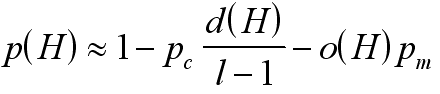
Kontynuacja prezentacji algorytmu genetycznego, tym razem od strony teoretycznej. Omówione zostanie podejście teoretyczne związane z twierdzeniem o schematach, a także hipoteza o cegiełkach, czyli najbardziej znane próby wyjaśnienia skuteczności algorytmów genetycznych. Ponadto zaprezentowane zostaną techniki dodatkowe, pozwalające znacznie poprawić wydajność algorytmu genetycznego.
Teoretycy algorytmów ewolucyjnych przyznają, że teoria algorytmów ewolucyjnych nie została jeszcze w satysfakcjonującym stopniu skonstruowana. Wciąż albo konieczne jest wprowadzanie bardzo silnych założeń upraszczających, albo uzyskane wyniki dalekie są od oczekiwań. Główną przyczyną jest znane w teorii optymalizacji twierdzenie "nic darmo" (no free lunch theorem). Zapewnia ono, że nie czyniąc żadnych założeń na temat natury optymalizowanej funkcji celu f, nigdy nie będziemy w stanie wykazać wyższości metod ewolucyjnych nad np. błądzeniem losowym.
Z drugiej strony, problemy występujące w praktyce bardzo często dają się skutecznie (tzn. skuteczniej, niż zrobiłby to algorytm losowy) rozwiązywać w sposób przybliżony. O ile więc przytoczonych w tym rozdziale wyników teoretycznych nie można uznawać za ścisły dowód skuteczności algorytmów genetycznych, to wynikające z nich zasady opisujące wpływ reprezentacji i operatorów genetycznych na skuteczność algorytmu mają istotne znaczenie praktyczne. Teorie te pozwalają też wyrobić sobie intuicyjne zrozumienie mechanizmów odpowiadających za skuteczność algorytmów genetycznych.
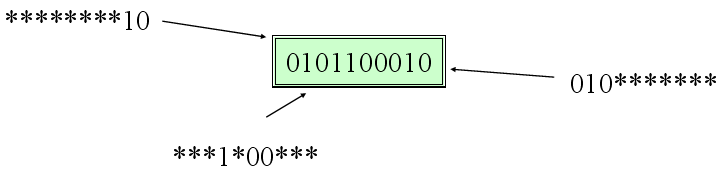
Najpowszechniejszym podejściem teoretycznym próbującym wyjaśnić skuteczność algorytmów genetycznych jest twierdzenie o schematach i związana z nim hipoteza o cegiełkach i zjawisko ukrytej równoległości. Schematem w ogólności jest dowolny podzbiór przestrzeni możliwych wartości chromosomu, przy czym na potrzeby omawianych twierdzeń ograniczymy się do schematów postaci np. 100**1*1** (gwiazdka oznacza "cokolwiek"). Mówimy, że osobnik pasuje do schematu, jeśli na ustalonych pozycjach (różnych od "*") jest identyczny ze schematem. Twierdzenie o schematach mówi, że jeśli schemat odpowiada osobnikom średnio lepszym niż inne (a więc koduje pewne korzystne cechy), to jego reprezentanci są coraz liczniejsi w miarę trwania ewolucji, przy czym wzrost ich liczebności jest w przybliżeniu wykładniczy.
Bardziej formalnie: przez H oznaczmy schemat, o(H) - liczbę miejsc ustalonych (czyli różnych od "*"), d(H) - rozpiętość schematu, czyli odległość między skrajnymi miejscami ustalonymi, l - długość chromosomu, pm - prawdopodobieństwo mutacji pojedynczego bitu, pc - prawdopodobieństwo krzyżowania osobnika.
Wtedy:
- stanowi prawdopodobieństwo, że dany schemat pozostanie nienaruszony w wyniku mutacji i krzyżowania (gdyż mutacja zniszczy schemat, jeśli trafi w miejsce ustalone, a krzyżowanie - jeśli punkt krzyżowania wypadnie pomiędzy miejscami ustalonymi). Jeżeli teraz przez m(H,t) oznaczymy liczbę (procent) osobników w populacji, które w chwili t pasują do schematu H, to średnia liczba takich osobników w następnym kroku może być oszacowana jako:
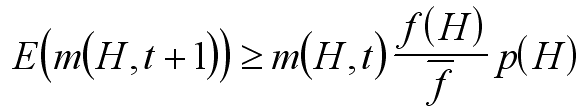
gdzie f(H) oznacza średnią wartość funkcji celu osobników pasujących do danego schematu (w danej populacji), f oznacza średnią wartość funkcji celu w populacji.
Wniosek: jeśli schematy są krótkie i zwarte (czyli mają duże p(H)), oraz jeśli mają średnią wartość funkcji celu wyższą niż przeciętna, to ich reprezentacja w populacji będzie rosła wykładniczo.
Analiza algorytmów genetycznych oparta na badaniu schematów wskazuje na zjawisko ukrytej równoległości jako na główną przyczynę zaskakującej skuteczności tej metody: przetwarzaniu w procesie ewolucji (tzn. tworzeniu, modyfikacji, przenoszeniu do następnego pokolenia, ocenie) podlegają właśnie schematy, a ponieważ każdy osobnik pasuje do wielu różnych schematów (w typowych rozwiązaniach - wykładniczo wielu: np. dla kodowania binarnego osobnik reprezentuje 2n schematów), w rzeczywistości algorytm genetyczny przetwarza równolegle znacznie więcej schematów niż osobników.
Hipoteza o cegiełkach
Aby ukryta równoległość rzeczywiście uzasadniała skuteczność algorytmów genetycznych w danym problemie, należy założyć pewne właściwości kodowania przestrzeni stanów na przestrzeń możliwych chromosomów. Założenie to nosi nazwę hipotezy o cegiełkach: przyjmujemy, że schematy mogą odzwierciedlać również pewne (potencjalnie pozytywne) cechy przestrzeni stanów wyjściowego problemu, tzn. dobre rozwiązanie problemu można zbudować z dobrych (o ponadprzeciętnej wartości średniej funkcji celu) schematów. Twierdzenie o schematach wskazuje, że liczba osobników pasujących do ponadprzeciętnych schematów rośnie w ramach populacji. Przyrost ten powoduje, że (przy stałej liczbie osobników w populacji) zwiększa się prawdopodobieństwo, że dany osobnik będzie reprezentował większą liczbę ponadprzeciętnych schematów. Jeśli przyjmiemy za prawdziwą hipotezę o cegiełkach, wzrost ten oznacza również rosnącą szansę pojawienia się osobnika optymalnego.
Algorytmy genetyczne działają więc najskuteczniej wtedy, gdy sposób zakodowania problemu i kształt funkcji celu pozwalają na istnienie "cegiełek": niewielkich i zwartych schematów o ponadprzeciętnej wartości funkcji celu. Wniosek praktyczny: jeśli kilka bitów koduje pojedynczą cechę, powinny one leżeć blisko siebie (wówczas będą częściej przenoszone wspólnie w ramach krzyżowania i mają szanse stać się "cegiełką").
Przez szybkość zbieżności będziemy rozumieli czas (liczbę pokoleń), po których wartość najlepszego osobnika w populacji stabilizuje się. W praktyce możemy ten parametr uznać za szybkość znalezienia rozwiązania przez algorytm genetyczny. Przyczyną zbieżności jest niemożność poprawienia wyniku przez dłuższy czas i w rezultacie stopniowe opanowane populacji przez najlepsze znalezione osobniki, co z kolei powoduje, że operatory genetyczne (głównie krzyżowanie) przestają tworzyć nowe kombinacje i stagnacja pogłębia się. Wynika z tego, że z punku widzenia ewolucji najlepsza jest wolna zbieżność i utrzymanie możliwie dużej różnorodności genetycznej w populacji. Jednak taka sytuacja ma też złe strony: przy zbyt wolnej zbieżności bardzo długo musielibyśmy czekać na lokalnie optymalne rozwiązania o satysfakcjonującej jakości. Zadanie zapobiegania zarówno zbyt wolnej, jak i zbyt szybkiej zbieżności spoczywa na pewnych technikach dodatkowych i właściwym doborze parametrów (wielkość populacji, prawdopodobieństwa mutacji i krzyżowania).
Liniowe skalowanie funkcji przystosowania
Prawdopodobieństwo wylosowania osobnika w algorytmie koła ruletki jest proporcjonalne do wartości funkcji celu. Jeśli jednak różnice wartości są niewielkie, presja selekcyjna może się okazać zbyt mała (zbyt wolna zbieżność, najlepsze osobniki nie są adekwatnie wynagradzane). Aby temu zaradzić, można przed użyciem algorytmu koła ruletki przeskalować liniowo wartości funkcji:
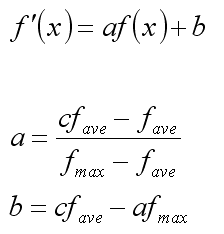
gdzie fave oznacza średnią wartość funkcji celu w populacji, fmax - wartość maksymalną, f'(x) - docelową (wykorzystaną w algorytmie koła ruletki) wartość funkcji przystosowania.
Tak dobrane przekształcenie gwarantuje, że:
a) średnia wartość po przeskalowaniu nie zmieni się,
b) wartość maksymalna będzie c razy większa, niż średnia.
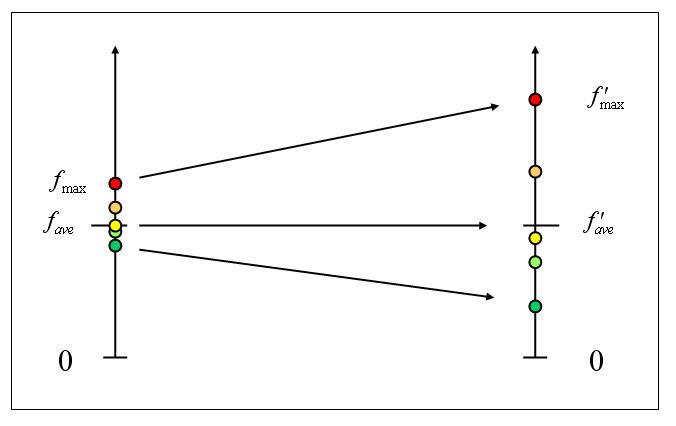
Metoda ta jest na tyle skuteczna, że warto standardowo stosować ją we wszystkich zastosowaniach praktycznych. Zwykle przyjmuje się c o wartościach 1,2 - 3, przy czym wielkość ta może regulować szybkość zbieżności algorytmu (duża wartość c oznacza uwypuklanie różnic między osobnikami, a więc szybszą zbieżność). Możemy więc w ten sposób zapobiegać zarówno zbyt szybkiej, jak i zbyt wolnej zbieżności algorytmu genetycznego.
Strategia elitarystyczna
Strategia elitarystyczna polega na tym, że po wyliczeniu funkcji celu dla osobników kilka (ustalone k) najlepszych z nich przenoszone jest do następnej populacji bez zmian, tzn. nie podlega normalnej selekcji. Metoda ta, często wykorzystywana dla k=1, zabezpiecza nas przed przypadkową utratą najlepszego osobnika, jaka może się zdarzyć ze względu na losowy charakter algorytmu koła ruletki.
Warto zauważyć, że jest to technika zwiększająca szybkość zbieżności algorytmu, co jak wiemy nie zawsze jest wskazane (zbyt silne popieranie aktualnego lidera w populacji zmniejsza szansę zbadania innych możliwości, tzn. poszukiwanie innych maksimów funkcji celu). Stąd należy unikać zbyt wysokich wartości k.
W niektórych zastosowaniach skuteczne okazuje się wprowadzenie barier reprodukcyjnych: dodatkowych ograniczeń, jakie muszą spełniać osobniki, by się mogły skrzyżować. Motywacją do takiego podejścia jest obserwacja, że w naturze osobniki różnych gatunków nie krzyżują się - ich geny są zbyt różne, aby po ich zmieszaniu powstało dobrze przystosowane potomstwo. Stosuje się różne podejścia praktyczne:
Metoda 1: krzyżujemy tylko osobniki podobne (np. różniące się na najwyżej k bitach).
Metoda 2: do każdego osobnika doklejamy wzorzec kojarzeniowy, czyli ciąg symboli {0,1,*}, oraz identyfikator, czyli dodatkowy ciąg binarny. Krzyżowanie jest dozwolone, jeśli wzorzec kojarzeniowy jednego z rodziców pasuje do identyfikatora drugiego. Identyfikator i wzorzec kojarzeniowy podlegają mutacji i krzyżowaniu w zwykły sopsób.

Podejście to umożliwia wykształcenie się "gatunków", z których każdy zasiedli inną niszę ekologiczną (inne maksimum lokalne). Wyniki są więc bardziej zróżnicowane - otrzymamy nie tylko jedno dobre rozwiązanie (i kilka gorszych, podobnych do niego), ale całą gamę różnych, lokalnie optymalnych wyników.
Inwersja jest techniką pozwalającą wprowadzić elementy samoadaptacji do jednego z najtrudniejszych etapów projektowania algorytmu ewolucyjnego: do ustalenia sposobu kodowania przestrzeni stanów. Hipoteza cegiełek mówi, że ważnym czynnikiem wpływającym na skuteczność algorytmu jest właściwe rozłożenie cech w ramach chromosomu. Stąd pomysł, by to ułożenie również podlegało ewolucji - podobnie jak w przypadku strategii ewolucyjnych pośrednio ewolucji podlega parametr mutacji s. W tym celu rozszerzamy chromosom o dodatkową informację, na jakiej pozycji leży bit reprezentujący daną cechę, a następnie (w ramach mutacji) przeprowadzamy czasem losową reorganizację chromosomu, zwykle poprzez odwrócenie kolejności genów na losowym odcinku (np. kolejność 12-34567-89 zamieniamy na 12-76543-89). Taka zamiana kolejności nie wpływa na rozwiązanie kodowane przez osobnika, gdyż bity kodujące dane cechy nadal (dzięki zachowaniu informacji o kolejności) są prawidłowo interpretowane. Natomiast wpływa ona na krzyżowanie, które odtąd wykonywane jest na inaczej zorganizowanym chromosomie. W efekcie losowych inwersji mogą powstać "cegiełki" - zestawy blisko położonych bitów mających wspólny pozytywny wpływ na jakość osobnika i rzadko niszczonych przez krzyżowanie. Zgodnie z ideą samoadaptacji, takie korzystne ustawienie kolejności bitów pośrednio zwiększa szanse osobników, a więc będzie promowane w procesie ewolucji.
Rozważa się też często równoległe implementacje algorytmów genetycznych. Zauważmy, że najkosztowniejsze obliczenia związane z liczeniem funkcji celu mogą być przeprowadzane równolegle dla każdego osobnika - daje to szerokie możliwości wykorzystania architektury równoległej. Jeszcze dalej idzie podejście zwane modelem wyspowym, w którym populację dzielimy na wiele podpopulacji, obliczanych niezależnie (operatory genetyczne i selekcja następuje w ramach podpopulacji) i jedynie co jakiś czas wymieniające między sobą pulę najlepszych osobników. Ta metoda nadaje się do rozproszonego modelu obliczeń (asynchronicznie, na wielu komputerach).
Zastosowanie diploidalnego kodu genetycznego, czyli podwójnego zestawu chromosomów, okazuje się skuteczna metodą w sytuacji, gdy postać funkcji celu zmienia się podczas trwania ewolucji. Kod diploidalny rozszerzany jest o tzw. jedynkę recesywną, czyli dodatkowy symbol interpretowany przez funkcję celu jako 1. Odczytanie wartości z podwójnego zestawu genów wygląda następująco: badamy, co na danej pozycji umieszczone jest w obu chromosomach; jeśli są to różne wartości, to wybieramy dominującą. Zasada jest taka, że 1 dominuje nad 0, a 0 nad jedynką recesywną. Czyli chromosomy 100r01 i 01rrr0 (gdzie r oznacza jedynkę recesywną) zostaną przez funkcję celu zinterpretowane jako 110101. Algorytm krzyżowania i mutacji musimy oczywiście również przystosować do rozszerzonego alfabetu i podwójnego zestawu genów. Korzyść ze stosowania diploidalnego kodu genetycznego polega na tym, że pewne cechy (zestawy genów) mogą być utajone w postaci recesywnej i nie podlegać eliminującej presji ewolucyjnej. Gdy warunki środowiska (czyli funkcja celu) często się zmieniają, populacja klasyczna musi na nowo "odkrywać" cechy korzystne w nowych okolicznościach, natomiast populacja diploidalna często ma gotowe rozwiązania w postaci recesywnej, oczekujące na sprzyjające warunki, by się ujawnić.
Oprócz swej wartości teoretycznej, twierdzenie o schematach daje nam pewne wskazówki dotyczące prawidłowego sposobu kodowania problemu. Wskazówki te wynikają wprost z hipotezy o cegiełkach. Druga część wykładu poświęcona była technikom pomocniczym, które warto stosować w celu poprawy wydajności algorytmu. Niektóre z tych technik, jak inwersja czy skalowanie liniowe, są rutynowo wykorzystywane w praktycznych zastosowaniach algorytmów genetycznych.
Zalecana literatura:
Szczegółowe definicje znajdują się w treści wykładu (słowa kluczowe zaznaczone są na czerwono).
bariery reprodukcyjne - ograniczenia pozwalające krzyżować się tylko niektórym osobnikom
diploidalny kod genetyczny - podwójny zestaw genów, rozkodowywany podczas liczenia funkcji celu za pomocą reguł recesywności; modyfikacja klasycznego algorytmu genetycznego skuteczna w przypadku zmieniającej się w czasie funkcji celu
hipoteza o cegiełkach - założenie, że optymalne rozwiązanie zadania da się złożyć z niewielkich, ponadprzeciętnych fragmentów chromosomu (schematów)
inwersja - technika samoadaptacyjna polegająca na zmianie kolejności bitów w chromosomie, co ułatwia tworzenie silnych, zwartych schematów ("cegiełek")
model wyspowy - podział populacji na równolegle przetwarzane podzbiory, sporadycznie wymieniające zestawy najlepszych osobników
schemat - ciąg znaków równy długością chromosomowi, zawierający 0, 1 i * (gwiazdka oznacza, że na tej pozycji może stać zarówno 0, jak i 1)
skalowanie liniowe funkcji celu - metoda sterowania szybkością zbieżności algorytmu poprzez uwypuklanie lub łagodzenie różnic między wartościami funkcji celu osobników
strategia elitarystyczna - metoda polegająca na przeniesieniu bez zmian najlepszych osobników do kolejnego pokolenia
twierdzenie o schematach - twierdzenie szacujące średnią liczbę reprezentantów danego schematu w kolejnych pokoleniach
ukryta równoległość - ocena osobników w algorytmie genetycznym traktowana jako równoległa ocena wielu schematów, do których dane osobniki pasują
11.1. Zaimplementować operator inwersji i porównać skuteczność działania algorytmów genetycznych wyposażonych i niewyposażonych w ten mechanizm.
Strona uaktualizowana przez Sinh Hoa Nguyen, 2009