Budowa i ponowne wykorzystanie klas
Wykład systematyzuje podstawowe pojęcia, związane z programowaniem
obiektowym w Javie, jednocześnie przedstawiając ich zastosowanie przy budowie
konkretnych klas obiektów.
Dotychczas wprowadzone zostały tylko niezbędne dla podstaw
programowania
w Javie elementy obiektowości (zob. wcześniejsze
wykłady "Klasy i obiekty"). Tutaj rozszerzymy ich zakres.
Zostaną m.in. przedstawione pojęcia przeciążania i przedefiniowania
metod, będzie też mowa o ponownym wykorzystaniu klas. Przypominając
konwersje referencyjne zajmiemy się też w szczegółach sposobami
stwierdzania typu zmiennych.
1. Abstrakcja i hermetyzacja
Java jest językiem obiektowym. Języki obiektowe posługują się pojęciem obiektu i klasy.
Obiekt – to konkretny lub abstrakcyjny byt, wyróżnialny w modelowanej rzeczywistości,
posiadający określone granice i atrybuty (właściwości) oraz mogący świadczyć
określone
usługi, czyli wykonywać określone działania lub przejawiać określone zachowanie.
Obiekty współdziałają ze sobą wymieniając komunikaty.
Komunikat - to wąski i dobrze określony interfejs, opisujący współzależność działania obiektów.
Komunikaty zwykle żądają od obiektów wykonania określonych (właściwych im) usług.
Jak już wiemy, klasa opisuje wspólne cechy grupy podobnych obiektów.
Klasa - to opis takich cech grupy podobnych obiektów, które są dla nich
niezmienne (np. zestaw atrybutów i metod czyli usług, które mogą świadczyć)
Przedstawione definicje stanowią abstrakcyjne odzwierciedlenie cech rzeczywistości.
Gdybyśmy mieli w języku programowania podobne pojęcia, to moglibyśmy ujmować
projekt rozwiązania rzeczywistego problemu i jego oprogramowanie w języku
adekwatnym do problemu.
I to zapewniają języki obiektowe. Jest to ich bardzo
ważna cecha – zwana abstrakcją obiektowa, znacznie ułatwiająca tworzenie oprogramowania.
Programowanie polega na przetwarzaniu danych. Dane zawsze są określonych
typów, a typ to nic innego jak rodzaj danych i działania które na nich można
wykonać.
Z pragmatycznego punktu widzenie możemy więc powiedzieć, że klasa to typ,
jej definicja opisuje właściwości typu danych (również funkcjonalne tzn.
jakie są dostępne operacje na danych tego typu).
Języki obiektowe pozwalają na definiowanie własnych klas – własnych typów
danych, co właśnie oznacza programowanie w języku problemu.
O obiektach możemy myśleć jako o egzemplarzach określonych klas.
Możemy mieć np. klasę pojazdów o następujących atrybutach: szerokość, wysokość,
długość, ciężar, właściciel, stan (stoi, jedzie, zepsuty itp.) oraz udostępniających
usługi: ruszania, zatrzymywania, zmiany właściciela (sprzedaż pojazdu) itp
.
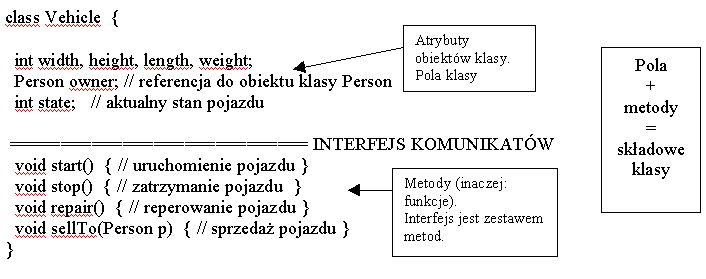
Gdy mamy np. dwa obiekty – egzemplarze klasy pojazdów, oznaczane przez zmienne
a i b, to możemy symulować w programie sekwencję działań: uruchomienie pojazdu
a, uruchomienie pojazdu b, zatrzymanie obu pojazdów - za pomocą komunikatów
posyłanych do obiektów, np.:
a.start(); // komunikat do pojazdu a: ruszaj!
b.start(); // komunikat do pojazdu b: ruszaj!
a.stop(); // komunikat do pojazdu a: zatrzymaj się!
b.stop(); // komunikat do pojazdu b: zatrzymaj się!
Jak wiemy, mówi się również: a.start() - to użycie metody start() na rzecz obiektu oznaczanego przez zmienną a.
Zauważmy: dzięki abstrakcji obiektowej w programowaniu posługujemy się językiem
zbliżonym do języka opisu rzeczywistego problemu.
Oprócz odzwierciedlenia w programie "języka problemu" podejście obiektowe
ma jeszcze jedną ważną przewagę nad ujęciami nieobiektowymi.
Mianowicie, można zapewnić aby atrybuty obiektów nie były bezpośrednio dostępne poza klasą. W programie
z obiektami "rozmawiamy" za pomocą komunikatów, obiekty same "wiedzą najlepiej"
jak zmieniać swoje stany. Dzięki temu nie możemy nic nieopatrznie popsuć,
co więcej nie możemy zażądać od obiektu usługi, której on nie udostępnia.
Dane (atrybuty) są ukryte i są traktowane jako nierozdzielna całość z usługami.
Nazywa się to hermetyzacją i oznacza znaczne zwiększenie odporności programu na błędy.
Sama koncepcja klasy jako zestawu pól i metod już zapewnia określony poziom hermetyzacji.
Nie możemy np. do obiektów klasy Vehicle posłać komunikatu sing(),
bowiem metoda sing() nie występuje jako składowa w tej klasie.
Dodatkowo języki obiektowe (w tym Java) pozwalają ukrywać dane (i metody) przed powszechnym dostępem.
Dostęp do składowych klasy regulują tzw. specyfikatory dostępu, których używamy w deklaracjach zmiennych, stałych i metod.
Każda składowa klasy może być:
- prywatna – dostępna tylko w danej klasie (specyfikator private),
- zaprzyjaźniona – dostępna ze wszystkich klas danego pakietu; mówi się tu też o dostępie pakietowym
lub domyślnym - domyślnym dlatego, iż ten rodzaj dostępności występuje wtedy,
gdy w deklaracji składowej nie użyjemy żadnego specyfikatora,
- chroniona lub zabezpieczona – dostępna z danej klasy, wszystkich klas
ją dziedziczących oraz z klas
danego pakietu (specyfikator protected),
- publiczna – dostępna zewsząd (specyfikator public).
Po co jest prywatność?
1. Ochrona przed zepsuciem (zazwyczaj pola powinny być prywatne, wyjątkiem są stałe)
- użytkownik klasy nie ma dostępu do prywatnych pól i nic nie popsuje (nieświadomie).
2. Zapewnienie właściwego interfejsu (metody "robocze" winny być prywatne)
- użytkownik klasy ma do dyspozycji tylko niezbędne (klarowne) metody, co ułatwia mu korzystanie z klasy.
3. Ochrona przed konsekwencjami zmiany implementacji
- twórca klasy może zmienić zestaw i implementację prywatnych metod,
nie zmieniając interfejsu publicznego: wszystkie programy napisane przy wykorzystaniu
tego interfejsu nie będą wymagały żadnych zmian.
Mamy też w Javie pojęcie klas publicznych i pakietowych (klasy w Javie są
albo publiczne albo pakietowe). Klasa pakietowa jest dostępna tylko z klas
pakietu. Klasa publiczna jest dostępna zewsząd (z innych pakietów). Klasę
publiczną deklarujemy ze specyfikatorem public
Stosując regułę ukrywania danych i specyfikatory dostępu możemy teraz przedstawić
przykładową definicję klasy Person, a następnie zmodyfikować definicję klasy
Vehicle.
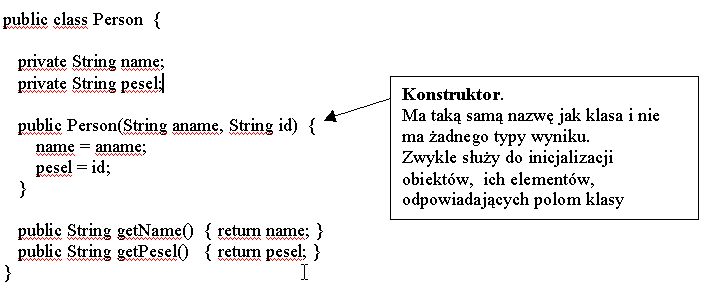
Atrybuty obiektów klasy Person przedstawiono jako pola prywatne.
Spoza klasy nie ma do nich dostępu.
Przy tworzeniu obiektu jego elementy odpowiadające tym polom są inicjowane
za pomocą wywołania konstruktora. Później zmiany tych elementów danych nie
są już możliwe, możemy tylko uzyskać dane za pomocą publicznych metod getName()
i getPesel().
Modyfikując i rozbudowując klasę Vehicle w myśl reguł hermetyzacji:
- uczynimy atrybuty pojazdów prywatnymi,
- dostarczymy – jako publicznego – tylko niezbędnego interfejsu,
- ukryjemy "roboczą" metodę zmieniającą stan obiektu,
- wprowadzimy
publiczne stałe oznaczające stany pojazdu oraz odpowiadające
im nazwy stanów (które uczynimy prywatnymi, by ew. zmiany nazw nie
wpływały
na oprogramowanie wykorzystujące klasę Vehicle). Alternatywnie na
oznaczenie stanów moglibyśmy użyć enumeracji, ale bez nich przykład
będzie będzie bardziej zwarty i klarowny.
public class Vehicle {
// stany
public final int BROKEN = 0, STOPPED = 1, MOVING = 2;
private final String[] states = { "ZEPSUTY", "STOI", "JEDZIE" };
private int width, height, length, weight;
private Person owner;
private int state;
public Vehicle(Person p, int w, int h, int l, int ww) { // konstruktor
owner = p; width = w; height = h;
length = l; weight = ww; state = STOPPED;
}
public void start() { setState(MOVING); }
public void stop() { setState(STOPPED); }
// Prywatna metoda robocza wykorzystywana w metodach start() i stop().
// Arbitralne ustalenie stanu spoza klasy nie jest możliwe
private void setState(int newState) {
if (state == newState || state == BROKEN)
System.out.println("Nie jest mozliwe przejscie ze stanu " +
states[state] + " do stanu " + states[newState]);
else state = newState;
}
public void repair() {
if (state != BROKEN)
System.out.println("Pojazd sprawny");
else state = STOPPED;
}
// Sprzedaż pojazdu
public void sellTo(Person p) {
owner = p;
}
public String toString() {
return "Pojazd, właścicielem którego jest "
+ owner.getName() + " - " + states[state];
}
}
Zwróćmy uwagę:
- atrybuty pojazdu (wysokość, waga etc) nadawane są przy tworzeniu obiektu i żadna inna klasa nie może ich później zmienić,
- stan pojazdu jest zmieniany tylko na skutek wywołania publicznych metod
start(), stop(), repair() przy czym "sam obiekt" dba, by nie dopuścić do
niewłaściwych zmian (zob. definicje tych metod oraz prywatnej metody setState(...)).
- przypomnijmy, że metoda toString() ma ważną właściwość:
jest wywoływana, gdy referencja do obiektu klasy, w której ją
zdefiniowano,
pojawi się w wyrażeniu konkatenacji; wynik zastępuje w tym wyrażeniu
wspomnianą
referencję. A zatem jeśli v jest obiektem klasy Vehicle, i użyliśmy
wobec
niego metody start(), to gdy napiszemy System.out.println("
=> " + v);
to na konsolę zostanie wyprowadzony napis "=> Pojazd, właścicielem
którego
jest ... - JEDZIE". Sama metoda println(...) wołana z
argumentem-dowolnym obiektem w swoim wnętrzu też używa metody
toString() z klasy obiektu do wypisania informacji o obiekcie.
2. Wykorzystanie składowych statycznych
Stałe (oznaczające stany i ich nazwy) są teraz zawarte w każdym tworzonym
obiekcie klasy Vehicle. Niewątpliwie jest to marnotrawstwo: powinniśmy móc
zdefiniować je jako właściwość raczej całej klasy obiektów, a nie każdego
obiektu z osobna (zawsze są przecież takie same). Na pomoc przychodzi koncepcja
składowych statycznych. Przypomnijmy:
Składowe klasy mogą być
statyczne i niestatyczne.
Niestatyczne zawsze wiążą się z istnieniem jakiegoś obiektu (pola
- odpowiadają elementom obiektu, metody muszą być wywoływane na rzecz obiektu,
są komunikatami do obiektu)
Składowe statyczne (pola i metody) są wspólne dla wszystkich obiektów i:
- są deklarowane przy użyciu specyfikatora static,
- mogą być używane nawet wtedy, gdy nie istnieje żaden obiekt klasy
Uwaga: ze statycznych metod nie wolno odwoływać się do niestatycznych
składowych klasy (obiekt może nie istnieć). Możliwe są natomiast odwołania
do innych statycznych składowych.
Spoza klasy do jej statycznych składowych możemy odwoływać się na dwa sposoby:
- NazwaKlasy.NazwaSkładowej
- gdy istnieje jakiś obiekt: tak samo jak do niestatycznych składowych (uwaga: jest to mylące i nie polecane).
Uczynimy zatem stałe zdefiniowane w klasie Vehicle statycznymi, dostarczymy
też metody pozwalającej pokazać możliwe nazwy stanów pojazdów, nawet jeśli
nie ma jeszcze żadnych obiektów klasy Vehicle. Skorzystamy też z koncepcji
składowych statycznych po to, by każdemu pojazdowi tworzonemu w naszym programie
nadawać unikalny numer (powiedzmy od jednego), a także zawsze mieć rozeznanie
ile obiektów typu Vehicle dotąd utworzyliśmy.
public class Vehicle {
public final static int BROKEN = 0, STOPPED = 1, MOVING = 2;
private final static String[] states = { "ZEPSUTY", "STOI", "JEDZIE" };
private static int count; // ile obiektów dotąd utworzyliśmy
private int currNr; // bieżący numer pojazdu
//...
public Vehicle(Person p, int w, int h, int l, int ww) {
// ....
// Każde utworzenie nowego obiektu zwiększa licznik o 1
// bieżąca wartość licznika nadawana jest jako numer pojazdu
// numer pojazdu jest niestatycznym polem klasy, a więc elementem obiektu
currNr = ++count;
}
//.....
// zwraca unikalny numer pojazdu
public int getNr() { return currNr; }
// zwraca liczbę dotąd utworzonych obiektów
// metoda jest statyczna, by móc zwrócić 0
// gdy nie ma jeszcze żadnego obiektu
public static int getCount() { return count; }
// zwraca tablicę nazw stanów
// Metoda jest statyczna, bo dopuszczalne stany
// nie zależą od istnienia obiektów
public static String[] getAvailableStates() {
return states;
}
// ...
}
Wykorzystanie:
// jakie są dopuszczalne nazwy stanów
// pojazdów?
String[] stany = Vehicle.getAvailableStates();
// ile obiektów dotąd utworzyliśmy?
int n =Vehicle.getCount()
3. Inicjacje
Przy tworzeniu obiektu:
- pola klasy mają zagwarantowaną inicjację na wartości ZERO (0, false
– dla typu boolean, null – dla referencji, co oznacza referencję "pustą",
nie odnosząca się do żadnego obiektu),
- zwykle w konstruktorze dokonuje się reinicjacji pól,
- ale można również posłużyć się jawną inicjacją przy deklaracji pól.
Obiekt klasy Vehicle składa się z następujących elementów (odpowiadają one polom klasy):
private int currNr;
private int width, height, length, weight;
private Person owner;
private int state;
W trakcie tworzenia obiektu ( new Vehicle(...) ) uzyskają one wartości 0
(dla elementów typu int) oraz null dla elementu, odpowiadającego referencji
owner.
Następnie zostanie wywołany konstruktor, w którym dokonujemy właściwej inicjacji.
Można by było napisać np.
private int state = STOPPED; // jawna inicjacja pola
i usunąć z konstruktora instrukcję state = STOPPED.
Z inicjacją wiąże się również pojęcie bloków inicjacyjnych.
Jak pamiętamy - w Javie w zasadzie nie można używać instrukcji wykonywalnych
(m.in. sterujących) poza ciałami metod. Od tej zasady istnieją jednak dwa wyjątki:
- użycie niestatycznego bloku inicjacyjnego,
- oraz użycie statycznego bloku inicjacyjnego.
Niestatyczny blok inicjacyjny wprowadzamy ujmując kod wykonywalny w nawiasy
klamrowe i umieszczając taką konstrukcję w definicji klasy poza ciałem jakiejkolwiek
metody (czy konstruktora). Kod bloku zostanie wykonany na etapie inicjacji obiektu, czyli przy
tworzeniu obiektu, przed wywołaniem konstruktora.
Taka możliwość może okazać się przydatna, gdy mamy kilka
konstruktorów (o
wielu różnych konstruktorach definiowanych w jednej klasie - zob.
dalej) i chcemy wyróżnić pewien kod, który będzie inicjował obiekt
niezależnie
od użytego konstruktora i przed użyciem jakiegokolwiek z nich.
Np. możemy w bloku inicjacyjnym wyodrębnić nieco bardziej zaawansowaną postać
inicjacji zmiennej state, opisującej stan pojazdu.
public class Vehicle {
// ...
private int state;
// Niestatyczny blok inicjacyjny
// -- w niedzielę wszystkie samochody inicjalnie stoją
// -- w poniedziałek te o parzystych numerach inicjalnie jadą,
// inne - stoją
// -- w pozostałe dni tygodnia: pierwszy stworzony inicjalnie stoi,
// inne jadą
{ // początek bloku
int dayOfWeek = Calendar.getInstance().get(Calendar.DAY_OF_WEEK);
switch (dayOfWeek) {
case Calendar.SUNDAY : state = STOPPED; break;
case Calendar.MONDAY : state = (currNr % 2 == 0 ? MOVING : STOPPED);
break;
default : state = (currNr == 1 ? STOPPED : MOVING);
break;
}
} // koniec bloku
// Konstruktory i metody klasy
public Vehicle(...) {
// ...
}
// ...
}
Uwaga: dla uzyskania aktualnego dnia tygodnia stosujemy klasę Calendar. Wywołanie
Calendar.getInstance().get(Calendar.DAY_OF_WEEK) zwraca stałą oznaczającą dzień tygodnia.
W pokazanym przypadku takie wyodrębnienie niestatycznego bloku inicjacyjnego ma pewien sens (kod ew. kilku konstruktorów jest
może bardziej czytelny), ale zazwyczaj nie jest to zbyt interesujące rozwiązanie,
i - jeśli już - należy go stosować z wyjątkowym umiarem (bowiem może ono
oznaczać trudniej czytelny kod - rozproszony po wielu miejscach, zamiast
skupiony w naturalnym miejscu inicjacji - konstruktorach).
Ciekawszym rozwiązaniem wydaje się statyczny blok inicjacyjny
. Czasem pojawia się potrzeba wykonania jakiegoś kodu jeden raz, przy pierwszym
odwołaniu do klasy. Przy inicjacji pól statycznych możemy skorzystać z dowolnych
wyrażeń, składających się ze zmiennych i stałych statycznych oraz z wywołań
statycznych metod, ale - oczywiście - nie sposób użyć instrukcji wykonywalnych
(np. sterujących).
Statycznym blok inicjacyjny wprowadzamy słowem kluczowym static z
następującym po nim kodem ujętym w nawiasy klamrowe. Kod ten będzie wykonywany
jeden raz przy pierwszym odwołaniu do klasy (np. użyciu metody statycznej
lub stworzeniu pierwszego obiektu). Oczywiście, z takiego bloku możemy odwoływać
się wyłącznie do zmiennych statycznych (obiekt jeszcze nie istnieje).
Przykład:
wyobraźmy sobie, że numeracja pojazdów zależy od domyślnej lokalizacji (ustawień regionalnych) aplikacji
(inna jest jeśli lokalizacją jest USA - inną dla, powiedzmy, Włoch). Będziemy
więc inicjować zmienną statyczną count w zależności od lokalizacji (w tym
przypadku oczywiście count nie będzie oznaczać liczby utworzonych w programie
obiektów, ale inicjalny numer pojazdu). Taki problem można rozwiązać właśnie
za pomocą statycznego bloku inicjacyjnego.
public class Vehicle {
public final static int BROKEN = 0, STOPPED = 1, MOVING = 2;
private final static String[] states = { "ZEPSUTY", "STOI", "JEDZIE" };
private static int count;
// Statyczny blok inicjacyjny
// za jego pomocą inicjujemy zmienną count w taki sposób,
// by numery pojazdów zaczynały się w zależności
// od domyślnej lokalizacji aplikacji
// np. jeśli aplikacja jest wykonywana w lokalizacji włoskiej
// numery zaczynają się od 10000.
static {
Locale[] loc = { Locale.UK, Locale.US, Locale.JAPAN, Locale.ITALY, };
int[] begNr = { 1, 100, 1000, 10000, };
count = 300; // jeżeli aplikacja działa w innej od wymienionych
// w tablicy lokalizacji, zaczynamy numery od 300
Locale defLoc = Locale.getDefault(); // jaka jest domyślna lokalizacja?
for (int i=0; i < loc.length; i++)
if (defLoc.equals(loc[i])) {
count = begNr[i];
break;
}
} // koniec bloku
// pola niestatyczne
private int currNr = ++count;
private int width, height, length, weight;
// ...
// Konstruktory i metody
// ...
} // koniec klasy
Uwaga:
obiekty klasy Locale z pakietu java.util oznaczają lokalizacje. W
kodzie dostarczamy tablicy lokalizacji loc inicjowanej statycznymi
stałymi klasy Locale. Metoda getDefaultLocale() zwraca aktualne
systemowe ustawienia regionalne (aktualną lokalizację).
Ogólnie inicjatory pól statycznych oraz statyczne bloki inicjacyjne nazywają się inicjatorami statycznymi, a niestatyczne bloki inicjacyjne i inicjatory niestatycznych pól - inicjatorami niestatycznymi.
Niezwykle ważne są reguły inicjacji.
- Inicjacja
klasy powoduje jednokrotne zainicjowanie elementów statycznych
tzn. najpierw wszystkie pola statyczne uzyskują wartości domyślne, a
następnie wykonywane są inicjatory statyczne w kolejności ich
występowania w klasie. Inicjacja klasy następuje w wyniku jej
załadowania przez JVM, co może się zdarzyć przy uruchomieniu głównej
klasy programu lub pierwszym odwołaniu z programu do innej klasy na
skutek odwołanie do składowej statycznej
(np. Vehicle.getCount()) lub utworzenie obiektu ( np. Vehicle v – new
Vehicle());
- Tworzenie każdego obiektu (new)
powoduje nadanie niestatycznym polom klasy wartości domyślnych,
następnie wykonanie inicjatorów niestatycznych w kolejności ich
występowania w klasie, po czym wykonywany jest konstruktor. W
momencie tworzenia jakiegokolwiek obiektu wszystkie pola statyczne są
już zainicjowane i zostały już wykonane wszystkie inicjatory statyczne.
- W
inicjatorach statycznych można odwoływać się do wszystkich statycznych
metod klasy, ale tylko do tych statycznych pól, których deklaracje
poprzedzają inicjator.
- W inicjatorach niestatycznych można
odwoływać się do wszystkich metod klasy, do wszystkich pól statycznych
(niezależnie od miejsca ich występowania), ale tylko do tych pól
niestatycznych, których deklaracje poprzedzają inicjator.
- W konstruktorze można odwoływać się do wszystkich metod i pól klasy (są już zainicjowane).
Reguł
inicjacji nie należy lekceważyć, bowiem niewłaściwa kolejność
inicjatorów w kodzie może prowadzić do subtelnych błędów.
Lepszemu zrozumieniu może sprzyjąć następujący program:
public class InitOrder {
private static int s = 100;
private static final int C;
private int a = 1;
InitOrder() {
report("Konstruktor: s, C, a, b mają wartości :", s, C, a, b);
}
private int b = 2;
{
report("Blok inicjacyjny: s, C, a =", s, C, a);
}
static {
report("Statyczny blok inicjacyjny, zmienna s = ", s);
C = 101; // opóźniona inicjacja stałej!
}
private static void report(String msg, int ... args ) {
System.out.print(msg + " ");
for (int i : args) {
System.out.print(i + " ");
}
System.out.println();
}
public static void main(String[] args) {
report("Wywołanie metody main");
new InitOrder();
}
}który wyprowadzi w wyniku:
Statyczny blok inicjacyjny, zmienna s = 100
Wywołanie metody main
Blok inicjacyjny: s, C, a = 100 101 1
Konstruktor: s, C, a, b mają wartości : 100 101 1 2
Najczęściej
jednak nie będziemy stosować zbyt zaawansowanych konstrukcji
inicjacyjnych i całkiem wystarczająca jest prosta regułka: najpierw - i
tylko raz - inicjowane są kolejno pola statyczne, a przy każdym
tworzeniu obiektu - kolejno - pola niestatyczne. Opierając się na niej
w łatwy sposób uzyskamy zwięzłość kodowania.
Gdybyśmy np. zmienili interpretację statycznego pola count (niech będzie
to teraz pierwszy dopuszczalny numer identyfikacyjny) i jawnie je zainicjowali
wielkością 100, to w kontekście:
class Vehicle {
private int currNr = ++count;
private static count = 100;
...
public int getNr() { return currNr; }
public static int getCount() { return count; }
}
po:
Vehicle.getCount()
Vehicle v = new Vehicle(...);
wyrażenie:
v.getNr()
miałoby wartość 101.
4. Przeciążanie metod i konstruktorów
W klasie (i/lub jej klasach pochodnych) możemy zdefiniować metody o tej samej
nazwie, ale różniące się liczbą i/lub typami parametrów.
Nazywa się to przeciążaniem metod.
Po co istnieje taka możliwość?
Wyobraźmy sobie, że na obiektach klasy par liczb całkowitych (znanej nam
z poprzednich rozdziałów) chcielibyśmy wykonywać operacje:
- dodawania innych obiektów-par
- dodawania (do składników pary) kolejno dwóch podanych liczb całkowitych
- dodawania (do każdego składnika pary) jednej i tej samej podanej liczby całkowitej
Gdyby nie było przeciążania metod musielibyśmy dla każdej operacji wymyślać
inną nazwę metody. A przecież istota operacji jest taka sama (wystarczy więc
nazwa add), a jej użycie powinno być jasne z kontekstu (określanego przez argumenty).
Dzięki przeciążaniu można w klasie Para np. zdefiniować metody:
void add(Para p) // dodaje do pary, na rzecz której wywołano metodę, parę
// podaną jako argument
void add(int i) // do obu składników pary dodaje podaną liczbę
void add(int i, int k) // pierwszą podaną liczbę dodaje do pierwszego składnika pary
// a drugą - do drugiego
i użyć – gdzie indziej – w naturalny sposób:
Para p;.
Para jakasPara;
....
p.add(3);
// wybierana jest ta metoda, która pasuje (najlepiej) do argumentów
p.add(1,2);
p.add(jakasPara);
Innym
przykładem przeciążonej metody jest metoda println(...). Ma ona bardzo
wiele wersji - z argumentami różnych typów (m.in. wszystkich prostych,
String i Object). I bardzo dobrze, bo w przeciwnym przypadku
musielibyśmy pisać np. printInt(3) i printString("Ala"), aby
wyprowadzić odpowiednio liczbę całkowitą i napis.
Identyfikatory metod definiowanych w klasie muszą być od siebie różne.
Wyjątkiem od tej reguły są metody przeciążone tj. takie, które mają tę samą nazwę (identyfikator), ale różne typy i/lub liczbę argumentów
Z przeciążaniem metod związany jest pewien problem. Otóż dopasowanie wywołania
do odpowiedniej wersji metody jest dokonywane przez kompilator na podstawie
liczby i typów argumentów. Musimy przy tym uważać, bowiem kiedy liczba parametrów
jest w różnych wersjach metody przeciążonej taka sama, a ich typy zbliżone
- to może się okazać, że źle interpretujemy działanie programu. Co się np
stanie, jeśli mamy dwie metody o nazwie show, pierwsza z parametrem typu
short, a druga z parametrem typu int, i wywołujemy metodę show z argumentem
typu char ? Powiedzieliśmy przed chwilą, że zostanie wywołana metoda, której
parametry najlepiej pasują do argumentów wywołania. Ponieważ typ short jest
"bliższy" typowi char niż typ int - mogłoby się wydawać, że zostanie wywołana
metoda show(short).
Tymczasem - jak pamiętamy - wykonywana jest promocja argumentu
typu char do typu int i będzie wywołana metoda show(int).
Jeżeli nie znamy dobrze mechanizmów automatycznych konwersji, to w metodach
przeciążonych specyfikujmy różną liczbę parametrów lub radykalnie różne typy
parametrów
Ogólnie, algorytm wyboru przez kompilator odpowiedniej metody
przeciążonej jest dość skomplikowany i może mieć zaskakujące,
nieintuicyjne konsekwencje (zob. specyfikację języka: JLS 15.12.2.5).
Również z tego powodu należy wyraźnie różnicować liczbę/typy argumentów.
Zwróćmy też uwagę, że przeciążanie "rozciąga się" na różne rodzaje metod.
Dwie metody - statyczną i niestatyczną - o tej samej nazwie, ale o różnych
typach/liczbie argumentów są przeciążone.
Podobnie jak w przypadku metod, możemy przeciążać konstruktory, Znaczy
to, że w jednej klasie możemy mieć kilka wersji konstruktorów z różnymi parametrami.
W ten sposób udostępniamy różne sposoby inicjacji obiektów klasy.
W takim
przypadku, po to by nie powtarzać wspólnego kodu w różnych konstruktorach,
wygodna okazuje się możliwość wywoływania konstruktora z innego konstruktora.
Do takiego wywołania stosujemy słowo kluczowe this, co ilustruje poniższy
fragment składni:

5. Zastosowanie słowa kluczowego this
Słowo kluczowe
this w ciele konstruktorów i metod niestatycznych oznacza
referencję do danego obiektu (tzn. tego, który jest inicjowany przez konstruktor
lub tego na rzecz którego użyto metody).
Zwykle nie używamy this: odwołania do składowych klasy wewnątrz konstruktora lub metody są jednoznaczne – dotyczą
tego obiektu (inicjowanego przez konstruktor lub na rzecz którego wywołano metodę). Np.
public void start() { setState(MOVING); }
=
public void start() { this.setState(Vehicle.MOVING); }
i
public int getState() { return state; }
=
public int getState() { return this.state; }
Czasem jednak musimy użyć słowa this.
1. Przy przesłonięciu nazw zmiennych oznaczających pola.
Np.:
class Vehicle {
private int width, height, length, weight;
private Person owner = null;
private int state;
public Vehicle(Person owner, int width, int height, int length, int weight) {
this.owner = owner; this.width = width; this.height = height;
this.length = length; this.weight = weight;
}
2. Drugi - częsty - przypadek koniecznego użycia słowa this występuje
wtedy, gdy metoda musi zwrócić TEN obiekt (na rzecz którego została wywołana).
Możemy np. zdefiniować metodę repair() tak, by zwracała ten pojazd (który został naprawiony).
Vehicle repair() {
// ...
return this;
}
i pisać szybko:
Vehicle v .... ;
...
v.repair().start();
Korzystaliśmy często z tej właściwości, używając klas narzędziowych Javy. Np. jednolinijkowy kod wczytujący cały plik tekstowy:
String content = new Scanner(new File("plik")).useDelimiter("\\Z").next();
działa dlatego, że metoda useDelimiter(...) wywołana na rzecz skanera zwraca this.
3. Trzeci przypadek użycia słowa this - to wywołanie z konstruktora innego konstruktora (o czym mowa była przed chwilą).
6. Ponowne wykorzystanie klas: kompozycja i dziedziczenie
Podejście obiektowe umożliwia ponowne wykorzystanie (ang. reusing) już gotowych klas przy
tworzeniu klas nowych, co znacznie oszczędza pracę przy kodowaniu, a także czyni programowanie mniej podatne na błędy.
Istnieją dwa sposoby ponownego wykorzystania klas:
- kompozycja,
- dziedziczenie.
Rozważmy najpierw kompozycję.
6.1. Kompozycja
Z koncepcyjnego punktu widzenia
kompozycja oznacza, że "obiekt jest
zawarty w innym obiekcie" . Jest to relacja "całość – część" ( B "zawiera"
A). Np. obiekty typu Lampa zawierają obiekty typu Żarówka.
Kompozycję uzyskujemy w prosty sposób - poprzez definiowanie pól obiektowych w klasie.
Na przykład, klasa RegisteredUser (użytkownik np. jakiejś listy dyskusyjnej
lub serwisu WEB - dla uproszczenia pomijamy tu kwestie hasła i identyfikatora
użytkownika) może określać informacje o osobie (obiekt klasy Person),
jej adresie (obiekt klasy Address) i mailu (String).
Ilustracyjne definicje klas Person i Address przedstawiono poniżej:
public class Person {
private String firstName;
private String lastName;
public Person (String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public String toString() {
return firstName + " " + lastName;
}
}
import java.util.*;
public class Address {
private String country;
private String city;
private String street;
public Address (String country, String city, String address) {
this.country = country;
this.city = city;
this.street = address;
}
public String getCountry() {
return country;
}
public String getCity() {
return city;
}
public String getStreet() {
return street;
}
public String getCurrentTimeThere() {
TimeZone tz = TimeZonesMap.getTimeZone(country, city);
if (tz == null) return "Uknown time";
// pobieramy kalendarz dla danej strefy czasowej
// i formatujemy datę
Calendar cal = Calendar.getInstance(tz);
return String.format("%tF %<tT", cal);
}
public String toString() {
return country+ ", " + city+ ", " + street;
}
}
Oprócz oczywistych metod, w klasie Address zdefiniowano metodę pobierania bieżącego czasu (getCurrentTimeThere())
z uwzględnieniem strefy czasowej. Referencje do obiektów klasy TimeZone (z pakietu java.util) odpowiadających
danemu krajowi i miastu są pobierane z "bazy danych" stref czasowych, dostarczanej
przez zewnętrzną klasę TimeZonesMap, która może wyglądac tak:
import java.util.*;
public class TimeZonesMap {
private static HashMap<String, TimeZone> map = new HashMap<String, TimeZone>();
static {
add("POLAND/WARSAW", "Europe/Warsaw");
add("INDONESIA/JAKARTA", "Asia/Jakarta");
add("CUBA/HAVANA", "America/Havana");
//.. jakieś inne
}
private static void add(String cc, String tzo) {
map.put(cc, TimeZone.getTimeZone(tzo));
}
public static TimeZone getTimeZone(String country, String city) {
return map.get(country.toUpperCase() + "/" + city.toUpperCase());
}
}Uwaga:
taka mapa jest nam potrzebna, bowiem symbole na oznaczenie stref
czasowych są ustalone i zawierają teksty w postaci kontynent/miasto lub
- dla niektorych krajów - kraj. Nasz adres nie ma kontynentu, może mieć
kraj, który na liście dostępnych symboli nie występuje itp.
Elementy mogą być dodawane do mapy np. przy połaczeniach klientów
z serwerem (wykorzystanie skryptów działających po stronie klienta) lub
pobierane z jakichś serwisów geograficznych itp.
Nie tylko samo użycie obiektów klas Address i Person w klasie RegisteredUser
stanowi o ich ponownym wykorzystaniu. Może ono również znaleźć zastosowanie
przy dostarczaniu takich metod klasy RegisteredUser, które upraszczają uzyskiwanie
informacji o zarejestrowanym użytkowniku.
Istotnie, aby uzyskać imię użytkownika usr musimy teraz napisać:
usr.getPerson().getFirstName();
"Skrót", który można dostarczyć polega na zdefiniowaniu w klasie RegisteredUser metody getFirstName():
public String getFirstName() {
return person.getFirstName();
}
Taki rodzaj definicji nazywa się delegowaniem wywołań metod.
Teraz możemy pisać prościej: usr.getFirstName();
To ponowne wykorzystanie klasy Person nie jest zbyt imponujące.
Idzie jednak o zasadę: kompozycja w praktyce umożliwia naprawdę ponowne wykorzystanie klas bez znacznych nakładów na kodowanie.
W naszym ilustracyjnym przykładzie zarejestrowanego użytkownika taką bardziej
praktycznie widoczną rolę spelnia ponowne wykorzystanie klasy Address.
Wyobraźmy sobie oto, że - jako dostarczyciele jakiegoś serwisu - chcemy
mieć informację o tym, która godzina jest teraz u "naszego użytkownika".
Gdyby nie było klasy Address, w której zdefiniowano metodę getCurrentTimeThere(),
musielibyśmy w klasie RegisteredUser nie tylko definiować dodatkowe pola
(kraj, miasto, adres) i związane z nimi metody (co może nie jest zbyt uciążliwe),
ale - również - musielibyśmy dostarczyć definicji metody ustalającej aktualną
datę i czas użytkownika (co już jest bardziej obciążające).
Tymczasem klasa Address ma już taką metodę (i - teoretycznie - słusznie:
bo strefa czasowa jest immanentną cechą miejsca), zatem ponowne wykorzystanie
tej klasy daje nam spore korzyści. Zamiast pisać "od nowa", zamiast zastanawiać
się nad subtelnościami kalendarza Javy oraz traktowania stref czasowych -
korzystamy z tego co już gotowe. Np. dostarczając w klasie RegisteredUser metody delegującej odwołanie do metody getCurrentTimeThere() z klasy Address:
public class RegisteredUser {
private Person person;
private Address address;
private String email;
// ...
public String getCurrentTimeThere() {
return address.getCurrentTimeThere();
}
// ...
}
Zastosowanie pokazanych klas ilustruje program testowy.
public class TestRegUser {
public static void main(String[] args) {
RegisteredUser usr = new RegisteredUser(
new Person("Kuba", "Kowalski"),
new Address("Cuba", "Havana", "Malecon 333"),
"kuba@Cuba"
);
System.out.printf("Czas serwera (tutaj) : %tF %<tT", Calendar.getInstance());
System.out.println("\nUżytkownik: " + usr);
System.out.println(usr.getFirstName() + " ma teraz czas: " + usr.getCurrentTimeThere());
}
}który daje następujące wyniki:
Czas serwera (tutaj) : 2008-08-06 02:34:37
Użytkownik: Kuba Kowalski ; Cuba, Havana, Malecon 333 ; kuba@Cuba
Kuba ma teraz czas: 2008-08-05 20:34:38
W
różnych środowiskach uruchomieniowych delegowanie odwołań przy
kompozycji jest łatwe, bowiem zapewniona jest automatyczna generacja
kodu na podstawie naszych wyborów.
Przykład tego w środowisku Eclipse pokazuje prezentacja multimedialna:
zobacz prezentację delegowania wywołań metod w Eclipse.
6.2. Dziedziczenie
O pojęciu dziedziczenia była już mowa (zob. wprowadzenie w wykładzie "Klasy i obiekty II"). Przypomnijmy:
Dziedziczenie polega na przejęciu właściwości i funkcjonalności
obiektów innej klasy i ewentualnej modyfikacji tych właściwości i funkjconalności w taki sposób, by były one bardziej
wyspecjalizowane.
Jest to relacja, nazywana generalizacją-specjalizacją: B "jest typu" A,
"B jest A", a jednocześnie B specjalizuje A. A jest generalizacją B.
Dziedziczenie - podobnie jak kompozycja (a nawet w większym stopniu) - pozwala na zmniejszanie nakładów na kodowanie (reusing).
Jest to również odzwierciedlenie naturalnych sytuacji. Oba te aspekty
były wyraźnie widoczne na przykładzie dziedziczenia klasy
Publication przez klasy Book, Journal itp. omawianym w wykładzie "Klasy
i obiekty II".
Jako prosty, przypominający te obserwacje,
przykład rozważmy klasę AppartmentAddress. Adresy apartamentów są
szczególnym przypadkiem adresów w ogóle, naturalne jest więc
dziedziczenie klasy Address. Klasa Address jest nadklasą, klasą bazową
klasy AppartmentAddress, a ta ostatnia jest podklasą, klasą pochodną
klasy Address.
public class AppartmentAddress extends Address {
// ...
}Apartamenty
mają tę szczególną właściwość, że są ulokowane na piętrach i
ponumerowane - stąd w nowej klasie pola dla numerów piętra i mieszkania
oraz nowe metody zwracające tę informację. Naturalnie, adresy
apartamentów mają też te same właściwości co adresy w ogóle (np.
atrybuty: kraj, miasto, ulica). Te pola są dziedziczone z klasy Address
i oczywiście nie musimy ich definiować. Konstruktor klasy
AppartmentAddress winien zainicjować wszystkie pola nowopowstającego
obiektu - i te z własnej klasy i te z klasy Address. Jednak te ostatnie
są prywatne i nie mamy do nich dostępu. Dlatego użyjemy konstrukcji
super(...), która oznacza wywołanie konstruktora klasy bazowej i musi
występować w pierwszym wierszu konstruktora podklasy (jeśli nie
występuje, to będzie wywołany konstruktor bezparametrowy klasy bazowej).
To wszystko - adresy apartamentów są gotowe:
public class AppartmentAddress extends Address {
private int floor;
private int appNr;
public AppartmentAddress(String country, String city, String street,
int floor, int appNr) {
super(country, city, street);
this.floor = floor;
this.appNr = appNr;
}
public int getFloor() {
return floor;
}
public int getAppNr() {
return appNr;
}
}Oszczędziliśmy
znacząco na kodowaniu. Kod klasy Address (a w szczególności nieco bardziej skomplikowana metoda
getTimeThere()) może być bezpośrednio ponownie użyty w aplikacji dla
obiektów klasy AppartmentAddress.
Obiekty te są typu AppartmentAddress, ale również typu Address, zatem możemy na ich rzecz wywoływać gotowe metody klasy Address:
public class AppartmentAddressTest {
public static void main(String[] args) {
AppartmentAddress adr = new AppartmentAddress("Thailand", "Bangkok", "Rama V", 29, 3111);
System.out.println(adr);
System.out.println("floor: " + adr.getFloor() + " apt: " + adr.getAppNr());
String time = adr.getCurrentTimeThere(); // korzystamy ze "skomplikowanej" metody klasy Address
System.out.println(time);
}
}
Wynik:
Thailand, Bangkok, Rama V
floor: 29 apt: 3111
2008-08-16 06:02:42
Przy budowaniu obiektów klas pochodnych podstawową regułą jest, iż najpierw muszą być zainicjowane pola klasy bazowej, a dopiero później klasy pochodnej.
Sekwencja wykonania kodu konstruktorów jest następująca:
- Wywoływany jest konstruktor klasy pochodnej.
- Jeśli pierwszą instrukcją jest super(args) wykonywany jest konstruktor klasy bazowej z argumentami args.
- Jeśli nie ma super(...) wykonywany jest konstruktor bezparametrowy klasy bazowej.
- Wykonywane są instrukcje wywołanego konstruktora klasy pochodnej.
Przykład.
class s { // ułatwienie dla wypisywania
static void ay(String s) { System.out.println(s); } }
class A {
A() { s.ay("Konstruktor bezparametrowy klasy A"); }
A(String t) {
s.ay("Konstruktor klasy A z parametrem String = " + t);
}
}
class B extends A {
B() { s.ay("Konstruktor bezparametrowy klasy B"); }
B(int i) { s.ay("Konstruktor klasy B z parametrem int = " + i); }
B(String t) {
super(t);
s.ay("Konstruktor klasy B z parametrem String = " + t);
}
}
class C extends B {
}
class Test {
public static void main(String[] arg) {
s.ay("Tworzenie obiektu B - B():");
new B();
s.ay("Tworzenie obiektu B - B(int)");
new B(1);
s.ay("Tworzenie obiektu B - B(String)");
new B("Ala");
s.ay("Tworzenie obiektu C:");
new C();
}
}
Wynik działania programu:
Tworzenie obiektu B - B():
Konstruktor bezparametrowy klasy A
Konstruktor bezparametrowy klasy B
Tworzenie obiektu B - B(int)
Konstruktor bezparametrowy klasy A
Konstruktor klasy B z parametrem int = 1
Tworzenie obiektu B - B(String)
Konstruktor klasy A z parametrem String = Ala
Konstruktor klasy B z parametrem String = Ala
Tworzenie obiektu C:
Konstruktor bezparametrowy klasy A
Konstruktor bezparametrowy klasy B
Gdybyśmy w klasie A nie dostarczyli konstruktora bezparametrowego ( a
nie jest on automatycznie dodawany, gdy zdefiniowano jakikolwiek
konstruktor), wystąpiłyby błędy w kompilacji.
Test.java:12: cannot resolve symbol
symbol : constructor A ()
location: class A
B() { s.ay("Konstruktor bezparametrowy klasy B"); }
^
Test.java:13: cannot resolve symbol
symbol : constructor A ()
location: class A
B(int i) { s.ay("Konstruktor klasy B z parametrem int = " + i); }
Przewidując,
że tworzona przez nas klasa może być kiedyś dziedziczona, warto
zatem rozważyć,
czy nie istnieje naturalny, domyślny sposób inicjacji jej obiektów i
dostarczyć
ew. konstruktora bezparametrowego, który taką domyślną inicjację
wykonuje. Inne powody skłaniające do umieszczania w klasach
konstruktorów bezparametrowych
związane są z wymaganiami różnych protokołów (czyli pewnych reguł
komunikowania
się z obiektami lub uzyskiwania informacji o nich - np. JavaBeans).
Rozwiązując problem adresów apartamentów można było zastosować również kompozycję:
public class AppartmentAddress {
private Address adres;
// ...
} ale
kod byłby nieco większy, bowiem zamiast bezpośredniej możliwości
ponownego użycia metod klasy Address musielibyśmy zastosowac
delegowanie odwołań np.
public class AppartmentAddress {
private Address adres;
// ...
public String getCurrentTimeThere() {
return adres.getCurrentTimeThere();
}
// ...
} Nie
oznacza to jednak, że kompozycja jest czymś gorszym od dziedziczenia.
Zalety dziedziczenia mogą się bowiem czasem okazać wadami: istnieje np.
możliwość rozhermetyzowania klasy bazowej przez przedefiniowanie jej
funkcjonalności w klasie pochodnej (zob. następny punkt o
przedefiniowaniu metod). Z tego względu niektóre ważne klasy (takie jak
np. String) są deklarowane ze specyfikatorem final, co oznacza
zabronienie ich dziedziczenia.
Specyfikator final użyty w definicji klasy zabrania jej dziedziczenia.
Np. klasa String jest definiowana jako:
public final class String {
// ...
}
Innym
problemem, związanym z dziedziczeniem jest tzw. kruchość interfejsu
klasy bazowej, polegająca na tym, że zmiany interfejsu klasy bazowej
mogą spwodować konieczność modyfikacji kodu wielu klas w hierarachii
dziedziczenia.
Dla przykładu, jeśli w klasie Address zmienimy typ
wyniku metody getCurrentTimeThere() na Calendar, to klasa
AppartmentAddresTest przestanie działać i będzie wymagała modyfikacji i
ponownej rekompilacji (a przecież jej kod nie odwołuje się bezpośrednio
do klasy Address i nic nie wie o jej istnieniu).
Dziedziczenie trzeba zatem stosować umiejętnie i z pewnym umiarem.
Odpowiednio użyte daje duże możliwości ponownego użycia klas.
Na marginesoie warto zauważyć, że stosując kompozycję w Javie nie jesteśmy
całkowicie pozbawieni zalet polimorfizmu. Polimorfizm jest jednak tutaj nie
tak bardzo bezpośredni jak przy dziedziczeniu - wymaga bowiem umiejętnego
stosowania interfejsów o czym w następnym wykładzie.
Przede wszystkim
jednak dziedziczenie umożliwia (w bardzo naturalny i intuicyjny sposób) posługiwanie
się ważną koncepcją programowania obiektowego, jaką jest polimorfizm, o czym już za chwilę.
Przypomnijmy na koniec, że hierarchia dziedziczenia w Javie charakteryzuje się ważnymi własciwościami:
- wszystkie klasy pochodzą pośrednio lub bezpośrednio od klasy Object,
- klasa może bezposrednio odziedziczyć tylko jedną klasę.
7. Przedefiniowanie metod
7.1. Pojęcie przedefiniowania metod
Rozważmy teraz inny przykład dziedziczenia, oparty na wprowadzonej w poprzednim
rozdziale definicji klasy Vehicle (pojazdy). Niech naszym zadaniem będzie
stworzenie klasy samochodów.
Samochody są specjalnym rodzajem pojazdów, zatem obiekty klasy samochodów przejmują wszystkie właściwości obiektów klas
pojazdów, dodatkowo dostarczając jakichś własnych specyficznych cech.
Projektując klasę samochodów (klasę Car) możemy skorzystać z gotowej klasy
Vehicle (nie musimy na nowo pisać metod, definiować pól etc). Skupiamy się
na specyficznych cechach samochodów, ich cechy jako pojazdów "w ogóle" przejmując
z klasy Vehicle.
Przyjmijmy, że wyróżniającymi cechą samochodów są:
- numer rejestracyjny
- użycie paliwa (przy braku paliwa samochód nie może ruszyć)
i
- dodajmy odpowiednie pola do klasy Car oraz odpowiedni konstruktor,
- dodajmy metodę fill() pozwalającą tankować paliwo,
- przedefiniujmy metodę start(), tak, by bez paliwa samochód nie mógł ruszyć
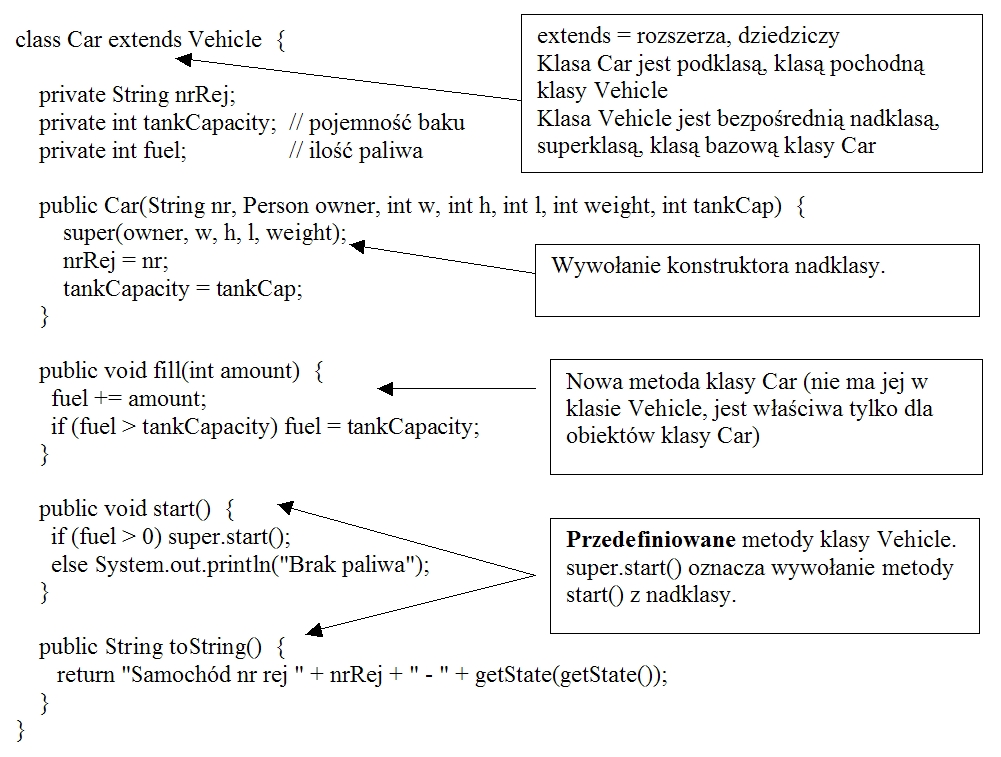
Przedefiniowanie metody (ang. overriding)
nadklasy w klasie pochodnej oznacza dostarczenie w klasie pochodnej definicji
nieprywatnej i niestatycznej metody z taką samą sygnaturą
(czyli nazwą i listą parametrów) jak sygnatura nieprywatnej i niestatycznej metody nadklasy,
ale z ew. inną definicją ciala metody (innym kodem, który jest wykonywany przy
wywołaniu metody), przy czym:
- typy
wyników tych metod muszą być takie same lub kowariantne (co oznacza
m.in., że typ wyniku metody z podklasy może być podtypem wyniku metody
nadklasy),
- przedefiniowanie nie może ograniczać dostępu:
specyfikator dostępu metody przedefiniowanej w podklasie musi być taki
sam lub szerszy (np. public zamiast protected) niż metody
przedefiniowywanej,
- metoda przedefiniowana (z podklasy) nie
może zgłaszać więcej lub bardziej ogólnych wyjątków kontrolowanych niż
metoda przedefiniowywana (z nadklasy).
W klasie Car przedefiniowano metody start() i toString() z klasy Vehicle.
Zwróćmy uwagę, że w metodzie start() klasy Car uruchamiamy samochód, gdy
bak nie jest pusty. Nie mogliśmy jednak napisać w metodzie start() klasy
Car:
if (fuel > 0) start();
oznaczałoby to bowiem rekurencyjne wywołanie metody start() klasy Car.
Ogólnie uruchamianiem wszelkich pojazdów zajmuje się metoda start() z klasy Vehicle i to ją właśnie chcemy wywołać.
Odwołanie do metody klasy bazowej, która w klasie pochodnej jest przedefiniowana, zapisujemy za pomocą specyfikatora super np.
super.start() użyte w klasie Car wywoła metodę start() z klasy Vehicle
(gdy tymczasem samo start() wywoła metodę start() z klasy Car).
Obiekt klasy Car składa się z elementów zdefiniowanych przez pola klasy Vehicle
oraz elementów zdefiniowanych przez pola klasy Car.
Wobec obiektów klasy Car możemy używać:
- wszystkich nieprywatnych (i nieprzedefiniowanych) metod klasy Vehicle,
- przedefiniowanych w klasie Car metod klasy Vehicle,,
- własnych metod klasy Car.
Pokazuje to poniższy program:
class Cars21 {
static void say(Car c) { System.out.println(c.toString()); }
public static void main(String[] args) {
Car c = new Car("WA1090",
new Person("Janek", "0909090"),
100, 100, 100, 100, 50),
d = new Car("WB7777", new Person("Zbyszek", "0909090"),
100, 100, 100, 100, 50);
c.start();
say(c);
c.fill(30);
c.start();
say(c);
d.fill(40);
d.start();
say(d);
c.stop();
say(c);
d.crash(c);
say(c);
say(d);
}
}
który wyprowadzi:
Brak paliwa
Samochód nr rej WA1090 - STOI
Samochód nr rej WA1090 - JEDZIE
Samochód nr rej WB7777 - JEDZIE
Samochód nr rej WA1090 - STOI
Samochód nr rej WA1090 - ZEPSUTY
Samochód nr rej WB7777 - ZEPSUTY
Przedefiniowując metody w podklasach warto używać adnotacji
@Override. Daje ona sygnał kompilatorowi, że intencją programisty jest
przedefiniowanie metody. Na przykład, programista chce przedefiniować
metodę getPreferredSize() z klasy Component w jakiejś jej podklasie,
ale pomylił się w pisowni i zapisał metodę getPrefferedSize().
Nie ma błędu - to jest po prostu całkiem nowa metoda. Metoda
getPreferredSize() używana jest przy wyznaczaniu preferowanych
rozmiarów komponentu - programista chicał przedefiniować jej działanie z nadklasy. Program się skompiluje i będzie
działał, ale kod metody napisanej przez programistę nie będzie
wykonywany i trudno będzie dociec błędu. Jeśli użyjemy adnotacji
@Overriide kompilator wykryje błąd i poinformuje o nim.
Przy przedefiniowaniu metod używajmy adnotacji @Override
np.
class MKomp extends JComponent {
@Override
public Dimension getPreferredSize() {
// ...
}
}
Istotą
przedefiniowania jest modyfikacja, uszczegółowienie funkcjonalności.
Jest to wielka zaleta, bez tego programowanie obiektowe nie byłoby
możliwe. Ale równocześnie otwiera pole dla wspomnianej wcześniej
możliwej słabej hermetyzacji klasy bazowej. W klasie Vehicle nie ma
metody sing(), więc pojazdy nie śpiewają? Ależ niektóre mogą śpiewać:
wystarczy odpowiednio przedefiniować metodą start() w podklasie!
Aby
uniknąć możliwości popełniania podobnych błędów w przypadkach, gdy
zmiany funkcjonalności fragmentów kodu nie są potrzebne, czy też są nawet niebezpieczne, w deklaracji
metod stosuje się słowo kluczowe final.
Słowo kluczowe final, użyte w deklaracji metody zabrania jej przedefiniowania.
7.2. Przedefiniowanie i klauzula throws
Jak wczesniej wspomniano, przedefiniowanie metody nie może poszerzać zakresu wyjatków kontrolowanych wymienionych
w klauzuli throws (przypomnijmy, że wyjątki kontrolowane, to te których
klasy są pochodne od klasy Exception, ale nie RuntimeException).
Oznacza to, że:
- jeżeli
metoda z klasy bazowej nie ma klauzuli throws, to metoda
przedefiniowująca ją w klasie pochodnej nie może wymienić w swojej
klauzuli throws żadnych wyjątków kontrolowanych,
- jeżeli metoda
z klasy bazowej wymienia w swojej klauzuli throws jakieś wyjatki
kontrolowane, to metoda przedefiniowująca ją w klasie
pochodnej nie może wymienić żadnej nadklasy tych wyjątków ani żadnych
dodatkowych innych klas wyjątków kontrolowanych, może natomiast
wymienić dowolne wyjątki pochodzące z podklas wyjątków, zgłaszanych
przez metodę z klasy bazowej,
- niezależnie od metody z
klasy bazowej metoda przedefiniowana w klasie pochodnej może nie
zgłaszać żadnych wyjatków i nie mieć klauzuli throws,
- metoda
przedefiniowana w klasie pochodnej zawsze może zgłaszać wyjatki
niekontrolowane i ew. wymieniać je w swojej klauzuli throws (co nie
jest obowiązkowe).
Ilustruje to przykładowy kod, w którym:
- wyjątek IOException jest pochodny od Exception,
- wyjątek FileNotFoundException jest pochodny od IOException,
- wyjątek NumberFormatException jest pochodny od RuntimeException.
class A {
void met1() {}
void met2() throws FileNotFoundException {}
void met3() throws IOException {}
void met4() throws Exception {}
void met5() {}
}
class B extends A {
void met1() throws Exception {} // błąd: ilustruje pkt. 1
void met2() throws IOExcepetion {} // błąd: ilustruje pkt. 2
void met3() throws FileNotFoundException, IOException {} // ok, ilustruje pkt 2
void met4() {} // ok, ilustruje pkt 3
void met5() throws NumberFormatException { } // ok, ilustruje pkt 4
}
7.3. Przedefiniowanie a przesłanianie i pokrywanie
Przedefiniowanie metod (overriding) należy odróżniać od przeciążania metod (overloading), a także od dwóch innych pojęć: przesłaniania (shadowing) i pokrywania (hiding) identyfikatorów (zmiennych, metod, klas).
Niewątpliwie najłatwiej odróżnić metody przeciążone. Mają po prostu te same
nazwy, ale inną liczbę i/lub typy parametrów. Zwróćmy uwagę, że:
- po pierwsze, przeciążone metody mogą należeć do tej samej lub różnych
klas (z których jedna pośrednio lub bezpośrednio dziedziczy inną),
- po drugie przeciążanie nie wyklucza przedefiniowania: jeśli np. w klasie
A zdefiniowano dwie publiczne metody z tą samą nazwą (co oznacza, że są one
przeciążone, bo sygnatury metod deklarowanych w jednej klasie muszą się różnić),
to w klasie B dziedziczącej klasę A możemy jedną z nich dodatkowo przeciążyć
(czyli podać w deklaracji inny zestaw parametów, a drugą przedefiniować -
pozostawiając jej sygnatirę bez zmian i dostarczając innej definicji kodu metody). W tym względzie Java różni się od C++.
Terminu przesłanianie (shadowing) używa się w Javie wtedy, gdy w zasięgu deklaracji
identyfikatora zmiennej, metody lub klasy (ogólniej: typu), pojawia się inna deklaracja
tego identyfikatora (widzieliśmy przykłady przesłaniania identyfikatorów pól przez identyfikatory zmiennych lokalnych).
W przeciwieństwie do przesłaniania, terminów przedefiniowanie (metody) i pokrycie (metody lub pola) używa się w sytuacji dziedziczenia.
Czym różni się pokrycie metody od jej przedefiniowania?
Otóż, dostarczenie w podklasie definicji metody statycznej o tej
samej sygnaturze i tym samym lub kowariantnym typem wyniku jak metoda statyczna z nadklasy nazywa się pokryciem metody.
Pokrywanie (hiding) nie dotyczy metod niestatycznych, co więcej jeśli w podklasie
dostarczymy definicji metody statycznej o tej samej sygnaturze jak metoda
niestatyczna nadklasy, to wystąpi błąd w kompilacji.
Rozróżnienie
pokrycia
i przedefiniowania metody związane jest też z pojęciem polimorfizmu
(zob. następne punkty): metody przedefiniowane są wywoływane
polimorficznie, pokrycie
zaś oznacza tylko zastąpienie wywołania metody pokrytej.
Pokrywanie może dotyczyć również pól: oznacza ono wtedy
deklarację
w podklasie pola o takim samym identyfikatorze jak pole z nadklasy.
Pokrycie
identyfikatorów pól różni się zarówno od pokrywania
identyfikatorów metod
jak i przedefiniowania metod. Pole statyczne może pokryć pole
niestatyczne i odwrotnie. Pole pokrywające pole nadklasy może mieć
całkiem inny typ niż pokryte pole nadklasy.
Metoda prywatna nigdy nie może być pokryta ani przedefiniowana w podklasie.
Deklaracja w podklasie metody o tej samej sygnaturze co metoda prywatna
nadklasy oznacza praktycznie wprowadzenie "niezależnego" bytu do naszego
programu (zatem możemy tu już mieć np. całkiem inny typ wyniku niż w metodzie prywatnej o tej samej sygnaturze z nadklasy).
Warto na koniec syntetycznie przedstawić znaczenie słowa kluczowego super.
Jego znaczenie wiąże się z pewnymi subtelnościami, jednak dla praktycznych celów wystarczające będzie poniższe podsumowanie.
Odwołania do przedefiniowanych metod
oraz pokrytych metod i pól nadklasy z poziomu metod podklasy realizowane są za pomocą konstrukcji:
super.odwołanie_do_składowej
czyli np.:
super.x // odwołanie do pola z nadklasy,
// które ma taki sam identyfikator
// jak pole w klasie
super.show() // wywołanie metody z nadklasy,
// która w danej klasie
// jest przedefiniowana lub pokryta
|
W konstruktorze
użycie wyrażenia:
super(argumenty)
oznacza wywołanie konstruktora klasy bazowej z argumentami "argumenty".
Jeśli występuje - MUSI być pierwszą instrukcją konstruktora klasy pochodnej.
Jeśli nie występuje - przed utworzeniem obiektu klasy pochodnej zostanie wywołany konstruktor bezparametrowy klasy bazowej.
|
7.4. Kowariantne typy wyników
W kontekście:
class A {
[static] R1 metoda() {
// ...
}
}
class B extends A {
[static] R2 metoda() {
// ...
}
}
typy wyników R1 i R2 są kowariantne, jeśli R2 jest podtypem R1.
W takim przypadku metoda metoda() z
klasy A bez specyfikatora static jest właściwie przedefiniowana w
klasie B, a ze specyfikatorem static - właściwie pokryta w klasie B.
Uwaga: pewne dodatkowe niuanse dotyczą typów sparametryzowanych.
Okazuje się więc, że metody przedefiniowane lub pokryte nie muszą mieć identycznych typów wyników (wystarczy kowariancja).
Dla przykładu zdefiniujemy klasę Liczba, która reprezentuje dowolne liczby,
public class Liczba {
private Number n;
public Liczba() {
}
public Liczba(Integer i) {
n = i;
}
public Liczba(Double d) {
n = d;
}
// ... inne konstruktory dla innych typów liczb
public Number getNumber() {
return n;
}
}Dziedzicząc
klasę Liczba, możemy teraz wprowadzić klasy dla konkretnych typów
liczb, w których metoda getNumber() będzie przedefiniowywana z
kowariantnymt typami wyniku. Na przykład:
public class Cala extends Liczba {
public Cala(int n) {
super(n);
}
public Integer getNumber() {
return super.getNumber().intValue();
}
}public class Rzecz extends Liczba {
public Rzecz(double n) {
super(n);
}
public Double getNumber() {
return super.getNumber().doubleValue();
}
}Metoda
getNumber() jest przedefiniowana i nie będzie błędu w kompilacji,
ponieważ klasy Integer i Double dziedziczą klasę Number.
Poprawność - poprawnością, a sens? Za chwilę zobaczymy, że takie zastosowanie kowariancji typów wyników może się przydać.
8. Rzutowanie typów referencyjnych
8.1. Konwersje referencyjne
Z koncepcją konwersji referencyjnych zapoznaliśmy się wstępnie w wykładzie "Klasy i obiekty II".
Przypomnijmy teraz istotę zagadnienia na przykładzie pojazdów "w ogóle" i samochodów - klas Vehicle i Car.
Klasa
Car dziedziczy klasę Vehicle. Samochody (obiekty klasy Car) mają
specyficzne cechy (paliwo) i klasa Car odpowiednio do tego definiuje
dodatkowe pola i dodatkową metodę fill(..). Ale oprócz tego samochody
są również "pojazdami w ogóle" (dziedziczenie klasy Vehicle) i wobec
tego mają wszelkie cechy i funkcjonalność pojazdów "w ogóle"
zdefiniowane w klasie Vehicle. Obiekt klasy Car jest typu Car, ale
również jest typu Vehicle.
Oznacza to, że dopuszczalne jest przypisania:
Car c = new Car(...);
Vehicle v = c;
Zachodzą tu automatycznie tzw. rozszerzające
konwersje referencyjne.
Jeżeli klasa B dziedziczy klasę A, to po:
B b = new B();
dopuszczalne jest przypisanie zmiennej b na zmienną typu A:
A a = b;
Przekazywanie
argumentów metodom i zwrot wyników z metod ma także charakter
przypisania, zatem dopuszczalne są takie konstrukcje:
void metoda1(A a) { ... }
// ...
metoda1(new B());
B metoda2() { return new B(); }
// ...
A a = metoda2()
A metoda3() { return new B(); }
Dzięki
referencyjnym konwersjom rozszerzającym możemy pisać uniwersalne
metody. Wyobraźmy sobie, że mamy różne klasy pochodne od Vehicle (Car,
Kayak itp.) i różne obiekty-pojazdy w programie. Dostarczymy
uniwersalnej metody info, która wypisuje pewne informacje o pojeździe
niezależnie od jego rodzaju:
public class Test1 {
static void info(Vehicle v) {
System.out.println("Pojazd nr. " + v.getNr() + " " + Vehicle.getState(v.getState()));
}
public static void main(String[] args) {
Car c = new Car("WA1090", new Person("Janek", "0909090"),
100, 100, 100, 100, 50);
Kayak k = new Kayak(new Person("Stefan", "0101010"),
70, 40, 200, 5);
info(c);
info(k);
}
}Wynik:
Pojazd nr. 1 STOI
Pojazd nr. 2 STOI
Pamiętamy,
że tablice mogą zawierać referencje do dowolnych obiektów. Możemy więc
napisać metodę, podającą informację o różnych pojazdach, "zawartych" w
tablicy.
public class Test2 {
static void info(Vehicle[] vehs) {
for (Vehicle v : vehs) {
System.out.println("Pojazd nr. " + v.getNr() + " " + Vehicle.getState(v.getState()));
}
}
public static void main(String[] args) {
Vehicle[] vehs = { new Car(), new Car(), new Kayak(), new Bicycle(), new Car() };
info(vehs);
}
}Wynik:
Pojazd nr. 1 STOI
Pojazd nr. 2 STOI
Pojazd nr. 3 STOI
Pojazd nr. 4 STOI
Pojazd nr. 5 STOI
lub
jeszcze lepiej - metodę ze zmienna liczbą argumentów typu Vehicle,
którą będzie można wywołać z argumentem - tablicą pojazdów lub dowolną
liczbą pojedyńczych pojazdów:
static void info(Vehicle ... vehs) {
for (Vehicle v : vehs) {
System.out.println("Pojazd nr. " + v.getNr() + " " + Vehicle.getState(v.getState()));
}
}
public static void main(String[] args) {
Vehicle[] vehs = { new Car(), new Car(), new Kayak(), new Bicycle(), new Car() };
info(vehs);
info( new Kayak(), new Car(), new Bicycle() );
info( new Car() );
}
Również
kolekcje mogą przechowywać referencje do dowolnych obiektów i operując
na nich możemy korzystać z dobrodziejstw referencyjnych konwersji
rozszerzających. Napiszmy program, który tworzy listę różnych
pojazdów, następnie - losowo - pojazdy się psują, po czym lista jest
przeglądana w serwisie i zepsute pojazdy są naprawiane.
Serwis reprezentuje następująca klasa.
public class Serwis {
private ArrayList<Vehicle> toServe;
public Serwis(ArrayList<Vehicle> toServe) {
this.toServe = toServe;
}
public void repairBroken() {
for (Vehicle v : toServe) {
if (v.getState() == Vehicle.BROKEN) v.repair();
}
}
}Uwagi:
- serwisowi
przekazywana jest referencja do listy wszystkich pojazdów (używamy tu
klasy ArrayList, bo tylko taki sposób dostępu do list dotąd
poznaliśmy),
- metoda
repairBroken przegląda tę listę i jeśli stan pojazdu jet BROKEN -
naprawia go (zmiana stanu na STOPPED), operujemy tu na referencjach do
pojazdów utworzonych w głównym programie i dodanych do listy.
Główny program - wykonujący symulację - wygląda następująco:
import java.util.*;
public class Test3 {
static void info(ArrayList<Vehicle> vehs) {
for (Vehicle v : vehs) {
System.out.println("Pojazd nr. " + v.getNr() + " " + Vehicle.getState(v.getState()));
}
}
static Random rand = new Random(); // generator
static Vehicle badLuck = new Vehicle(); // będziemy zderzać pojazdy z pechem
// Przekazany jako argument pojazd losowo zderza się z pechem (psuje)
// i jest dodawany do listy
static void breakRandomly(Vehicle v, ArrayList<Vehicle> list) {
boolean toBreak = rand.nextBoolean();
if (toBreak) {
badLuck.start(); // zaczyna się pech ...
v.crash(badLuck);
badLuck.repair(); // po zderzeniu "pech" się odnawia
} // (będzie gotowy do ponownego losowego startu)
list.add(v);
}
public static void main(String[] args) {
ArrayList<Vehicle> list = new ArrayList<Vehicle>();
breakRandomly(new Car(), list);
breakRandomly(new Kayak(), list);
breakRandomly(new Bicycle(), list);
breakRandomly(new Car(), list);
breakRandomly(new Kayak(), list);
info(list);
System.out.println("Go to service");
Serwis serv = new Serwis(list);
serv.repairBroken();
System.out.println("After service");
info(list);
}
}Najciekawsza
jest tu metoda breakRandomly. Musimy w niej losowo popsuć przekazany
pojazd. Losowość uzyskujemy przez wywołanie metody nextBoolean(), która
losowo zwraca wartości true albo false (popsuć nie popsuć). Klasa
Vehicle jest tak zdefiniowana, że popsucie pojazdu może nastąpić tylko
na skutek zderzenia z innym pojazdem (metoda crash(...)). Dlatego
wprowadzono fikcyjny pojazd badLuck (a to pech, mój pojazd się
zepsuł!). Pech trzeba ucruchomić (dwa stojące pojazdy nie mgą się
zderzyć) - dlatego wolamy badLuck.start(). Ponieważ w metodzie
crash(...) oba pojazdy biorące udział w
zderzeniu wychodzą z niego zepsute, to "pech" trzeba nareperować, aby
mógł być znowu uruchomiony i czychać na następny, pechowy w losowaniu
(czy
popsuć?) pojazd. Niektóre pojazdy zderzają się z pechem (psuja), inne
nie. Ale wszystkie są dodawane do listy pojazdów (przekazanej jako
drugi argument metody), która następnie jest przekazywana serwisowi do
przeglądu i naprawy zepsutych elementów.
Program wyprowadza następujący wynik (to które pojazdy będą zepsute zależy od losowań).
Pojazd nr. 2 STOI
Pojazd nr. 3 ZEPSUTY
Pojazd nr. 4 STOI
Pojazd nr. 5 ZEPSUTY
Pojazd nr. 6 ZEPSUTY
Go to service
After service
Pojazd nr. 2 STOI
Pojazd nr. 3 STOI
Pojazd nr. 4 STOI
Pojazd nr. 5 STOI
Pojazd nr. 6 STOI
Uwaga:
pokazane numery pojazdów zaczynają się od 2, bo nr 1 otrzymał
wcześniej utworzony pojazd-pech (zmienna badLuck).
Warto wyraźnie podkreślić, że po:
Car c = new Car();
Vehicle v = c;
zmienne c i v wskazują na ten sam obiekt - obiekt klasy Car.
Za
pomocą referencji c możemy na jego rzecz wywoływać wszystkie metody
klasy Vehicle i Car (i Object, bo Vehicle automatycznie dziedziczy
Object, mimo, że nie podaliśmy tego w extends - pamiętamy: każda klasa
jest - pośrednio lub bezpośrednio - pochodna od Object).
Natomiast
za pomocą referencji v możemy na jego rzecz wywoływać tylko
metody klasy Vehicle. Kompilator nie pozwoli nam na wywołanie metod
specyficznych dla klasy Car (statyczna zgodność typów). Np. nie będzie
można zawołać:
v.fill(100); // Błąd w kompilacji - w klasie Vehicle nie ma metody fill !
Ale przecież v wskazuje na obiekt klasy Car, zatem powinna być jakaś możliwość
wywołania metody fill(...). Na pomoc przychodzą zawężające konwersje referencyjne.
Jeśli klasa B dziedziczy klasę A, to po:
B b = new B();
A a = b;
możemy poinformować kompilator, że
a wskazuje na obiekt klasy B za pomocą jawnej referencyjnej konwersji zawężającej (używając operatora rzutowania):
B c = (B) a;
po czym wobec zmiennej
c będziemy mogli używać metod klasy B
Referencyjne konwersje zawężające:
- Wymagają jawnego użycia operatora rzutowania (nawiasów).
- Są bezpieczne: Java w trakcie wykonania programu wykryje błąd, polegający
na konwersji do niewłaściwego typu. W tym przypadku zgłoszony zostanie wyjątek ClassCastException.
Możemy więc pisać tak:
Car c = new Car();
Vehicle v = c;
// ...
((Car) v).fill(100);
albo np. wywołując metodę doFill(Vehicle) za pomocą
doFill(c);
w samej metodzie można, by napisać tak:
void doFill(Vehicle v) {
Car x = (Car) v;
x.fill(100);
}
lub - skrótowo - tak:
void doFill(Vehicle v) {
((Car) v).fill(100);
}
Gdyby
się okazało, że klasa Car nie dziedziczy klasy Vehicle, to powstałby
wyjątek ClassCastException. Powstałby on również wtedy, gdyby na
zmienną v (lub parametr v metody doFill) podstawić zmienną innej niż
Car klasy pochodnej od Vehicle (nie definiującej metody fill), np.
klasy Kayak.
Wobec tego powstaje ciekawe pytanie: w jaki sposób
napisać metodę repairBroken w klasie Serwis. tak aby przekazane na
liście pojazdy były reperowane, a dodatkowo wszystkim samochodom z
listy dolewano do baku 10 litrów paliwa (co najwyżej, o ile w baku jest
miejsce).
Zwykłe:
public void repairBroken() {
for (Vehicle v : toServe) {
if (v.getState() == Vehicle.BROKEN) v.repair();
((Car) v).fill(10);
}
}jest niedobre, bo gdy kolejny element z listy nie będzie typu Car, wystąpi wyjątek ClassCastException:
Pojazd nr. 2 STOI
Pojazd nr. 3 STOI
Pojazd nr. 4 ZEPSUTY
Pojazd nr. 5 ZEPSUTY
Pojazd nr. 6 STOI
Go to service
Exception in thread "main" java.lang.ClassCastException: casts.Kayak cannot be cast to casts.Car
at casts.Serwis.repairBroken(Serwis.java:17)
at casts.Test3.main(Test3.java:38)
Trzeba
zatem umieć sprawdzić czy referencja (kolejny element listy) jest
referencją do obiektu klasy Car i tylko w tym przypadku zastosować
konwersję zawężającą i wywołanie metody fill(..).
8.2. Stwierdzanie typu
Stwierdzeniu jakiego typu jest referencja służy m.in. operator instanceof.
Wyrażenie:
ref instanceof T
ma wartość true, jeśli referencja ref nie jest null i może być w fazie wykonania programu rzutowana do typu T bez zgłoszenia wyjątku ClassCastException.
Przy tym:
- wyrażenie null instanceof dowolny_typ zawsze ma wartość false,
- wyrażenie x instanceof T, będzie błędne składniowo (wystąpi błąd w kompilacji), jeśli typ referencji x i typ T nie są związane stosunkiem dziedziczenia,
- wyrażenie x instanceof T będzie miało wartość false, jeśli faktyczny typ referencji x jest nadtypem typu T,
- na razie terminy typ, podtyp i nadtyp kojarzyć możemy z pojęciami klasy, podklasy i nadklasy.
Pokazuje to poniższy program testowy:
class A {
}
class B extends A {
}
class C extends B {
}
class D extends A {
}
class E {
}
public class InstanceOf1 {
static void say(String msg, boolean is) {
System.out.println(msg + ": " + is );
}
public static void main(String[] args) {
A a = new A();
B b = new B();
C c = new C();
D d = new D();
E e = new E();
say("Czy a jest typu A ? ", a instanceof A);
say("Czy b jest typu A ? ", b instanceof A);
say("Czy c jest typu A ? ", c instanceof A);
say("Czy c jest typu B ? ", c instanceof B);
say("Czy a jest typu B ? ", a instanceof B);
say("Czy b jest typu C ? ", b instanceof C);
say("Czy null jest typu A", null instanceof A);
say("Czy d jest typu A?", d instanceof A);
// say("Czy d jest typu B?", d instanceof B); <- błąd w kompilacji
// say("Czy e jest typu A ? ", e instanceof A); <- błąd w kompilacji
}
}który po zakomentowaniu ostatnich dwóch wierszy (błędnych składniowo) da następujący wynik:
Czy a jest typu A ? : true
Czy b jest typu A ? : true
Czy c jest typu A ? : true
Czy c jest typu B ? : true
Czy a jest typu B ? : false
Czy b jest typu C ? : false
Czy null jest typu A: false
Czy d jest typu A?: true
Operator instanceof
ma zastosowanie przede wszystkim w sytuacji rzutowania typów. Wynik
jego zastosowania wyliczany jest w fazie wykonania programu i
dzięki temu możemy sprawdzić jakiego naprawdę typu jest referencja i
czy wobec tego możliwe jest dokonanie referencyjnej konwersji
zawężającej (o rozszerzające dba przecież kompilator).
Pokazuje to poniższy fragmencik:
class A {
}
class B extends A {
}
class C extends B {
}
public class InstanceOf1 {
static void say(String msg, boolean is) {
System.out.println(msg + ": " + is );
}
public static void main(String[] args) {
B b = new B();
C c = new C();
A a = b;
B b1 = c;
say("Czy a jest typu B ? ", a instanceof B);
say("Czy b1 jest typu C ? ", b1 instanceof C);
testTyp(b);
}
private static void testTyp(A a) {
say("Czy przekazany argument jest typu B ?", a instanceof B);
}
}który wyprowadzi:
Czy a jest typu B ? : true
Czy b1 jest typu C ? : true
Czy przekazany argument jest typu B ?: true
Mimo dość zawikłanej definicji i opisu, operator instanceof jest prosty w intuicyjnym, praktycznym stosowaniu.
Mamy
np. jakąś referencję v formalnego typu Vehicle. Na skutek ew.
wcześniejszych konwersji rozszerzających może ona oznaczać obiekt
klasy Car, a może obiekt klasy Kayak. Czy to jest Car? - zapytamy. Jeśli
tak to możemy mu wlać paliwo do baku:
Vehicle v;
// ....
if (v instanceof Car) {
Car c = (Car) v;
c.fill(10);
}
// ....
Mamy więc proste rozwiązanie postawionego wcześniej problemu: dolewania paliwa do baków samochodów w serwisie:
public void repairBroken() {
for (Vehicle v : toServe) {
if (v.getState() == Vehicle.BROKEN) v.repair();
if (v instanceof Car) ((Car) v).fill(10);
}
}
Innym sposobem stwierdzania typu jest zastosowanie metody getClass() z
klasy Object. Metoda ta zwraca faktyczny typ obiektu w postaci
referencji do obiektu klasy Class. Obiekty tej klasy
oznaczają klasy. Zatem, w kontekście:
Car c = new Car();
Vehicle v = c;
wywołanie v.getClass() zwróci referencję do obiektu klasy Class oznaczającego klasę Car.
Łatwo możemy się dowiedzieć o nazwę klasy:
Class klasa = v.getClass();
String nazwa = klasa.getName(); // będzie zwrócona pełna kwalifikowana nazwa klasy
i w ten sposób sprawdzić o jaką klasę chodzi.
Przy takim sprawdzaniu można też użyć tzw. literałów klasowych. Mają one postać:
kwalifikowana_nazwa_klasy.class
np.
java.lang.String.class // oznacza klasę String z pakietu java.lang
Para.class // oznacza klasę Para z pakietu domyślnego
casts.Car.class // klasa Car z pakietu casts
Zakładając, że klasa Car jest w pakiecie casts, poprzednią metodę można by więc napisac i tak:
public void repairBroken() {
for (Vehicle v : toServe) {
if (v.getState() == Vehicle.BROKEN) v.repair();
if (v.getClass() == casts.Car.class) ((Car) v).fill(10);
}
}Pomiędzy użyciem operatora instanceof i metody getClass() dla stwierdzania typów istnieje jednak zasadnicza różnica.
Użycie metody getClass() pozwala sprawdzić, czy referencja jest ściśle podanego typu (np. Car).
Użycie instanceof pozwala sprawdzić, czy referencja jest podanego typu lub dowolnego jego podtypu.
Stanie
się to bardziej zrozumiałe na przykładzie, w którym dodamy sobie do
poprzednich klasę klasę Truck dziedzicząca Car, a wszystkie klasy (i
Vehicle i Car też) umieścimy w pakiecie casts.
package casts;
class Truck extends Car {
public Truck() { }
// ...
}
public class InstDif {
static void reportType(Vehicle v) {
say("instanceof 1: v jest typu Vehicle? - ", v instanceof Vehicle);
say("instanceof 2: v jest typu Car? - ", v instanceof Car);
say("instanceof 3: v jest typu Truck? - ", v instanceof Truck);
say("getClass() 1: v jest typu Vehicle? - ", v.getClass() == casts.Vehicle.class);
say("getClass() 2: v jest typu Car? - ", v.getClass() == casts.Car.class);
say("getClass() 3: v jest typu Truck? - ", v.getClass() == casts.Truck.class);
}
public static void main(String[] args) {
Truck t = new Truck();
reportType(t);
}
static void say(String msg, boolean is) {
System.out.println(msg + ": " + is );
}Program wyprowadzi:
instanceof 1: v jest typu Vehicle? - : true
instanceof 2: v jest typu Car? - : true
instanceof 3: v jest typu Truck? - : true
getClass() 1: v jest typu Vehicle? - : false
getClass() 2: v jest typu Car? - : false
getClass() 3: v jest typu Truck? - : true
Przypominając sobie definicję metody boolean equals(Object)
(zob. "Klasy i obiekty II"). warto w tym kontekście zaznaczyć, że
nieprzypadkowo użyto tam metody getClass(), a nie operatora
instanceof:
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null) return false;
if (getClass() != obj.getClass()) return false;
// ... porównanie zawartośi obiektów
}
Generalnie
bowiem należy przyjąć restrykcyjny kontrakt metody equals: obiekty są
równe jeśli są ściśle tej samej klasy i mają taką samą treść.
Uzycie
instanceof (zamiast getClass) spowodowałoby, że za takie same mogłyby
zostać uznane obiekty klasy Vehicle i Car (gdy metoda jest w klasie
Vehicle, a jako argument przekazywany jest obiekt Car).