Wykład 8
Algorytmy zrandomizowane.
Streszczenie
Pokażemy, jak wprowadzenie elementów losowych może wspomóc działanie niektórych algorytmów. Tematem wykładu jest też przegląd metod otrzymywania liczb losowych w programach oraz kolejna metoda optymalizacji - algorytm wychładzania.
Algorytmy zrandomizowane to takie, których działanie uzależnione jest od czynników losowych. Możemy wśród nich wyróżnić:
- Algorytmy typu Monte Carlo: dają (po pewnym czasie) wynik optymalny z prawdopodobieństwem bliskim 1.
- Algorytmy typu Las Vegas: dają zawsze wynik optymalny, a randomizacja służy jedynie poprawie szybkości lub stabilności działania.
Większość omawianych metod zrandomizowanych należy do klasy Monte Carlo. Wspólną cechą tych algorytmów jest możliwość zwiększania prawdopodobieństwa znalezienia optymalnego rozwiązania poprzez wielokrotne powtarzanie losowań. Cechy tej nie mają algorytmy deterministyczne (np. zachłanny).
Przykłady
- Algorytm szukania pokrycia macierzy przez wielokrotny losowy wybór kolejnych kolumn do pokrycia.
- Algorytm numeryczny: sprawdzanie, czy AB=C dla macierzy A,B,C. Mnożenie macierzy jest dość kosztowne, więc zamiast mnożyć A i B, losujemy wektor x i badamy, czy A(Bx)=Cx (ta operacja jest znacznie szybsza). Jesli nie, to na pewno AB nie jest równe C. Jeśli tak, to mogliśmy mieć pecha i musimy wylosować następne x. Im więcej wektorów sprawdzimy, tym większa pewność, że równość zachodzi.
W algorytmach klasy Las Vegas średnia złożoność obliczeniowa jest taka sama, jak w przypadku deterministycznym. Losowanie zapobiega natomiast pojawianiu się "złośliwych" danych wejściowych, dla którego dany algorytm działa mało efektywnie.
Przykład: RandomQuickSort
1. Mamy posortować zbiór S. Wybieramy z S losowy x.
2. Dzielimy S na zbiory S1 - elementów mniejszych niż x, oraz S2 - większych.
3. Rekurencyjnie sortujemy S1 i S2.
Jak wiadomo, metoda QuickSort dla niektórych danych działa w czasie kwadratowym. Nasz program może trafić na sytuację, w której źródło danych będzie nagminnie tworzyło dane w niekorzystej dla nas formie. Randomizacja chroni nas przed tego typu zbiegami okoliczności.
Aby wykorzystywać algorytmy zrandomizowane, konieczna jest umiejętność generowania liczb losowych. Ponieważ komputery są urządzeniami deterministycznymi (przynajmniej z założenia), źródłem losowości nie mogą być wyłącznie programy. Tzw. programowe generatory liczb pseudolosowych dają w rzeczywistości ciągi liczb ściśle przewidywalne, choć tak skonstruowane, by wyglądały na losowe (póki nie zna się algorytmu).
Źródłem "prawdziwej" losowości w komputerze mogą być takie elementy, jak zegar systemowy (najczęściej używany do inicjalizacji generatorów programowych), użytkownik (np. czas naciśnięcia klawisza, ruch myszki), zewnętrzne przyrządy pomiarowe (np. szum wzmacniacza, licznik Geigera obok próbki promieniotwórczej). W praktyce te źródła losowości służą do inicjowania ciągów liczb pseudolosowych w generatorach programowych, a także do celów specjalnych (np. kryptografia). Generatory programowe są natomiast zwykle określone pewnymi zależnościami rekurencyjnymi (kolejna liczba pseudolosowa jest wynikiem złożonych działań na poprzednich liczbach) i w związku z tym są okresowe.
Przykłady generatorów programowych:
- generatory Marsaglii:
xn = (xn-s + xn-r + c) mod M,
gdzie c = 1, jeśli poprzednia suma przekroczyła M, c = 0 w p.p.
Np: xn = (xn-2 + xn-21 + c) mod 6 , generator ten ma okres: 1016
Np: xn = (xn-22 - xn-43 - c) mod 232-5 , generator ten ma okres: 10414
- generator z niektórych kompilatorów C/C++ (np. GCC):
xn = (1103515245 xn-1 + 12345) mod 232
wówczas rand() = (xn / 216) mod 215
W niektórych zastosowaniach wymagane jest generowanie liczb losowych o zadanym rozkładzie. Załóżmy, że znamy gęstość f(x) tego rozkładu. Oto najważniejsze metody postepowania:
Odwracanie dystrybuanty.
Mamy wygenerować zmienną losową z rozkładu o znanej gęstości f(x). Niech F(x) - dystrybuanta tego rozkładu. Wtedy:
wynik = F-1(u)
jest szukaną zmienną losową, o ile u - wartość losowa z przedziału [0,1).
Metoda eliminacji.
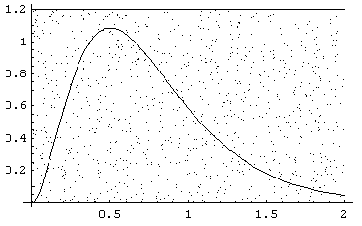 Znamy gęstość f(x) na pewnej dziedzinie D, jednak nie znamy F-1. Niech M - ograniczenie górne wartości f(x) na D. Narysujmy wykres gęstości na D, ograniczony w pionie wartościami 0 oraz M. Wówczas wartość losową u1 o zadanym rozkładzie uzyskamy poprzez losowanie punktów (u1,u2) z prostokąta zawierającego wykres i akceptowaniu tylko tych punktów, które znajdą się pod wykresem. Formalnie procedura ta może zostać zapisana jako:
Znamy gęstość f(x) na pewnej dziedzinie D, jednak nie znamy F-1. Niech M - ograniczenie górne wartości f(x) na D. Narysujmy wykres gęstości na D, ograniczony w pionie wartościami 0 oraz M. Wówczas wartość losową u1 o zadanym rozkładzie uzyskamy poprzez losowanie punktów (u1,u2) z prostokąta zawierającego wykres i akceptowaniu tylko tych punktów, które znajdą się pod wykresem. Formalnie procedura ta może zostać zapisana jako:
repeat
u1=random(D)
u2=random(0,M)
until u2
Przykład: losowanie (z rozkładem jednostajnym) punktów rozmieszczonych w kole jednostkowym.
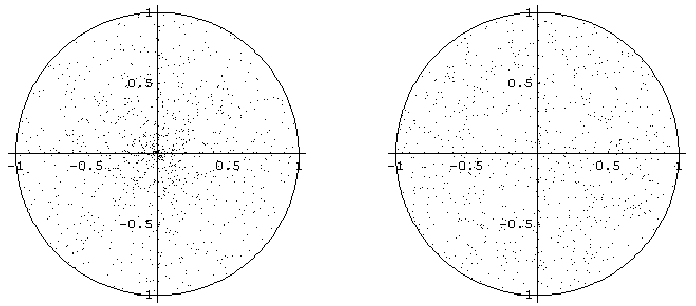
O konieczności zachowania szczególnej ostrożności podczas generowania liczb losowych przekonamy się na przykładzie pozornie prostego zadania: wygenerować punkty z koła jednostkowego, wylosowane zgodnie z rozkładem jednostajnym na tym kole. Metoda eliminacji polega w tym przypadku na losowaniu punktów z kwadratu obejmującego okrąg jednostkowy (co jest łatwe), a następnie ignorowaniu tych punktów, które leżą poza kołem. W ten sposób jednak tracimy prawie 25% wszytskich losowań - czy nie mozna tego procesu usprawnić? Wyobraźmy sobie następujące usprawnienie (nazwane roboczo "metodą biegunową"): najpierw losujemy kąt z przedziału [0.360], nastepnie promień z przedziału [0,1] i wynik traktujemy jako współrzędne biegunowe wylosowanego punktu. Dzięki temu nie tracimy żadnego losowania.
Niestety, rzut oka na poniższe wykresy wystarczy, by się przekonać o niewłaściwości metody biegunowej. Losowane punkty dalekie są od rozkładu jednostajnego na kole. Lewy wykres pokazuje rzeczywisty wynik zastosowania opisanej powyżej metody "biegunowej", prawy - metody eliminacji.
Ze względu na tematykę przedmiotu, najbadziej będą nas interesowały zrandomizowane wersje algorytmów optymalizacyjnych (heurystycznych). Tak zmodyfikowane algorytmy należą zwykle do klasy Monte Carlo, a więc pozwalają na znaczne zwiększenie prawdopodobieństwa znalezienia dobrych rozwiązań poprzez wielokrotne powtarzanie losowań. Oto niektóre z wykorzystywanych usprawnień:
- Najprostsza metoda: z przestrzeni stanów S losujemy wiele obiektów x i wybieramy ten, dla którego funkcja celu f(x) ma wartość największą.
- Błądzenie losowe: spacerujemy od sąsiada do sąsiada (jak w metodzie wspinaczki), wybierając sąsiadów losowo. Zapamiętujemy najlepszy wynik.
- Zrandomizowana wersja algorytmu zachłannego: w każdym kroku z prawdopodobieństwem 1/2 wybieramy najlepszą (lokalnie) ścieżkę budowy rozwiązania, z prawd. 1/4 - drugą z kolei, z prawd. 1/8 - trzecią itd.
- Zrandomizowana wersja algorytmu wspinaczki: w każdym kroku z prawdopodobieństwem 1/2 wybieramy najlepszego (dozwolonego) sąsiada, z prawd. 1/4 - drugiego z kolei, z prawd. 1/8 - trzeciego itd.
- Podobne modyfikacje można wprowadzić do algorytmów opartych na dwóch powyższych, a więc np. przeszukiwania wiązkowego czy metody tabu.
- Losujemy 1000 rozwiązań, wybieramy 10% najlepszych i każde z nich optymalizujemy algorytmem wspinaczki.
- Losujemy 1000 rozwiązań, wybieramy 10% najlepszych, z ich otoczenia losujemy znów w sumie 1000 rozwiązań, wybieramy 10% najlepszych itd.
Algorytm wychładzania (lub wyżarzania, simulated annealing) jest opartą na pojęciu sąsiedztwa zrandomizowaną metodą optymalizacji, często wykorzystywaną w praktyce.
 Schemat działania algorytmu wychładzania: startujemy z losowego punktu x0, wybieramy losowo nowy punkt x z sąsiedztwa aktualnego. Jeśli nowy punkt ma większą wartość - idziemy tam (jak w metodzie wspinaczki), jeśli mniejszą - nie rezygnujemy z niego od razu: z pewnym prawdopodobieństwem P(x0,x) albo tam idziemy, albo pozostajemy w x0. Znów losujemy sąsiada aktualnego rozwiązania i koło się zamyka. Algorytm zatrzymuje się po zadanym czasie lub po znalezieniu satysfakcjonującego rozwiązania.
Schemat działania algorytmu wychładzania: startujemy z losowego punktu x0, wybieramy losowo nowy punkt x z sąsiedztwa aktualnego. Jeśli nowy punkt ma większą wartość - idziemy tam (jak w metodzie wspinaczki), jeśli mniejszą - nie rezygnujemy z niego od razu: z pewnym prawdopodobieństwem P(x0,x) albo tam idziemy, albo pozostajemy w x0. Znów losujemy sąsiada aktualnego rozwiązania i koło się zamyka. Algorytm zatrzymuje się po zadanym czasie lub po znalezieniu satysfakcjonującego rozwiązania.
x0 = Random(X)
do
x = Random(N(x0))
if(f(x) > f(x0))
x0=x
else
if(Random() < P(x0,x))
x0=x
while(time_out)
Prawdopodobieństwo akceptacji gorszego stanu dane jest wzorem:
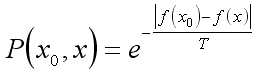
gdzie T - pewien parametr (temperatura)
Prawdopodobieństwo zależy od temperatury (im niższa, tym mniejsze), oraz od spadku wartości funkcji f.
Parametr temperatury służy do regulowania skłonności algorytmu do akceptowania gorszych rozwiązań - wysoka temperatura oznacza, że chętniej będziemy wychodzili z maksimów lokalnych. Temperatura zwykle zmniejsza się w czasie:
Zaletą algorytmu wychładzania jest znaczna odporność na maksima lokalne. Wadą - wolniejsza zbieżność (jeśli maksimum jest tylko jedno, to metoda wspinaczki znajdzie je szybciej).
Wprowadzenie elementów losowych do algorytmów może w niektórych przypadkach usprawnić ich pracę, umożliwiając np. wielokrotne ponawianie prób znalezienia coraz lepszych rozwiązań. Zaprezentowano zrandomizowane wersje poznanych już heurystyk optymalizacyjnych, a ponadto algorytm wychładzania - zrandomizowaną metodę pozwalającą na omijanie maksimów lokalnych funkcji celu. Ważną częścią wykładu jest też ogólny przegląd metod otrzymywania wartości losowych w komputerze.
Zalecana literatura:
- T.H. Cormen, C.E. Leiserson, R.L. Rivest. Wprowadzenie do algorytmów. WNT, Warszawa 1997.
- Wieczorkowski, Zieliński. Komputerowe generatory liczb losowych. WNT, Warszawa 1997.
Szczegółowe definicje znajdują się w treści wykładu (słowa kluczowe zaznaczone są na czerwono).
algorytm wychładzania (wyżarzania) - metoda optymalizacji pozwalająca omijać maksima lokalne
algorytmy Las Vegas - algorytmy zrandomizowane dające zawsze poprawny wynik, w których randomizacja usprawnia ich działanie (np. poprzez unikanie "trudnych" przypadków danych wejściowych)
algorytmy Monte Carlo - algorytmy zrandomizowane dające wynik optymalny z prawdopodobieństwem dowolnie bliskim 1 (w zależności od czasu działania)
algorytmy zrandomizowane - algorytmy, których działanie uzależnione jest od czynników losowych
metoda eliminacji - jedna z metod uzyskiwania liczby losowej o zadanym rozkładzie
odwracanie dystrybuanty - jedna z metod uzyskiwania liczby losowej o zadanym rozkładzie
temperatura - parametr algorytmu wychładzania regulujący szybkość wychodzenia algorytmu z maksimów lokalnych
8.1. Jak najefektywniej wylosować punkt z rozkładu jednostajnego na okręgu jednostkowym
8.2. Jak działa algorytm wychładzania, gdy temperatura T maleje prawie do 0?
8.3. Zaproponować i zaimplementować zrandomizowaną wersję algorytmu grupowania k-means. Sprawdzić skuteczność działania obu wersji na zestawach danych losowych.
Strona uaktualizowana
przez Sinh Hoa Nguyen,
2009