.765474 wygląda tak: ,7655
Liczba: 100.2189091 wygląda tak: 100,2189
Format #.00 ¤
Liczba: 1.346 wygląda tak: 1,35 zł
Liczba: 0.765474 wygląda tak: ,77 zł
Liczba: 100.2189091 wygląda tak: 100,22 zł
Format #.00 ¤¤
Liczba: 1.346 wygląda tak: 1,35 PLN
Liczba: 0.765474 wygląda tak: ,77 PLN
Liczba: 100.2189091 wygląda tak: 100,22 PLN
Format [ 000.0 ]
Liczba: 1.346 wygląda tak: [ 001,3 ]
Liczba: 0.765474 wygląda tak: [ 000,8 ]
Liczba: 100.2189091 wygląda tak: [ 100,2 ]
Zwrócmy uwagę, że za pomocą metody format(...) można formatowac nie
tylko liczby typu double, ale również typu long oraz obiekty klas pochodnych
od Number (np. Double, Float, Long, Integer) i BigInteger oraz BigDecimal.
Klasy formatujące liczby
są przygotowane na prezentację liczb według reguł lokalizacyjnych. Jeśli
w metodzie getInstance() nie podamy lokalizacji - będzie użyta lokalizacja domyślna, w naszym przypadku
polska, wedle której separatorem miejsc dziesiętnych jest przecinek.
Jak uzyskać kropkę zamiast przecinka? Możemy zmienić lokalizację na taką,
w której seperatorem jest kropka (np. angielską) np. tak:
DecimalFormat df = (DecimalFormat)
NumberFormat.getInstance(new Locale("en", "US"));
df.applyPattern(format);
Ale wtedy utracimy polskie symbole waluty, zamiast nich pojawią się dla
Stanów Zjednoczonych USD, dla innych anglojęzycznych krajów inne symbole,
a jeśli nie podamy kraju - XXX (nieznana waluta).
Możemy co prawda ustalić walutę za pomocą metody setCurrency(...), użytej wobec formatora, ale wykorzystajmy raczej to, że
- z każdą lokalizacją związany jest zestaw symboli
używanych przy formatowaniu liczb (jest to obiekt klasy DecimalFormatSymbols),
- możemy go łatwo uzyskać od formatora dla domyślnej lokalizacji (metoda
getDecimalFormatSymbols())
- i zmienić wybrany symbol (za pomoca odpowiedniej
metody klasy DecimalFormatSymbols).
Zmiana separatora miejsc dziesiętnych na kropkę może wyglądać tak:
DecimalFormat df = new DecimalFormat(format); // formator w domyślnej lokalizacji
DecimalFormatSymbols sym = df.getDecimalFormatSymbols(); // symbole
sym.setDecimalSeparator('.'); // ustalenie separatora miejsc dziesiętnych
Teraz nasz program wyprowadzi np. zamiast 1,35 zł napis 1.35 zł.
Inne symbole używane przy formatowaniu i metody ich zmian opisane są w dokumentacji.
Zwykle jednak będziemy chcieli wypisywać liczby w takiej postaci, w jakiej
przyjęto dla danej lokalizacji i tutaj rola formatorów jest nieoceniona,
łatwo bowiem ustalić potrzebną lokalizację (oprócz wspomnianych wcześniej
sposobów można też stworzyć obiekt klasy DecimalFormatSymbols dla lokalizacji
określanej przez argument konstruktora tej klasy i użyć tego obiektu przy
tworzeniu formatora DecimalFormat - konstruktor DecimalFormat(String format,
DecimalFormatSymbols symbole)).
Zwróćmy uwagę, że metoda getInstance(...) klasy NumberFormat jest metodą
fabryczną - zwraca obiekt określonej podklasy klasy NumberFormat. Obecnie
jest to obiekt klasy DecimalFormat, ale - jak napisano w dokumentacji -
to niekoniecznie musi być zagwarantowane w przyszłości, tak że dla większej
przenośności kody należało by przed formatowaniem dziesiętnym sprawdzać
czy zwrócony przez getInstance() obiekt jest obiektem klasy DecimalFormat.
Możemy też uzyskać specjalne formatory (będące teraz również obiektami klasy
DecimalFormat, ale o specjalnych właściwościach) do formatowania:
- liczb całkowitych - metoda NumberFormat.getIntegerInstance(...)
- wartości wyrażonych w walucie - metoda NumberFormat.getCurrencyInstance(...)
- wartości w procentach - metoda NumberFormat.getPercentInstance(...)
Te swoiste warianty są jak gdyby prostszą drogą uzyskiwania efektów podobnych
do użycia wzorców formatowania, o ile zależy nam tylko na tych właśnie (całkowitych,
walutowych, procentowych) formatach.
Oczywiście, wszystkie te metody mają wersje z argumentem okreslającym lokalizację.
Formatory potrafią także dokonywać przekształceń odwrotnych: zamieniać napisy
reprezentujące liczby na postać binarną tych liczb. Istotnie, jeśli mam jakiś
tekst, w którym liczby podawane są z przecinkami jako separatorami miejsc
dziesiętnych, to metoda parseDouble z klasy Double nie da oczekiwanych wyników.
Zamiast niej możemy zastosować metodę parse(..) zdefiniowaną w klasach formatorów
i metoda ta poradzi sobie z dowolnymi sposobami zapisu liczb wedle różnych
reguł lokalizacyjnych (a także wedle różnych formatów).
Do zamiany napisów reprezentujących liczby w danym formacie na ich binarną
postać można zastosować metodę parse(String) użytą na rzecz formatora.
Przy tym:
- metoda parse(...) zwraca referencję do obiektu podklasy klasy Number,
który - w zależności od wartości interpretowanego napisu może wskazywać na
Long lub Double,
- napis podlega interpretacji jako liczba zgodnie z lokalizacją (np.
w polskiej lokalizacji użycie przecinka jako sepratora miejsc dziesiętnych),
- jeżeli formator nie dotyczy walut, procentów i nie uzyskano go wg
wzorca formatowania, który zawiera inne od specjalnych znaki, to przekształcanie
napisu na liczbę będzie dokonywane dopóki można, tzn. dopóki kolejny znak
będzie stanowił (w danej lokalizacji) część liczby, pozostałe znaki zostaną
pominięte i nie wystąpi żaden wyjątek,
- dla prostego, ogólnego formatu liczbowego wyjątek wystąpi
tylko wtedy, gdy początek napisu nie da się zinterpretować jako liczba (wyjątek
klasy ParseException)
- przy interpretacji napisów wg specyficznych formatów (np. walutowego
lub wg rozbudowanych wzorców formatowania) napis musi być zgodny z formatem
i niezaleznie od tego czy niezgodność wystąpi na początku czy na końcu -
powstanie wyjątek ParseException.
Program na listingu pokazuje prosty przykład użycia metody parse(...).
import javax.swing.*;
import java.text.*;
public class Parse1 {
public static void main(String[] args) {
NumberFormat format = NumberFormat.getInstance();
String in,
msg = "Podaj liczbę";
Number num = null;
while ((in = JOptionPane.showInputDialog(msg)) != null) {
System.out.println("Wejście: " + in);
try {
num = format.parse(in);
} catch (ParseException exc) {
System.out.println("Wadliwe dane: " + in);
System.out.println(exc);
continue;
}
System.out.println("Parse daje: " +
num.getClass().getName()+ " = " + num);
}
System.exit(0);
}
}
Na wydruku przedstawiono efekty działania programu dla różnych danych wejściowych:
Wejście: 1
Parse daje: java.lang.Long = 1
Wejście: 1.111
Parse daje: java.lang.Long = 1
Wejście: 1,111
Parse daje: java.lang.Double = 1.111
Wejście: 1e16
Parse daje: java.lang.Long = 1
Wejście: 99999999999999999999999999999999999
Parse daje: java.lang.Double = 1.0E35
Wejście: 9999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999888888888888888888888888888888888888888888888888888888899999999999999999999999999999999999999999999999999
Parse daje: java.lang.Double = Infinity
Wejście: -1,213
Parse daje: java.lang.Double = -1.213
Wejście: 212a
Parse daje: java.lang.Long = 212
Wejście: aaaa
Wadliwe dane: aaaa
java.text.ParseException: Unparseable number: "aaaa"
Gdybyśmy w tym programie zamienili format na:
NumberFormat format = NumberFormat.getCurrencyInstance();
to:
wprowadzenie napisu 23 - dałoby wyjątek ParseException
wprowadzenie napisu 23 PLN - dałoby wyjątek ParseException
wprowadzenie napisu 23zł - dałoby wyjątek ParseException
i tylko po wprowadzeniu właściwiego domyślnego formatu walutowego:
23 zł
uzyskalibyśmy liczbę 23.
Jeśli natomiast użylibyśmy wzorca formatowania:
NumberFormat format = new DecimalFormat("[ #.0000 ]");
to akceptowane byłyby wyłącznie napisy, reprezentujące poprawne liczby ujęte w nawiasy kwadratowe (z okalającymi spacjami).
W tych przypadkach, gdy błąd może pojawić się nie tylko na samym początku
napisu, użyteczna może okazać się metoda getErrorOffset() z klasy ParseException,
która zwraca pozycję w napisie, na której pojawił się błąd.
Zobaczmy na przykładzie zmodyfikowanego programu:
public static void main(String[] args) {
NumberFormat format = new DecimalFormat("[ #.0000 ]");
//...
while ((in = JOptionPane.showInputDialog(msg)) != null) {
System.out.println("Wejscie: " + in);
try {
num = format.parse(in);
} catch (ParseException exc) {
System.out.println("Wadliwe dane: " + in);
System.out.println(exc);
System.out.println("Wadliwa pozycja: " + exc.getErrorOffset());
continue;
}
System.out.println("Parse daje: " +
num.getClass().getName()+ " = " + num);
}
}
Przykładowy wydruk zmodyfikowanego programu :
Wejscie: [23]
Wadliwe dane [23]
java.text.ParseException: Unparseable number: "[23]"
Wadliwa pozycja: 0
Wejscie: [ 23 ]
Parse daje: java.lang.Long = 23
Wejscie: [ 23
Wadliwe dane: [ 23
java.text.ParseException: Unparseable number: "[ 23 "
Wadliwa pozycja: 4
Wejscie: [ 23 a ]
Wadliwe dane: [ 23 a ]
java.text.ParseException: Unparseable number: "[ 23 a ]"
Wadliwa pozycja: 4
Wejscie: [ 23.000 ]
Wadliwe dane: [ 23.000 ]
java.text.ParseException: Unparseable number: "[ 23.000 ]"
Wadliwa pozycja: 4
Wejscie: [ 23, 00 ]
Wadliwe dane: [ 23, 00 ]
java.text.ParseException: Unparseable number: "[ 23, 00 ]"
Wadliwa pozycja: 5
Wejscie: [ 23,0 ]
Parse daje: java.lang.Long = 23
Inną formą metody parse z klas formatorów jest:
Number num = parse(String dane, ParsePosition pos);
Tutaj używamy obiektu pos klasy ParsePosition, który określa bieżącą pozycję rozbioru napisu dane oraz ew. pozycję (indeks) na której wystąpił błąd.
Rozbiór danych (wedle formatu) rozpoczyna się od pozycji okreslonej przez
podany obiekt klasy ParsePosition. Napis podlega interpretacji (dopóki kolejne
jego znaki można traktować jako znaki liczby wg danego formatu), po czym
bieżąca pozycja rozbioru (indeks) jest ustawiana za ostatnim zinterpretowanym
znakiem i zwracana jest liczba jako obiekt klasy Number.
Ta metoda nie zgłasza żadnych wyjątków. W przypadku błędu interpretacji (a
w zależności od formatu - występuje on albo tylko na początku napisu, albo
gdzieś dalej) zwracana jest wartość null, bieżąca pozycja nie ulega zmianie,
a indeks błędu ustawiany jest na znaku, który spowodowłą bład. Jeżeli nie
ma błędu indeks błędu ma wartość -1.
Pozycje (indeks) - bieżący i błędu - możemy uzyskiwac od obiektu ParsePosition
za pomocą metod getIndex() i getErrorIndex() oraz ustawiać za pomocą odpowiednich
metod setIndex(...) i setErrorIndex(...).
Program na wydruku pokazuje przykładowe użycie tej metody parse do wyodrębnienia
z pliku tekstowego wszystkich informacji zapisanych w formacie walutowym
(możemy sobie wyobrażać, że jest to plik opisujący jakieś wydatki, a naszym
zadaniem jest ich podsumowanie)
.import java.io.*;
import java.text.*;
import java.util.*;
public class Parse2 {
public static void main(String[] args) {
// Format walutowy w domyślnej lokalizacji
// czyli w PL np. 12 zł
NumberFormat format = NumberFormat.getCurrencyInstance();
// Lista wartości wydatków (zapisanych w tekście pliku)
List numList = new ArrayList();
try {
BufferedReader br = new BufferedReader(
new FileReader("testdata.txt")
);
// czytanie kolejnych wierszu
String in;
while ((in = br.readLine()) != null) {
int p = 0; // bieżący indeks rozbioru
int last = in.length() - 1; // ostatni indeks w wierszu
// Utworzenie pozycji rozbioru wiersza (od 0)
ParsePosition ppos = new ParsePosition(0);
// Dopóki nie dobiegliśmy do końca wiersza
while (p <= last) {
// Próbujemy pobrać kolejną liczbę w formacie walutowym
Number num = format.parse(in, ppos);
if (num == null) // jeżeli błąd,
p = ppos.getErrorIndex()+1; // indeks na znaku po błędzie
else { // jeżeli udało się sczytać wartość
numList.add(num); // dodajemy ją do listy
p = ppos.getIndex(); // indeks na następnym znaku po
}
ppos.setIndex(p); // ustawiamy następną pozycję
} // od której kontynuacja rozbioru
}
br.close();
} catch(Exception exc) {
exc.printStackTrace();
System.exit(1);
}
// Wypisanie i podsumowanie zapisanych w pliku wydatków
System.out.println("Wydatki w zł:");
double suma = 0;
for (Iterator iter = numList.iterator(); iter.hasNext(); ) {
Number val = (Number) iter.next();
System.out.println(val);
suma += val.doubleValue();
}
System.out.println("Wydano w sumie: " + format.format(suma));
}
}
Gdy użyjemy tego programu wobec pliku, zawierającego następujący tekst:
Wydano najpierw 123 zł na 23 kilo jabłek
Kolejny wydatek objął 77,77 zł (70 litrów maślanki)
a potem jeszcze doszło 999,99 zł w 4 ratach.
to w wyniku uzyskamy:
Wydatki w zł:
123
77.77
999.99
Wydano w sumie: 1 200,76 zł
Zwrócmy uwagę: tylko liczby zapisane w formacie walutowym zostały wyodrębnione, inne liczby nie były brane pod uwagę.
Przykład ten pokazuje dużą siłe klas formatorów. Ten program zadziała bez rekompilacji przy każdej innej domyślnej lokalizacji
i dla plików, w których dane zapisano w innej (właściwiej dla tej lokalizacji)
walucie.
Nieco brzydkie formatowanie wyniku w powyższym przykładzie można oczywiście
poprawić i to w dość prosty sposób. Oto przy formatowaniu liczb mamy swoisty
odpowiednik klasy ParsePosition. Tym razem jest to klasa FieldPosition
, która umożliwia uzyskiwanie informacji o początku i końcu pól sformatowanego
wyniku. W przypadku prostych liczb pola oznaczają część całkowitą i część
dziesiętną, co jest identyfikowane przez stałe statyczne z klasy NaumberFormat
o nazwach INTEGER_FIELD i FRACTIONAL_FIELD. Użycie FieldPosition w specjalnej
wersji metody format pozwala na dodatkowe formatowanie wyniku.
Zatem, aby mieć dodatkową kontrolę nad formatowaniem:
- tworzymy obiekt klasy FieldPosition, podając w konstruktorze o jaki rodzaj pola chodzi,
- po czym przekazujemy go jako ostatni argument specjalnej wersji metody
format, która ma też jako argumenty liczbę do sformatowania i StringBuffer
do którego dołączany jest wynik formatowania,
- i po użyciu metody format(...) możemy dowiedzieć się od obiektu FieldPosition
gdzie (na której pozycji) w buforze wynikowym zaczyna się dane pole (metoda
getBeginIndex()) i gdzie się kończy (metoda getEndIndex()).
Pokazuje to poniższy program, który stanowi modyfikację poprzedniego przykładu
dokonaną z myślą o wyrównywaniu wyprowadzanych wyników "na" separatorze miejsc
dziesiętnych.
public class ParseAndFormat {
public static void main(String[] args) {
// ... tutaj część analogiczna jak w poprzednim pzrykładzie
// ... czytanie danych z pliku i parsowanie liczb wg formatu walutowego
// ... dla przejrzystości format ten (uzyskiwany z getCurrencyInstance())
// ... nazwano cform (nazwa zmiennej)
// Wypisanie i podsumowanie przeczytanych z pliku wydatków
// formatowanie wyjścia za pomocą metody align (zob. dalej)
// w której używamy FieldPosition
// Format wyjściowy - walutowy, z dwoma miejscami dziesiętnymi
DecimalFormat outform = new DecimalFormat("#.00 ¤");
System.out.println("Wydatki w : " +
cform.getCurrency().getSymbol()); // symbol waluty
double suma = 0;
int i = 1;
final int DOTPOS = 30; // pozycja separatora miejsc dziesiętnych
for (Iterator iter = numList.iterator(); iter.hasNext(); i++ ) {
Number val = (Number) iter.next();
suma += val.doubleValue();
System.out.println(
align("Pozycja " + i, outform, val, DOTPOS)
);
}
System.out.println(
align("Wydano w sumie", outform, new Double(suma), DOTPOS)
);
}
// Metoda wyrównująca liczby na separatorze miejsc dziesiętnuych
// Liczba v formatowana zgodnie z formatem f
// poprzedzona jest napisem msg
// i taką liczbą kropek, by separatory miejsc dziesiętnych
// były wyrównane na pozycji width
static StringBuffer align(String msg, Format f, Number v, int width) {
//Interesuje nas pole - część całkowita liczby
FieldPosition fp = new FieldPosition(NumberFormat.INTEGER_FIELD);
// Bufor do którego zapisywana jest sformatowana liczba
// na początku bufora już zapisujemy msg (opis pozycji wydatków)
StringBuffer out = new StringBuffer(msg);
int msgLen = out.length();
// formatowanie: v = liczba, out - bufor wynikowy, fp - opis pola
f.format(v, out, fp);
// Po sformatowaniu metoda fp.getEndIndex() zwraca
// pozycję końca pola = części całkowitej liczby
// łatwo obliczyć liczbę dodatkowych (dotNum) "wypełniaczy",
// potrzebnych, by separator dziesiętny znalazł się na pozycji width
int dotNum = width - fp.getEndIndex();
// Wstawiamy do bufora - jako wypełniacze - kropki
while (dotNum-- > 0) {
out.insert(msgLen, '.');
}
return out;
}
}
Teraz wyniki przetwarzania naszego pliku tekstowego będą wyglądac następująco:
Wydatki w : zł
Pozycja 1..................123,00 zł
Pozycja 2...................77,77 zł
Pozycja 3..................999,99 zł
Wydano w sumie............1200,76 zł
Uwaga: program nie jest uniwesralny, gdyż pozycja "równania" na separatorze
miejsc dziesiętnych jest niezależna od długości poprzedzającego liczbę napisu
msg. Ogólnie, trzeba by najpierw określić maksymalną długość napisów wyprowadzanych
przed kolejnymi liczbami i dostosować do tego wielkość width. Pominęliśmy
jednak ten etap, aby nie zaciemniać ogólnego mechanimzu użycia FieldPosition.
Istnieją też inne sposoby formatowania liczb.
Wśród podklas klasy NumberFormat znajdziemy klasę ChoiceFormat.
Generalnie pozwala ona kojarzyć dowolne napisy z (półotwartymi z prawej
strony) przedziałami liczb. Formatowanie za jej pomocą polega na zastąpieniu
liczby, "trafiającej" w dany przedział, skojarzonym z tym przedziałem napisem.
Jedna z wersji konstruktorów klasy ChoiceFormat przyjmuje jako argumenty:
- tablicę liczb typu double, określająca pólotwarte (z prawej strony) przedziały liczbowe,
- tablicę napisów, kojarzonych z przedziałami.
Rozmiary obu tablic muszą być równe.
Liczby w tablicy muszą być uporządkowane w kolejności rosnącej.
Reguły działania na zdefiniowanych przedziałach i kojarzenia liczb trafiających
w dany przedział z napisami można opisać w następujący sposób.
Jeżeli:
double[] val = { .... }; // przedziały liczbowe
String[] msg = { ... }; // napisy
ChoiceFormat cf = new ChoiceFormat(val, msg);
double x = ...;
String out = cg.format(x);
to:
gdy val[0] < x, to out = msg[0],
gdy val[0] <= x < val[1], to out == msg[0],
gdy val[1] <= x < val[2], to out == msg[1].
gdy val[2] <= x < val[3], to out == msg[2].
...
gdy val[val.length-2] <= x < val[val.length-1], to out == msg[msg.length-2]
gdy val[val.length-1] <= x , to out = msg[msg.length-1]
Pokazuje to poniższy program:
import java.text.*;
public class ChoiceForm {
public static void main(String[] args) {
double[] vals = { -1, 0, 1, 10 };
String[] msg = { "x mniejsze od zera",
"0 <= x < 1",
"1 <= x < 10",
"x >= 10"
};
ChoiceFormat cf = new ChoiceFormat(vals, msg);
String in;
while ((in = JOptionPane.showInputDialog("Podaj x")) != null) {
double x = Double.parseDouble(in);
String out = cf.format(x);
System.out.println(x + " : " + out);
}
}
}
który może (w zależności od podawanych liczb) wyprowadzić np. taki wynik:
11.0 : x >= 10
10.0 : x >= 10
9.99999 : 1 <= x < 10
0.0 : 0 <= x < 1
1.0 : 1 <= x < 10
2.0 : 1 <= x < 10
-0.5 : x mniejsze od zera
-10000.0 : x mniejsze od zera
Korzystając z klasy ChoiceFormat czasem wygodnie będzie posłużyć się wzorcem formatowania.
Wzorzec definiujemy w postaci łańcucha znakowego (String):
liczba sep napis | liczba sep napis | liczba sep napis ....
gdzie kolejne, rozdzielone znakiem | fragmenty określają kojarzone przedziałów
i napisów, a jako separatora (sep) możemy użyć znaków # lub <.
Wzorzec podajemy jako argument konstruktora klasy ChoiceFormat.
Wyjaśnia to przykładowy program.
import javax.swing.*;
import java.text.*;
public class ChoiceForm2 {
public static void main(String[] args) {
String pattern =
"0#brak jablek |0<niecala polowa jablka |"+
"0.5#rowno pol jablka | 0.5<ponad polowa jablka |" +
"1#jedno jablko |1<niecale dwa jablka |" +
"2#dwa jablka |2<wiecej niż dwa jablka";
ChoiceFormat cf = new ChoiceFormat(pattern);
String in;
while ((in = JOptionPane.showInputDialog("Ile jest jabłek?")) != null) {
double x = Double.parseDouble(in);
String out = cf.format(x);
System.out.println("Podano: " + x + " Wynik: " + out);
}
}
}
a jego możliwy wynik wyhląda następująco:
Podano: 0.0 Wynik: brak jablek
Podano: 0.1 Wynik: niecala polowa jablka
Podano: 0.5 Wynik: rowno pol jablka
Podano: 0.6 Wynik: ponad polowa jablka
Podano: 1.0 Wynik: jedno jablko
Podano: 1.7 Wynik: niecale dwa jablka
Podano: 2.0 Wynik: dwa jablka
Podano: 2.1 Wynik: wiecej niż dwa jablka
Podano: 3.0 Wynik: wiecej niż dwa jablka
Podano: -1.0 Wynik: brak jablek
Klasa ChoiceFormat jest szczególnie użyteczna przy internacjonalizacji napisów
w programie z wykorzystaniem klasy MessageFormat - o czym będziemy mówić
dalej.
Uwaga: aby korzystać z klas pakietów ICU należy udostępnić archiwum
JAR z tymi pakietami. Możemy to uczynić na kilka sposobów:
- umieścić archiwum w katalogu javax katalogu instalacyjnego Javy (wtedy
biblioteka ICU stanie się standardowym rozszerzeniem - inaczej zwanym pakietem
opcjonalnym - i nasze programy będą miały do niej dostęp,
- umieścić nazwę archiwum JAR biblioteki ICU na ścieżce classpath,
- kompilować i uruchamiać programy z opcją -classpath, podając archiwum
JAR biblioteki ICU wraz z innymi elmentami ścieżki (%classpath%); przy uruchamianiu
klas z pakietu domyślnego nie należy zapomnieć o podaniu jako elementu ścieżki
bieżącego katalogu, oznaczanego kropką,
Pozwala ona na formatowanie liczb za pomocą definiowania zestawów reguł.
Przykładowe zdefiniowane już reguły dla formatora RuleBasedNumber to:
- SPELLOUT - przedstawianie liczb w postaci słownej,
- ORDINAL - przedstawianie liczb jako liczebników porządkowych (z odpowiednimi końcówkami),
- DURATION - przekształcanie liczb na jednostki czasu (godziny, minuty, sekundy).
Te reguły są już gotowe dla niektórych lokalizacji, nic nie stoi też na przeszkodzie,
by tworzyć własne reguły (np. dla innych lokalizacji lub całkiem innego rodzaju).
Opis sposobów definiowania reguł zawarty jest w dokumentacji ICU4J, tu przyjrzymy
się tylko przykładowym zastosowaniom gotowych reguł.
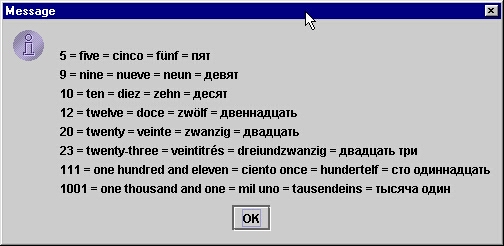
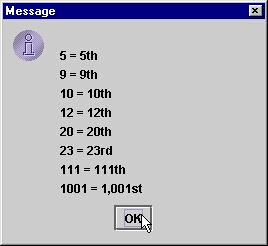
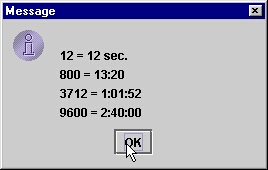
Poniższy program pokazuje najpierw słowny opis liczb w różnych lokalizacjach
(niestety formator SPELLOUT nie jest spolszczony), po czym liczby porządkowe
oraz czas (ale tylko po angielsku, bo formatory ORDINAL i DURATION nie są
zlokalizowane dla większości innych jezyków).
import com.ibm.icu.text.*; // podpakiet ICU - dla RuleBasedNumberFormat
import java.util.*; // Locale
import javax.swing.*; // JOptionPane
class RuleBasedNumberFormatTest {
public static void main(String[] args) {
// Lokalizacje
Locale[] loc = { new Locale("en"),
new Locale("es"),
new Locale("de"),
new Locale("ru"),
};
// Tablica formatorów typu SPELLOUT - dla każdej lokalizacji jeden
RuleBasedNumberFormat[] rbnfSpell =
new RuleBasedNumberFormat[loc.length];
// Utworzenie formatorów SPELLOUT
for (int i= 0; i < loc.length; i++) {
rbnfSpell[i] = new RuleBasedNumberFormat(
loc[i], RuleBasedNumberFormat.SPELLOUT
);
}
// Wartości do formatowania
long[] values = { 5, 9, 10, 12, 20, 23, 111, 1001 };
// Jako SPELLOUT
show(values, rbnfSpell);
// Jako liczby porządkowe - tylko angielskie
show(values,
new NumberFormat[] { new RuleBasedNumberFormat(
loc[0], RuleBasedNumberFormat.ORDINAL
)
}
);
// Formatowanie czasów wyrażonych w sekundach
// Tylko lokalizacja angielska
long[] times = { 12, 800, 3712, 9600 };
show(times,
new NumberFormat[] { new RuleBasedNumberFormat(
loc[0], RuleBasedNumberFormat.DURATION
)
}
);
System.exit(0);
}
// Ogólna metoda formatująca i pokazująca wyniki
// Argumenty: tablica liczb do sformatowania
// tablica formatorów
static void show(long[] val, NumberFormat[] rbnf) {
String msg = "";
for (int i=0; i < val.length; i++) {
msg += "\n" + val[i];
for (int j=0; j<rbnf.length; j++) {
msg += " = " + rbnf[j].format(val[i]);
}
}
JOptionPane.showMessageDialog(null, msg);
}
}
Wyniki działania programu pokazują kolejne rysunki.
Omawiane formatory potrafią wykonywać operacje odwrotne, np. przekształcać
liczby wyrażone słownie na ich wartości, a przy tym możliwe jest ustawienie
opcji "lenientParse", która "luźno" traktuje napisy (słowne wyrażenie liczb
może być różne np. ze spacjami, z myślnikami, w ogóle bez znaków rozdizielających
słowa, z różną wielkością liter itp.).
Zobaczmy przykład. Poniższy program "umie" odczytać słowne (angielskie) opisy liczb i przekształcić je w liczby.
import com.ibm.icu.text.*; // podpakiet ICU - dla RuleBasedNumberFormat
import java.util.*; // Locale
import java.text.*; // ParsePosition
import javax.swing.*; // JOptionPane
class LenientParseTest {
public static void main(String[] args) {
// formator typu SPELLOUT
RuleBasedNumberFormat rbnf = new RuleBasedNumberFormat(
new Locale("en"),
RuleBasedNumberFormat.SPELLOUT
);
// Ustalenie "luźnego" parsowania
rbnf.setLenientParseMode(true);
// Wartości do parsowania
String[] snum = { "twenty-one", "TWENTYone",
"one hundred and one",
"one-hundred-and-one",
"one-hundred AND one",
};
// Przekształcenie opisów na liczby
for (int i=0; i< snum.length; i++) {
Number val = rbnf.parse(snum[i], new ParsePosition(0));
System.out.println(snum[i] + " = " + val);
}
}
}
Wynik programu:
twenty-one = 21
TWENTYone = 21
one hundred and one = 101
one-hundred-and-one = 101
one-hundred AND one = 101
Formator parsuje również liczby opisywane w innych popularnych językach.
1.3. Waluty
Klasa Currency z pakietu java.util opisuje waluty. Obiekty tego typu są wykorzystywane
przez klasę DecimalFormat i możemy je np. stosować dla zmiany formatów walutowych
(metoda setCurrency(Currency) z klasy DecimalFormat).
Klasa Currency może być użyteczna w różnych sytuacjach.
Wyobraźmy sobie taki scenariusz: mamy stworzyć aplikację, która generuje
raporty o aktualnych kursach wybranych walut w kilku językach. Aktualne kursy
pobieramy z jakiegoś serwisu WEB na podstawie podanych międzynarodowych symboli
walut.
Aby taki program można było napisać, trzeba wiedzieć jakie są symbole walut i umieć tłumaczyć symbole walut na wybrane języki.
Informacje, które można uzyskać o walutach przedstawia w syntetycznej postaci poniższy program.
import java.util.*;
public class Waluty {
public static void main(String[] args) {
// Domyślna lokalizacja (w naszym przypadku polska)
Locale def = Locale.getDefault();
// Tablica dostępnych lokalizacji
Locale[] loc = Locale.getAvailableLocales();
char[] zera = { '0', '0', '0', '0', '0', '0' }; // do pokazu walut
for (int i=0; i<loc.length; i++) {
String countryCode = loc[i].getCountry(); // kod kraju
String langCode = loc[i].getLanguage(); // kod języka
if (countryCode.equals("")) continue;
// lokalizacja opisana w języku domyślnej lokalizacji (polskim)
String kraj = loc[i].getDisplayCountry(def);
String jezyk = loc[i].getDisplayLanguage(def);
// Waluta dla lokalizacji loc[i]
Currency c = Currency.getInstance(loc[i]);
String sym = c.getSymbol(); // symbol w domyślnej lokalizacji (pl)
String nsym = c.getSymbol(loc[i]); // symbol w danym kraju
String icode = c.getCurrencyCode(); // międzynarod. kod waluty
int cdig = c.getDefaultFractionDigits(); // ile może być miejsc dzies.
System.out.println(loc[i]+" kraj: "+kraj+" język: "+jezyk +
"\nwaluta: "+sym+" "+nsym+" "+icode +
" grosz = 1/1"+new String(zera,0,cdig)+" "+sym +
"\n============================================================"
);
}
}
}
Warto zwrócić uwagę na informację jaka jest minimalna cześć podstawowej jednostki
pieniężnej (tu nazwaliśmy to "groszem"), uzyskiwaną za pomocą metody getFractionDigits().
Fragment wydruku działania programu przedstawiono poniżej:
es_VE kraj: Wenezuela język: hiszpański
waluta: VEB Bs VEB grosz = 1/100 VEB
============================================================
et_EE kraj: Estonia język: estoński
waluta: EEK kr EEK grosz = 1/100 EEK
============================================================
fi_FI kraj: Finlandia język: fiński
waluta: EUR ? EUR grosz = 1/100 EUR
============================================================
fr_BE kraj: Belgia język: francuski
waluta: EUR ? EUR grosz = 1/100 EUR
============================================================
fr_CA kraj: Kanada język: francuski
waluta: CAD $ CAD grosz = 1/100 CAD
============================================================
fr_CH kraj: Szwajcaria język: francuski
waluta: CHF SFr. CHF grosz = 1/100 CHF
============================================================
hu_HU kraj: Węgry język: węgierski
waluta: HUF Ft HUF grosz = 1/100 HUF
============================================================
is_IS kraj: Islandia język: islandzki
waluta: ISK kr. ISK grosz = 1/100 ISK
============================================================
ja_JP kraj: Japonia język: japoński
waluta: JPY ? JPY grosz = 1/1 JPY
============================================================
ko_KR kraj: Korea Południowa język: koreański
waluta: KRW ? KRW grosz = 1/1 KRW
============================================================
pl_PL kraj: Polska język: polski
waluta: zł zł PLN grosz = 1/100 zł
============================================================
pt_BR kraj: Brazylia język: portugalski
waluta: BRL R$ BRL grosz = 1/100 BRL
============================================================
pt_PT kraj: Portugalia język: portugalski
waluta: EUR ? EUR grosz = 1/100 EUR
Pakiet ICU dostarcza dodatkowych możliwości, gdy chodzi o waluty. M.in. możemy
uzyskać bardziej opisową, stosowaną w podanej lokalizacji nazwę waluty. Pokazuje
to poniższy program.
import javax.swing.*;
import java.awt.*;
import java.util.Locale;
import com.ibm.icu.util.Currency;
public class Waluty1 {
public static void main(String[] args) {
Locale def = Locale.getDefault();
Locale en = new Locale("en", "US");
// Tablica dostępnych lokalizacji
Locale[] loc = Currency.getAvailableLocales();
boolean[] b = { false }; // dla getName() - oznacza normalny wynik
// w przeciwieństwie do wyniku dla ChoiceFormat
String out = "";
for (int i=0; i<loc.length; i++) {
String kraj = loc[i].getDisplayCountry(def);
if (kraj.equals("")) continue;
String lang = loc[i].getDisplayLanguage(def);
String variant = loc[i].getVariant();
// Waluta dla lokalizacji loc[i]
Currency c = Currency.getInstance(loc[i]);
String icode = c.getCurrencyCode(); // międzynarod. kod waluty
// symbol w danym kraju
String sym = c.getName(loc[i], Currency.SYMBOL_NAME, b);
// nazwa w danym kraju
String name = c.getName(loc[i], Currency.LONG_NAME, b);
// nazwa po angielsku
String enName = c.getName(en, Currency.LONG_NAME, b);
out += kraj + " " + lang + " " + variant +
"\nwaluta: "+icode+" "+sym+
"\n"+ name + '\n' + enName +
"\n------------------------------------------\n";
}
JFrame f = new JFrame();
JTextArea ta = new JTextArea();
ta.setFont(new Font("Dialog", Font.BOLD, 14));
ta.setText(out);
f.getContentPane().add(new JScrollPane(ta));
f.pack();
f.show();
}
}
Uwaga: aby móc bez problemów odczytywać znaki Unikodu wyniki pokazujemy w
polu tekstowym JTextArea (o programowaniu graficznych interfejsów użytkownika
zob. część D książki)
Fragmenty wyników działania programu prezentuje poniższy rysunek.
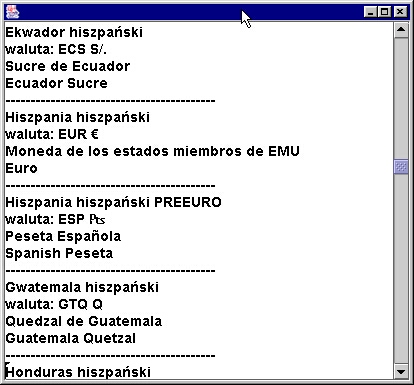
1.4. Strefy czasowe
Strefy czasowe są przedstawiane przez obiekty klasy TimeZone z pakietu java.util.
Aby uzyskać aktualną, domyślną dla komputera na którym działa nasz program,
strefę czasową stosujemy statyczną metodę getDefault() z klasy TimeZone.
O strefie czasowej możemy dowiedzieć się wielu interesujących informacji, co pokazuje poniższy program.
import java.util.*;
public class Strefy0 {
public static void main(String[] args) {
TimeZone tz = TimeZone.getDefault();
// --- Informacje o strefie czasowej
// identyfikator strefy
String id = tz.getID();
// różnica względem czasu standardowego (UCT)
int diff = tz.getRawOffset();
// czy strefa używa czasu letniego
boolean useDST = tz.useDaylightTime();
// ile czasu trzeba dodać do lokalnego zegara
// aby uzyskać czas bez ew. przesunięcia letniego
int dstSav = tz.getDSTSavings();
// Nazwa strefy
String defName = tz.getDisplayName();
// Krótka nazwa strefy
String shortName = tz.getDisplayName(useDST, TimeZone.SHORT);
// Nazwa strefy w podanym języku
String locName = tz.getDisplayName(new Locale("fr"));
// Dluga nazwa strefy
String fullName = tz.getDisplayName(useDST, TimeZone.LONG);
// Długa nazwa strefy w podanym języku
String locFullName = tz.getDisplayName(useDST, TimeZone.LONG,
new Locale("es"));
// Jaka jest aktualna różnica czasu TERAZ wobec UCT,
// z uwzględnieniem czasu letniego
Date teraz = new Date();
long ms = teraz.getTime();
int offset = tz.getOffset(ms);
System.out.println("ID = " + id);
System.out.println("RawOffset = " + diff);
System.out.println("useDaylightTime = " + useDST);
System.out.println("DSTSavings = " + dstSav);
System.out.println("DisplayName = " + defName);
System.out.println("DisplayName short = " + shortName);
System.out.println("DisplayName full = " + fullName);
System.out.println("DisplayName locale(\"fr\") = " + locName);
System.out.println("DisplayName full locale(\"es\") = " + locFullName);
System.out.println("Offset = " + offset);
}
}
i jego wyniki:
ID = Europe/Belgrade
RawOffset = 3600000
useDaylightTime = true
DSTSavings = 3600000
DisplayName = Central European Time
DisplayName short = CEST
DisplayName full = Central European Summer Time
DisplayName locale("fr") = Heure d'Europe centrale
DisplayName full locale("es") = Hora de verano de Europa Central
Offset = 7200000
Uwagi:
- identyfikatory stref są podawane w różnej postaci, najcześciej: region/miasto;
trzyliterowe identyfikatory stref czasowych (takie jak np. CET, AST, CST)
są również dostępne, ale nie powinny być używane ze względu na niejednoznaczność
(CST - to zarówno U.S. Central Standard Time jak i China Standard Time); UTC,
GMT i Zulu - oznaczają czas standardowy;
- nasza strefa czasowa - to czas środkowoeuropejski, mający tu pierwszy dostępny identyfikator Europe/Belgrad,
- różnice czasu podawane są w milisekundach,
- raw offset - pokazuje aktualną różnicę wobec czasu standardowego (UTC)
bez uwzględnienia przesunięcia czasu letniego; jest to czas, który trzeba
dodać do UTC, aby uzyskać "prawdziwą" godzinę (nie przesuniętą z uwagi na czas letni)
- różnica czasu dla podanej daty wobec UTC z uwzględnieniem czasu letniego pokazywana jest przez metodę getOffset().
W naszym programie możemy skonstruować dowolną strefę czasową, używając metody
TimeZone.getTimeZone(String ID) i podając jako argument identyfikator strefy
czasowej.
Listę dostępnych identyfikatorów można uzyskać jako tablicę Stringów za pomoca odwołania TimeZone.getAvailableIDs().
Poniższy przykładowy programik pokazuje jak można wyliczyć aktualną różnicę
czasu pomiędzy podanymi strefami czasowymi oraz jak można dowiedzieć się
jakie strefy czasowe mają podaną różnicę czasu wobec GMT.
import java.util.*;
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
public class Strefy1 {
public static void main(String[] args) {
// Konstruowanie stref czasowych
TimeZone myTz = TimeZone.getTimeZone("Europe/Warsaw");
TimeZone java = TimeZone.getTimeZone("Asia/Jakarta");
TimeZone cuba = TimeZone.getTimeZone("America/Havana");
// za pomocą pokazanej dalej metody getDiffMsg
// wyliczamy i pokazujemy aktualną różnicę czasu
// pomiędzy sterfami czasowymi
System.out.println(getDiffMsg(myTz, java));
System.out.println("--------------------------------------------------");
System.out.println(getDiffMsg(myTz, cuba));
System.out.println("--------------------------------------------------");
System.out.println(getDiffMsg(cuba, java));
System.out.println("--------------------------------------------------");
// Jakie strefy czasowe mają podaną różnicę czasu wobec GMT
for (int k = 12; k <= 14; k++) {
String[] ids = TimeZone.getAvailableIDs(k*3600000);
Arrays.sort(ids);
System.out.println(
"Strefy czasowe mające różnice +" + k + " godzin wobec GMT" );
for (int i=0; i < ids.length; i++) {
System.out.println(ids[i]);
}
System.out.println("--------------------------------------------------");
}
}
static String getDiffMsg(TimeZone z1, TimeZone z2) {
Date data = new Date();
long teraz = data.getTime();
double offset1 = z1.getOffset(teraz)/3600000.0;
double offset2 = z2.getOffset(teraz)/3600000.0;
double diff;
if (offset1 > offset2) diff = -(offset1 - offset2);
else diff = offset2 - offset1;
String out = "Różnica czasu pomiędzy" + '\n' +
z1.getID() + " i " + z2.getID() + '\n' +
"wynosi teraz : " + diff + " godz." + '\n' +
"W strefie " + z1.getID() +
(z1.inDaylightTime(data) ? " " : " nie ") +
"działa czas letni" + '\n' +
"W strefie " + z2.getID() +
(z2.inDaylightTime(data) ? " " : " nie ") +
"działa czas letni";
return out;
}
}
Wydruk:
Różnica czasu pomiędzy
Europe/Warsaw i Asia/Jakarta
wynosi teraz : 5.0 godz.
W strefie Europe/Warsaw działa czas letni
W strefie Asia/Jakarta nie działa czas letni
--------------------------------------------------
Różnica czasu pomiędzy
Europe/Warsaw i America/Havana
wynosi teraz : -6.0 godz.
W strefie Europe/Warsaw działa czas letni
W strefie America/Havana działa czas letni
--------------------------------------------------
Różnica czasu pomiędzy
America/Havana i Asia/Jakarta
wynosi teraz : 11.0 godz.
W strefie America/Havana działa czas letni
W strefie Asia/Jakarta nie działa czas letni
--------------------------------------------------
Strefy czasowe mające różnice +12 godzin wobec GMT
Antarctica/McMurdo
Antarctica/South_Pole
Asia/Anadyr
Asia/Kamchatka
Etc/GMT-12
Kwajalein
NST
NZ
Pacific/Auckland
Pacific/Fiji
Pacific/Funafuti
Pacific/Kwajalein
Pacific/Majuro
Pacific/Nauru
Pacific/Tarawa
Pacific/Wake
Pacific/Wallis
--------------------------------------------------
Strefy czasowe mające różnice +13 godzin wobec GMT
Etc/GMT-13
Pacific/Enderbury
Pacific/Tongatapu
--------------------------------------------------
Strefy czasowe mające różnice +14 godzin wobec GMT
Etc/GMT-14
Pacific/Kiritimati
--------------------------------------------------
1.5. Kalendarze
Informacje o datach i czasie są w Javie reprezentowane przez obiekty klasy Calendar.
Informacje o bieżącej dacie i czasie możemy uzyskać m.in. za pomocą odwołania:
Calendar c = Calendar.getInstance();
które zwraca obiekt - domyślny kalendarz dla domyślnej lokalizacji
ustawiony na bieżącą datę i czas w strefie czasowej właściwej dla domyślnej
lokalizacji.
Informacje o dacie i czasie są zapisane w polach obiektu-kalendarza. Dostęp do tych pól uzyskujemy za pomocą metody get(...)
, użytej na rzecz obiektu-kalendarza, z argumentem - stałą statyczną klasy
Calendar, okreslającą o jaki rodzaj informacji nam chodzi. Oprócz tego pewne
informacje, związane z właściwościami danego kalendarza lub dla danej lokalizacji
można uzyskać za pomocą innych metod get... (np. jaki jest pierwszy dzień
tygodnia - niedziela czy poniedziałek - getFirstDayOfWeek()).
Przykładowy program spełnia funkcję przewodnika po polach kalendarza, pokazują
ich znaczenie oraz sposoby uzyskiwania ich wartości.
import java.util.*;
public class Kal1 {
public static void say(String s) { System.out.println(s+'\n'); }
public static void main(String[] args) {
// uzyskanie kalendarza domyślnego
// (obowiązującgo dla domyślnej lokalizacji - tu dla Polski)
// ustawionego na bieżącą datę i czas
Calendar cal = Calendar.getInstance();
say("ERA.............. " + cal.get(Calendar.ERA) +
" (tu: 0=pne, 1=AD)");
say("ROK.............. " + cal.get(Calendar.YEAR));
say("MIESIĄC.......... " + cal.get(Calendar.MONTH) +
" (0-styczeń, 2-luty, ..., 11-grudzień)");
say("LICZBA DNI\n" +
"W MIESIĄCU....... " + cal.getActualMaximum(Calendar.DAY_OF_MONTH));
say("DZIEŃ MIESIĄCA... " + cal.get(Calendar.DAY_OF_MONTH));
say("DZIEŃ MIESIĄCA... " + cal.get(Calendar.DATE));
say("TYDZIEŃ ROKU..... " + cal.get(Calendar.WEEK_OF_YEAR));
say("TYDZIEŃ MIESIĄCA. " + cal.get(Calendar.WEEK_OF_MONTH));
say("DZIEŃ W ROKU..... " + cal.get(Calendar.DAY_OF_YEAR));
say("PIERWSZY DZIEŃ\n" +
"TYGODNIA......... " + cal.getFirstDayOfWeek() +
" (1-niedziela, 2-poniedziałek, ..., 7 sobota)");
say("DZIEŃ TYGODNIA... " + cal.get(Calendar.DAY_OF_WEEK) +
" (1-niedziela, 2-poniedziałek, ..., 7-sobota)");
say("GODZINA.......... " + cal.get(Calendar.HOUR) +
" (12 godzinna skala; następne odwolanie czy AM czy PM)");
say("AM/PM............ " + cal.get(Calendar.AM_PM) +
" (AM=0, PM=1)");
say("GODZINA.......... " + cal.get(Calendar.HOUR_OF_DAY) +
" (24 godzinna skala)");
say("MINUTA........... " + cal.get(Calendar.MINUTE));
say("SEKUNDA......... " + cal.get(Calendar.SECOND));
say("MILISEKUNDA: " + cal.get(Calendar.MILLISECOND));
int msh = 3600*1000; // liczba milisekund w godzinie
say("RÓŻNICA CZASU\n" +
"WOBEC GMT........ " + cal.get(Calendar.ZONE_OFFSET)/msh);
say("PRZESUNIĘCIE\n" +
"CZASU............ " + cal.get(Calendar.DST_OFFSET)/msh +
" (w Polsce obowiązuje w lecie)");
}
}
Na wydruku pokazano wyniki działania programu, uruchomionego we wtorek 6 maja 2003 roku o godzinie 18:05:00.
Wydruk:
ERA.............. 1 (tu: 0=pne, 1=AD)
ROK.............. 2003
MIESIĄC.......... 4 (0-styczeń, 2-luty, ..., 11-grudzień)
LICZBA DNI
W MIESIĄCU....... 31
DZIEŃ MIESIĄCA... 6
DZIEŃ MIESIĄCA... 6
TYDZIEŃ ROKU..... 19
TYDZIEŃ MIESIĄCA. 2
DZIEŃ W ROKU..... 126
PIERWSZY DZIEŃ
TYGODNIA......... 2 (1-niedziela, 2-poniedziałek, ..., 7 sobota)
DZIEŃ TYGODNIA... 3 (1-niedziela, 2-poniedziałek, ..., 7-sobota)
GODZINA.......... 6 (12 godzinna skala; następne odwolanie czy AM czy PM)
AM/PM............ 1 (AM=0, PM=1)
GODZINA.......... 18 (24 godzinna skala)
MINUTA........... 5
SEKUNDA......... 0
MILISEKUNDA: 550
RÓŻNICA CZASU
WOBEC GMT........ 1
PRZESUNIĘCIE
CZASU............ 1 (w Polsce obowiązuje w lecie)
Uwaga: należy zwrócić baczną uwagę na to, że indeksowanie miesięcy rozpoczyna
się od 0, a nie od 1 (czyli styczeń ma numer 0). Jest to fatalny błąd, który
popełniono w pierwszej wersji Javy, wprowadzając klasę Date. Twórcy klasy
Calendar (firma Taligent) mieli tego świadomość, ale - by nie wprowadzać
jeszcze większego zamieszania - pozostawili tę bardzo mylącą konwencję.
Za pomocą metod set... kalendarza możemy ustawiać jego bieżącą datę i czas.
Np. aby ustawić kalendarz na 7 maja 2003 roku na tę samą godzinę co "teraz" możemy napisać:
Calendar c = Calendar.getInstance();
c.set(2003, 4, 7); // rok 2003, indeks miesiąca = 4 (maj), dzień 7
a jeśli chcemy zarazem ustalić godzinę 18 minut 05 napiszemy:
c.set(2003, 4, 7, 18, 5);
Możemy też zmieniać (ustawiać) wartości poszczególnych pól.
Służą do tego metody, które wykonują operacje na datach.
Operacje na datach wykonujemy za pomocą następujących metod:
set(id_pola, wartość)
add(id_pola, wartość)
roll(id_pola, wartość)
gdzie:
id_pola - stała statyczna z klasy
Calendar, określająca pole na którym wykonywana jest oparacja,
wartość - nowa wartość pola.
Wszystkie w/w operacje uwzględniają reguły danego kalendarza, a różnica pomiędzy nimi jest następująca:
- set - ustala wartość pola; jeśli trzeba dostosowując inne pola (np.
ustawienie pola DAY_OF_MONTH na wartość 31 dla kalendarza ustawionego na
dowolną datę w czerwcu spowoduje, że kalendarz będzie wskazywał na 1 lipca,
gdyż w czerwcu jest tylko 30 dni),
- add - dodaje do pola podaną wartość, stosując przy tym arytmetykę
kalendarzową (np. dodanie do 30 maja 2 dni spowoduje ustawienie kalendarza
na 1 czerwca),
- roll - również wykonuje dodawanie, ale przy tym nie zmienia wartości
"starszych" pól np. jeżeli dodajemy dni i okaże się, że nowa data znajdzie
się w innym niż teraz miesiącu, to miesiąc nie zostanie zmieniony, zaś "nadwyżka"
dni (poza końcem bieżącego miesiąca) będzie dodawana od początku miesiąca.
Dokładne reguły obliczeniowe są podane w dokumentacji klasy Calendar.
Przykładowy program na wydruku testuje działanie omówionych metod.
import java.util.*;
import javax.swing.*;
public class TestKal {
public static void main(String[] args) {
String in;
int d = 0;
while ((in = JOptionPane.showInputDialog("DATE:")) != null) {
d = Integer.parseInt(in);
show("set", "DATE", Calendar.DATE, d);
show("add", "DATE", Calendar.DATE, d);
show("roll", "DATE", Calendar.DATE, d);
}
System.exit(0);
}
static void say(String s) { System.out.println(s); }
static void show(String oper, String what, int field, int value) {
Calendar c = Calendar.getInstance();
say("Teraz jest: " + c.getTime());
say("Operacja: " + oper + "(Calendar." + what + ", " + value + ")");
if (oper.equals("set")) c.set(field, value);
else if (oper.equals("add")) c.add(field, value);
else if (oper.equals("roll")) c.roll(field,value);
say("Aktualne ustawienia kalendarza: " + c.get(Calendar.YEAR) + '/'
+ (c.get(Calendar.MONTH) + 1) + '/' +
+ c.get(Calendar.DATE));
say("-----------------------------------------------------------");
}
}
a wydruk jego dzialania (dla kilku wprowadzonych wartości pola Calendar.DATE, okreslającego dzień miesiąca)
ilustruje działanie metod set, add i roll oraz róznice między nimi:
Teraz jest: Mon May 05 07:27:43 CEST 2003
Operacja: set(Calendar.DATE, 7)
Aktualne ustawienia kalendarza: 2003/5/7
-----------------------------------------------------------
Teraz jest: Mon May 05 07:27:43 CEST 2003
Operacja: add(Calendar.DATE, 7)
Aktualne ustawienia kalendarza: 2003/5/12
-----------------------------------------------------------
Teraz jest: Mon May 05 07:27:43 CEST 2003
Operacja: roll(Calendar.DATE, 7)
Aktualne ustawienia kalendarza: 2003/5/12
-----------------------------------------------------------
Teraz jest: Mon May 05 07:27:55 CEST 2003
Operacja: set(Calendar.DATE, 31)
Aktualne ustawienia kalendarza: 2003/5/31
-----------------------------------------------------------
Teraz jest: Mon May 05 07:27:55 CEST 2003
Operacja: add(Calendar.DATE, 31)
Aktualne ustawienia kalendarza: 2003/6/5
-----------------------------------------------------------
Teraz jest: Mon May 05 07:27:55 CEST 2003
Operacja: roll(Calendar.DATE, 31)
Aktualne ustawienia kalendarza: 2003/5/5
-----------------------------------------------------------
Teraz jest: Mon May 05 07:27:58 CEST 2003
Operacja: set(Calendar.DATE, 32)
Aktualne ustawienia kalendarza: 2003/6/1
-----------------------------------------------------------
Teraz jest: Mon May 05 07:27:58 CEST 2003
Operacja: add(Calendar.DATE, 32)
Aktualne ustawienia kalendarza: 2003/6/6
-----------------------------------------------------------
Teraz jest: Mon May 05 07:27:58 CEST 2003
Operacja: roll(Calendar.DATE, 32)
Aktualne ustawienia kalendarza: 2003/5/6
Uwaga: CEST oznacza Central European Summer Time
Zwróćmy uwagę na metodę getTime(). Wykorzystano ją w omawianym programie,
by łatwo wypisać datę i czas w jakiejś ludzkiej postaci,
Metody zdezaktualizowane (deprecated) są utrzymywane w standardowych
pakietach Javy ze względu na aplikacje, które zostały kiedyś napisane i odwołują
sie do tych metod. Pisząc nowe programy nie nalezy używac takich metod, nie
tylko dlatego, że istnieją inne, nowsze i lepsze metody, ale również dlatego,
że użycie metod zdezaktualizowanych w niektórych okolicnościach może prowadzić
do błędnego działania aplikacji.
Metoda ta zwraca obiekt klasy Date, reprezentujący datę i czas dla danego ustawienia kalendarza. Klasa
ta w dawnych wersjach Javy była stosowana do dzialania na datach i czasie,
ale ponieważ nie była ona zlokalizowana ani nie uwzględniała możliwośc istnienia
różnych kalendarzy, to w tej chwili większość jej metod jest zdezaktualizowana
i zamiast nich należy stosować metody klasy Calendar.
Jednak klasa Date nadal jest przydatna przy:
- porównywania dat (bowiem w klasie Date zdefiniowano metodę compareTo(...), której brakuje w klasie Calendar),
- szybkiem uzyskiwaniu standardowej angielskiej postaci napisów reprezentujących
daty (poprzez bezpośrednie lub automatyczne zastosowanie metody toString();
jest ona stosowana automatycznie przy konkatenacji napisu i zmiennej typu
Date lub przekazaniu argumentu typu Date metodzie println),
- oraz - co szczególnie ważne - przy formatowaniu dat i czasu za pomocą
metody format(...) formatorów daty i czasu (której argument jest
referencją do obiektu klasy Date) oraz przy przekształcaniu znakowej postaci
dat i czasy do obiektów klasy Date za pomocą metody parse(...) klasy DateFormat.
Porównywania dat i czasu możemy również łatwo dokonywać za
pomocą metody getTimeInMillis() z klasy Calendar, która zwraca liczbę
milisekund, które (dla danego ustawienia kalendarza) uplynęły od 1
stycznia 1970 roku (taka szczególna data, od której odlicza
się czas nazywa się datą początku epoki).
Warto zwrócić przy tym uwagę, że wewnętrznie klasa kalendarza prowadzi równoległą
podwójną reprezentację daty i czasu - za pomocą omówionych wcześniej pól
oraz za pomocą liczby milisekund od początku epoki (wartość typu long,
ją własnie zwraca metoda getTimeInMillis()). Wartość milisekund można ustawiać
za pomocą metody setTimeInMillis(long) klasy Calendar.
Mówiliśmy już o tym, że Calendar.getInstance() zwraca domyślny kalendarz
dla domyślnej lokalizacji i związanej z nią strefy czasowej.
Możemy też uzyskać inne kalendarze:
- dla domyślnej lokalizacji, ale ustawiony na podaną strefę czasową (Calendar.getInstance(TimeZone)),
- dla podanej lokalizacji (Calendar.getInstance(Locale)),
- dla podanej lokalizacji i strefy czasowej (Calendar.getInstance(TimeZone,Locale)),
Oto prosty przykłady.
W poniższym fragmencie kodu:
TimeZone tz = TimeZone.getTimeZone("Asia/Jakarta");
Calendar c = Calendar.getInstance(tz);
System.out.println("Current time: " + c.getTime());
System.out.println("Java time: " +
c.get(Calendar.HOUR_OF_DAY) + ":" + c.get(Calendar.MINUTE));
kalendarz ustawiany jest na strefę czasową Javy (wyspy, nie języka). Metoda
getTime() zwróći aktualny czas w domyślnej lokalizacji, ale pola kalendarza
są ustawiane z uwzględnieniem różnicy czasu.
W wyniku otrzymamy.
Current time: Fri Jul 18 12:44:47 CEST 2003
Java time: 17:44
Czym różnią się kalendarze dla różnych lokalizacji?
Przede wszystkim rodzajem kalendarza. Klasa Calendar jest klasą abstrakcyjną.
Konkretne klasy kalendarzy są jej podklasami. Najczęściej spotkamy się z
klasą GregorianCalendar (która reprezentuje kalendarz gregoriański).
Ale nawet w standardzie Javy znajdziemy też inny kalendarz - mianowicie buddyjski
- właściwy np. dla lokalizacji tajskiej. Zobaczmy.
Następujący fragment kodu:
Calendar c = Calendar.getInstance();
System.out.println(c.getClass().getName());
c = Calendar.getInstance(new Locale("th", "TH"));
System.out.println(c.getClass().getName());
wyprowadzi:
java.util.GregorianCalendar
sun.util.BuddhistCalendar
Dużo więcej kalendarzy znajdziemy w pakiecie ICU.
Mamy tam kalendarze: buddyjski, tradycyjny chiński, tradycyjny japoński, islamski, hebrajski.
Sposób użycia tych kalendarzy oraz tóżnice pomiędzy nimi pokazuje poniższy program.
import com.ibm.icu.util.*;
import com.ibm.icu.text.*;
public class MiscCal {
public static void main(String[] args) {
Calendar[] kal = {
Calendar.getInstance(), // domyślny kalendarz - gregoriański
new GregorianCalendar(), // jeszcze raz - ale inaczej tworzony
new BuddhistCalendar(), // buddyjski
new ChineseCalendar(), // chiński
new JapaneseCalendar(), // japoński
new IslamicCalendar(), // islamski
new HebrewCalendar(), // hebrajski
};
java.util.Date teraz = new java.util.Date(); // aktualny czas
System.out.println("Teraz jest: " + teraz); // po angielsku
// przebiegamy po klaendarzach
// ustawiamy je na bieżący czas
// i pokazujemy wartości takich pól jak rok, miesiąc itp.
for (int i=0; i<kal.length; i++) {
kal[i].setTime(teraz);
String className = kal[i].getClass().getName();
String name = className.substring(className.lastIndexOf(".") + 1);
System.out.println(name + " - " +
"era " + kal[i].get(Calendar.ERA) +
"; rok " + kal[i].get(Calendar.YEAR) +
(name.equals("ChineseCalendar") ?
" czyli " + kal[i].get(Calendar.EXTENDED_YEAR) : "") +
"; mies " + kal[i].get(Calendar.MONTH) +
"; dzień mies. " + kal[i].get(Calendar.DAY_OF_MONTH) +
"; dzień tyg. " + kal[i].get(Calendar.DAY_OF_WEEK)
);
}
}
}
Program wyprowadzi następujące wyniki.
Teraz jest: Fri Jul 18 15:02:24 CEST 2003
GregorianCalendar - era 1; rok 2003; mies 6; dzień mies. 18; dzień tyg. 6
GregorianCalendar - era 1; rok 2003; mies 6; dzień mies. 18; dzień tyg. 6
BuddhistCalendar - era 0; rok 2546; mies 6; dzień mies. 18; dzień tyg. 6
ChineseCalendar - era 78; rok 20 czyli 4640; mies 5; dzień mies. 19; dzień tyg. 6
JapaneseCalendar - era 235; rok 15; mies 6; dzień mies. 18; dzień tyg. 6
IslamicCalendar - era 0; rok 1424; mies 4; dzień mies. 18; dzień tyg. 6
HebrewCalendar - era 0; rok 5763; mies 10; dzień mies. 18; dzień tyg. 6
Kalendarze różnią się przede wszystkim erą i rokiem. W buddyjskim lata liczone
są od narodzin Buddy. W tradycyjnym japońskim zliczanie czasu odbywa się
w ten sposób, że panowanie każdego Cesarza oznacza nową erę, a rok intronizacji
jest pierwszym rokiem tej ery. Tradycyjny chiński kalendarz jest kalendarzem
księżycowym (co od razu widać w rachubie miesięcy). Lata są liczone na dwa
różne sposoby. Pierwszy polega na numerowaniu lat kolejno poczynając od 61
roku panowania cesarza Szy Huang Ti (2637 r. pne). Drugi sposób bierze za
początek kalendarza tę sama datę, ale używa 60- letnich cykli, w każdym z
których lata numerowane są od początku. Pole ERA chińskiego kalendarza pokazuje
numer cyklu, pole YEAR - numer roku w danym cyklu (od 1 do 60), a pole EXTENDED_YEAR
aktualny numer roku, liczony sekwencyjnie według pierwszego sposobu. Kalendarz
hebrajski jest kalendarzem lunisolarnym (zatem zliczanie miesięcy ma ciekawe,
różne od kalendarza gergoriańskiego, własciwości). Kalendarz islamski rozpoczyna
rachubę lat od daty pielgrzymki Mohameta do Medyny (czwartek, 15 lipca 622
roku ).
Oczywiście, nie sposób tutaj wdawać sie w dalszą dyskusję tych zagadnień
(zainteresowanych odsyłam do bogatej literatury, dotyczącej różnych kalendarzy,
dostępnej również w Internecie).
Zauważmy tylko, że istnieje jeszcze wiele innych kalendarzy (do ciekawszych,
a zarazem bardzo skomplikowanych nalezy np. kalendarz balijski, obowiązujący
tradycyjnei na wyspie Bali). Klasa Calendar (szczególnie w wersji pakietu
ICU, gdzie pod kątem ułatwień dziedziczenia jej konstrukcja została mocno
przebudowana) jest przygotowana do tego, by w miarę prosto można było tworzyć jej podklasy, reprezentujące konkretne kalendarze,
Dostosowanie kalendarza do lokalizacji nie polega tylko na zmianie samego
kalendarza. Ten sam kalendarz - np. gregoriański - w różnych lokalizacjach
może się różnić np. pierwszym dniem tygodnia. W Polsce pierwszym dniem tygodnia
jest poniedziałek (indeks 2). Dla innych krajów - może być to inny dzień
tygodnia.
Poniższy program pokazuje wszystkie kraje dla których pierwszy dzień tygodnia nie jest poniedziałkiem.
import com.ibm.icu.util.Calendar;
import java.util.Locale;
import java.util.Map;
import java.util.TreeMap;
import java.util.Iterator;
import java.text.DateFormatSymbols;
public class FirstDoW {
public static void main(String[] args) {
// Domyślna lokalizacja (w naszym przypadku polska
Locale def = Locale.getDefault();
// Chcemy mieć dni tygodnia po polsku
DateFormatSymbols dafs = new DateFormatSymbols(def);
String[] wdays = dafs.getWeekdays(); // dni tygodnia po polsku
// Tablica dostępnych lokalizacji (z pakietu ICU!!!)
Locale[] loc = Calendar.getAvailableLocales();
// Mapa: klucz = kraj, wartość = piewrwszy dzień tygodnia
Map fdowMap = new TreeMap();
for (int i=0; i<loc.length; i++) {
// Uzyskanie kalendarza dla danej lokalizacji
// (będą to kalendzrae gregoriańskie, bo taka jest właściwość pakietu ICU)
Calendar c = Calendar.getInstance(loc[i]);
// indeks pierwszego dnia tygodnia w tym kalendarzu
int fdow = c.getFirstDayOfWeek();
// jeżeli to poniedziałek - nie interesuej nas
if (fdow == 2) continue;
// lokalizacja opisana w języku domyślnej lokalizacji (polskim)
String country = loc[i].getDisplayCountry(def);
if (country.equals("")) continue; // pomijamy te bez kraju
if (!fdowMap.containsKey(country)) fdowMap.put(country, wdays[fdow]);
}
System.out.println("Gdzie pierwszy dzień tygodnia nie jest poniedziałkiem?");
for (Iterator it = fdowMap.keySet().iterator(); it.hasNext(); ) {
// Jaki jest pierwszy dzień tygodnia
String country = (String) it.next();
String fday = (String) fdowMap.get(country);
System.out.println(country + " = " + fday);
}
}
Wydruk programu:
Gdzie pierwszy dzień tygodnia nie jest poniedziałkiem?
Albania = niedziela
Algeria = sobota
Arabia Saudyjska = sobota
Armenia = niedziela
Australia = niedziela
Bahrajn = sobota
Botswana = niedziela
Chiny = niedziela
Chorwacja = niedziela
Dziewicze Wyspy Stanów Zjednoczonych = niedziela
Dżibuti = sobota
Egipt = sobota
Erytrea = sobota
Etiopia = sobota
FO = niedziela
Filipiny = niedziela
GL = niedziela
Hong Kong = niedziela
Indie = sobota
Irak = sobota
Iran = sobota
Islandia = niedziela
Izrael = niedziela
Japonia = niedziela
Jemen = sobota
Jordan = sobota
Jugosławia = niedziela
Kanada = niedziela
Katar = sobota
Kenia = sobota
Korea Południowa = niedziela
Kuwejt = sobota
Liban = sobota
Libia = sobota
MO = niedziela
Macedonia = niedziela
Malta = niedziela
Maroko = sobota
Nowa Zelandia = niedziela
Oman = sobota
Republika Czeska = niedziela
Republika Południowej Afryki = niedziela
Rumunia = niedziela
Singapur = niedziela
Somalia = sobota
Stany Zjednoczone Ameryki = niedziela
Sudan = sobota
Syria = czwartek
Słowacja = niedziela
Słowenia = niedziela
Tajlandia = niedziela
Tajwan = niedziela
Tanzania = sobota
Tunezja = sobota
Wietnam = niedziela
Zimbabwe = niedziela
Zjednoczone Emiraty Arabskie = sobota
Już w tym przykładzie natknęliśmy się na kwestie pokazywania dat według
reguł danej lokalizacji (tu chodziło o nazwy dni tygodnia). Skorzystaliśmy
przy tym z klasy DateFormatSymbols, jej obiektu utworzonego dla domyślnej
lokalizacji (polskiej) i metody getWeekDays(), która - wołana na jego rzecz
- zwraca nazwy dni tygodnia w języku danej lokalizacji.
Ogólnie, wyprowadzanie dat i czasu w przyjaznej dla użytkownika postaci wymaga
ich formatowania za pomoca klasy DateFormat, która posługuje się klasą DateFormatSymbols.
Klasa DateFormat służy również do przekształacania tekstów (napisów) reprezentujących
daty na obiekty klasy Date.
1.6. Formatowanie dat
Przy formatowaniu dat podobnie jak w przypadku liczb musimy najpierw uzyskać odpowiedni formator
za pomocą statycznych metod getXXXInstance(...) z klasy DateFormat, a następnie
na jego rzecz użyć metody format z argumentem typu Date.
Możemy zastosować:
- formator dla dat - metody getDateInstance(...)
- formator dla czasu - metody getTimeInstance(...)
- formator dla daty i czasu - metody getDateTimeInstance(...)
- domyślny formator dla daty i czasu - metoda getInstance().
Argumenty w/w metod określają lokalizację oraz styl formatowania .
Mamy do dyspozycji cztery style formatowania określone przez statyczne stałe
klasy DateFormat: SHORT, MEDIUM, LONG, FULL, a ew. dodatkowy argument metod
getXXXInstance(...) określa lokalizację za pomocą referencji do obiektu
klasy Locale.
Oprócz tego możemy posłużyć się wzorcami formatowania.
Najprostsze sposoby formatowania dla domyślnej i kilku wybranych lokalizacji pokazuje poniższy kod.
import java.util.*;
import java.text.*;
import javax.swing.*;
public class Daty {
public static void main(String[] args) {
Date teraz = new Date();
int[] styles = { DateFormat.SHORT, DateFormat.MEDIUM,
DateFormat.LONG, DateFormat.FULL };
String outMsg = "";
for (int i=0; i < styles.length; i++) {
DateFormat df = DateFormat.getDateTimeInstance(
styles[i], // styl daty
DateFormat.FULL // styl czasu
);
outMsg += df.format(teraz) + '\n' + "-----------------\n" ;
}
System.out.println(outMsg);
Locale[] llist = { new Locale("de"),
new Locale("fr"),
new Locale("es"),
new Locale("ar"),
new Locale("ru"),
new Locale("th")
};
outMsg = "";
for (int i=0; i < llist.length; i++) {
DateFormat df = DateFormat.getDateTimeInstance(
DateFormat.FULL, // styl daty
DateFormat.FULL, // styl czasu
llist[i] // lokalizacja
);
outMsg += df.format(teraz) + '\n' + "-----------------\n" ;
}
JOptionPane.showMessageDialog(null, outMsg);
System.exit(0);
}
}
Program wypisze na konsoli daty w domyślnej lokalizacji (pl) i wszystkich
stylach oraz czas w stylu FULL. W pokazanym okienku komunikatów zobaczymy
tę samą informację sformatowaną dla killku innych lokalizacjach (styl daty
i czasy FULL).
03-07-18 16:47:57 CEST
-----------------
2003-07-18 16:47:57 CEST
-----------------
18 lipiec 2003 16:47:57 CEST
-----------------
piątek, 18 lipiec 2003 16:47:57 CEST
-----------------
Metoda getXXXInstance() klasy DateFormat zwraca (zlokalizowany, jeśli można)
obiekt klasy SimpleDateFormat. Za pomocą tej klasy możemy zastosować wzorce
formatowania do pokazywania (i parsowania) dat i czasu.
Wzorzec formatowania składa się z liter ('a' - 'z', 'A' - 'Z')), które mają
specjalne znaczenie i są interpretowane jako składowe daty/czasu (lub zarezerwowane)
oraz innych symboli, które są po prostu kopiowane przy formatowaniu. Litery
ujęte w apostrofy nie są interpretowane.
Litery, mające specjalne znaczenie pokazuje tablica.
| Litera
| Znaczenie
| Typ
| Przykład
|
|---|
G | Era
| Tekst | AD |
y | Rok
| Rok | 1996; 96 |
M | Miesiąc w roku
| Miesiąc | July; Jul; 07 |
w | Tydzień w roku
| Liczba
| 27 |
W | Tydzień w miesiącu | Liczba | 2 |
D | Dzień roku
| Liczba | 189 |
d | Dzień miesiąca
| Liczba | 10 |
F | Dzień tygodnia
| Liczba | 2 |
E | Dzień tygodnia
| Tekst | Tuesday; Tue |
a | Tekst Am/pm
| Tekst | PM |
H | Godzina dnia (0-23)
| Liczba | 0 |
k | Godzina dnia (1-24)
| Liczba | 24 |
K | Godzina am/pm (0-11)
| Liczba | 0 |
h | Gdodzina am/pm (1-12) | Liczba |
| 12 |
m | Minuta
| Liczba | 30 |
s | Sekunda
| Liczba | 55 |
S | Milisekunda | Liczba | 978 |
z | Strefa czasowa
| Symbol strefy
| Pacific Standard Time; PST; GMT-08:00 |
Z | Strefa czasowa
| Symbol RFC 822 | -0800 |
Poszczególne specjalne litery są we wzorcach formatowania powtarzane określoną liczbę razy.
Przy tym:
- dla składowych typu Tekst : jeśli przy formatowaniu powtórzono literę
4 lub więcej razy stosowana jest pełna forma (np. EEEE - "wtorek"), przy
parsowaniu - liczba liter nie ma znaczenia,
- dla składowej typu Rok: jeśli podano dwie litery YY - dostaniemy dwie cyfry
roku, w przeciwnym razie rok jest traktowany jako typu Liczba,
- dla składowych typu Miesiąc: jeśli podano 3 lub więcej liter mamy
miesiąc w postaci słownej (traktowany jak Tekst), w przeciwnym razie jako
typu Liczba,
- dla składowych typu Liczba: liczba liter określa minimalną liczbę
cyfr (nie ma to znaczenia przy parsowaniu, o ile nie trzeba oddzielać dwóch
stycznych pól).
Przyjrzyjmy
się kilku przykładom zastosowania wzorców formatowania dat.
Poniższy program:
import java.util.*;
public class Daty1 {
public static void main(String[] args) {
Calendar c = Calendar.getInstance();
Date teraz = c.getTime();
SimpleDateFormat df = (SimpleDateFormat) DateFormat.getDateInstance();
String[] pattern = {"dd-MM-yyyy",
"MMMM, 'dzień 'dd ( EE ), 'roku 'yyyy GGGG",
"EEEE, dd MMM yyyy 'r.'"
};
for (int i=0; i<pattern.length; i++) {
df.applyPattern(pattern[i]);
System.out.println(df.format(teraz));
}
}
}
wyprowadzi:
18-07-2003
lipiec, dzień 18 ( Pt ), roku 2003 n.e.
piątek, 18 lip 2003 r.
Przy parsowaniu z użyciem zdefiniowanych wzorców formatowania teksty (zapisane
zgodnie z tymi wzorcami) przekształcane są na daty (obiekty klasy Date).
Reguły parsowania są podobne jak w przypadku klasy NaumberFormat (przypopmnijmy
sobie omówione wczesniej zasady zgłaszania wyjątków oraz posługiwanie się
klasą ParseException).
Poniższy przykładowy fragment:
public static void main(String[] args) {
SimpleDateFormat df = (SimpleDateFormat) DateFormat.getDateInstance();
String[] pattern = {"dd-MM-yyyy",
"MMMM, 'dzień 'dd ( EE ), 'roku 'yyyy GGGG",
"EEEE, dd MMM yyyy 'r.'"
};
for (int i=0; i<pattern.length; i++) {
String in=JOptionPane.
showInputDialog("Wprowadź datę wg wzorca " + pattern[i]);
df.applyPattern(pattern[i]);
Date data = df.parse(in, new ParsePosition(0));
System.out.println(data);
}
}
po wprowadzeniu w dialogach tekstów:
12-12-1999
lipiec, dzień 18 ( Pt ), roku 2003 n.e.
wtorek, 12 lipiec 2003 r.
wyprowadzi na konsolę:
Sun Dec 12 00:00:00 CET 1999
Fri Jul 18 00:00:00 CEST 2003
Sat Jul 12 00:00:00 CEST 2003
Zwróćmy uwagę: błędny dzień tygodnia (wtorek zamiast soboty) nie spowodował
błędu interpretacji, ale uzyskana data jest właściwa (nazwa dnia tygodnia
została skorygowana).
Oczywiście, formatowanie i parsowanie podlega zasadom lokalizacji.
Istotnych informacji lokalizacyjnych dostarcza klasa DateFormatSymbols. Mieliśmy
okazję z niej korzystać przy okazji uzyskiwania nazw dni tygodnia po polsku.
Zobaczmy teraz jakich jeszcze informacji możemy się po niej spodziewać.
Przykładowy program tworzy obiekty klasy DateFormatSymbols dla kilku lokalizacji
i wywołuje na ich rzecz metody takie jak getWeekdays() (zwracającą nazwę
dni tygodnia) czy getMonths() (nazwy dni miesiąca). Nazwy metod pozyskujących
zlokalizowane informacje są samoobjaśniające sie, wynik działania programu
pokazujemy w obszarze wielowierszowego pola edycyhnego (JTextArea) po to
by właściwie były interpretowane znaki Unicode (zob. rysunek).
import java.util.*;
import java.text.*;
import java.awt.*;
import javax.swing.*;
public class DateFormatSymbolsShow {
String[] lang = { "fr", "es", "de", "ru" };
String out = "";
public DateFormatSymbolsShow() {
for (int i=0; i<lang.length; i++) {
Locale loc = new Locale(lang[i]);
DateFormatSymbols dfs = new DateFormatSymbols(loc);
out += '\n' + loc.getDisplayLanguage();
// nazwy er
addToOut("Ery: ", dfs.getEras());
// nazwy miesięcy
addToOut("Miesiące: ", dfs.getMonths());
// skróty miesięcy
addToOut("Miesiące - skróty: ", dfs.getShortMonths());
// nazwy dni tygodnia
addToOut("Dni tygodnia: ", dfs.getWeekdays());
// skróty nazw dni tygodnia
addToOut("Dni tygodnia - skróty: ", dfs.getShortWeekdays());
}
JTextArea ta = new JTextArea(out);
ta.setFont(new Font("Dialog", Font.BOLD, 14));
JFrame f = new JFrame();
f.getContentPane().add(ta);
f.pack();
f.show();
}
void addToOut(String msg, String[] s) {
out += "\n" + msg;
for (int i=0; i<s.length; i++) {
out += ' ' + s[i];
}
}
public static void main(String[] args) {
new DateFormatSymbolsShow();
}
}

Zwykle nie korzystamy z klasy DateFormatSymbols (jest ona używana automatycznei
przy formatowaniu dat), Czasem jednak może zajść taka potrzeba. Wtedy można
użyc konstruktora klasy SimpleDateFormat, dostarczając mu oprócz pierwszego
argumentu (wzorca formatowania) argument drugi - refrencję do obiektu DateFormatSymbols.
Wykorzystamy to teraz do poprawieniu błędów gramatycznych, które nieuchronnie
powstają przy formatowaniu dat w języku polskim ze względu na brak uwzględnienia
właściwej odmiany nazw miesięcy (nb uważny Czytelnik zapewne zauważył, że
lokalizacje dokonywane przez "lokalnych" ekspertów firm Sun i IBM są często
nieco powierzchowne; błędy gramatyczne i ortograficzne dotyczą nie tylko
polskiego, co można było spostrzec w kilku przykładach z tego rozdziału).
Przy okazji zobaczymy, że właściwości lokalizacyjne formatowania dat można
łatwo zmieniać (za pomocą rozlicznych metod set... z klasy DateFormatSymbols).
import java.util.*;
import java.text.*;
public class DateFormatPol {
public static String polskaData(Date data) {
String[] mies = { "stycznia", "lutego", "marca", "kwietnia",
"maja", "czerwca", "lipca", "sierpnia",
"września", "października", "listopada",
"grudnia"
};
DateFormatSymbols dfs = new DateFormatSymbols();
dfs.setMonths(mies);
SimpleDateFormat df = new SimpleDateFormat("dd MMMM yyyy", dfs);
return df.format(data);
}
public static void main(String[] args) {
System.out.println( polskaData( new Date() ) );
}
}
Prrzykładowy listing programui:
20 lipca 2003
1.7. Zlokalizowany rozbiór tekstów
W części A omawialiśmy rozbiór tekstów za pomocą klasy StringTokenizer.
Oczywiście, zastosowane tam proste reguły wyodrębniania fragmentów napisów
tak naprawdę nie nadają się do przetwarzania "języka pisanego".
Tę - może nie na codzień potrzebną, ale wartą odnotowania - funkcję spełnia klasa BreakIterator
z pakietu java.text. Warto też wspomnieć o tej klasie dlatego, że zastosowano
w niej - na pierwszy rzut oka - mało intuicyjne, ale, okazuje się, wygodny
mechanizm analizy składniowej.
Klasa ta pozwala dzielić tekst pisany w danym języku na elementy takie jak: zdania, wiersze (wiersz jest częścią zdania od początku linii do jej końca lub znaku przeniesienia), słowa, znaki.
Do wyodrębniania każdego z w/w elementów tekstu trzeba stworzyć odrębny iterator. Służą temy
statyczne metody klasy: getSentenceInstance(...), getLineInstance(...), getWordInstance(...)
, getCharacterInstance(...).
Metody iteratora (związanego z danym elementem tekstu) umożliwiają m.in.
- pobranie indeksu pierwszej pozycji podziału tekstu na elementy (zdania, wiersza etc) - metoda first().
- pobranie indeksu ostatniej pozycji podziału tekstu na elementy (zdania, wiersza etc) - metoda last(),
- pobranie indeksu następnej pozycji podziału tektsu na elementy (zdania, wiersza etc) - metoda next(),
- pobranie indeksu poprzedniej pozycji podziału tektsu na elementy (zdania, wiersza etc) - metoda previous(),
- swobodny wybór elementów tekstu - np. pobranie indeksu poz
ycji podziału tekstu oddalonego
o n pozycji od bieżącego "w przód" lub "w tył" - metody next(int n) lub
preceding(int n).
Metody te nie tylko zwracają pozycję, ale przesuwają bieżącą pozycję
podziału tekstu. Dlatego właśnie klasa została nazwana BreakIterator - jej
metody pozwalają iterować poprzez pozycje podziału tekstu.
Ale uwaga! Iterator służący do wyodrębniania słów - w przeciwieństwie do
innych iteratorów (np. zdań) - zwraca indeksy elementów (słów) oraz indeksy
separatorów elementów-słów. To czy na danej pozycji zaczyna się akurat
kolejne słowo czy też ciąg znaków dzielących słowa musimy sprawdzić samodzielnie.
Program testujący wraz z komentarzami pokazuje sposób użycia BreakIteratora.
import java.text.BreakIterator;
public class BreakIteratorTest {
// Metoda wypisująca na konsoli
// - zdania - jeśli przekazano jako argument typ wartość 0
// - lub słowa - jeśli przekazano jako argument typ wartość 1
// wyodrębnione z tekstu txt
private static void show(int typ, String txt) {
String[] head = { "Zdania", "Słowa" }; // Nagłówek: dla typ==0 "Zdania"
// dla typ==1 "Słowa"
// Uzyskanie odpowiedniego breakiteratora
// dla typ == 0 będzie to iterator "po zdaniach"
// dla typ == 1 będzie to iterator "po słowach"
BreakIterator bri = (typ == 0 ? BreakIterator.getSentenceInstance()
: BreakIterator.getWordInstance()
);
System.out.println(head[typ]); // Wypisanie nagłówka
// Po stworzeniu iteratora a przed jego użyciem
// należy ustalić tekst, który będzie przetwarzany
bri.setText(txt);
// Iterowanie
int start = bri.first(); // pozycja pierwszego podziału na elementy
int end = bri.next(); // pozycja następnego podziału na elementy
while (end != BreakIterator.DONE) { // dopóki można dzielić tekst
// Wyodrębniamy element
String elt = txt.substring( start, end);
// Wypisujemy element jeżeli to jest iterator dla zdań
// albo jeżeli to jest iterator dla słów, a elementem jest słowo
// Czy to jest słowo stwierdzamy za pomocą metody
// isIteratorWord(...) - zob. dalej
if (typ == 0 | (typ == 1 && isIteratorWord(elt)))
System.out.println(start + ": " + elt);
start = end; // początek następnego (po wypisanym) elementu
end = bri.next(); // pozycja następnego podziału
}
}
// Metoda stwierdza czy element wyodrębniony przez iterator słów
// jest słowem. Będzie nim każdy element, który zawiera choć jedną
// literę lub cyfrę. Czy dany znak jest literą lub cyfrą
// stwierdzamy za pomocą statycznej metody z klasy Character
// Character.isLetterOrDigit(znak)
private static boolean isIteratorWord(String elt) {
int l = elt.length();
for (int i=0; i < l; i++)
if (Character.isLetterOrDigit(elt.charAt(i))) return true;
return false;
}
public static void main(String[] args) {
String s = "Ala Kot-Kotowska ma kota. A mleko? "+
"Pies go wychłeptał (swobodnie) - 0.1 litra. " +
"Tak? Nie! Chyba nie... A może? Byłażby to \"hańba\"?!!!";
show(0, s); // pokaż zdania
show(1, s); // pokaż słowa
}
}
Wydruk działania programu pokazano .... poniżej:
Zdania
0: Ala Kot-Kotowska ma kota.
26: A mleko?
35: Pies go wychłeptał (swobodnie) - 0.1 litra.
79: Tak?
84: Nie!
89: Chyba nie...
102: A może?
110: Byłażby to "hańba"?!!!
Słowa
0: Ala
4: Kot-Kotowska
17: ma
20: kota
26: A
28: mleko
35: Pies
40: go
43: wychłeptał
55: swobodnie
68: 0.1
72: litra
79: Tak
84: Nie
89: Chyba
95: nie
102: A
104: może
110: Byłażby
118: to
122: hańba
BreakIterator pozwala dość wygodnie działać na tekstach. Oczywiście - i to
jest jego równie ważna zaleta - BreakIterator przygotowany jest do przetwarzania
tekstów zgodnie z ustawieniami lokalizacyjnymi (dla różnych języków). Inaczej
wygląda tekst i jego podział na zdania czy słowa w języku niemieckim, inaczej
w angielskim, inaczej w chińskim. BreakIterator będzie umiał dokonać właściwego
rozbioru w każdym z tych przypadkóe.
Tak jak zawsze w przypadku klas czułych na lokalizację ustawić odpowiednie
przetwarzanie można za pomocą metod statycznych. które zwracają iterator
dla odpowiednich elementów (zdania, słowa, itp.), a mają za argument referencję
do obiektu klasy Locale, który określa lokalizację.
1.8. Porównywanie i sortowanie napisów
Różne języki implikują różny alfabetyczny porządek napisów.
Właściwe porównywanie napisów możemy przeprowadzić za pomocą obiektu klasy Collator z pakietu java.text.
Jest to klasa czuła na lokalizację, zatem właściwą instancję kolatora dla
domyślnej lokalizacji uzyskamy za pomocą odwołania Collator.getInstance().
Możemy też uzyskać kolator dla dowolnej lokalizacji, podając w metodzie getInstance(...) argument-lokalizację
Mając obiekt-kolator dla okreslonej (domyślnej lub podanej) lokalizacji możemy
za pomocą metody compare(...) wywołanej na jego rzecz uzyskać własciwy dla
danej lokalizacji wynik porównania dwóch napisów podanych jako argumenty
metody.
Łatwo się domyślić, że klasa Collator implementuje interfejs Comparator.
Zatem porównania uzyskiwane za pomoca metody compare(...) kolatora łatwo
uczynić podstawą sortowania tablic i kolekcji, a także decydowania o dodawaniu
elementów do uporządkowanych zbiorów i map.
Zobaczmy najprostszy przykład. Niech domyślna lokalizacja będzie lokalizacją
polską, Jak posortować tablicę napisów w tej lokalizacji ? Reguła jest prosta:
- uzyskać kolator dla lokalizacji domyslnej (polskiej) - metoda Collator.getInstance(),
- podać ten kolator jako komparator w metodzie Arrays.sort(...)
Poniższy program - oprócz wspomnianej wyżej procedury - pokazuje, że porządek
napisów w róznych lokalizacjach jest różny (przy sortowaniu polskich napisów
powinniśmy oczywiście stosować kolator dla lokalizacji polskiej)\.
import java.util.*;
import java.text.*;
public class Kolator0 {
static void sortShow(String msg, String[] txt, Collator col) {
String[] copyTxt = (String[]) txt.clone();
Arrays.sort(copyTxt, col);
System.out.println(msg);
for (int i=0; i < copyTxt.length; i++) {
System.out.println(copyTxt[i]);
}
}
public static void main(String[] args) {
String[] txt = { "bela", "Ala", "ą", "Ą", "ą", "ala" , "Be", "Ala",
"alabama", "be", "Be", "1", "ć", "my", "My", "Myk", "myk" };
Collator col = Collator.getInstance();
sortShow("Sort pol", txt, col);
Collator col1 = Collator.getInstance(new Locale("en"));
sortShow("Sort en", txt, col1);
}
}
Program wyprowadzi na konsolę:
Sort pol
1
ala
Ala
Ala
alabama
ą
ą
Ą
be
Be
Be
bela
ć
my
My
myk
Myk
Sort en
1
ą
ą
Ą
ala
Ala
Ala
alabama
be
Be
Be
bela
ć
my
My
myk
Myk
W jaki sposób (dla różnych lokalizacji) uzyskujemy właściwe porównania?
Otóż konkretne kolatory są obiektami klasy RuleBasedCollator, która jest podklasą klasy Collator.
Uporządkowanie za pomocą kolatorów klasy RuleBasedCollator odbywa się na
podstawie porównywanie znaków w oparciu o reguły zapisane za pomocą prostej
składni. Reguły te określają cztery (a w pakieice ICU nawet pięć) porządki:
- podstawowy (PRIMARY), w którym rozróżniane są (zdefiniowane w zestawie reguł jako rozróżnialne) znaki,
- drugorzędny (SECONDARY) , który określa porządek napisów identycznych
ze względu na porządek podstawowy, ale różniących się akcentowanymi znakami
(to dotyczy np. języków francuskiego, hiszpańskiego, angielskiego),
- trzeciorzędny (TERTIARY), który napisy identyczne wedle dwóch poprzednich porządków rozróżnia na podstawie wielkości liter,
- identyczności (IDENTICAL): rozróżniający wszelkie znaki, nawet te uznane
za takie same wedle trzech poprzednicj porządków (np. w wielu lokalizacjach
znaki \u0001 i \u0002 są uznawane za takie same wedle trzech w/w porządków,
natomiast porządek identyczności będzie je rozróżniał)
Stosowany dla danego kolatora porządek nazywa się siłą kolatora.
Nawet nie znając reguł danego kolatora możemy ustalać jego siłę (np. czy
napisy różniące się tylko wielkością liter mają być rozrózniane). Służy temu
metoda setStrength(...) z argumentem określającym siłę kolatora (jedna ze
stałych statycznych klasy Collator o nazwach PRIMARY, SECONDARY, TERTIARY,
IDENTICAL).
W modyfikacji poprzedniego przykładowego programu ustalimy siłę kolatora
na PRIMARY (domyślnie jest TERTIARY). W polskiej lokalizacji (wedle reguł
dla niej okreslonych) nie będą teraz rozróżniane wielkie i małe litery.
public static void main(String[] args) {
String[] txt = { "bela", "Ala", "ą", "Ą", "ą", "ala" , "Be", "Ala",
"alabama", "be", "Be", "1", "ć", "my", "My", "Myk", "myk" };
Collator col = Collator.getInstance();
sortShow("Sort TERTIARY", txt, col);
col.setStrength(Collator.PRIMARY);
sortShow("Sort PRIMARY", txt, col);
}
Program wyprowadzi napisy w dwóch różnych porządkach, odpowiadjących dwóm różnym siłom kolatora:
Sort TERTIARY
1
ala
Ala
Ala
alabama
ą
ą
Ą
be
Be
Be
bela
ć
my
My
myk
Myk
Sort PRIMARY
1
Ala
ala
Ala
alabama
ą
Ą
ą
Be
be
Be
bela
ć
my
My
Myk
myk
Oczywiście, możemy sami definiować reguły dla obiektów klasy RuleBasedCollator.
Reguły są zapisywane jak łańcuchy znakowe w postaci:
<relacja> tekst <relacja> tekst ....
gdzie relacja wprowadzana jest za pomocą znaków:
< - większe wedle pierwszego porządku (rozróżniania liter)
; - większe wedle drugirgo porządku (rozróżniania akcentowanych liter),
, - większe wedle trzeciego porządku (wielkość liter)
= - równe
a tekst jest dowolym ciągiem znaków wyłączając znaki specjalne i znaki opisujące
w/w relacje (jeśli takie znaki chcemy włączyć do porównań ujmujemy je w apostrofy).
Na przykład:
9 < a, A < b, B < c, C
Możemy też użyć znaku &, który łogicznie łączy reguły np:
a < b & b < c
jest identyczne z :
a < b < c
przy tym jednak należy uważać na kolejność, bowiem połączone reguły są stosowane w kolejności od lewej do prawej i np.
a < c & a < b
nie jest tożsame z
a < b & a < c
Stworzenie pełnego zestawu reguł dla kolatora może być dość pracochłonne. trzeba bowiem uwzględnić wiele możliwych znaków.
Zobaczmy najpierw jak wygląda fragment reguł dla kolatora w lokalizacji polskiej.
Reguły te możemy uzyskać za pomocą odwołania:
Collator col = Collator.getInstance();
String rules = ((RuleBasedCollator) col).getRules();
i pokazać np. w oknie:
Spróbujmy teraz rozpatrzyć uproszczony przykład (abstrahując od wielu możliwych
znaków). Przykłady sortowania pokazały nam, że rozróżnienie pomiędzy dużymi
i małymi literami nie jest pierwszorzędne: tylko w przypadku gdy napisy
są takie same kolator bierze pod uwagę tę różnicę i ustawia wtedy małe litery
przed wielkimi. Widać to zresztą w zestawie reguł np. ... < a, A <
b, B rozróznia najpierw litery a i b (bez uwzględneinia ich wielkości),
a dopiero gdy napisy (składający się z tych liter) są takie same bierze pod
uwagę
ich wielkość.
Stworzymy więc przykładowy inny zestaw reguł, który (przy sortowaniu rosnącym)
ustawi wyraz "Polska" na początku, a inne napisy posortuje w porządku -
najpierw duże litery, później małe (z uwzględnieniem polskich znaków i tego,
że polskie odpsoiedniki znaleźc sie mają po "normalnych" literach np. ą po
a).
Obrazuje to poniższy program:
import java.util.*;
import java.text.*;
public class Kolator1 {
static void sortShow(String msg, String[] txt, final Collator col) {
String[] copyTxt = (String[]) txt.clone();
Arrays.sort(copyTxt, col);
System.out.println(msg);
for (int i=0; i < copyTxt.length; i++) {
System.out.println(copyTxt[i]);
}
}
public static void main(String[] args) {
// Napisy do posortowania
String[] txt = { "bela", "Ala", "ą", "Ą", "ą", "ala" , "Be", "Ala",
"alabama", "be", "Be", "1", "Ćwikła", "ćwikła",
"ćwikla", "Polska",
"My", "my", "Myk", "myk" };
// Domyślny polski kolator
Collator col = Collator.getInstance();
sortShow("Default sort", txt, col);
// Nowe reguły
String rules = " < Polska < A < Ą < B < C < Ć < D < E < Ę < F < G < H" +
" < I < J < K < L < Ł < M < N < Ń < O < P < Q < R < S < Ś" +
" < T < U < V < W < X < Y < Z < Ź " +
" < a < ą < b < c < ć < d < e < ę < f < g < h" +
" < i < j < k < l < ł < m < n < ń < o < p < q < r < s < ś" +
" < t < u < v < w < x < y < z < ź";
try {
col = new RuleBasedCollator(rules);
} catch (ParseException exc) {
System.out.println("Wadliwa reguła na pozycji " + exc.getErrorOffset());
System.out.println(exc);
System.exit(1);
}
sortShow("My new rules sort", txt, col);
}
}
który wyprowadzi:
Default sort
1
ala
Ala
Ala
alabama
ą
ą
Ą
be
Be
Be
bela
ćwikla
ćwikła
Ćwikła
my
My
myk
Myk
Polska
My new rules sort
Polska
Ala
Ala
Ą
Be
Be
Ćwikła
My
Myk
ala
alabama
ą
ą
be
bela
ćwikla
ćwikła
my
myk
1
Jeżeli sortowanie jakiegoś zestawu napisów ma się powtarzać wielokrotnie,
to dla zwiększenia efektywności działania można przyporządkować napisom klucze
i sortować te klucze (klucze są sortowane szybciej).
Sposób postępowania jest następujący:
- stworzyć kolekcję lub tablicę na przechowywanie kluczy (obiektó klasy CollationKeys),
- dla każdego napisu, który ma podlegać porządkowaniu (sortowaniu) uzyskąc
klucz do kolatora za pomocą wywołania metody getCollationKey(napis) z klasy
Collator,
- wstawić klucz do tablicy lub kolekcji,
- posortować tablicę lub kolekcję,
- teraz klucze w tablicy/kolekcji są ustwaione w porządku napisów, określanym przez kolator
- żeby pokazać wynik sortowania przebiegamy tablicę/kolekcję kluczy i
od każdgeo klucza za pomocą odwołania getSourceString() uzyskujemy skojarzony
z nim napis.
Ilustruje to poniższy program.
import java.util.*;
import java.text.*;
public class Kolator2 {
public static void main(String[] args) {
// Napisy do posortowania
String[] txt = { "bela", "Ala", "ą", "Ą", "ą", "ala" , "Be", "Ala",
"alabama", "be", "Be", "1", "Ćwikła", "ćwikła",
"ćwikla", "Polska",
"My", "my", "Myk", "myk" };
// Domyślny polski kolator
Collator col = Collator.getInstance();
// Lista kluczy
List keys = new ArrayList();
// Uzyskanie kluczy dla napisów
// wartości kluczy uzyskujemy od kolatora
for (int i=0; i<txt.length; i++) {
CollationKey key = col.getCollationKey( txt[i] );
keys.add(key);
}
// Sortowanie
// porównywane mogą być tylko klucze uzyskane od tego samego kolatora!
Collections.sort(keys);
// Pokazanie wyniku
// mamy klucze ułożone w określonym porządku napisów, które reprezentują
// musimy pobrać napis skojarzony z kluczem
for (Iterator it = keys.iterator(); it.hasNext(); ) {
CollationKey key = (CollationKey) it.next();
String napis = key.getSourceString();
System.out.println(napis);
}
}
}
1.9. Internacjonalizacja aplikacji i dodatkowe zasoby (resource bundle)
Nie tylka liczby, daty, czas powinny być w aplikacjach przygotowane do prezentacji
zgodnie z wymaganiami danej lokalizacji. Również komunikacja aplikacji z
użytkownikiem powinna przebiegać w języku użytkownika.
Wszelkiego rodzaju napisy i komunikaty dla użytkownika powinny być lokalizacyjnie przygotowane.
Częstym błędem przy tworzeniu aplikacji "produkcyjnych" jest nieuwzględnianie
tego warunku. Oto ktoś przygotowuje aplikację, używając do komunikowania
się z użytkownikiem napisów w jezyku polskim. Wszystko działa poprawnie,
klient jest zadowolony. Nagle okazuje się, że ta sama aplikacja powinna działać
w londyńskiej centrali firmy i wszystkie komunikaty, napisy itp. trzeba przerabiać
na angielski. Kosztuje to wiele wysiłku, powoduje powstawanie błędów w programie
itd.
Generalnie więc aplikacja powinna być od początku przygotowana na działanie
w różnych środowiskach językowych. A to oznacza konieczność odseparowania
językowych właściwości apliakcji (takich jak język komunikatów) od samego
jej kodu.
Mechanizmem umożliwiającycm takie odseparowanie w Javie są tzw. dodatkowe zasobu (ResourceBundle).
Istnieją dwa rodzaje dodatkowych zasobów: oparte na klasach (ListResourceBoundle)
i na czystych, tekstowych plikach właściwości (PropertiesResourceBundle).
Pliki właściwości umożliwiają odseparowanie napisów, klasy ListResourceBundle - dowolnych obiektów.
Aby odseparować napisy i dostarczyć ich różnych wersji jezykowych za pomocą plików właściwości:
tworzymy plik właściwości o wybranej nazwie i rozszerzeniu np. HelloMessages.properties
w pliku tym zapisujmey pary: klucze = napis,
dla każdej lokalizacji branej pod uwagę w naszej aplikacji towrzymy dodatkowy
plik właściwości o nazwie uzupelnionej o sufiks, wskazujący na lokalizacje
(np. HelloMessages_pl.properties)
zapisujemy w nim (pod tymi samymi kluczami) napisy w języku danej lokalizacji.
w naszym programie używamy zdefiniowanych napisów poprzez mechanizm odwołania
do do określonego przez aktualną lokalizację dodatkowego zasobu (np. ResourceBundle
msgs = ResourceBundle.getBundle("HelloMessages", lokalizacja) i pobranie
napisu, znajdującego się pod podanym kluczen (np. String value = msgs.getString(key);
Java odnajdzie odpowiedni plik właściwości (np. HelloMessages_pl.properties)
i pobierze z niego napis, odpowidające podanemu kluczowi; jeśli takiego pliku
nie będzie - to zostanie wybrany plik o możliwie bliskiej nazwie (np. gdy
szukany jest niestniejący plik HelloMessages_pl_PL.properties, to wynikiem
może być istniejący plik HelloMessages_pl.properties) albo plik bez sufiksu
w nazwie, który pełni rolę domyślnego przy braku odpowiednio zlokaalizowanych.
Jako prosty przykład stworzymy dwa pliki wartości klucz=napis: domyślny i dla lokalizacji polskiej:
Plik HelloMessages.properties
# Komunikaty w aplikacji Hello - domyślne przy braku pliku dla danej lokalizacji
hello = Hello!
bye = Good bye!
Plik HelloMessages_pl.properties
# Komunikaty w aplikacji Hello - po polsku
hello = Dzień dobry!
bye = Do widzenia.
Uwaga: klucze (hello, bye) są takie same.
Plików tych i mechanizmu dodatkowych zasobów użyjemy w prościutkiej aplikacji
Hello (dzięki czemu komunikacja z użytkownikiem naprawdę będzie odseparowana
od kodu źródłowego).
import java.util.*;
public class Hello {
static void sayHello() {
Locale defLoc = Locale.getDefault();
ResourceBundle msgs =
ResourceBundle.getBundle("HelloMessages", defLoc);
String powitaj = msgs.getString("hello");
String pozegnaj = msgs.getString("bye");
System.out.println(powitaj);
System.out.println(pozegnaj);
}
public static void main(String[] args) {
sayHello(); // tutaj działa domyślna lokalizacja pl_PL
// zmieniamy domyślną lokalizację
Locale.setDefault(new Locale("en"));
sayHello();
}
}
Wynik działania programu:
Dzień dobry!
Do widzenia.
Hello!
Good bye!
Uwagi:
- pierwsza para napisów powstaje, gdyż domyślną lokalizacją jest pl_PL,
getBundle(defLoc) nie znajduje pliku właściwości o takim sufiksie, ale znajduje
bliski mu z sufiksem pl,
- przy drugim odwołaniu do sayHello poszukiwany jest plik HelloMessages_en.properties,
a ponieważ go nie ma - używany jest domyślny HelloMessages.properties
Tak naprawdę ResourceBundle.getBundle(..) szuka najpierw klas dziedziczących
ListResourceBundle, a dopiero później plików właściwości.
Użycie ListResourceBundle wymaga od nas pisania kodu (i to jest wada w stosunku
do mechanizmu plików właściwości), ale równocześnie pozwala na wprowadzenie
"pod kluczami" - innych obiektów niż napisy (np. jakichś liczb, obrazów,
dźwięków - oczywiścię zlokalizowancyh).
Nasze zlokalizowane listy zasobów są klasami, które:
- mają nazwy zgodne z opisaną wcześniej (przy okazji plików własciwości) konwencją (sufiksy wskazujące na lokalizację)
- dziedziczą klasęe ListResourceBundle,
- dostarczają publicznej metody Object[][] getContents() która zwraca
tablicę odpowiedniości klucze - wartości, przy czym zaróno klucze jak i odpowiadające
im wartości mogą być dowolnymi obiektami.
Przykład:
public class CountryInfo_pl_PL extends ListResourceBundle {
public Object[][] getContents() {
return contents;
}
private Object[][] contents = {
{ "name", "Polska" },
{ "flag", new ImageIcon("PolskaFlaga.gif" },
};
}
Uzyskiwanie wartości z takich zasobó odbywa się w następujący sposób:
ResourceBundle info =
ResourceBundle.getBundle("CountryInfo", currentLocale);
String nazwaKraju = info.getString("name");
ImageIcon flaga = (ImageIcon) info.getObject("flag");
Uwaga: jeżeli wartość nie jest Stringiem należy zastosować metodę getObject()
i dokonać zawężającej konwersji do właściwego typu.
Dodatkowe zasoby (w specjalnej formie) razem z formatorem MessageFormat są
używane do generowania złożonych komunikatów, które opisywane są za pomocą
szablonu z wymiennymi parametrami.
Opanowanie tego zagadnienia pozstawiamy Czytelnikowi jako dodatkowe ćwiczenie z dokumentacją (klasa MessageFormat)
1.10. Zadania i ćwiczenia
- Dokonać internacjonalizacji aplikacji Owoce (z części B), tak by możliwe
było jej własciwe działanie w lokalizacji polskiej i angielskiej. Przy wydruku
rachunku z kasy podać godzinę. Uwzględnić właściwie dla danych lokalizacji:
nazwy owoców, formaty liczb, waluty, formaty dat i czasu.
- Samodzielnie opanować posługiwanie się klasą MessageFormat. Użyć jej
dla zlokalizowanego traktowania liczby mnogiej liczebników (np. 1 kosz owowców,
2 kosze owoców). W jaki sposób możemy tu użyć klasy ChoiceFormat? A jak zdefiniuejmy
reguły dla korzystania z klasy RuledBasedFormat pakietu ICU?