import javax.swing.*;
class QTimer {
private final long start;
public QTimer() {
System.gc();
start = System.currentTimeMillis();
}
public long getElapsed() {
return System.currentTimeMillis() - start;
}
}
public class Test {
public static void main(String args[]) throws InterruptedException {
int n = Integer.parseInt(JOptionPane.showInputDialog("Liczba operacji"));
// String
QTimer t = new QTimer();
String strA = "";
for (int i = 1; i <= n; i++) strA += "A";
long etA = t.getElapsed();
System.out.println("String operator +; Czas: " + etA + " ms");
// StringBuffer
t = new QTimer();
StringBuffer sb = new StringBuffer();
for (int i = 1; i <= n; i++) sb.append("B");
sb.toString();
long etB = t.getElapsed();
System.out.println("StringBuffer append. Czas: " + etB + " ms");
System.out.println("Wykonano " + n + " operacji.");
System.out.println("Relacja String/StringBuffer = " + (double) etA/etB);
}
}
Możliwy wynik:FileInputStream in = new FileInputStream("Program1.java"); // gdy nie podano ściezki,
FileOutputStream out = new FileOutputStream("Program2.java"); // pliki w katalogu roboczym aplikacji
lub
FileInputStream in = new FileInputStream("C:/Test/Program1.java"); // z podaną ściezką
FileOutputStream out = new FileOutputStream("C:\\Test\\Program2.java"); // uwaga na symbol "escape"! import java.io.*;
import static javax.swing.JOptionPane.*;
public class CopyFile {
public static void main(String[] args) {
FileInputStream in = null; // plik wejściowy
FileOutputStream out = null; // plik wyjściowy
try {
in = new FileInputStream("in1");
out = new FileOutputStream("out1");
int c;
while ((c = in.read()) != -1) out.write(c); // kopiowanie
} catch (ArrayIndexOutOfBoundsException exc) { // brak argumentu
System.out.println("Syntax: CopyFile in out");
System.exit(1);
} catch (FileNotFoundException exc) { // nieznany plik
System.out.println("Plik wejściowy nie istnieje.");
System.exit(2);
} catch (IOException exc) { // inny błąd wejścia- wyjścia
System.out.println(exc.toString());
System.exit(3);
} finally { // zawsze zamykamy pliki
try { // niestety close może zgłosić wyjatek kontrolowany - trzeba użyć try
if (in != null) in.close();
if (out != null) out.close();
} catch (IOException exc) {
System.out.println(exc.toString());
}
}
}
}
import java.io.*;
public class ReadBytesAsChars {
public static void main(String[] args) {
StringBuffer cont = new StringBuffer();
try {
FileInputStream in = new FileInputStream(args[0]);
int c;
while ((c = in.read()) != -1) cont.append((char) c);
in.close();
} catch(Exception exc) {
System.out.println(exc.toString());
System.exit(1);
}
String s = cont.toString();
System.out.println(s);
}
}
czyta
plik tekstowy i zapisuje jego zawartość w łańcuchu znakowym (String),
po czym wypisuje na konsoli ten łańcuch znakowy. Jeśli
przeczytaliśmy z
pliku zapisanego w Cp1250 następujący tekst:import java.io.*;
public class ReadByReader {
public static void main(String[] args) {
StringBuffer cont = new StringBuffer();
try {
FileReader in = new FileReader(args[0]);
int c;
while ((c = in.read()) != -1) cont.append((char) c);
in.close();
} catch(Exception exc) {
System.out.println(exc.toString());
System.exit(1);
}
String s = cont.toString();
System.out.println(s);
}
}
// tu powstaje związek z fizycznym źródłem
FileReader fr = new FileReader("plik.txt");
// tu dodajemy "opakowanie", umożliwiające buforowanie
BufferedReader br = new BufferedReader(fr);
//... teraz wszelkie odwołania czytania itp. kierujemy do obiektu br
Dodatkowo
w klasie BufferedReader zdefiniowano wygodną metodę czytania wierszy
pliku: try {
String line;
FileReader fr = new FileReader(fname); // fname jest nazwą pliku
BufferedReader br = new BufferedReader(fr);
while ((line = br.readLine()) != null) { // kolejny wiersz pliku: metoda readLine
...
// tu robimy coś z wierszami pliku
}
br.close(); // zamknięcie pliku
} catch (IOException e) {
e.printStackTrace();
} i
jego realizacja na przykładzie poprzedniego programu:import java.io.*;
public class BuffRead {
public static void main(String[] args) {
try {
BufferedReader in = new BufferedReader(
new FileReader("in1"));
StringBuffer sb = new StringBuffer();
String line;
while ((line = in.readLine()) != null) {
sb.append(line).append('\n');
}
in.close();
System.out.println(sb);
} catch (IOException exc) {
exc.printStackTrace();
}
}
}Naturalnie,
do czytania plików tekstowych zapisanych w domyślnej stronie kodowej
nieco wygodniejszy jest Scanner.import java.io.*;
import java.util.*;
public class ScanRead {
public static void main(String[] args) {
StringBuffer sb = new StringBuffer();
try {
Scanner scan = new Scanner(new File("in1"));
while (scan.hasNextLine()) {
sb.append(scan.nextLine()).append('\n');
}
scan.close();
System.out.println(sb);
} catch (FileNotFoundException exc) {
exc.printStackTrace();
}
}
}Ale
do zapisywania plików musimy używać klas strumieniowych.public class BuffTextFileCopy {
public static void main(String[] args) {
BufferedReader in = null;
BufferedWriter out = null;
try {
in = new BufferedReader(new FileReader("in1"));
out = new BufferedWriter(new FileWriter("out1"));
String line;
while ((line = in.readLine()) != null) {
out.write(line);
out.newLine();
}
} catch (IOException exc) {
exc.printStackTrace();
} finally {
try {
if (in != null) in.close();
if (out != null) out.close();
} catch(IOException exc) {
exc.printStackTrace();
}
}
}
}Przy
zapisie buforowanych plików ważne jest, aby po zakończeniu zapisu
zawsze je zamykać. W przeciwnym razie część (lub całość) informacji
może pozostać w buforze i nie trafić do pliku. Dlatego zamknięcie
plików umieściliśmy w klauzuli finally, która wykona się zawsze
bez względu na to czy powstaną jakieś wyjątki czy nie.File file = new File("tekst.txt");
// załóżmy, że plik jest zapisany w stronie kodowej ISO8859-2
// normalnie skaner dokonuje dekodowania do domyślnej strony kodowej na danej platformie
// jeśli nie jest to ISO8859-2, to plik nie zostanie właściwie odczytany
// możemy jednak podać z jakiej strony kodowej ma być dekodowanie
Scanner scan = new Scanner(file, "ISO8859-2");
// i teraz zawartość pliku będzie włąsciwie przekształcona do Unicodu
Wybrane
metody klasy String | |
| char | charAt(int
index) Zwraca znak na pozycji, oznaczonej indeksem index. Pierwsza pozycja ma indeks 0. |
| int | compareTo(String anotherString) Porównuje dwa napisy: ten (this) na rzecz którego użyto metody oraz przekazany jako argument. Metoda zwraca 0, gdy napisy są takie same. Jeżeli się różnią, to - gdy występują w nich różne znaki - zwracana jest wartość: this.charAt(k) - anotherString.charAt(k), gdzie k - indeks pierwszej pozycji, na której występuje różnica znaków. Jeżeli długość napisów jest różna (a znaki napisów są takie same w części określanej przez dlugośc krótszego napisu) - zwracana jest różnica dlugości: this.length() - anotherString.length(). Oznacza to, że wynik jest ujemny, gdy ten (this) łańcuch poprzedza leksykograficznie (alfabetycznie) argument (anothetString) oraz dodatni - gdy ten łańcuch jest leksykograficznie większy od argumentu. |
| int | compareToIgnoreCase(String str) Porównuje leksykograficznie dwa napisy, bez rozróżnienia małych i wielkich liter. |
| boolean | endsWith(String suffix) Zwraca true, gdy napis kończy się łańcuchem znakowym podanym jako argument, false - w przeciwnym razie. |
| boolean | equals(Object
anObject) Zwraca true gdy anObject jest takim samym co do zawartości napisem jak ten napis; w każdym innym przypadku - zwraca false. |
| boolean | equalsIgnoreCase(String
anotherString) J.w. - ale bez rozróżniania małych i wielkich liter. |
| int | indexOf(String str) Zwraca indeks pozycji pierwszego wystąpienia w danym napisie napisu podanego jako argument str; jeżeli str nie występuje w tym napisie - zwraca -1 |
| int | indexOf(String str, int fromIndex) Poszukuje pierwszego wystąpienia napisu str poczynając od pozycji oznaczonej przez indeks fromIndex; zwraca indeks pozycji na której zaczyna się str lub - 1 gdy str nie występuje w tym napisie. Jeśli fromIndex jest ujemne lub zero - przeszukiwany jest cały napis; jeśli fromIndex jest większe od długości napisu - zwracane jest -1. |
| int | lastIndexOf(String str) Jak indexOf - ale zwracany jest indeks pozycji ostatniego wystąpienia. |
| int | lastIndexOf(String str, int
fromIndex) J.w. Uwaga: metody indexOf i lastIndexOf mają również swoje wersje dla argumentów - znaków (typu char). |
| int | length() Zwraca długość napisu. |
| String | replace(char oldChar, char
newChar) Zwraca nowy obiekt klasy String, w którym zastąpiono wszystkie wystąpienia znaku oldChar na znak newChar. |
| String | replace(CharSequence target,
CharSequence replacement) Zwraca nowy obiekt klasy String, w którym zastąpiono wszystkie wystąpienia podnapisu target na napis replacement. |
| String | replaceAll(String regex, String
replacement) Zwraca nowy obiekt klasy String, w którym zastąpiono wszystkie wystąpienia podnapisów pasujących do wzorca podanego przez wyrażenie regularne regex na napis target. |
| String | split(String regex) Rozkłada napis na jego podnapisy rozdzielone dowolnymi separatorami, pasującymi do wzorca regex. |
| boolean | startsWith(String prefix) Zwraca true, gdy napis zaczyna się podanym jako argument łańcuchem znakowym; false - w przeciwnym razie. |
| boolean | startsWith(String prefix, int
toffset) Zwraca true, gdy podłańcuch tego łańcucha znakowego zaczynający się na pozycji o indeksie toffset zaczyna się napisem prefiks; zwraca false w przeciwnym razie, lub gdy toffset jest < 0 albo większy od dlugości napisu. |
| String | substring(int beginIndex) Zwraca podłańcuch tego łańcucha znakowego zaczynający się na pozycji o indeksie beginIndex (do końca łańcucha). |
| String | substring(int beginIndex, int
endIndex) Zwraca podłańcuch tego łańcucha jako nowy obiekt klasy String. Podłańcuch zaczynay się na pozycji o indeksie beginIndex, a kończy (uwaga!) - na pozycji o indeksie endIndex-1. Długość podlańcucha równa jest endIndex - beginIndex. |
| char[] | toCharArray() Znaki łańcucha -> do tablicy znaków (typ char[]). |
| String | toLowerCase() Zamiana liter na małe. |
| String | toUpperCase() Zamiana liter na duże. |
| String | trim() Usuwa znaki spacji, tabulacji, końca wiersza itp. tzw. biale znaki z obu końców łańcucha znakowego. Zwraca wynik jako nowy łańcuch. |
| static String | valueOf(boolean
b) Zwraca wartość boolowską (boolean) jako napis (String). |
| static String | valueOf(char c) Zwraca wartość typu char jako napis. |
| static String | valueOf(char[]
data) Zwraca napis złożony ze znakow tablicy. |
| static String | valueOf(double
d) Zwraca znakową treprezentację liczby typu double. |
| static String | valueOf(float f) Zwraca znakową treprezentację liczby typu float. |
| static String | valueOf(int
i) Zwraca znakową treprezentację liczby typu int. |
| static String | valueOf(long
l) Zwraca znakową reprezentację liczby typu long. |
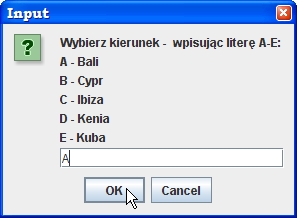 Problem: napisać program, który
prosi użytkownika o wybranie jednej z możliwych
wycieczek oznaczanych dużymi literami A, B, C ..., po czym podaje cenę
tej
wycieczki. Miejsca docelowe wycieczek oraz ich ceny mają być zapisane w
tablicach, np.:
Problem: napisać program, który
prosi użytkownika o wybranie jednej z możliwych
wycieczek oznaczanych dużymi literami A, B, C ..., po czym podaje cenę
tej
wycieczki. Miejsca docelowe wycieczek oraz ich ceny mają być zapisane w
tablicach, np.:import static javax.swing.JOptionPane.*;
public class Wycieczki {
public static void main(String[] args) {
String[] dest = { "Bali", "Cypr", "Ibiza", "Kenia", "Kuba" };
double[] price = { 5000, 2500, 2800, 4500, 6000 };
String msg = "Wybierz kierunek - " +
" wpisując literę A-"+ (char) ('A'+dest.length-1)+ ":\n";
for (int i=0; i < dest.length; i++)
msg += (char) ('A' + i) + " - " + dest[i] + '\n';
String res;
while ((res = showInputDialog(msg)) != null) {
if (res.length() == 1) {
int i = res.toUpperCase().charAt(0) - 'A';
if (i < 0 || i > dest.length -1) continue;
showMessageDialog(null, dest[i] + " - cena: " + price[i]);
}
}
}
}
package toc;
public class Toc {
private String doc; // przekazany dokument
private String toc = ""; // wynikowy spis treści
// separator końca wiersza; ponieważ jest zależny od systemu
// pobieramy go jako wartość tzw. właściwości systemowej
private final String ls = System.getProperty("line.separator");
public Toc(String doc) { // Konstruktor
this.doc = doc;
}
public String getToc() throws IllegalStateException {
int p = 0; // pozycja od której zaczynamy szukanie "<h2>"
while ((p = doc.indexOf("<h2>", p)) != -1) { // dopóki są "<h2>"
// poszukajmy znacznika zamykającego
// end jest indeksem pozycji na której on występuje
int end = doc.indexOf("</h2>", p+4);
// jeżeli go nie ma ...
if (end == -1) throw new IllegalStateException("Invalid document structure");
// w przeciwnym razie: wyłuskujemy nagłówek
toc += doc.substring(p+4, end) + ls; // ls - separator wierszy
p = end + 5; // i przesuwamy pozycję od której będziemy dalej szukać
}
return toc;
}
}
Uwaga: w przypadku braku zamykającego znacznika </h2>
zgłaszany
jest wyjątek IllegalStateException. Jest on pochodny od klasy
RuntimeExecption, więc wołający metodę getToc() może go obsługiwać bądź
nie. Mimo to w celach dokumentacyjnych wymieniono wyjątek w
klauzuli throws. Ta wersja programu jest oczywiście niedoskonała
- nie obsługuje przypadku wadliwej struktury
dokumentu, gdy znacznik <h2> występuje pomiędzy
znacznikami
<h2>
i </h2>.import java.io.*;
import java.util.*;
import static javax.swing.JOptionPane.*;
public class MainToc {
public static void main(String[] args) throws Exception {
Scanner fnameScan = new Scanner(showInputDialog("in out ?"));
File in = new File(fnameScan.next());
BufferedWriter out = new BufferedWriter(new FileWriter(fnameScan.next()));
Scanner inScan = new Scanner(in);
StringBuffer sb = new StringBuffer();
try {
while (inScan.hasNextLine())
sb.append(inScan.nextLine());
inScan.close();
Toc toc = new Toc(sb.toString());
out.write(toc.getToc());
} finally {
out.close();
}
}
}Nazwy
plików sa pobierane z dialogu wejściowego. Skaner fnameScan
wyróżnia je z tekstu wpisanego w dialogu, skaner inScan czyta wiersze
pliku wejściowego i tworzy z nich jeden długi tekst w StringBufferze.
Tekst ten jest przekazywany klasie Toc, a otrzymany wynikowy spis
treści zapisywany do pliku wyjściowego. Warto zwrócić uwagę na obsługę
wyjatków. Metoda main wymienia klasę Exception w klauzuli throws, co
zwalnia z ich obsługi w kodzie. Mimo to, zastosowano blok
try,
tym razem bez żadnego catch, ale za to z finally, po to by zapewnić
zamknięcie pliku wyjściowego w każdej sytuacji (czy powstał jakiś
wyjątek czy nie).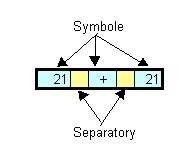
String expr = "21 + 21"; StringTokenizer st = new StringTokenizer(expr);Ta postać konstruktora zaklada domyślnie, że separatorami są znaki z następujacego zestawu
" \t\n\r\f" (czyli znak
spacji, tabulacji, przejścia do nowego wiersza, powrotu karetki,
nowej strony - tzw. "Białe znaki"). W tym przypadku symbolami będą ciągi znaków, które nie
zawierają
żadnego z wymienionych separatorów.int n = st.countTokens(); // n = 3
String s1 = st.nextToken(); // napis "21" String s2 = st.nextToken(); // napis "+" String s3 = st.nextToken(); // napis "21"Gdy nie ma już symboli "do zwrotu" - wywołanie nextToken() spowoduje powstanie wyjątku NoSuchElementException.
while (st.hasMoreTokens()) {
Sring s = st.nextToken();
// ... tu coś robimy z s
}
import java.util.*;
import static javax.swing.JOptionPane.*;
public class Oper {
public static void main(String[] args) {
String normalQuest = "Liczba1 op Liczba2", // normalny komunikat
errorQuest = "Wadliwe dane. Popraw.\n", // komunikat w przypadku błędu
quest = normalQuest;
String expr = ""; // wyrażenie do obliczenia
while ((expr = showInputDialog(quest, expr)) != null) {
StringTokenizer st = new StringTokenizer(expr);
if (st.countTokens() != 3) { // jeżeli za mało lub za dużo symboli
quest = errorQuest;
continue;
}
String snum1 = st.nextToken(), // pierwsza liczba (napisowo)
sop = st.nextToken(), // symbol operatora
snum2 = st.nextToken(); // druga liczba (napisowo)
int num1 = 0, num2 = 0, res = 0; // liczbt do obliczeń i wynik
try {
num1 = Integer.parseInt(snum1);
num2 = Integer.parseInt(snum2);
} catch (NumberFormatException exc) { // jeżeli napisy nie są liczbami całkowitymi
quest = errorQuest; // komunikat o błędzie
continue;
}
char op = sop.charAt(0);
// jezeli napis oznaczający operator za długi (np. ktoś wprowadził +*)
// lub gdy w ilorazie dzialnik jest zerem - błąd
if (sop.length() != 1 || (op == '/' && num2 == 0)) {
quest = errorQuest;
continue;
}
switch (op) {
case '+' : res = num1 + num2; break;
case '-' : res = num1 - num2; break;
case '*' : res = num1 * num2; break;
case '/' : res = num1 / num2; break;
default: { // wadliwy operator
quest = errorQuest;
continue;
}
}
showMessageDialog(null, "Wynik = " + res);
quest = normalQuest;
expr = ""; // w kolejnym dialogu inicjalny tekst ma być pusty
}
}
}Uwaga:
w programie zastosowano wersję metody showInputDialog, w której drugi
argument oznacza inicjalny napis umieszczony w polu tekstowym dialogu.
Normalnie będzie to pusty tekst, ale w przypadku błędu umieścimy w polu
tekstowym błędny napis, tak aby od razu można go było poprawić.import java.util.*;
import static javax.swing.JOptionPane.*;
public class Oper1 {
public static void main(String[] args) {
String normalQuest = "Liczba1 op Liczba2",
errorQuest = "Wadliwe dane. Popraw.\n" + normalQuest,
quest = normalQuest,
expr = "";
while ((expr = showInputDialog(quest, expr)) != null) {
int res;
try {
StringTokenizer st = new StringTokenizer(expr);
int num1 = Integer.parseInt(st.nextToken());
String sop = st.nextToken();
int num2 = Integer.parseInt(st.nextToken());
if (sop.length() != 1 || st.hasMoreTokens())
throw new IllegalArgumentException();
switch (sop.charAt(0)) {
case '+' : res = num1 + num2; break;
case '-' : res = num1 - num2; break;
case '*' : res = num1 * num2; break;
case '/' : res = num1 / num2; break;
default : throw new IllegalArgumentException();
}
} catch (Exception exc) {
quest = errorQuest;
continue;
}
showMessageDialog(null, "Wynik = " + res);
quest = normalQuest;
expr = "";
}
}
}import java.util.*;
public class Words {
private String[] words; // tablica slów
private String maxLenWord; // słowo o max długości
private String minLenWord; // słowo o minimalnej długości
// Konstruktor
public Words(String txt) throws IllegalArgumentException {
// Sprawdzamy czy przekazano właściwy argument
if (txt == null)
throw new IllegalArgumentException("Wadliwy argument konstruktora Words: null");
// Uwzględniamy bogaty zestaw separatorów słów
StringTokenizer st = new StringTokenizer(txt, " \t\n\r\f.,:;()[]\"'?!-{}");
int n = st.countTokens(); // ile słów?
if (n == 0)
throw new IllegalArgumentException("Wadliwy argument konstruktora Words: napis nie zawiera słów");
words = new String[n]; // utworzenie tablicy słów
words[0] = st.nextToken(); // pierwsze słowo
int maxL = words[0].length(), // max i min długość (na razie = długości pierwszego słowa)
minL = maxL;
int i = 1; // kolejny indeks w tablicy
while (st.hasMoreTokens()) { // dopóki są slowa
String s = st.nextToken();
int len = s.length();
if (len > maxL) { // maksymalna długość ?
maxL = len;
maxLenWord = s;
}
if (len < minL) { // minimalna długość ?
minL = len;
minLenWord = s;
}
words[i++] = s; // slowo -> do tablicy; zwiększenie indeksu
}
}
// Zwraca liczbę słów
public int getWordsCount() {
return words.length;
}
// Zwraca i-te słowo (liczymy od 1)
// jeśli podano wadliwy indeks - zwraca null
public String getWord(int i) {
return (i < 1 || i > words.length) ? null : words[i-1];
}
// Zwraca tablicę slów
public String[] getWords() {
return words;
}
// Zwraca slowo o max długości
public String getMaxLenWord() {
return maxLenWord;
}
// Zwraca slowo o min długości
public String getMinLenWord() {
return minLenWord;
}
}I
klasa testująca:import static javax.swing.JOptionPane.*;
public class TestWords {
public static void main(String[] args) {
String txt;
while ((txt = showInputDialog("Wpisz tekst")) != null) {
Words w = new Words(txt);
int n = w.getWordsCount();
System.out.println("Liczba słów: " + n);
System.out.println("Kolejne slowa: ");
for (int i=1; i <= n; i++) System.out.println(w.getWord(i));
int iw = Integer.parseInt(showInputDialog("Podaj numer słowa:"));
System.out.println("Słowo o numerze " + iw + ": " + w.getWord(n+1));
System.out.println("Kolejne slowa: ");
String[] words = w.getWords();
for (String wrd : words) System.out.println(wrd);
System.out.println("Najdluższe słowo: " + w.getMaxLenWord());
System.out.println("Najkrótsze słowo: " + w.getMinLenWord());
}
}
}| Tekst txt | Separator sep | StringTokenizer st = new StringTokenizer(txt, sep) | String[] s = txt.split(sep) | |||
| Liczba symboli: st.countTokens() | Wyróżnione symbole: st.nextToken() | Liczba symboli: s.length | Wyróżnione symbole: s[i] | |||
| 1 | "ala ma kota i psa" | " " | 5 | 0: Ala 1: ma 2: kota 3: i 4: psa | 5 | 0: Ala 1: ma 2: kota 3: i 4: psa |
| 2 | "ala ma kota i psa" | " " | 5 | 0: Ala 1: ma 2: kota 3: i 4: psa | 7 | 0: Ala 1: ma 2: kota 3: 4: i 5: 6: psa |
| 3 | "Pierwszy.Drugi.Trzeci" | "." | 3 | 0: Pierwszy 1: Drugi 2: Trzeci | 0 | |
String[] s = txt.split(" +");da w wyniku tablicę wszystkich podnapisów napisu txt rozdzielonych co najmniej jedną spacją.String[] s = txt.split("\\."); uzyskamy tablicę podnapisów napisu txt rozdzielonych kropką.| $ | ^ | . | * | |
| + | ? | [ | ] | |
| ( | ) | { | } | \ |
import java.util.regex.*;
public class Sample1 {
public static void main(String[] args) {
// Wzorzec: jedno lub więcej wystąpień dowolnej cyfry
String regex = "[0-9]+";
// Kompilacja wzorca
Pattern pattern = Pattern.compile(regex);
// Tekst wejściowy
String txt = "196570";
// Uzyskanie matchera
Matcher matcher = pattern.matcher(txt);
// Czy tekst pasuje do wzorca?
boolean match = matcher.matches();
System.out.println("Tekst: " + txt + '\n' +
(match ? " " : " NIE ") + "pasuje do wzorca: " + regex);
// Nowy tekst wejściowy
txt = "123 996";
// reset matchera "zeruje" jego stany i pozwala też na podanie nowego tekstu
matcher.reset(txt);
match = matcher.matches();
System.out.println("Tekst: " + txt + '\n' +
(match ? " " : " NIE ") + "pasuje do wzorca: " + regex);
}
}wynik:iimport java.util.regex.*;
public class Sample2 {
public static void main(String[] args) {
// Wzorzec: jedno lub więcej wystąpień dowolnej cyfry
String regex = "[0-9]+";
// Tekst wejściowy
String txt = "123 996";
System.out.println("Tekst: \n" + "'" + txt + "'" +
"\nWzorzec: " + "'" + regex + "'");
// Kompilacja wzorca
Pattern pattern = Pattern.compile(regex);
// Uzyskanie matchera
Matcher matcher = pattern.matcher(txt);
String result = ""; // do prezentacji wyników wyszukiwania
// Zastosujemy metodę find()
// Jej wywołanie zwraca true po znalezieniu pierwszego
// pasującego do wzorca podłańcucha w tekście.
// Kolejne wywołania pozwalają wyszukiwać kolejne pasujące podłańcuchy;
// wynik false oznacza, że w tekście nie ma pasujących podłańcuchów
while (matcher.find()) {
result += "\nDopasowano podłańcuch '" +
matcher.group() + "'" + // group() zwraca ostatni dopasowany tekst
"\nod pozycji " + matcher.start() + // start() zwraca jego poczatkową pozycję
"\ndo pozycji " + matcher.end(); // end() zwraca pozycję po ostatnim dopasowanym znaku
}
if (result.equals("")) result = "Nie znaleziono żadnego podnapisu " +
"pasującego do wzorca";
System.out.println(result);
}
}wynik:import java.util.regex.*;
public class Sample3 {
public static void main(String[] args) {
// Wzorzec:
// jedno lub więcej wystąpień dowolnej cyfry (grupa, bo w nawiasach)
// po czym jeden lub więcej białych znaków
// po czym jedna lub więcej liter Unicode (grupa 2, w nawiasach)
// po czym jeden lub więcej białych znaków
// po czym dowolna liczba całkowita > 1 (grupa 3, w nawiasach)
String regex = "([0-9]+)\\s+(\\p{L}+)\\s+([1-9][0-9]*)";
// Tekst wejściowy
String txt = "1111 Odkurzacz 20";
System.out.println("Tekst: " + "'" + txt + "'" +
"\nWzorzec: " + "'" + regex + "'");
// Kompilacja wzorca
Pattern pattern = Pattern.compile(regex);
// Uzyskanie matchera
Matcher matcher = pattern.matcher(txt);
// Dopasowanie tekstu
boolean isMatching = matcher.matches();
if (isMatching) {
int n = matcher.groupCount(); // ile jest grup
for (int i = 1; i <=n; i++) {
String grupa = matcher.group(i); // pobranie zawartości i-ej grupy (numeracja od 1)
System.out.println("Grupa " + i +
" = '" + grupa + "'");
}
} else System.out.println("Tekst nie pasuje do wzorca");
}
}wynik:public class Sample4 {
public static void main(String[] args) {
// ogólny wzorzec separatorów do wyróżniania słów:
// separatorem jest 1 lub więcej "białych znaków" lub znaków interpunkcji
String regex = "[\\s\\p{Punct}]+";
// Tekst wejściowy
String txt = "Ala(11), kot,; pies-1 <kot2>[mrówka]";
// Kompilacja wzorca
Pattern pattern = Pattern.compile(regex);
String[] words = pattern.split(txt); // inaczej wołane niż split() z klasy String
System.out.println("Liczba wyróżnionych słów: " + words.length);
for (String w : words) {
System.out.println(w);
}
}
}wynik:import java.io.*;
import java.util.*;
import java.util.regex.*;
public class Sample5 {
public static void main(String[] args) throws Exception {
// Usuniemy z tekstu z pliku wszystkie komentarze jednowierszowe
// (zaczynające się od dwóch ukosników - składnia jak w Javie)
// wynik zapiszemy do innego pliku
Scanner in = new Scanner(new File("test1.txt")); // skaner dla pliku wejściowego
BufferedWriter out = new BufferedWriter(
new FileWriter("test2.txt")); // plik wyjściowy
// Wzorzec komentarzy:
// 0 lub więcej białych znaków, potem dwa ukosniki po których występują bądź nie inne znaki
String regex = "\\s*//.*";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher("");
try {
while (in.hasNextLine()) {
String line = in.nextLine();
matcher.reset(line);
String nline = matcher.replaceFirst(""); // komentarz zastępujemy pustym napisem
if (!nline.equals("")) { // wynikowy wiersz zapiszemy, jeśli nie jest pusty
out.write(nline);
out.newLine();
}
}
} finally {
in.close();
out.close();
}
}
}wynik:import java.util.regex.*;
public class Sample6 {
public static void main(String[] args) throws Exception {
// Zastąpimy w tekście wszystkie napisy:
// (liczbaCałkowita1:liczbaCałkowita2)
// na napisy:
// [liczbaCałkowita2:liczbaCałkowita1]
// czyli zmienimy nawiasy na kwadratowe i przestawimy miejscami liczby
// Wzorzec:
// nawias,liczba,dwukropek,liczba, nawias - uwaga nawias jest znakiem specjalnym - uzyjemy ukośnika
// zastosujemy dwie grupy: dla liczby1 i liczby2
String regex = "\\((\\d):(\\d)\\)";
Pattern pattern = Pattern.compile(regex);
String txt = "tekst 1 (ale) (2) (1:2) wołanie f() (3:4) (8:9)(10:11)";
Matcher matcher = pattern.matcher(txt);
// W wywołaniu metody replaceAll (i replaceFirst) podając tekst zastępujący
// możemy odwoływać się do zawartości grup wzorca.
// Wtedy tekst zastępujący będzie zawierał zawartość grupy z dopasowania wyrażenia.
// W tekście zastępującyn stosujemy znak $ z następującym po nim numerem grupy
// (a więc znak $ jest w tym kontekście zarezerwowany!)
// W naszym przykładzie mamy dwie grupy: pierwszą liczbę i drugą liczbę
// oznaczamy je $1 i $2
// zamiana nawiasów i przestawienie liczb
String newTxt = matcher.replaceAll("[$2:$1]");
System.out.println("Tekst przed zamianą:");
System.out.println(txt);
System.out.println("Tekst po zamianie:");
System.out.println(newTxt);
}
}| boolean | matches(String regex) Czy ten napis pasuje do wzorca regex? |
| String | replaceAll(String regex,
String replacement) Zastępuje każdy pasujący do regex podłańcuch tego napisu podanym napisem replacement. Uwaga: znaki $ i \ mają specjalne znaczenie (zob. przykład F z poprzedniego punktu). |
| String | replaceFirst(String regex,
String replacement) Zastępuje pierwszy pasujący do regex podłańcuch tego napisu podanym napisem replacement. Uwaga: j.w. |
| String[] | split(String regex) Rozklada ten napis wokół separatorów, które są podłancuchami pasującymi do wzorca |
| String[] | split(String regex,
int limit) j.w., ale nie więcej niż limit-1 razy |
import java.util.*;
import static java.lang.System.out;
public class Skaner1 {
// Metoda pomocnicza do okalania napisów apostrofami
public static String quote(String s) { return "'" + s + "'" + " "; }
public static void main(String[] args) {
// Zadanie: wyróżnić wszystkie napisy rozdzielone spacjami lub znakiem /
String txt = "1/2 /3/ 4";
// Separator?
// intuicyjnie jedno z: spacja lub znak /
String delim = "[ /]";
// Przy tworzeniu skanera od razu można ustalić separator
Scanner scan = new Scanner(txt).useDelimiter(delim);
out.println("Tekst : " + quote(txt) + " Separator: " + quote(delim));
// Ale wynik - podobnie jak w split() inny od oczekiwań
// ze względu na sposób działania machiny wyrażeń regularnych
// uzyskamy 5 symboli zamiast 4: '1' '2' '' '3' '' '4'
while (scan.hasNext()) out.print( quote(scan.next()) + " ");
// Aby uzyskać taki sam wynik jak w StringTokenizerze
// nalezy zastosować wyrażenie regularne: 1 lub więcej spacji lub znaków /
delim = "[ /]+";
// Uwaga: do nowego skanowania zawsze trzeba tworzyć nowys skaner (nawet jeśli tekst jest ten sam)
scan = new Scanner(txt).useDelimiter(delim);
out.println("\nTekst : " + quote(txt) + " Separator: " + quote(delim));
// uzyskamy 4 symbole : '1' '2', '3' '' '4'
while (scan.hasNext()) out.print( quote(scan.next()) + " ");
}
}
Wynik:import java.util.*;
public class Skaner2 {
public static void main(String[] args) {
// Zadanie: z napisu (np. jakiegoś dokumentu)
// wyróżnić nazwiska, imiona i daty urodzenia
// wstawione w odpowiednio opisane pola dokumentu
String txt = "LNAME: Kowalski FNAME: Jan BORN: 1980-12-01\n" +
"LNAME: Malinowski FNAME: Stefan BORN: 1950-01-15\n";
// Separator:
// dowolna z nazw pól LNAME: albo FNAME: albo BORN:
String delim = "(LNAME:)|(FNAME:)|(BORN:)";
Scanner scan = new Scanner(txt).useDelimiter(delim);
while(scan.hasNext()) {
String s = scan.next();
// Ponieważ wyłuskane symbole mogą na końcach zawierać białe znaki
// usuniemy je za pomocą metody trim() z klasy String
s = s.trim();
System.out.println( "'" + s + "'");
}
}
}
import java.util.*;
public class Skaner3 {
public static void main(String[] args) {
// Zadanie: zsumować wszystkie liczby całkowite występujące w tekście
String txt = "Wydano najpierw 20, a później 35.\n" +
"W kolejnym dniu zakupiono coś jescze za 1000";
// Separator:
// 1 lub więcej wystapień nie-cyfry
// można tu użyć klasy znaków \D, ale zapiszemy bardziej naocznie:
String delim = "[^0-9]+";
Scanner scan = new Scanner(txt).useDelimiter(delim);
int sum = 0;
while(scan.hasNextInt()) {
sum += scan.nextInt();
}
System.out.println("Tekst:\n" + txt + "\n\nSuma liczb: " + sum);
}
}import java.util.*;
public class Skaner4 {
public static void main(String[] args) throws Exception {
// Znane nam już zadanie z wyróżnieniem tytułow rozdziałów
// (napisy w znacznikach <h2> dokumentu html)
// w kilku linijkach kodu
// Będziemy wczytywać podany plik
Scanner fScan = new Scanner(new File("TypyOp.html"));
// Wyrażenie reg. do wyłuskania tekstu w znacznikach;
// - kwantyfikator jest wstrzęmiężliwy (znak ? po +) inaczej bylyby kłopoty
// - zastosujemy grupę (nawiasy), aby od razu mieć tekst bez okalających znaczników
String h2regex = "(?s)<h2>(.+?)</h2>";
// Metoda findWithinHorizon wyszukuje kolejne wystąpienie
// tekstu pasującego do wzorca (drugi arg 0 = limit wyszukiwania nieograniczony)
while(fScan.findWithinHorizon(h2regex, 0) != null) {
// Skaner może uzyskać Matcher przez odwolanie match()
// Od Matchera pobierzemy zawartość jedynej grupy
String title = fScan.match().group(1);
System.out.println(title);
}
fScan.close(); // zamykamy skaner i plik
}
}
import java.util.*;
public class Skaner5 {
public static void main(String[] args) {
// Zadanie: pobrać liczby rzeczywiste z tekstu
// uwzględniając format ich zapisu właściwy dla podanych lokalizacji
// Tekst ma postać: symbol_języka zapis_liczby_zgodny_z_lokalizacją ...
// zsumować wszystkie liczby
String txt = "en 1.1 fr 2,2 pl 3,3";
Scanner scan = new Scanner(txt);
// Załóżmy, że symbol języka składa się z dwóch dowolnych małych liter
// Będziemy go w tekście wyszukiwać za pomocą poniższego wzorca
String langSymRx = "[a-z][a-z]";
double sum = 0;
// Metoda findInLine znajduje w wierszu kolejny podnapis
// pasujący do wzorca, jeśli go nie ma - zwraca null
String lang = scan.findInLine(langSymRx);
while (lang != null) {
scan.useLocale( new Locale(lang) );
sum += scan.nextDouble();
lang = scan.findInLine(langSymRx);
}
System.out.println("Tekst:\n" + txt + "\n\nSuma liczb: " + sum);
}
}
1.dochody: 100,11 21,21 500,80 2.wydatki: 200,10 11,31 756,21 3.wydatki: 10,61 2,11 25,00 4.dochody: 2,30 99,12 101,11przy czym liczba i kolejność wierszy a także ilość liczb w poszczególnych wierszach może być różna.
import java.io.*;
import java.util.*;
public class Report {
private String report;
public double sum(String what) {
Scanner sc = new Scanner(report);
String regex = "\\d\\." + what + ":";
if (sc.findWithinHorizon(regex, 0) == null)
throw new IllegalArgumentException("Brak wymaganej kategorii");
double sum = 0;
do {
while (sc.hasNextDouble()) {
sum += sc.nextDouble();
}
} while (sc.findWithinHorizon(regex, 0) != null);
return sum;
}
public Report(String fname) throws FileNotFoundException {
Scanner fs = new Scanner( new File(fname) );
report = fs.useDelimiter("\\Z").next();
fs.close();
}
public static void main(String[] args) throws FileNotFoundException {
Report rep = new Report("RaportKsiegowej.txt");
double wydatki = rep.sum("wydatki"),
dochody = rep.sum("dochody");
System.out.println("Dochody: " + dochody + "\nWydatki: " + wydatki );
}
}Dla przykładowego pliku otrzymamy w wyniku: