Przetwarzanie danych: liczby, daty, algorytmy
1. Opakowanie typów prostych i autoboxing
Bardzo często występuje potrzeba traktowania liczb jako obiektów.
Możemy np. zechcieć utworzyć tablicę, która zawiera i liczby i napisy. Wiemy, że można utworzyć tablicę dowolnych obiektów np.:
Object[] arr = new Object[3];
Ale liczby są reprezentowane przez typy proste (i nie są obiektami).
Zatem kompilator nie zgodzi się na wstawienie do niej elementu typu prostego np. taka konstrukcja będzie niedopuszczalna.
Object[] arr = { "ala", 3, "asia", 5 };
Również kolekcje mogą zawierać dowolne obiekty, ale nie uda nam się do "surowej" listy:
ArrayList list = new ArrayList();
czy też listy elementów typu Object:
ArrayList<Object> list = new ArrayList<Object>();
dodać elementy typów prostych.
Kolekcje mogą zawierać tylko referencje do obiektów.
Dlatego
w standardowym pakiecie java.lang umieszczono specjalne klasy, opakowujące typy proste i czyniące z nich obiekty.
Są to klasy:
- Integer
- Short
- Byte
- Long
- Float
- Double
- Boolean
Obiekty tych klas reprezentują (w sposób obiektowy) dane odpowiednich typów.
Mówimy
tu o opakowaniu liczby (czy też danej typu boolowskiego), bowiem liczba
(lub wartość true|false) jest umieszczone "w środku" obiektów
odpowiedniej klasy, jako jego element.
Klasy opakowujące nie dostarczają żadnych metod do wykonywania operacji na
liczbach. Operatory arytmetyczne zaś możemy stosować tylko wobec liczbowych typów prostych.
A przecież często potrzebujemy liczby jako obiektu, a jednocześnie jako typu prostego - do wykonania operacji arytmetycznych
Musimy
więc umieć zapakować liczbę do obiektu klasy opakowującej (po to by
użyć wtedy, gdy wymagany jest obiekt) i wyciągnąć ją stamtąd
(wtedy gdy potrzebne są obliczenia).
Pakować i rozpakowywać typy proste możemy "ręcznie".
Np. obiektowy odpowiednik liczby 5 typu int możemy uzyskać tworząc obiekt klasy Integer:
Integer a = new Integer(5);
Z obiektu takiej klasy możemy liczbę "wyciągnąć" za pomocą odpowiednich
metod, np.
int i = a.intValue(); // zwraca wartość typu int, "zawartą" w obiekcie a
Podobnie:
Double dd = new Double(7.1);
double d = dd.doubleValue(); // d == 7.1
Jest
to jednak nieco żmudne. Zobaczmy przykład wczytania liczb
całkowitych z pliku, posortowania ich i wypisania sumy pierwszej i
ostatniej liczby z posortowanej sekwencji.
import java.io.*;
import java.util.*;
public class Test1 {
public static void main(String[] args) throws FileNotFoundException {
ArrayList<Integer> list = new ArrayList<Integer>();
Scanner in = new Scanner(new File("liczby.txt"));
while (in.hasNextInt()) {
Integer n = new Integer(in.nextInt());
list.add(n);
}
Collections.sort(list);
int wynik = list.get(0).intValue() + list.get(list.size()-1).intValue();
System.out.println(wynik);
}
} Nieco za dużo tu pisania - new Integer albo intValue.
Dlatego w Javie wprowadzono mechanizm zwany autoboxingiem.
Autoboxing to automatyczne
przekształcanie pomiędzy typami prostymi a typami obiektów
klas, opakowujących typy proste.
Boxing
Automatyczne przekształcenie z typu prostego do obiektowego.
Typ prosty (i) -> typ
obiektowy
(r), tak, że : r.value() == i
boolean -> Boolean
byte -> Byte
char -> Character
short -> Short
int -> Integer
long -> Long
float -> Float
double -> Double
Unboxing
Automatyczne przekształcenie z typu obiektowego do prostego.
Typ obiektowy (r) -> typ prosty (i), tak, że
i ==
r.value()
Boolean ->
boolean
Byte
-> byte
Character -> char
Short
-> short
Integer -> int
Long
-> long
Float
-> float
Double ->
double
Kiedy zachodzą te automatyczne konwersje?
- przy przypisaniach,
- przy
przekazywaniu argumentów (metodom i
konstruktorom),
- przy zwrocie wyników.
Przykład.
Poniższy program:
public class AutoBoxing {
private int intField;
public AutoBoxing() {
// Konwersje przy przypisaniu
int x = 1;
Integer a = x;
int y = a;
System.out.println("Konwersje przy przypisaniu: " + a + " " + y);
// Konwersje przy wywołaniu metod
methodInvocationConversion1(x);
methodInvocationConversion2(a);
// Konwersje przy zwrocie wyników
y = getIntFromInteger();
a = getIntegerFromInt();
System.out.println("Konwersje przy zwrocie wyniku: " + a + " " + y);
}
public AutoBoxing(Integer i) {
intField = i;
System.out.println("W konstruktorze bezparametrowym: " + intField);
}
void methodInvocationConversion1(Integer p) {
System.out.println("Parametr Integer, argument int " + p);
}
void methodInvocationConversion2(int p) {
System.out.println("Parametr int, argument Integer " + p);
}
int getIntFromInteger() {
return new Integer(2);
}
Integer getIntegerFromInt() {
return 2;
}
public static void main(String[] args) {
new AutoBoxing();
// Zauważmy, że konstruktor możemy wołać z arg. int lub Integer
new AutoBoxing(3);
new AutoBoxing(new Integer(3));
}
}da
w wyniku:
Konwersje przy
przypisaniu: 1 1
Parametr Integer, argument int 1
Parametr int, argument Integer 1
Konwersje przy zwrocie wyniku: 2 2
W konstruktorze bezparametrowym: 3
W konstruktorze bezparametrowym: 3
Poprzedni programik sumowania pierwszej i ostatniej liczb posortowanej sekwencji możemy teraz napisać dużo prościej:
public class Test1 {
public static void main(String[] args) throws FileNotFoundException {
ArrayList<Integer> list = new ArrayList<Integer>();
Scanner in = new Scanner(new File("liczby.txt"));
while (in.hasNextInt())
list.add(in.nextInt());
Collections.sort(list);
int wynik = list.get(0) + list.get(list.size()-1);
System.out.println(wynik);
}
}
Warto
zauwazyć, że opakowanie typów prostych zachodzi również przy
przypisaniach (w tym przekazywaniu argumentów i zwrocie wyników) na
zmienne typu Object.
Np. przypisanie:
Object o = 1;
spowoduje stworzenie obiektu klasy Integer opakowującego liczbe 1 i przypisanie referencji do tego obiektu na zmienną o.
Jednak wypakowanie nie jest już automatyczne.
W kontekście:
Object o = 1;
przy próbie podstawienia na zmienną typu int:
int x = o;
wystąpi błąd w kompilacji.
Aby tego uniknąć musimy uzyć operatora rzutowania i to do typu Integer:
int x = (Integer) o;
Choć
głównego powodu istnienia klas opakowujących upatrywać można w
konieczności ich obiektowej reprezentacji, to - niejako przy okazji - w
klasach tych zdefiniowano wiele użytecznych metod.
Znamy już statyczne metody przekształcające napisową reprezentację liczb w ich wartości binarne:
public static ttt parseTtt(String s)
zwracające wartości typu ttt reprezentowane przez napis s
gdzie: ttt nazwa typu prostego (np. int, double), Ttt - ta sama nazwa z kapitalizowaną pierwszą literą (np. Int, Double)
Oprócz tego w klasach tych znaleźć można wiele metod do operowania
na bitach liczb, przekształcania pomiędzy różnymi systemami liczbowymi
oraz przekształcania wartości pomiędzy typami prostymi (np.
doubleValue() zwraca wartość jako double).
Użytecznych dodatkowych metod dostarcza klasa Character (opakowująca typ char).
Należą do nich metody stwierdzania rodzaju znaku np.:
isDigit() // czy znak jest znakiem cyfry
isLetter() // czy znak jest znakiem litery
isLetterOrDigit() // czy znak jest litera lub cyfra
isWhiteSpace() // czy to "biały" znak (spacja, tabulacja etc.)
isUpperCase() // czy to duża litera
isLowerCase() // czy to mała litera
Metody te zwracają wartości true lub false.
W klasach opakowujących typy numeryczne zdefiniowano także wiele użytecznych
statycznych stałych. Należą do nich stałe zawierające maksymalne i minimalne
wartości danego typu.
Mają one nazwy MAX_VALUE i MIN_VALUE.
Dzięki temu nie musimy pamiętać zakresu wartości danego typu.
Możemy np. zsumować wszystkie dodatnie liczby typu short:
public class MaxVal {
public static void main(String[] args) {
long sum = 0;
for (int i=1; i <= Short.MAX_VALUE; i++) sum +=i;
System.out.println(sum);
}
}
Uwaga:
w tym kodzie nie wolno nadać licznikowi (zmiennej i) typu short,
bo przy dojściu do wartości Short.MAX_VALUE (warunek pętli spełniony) w
kolejnej iteracji zmienna i uzyska wartość o 1 większą, a więc
przekraczająca dopuszczalny zakres. Nie spowoduje to wyjątku tylko
arytmetyczne przepełnienie - zmienna i uzyska wartość Short.MIN_VALUE.
W rezultacie pętla będzie działać w nieskończoność.
2. Operacje na bitach
Liczby calkowite (typów byte, short, int, long) są reprezentowane w pamięci
komputera w postaci binarnej jako ciągi bitów. Bit, który znajduje się w
takim zapisie najbardziej z lewej strony nazywa się bitem najstarszym (najbardziej znaczącym), a
ten najbardziej z prawej - najmłodszym (najmniej znaczącym).
Najstarszy bit jest tzw. bitem znaku - jesli jest ustawiony (ma wartość
1) to liczba jest ujemna, a jeśli nie (ma wartość 0) - to liczba jest dodatnia.
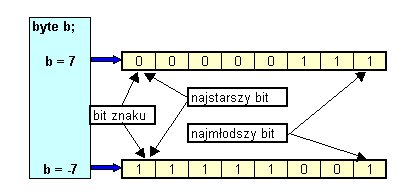
Jak pamiętamy z wykładu 1 - dziesiętną wartość liczby zapisaną w systemie
dwójkowym możemy uzyskać sumując kolejne iloczyny wartości bitów (1 lub 0)
i odpowiednich potęg 2. Uwzględnienie liczb ujemnych wymaga, by wartość
bitu znaku "brana była" z minusem. Dlatego na powyższym rysunku:
7 = -0*27 + 0*26 + 0*25 + 0*24 +0*23 + 1*22 + 1*21 + 1*20
-7 = -1*27 + 1*26 + 1*25 + 1*24 +1*23 + 0*22 + 0*21 + 1*20
Taki zapis liczb całkowitych nazywa się zapisem z uzupełnieniem do dwóch
Łatwo dostrzec, że z tego powodu wartość bezwzględna największej całkowitej liczby
ujemnej jest zawsze większa od wartości bezwględnej największej całkowitej liczby dodatniej.
W przypadku wartości typu byte najmniejsza możliwa wartość równa jest 100000000,
czyli -1*27 = - 128, natomiast największa możliwa licznba dodatnia równa jest 01111111 = 127.
Pamiętamy też, że wartości typu char (reprezentujące znaki) mogą być traktowane
jak liczby całkowite. W tym przypadku jednak najstarszy bit nie jest traktowany
jako bit znaku - zatem wartości typu char (zajmujące 2 bajty) mogą kształtować
się w przedziale od 0 do 65536.
Na bitach wartości wszystkich całkowitych typów numerycznych (w tym bitach wartości typu char) możemy wykonywać operacje.
Do operowania na bitach liczb całkowitych służą następujące operatory:
- jednoargumentowy operator uzupełnienia jedynkowego ~ ,
- dwuargumentowe operatory przesunięcia bitowego >> (w prawo) i
<< (w lewo) oraz operator przesunięcia bitowego w prawo bez propagacji
bitu znakowego (>>>),
- dwuragumentowy operator koniunkcji bitowej &,
- dwuargumentowy operator bitowej różnicy symetrycznej ^ (wykluczające ALBO),
- dwuargumentowy operator alternatywy bitowej | .
Każdy z argumentów wszystkich wymienionych operatorów bitowych musi być typu całkowitego.
Operatory przesunięcia bitowego powodują przesunięcie bitów swojego lewego
argumentu o liczbę pozycji specyfikowaną przez prawy argument w lewo (operator
<<), lub w prawo (operator >>). Przy przesuwaniu w lewo, młodsze
(zwalniane) bity zapełniane są zerami; przy przesunięciu w prawo zwalniane
bity zapełniane są wartością bitu znakowego (najstarszego). co nazywa się
propagację bitu znakowego. W przypadku użycia operatora >>> taka
propagacja nie występuje i niezaleznie od wartości bitu znaku zwalniane bity
są zapełniane zerami.
Rozpatrzmy przykłady:
byte b = 1; -> bitowa reprezentacja: 00000001 (1)
b << 1 -> 00000010 (2)
b << 4 -> 00010000 (16)
A zatem w przypadku, gdy a jest którąś z potęg dwójki, kolejne przesunięcie
w lewo mnoży wartość a przez 2. A co się stanie gdy będziemy chcieli przesunąć
w lewo bity największej z możliwych liczb danego typu?
Warto wiedzieć, że lewy argument operatora << (jeśli był typu byte,
short lub char) jest promowany do typu int i całe wyrażenie ma wartość typu
int (jesli argument był typu long - wartość wyrażenia jest typu long).
Zatem taki program:
public class Test {
public static void main(String[] args) {
byte b = Byte.MAX_VALUE;
System.out.println(b + " " + (b << 1));
System.out.println(b + " " + (byte) (b << 1));
int i = Integer.MAX_VALUE;
System.out.println(i + " " + (i << 1));
}
}
wyprowadzi:
127 254
127 -2
2147483647 -2
Pierwszy wynik jest faktycznie rezultatem mnożenia wartości b przez dwa tylko
dlatego, że nastąpiła promocja wartości b do typu int i typem wyniku wyrażenia
b << 1 jest int.
Trzeci wynik pokazuje, że przesunięcie bitów może doprowadzić do zmiany bitu
znaku z 0 na 1. W tym przypadku nie było miejsca na promocję (czyli faktycznie
zwiększenie liczby bitów zajmowanych przez liczbę) w konsekwencji bit znaku
stał się 1 i otrzymaliśmy liczbę ujemną.
Pośredni, drugi wynik uwidacznia dokładnie to samo. Dokonaliśmy tu konwersji
do typu byte, zatem rezultat jest taki jakbyśmy operowali na wartościach typu
byte (bez promocji):
127 = 01111111
a po przesunięciu bitów o jedno miejsce, otrzymujaemy:
11111110
co jest rowne dokładnie -2.
Zobaczmy jak dziala operator >> (przesunięcie bitów w prawo - z propagacja znaku)
byte b = 127; -> 01111111
b >> 1 -> 00111111 (63)
b >> 2 -> 00011111 (31)
b >> 3 -> 00001111 (15)
Operacja a >> n dla liczb całkowitych jest równoważna całkowitoliczbowemu
dzieleniu (dającemu w rezultacie całkowitą część rezultatu dzielenia) a/2n.
Dla liczb ujemnych wygląda to w następujący sposób:
byte b = -64; -> 11000000
b >> 1 -> 11100000 (-32)
b >> 2 -> 11110000 (-16)
b >> 3 -> 11111000 (-8)
c >> 4 -> 11111100 (-4)
(zwalniane bity są zapełniane wartością bitu znakowego tj. 1)
Zauważmy więc, że jeśli b = -1 (11111111), to przesunięcie bitów w prawo da wynik -1.
Logiczne operatory bitowe ( ~,^, &, |) służą do ustalania wartości
bitów rezultatu za pomocą wartości bitów argumentów. Operator uzupełnienia
jedynkowego ~ zamienia w swoim jedynym argumencie wszystkie zerowe bity na
1, a 1 na 0. Sposób w jaki określane są bity rezultatu pozostałych logicznych
operacji bitowych obrazuje poniższa tablica, w której a1 i a2 oznaczają argumenty
operatorów bitowych.
|
Wartość
bitu
w a1
|
Wart. odpo-
wiadajęcego
mu bitu w
a2
|
Wart. odpowiadającego bitu rezultatu
oper.
|
|
a1 & a2
|
a1 ^ a2
|
a1 | a2
|
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 0 | 1 |
Np. jeśli a1 = 5, a2 = 7, to logiczne operacje bitowe są
przeprowadzane w następujący sposób:
a1 & a2 = ...0101
& ...0111
---------
...0101
= 5 | a1 ^ a2 = ...0101
^ ...0111
---------
...0010
= 2 | a1 | a2 = ...0101
| ...0111
---------
...0111
= 7 |
Zwróćmy uwagę, że operacje te dotyczą tylko najmłodszych 3 bitów, niezależnie
od tego jakiego są typu i ile miejsca w pamięci zajmują argumenty a1 i a2.
Np. aby wyzerować najmłodszy bit całkowitej zmiennej x - niezależnie od jej typu możemy napisać:
x = x & ~0x1;
zerowe bity stałej 0x1 staną się 1, a jedyny bit o wartości 1 - zerem; w
rezultacie w x zerowany będzie najmłodszy bit - niezależnie od tego jakiego
typu jest i ile miejsca zajmuje x.
Operacje bitowe są właśnie najbardziej przydatne do ustawiania i testowania
wartości bitów. Często w programowaniu wykorzystuje się tzw. flagi - znaczniki,
których wartości określają np. charakterystyki jakiegoś zdarzenia, albo jaki
jest stan jakiegoś obiektu. Flagi mają zwykle charakter zero-jedynkowy -
szkoda więc byłoby na każdą z nich tracić 8 bitów, gdy wystarczy 1. Zestawy
flag zapisujemy więc zwykle jako bity wartości jakiejś zmiennej - typu byte (8 flag),
albo int (32 flagi), albo long (64 flagi). Za pomocą operatorów bitowych
możemy sprawdzać które z flag przechowywanych w tych zmiennych są ustawione
i modyfikować ich ustawienie.
Popatrzmy na następujący przykladowy program (wykorzystamy w nim statyczną
metodę getBits(wart) z klasy Unspec, która zwraca tablicę znaków
0 - 1, pokazujących bitową reprezentację przekazanej jako argument wartości;
klasę tę za chwilę zbudujemy i omówimy).
public class Flags {
public static void main(String[] args) {
final int FL1 = 0x01, // stałe pokazujące które bity (flagi) mają
FL2 = 0x02, // być testowane lub ustawiane
FL3 = 0x04,
FL4 = 0x08;
int flags = 0;
flags = flags | FL1; // ustawia flagę 1 (najmłodszy bit)
show("flags = flags | FL1",
flags);
flags = 0;
flags = flags | FL3; // ustawia flagę 3 (trzeci bit)
show("flags = flags | FL3",
flags);
flags = 0;
flags = flags | (FL1 | FL4); // ustawia 1 i 4 flagę
show("flags = flags | (FL1 | FL4)",
flags);
// czy flaga 1 ustawiona
if ((flags & FL1) > 0) System.out.println("Flaga 1 ustawiona");
else System.out.println("Flaga 1 NIE ustawiona");
// czy flaga 2 ustawiona
if ((flags & FL2) > 0) System.out.println("Flaga 2 ustawiona");
else System.out.println("Flaga 2 NIE ustawiona");
// czy flagi 1 i 4 ustawione (jednoczesnie)
int mask = FL1 | FL4;
if ((flags & mask) == mask) System.out.println("Flagi 1 i 4 ustawione");
else System.out.println("Flagi 1 i 4 NIE ustawione");
// czy flagi 1 i 2 ustawione (jednoczesnie)
mask = FL1 | FL2;
if ((flags & mask) == mask) System.out.println("Flagi 1 i 2 ustawione");
else System.out.println("Flagi 1 i 2 NIE ustawione");
}
static void show(String s, int flags) {
System.out.println(s);
char[] bits = Unspec.getBits(flags);
System.out.println(new String(bits) + " --- val: " + flags);
}
}
Program wyprowadzi następujące informacje:
flags = flags | FL1
00000000000000000000000000000001 --- val: 1
flags = flags | FL3
00000000000000000000000000000100 --- val: 4
flags = flags | (FL1 | FL4)
00000000000000000000000000001001 --- val: 9
Flaga 1 ustawiona
Flaga 2 NIE ustawiona
Flagi 1 i 4 ustawione
Flagi 1 i 2 NIE ustawione
Znając już działanie operatorów bitowych możemy pokusić się o stworzenie
klasy Unspec, ktra dostarczy następujących statycznych metod, zwracających
w tablicy bitowe reprezentacje wartości różnych typów:
public static char[] getBits(byte)
public static char[] getBits(char)
public static char[] getBits(int)
public static char[] getBits(long)
Możliwe rozwiązanie:
public class Unspec {
public static char[] getBits(byte v) {
return getBits(8, (long) v);
}
public static char[] getBits(char v) {
return getBits(16, (long) v);
}
public static char[] getBits(int v) {
return getBits(32, (long) v);
}
public static char[] getBits(long v) {
return getBits(64, v);
}
private static char[] getBits(int n, long v) {
char[] bits = new char[n];
long mask = 1;
for (int k = n-1; k >= 0; k--) {
if ((v & mask) != 0) bits[k] = '1';
else bits[k] = '0';
mask = mask << 1;
}
return bits;
}
}
oraz program testujący, w którym - jako argumenty wywolania podajemy kolejno
liczbę typu long, liczbę typu int, znak, liczbę typu byte:
class Test {
public static void main(String[] args) {
long l = Long.parseLong(args[0]);
int i = Integer.parseInt(args[1]);
char c = args[2].charAt(0);
byte b = Byte.parseByte(args[3]);
System.out.println("Wartość typu long " + l);
System.out.println(new String(getBits(l)));
l = Long.MAX_VALUE;
System.out.println("Maksymalna wartość typu long " + l);
System.out.println(new String(getBits(l)));
l = Long.MIN_VALUE;
System.out.println("Minimalna wartość typu long " + l);
System.out.println(new String(getBits(l)));
System.out.println("Wartość typu int " + i);
System.out.println(new String(getBits(i)));
System.out.println("Wartość typu char: znak " + "'" + c + "'" + ", kod " + (int) c);
System.out.println(new String(getBits(c)));
System.out.println("Wartość typu byte " + b);
System.out.println(new String(getBits(b)));
}
}
Program ten - przy podanych argumentach: 1 -1 a -7 - wyprowadzi:
Wartość typu long 1
0000000000000000000000000000000000000000000000000000000000000001
Maksymalna wartość typu long 9223372036854775807
0111111111111111111111111111111111111111111111111111111111111111
Minimalna wartość typu long -9223372036854775808
1000000000000000000000000000000000000000000000000000000000000000
Wartość typu int -1
11111111111111111111111111111111
Wartość typu char: znak 'a', kod 97
0000000001100001
Wartość typu byte -7
11111001
Warto zauważyć, że w klasach opakowujących numeryczne typy proste jest wiele gotowych metod do operowania na bitach np.
- toBinaryString(..) zwraca napis -bitową reprezentację liczby) ,
- rotateLeft(...) i rotateRight(...) - rotacja (w lewo,w prawo) o podaną liczbę bitów,
- bitCount(...) - zwraca liczbę bitów jedynkowych w bitowej reprezentacji liczby.
Przykładowy program pokazuje zastosowanie "bitowych metod" klasy Integer.
public class BitFun {
static void show(int x) {
System.out.println("Wartość: " + x);
String s = Integer.toBinaryString(x);
System.out.println("Bity: " + s);
System.out.println("Liczba jedynek: " + Integer.bitCount(x));
System.out.println("Liczba wiodących zer: " + Integer.numberOfLeadingZeros(x));
System.out.println("Liczba zer na końcu: " + Integer.numberOfTrailingZeros(x));
}
public static void main(String[] args) {
int x = 101;
show(x);
System.out.println("Po rotacji w lewo o 1 pozycję");
show(Integer.rotateLeft(x, 1));
System.out.println("Po rotacji w prawo o 1 pozycję");
show(Integer.rotateRight(x, 1));
System.out.println("Po odwróceniu bitów");
show(Integer.reverse(x));
System.out.println("Po odwróceniu bajtów");
show(Integer.reverseBytes(x));
}
}
Wynik:
Wartość: 101
Bity: 1100101
Liczba jedynek: 4
Liczba wiodących zer: 25
Liczba zer na końcu: 0
Po rotacji w lewo o 1 pozycję
Wartość: 202
Bity: 11001010
Liczba jedynek: 4
Liczba wiodących zer: 24
Liczba zer na końcu: 1
Po rotacji w prawo o 1 pozycję
Wartość: -2147483598
Bity: 10000000000000000000000000110010
Liczba jedynek: 4
Liczba wiodących zer: 0
Liczba zer na końcu: 1
Po odwróceniu bitów
Wartość: -1509949440
Bity: 10100110000000000000000000000000
Liczba jedynek: 4
Liczba wiodących zer: 0
Liczba zer na końcu: 25
Po odwróceniu bajtów
Wartość: 1694498816
Bity: 1100101000000000000000000000000
Liczba jedynek: 4
Liczba wiodących zer: 1
Liczba zer na końcu: 24
3. Działania matematyczne
Wiemy już dość dużo o operacjach arytmetycznych. Warto jednak zwrócić krótko uwagę na cztery kwestie:
- specjalne wartości dla liczb typu double,
- "bibliotekę" funkcji matematycznych,
- reprezentację i precyzję liczb rzeczywistych,
- możliwość posługiwania się dowolnie dużymi liczbami dziesiętnymi w dowolnej precyzju.
Jeżeli zdarzy się nam w programie podzielić liczbę całkowitą przez całkowite
zero, to powstanie wyjątek (sygnał o błedzie) ArithmeticException.
Całkiem inaczej jest w przypadku liczb rzeczywistych.
Dzielenie przez zero nie powoduje błędu, ale daje w wyniku specjalną wartość,
reprezentującą nieskończoność. Wartości +- nieskończoność są dostępne jako
statyczne stałe klasy Double: Double.POSITIVE_INFINITY i Double.NEGATIVE_INFINITY.
Dzięli temu łatwo możemy wykryć przypadek dzielenia przez zero.
Inną specjalną wartością typu rzeczywistego jest NaN ("Not-a-Number" - nie-liczba.
liczba nie zdefiniowana). Reprezentuje ona wyniki pewnych operacji arytmetycznych
(takich jak np. 0.0 / 0.0). W klasie Double zdefiniowano stałą statyczną
NaN. Ale nie powinna ona być wykorzystywana do sprawdzania czy wynik operacji
jest "Not-a-Number", bowiem wartości Nan mają ciekawą własciwość: NaN !=
Nan.
Do sprawdzania czy wartość jest Nan czy nie należy używac metody isNan z klasy Double.
Przykładowy program ilustruje wyżej powiedziane:
public class InfNan {
public static void main(String[] args) {
double d = 1.0 / 0.0;
System.out.println("d = " + d);
if (d == Double.POSITIVE_INFINITY)
System.out.println("to jest + nieskończoność");
d = -1.0 / 0.0;
System.out.println("d = " + d);
if (d == Double.NEGATIVE_INFINITY)
System.out.println("to jest - nieskończoność");
d = 0.0 / 0.0;
System.out.println("d = " + d);
if (d == Double.NaN)
System.out.println("to nie jest liczba");
else System.out.println("to jest liczba");
Double dd = new Double(d);
System.out.println("naprawdę: to nie jest liczba ? - " + dd.isNaN());
}
}
Wynik działania programu:
d = Infinity
to jest + nieskończoność
d = -Infinity
to jest - nieskończoność
d = NaN
to jest liczba
naprawdę: to nie jest liczba ? - true
W klasie Math pakietu java.lang zdefiniowano statyczne metody matematyczne.
Między innymi:
|
Metody matematyczne
|
| int abs(int arg) | wartość bezwzględna argumentu |
| double abs(double arg) |
|
| int min(int arg1, int arg2) | minimum z arg1, arg2 |
| double min(double arg1, double arg2) | minimum z arg1, arg2 |
| int max(int arg1, int arg2) | maksimum z arg1, arg2 |
| double max(double arg1, double arg2) | maksimum z arg1, arg2 |
| double ceil(arg) | zwraca
najmniejszą wartość rzeczywistą większą lub równą argumentowi i
matematycznie tożsamą z liczbą całkowitą, np. ceil(2.1) == 3 |
| double floor(arg) | zwraca
największą wartość rzeczywistą mniejszą lub róną argumentowi i
matematycznie tożsamą z liczbą całkowitą np. floor(2.1) == 2 |
| double sqrt(double arg) | pierwiastek kwadratowy arg
|
| double cbrt(double arg) | pierwiastek 3 stopnia z arg |
| double exp(double arg) | Zwraca potęgę o podstawie e i wykładniku arg |
| double expm(double x) | Zwraca ex -1 |
| double pow(double base, double exp) | zwraca potęgę o podstawie base i wykładniku
exp. Jeśli base ma wartość 0, a exp jest ujemne albo niecałkowite, to zwraca
NaN. |
| |
| double log(double arg) | Zwraca logarytm naturalny arg. Jeśli argument nie jest dodatni, to zwraca NaN. |
| double sin(double arg) | Zwraca sinus argumentu podanego w radianach. |
| double cos(double arg) | cosinus |
| double tan(double arg) | tangens |
W klasie Math znajduje się również generator liczb pseudolosowych - metoda
random. Jej użycie jest jednak mniej wygodne niż użycie niestatycznych metod klasy Random, znajdującej się w pakiecie java.util.
Generator liczb pseudolowowych należy najpierw zainicjować za pomocą konstruktorów klasy Random:
Random() // inicjuje generator na podstawie aktualnego czasu w milisekundach
Random(long seed) // inicjuje generator na podstawie podanej liczby
Następnie można generować kolejne liczby pseudolosowe za pomocą odpowiednich niestatycznych metod np:
double nextDouble()
zwraca kolejną pseudolosową liczbę rzeczywistą z równomiernego rozkładu w przedziale [0,1]
int nextInt(int n)
zwraca kolejną pseudolosową liczbę całkowitą z równomiernego rozkładu w przedziale [0, 1) tj. 0 <= nextInt(n) < n.
Zadanie: napisać program do losowania liczb w totolotku (6 z 49).
Umożliwić - na życzenie - inicjowania generatora na podstawie sumy podanch przez użytkownika liczb.
Uwaga: uwzględnić to, że w jednym losowaniu liczby nie mogą się powtarzać.
Możliwe rozwiązanie.
import static javax.swing.JOptionPane.*;
import java.util.*;
public class Toto {
public static void main(String[] args) {
String msg = "Podaj magiczne liczby,\n" +
"nic nie wpisuj = automatyczna inicjacja,\n" +
"lub wybierz Cancel, by skończyć losowania";
Random rand; // generator
boolean[] isDrawn = new boolean[49]; // i-ty element tablicy
// ma wartość true
// gdy liczba i została wylosowana
// inicjalnie jest false (żadna nie wylosowana)
String inp;
while ((inp = showInputDialog(msg)) != null) {
if (!inp.equals("")) { // inicjacja generatora sumą podanych liczb
Scanner sc = new Scanner(inp);
long sum = 0;
while (sc.hasNextInt()) sum += sc.nextInt();
rand = new Random(sum);
}
else rand = new Random(); // gdy nic nie podano - inicjacja czasem
// Losowanie
final int ILE = 6; // liczb do wylosowania
int k = 0; // licznik niepowtarzających się liczb
String out = ""; // tu będzie wynik
while (k < ILE) {
int n = rand.nextInt(49); // losowanie: 0 <= n < 49
if (isDrawn[n]) continue; // jeżeli ta liczba już była wylosowana
else { // nie była - bierzemy ją!
k++; // licznik wziętych + 1
isDrawn[n] = true; // teraz jest naprawdę wylosowana
out += " " + (n+1); // n+1, bo mamy mieć od 1 do 49
}
}
showMessageDialog(null, "Wylosowane liczby:\n" + out);
}
}
}
Szczególnego komentarza wymaga porównywanie wyników operacji na liczbach rzeczywistych. Rozważmy krótki program:
public class FloatRep {
public static void main(String[] args) {
double liczba = 3 * 0.2;
double wynik = 0.6;
if (liczba != wynik)
System.out.println("Nie równe. Różnica wynosi: " + (liczba - wynik));
else System.out.println("Równe");
}
}
Wbrew intuicyjnym oczekiwaniom wynikeim jego działania będzie, stwierdzenie,
że 3 * 0.2 nie jest równe 0.6. Wyprowadzi on bowiem następujący napis:
Nie równe. Różnica wynosi: 1.1102230246251565E-16
Dzieje się tak ze względu na reprezentację liczb rzeczywistych, która w Javie
opiera się na standardzie IEEE 754, w którym niektóre liczby rzeczywiste
nie mogą mieć dokładnej reprezentacji. Innym problemem związanym z liczbami
jest ich precyzja - maksymalna liczba miejsc dziesiętnych. Ponieważ dla liczb
typu double mamy w Javie 53 bity precyzji, czyli ok. 16 miejsc dziesiętnych,
to okaże się że np. taki fragment:
double licz2 = 0.1111111111111111,
licz3 = 1111 + licz2,
licz4 = licz3 - 1111;
System.out.println(licz4 - licz2);
wyprowadzi wartość różną od zera (bowiem przy dodawania 1111 i licz2 tracimy
precyzję: liczbę która ma 20 znaczących cyfr dziesiętnych możemy przedstawić
tylko na 16 miejscach dziesiętnych).
Zatem porównywanie wyników operacji na liczbach rzeczywistych może być tylko
przybliżone, wykonywane z pewną dokładnością. Jeżeli mamy dwie liczby rzeczywiste
d1 i d2, to ich porównanie powinniśmy wykonywać za pomocą następującej konstrukcji:
if (Math.abs(d1-d2)) <= epsilon) // liczby równe
else // liczby nierówne
gdzie: epsilon - zadana dokładność porównania.
Jeśli natomiast chcemy wykonywać operacje matematyczne z pełną dokładnością
i w dowolnej precyzji, należy zastosować klasę BigDecimal, która pozwala
na posługiwanie się dowolnymi liczbami z dowolną dokładnością (ograniczeniem
są tylko rozmiary pamięci operacyjnej).
Oto przykład:
import java.math.*;
public class BigDec {
public static void main(String[] args) {
BigDecimal liczbaA = new BigDecimal("3");
BigDecimal liczbaB = new BigDecimal("0.2");
BigDecimal wynik = liczbaA.multiply(liczbaB);
if (!wynik.equals(new BigDecimal("0.6")))
System.out.println("Nie równe.");
else System.out.println("Równe");
BigDecimal licz2 = new BigDecimal("0.111111111111111111111111111111111"),
licz1111 = new BigDecimal("1111"),
licz3 = licz1111.add(licz2),
licz4 = licz3.subtract(licz1111);
System.out.println(licz3);
System.out.println(licz4);
System.out.println(licz4.subtract(licz2).toPlainString());
}
}
Wyniki działania tego program - w przeciwieńswie do podobnych operacji na
liczbach typu double - będą zgodne z regułami matematycznymi. Zauważmy też,
że możemy posługiwać się dowolną liczbą cyfr znaczących (tu liczba reprezentowana
przez zmienną licz3 ma ich 37):
Równe
1111.111111111111111111111111111111111
0.111111111111111111111111111111111
0.000000000000000000000000000000000
W klasie BigDecimal dostępne są także operacje skalowania i zaokrąglania liczb.
Do prowadzenia dokładnych obliczeń (np. finansowych) nalezy uzywać klasy BigDecimal.
Działając
na liczbach rzeczywistych (typu double lub float) należy też pamiętać,
ze w komputerze nie jest możliwa reprezentacja wszystkich liczb
rzeczywistych.
W pobliżu liczby 1 jest przecież nieskończenie wiele
liczb rzeczywistych, ale komputerowa reprezentacja widzi tylko niektóre
z nich, bowiem są one przechowywane w skończonej liczbie bitów.
Wartość
tzw. ULP (Unit in the last place) pokazuje odległość pomiędzy dwoma
sąsiednimi liczbami - mówiąc dokładniej: ULP(x) to odległośc
między dwoma najbliższymi x liczbami.
Za pomocą metody ulp(x) z
klasy Math możemy dowiedzieć się ile wynosi ta odległosć, a metoda
nextUp(x) zwraca najbliższą mozliwą do uzyskania liczbę rzeczywistą
więksża od x.
Przykładowy program pokazuje ulp dla wartości 1 oraz nastepną (po 1) możliwą do uzyskania liczbę rzeczywistą:
import static java.lang.Math.*;
public class Ulp1 {
public static void main(String[] args) {
double d1 = 1;
System.out.println("Dla wartości:" + d1);
System.out.println("ULP: " + ulp(d1));
System.out.println("Następna możliwa liczba: " + nextUp(d1));
}
}Wynik:
Dla wartości: 1.0
ULP: 2.220446049250313E-16
Następna możliwa liczba: 1.0000000000000002
Ma to ważne konsekwencje, bowiem dodawanie do x wartości mniejszej od ulp(x) nie będzie miało żadnego efektu.
Weźmy
np. dwie zmienne d1 i d2, zainicjujmy obie wartością 1e16 (10 do potęgi
16), po czym milion razy zwiększmy d2 o jeden. Jaka jest różnica między
d2 i d1? Intuicyjnie - milion. Niestety, ulp dla liczby 1e16
wynosi 2, wobec tego dodawanie jedynki (nawet miliony razy) nie
ma żadnego efektu. zatem taki programik:
public static void main(String[] args) {
double d1 = 1e16,
d2 = d1;
for(int i = 1; i<=1000000; i++) d2++;
System.out.println("Różnica: " + (d2 - d1));
}da w wyniku:
Różnica: 0.0
4. Daty i czas
Informacje o datach i czasie są w Javie reprezentowane przez obiekty klasy Calendar.
Informacje o bieżącej dacie i czasie możemy uzyskać m.in. za pomocą odwołania:
Calendar c = Calendar.getInstance();
które zwraca obiekt - domyślny kalendarz dla domyślnej lokalizacji
ustawiony na bieżącą datę i czas w strefie czasowej właściwej dla domyślnej
lokalizacji.
Informacje o dacie i czasie są zapisane w polach obiektu-kalendarza. Dostęp do tych pól uzyskujemy za pomocą metody get(...)
, użytej na rzecz obiektu-kalendarza, z argumentem - stałą statyczną klasy
Calendar, okreslającą o jaki rodzaj informacji nam chodzi. import java.util.*;
import static java.util.Calendar.*;
public class Kal1 {
public static void say(String s) { System.out.println(s); }
public static void main(String[] args) {
// uzyskanie kalendarza domyślnego
// (obowiązującgo dla domyślnej lokalizacji - tu dla Polski)
// ustawionego na bieżącą datę i czas
Calendar cal = Calendar.getInstance();
say("ERA.............. " + cal.get(ERA) +
" (tu: 0=pne, 1=AD)");
say("ROK.............. " + cal.get(YEAR));
say("MIESIĄC.......... " + cal.get(MONTH) +
" (0-styczeń, 2-luty, ..., 11-grudzień)");
say("LICZBA DNI\n" +
"W MIESIĄCU....... " + cal.getActualMaximum(DAY_OF_MONTH));
say("DZIEŃ MIESIĄCA... " + cal.get(DAY_OF_MONTH));
say("DZIEŃ MIESIĄCA... " + cal.get(DATE));
say("TYDZIEŃ ROKU..... " + cal.get(WEEK_OF_YEAR));
say("TYDZIEŃ MIESIĄCA. " + cal.get(WEEK_OF_MONTH));
say("DZIEŃ W ROKU..... " + cal.get(DAY_OF_YEAR));
say("PIERWSZY DZIEŃ\n" +
"TYGODNIA......... " + cal.getFirstDayOfWeek() +
" (1-niedziela, 2-poniedziałek, ..., 7 sobota)");
say("DZIEŃ TYGODNIA... " + cal.get(DAY_OF_WEEK) +
" (1-niedziela, 2-poniedziałek, ..., 7-sobota)");
say("GODZINA.......... " + cal.get(HOUR) +
" (12 godzinna skala; następne odwolanie czy AM czy PM)");
say("AM/PM............ " + cal.get(AM_PM) +
" (AM=0, PM=1)");
say("GODZINA.......... " + cal.get(HOUR_OF_DAY) +
" (24 godzinna skala)");
say("MINUTA........... " + cal.get(MINUTE));
say("SEKUNDA......... " + cal.get(SECOND));
say("MILISEKUNDA: " + cal.get(MILLISECOND));
int msh = 3600*1000; // liczba milisekund w godzinie
say("RÓŻNICA CZASU\n" +
"WOBEC GMT........ " + cal.get(ZONE_OFFSET)/msh);
say("PRZESUNIĘCIE\n" +
"CZASU............ " + cal.get(DST_OFFSET)/msh +
" (w Polsce obowiązuje w lecie)");
}
}
Uwaga: warto zauwazyć jak bardzo przydał się tu statyczny import.
Na wydruku pokazano wyniki działania programu:
ERA.............. 1 (tu: 0=pne, 1=AD)
ROK.............. 2008
MIESIĄC.......... 7 (0-styczeń, 2-luty, ..., 11-grudzień)
LICZBA DNI
W MIESIĄCU....... 31
DZIEŃ MIESIĄCA... 14
DZIEŃ MIESIĄCA... 14
TYDZIEŃ ROKU..... 33
TYDZIEŃ MIESIĄCA. 2
DZIEŃ W ROKU..... 227
PIERWSZY DZIEŃ
TYGODNIA......... 2 (1-niedziela, 2-poniedziałek, ..., 7 sobota)
DZIEŃ TYGODNIA... 5 (1-niedziela, 2-poniedziałek, ..., 7-sobota)
GODZINA.......... 5 (12 godzinna skala; następne odwolanie czy AM czy PM)
AM/PM............ 0 (AM=0, PM=1)
GODZINA.......... 5 (24 godzinna skala)
MINUTA........... 38
SEKUNDA......... 12
MILISEKUNDA: 140
RÓŻNICA CZASU
WOBEC GMT........ 1
PRZESUNIĘCIE
CZASU............ 1 (w Polsce obowiązuje w lecie)
Uwaga: należy zwrócić baczną uwagę na to, że indeksowanie miesięcy rozpoczyna
się od 0, a nie od 1 (czyli styczeń ma numer 0).
Za pomocą metod set... kalendarza możemy ustawiać jego bieżącą datę i czas.
Np. aby ustawić kalendarz na 7 maja 2003 roku na tę samą godzinę co "teraz" możemy napisać:
Calendar c = Calendar.getInstance();
c.set(2003, 4, 7); // rok 2003, indeks miesiąca = 4 (maj), dzień 7
a jeśli chcemy zarazem ustalić godzinę 18 minut 05 napiszemy:
c.set(2003, 4, 7, 18, 5);
Możemy też zmieniać (ustawiać) wartości poszczególnych pól.
Służą do tego metody, które wykonują operacje na datach.
Operacje na datach wykonujemy za pomocą następujących metod:
set(id_pola, wartość)
add(id_pola, wartość)
roll(id_pola, wartość)
gdzie:
id_pola - stała statyczna z klasy
Calendar, określająca pole na którym wykonywana jest oparacja,
wartość - nowa wartość pola.
Wszystkie w/w operacje uwzględniają reguły danego kalendarza, a różnica pomiędzy nimi jest następująca:
- set - ustala wartość pola; jeśli trzeba dostosowując inne pola (np.
ustawienie pola DAY_OF_MONTH na wartość 31 dla kalendarza ustawionego na
dowolną datę w czerwcu spowoduje, że kalendarz będzie wskazywał na 1 lipca,
gdyż w czerwcu jest tylko 30 dni),
- add - dodaje do pola podaną wartość, stosując przy tym arytmetykę
kalendarzową (np. dodanie do 30 maja 2 dni spowoduje ustawienie kalendarza
na 1 czerwca),
- roll - również wykonuje dodawanie, ale przy tym nie zmienia wartości
"starszych" pól np. jeżeli dodajemy dni i okaże się, że nowa data znajdzie
się w innym niż teraz miesiącu, to miesiąc nie zostanie zmieniony, zaś "nadwyżka"
dni (poza końcem bieżącego miesiąca) będzie dodawana od początku miesiąca.
Dokładne reguły obliczeniowe są podane w dokumentacji klasy Calendar.
Przykładowy program na wydruku testuje działanie omówionych metod.
import java.util.*;
import javax.swing.*;
public class TestKal {
public static void main(String[] args) {
String in;
int d = 0;
while ((in = JOptionPane.showInputDialog("DATE:")) != null) {
d = Integer.parseInt(in);
show("set", "DATE", Calendar.DATE, d);
show("add", "DATE", Calendar.DATE, d);
show("roll", "DATE", Calendar.DATE, d);
}
System.exit(0);
}
static void say(String s) { System.out.println(s); }
static void show(String oper, String what, int field, int value) {
Calendar c = Calendar.getInstance();
say("Teraz jest: " + c.getTime());
say("Operacja: " + oper + "(Calendar." + what + ", " + value + ")");
if (oper.equals("set")) c.set(field, value);
else if (oper.equals("add")) c.add(field, value);
else if (oper.equals("roll")) c.roll(field,value);
say("Aktualne ustawienia kalendarza: " + c.get(Calendar.YEAR) + '-'
+ (c.get(Calendar.MONTH) + 1) + '-' +
+ c.get(Calendar.DATE));
say("-----------------------------------------------------------");
}
}
Wynik:
Teraz jest: Thu Aug 14 05:48:58 CEST 2008
Operacja: set(Calendar.DATE, 20)
Aktualne ustawienia kalendarza: 2008-8-20
-----------------------------------------------------------
Teraz jest: Thu Aug 14 05:48:58 CEST 2008
Operacja: add(Calendar.DATE, 20)
Aktualne ustawienia kalendarza: 2008-9-3
-----------------------------------------------------------
Teraz jest: Thu Aug 14 05:48:58 CEST 2008
Operacja: roll(Calendar.DATE, 20)
Aktualne ustawienia kalendarza: 2008-8-3
-----------------------------------------------------------
Uwaga: CEST oznacza Central European Summer Time
Zwróćmy uwagę na metodę getTime(). Wykorzystano ją w omawianym programie,
by łatwo wypisać datę i czas w jakiejś ludzkiej postaci,
Metody zdezaktualizowane (deprecated) są utrzymywane w standardowych
pakietach Javy ze względu na aplikacje, które zostały kiedyś napisane i odwołują
sie do tych metod. Pisząc nowe programy nie nalezy używac takich metod, nie
tylko dlatego, że istnieją inne, nowsze i lepsze metody, ale również dlatego,
że użycie metod zdezaktualizowanych w niektórych okolicnościach może prowadzić
do błędnego działania aplikacji.
Metoda ta zwraca obiekt klasy Date,
reprezentujący datę i czas dla danego ustawienia
kalendarza. Obiekty klasy Date zawierają czas w postaci liczby
milisekund, które
upłynęły od 1 stycznia 1970 r. (data zwana "początkiem epoki", ponieważ
jest to data premiery Unixa). Klasa
ta w dawnych wersjach Javy była stosowana do działania na datach i
czasie,
ale ponieważ nie uwzględniała on różnych ustawień regionalnych (lokalizacji) i
istnienia
różnych kalendarzy, to w tej chwili większość jej metod jest
zdezaktualizowana
i zamiast nich należy stosować metody klasy Calendar.
Wewnętrznie
klasa kalendarza prowadzi równoległą
podwójną reprezentację daty i czasu - za pomocą omówionych wcześniej
pól
oraz za pomocą liczby milisekund od początku epoki (wartość
typu long,
zwracana przez metoda getTimeInMillis()). Wartość milisekund można
pobierać za pomoca metody getTimeInMiiss() i ustawiać
za pomocą metody setTimeInMillis(long).
Za pomoca pomiaru milisekund można porównywac daty, ale również można wykorzystać metodę
c1.compareTo(Calendar
c2) klasy Calendar, zwracającą -1, gdy data ustawiona w c1 jest
wcześniejsza od określanej przez c2, 0 - gdy daty są takie same i 1 -
gdy data w c1 jest późniejsza niż w c2.
Do szybszego stwierdzania następstwa dat można wykorzystać metody before(...) i after(...).
5. Formatowanie liczb i dat
Wyprowadzając liczby rzeczywiste i daty w postaci napisów zetkniemy się z problemem formatowania.
Poniższy program:
import java.util.*;
public class BrakFormat {
public static void main(String[] args) {
double cena = 1.52;
double ilosc = 3;
double koszt = cena * ilosc;
System.out.println("Koszt wynosi: " + koszt);
Calendar c = Calendar.getInstance();
System.out.println("Data: " + c.getTime());
}
}
da w wyniku niezbyt sympatyczny wydruk:
Koszt wynosi: 4.5600000000000005
Data: Thu Aug 14 06:32:36 CEST 2008
A
chcielibyśmy może uzyskać informację o koszcie z dokładnością do groszy
(dwa miejsca po przecinku), a datę w jakimś sensownym, dopuszczalnym
formacie.
Klasa java.utill.Formatter zapewnia możliwości formatowania danych.
Tworząc formator (za pomocą wywołania konstruktora) możemy
określić:
- destynację formatowanych danych (dokąd mają być zapisane), którą m.in.
może być String, StringBuffer, plik tekstowy,
- lokalizację
(ustawienia regionalne, reprezentowane przez obiekt
klasyLocale), wpływającą m.in. na reprezentację liczb i dat,
- stronę kodową (do kodowania napisów) -
m.in. dla plików i Stringów
Uwaga: formatory dla plików powinny być po użyciu zamykane lub wymiatane
(close(), flush()),
co powoduje zamknięcie lub wymiecenie buforów tych destynacji.
Formatowanie polega na wywołaniu jednej z dwóch wersji metody format
(na rzecz fornatora):
Formatter
format(String format, Object... arg)
Formatter
format(Locale l, String format, Object... arg)
Druga z tych metod pozwala na podanie lokalizacji, m.in. wpływającej na sposób formatowania liczb.
Łańcuch formatu (zmienna format) zawiera dowolne ciągi znaków oraz specjalne elementy
formatujące.
Dalej następują dane do "wstawienia"
w łańcuch formatu
w miejsce elementów formatu i do sformatowania podług zasad określanych przez te elementy
(zmienna
liczba argumentów dowolnego typu - formalnie Object). Dzięki
autoboxingowi
nie ma problemu z formatowaniem danych typów prostych.
Dla uproszczenia dostępne są:
- statyczne metody format w
klasie String, pozwalające na uzyskiwanie sformatowanych napisów,
- metody format i printf
(działające tak samo) w klasach PrintStream i PrintWriter,
wyprowadzające sformatowane napisy "na wyjście" (np. na standardowe
wyjście lub do pliku).
Elementy formatu mają następującą ogólną postać:
%[arg_ind$][flagi][szerokość_pola][.precyzja]konwersja
gdzie:
- arg_ind$
- numer argumentu (z listy argumentów arg) do sformatowania przez dany
element; numeracja zaczyna się od 1; poczynając od drugiego
elmentu formatu można w tym miejscu zastosować znak < , co oznacza,
że dany element ma być zastosowany wobec argumentu uzytego w poprzednim
formatowaniu,
- flagi - znaki modyfikujące sposób formatowania (są różne dla różnych typów konwersji),
- szerokość_pola - minimalna liczba znaków dla danego argumentu w wynikowym napisie,
- .precyzja
- liczba pokazywanych miejsc dziesiętnych (dotyczy liczb rzeczywistych)
lub maksymalna liczba wyprowadzanych znaków (dotyczy np. napisów),
- konwersja
- określa jak ma być traktowany i formatowany odpowiadający danemu
elementowi argument - np. jako liczba rzeczywista albo jako napis albo
jako data.
Uwaga: nawiasy kwadratowe oznaczają opcjonalność.
Symboli konwersji jest b. dużo, dla różnych symboli mogą być stosowane też dodatkowe flagi.
Wszystko to jest opisane w sposób systematyczny w dokumentacji (proszę sięgać).
Tutaj przedstawione zostaną wybrane konwersje i flagi.
Wybrane konwersje - skrót
| Konwersja | Może być stosowana wobec | Wynik |
| s lub S | dowolnych danych | Jeżeli argument jest null - napis "null":
w przeciwym razie
jeżeli klasa arg na to zezwala
- wynik wywołania arg.formatTo(...)
w przeciwnym razie wynik wywołania arg.toString()
Uwaga: użycie jako symbolu konwersji dużego S spowoduje zamianę liter napisu na duże. |
| c lub C | typów reprezentujących znaki Unicode | znak Unicode |
| d | typów reprezentujących liczby całkowite | liczba całkowita (dziesiętna) |
| f | float, double, Float, Double, BigDecimal | liczba rzeczywista z separatorem miejsc dzisiętnych |
| tH | danych reprezentujących czas, czyli:
long, Long, Calendar, Date | godzina na zegarze 24-godzinnym-2 cyfry (00-23) |
| tM | minuty - 2 cyfry (00 - 59) |
| tS | sekundy - 2 cyfry (00-60) |
| tY | rok - 4 cyfry (np. 2008) |
| tm | miesiąc - 2 cyfry (01-12) |
| td | dzień miesiąca - 2 cyfry (01 -31) |
| tR | czas na zegarze 24 godzinnym sformatowany jako "%tH:%tM" |
| tT | czas na zegarze 24 godzinnym sformatowany jako "%tH:%tM:%tS" |
| tF | data sformatowana jako "%tY-%tm-%td" |
Wśród flag na szczególną uwagę zasługują:
'-' - wynik wyrównany w polu do lewej (domyslnie jest wyrównany do prawej),
'+' - wynik zawiera zawsze znak (dla typów liczbowych),
' ' - wynik zawiera wiodąca spację dla argumentów nieujmenych (tylko dla typów liczbowych).
Zatem,
aby uzyskać sformatowane wyniki w poprzednim przykładowym programie
(liczbę z dwoma miejscami dziesiętnymi, datę w postaci
rok-miesiąc-dzień) możemy napisać:
import java.util.*;
public class Format1 {
public static void main(String[] args) {
double cena = 1.52;
double ilosc = 3;
double koszt = cena * ilosc;
System.out.printf("Koszt wynosi %.2f zł", koszt);
System.out.printf("\nData: %tF", Calendar.getInstance());
}
}Wynik:
Koszt wynosi 4,56 zł
Data: 2008-08-14
Warto
tu zwrócić uwagę na to, że dla lokalizacji polskiej liczba pokazywana
jest z przecinkiem jako separatorem miejsc dziesiętnych.
Aby uzyskac kropkę można napisać:
System.out.printf(Locale.ROOT, "Koszt wynosi %.2f zł", koszt);
W tym przypadku stała statyczna Locale.ROOT oznacza neutralną lokalizację (bez wybranego kraju i języka).
Kilka innych przykładów pokazuje program na wydruku.
import javax.swing.*;
public class Format2 {
public static void main(String[] args) {
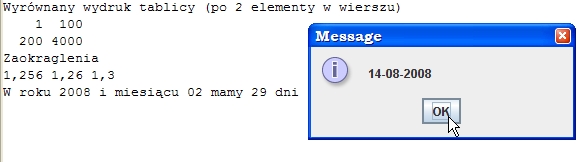
System.out.println("Wyrównany wydruk tablicy (po 2 elementy w wierszu)");
int[] arr = { 1, 100, 200, 4000 };
int k = 1;
for (int i : arr) {
System.out.printf("%5d", i);
if (k%2 ==0) System.out.println();
k++;
}
// Zastosowanie znaku < (elment formatu stosowany wobec argumentu z poprzedniego formatowania)
System.out.println("Zaokraglenia");
System.out.printf("%.3f %<.2f %<.1f", 1.256 );
// Znak < szczególnie przydatny w datach/czasie
Calendar c = Calendar.getInstance();
c.set(Calendar.MONTH, 1);
System.out.printf("\nW roku %tY i miesiącu %<tm mamy %d dni", c, c.getActualMaximum(Calendar.DATE) );
// Oczywiście możemy formatować do Stringów
String dateNow = String.format("%td-%<tm-%<tY", System.currentTimeMillis());
JOptionPane.showMessageDialog(null, dateNow);
}
}Wynik działania programu (konsolę i okno dialogowe) pokazuje rysunek.
6. Proste sortowanie i wyszukiwanie
Co
prawda o sortowaniu była już mowa i na pewno jest ono intuicyjnie
zrozumiałe, to warto jednak trochę uporządkować pojęcia, a przy okazji
poćwiczyć technikę programowania.
Wielokrotnie zetkniemy się z potrzebą uporządkowania informacji, ułożenia
danych w określonej kolejności. W uporządkowanych zestawach informacji łatwiej
jest odnajdywać dane, zresztą samo uporządkowanie może być niezbędną cechą
jakiegoś zbioru danych. Najprostsze przykłady:
- lista plików uporządkowanych
według nazw lub według daty ostatniej modyfikacji,
- lista 10 pierwszych zawodników,
którzy zdobyli najwięcej punktów.
Ułożenie danych w określonej kolejności oznacza jakiś ich porządek. Zwykle przy takim układaniu
będziemy posługiwać się tutaj rosnącymi (lub malejącymi) wartościami jakiejś
cechy danych. Np. lista 10 zawodników, którzy zdobyli największą liczbę punktów
powinna być uporządkowana wedlug liczby punktów - od największej do najmniejszej
(wtedy będziemy mogli stwierdzić kto wygrał zawody i jakie miejsca zajęli
poszczególni zawodnicy)
Samo porządkowanie zbioru danych nazywa się sortowaniem. Będziemy mówić więc o sortowaniu w porządku rosnącym lub malejącym.
Istnieje wiele algorytmów sortowania. Tutaj przedstawiony zostanie
jeden z najprostszych (ale za to mało efektywny - czyli
wolny) zwany
po angielsku selection sort (co możemy przetłumaczyć jako "sortowanie przez
wybór").
Załóżmy, że mamy tablicę 5 liczb całkowitych i chcemy je ułożyć w porządku
niemalejącym (czyli w kolejności wzrostu liczb - od najmniejszej do największej
- z uwzględnieniem tego, że niektóre liczby w tablicy mogą być takie same
i wtedy znajdą się na kolejnych pozycjach, mimo, że nie występuje ich wzrost).
Przykładowo możemy mieć taką tablicę.
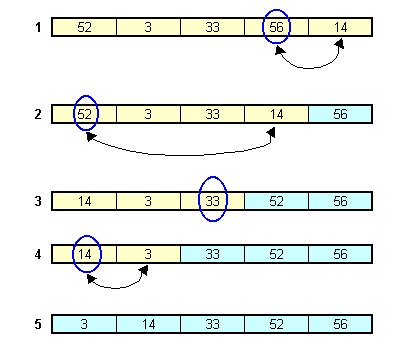
int[] a = { 52, 3, 33, 56, 14 };
Na ostatniej pozycji w tablicy powinna znaleźć się największa liczba. Możemy
ją znaleźć przeglądając tablicę od początku do ostatniego elementu tablicy
i określając na której pozycji znajduje się wielkość maksymalna. Aha, maksymalną
liczbą jest 56 i znajduje się na pozycji 4 (indeks 3). Powinna znaleźć się
na ostatniej pozycji (pozycja 5, indeks 4), Ale tam stoi liczba 14. Gdybyśmy po prostu
zapisali: a[4] = a[3] - stracilibyśmy liczbę 14. Musimy tę liczbę gdzieś
zapisać. Musi ona być uwzględniona przy dalszym porządkowaniu tablicy, zatem
nie może być zapisana gdzieś poza tablicą. Jeśli liczbę 56 zapiszemy z pozycji
4 na pozycję 5, to pozycja 4 będzie wolna i tam właśnie możemy umieścić liczbę
14. Oznacza to, że musimy przestawić elementy tablicy np. tak:
int temp = a[3];
a[3] = a[4];
a[4] = temp;
W tej chwili nasza tablica będzie wyglądać tak:
52 3 33 14 56
i kawałek tej tablicy jest już uporządkowany (ostatni element zawiera właściwą,
największą, liczbę). Teraz poszukamy kolejnego największego elementu. Szukamy
od początku tablicy, ale nie musimy już brać pod uwagę ostatniego elementu
(bo już jest właściwie umiejscowiony i na pewno nie będziemy go przestawiać).
Tym razem przeszukiwanie tablicy zakończymy na przedostatnim elemencie. Znaleziony
element maksymalny to 52 i ma indeks 0. Powinien znaleźć się w tablicy jako
jej przedostatni element. Zatem znowu dokonujemy przestawienia (14 <->
52) i otrzymujemy tablicę:
14 3 33 52 56
W tej tablicy we własciwym porządku są już dwa ostatnie elementy, zatem dalsze
kroki ograniczamy do trzech pierwszych elementów: znowu wyszukujemy największy.
Tym razem okazuje się, że jest to 33 i że już znajduje się na właściwej pozycji.
Uporządkowana część tablicy zwiększyła się do trzech elementów. Pozostało
zobaczyć, który z pierwszych dwóch elementów jest większy i ewentualnie je
przestawić. Zamieniamy miejscami 14 i 3. Tablica jest posortowana.
Kolejne kroki ilustruje poniższy rysunek na którym kolorem żółtym zaznaczono
nieposortowaną część tablicy, kolorem niebieskim - już posortowaną, a niebieskim
kółkiem - maksymalny element odszukiwany w każdym kroku w nieposortowanej
części tablicy.
Możliwy sposób oprogramowania algorytmu sortowania przez wybór przedstawia wydruk:
public void selectionSort(int[] a) {
// toInd - oznacza ostatni indeks nieposortowanej części tablicy
// na początku jest to ostatni indeks tablicy
// w kolejnych krokach toInd będzie zmniejszany o 1
// bo zmniejszają się rozmiary nieposortowanej częsci tablicy
// Gdy toInd osiągnie wartość 0 - "nieposortowany" będzie pierwszy
// element. Ale nie mamy go już gdzie przstawić, faktycznie znajduje się
// on na własciwym miejscu.
// Zatem nie musimy dokonywać żadnego przestawienia.
// Tablica jest posortowana. Kończymy pętle.
for (int toInd=a.length-1; toInd>0; toInd--) {
int indMax = 0; // indeks maksymalnego elementu
// w nieposortowanej części tablicy
// szukamy tego indeksu, przeglądając nieposortowaną część tablicy
for (int k=1; k <= toInd; k++)
if (a[indMax] < a[k]) indMax = k;
// Przestawiamy elementy:
// maksymalny element idzie na ostatnią pozycję w nieposortowanej
// części tablicy; a liczba spod tego indeksu jest zapisywana
// w miejscu okupowanym poprzednio przez max element
int temp = a[toInd];
a[toInd] = a[indMax];
a[indMax] = temp;
}
}
Do przetestowania napisanej metody możemy użyć następującej klasy:
import java.util.*;
public class SelSort {
public SelSort(int n, int m) {
Random rand = new Random();
int[] a = new int[n];
for (int i=0; i < n; i++) {
a[i] = rand.nextInt(m+1);
System.out.print(" " + a[i]);
}
selectionSort(a);
System.out.print('\n');
for (int i=0; i < n; i++) System.out.print(" " + a[i]);
}
public void selectionSort(int[] a) {
// ...
}
public static void main(String[] args) {
new SelSort(Integer.parseInt(args[0]), Integer.parseInt(args[1]));
}
}
Jako argumenty wywołania podajemy rozmiar tablicy oraz maksymalną liczbę,
jaka może znaleźć się w tablicy (powiedzmy max). Wartości elementów tablicy
zostaną utworzone przez generator liczb pseudolosowych (0 <= a[i] <=
max). Następnie wywołana zostanie metoda selectionSort.
Wydruk programu pokazuje tablicę nieposortowaną oraz posortowaną np.
5 72 58 39 75 18 92 79 35 63
5 18 35 39 58 63 72 75 79 92
Algorytm sortowania przez wybór należy do najwolniejszych algorytmów sortowania.
Jest wiele innych, lepszych algorytmow.
W praktycznym programowiu raczej rzadko
pisze się algorytmy sortowania - korzysta się zwykle z gotowego
oprogramownia.
Również Java dostarcza oprogramowanych algorytmów w postaci
gotowych metod. Widzieliśmy już w dzialaniu metodę sortowania list z
klasy Collections..
W pakiecie java.util istnieje klasa Arrays, w której zdefiniowano metody sort
, umożliwiające sortowanie m.in. tablic liczb całkowitych i rzeczywistych.
Dla ciekawości możemy sprawdzić jaka jest różnica czasowa zastosowania algorytmu
selection sort oraz tego, który poslużył do sformułowania metod sort w klasie
Arrays (jest to zmodyfikowany algorytm quicksort).
import java.util.*;
class QTimer {
private final long start;
public QTimer() {
start = System.currentTimeMillis();
}
public long getElapsed() {
return System.currentTimeMillis() - start;
}
}
public class SelSort1 {
static public void selectionSort(int[] a) {
// ... jak na poprzednim wydruku
}
public static void main(String[] args) {
int n = Integer.parseInt(JOptionPane.showInputDialog("Liczba elementów w tablicy"));
Random rand = new Random();
int[] a = new int[n];
int[] b = new int[n];
for (int i = 0; i < n; i++) {
a[i] = rand.nextInt(n * 10);
b[i] = a[i];
}
System.out.println("Liczba elementów tablicy " + n);
QTimer qt = new QTimer();
selectionSort(a);
System.out.println("Czas selection sort: " + qt.getElapsed());
qt = new QTimer();
Arrays.sort(b);
System.out.println("Czas quicksort: " + qt.getElapsed());
}
}
Przykładowo, dla losowo wygenerowanych tablic 100000 liczb całkowitych moglibyśmy uzyskać następujący wynik:
Liczba elementów tablicy 100000
Czas selection sort: 17359
Czas quicksort: 31
Widzimy więc, że dobry algorytm sortowania może być - przy dużej liczbie
elementów tablicy - nawet kilkaset razy szybszy niż bardzo proste, ale wolne
sortowanie przez wybór.
A jak posortować napisy?
Oczywiście - powinniśmy skorzystać z metody compareTo z klasy String.
public class SortString {
static public void selectionSort(String[] s) {
for (int toInd=s.length-1; toInd>0; toInd--) {
int indMax = 0;
for (int k=1; k <= toInd; k++)
if (s[indMax].compareTo(s[k]) < 0) indMax = k;
String temp = s[toInd];
s[toInd] = s[indMax];
s[indMax] = temp;
}
}
public static void show(String[] s) {
System.out.print('\n');
for (int i=0; i < s.length; i++) System.out.print(" " + s[i]);
}
public static void main(String[] args) {
String[] s = {"A", "Z", "C", "B", "1", "3", "2", "A", "C" };
show(s);
selectionSort(s);
show(s);
}
}
Wydruk programu:
A Z C B 1 3 2 A C
1 2 3 A A B C C Z
W klasie Arrays znajdziemy również metodę sort(...), która
za argument ma tablicę dowolnych obiektów. Jesli klasa tych obiektów odpowiednio
definiuje metodę compareTo, to możemy z powodzeniem użyć tej metody (taka
sytuacja dotyczy np. klasy String oraz klas "opakowujących" typy pierwotne:
Integer, Double.itp. a także klasy Date, której obiekty reprezentują daty).
Jeśli klasa nie dostarcza odpowiedniej metody compareTo, to trzeba zastosować
nieco bardziej zaawansowane podejście, o którym będzie mowa kiedy indziej.
Często też w programowaniu będziemy stykać się z problemem odnalezienia konkretnego elementu tablicy lub kolekcji.
W najprostszy sposób możemy to zrobić przeglądając po kolei wszystkie elementy
tablicy, dopóki nie natrafiimy na poszukiwaną wartość.
Np. odnaleźć w tablicy liczb całkowitych podaną liczbę, a następnie - jeśli
występuje - zwrócić jej indeks, a jeśli takiej liczby w tablicy nie ma -
zwrócić -1.
public class Search {
public static int linearSearch(int[] tab, int v) {
for (int i=0; i < tab.length; i++)
if (tab[i] == v) return i;
return -1;
}
}
Taki sposób wyszukiwania nazywany jest wyszukiwaniem liniowym.
Wyszukiwanie liniowe polega na przeglądaniu kolejnych elementów tablicy i porównywaniu ich z poszukiwaną wartością
Wyszukiwanie liniowe może okazać się bardzo wolne. Jeśli np. szukany element
znajduje się w tablicy na ostatniej pozycji, to liczba wykonanych iteracji
i porównań będzie równa liczbie elementów tablicy, co przy bardzo dużych
tablicach prowadzi do długiego dzialania programu.
Istnieje nieco lepszy sposób przeszukiwania tablic nazywany wyszukiwaniem binarnym.
Rozważmy przykład.
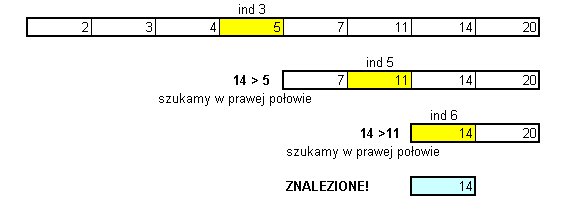
Mamy posortowaną w porządku niemalejącym tablicę liczb całkowitych.
2 3 4 5 7 11 14 20
Będziemy szukać w tej tablicy liczby 14.
Podzielmy tablicę na dwie połowy. Ostatni element w lewej połowie = 5, jest
mniejszy od szukanej liczby. Oznacza to, że (ponieważ tablica jest posortowana)
szukana liczba znajduje się w prawej połowie tablicy. Podzielmy tę połowę
znowu na dwie. Ostatni element w "nowej" lewej połowie to 11 - znowu mniejszy
od 14. Zatem szukana liczba znajduje się w "nowej" prawej połowie. Dzielimy
ją znowu na dwie (w tym przypadku w każdej nowej połówce znajduje się jedna
liczba) i odkrywamy że nowa "jednoliczbowa" lewa połówka zawiera poszukiwaną
wartość
Ilsutruje to poniższy rysunek:
Gdybyśmy natomiast szukali liczby 4, to sekwencja kroków byłaby następująca:
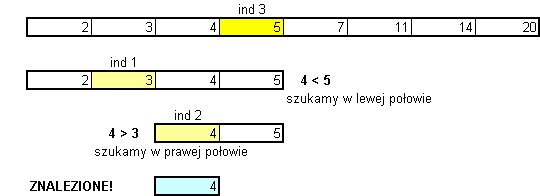
Zwróćmy uwagę, że w każdym kroku binarnego wyszukiwania porównujemy poszukiwaną
wartość z wartością elementu znajdującego się na pozycji "dzielącej" tablicę
na kolejne połówki (element ten na rysunkach zaznaczany jest na żółto, pokazano
też jego indeks).
Można powiedzieć, że zawsze jest to "środkowy" element kolejnych podziałów.
Jeśli w tablicy znajduje się szukana wartość, to w ostatnim kroku binarnego
wyszukiwania ten "środkowy" element będzie jej równy. Jeśli nie, jeśli jej nie ma -
to okaże się, że nie można już więcej dzielić tablicy na kolejne połówki;
stwierdzamy więc, że tablica nie zawiera poszukiwanej wartości.
Zatem możemy zdefiniowac następującą metodę binarnego wyszukiwania:
public class Search {
// v - poszukiwana wartość w tablicy tab
static public int binarySearch(int[] tab, int v) {
int low = 0; // lewy skrajny indeks "aktualnej" połówki
int high = tab.length - 1; // prawy skrajny indeks "aktualnej" połowki
// dopóki możemy dzielić tablicę
while (low <= high) {
int mid = (low + high) / 2; // indeks środkowego elementu
// zakresu low..high
if (v < tab[mid]) // jeżeli wartość jest w lewej połówce:
high = mid - 1; // zmodyfikować skrajny prawy indeks
else if (v > tab[mid]) // w przeciwnym razie jeżeli w prawej połówce:
low = mid + 1; // zmodyfikować skrajny lewy indeks
else return mid; // w przeciwnym razie: zanleziony!
}
return -1; // w tablicy nie znaleziono wartości v
}
Binarne wyszukiwanie jest szybkim algorytmem odnajdywania informacji
w posortowanych tablicach. W każdym jego kroku zakres rozpatrywanych elementów
tablicy zmniejsza się o połowę
Należy wyraźnie podkreślić, że binarne wyszukiwanie wymaga posortowanych
danych. Często jednak opłaca się najpierw posortować dane, by później móc
szybko odnajdywać wśród nich potrzebną informację.
W klasie Arrays znajdziemy statyczną metodę binarySearch(...), która
pozwala na binarne przeszukiwanie tablic i zwalnia nas od pisania kodu. Podobnie
jednak jak w przypadku metody sortującej jej zastosowanie dla tablic obiektów
obarczone jest dodatkowymi warunkami (odpowiednie zdefiniowanie metody compareTo
w klasie obiektów lub zastosowanie specjalnego obiektu, zwanego komparatorem
- o tym wszystkim będziemy mówić w rozdziale o kolekcjach).
7. Rekurencja
Z ciała (kodu) metody możemy wywołać ją samą. Takie wywołanie nazywa się wywołaniem rekurencyjnym.
Rekurencyjne wywołanie metody polega na wywołaniu tej metody z jej własnego ciała
Rozpatrzmy najprostsze przyklady.
public class Recurs {
public static void show1(int i) {
System.out.println("show1 " + i);
if (i > 10) return;
show1(i+1);
}
public static void main(String[] args) {
show1(1);
}
}
show1 1
show1 2
show1 3
show1 4
show1 5
show1 6
show1 7
show1 8
show1 9
show1 10
show1 11
Tutaj sprawa jest dość prosta i do przewidzenia. Wywołanie show1(1)
z metody main uruchamia łańcuch wywołań rekurencyjnych. Każde wywolanie wyprowadza
przekazany argument, po czym sprawdzany jest warunek (i>10), i dopóki
jest on nieprawdziwy ponownie wywoływana jest metoda show1 z powiększoną
o 1 wartością argumentu. Np. po wypisaniu 1 (pierwsze wywołanie) wywoływana
jest metoda show1 z argumentem 2 = 1+1, ten argument jest wypisywany, wywoływana
jest metoda show1 z argumenten 3 (= 2+1), ten jest wypisywany itd. aż w
"wewnętrznym wywołaniu" show1 argument nie osiągnie wartości 11. Wtedy -
po jej wypisaniu - warunek okaże się prawdziwy i dopiero teraz sterowanie
zwrócone zostanie do metody main.
Przy wywolaniach rekurencyjnych należy zapewnić warunek, którego spełnienie
zakończy łańcuch rekurencji i spowoduje zwrócenie sterowania do miejsca,
w którym po raz pierwszy wywołano metodę rekurencyjną
Zobaczmy drugi fragment kodu. Tym razem wywołamy z metody main - za pomocą odwołania show2(1) - następującą metodę.
public static void show2(int i) {
if (i > 10) return;
show2(i+1);
System.out.println("show2 " + i);
}
Wynik dzialania tej metody może wydac się nieco zaskakujący.
show2 10
show2 9
show2 8
show2 7
show2 6
show2 5
show2 4
show2 3
show2 2
show2 1
Co się dzieje? Wywołanie show2(1) przekazuje jako argument 1, i z wnętrza
show2 następuje wywołanie show2 z argumentem 2 (1+1). W tym momecie wykonanie
dalszego kodu metody zostaje wstrzymane. Wykonanie zaczyna się od początku!
Zaczyna działać jakby "nowy egzemplatrza" metody show2. Tym razem z nowym
argumentem (2). I tak dalej. Gdy parametr i osiągnie wartość
11 powinna zadziałać instrukcja return. Ale najpierw muszą być "dokończone"
wszystkie poprzednie, "wstrzymane", wykonania metody show2. Ostatnie było
z argumentem 10. Zatem wyprowadzona zostanie liczba 10 i wykonanie "tego
egzemplarza" metody zostanie zakończone. Poprzedzało go wywołanie show2 z
argumentem 9 - zostanie więc dokończone itd., aż dojdziemy do pierwszego
wywołania show2 (z argumentem 1). Po zakończeniu wykonania metody z tym argumentem
zostanie wykonana instrukcja return i sterowanie wróci do main.
Zauważmy, że w pierwszym przypadku mieliśmy tak naprawdę do czynienia z takim
samym wstrzymywaniem wykonania kodu metody show1 inicjowanego przez kolejne
wywołania rekurencyjne, tyle, że nie mogliśmy tego dostrzec, ponieważ wstrzymywanie
następowało na ostatniej instrukcji metody, już po wyprowadzeniu liczby.
Oczywiście metody rekurencyjne mogą zwracać wartości.
Zobaczmy, jak np. można rekurencyjnie zapisać zadanie sumowania dodatnich liczb całkowitych.
W istocie rekurencja oznacza "zdefiniowanie czegoś przez to samo coś".
Weźmy sumę 1 + 2 + 3 + 4 + 5.
Możemy powiedzieć tak:
suma(1..5) = 5 + suma(1..4)
suma(1..4) = 4 + suma(1..3)
Definiujemy sumę przez sumę!
Ogólnie, suma liczb od 1 do n równa jest n + suma(1..n-1)
Zatem jeśli nasza metoda sumowania otrzymuje argument n (oznaczający, że
mamy zsumować liczby od 1 do n), to moglibyśmy spróbować zapisać:
int sum(int n) {
return n + sum(n-1);
}
Łatwo jednak zauważyć, że wpadamy tu w "nieskończoną" rekurencję. Metoda sum
będzie wywoływana teoretycznie bez końca ze swojego wnętrza (praktycznym
ograniczeniem będzie pamięć komputera - program skończy działanie z komunkatem
"Stack overflow").
Musimy zatem zapewnić jakiś warunek zakończenia wywołań rekurencyjnych,
Uwzględnić jakiś szczególny przypadek wartości przekazanego argumentu, który przerwie nieskończone rekurencyjne wywolania.
W przypadku sumowania liczb od 1 do n, takim szczególnym przypadkiem jest wartość n = 1 (zwracamy wtedy 1).
public class Recurs {
public static int sum(int n) {
if (n == 1) return 1;
else return n + sum(n-1);
}
public static void main(String[] args) {
System.out.println(sum(100));
}
}
Wyprowadzi: 5050.
Warto dokładnie przeanalizować działanie tej metody np. dla n = 5
, pamiętając, że kolejne zwroty wyników rekurencyjnego wywołania sum(...)
są wstrzymywane dopóki n nie osiągnie wartości 1 i zauważając, że odtwarzanie
tych wyników następuje w else, po kolei: 1, 2 + 1, 3 + (2 + 1), 4 + (3 +
2 + 1), 5 + (4 + 3 + 2 +1) i ta ostatnia wartość jest właśnie zwracana do
punktu wywolania sum(..) w metodzie main.
Można się domyślić (choćby z przykładu sumowania), że rekurencyjne wywołania funkcji można zastąpić pętlami iteracyjnymi.
Bardzo często rekurencja będzie jednak prostsza do oprogramowania, bowiem
odzwierciedla ona bezpośrednio pewien sposób rozumowania: nie wiemy jak rozwiązać
cały problem, na którego rozwiązanie składa się powiedzmy n kroków, ale
wiemy jak wykonać jeden krok, gdy już n-1 poprzednich zostało wykonane. I
to właśnie możemy (dość prosto) zapisać w postaci rekurencyjnej.
Trzeba jednak też wiedzieć o tym, że nie zawsze podejście rekurencyjne prowadzi
do efektywnych algorytmów; czasami iteracyjne wersje rozwiązania jakichś
problemów są wielokrotnie szybsze od rekurencyjnych, a nawet - przy ograniczeniach
na pamięć operacyjną i moc procesora - jedynie możliwe. Sztandarowym przykładem
jest tu rekursywne oprogramowanie wyliczenia liczb ciągu Fibonacciego, które szybko prowadzi do wyczerpania pamięci.
Ciąg Fibonacciego dany jest za pomocą następującego równania, okreslającego wartości Fn kolejnych liczb ciagu (dla n = 0, 1, 2, ...):
F0 = 0,
F1 = 1,
Fn = Fn-2 + Fn-1, dla n > 1.
Czyli jest to ciąg liczb zaczynający się od liczb 0 i 1, przy czym każda
następna liczba ciągu (poczynając od trzeciej) jest sumą dwóch poprzednich
liczb ciągu:
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 ...
Liczby Fibonacciego mają niezwykle ciekawe właściwości. Nader często ciągi
takich liczb obserwowane są w zjawiskach naturalnych, mają też intrygujące
właściwości matematyczne. Więcej na ten temat zobacz np. na stronie Rona Knotta z Uniwersytetu w Surrey
.
Jak widać. ciąg Fibonanciego jest ciagiem rekurencyjnym, zatem wyliczenie
jego kolejnych wyrazów w naturalny sposob można zapisać w postaci rekurencyjnej.
int fib(int n) {
if (n < 2) return n;
else return fib(n-1) + fib(n-2);
}
Jednak wraz ze zwiększaniem wartości n czas obliczeń za pomocą tej metody rośnie katastrofalnie.
Dzieje się tak dlatego, że katastrofalnie rośnie liczba rekurencyjnych wywołań metody fib.
Większą część czasu zajmuje obliczanie już policzonych wartości!
Zobaczmy.
Używając zmodyfikowanej postaci metody fib:
int fib(int n) {
System.out.println("Wywołanie fib z argumentem " + n);
int wynik = 0;
if (n < 2) wynik = n;
else wynik = fib(n-1) + fib(n-2);
System.out.println("Zwrot wyniku: " + wynik);
return wynik;
}
i analizując wydruk po wywołaniu tej metody z jakimś argumentem (np. 8) -
zobaczymy, że wielokrotnie powtarzają się rekurencyjne wywołania metody fib
z tymi samymi argumentami i wielokrotnie powtarzają się zwroty tych samych wyników.
Możemy też automatycznie policzyć liczbę wywołań z różnymi argumentami za pomocą np. takiego programu:
public class ShowFibRec {
int[] calls;
ShowFibRec(int n) {
calls = new int[n+1];
fib(n);
for(int i=0; i <= n; i++)
System.out.println("Liczba wywołań fib z argumentem " + i
+ " " + calls[i]);
}
int fib(int n) {
calls[n]++;
if (n < 2) return n;
else return fib(n-1) + fib(n-2);
}
public static void main(String[] args) {
int n = Integer.parseInt(args[0]);
new ShowFibRec(n);
}
}
Po kompilacji, możemy porównać liczbę "powtórnych" wywołań dla różnych n podawanych jako argument wywołania, np. 8 i 20.
Uzyskamy następujący wyniki:
Dla n = 8
|
Dla n = 20
|
Liczba wywołań fib z argumentem 0 13
Liczba wywołań fib z argumentem 1 21
Liczba wywołań fib z argumentem 2 13
Liczba wywołań fib z argumentem 3 8
Liczba wywołań fib z argumentem 4 5
Liczba wywołań fib z argumentem 5 3
Liczba wywołań fib z argumentem 6 2
Liczba wywołań fib z argumentem 7 1
Liczba wywołań fib z argumentem 8 1
|
Liczba wywołań fib z argumentem 0 4181
Liczba wywołań fib z argumentem 1 6765
Liczba wywołań fib z argumentem 2 4181
Liczba wywołań fib z argumentem 3 2584
Liczba wywołań fib z argumentem 4 1597
Liczba wywołań fib z argumentem 5 987
Liczba wywołań fib z argumentem 6 610
Liczba wywołań fib z argumentem 7 377
Liczba wywołań fib z argumentem 8 233
Liczba wywołań fib z argumentem 9 144
Liczba wywołań fib z argumentem 10 89
Liczba wywołań fib z argumentem 11 55
Liczba wywołań fib z argumentem 12 34
Liczba wywołań fib z argumentem 13 21
Liczba wywołań fib z argumentem 14 13
Liczba wywołań fib z argumentem 15 8
Liczba wywołań fib z argumentem 16 5
Liczba wywołań fib z argumentem 17 3
Liczba wywołań fib z argumentem 18 2
Liczba wywołań fib z argumentem 19 1
Liczba wywołań fib z argumentem 20 1
|
Ze względu na konstrukcję metody rekurencyjnej, liczba wielokrotnych wywołań metody z tym samym argumentem i , dla i =1,2...n, jest liczbą Fibonacciego: F(n-i+1) ! Zatem przy dużych n bardzo dużo czasu tracone jest na powtarzanie tych samych wywołań i zwracanie tych samych wyników.
Zadanie do samodzielnego wykonania.
Napisać iteracyjną wersję metody obliczającej wyrazy ciągu Fibonacciego.
Za pomocą znanej nam już klasy QTimer porównać czas obliczeń wersji rekursywnej
i iteracyjnej.
8. Niezmienniki pętli iteracyjnych
W
tym podpunkcie zajmiemy się krótko zagadnieniem,
które jest istotne m.in. w dowodzeniu poprawności algorytmów. Ta
problematyka jest szczegółowo i znacznie bardziej formalnie
przedstawiona w ramach kursów związanych bezpośrednio z algorytmami i
strukturami danych. Tutaj w sposób możliwie najmniej formalny
zwrócona zostanie uwaga na pojęcie niezmienników pętli iteracyjnych i
to
raczej pod kątem lepszego rozumienia działania (czy nawet
sprawniejszego
formułowania) pętli iteracyjnych niż dowodzenia ich poprawności.
Rozpatrzymy najpierw pętlę while (jak już wiemy - pętle for łatwo sprowadzić
do pętli while), po czym zobaczymy w jaki sposób, mozna bezpośrednio formułowac
niezmienniki dla pętli for.
Ogólną postać pętli while można zapisać jako:
inicjacja_zmiennych_używanych_w_pętli
while (warunek_kontynuacji_pętli) {
ciało_pętli
}
gdzie przez ciało_pętli rozumiemy instrukcje wykonywane w pętli
Niezmiennikiem pętli
while nazywamy relację pomiędzy
wartościami zmiennych programu, która jest prawdziwa tuż przed rozpoczęciem
pętli, przed każdym wykonaniem i po każdym wykonaniu ciala pętli w kolejnych
iteracjach
oraz zaraz po zakończeniu pętli iteracyjnej;
przy czym przynajmniej niektóre z wartości zmiennych, uczestniczących w tej
relacji, zmieniają się w trakcie wykonywania iteracji pętli.
Jeśli przez K oznaczymy wyrażenia-warunek kontynuacji pętli, a przez N -
wyrażenie-niezmiennik pętli, to prawidłowa konstrukcja pętli powinna wyglądać następująco:
// N jest prawdziwe
while (K) {
// N i K jest prawdziwe
ciało pętli
// N jest prawdziwe
}
// N jest prawdziwe i jednocześnie K nie jest prawdziwe
przy czym instrukcje ciała pętli powinny zapewniać (w którymś momencie) zanegowanie
wyrażenia K (po to, by pętla mogła zakończyć działanie).
Uwaga: w pętli takiej może zdarzyć się, że od początku K nie jest prawdziwe
(wtedy pętla nie wykona się ani razu, ale powinny zachodzić pierwszy i ostatni
warunki podane w komentarzach).
Spójrzmy na przykład znajdowania minimalnego elementu tablicy n liczb całkowitych.
static int getMin(int[] a) {
int n = a.length;
int vmin = a[0];
int i = 1;
while (i < n) {
if (a[i] < vmin) vmin = a[i];
i++;
}
return vmin;
}
Zauważmy, że po zakończeniu pętli chcemy, by spełniony był warunek:
wartość zmiennej vmin jest wartością minimalnego elementu tablicy a czyli minimalną wartością spośród wartości zmiennych a[0], a[1], ... a[n-1].
Inaczej mówiąc wartością wyrażenia (zapisanego w pseudokodzie):
vmin == minimum (a[0], ... ,a[n-1])
winno być true.
Na tej podstawie możemy łatwo wydedukować niezmiennik (który - w tym
przypadku - bezpośrednio pomaga nam zbudować algorytm działania pętli) .
Niezmiennik: dla każdego i = 1, ... n : vmin == minimum ( a[0], .., a[i-1] )
.
Miejsca w którym warunek ten powinien być spełniony pokazano poniżej
za pomocą komentarza N z dodatkową liczbą 0, 1, 2, 3 - rozróżniającą umiejscowienie
warunku:
static int getMin(int[] a) {
int n = a.length;
int vmin = a[0];
int i = 1;
// N0
while (i < n) {
// N1
if (a[i] < vmin) vmin = a[i];
i++;
// N2
}
// N3
return vmin;
}
Niezmiennik ten wyraża określoną relację pomiędzy zmiennymi vmin, a oraz i
. Zwróćmy uwagę, że niektóre z tych zmiennych (vmin oraz i) zmieniają swoje
wartości w trakcie iteracji, a jednak wartość wyrażenia stanowiącego niezmiennik
powinna być w każdej iteracji taka sama (stąd nazwa niezmiennik!).
Jeżeli
możemy teraz wykazać, że wybrany jako niezmiennik warunek jest prawdziwy
we wszystkich pokazanych miejscach, pętla kończy działanie, a po jej zakończeniu
z niezmiennika możemy wyprowadzić zamierzony wynik działania pętli, to -
nasza pętla jest poprawna (gwoli ścisłości: trzeba jeszcze zapewnić spełnienie
jakichś warunków początkowych, w naszym przykładzie będzie to n > 0).
Faktycznie, przed wejściem w pętlę, i=1, vmin = a[0], zatem vmin jest minimum
z (a[0]...a[i-1]), bo zbiór ten zawiera tylko jedną liczbę a[0]. Wobec tego
w miejscu N0 niezmiennik jest prawdziwy. Jeżeli w miejscu N0 niezmiennik
jest prawdziwy, to w pierwszej iteracji - w miejscu N1 również będzie prawdziwy
(bo wyrażenie stanowiące warunek kontynuacji nie zmienia wartości i, vmin, oraz elementów tablicy a).
Dalej możemy łatwo wykazać że, jeżeli w jakiejkolwiek iteracji niezmiennik
jest prawdziwy w miejscu N1, to będzie również prawdziwy w miejscu N2. Weźmy
i-tą iterację. W miejscu N1 zachodzi vmin ==
minimum (a[0], ... a[i-1]). Następnie wartość a[i] porównywana jest z wartością vmin, jeśli jest mniejsza, to vmin = a[i], w przeciwnym
razie minimum się nie zmienia i w obu przypadkach w miejscu N2 (po zwiększeniu i o 1) znowu zachodzi vmin == minimum(a[0],
... . a[i-1]).
Jeśli niezmiennik jest prawdziwy w miejscu N2,
to - przy kontynuacji pętli - jest również prawdziwy w miejscu N1. Natomiast
gdy warunek kontynuacji nie jest spełniony - prawdziwość w N2 implikuje prawdziwość
niezmiennika w N3.
Pętla na pewno skończy działanie, bowiem w każdej iteracji i jest zwiększane, aż osiągnie wartość n.
W miejscu N3 wyrażenie stanowiącc niezmiennik bezpośrednio określa poprawność
zamierzonego wyniku działania pętli: otrzymaliśmy minimum ze wszystkich elementów
tablicy.
Zobaczmy więc: niezmiennik dobraliśmy tak by "prowadził nas" do końcowego wyniku.
Byłoby raczej bez sensu użyć tu jakiegoś innego niezmiennika.
Nie zawsze
uda się osiągnąć tak bezpośredni efekt, ale na podstawie dobrze dobranego
niezmiennika pętli można znacznie sobie ułatwić stworzenie poprawnego algorytmu
rozwiązania jakiegoś problemu.
No, dobrze, ale czy zawsze musimy przekształcać pętle for do pętli while - by poprowadzić rozumowanie za pomocą niezmienników?
Niekoniecznie. Bardzo często w pętlach for, w których mamy do czynienia z
prostą zmianą licznika iteracji możemy tego nie robić.
Ze względu na konstrukcję takich pętli (przypomnijmy: inicjacja licznika
wykonywana jest raz, warunek kontynuacji sprawdzany jest przed każdym wykonaniem
iteracji, a wyrażenie zmieniające licznik wykonywane jest po wykonaniu instrukcji
pętli) niezmiennik można "umieścić" na początku każdej iteracji oraz po pętli:
for (.....) {
// Niezmiennik
instrukcje pętli
}
// Niezmiennik
W naszym przypadku poszukiwania minimum z elementów tablicy moglibyśmy zapisać:
static int getMin(int[] a) {
int vmin = a[0];
for (int i=1; i < a.length; i++) {
// NIEZMIENNIK: vmin == minimum (a[0],.. a[i-1])
if (a[i] < vmin) vmin = a[i];
}
// NIEZMIENNIK: vmin == minimum (a[0],.. a[i-1])
return vmin;
}
Łatwo zobaczyć, że niezmiennik jest prawdziwy w każdej iteracji oraz po zakończeniu pętli.
9. Podsumowanie
W tekście omówiono:
- opakowanie typów prostych i autoboxing,
- operacje
na bitach,
- działania matematyczne na liczbach rzeczywistych,
- posługiwanie się datami,
- formatowanie liczb i dat,
- proste algorytmy sortowania i wyszukiwania,
- pojęcie rekurencji, która pozwala niektóre algorytmy zapisywać w bardzo
naturalny i intuicyjny sposób
Kończące
wykład kilka słów o niezmiennikach pętli iteracyjnych powinno wspomóc
prawidłowe ich programowani i konstruowanie poprawnych algorytmów.