Wykład będzie poświęcony zagadnieniom związanym z uczeniem się bez nadzoru, czyli z takim kierunkiem analizy danych, który nie wymaga znajomości prawidłowej odpowiedzi. Do metod tych zaliczamy sieci Kohonena i rozmaite metody grupowania pojęciowego.
Rozważane na poprzednich wykładach zadania klasyfikacji polegały na tym, że ktoś (ekspert, nauczyciel) prezentował pewien zbiór danych przypisanych do klas decyzyjnych, po czym budowana była reprezentacja tych danych, czy to w postaci wag sieci neuronowej, czy np. drzewa decyzyjnego. Jednym z kryteriów jakości klasyfikatora była zgodność wyników klasyfikatora z danymi treningowymi (z założenia wiemy, jak powinny te dane zostać sklasyfikowane).
Powyższe podejście nazywane jest uczeniem się z nadzorem (z nauczycielem). Przeciwieństwem tego podejścia są problemy, w których mamy podzielić zbiór obiektów na grupy, jednak nie mamy żadnych danych treningowych, z których moglibyśmy wywnioskować reguły tego podziału. Załóżmy, że mamy za zadanie pogrupować następujące słowa:
Rozsądnym wyjściem (przynajmniej tak by to zapewne rozwiązał człowiek) wydaje się podział:
Słowa zostały pogrupowane na bazie podobieństwa (długość, fonemy, litery). Podejście takie jest naturalne dla człowieka, ale oczywiście automatyzacja zadania grupowania obiektów wymaga jawnego określenia, jakie kryteria podobieństwa algorytm grupujący może brać pod uwagę. Uczenie bez nadzoru polega więc na tym, że zamiast szczegółowych wskazówek w postaci zbioru przykładów, mamy do dyspozycji ogólnie określone kryteria podobieństwa.
Sieci Kohonena są szczególnym przypadkiem algorytmu realizującego uczenie się bez nadzoru. Ich głównym zadaniem jest organizacja wielowymiarowej informacji (np. obiektów opisanych 50 parametrami w taki sposób, żeby można ją było prezentować i analizować w przestrzeni o znacznie mniejszej liczbie wymiarów, czyli mapie (np. na dwuwymiarowym ekranie). Warunek: rzuty "podobnych" danych wejściowych powinny być bliskie również na mapie. Sieci Kohonena znane są też pod nazwami Self-Organizing Maps, Competitive Filters.
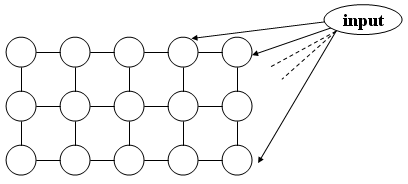
Topologia sieci Kohonena odpowiada topologii docelowej przestrzeni. Jeśli np. chcemy prezentować wynik na ekranie, rozsądnym modelem jest prostokątna siatka wezłów (im więcej, tym wyższą rozdzielczość będzie miała mapa):
Zasady działania sieci Kohonena:
Inicjalizacja wag sieci Kohonena jest losowa. Wektory wejściowe stanowią próbę uczącą, podobnie jak w przypadku zwykłych sieci rozpatrywaną w pętli podczas budowy mapy. Wykorzystanie utworzonej w ten sposób mapy polega na tym, że zbiór obiektów umieszczamy na wejściu sieci i obserwujemy, które węzły sieci się uaktywniają. Obiekty podobne powinny trafiać w podobne miejsca mapy.
Ciekawym zastosowaniem jest próba wykorzystania sieci Kohonena w eksploracji Internetu. Podobne pod względem treści dokumenty możemy rozłożyć na dwuwymiarowej mapie tak, by leżały w pobliżu siebie - prowadzi to do powstania mapy, na której można wyróżnić obszary tematyczne.
Grupowanie pojęciowe (analiza skupień, clustering) to algorytmy łączące obiekty w większe grupy na podstawie ich wzajemnego podobieństwa. Kryterium "podobieństwa" obiektów oparte jest na ich wzajemnej odległości (określonej jako np. suma modułów różnic między poszczególnymi cechami obiektów, o ile są wyrażone liczbowo). Przyjmijmy dla uproszczenia, że nasze obiekty opisane są liczbami (rysunki dotyczą przypadku dwuwymiarowego, czyli obiektów o dwóch cechach).
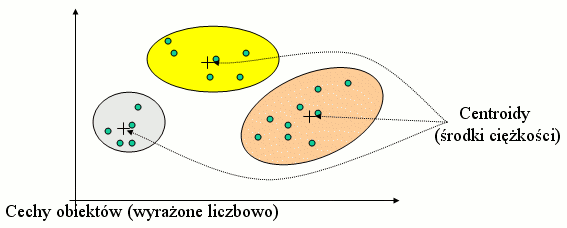
Zadanie optymalizacyjne: znaleźć taki podział, żeby odległości między obiektami w jednej klasie były jak najmniejsze, a między klasami - jak największe. Przyjmijmy, że wiemy, na ile klas chcemy podzielić dane.
Przykład: Zadanie kwantyzacji kolorów.
Znaleźć takich 16 kolorów, by za ich pomocą jak najwierniej odtworzyć oryginalny, 24-bitowy obrazek.
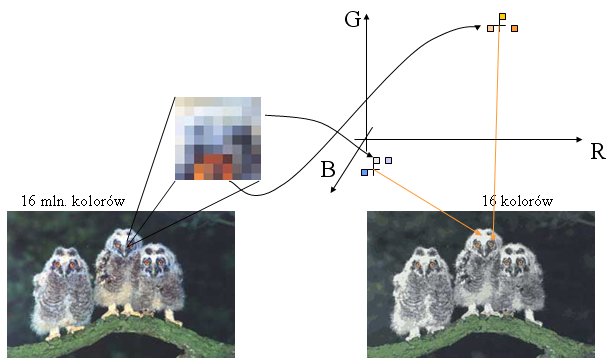
Wystarczy podzielić obiekty (tyle, ile jest pikseli w obrazie, czyli np. 1 milion) na 16 grup, przy czym kryterium to podobieństwo koloru pikseli. Potem przypiszemy każdej z 16 grup jej kolor średni i zamienimy wszystkie piksele wchodzące w skład grupy na ten właśnie kolor.
Algorytm k-means
Załóżmy, że mamy podzielić dane na K grup. Jednym z najprostszych algorytmów grupujących jest k-means:
Jest to prosta strategia budowy grup, nie dająca jednak gwarancji, że wynik bedzie optymalny (tzn. że inny podział na grupy nie będzie miał lepszych własności).
Algorytm centroidów
Drugi z prezentowanych algorytmów również nie daje pewności, że podział jest optymalny, ale zwykle daje lepsze wyniki (choć dłuzej działa).
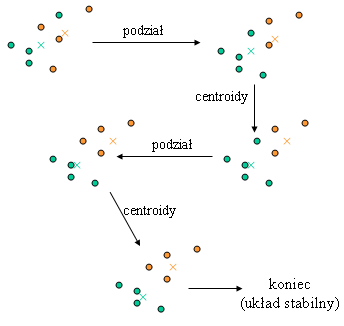
Jak widać, algorytm ten koncentruje się na poprawie istniejącego podziału. Można udowodnić, że algorytm zawsze się zatrzyma, tzn. w końcu osiągnie stan, którego już nie będzie mógł poprawić.
Zaprezentowano algorytmy uczenia się bez nadzoru. Główne pole zastosowania tego rodzaju algorytmów to metody automatycznego grupowania obiektów w sytuacji, gdy nie mamy narzuconych reguł podziału na grupy.
Zalecana literatura:
Szczegółowe definicje znajdują się w treści wykładu (słowa kluczowe zaznaczone są na czerwono).
centroid - średnia arytmetyczna współrzędnych punktów w grupie (czyli cech obiektów).
grupowanie pojęciowe - problem podziału zbioru danych na podstawie wzajemnego podobieństwa obiektów na możliwie wzajemnie odległe grupy.
k-means - jedna z metod grupowania obiektów.
sieć Kohonena - sieć węzłów realizująca ideę mapy samoorganizującej się, pozwalająca rozmieścić wielowymiarowe obiekty na dwuwymiarowej mapie.
uczenie z nadzorem - tworzenie algorytmów klasyfikujących na podstawie zbioru przykładów opatrzonych właściwymi odpowiedziami.
uczenie bez nadzoru - analiza danych, dla których nie znamy prawidłowego podziału na grupy.