1. Co robi komputer?
Jak wiemy, typowy zestaw komputerowy składa się z procesora, pamięci operacyjnej
(umieszczonych na płycie głównej) oraz urządzeń zewnętrznych, z których
niektóre są lub mogą być zintegrowane z płytą (karta graficzne, sterowniki
dysków i dyski, karta dźwiękowa, karta sieciowa, modem, monitor itp.). O tych
elementach komputera mówimy jako o sprzęcie (hardware ).
Czy wystarczają one, by za pomocą komputera wykonywać takie powszechne
czynności jak np.:
- pisanie i redagowanie dokumentów
- obliczenia w arkuszu kalkulacyjnym
- wyszukiwanie w bazach danych
- przeglądanie zasobów Internetu
- wysyłanie i odbieranie poczty elektronicznej
Odpowiedź jest negatywna. Nie wystarczy (nawet najnowocześniejszy)
sprzęt.
Potrzebne jest jeszcze oprogramowanie (software).
Program jest zakodowaną sekwencją instrukcji,
które ma wykonać procesor (lub za jego pośrednictwem inne elementy sprzętowe).
Na przykład pisanie i redagowanie tekstów może się odbywać tylko dzięki
temu, że działa odpowiedni program - edytor lub procesor tekstów. Programy
takie są skomplikowane, często bardzo duże, ale w sumie sprowadzają się
do pewnych sekwencji prostych
instrukcji zlecanych do wykonania sprzętowi
(przede wszystkim procesorowi).
Mówi się powszechnie, że instrukcje wykonuje program. Np. "program
wykonał błędną instrukcję i nie może być kontynuowany". Takie sformułowania
są wygodne i w pewnym sensie poprawne, pamiętajmy jednak o tym, że instrukcje
są przekazywane do wykonania procesorowi.
Kiedy zatem siedzimy przed
"czystą kartką" jakiegoś dokumentu i zastanawiamy się jak zacząć pisanie,
to jakaś część działającego akurat programu-edytora śledzi klawiaturę (czeka
na wprowadzenie znaku z klawiatury), a kiedy wciśniemy klawisz jakiegoś
znaku - wykonuje instrukcje skutkujące w uwidocznieniu w określony sposób
(rodzaj, wielkość, kolor pisma) tego znaku na ekranie monitora.
Zatem wykonanie programu polega na przekazywaniu instrukcji procesorowi.
Ale przecież nie zawsze program się wykonuje. Co się wtedy z nim dzieje?
Co musi się stać, żeby zaczął działanie?
Programy (jako zapisane ciągi instrukcji) rezydują na dysku twardym. Uruchomienie
programu polega na załadowaniu go do pamięci operacyjnej i przekazaniu sterowania
do pierwszej jego instrukcji. Tym zajmuje się specjalne oprogramowanie systemowe
i wspomagające. Bez niego komputer nie mógłby działać, nie mógłby komunikować
się z użytkownikiem, nie mógłby wykonywać - na jego zlecenie - określonych
programów.
System operacyjny - to zbiór programów
zajmujących się zarządzaniem zasobami komputera, obsługą systemu plików,
uruchamianiem programów, przydzielaniem im czasu procesora i komunikacją
między nimi oraz interakcją z użytkownikiem komputera.
Możemy zatem w tej chwili już z pewnością stwierdzić, że działanie komputera
polega po prostu na wykonywaniu programów - czy to systemowych, czy to
użytkowych.
Wszystkie programy komunikują się z procesorem w specjalnym języku. "Słowa"
tego języka to liczby. Niektóre z tych liczb mają specjalne znaczenie -
właśnie kodów instrukcji do wykonania (warto dodać, że bardzo prostych
instrukcji; złożone programy składają się z bardzo dużej liczby takich prostych
instrukcji). Inne liczby oznaczają dodatkową informację, która jest potrzebna
przy wykonaniu instrukcji. Ta dodatkowa informacja stanowi zwykle dane nad
którymi przeprowadzane są jakieś operacje (np. dodawanie liczb).
Taka cyfrowa reprezentacja instrukcji, zrozumiała przez procesor, nazywa
się kodem maszynowym lub językiem maszynowym.
Przykładowa sekwencja instrukcji maszynowych hipotetycznego komputera
może wyglądać tak:
10001010 10001000 00000001 11001010 .....
Cóż to za dziwne liczby składające się z samych zer i jedynek?
Jest to nic innego jak zapis informacji (w tym przypadku kodu programu)
w języku maszynowym jako ciągu liczb w w systemie binarnym
(zobacz tu o systemach liczbowych). Informacja "rozumiana" przez komputer musi
być tak właśnie zapisywana, gdyż powszechnie stosowane urządzenia cyfrowe
mają określone zbiory elementarnych stanów, każdy z których może być charakteryzowany
jako włączony (1) lub wyłączony (0).
Z tego wynika, że
Najmniejsza ilość informacji, którą może operować komputer - to cyfra
1 lub 0 w binarnej reprezentacji liczby.
Wielkość ta nazywana jest bitem.
Słowo maszynowe - to najmniejsza, adresowalna komórka
pamięci
operacyjnej, jak również - odpowiadający tej wielkości rozmiar
rejestrów
procesora, czyli specjalnego wewnętrznego układu pamięciowego, o bardzo
szybkim dostępie, w którym procesor przechowuje chwilowo dane aktualnie
wykonywanych operacji
W szczególności dlatego, że procesory operują
na jednostkach, które nazywają się słowami maszynowymi, składających się
z całkowitej liczby bajtów.
Bajt jest najmniejszą częścią słowa maszynowego, dostępną bezpośrednio
dla procesora. Kody instrukcji procesorów były i są jedno lub kilkubajtowe.
Znaki (litery) były i są kodowane jako liczby jedno (np. kody ASCII, EBCDIC)
lub wielo - bajtowe (np. DCSB lub Unicode).
A ponieważ pół bajta można przedstawić jako cyfrę szesnastkową,
to heksadecymalny system liczbowy jest wygodniejszą (od binarnego, bo
jest bardziej czytelny; ale i od dziesiętnego, bo widzimy w nim wyraźny
podział na bajty) formą przedstawiania zapisu maszynowego kodu programu.
Fragment kodu maszynowego przedstawia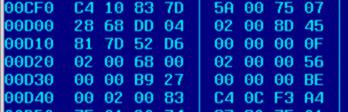 rysunek obok. Po lewej stronie widzimy kolumnę względnych adresów przestrzeni
adresowej programu, po niej następują ciągi instrukcji (kodów i danych).
rysunek obok. Po lewej stronie widzimy kolumnę względnych adresów przestrzeni
adresowej programu, po niej następują ciągi instrukcji (kodów i danych).
Oczywiście, można napisać program w języku maszynowym. Ale domyślamy się,
że jest to zadanie niezwykle pracochłonne, a pisanie w taki sposób programów
- niezwykle nieefektywne. A jednak - na samym początku epoki komputerów tak
właśnie pisano programy.
Na pomoc biednym programistom pionierskiej epoki komputeryzacji przyszło
stworzenie assemblerów - języków symbolicznego zapisu instrukcji
maszynowych danego procesora.
Od tego momentu, program, który wcześniej trzeba było zapisywać np. tak:
5830 D252 5A30 D256 5030 D260
można było zapisać dużo prościej i bardziej zrozumiale, np:
|
Instrukcja assemblera
|
Wyjaśnienie
|
|
L 3, X
|
do rejestru 3 załaduj liczbę znajdującą się w pamięci pod adresem
oznaczonym symbolicznie przez X |
|
A 3, Y
|
dodaj do zawartości rejestru 3 liczbę znajdującą się w pamięci
pod adresem oznaczonym symbolicznie przez Y |
|
ST 3, Z
|
zapisz nową zawartość rejestru 3 do pamięci pod adresem oznaczonym
symbolicznie przez Z |
Taki zapis - bardziej zrozumiały dla nas - jest jednak niezrozumiały
dla procesora. Programy zapisane w symbolicznym języku assemblera, muszą
być przetłumaczone na język maszynowy (ciąg cyfr binarnych) i tym zajmują
się translatory (czasem zwane potocznie również assemblerami).
Wszakże programowanie w języku assemblera jest wciąż uciążliwe. Co gorsza
obarcza ono programistę obowiązkiem pamiętania różnych technicznych szczegółów
(rejestry, ich numery, adresowanie pamięci), wymaga od niego zapisywania
bardzo elementarnych operacji i nie pozwala
dostatecznie skupić się na dziedzinie i logice rozwiązywanego (przez program)
problemu.
W istocie w powyższym "programiku" chodzi o dodanie do siebie dwóch liczb
(oznaczonych X i Y) i zapisanie wyniku jako Z.
Dlaczego by nie można napisać po prostu:
Z = X + Y ?
Dlatego pojawiły się języki programowania (ściślej - i dla odróżnienia
od języków assemblera - języki programowania wysokiego poziomu), które
w swoich instrukcjach, składni, semantyce konsolidują wiele prostych instrukcji
assemblerowych, ukrywają ich techniczne szczegóły, i - w porównaniu z
assemblerami - są składniowo niezależne od procesora. W tych językach
naprawdę możemy napisać: Z = X + Y, nie martwiąc się rejestrami, względnym
adresowaniem pamięci i zestawem rozkazów konkretnego procesora.
Użycie języków wysokiego poziomu wymaga jednak bardziej zaawansowanych
środków tłumaczenia tekstu programu na instrukcje zrozumiałe dla procesora:
kompilatorów i/lub interpreterów (o czym za chwilę).
2. Algorytmy i języki programowania
Instrukcje zapisane w programie powinny łącznie realizować jakieś zadanie,
rozwiązywać jakiś problem. Jest oczywiście możliwe napisanie programu,
który składa się z jakichś przypadkowych instrukcji, ale nie ma w tym za
wiele sensu.
Powinniśmy zatem spojrzeć na pojęcie programu z innego (niż "techniczny",
związany z wykonywaniem przez procesor instrukcji) punktu widzenia.
Skoro programy służą do rozwiązywania jakichś problemów, realizacji zadań, to punktem wyjścia programowania
powinno być sformułowanie problemu lub zadania, sposobu jego rozwiązania,
kroków prowadzących do realizacji celu. Innymi słowy - sformułowanie
algorytmu rozwiązania problemu lub wykonania zadania.
ALGORYTM to przepis postępowania prowadzący
do rozwiązania określonego zadania; zbiór poleceń dotyczących pewnych obiektów
(danych) — ze wskazaniem kolejności, w jakiej mają być wykonane; wykonawcą
jest układ, który na sygnały reprezentujące polecenia reaguje ich realizowaniem
— może nim być człowiek lub urządzenie automatyczne, np. komputer.
(
źródło: Encyklopedia PWN)
Wyobraźmy sobie np., że zamierzamy kupić nowy komputer i stoi przed
nami zadanie skonfigurowania go i policzenia całkowitej ceny (wg dostępnego
cennika części).
W pierwszym przybliżeniu najprostszy algorytm realizacji tego zadania
możemy opisać w kolejnych krokach
- Wybierz z cennika procesor, zapisz jego cenę
- Wybierz z cennika pamięć RAM, zapisz jej cenę
- Wybierz z cennika płytę główną, zapisz jej cenę
- Wybierz z cennika kartę graficzną, zapisz jej cenę
- Wybierz z cennika dysk twardy, zapisz jego cenę
- Wybierz z cennika CDROM lub DVD, zapisz jego cenę
- Wybierz z cennika kartę dźwiękową, zapisz jej cenę
- Wybierz obudowę i potrzebne akcesoria, zapisz ich ceny
- Zsumuj wszystkie ceny
Jest to zapis w języku naturalnym. Graficznie algorytm ten (z pewnymi
skrótami, ale bez zmniejszenia ogólności) moglibyśmy przedstawić w następujący
sposób jak na rysunku obok.
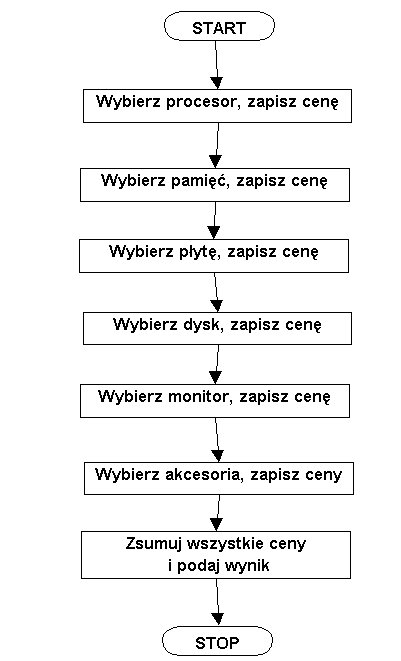 Widzimy tu ściśle określoną sekwencję kolejnych kroków.
Widzimy tu ściśle określoną sekwencję kolejnych kroków.
Algorytm ma swój
początek, jego wykonalność i zakończenie pracy są gwarantowane, może być
także wykonywany wielokrotnie, z różnymi danymi - w naszym przypadku różnymi
opcjami, dotyczącymi konfiguracji komputera.
Ten algorytm jest dla nas zrozumiały. Potrafimy go wykonać, choćby z
ołówkiem i kartką papieru.
Powstaje pytanie, w jaki sposób zadanie wyliczenia ceny można powierzyć
komputerowi?
Oczywiście, domyślamy się, że algorytm należy zapisać w jakimś języku
programowania (otrzymamy wtedy program w postaci źródłowej), przetłumaczyć
na język zrozumiały dla procesora (program w postaci wykonywalnej), następnie ten "wykonywalny" program uruchomić.
Od razu jednak natkniemy się na pewien podstawowy problem: co tak naprawdę
znaczy sformułowanie "wybierz ..., zapisz cenę."; kogo ma dotyczyć ta sekwencja
instrukcji do wykonania - tylko komputera, czy również nas samych - jako
użytkowników programu realizującego dany algorytm?
Skoro na podstawie algorytmu mamy stworzyć program, a program ma być
wykonywany przez komputer, to algorytm powinniśmy formułować w kategoriach
czynności wykonywanych przez komputer.
Zauważmy więc, że w ogólnym sensie omawiany algorytm realizuje przetwarzanie
jakichś danych wejściowych (podawanych przez użytkownika) w
dane wyjściowe (wynik działania algorytmu).
Musimy sprecyzować: jakie dane i kiedy ma podawać użytkownik i co z tymi
danymi ma robić komputer.
Mamy co najmniej trzy możliwości:
- użytkownik podaje konkretne ceny, program wylicza ich sumę;
- użytkownik podaje charakterystyki składników, program odszukuje np.
w jakiejś internetowej bazie danych ich ceny i sumuje je;
- użytkownik podaje kryteria wyboru konfiguracji sprzętowej, program
według tych kryteriów dokonuje wyboru konkretnych opcji sprzętowych i sumuje
ich ceny.
W pierwszym przypadku nasz algorytm tylko nieco się zmieni. Pamiętajmy:
formułujemy go w kategoriach czynności wykonywanych przez komputer.
1. Zapytaj użytkownika o cenę procesora
2. Zapytaj użytkownika o cenę płyty głównej
...
n-1. Zsumuj podane ceny
n. Podaj użytkownikowi wynik (cenę komputera)
Inne, przedstawione wyżej przypadki, prowadzą do algorytmów znacznie
bardziej skomplikowanych.
Zauważmy jeszcze, że ten prosty algorytm ma bardzo ogólną postać. Przełożenie
go na jakiś język programowania wymaga podjęcia wielu decyzji, np.
- w jaki sposób ma odbywać się interakcja z użytkownikiem: w jaki sposób
pytać go o dane wejściowe i jak pokazywać wynik (dane wyjściowe) ?
- w jaki sposób wykonywać sumowanie: czy przechowywać ceny poszczególnych
składników, czy składać je inkrementalnie mając na wyjściu do dyspozycji
tylko wynikową, sumaryczną cenę?
- w jaki sposób reagować na błędy danych ?
Decyzje te dotyczą zaprojektowania tzw. interfejsu użytkownika
(czyli sposobu komunikowania się programu z użytkownikiem) oraz przemyślenia
struktury algorytmu pod względem odporności na błędy i łatwości
modyfikacji. Np. w naszym algorytmie powinniśmy sprawdzać, czy użytkownik
nie wprowadził czasem danych, które nie są liczbą i zastanowić się, czy
nie przechowywać cen poszczególnych składników komputera, bo być może za
jakiś czas zmienimy zestaw danych wyjściowych i będziemy chcieli pokazać
użytkownikowi "raport z obliczeń", przedstawiający, oprócz sumarycznej ceny,
ceny poszczególnych składników, a może nawet ich procentowy udział w łącznym
koszcie.
Już tylko reagowanie na błędy danych zmieni sekwencję kroków
naszego algorytmu.
Zazwyczaj zresztą rozwiązanie jakiegoś problemu lub wykonanie jakiegoś
zadania wymaga - oprócz jakichś prostych sekwencji kroków::
- sprawdzania jakichś warunków i na tej podstawie podejmowania decyzji
o wyborze dalszych kroków algorytmu
- iteracyjnego wykonania jakichś fragmentów algorytmu (powtarzania
ich wykonania wielokrotnie, zadaną liczbę razy lub dopóki spełnione sa
jakieś warunki)
Uwzględniając możliwe błędy przy podawaniu danych przez użytkownika oraz
potrzebę przechowywania danych o podanych cenach składników , algorytm
wyliczenia ceny komputera może wyglądać tak:
1. Zapytaj użytkownika o cenę procesora
2. Jeżeli podana cena nie jest liczbą,
powiadom użytkownika o błędzie
i wróć do kroku 1
3. Zapisz cenę procesora (do ew. późniejszego użycia)
4. Zapytaj użytkownika o cenę płyty głównej
5. Jeżeli podana cena nie jest liczbą,
powiadom użytkownika o błędzie
i wróć do kroku 4
6. Zapisz cenę płyty głównej (do ew. późniejszego użycia)
... inne składniki
... inne składniki
n-1. Wylicz sumę cen składników
n. Pokaż wyniki
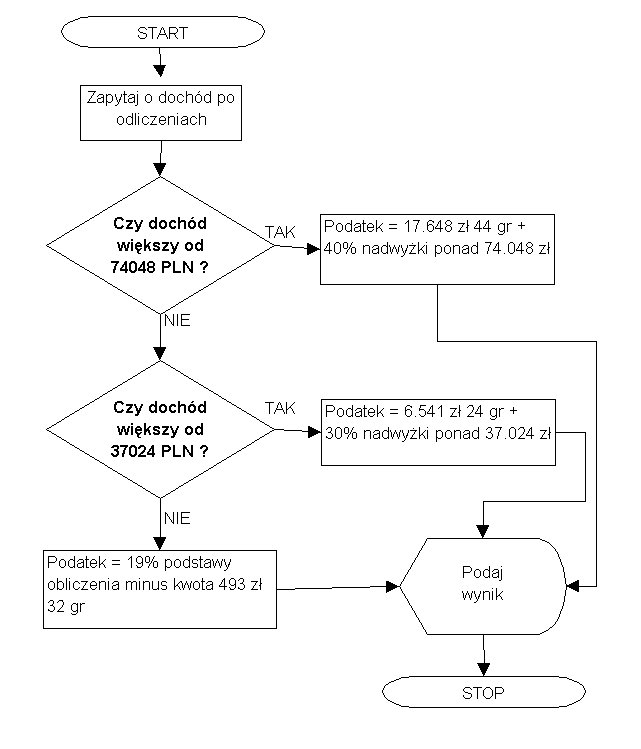
Na schematach blokowych podejmowanie decyzji przedstawia się w postaci rombu.
Przykład: schemat blokowy algorytmu obliczania podatku (dane są oczywiście fikcyjne).
Algorytmy możemy zapisywać również w pseudo-kodzie, czyli skróconej i
do pewnego stopnia sformalizowanej formie języka naturalnego, niezależnej
od konkretnego języka programowania. Pseudo-kod jest znacznie bliższy
językom programowania niż język naturalny i łatwiej jest przekładać go na
program zapisany w konkretnym języku programowania. W różnych podręcznikach
programowania znaleźć można różne formy pseudo-kodu, sami możemy także opracować
dla siebie własny pseudo-kod.
W pseudo-kodzie możemy posługiwać się pojęciem zmiennej, czyli symbolicznego
oznaczenia danych (więcej o pojęciu zmiennej w następnym wykładzie; teraz
możemy traktować je nieco podobnie jak w matematyce).
Operacje na zmiennych możemy zapisać skrótowo za pomocą operatorów
czyli symboli dodawania, odejmowania, mnożenia, porównania itp. (więcej
o operatorach w następnym wykładzie).
W pseudo-kodzie muszą znajdować się także słowa i wyrażenia, precyzyjnie określające
znaczenie fragmentów algorytmu (czynności, instrukcje do wykonania). Np.
podejmowanie decyzji może być zapisane w postaci:
jeżeli (warunek) to ...
albo
jeżeli (warunek) to ...
w przeciwnym razie ...
a pętle iteracyjne (czyli powtarzanie fragmentów algorytmu):
wykonuj dopóki (warunek) ...
wykonuj zmieniając wartość zmiennej i od p do l ..
.
Natomiast wprowadzanie i wyprowadzanie danych można wyrazić np. za pomocą
słów czytaj, pisz.
Używając symboli +, - i * dla wyrażenia operacji dodawania, odejmowania i
mnożenia, nawiasów (jak w matematyce) do grupowania operacji i specjalnych
słów dla wyrażenia czynności i decyzji, algorytm wyliczenia podatku możemy
teraz zapisać jako:
czytaj dochód
jeżeli (dochód > 74048) to podatek = 17048.44 + 0.4 * (dochód - 74048)
w przeciwnym razie jeżeli (dochód > 37024) to
podatek = 6541.24 + 0.3 * (dochód - 37024)
w przeciwnym razie podatek = 0.19 * dochód - 493.32
pisz podatek
Przy zapisie w ten sposób algorytmu obliczenia ceny komputera natkniemy się
jednak na dwa problemy.
Po pierwsze, błąd przy wprowadzaniu danych zmienia sekwencję kroków algorytmu
i powoduje powrót do kroku wczytywania danych. W pseudo-kodzie moglibyśmy to
zapisać jako instrukcję przejścia do konkretnego fragmentu algorytmu (
idź do ..), oznaczonego jakąś etykietą (etykieta będzie słowem zakończonym
dwukropkiem). Przy okazji, wprowadzimy do naszego pseudo-kodu nawiasy klamrowe,
które będą grupować czynności; np. w kontekście:
jeżeli (warunek) to {
czynność 1
czynność 2
}
przy zajściu warunku zostaną wykonane po kolei czynności podane w nawiasach
klamrowych.
.
pobieranieDanych1:
pisz "Podaj cenę procesora"
czytaj cenaProcesora
jeżeli (cenaProcesora nie jest liczbą) to {
pisz "Wadliwe dane"
idź do pobieranieDanych1
}
pobieranieDanych2:
pisz "Podaj cenę płyty głównej"
czytaj cenaPłyty
jeżeli (cenaPłyty nie jest liczbą) to {
pisz "Wadliwe dane"
idź do pobieranieDanych2
}
...
cenaWynikowa = suma cen części
pisz cenaWynikowa
Taki sposób zapisu powoduje jednak, że algorytmy (i programy) stają się trudno
czytelne, a ich logika zawikłana i narażona na błędy.
Dlatego w większości języków programowania nie ma już instrukcji goto
( idź do). Zamiast tego stosowane są instrukcje iteracyjne.
Algorytm wyliczenia ceny komputera powinniśmy więc wyrazić w inny sposób,
np. wprowadzając zmienną logiczną o nazwie trzebaPobraćDane, która może przyjmować
dwie symboliczne wartości tak i nie ( prawda, fałsz), oraz używając instrukcji
iteracyjnych.
trzebaPobraćDane = tak
wykonuj dopóki (trzebaPobraćDane) {
pisz "Podaj cenę procesora"
czytaj cenaProcesora
jeżeli (cenaProcesora nie jest liczbą) to pisz "Wadliwe dane"
w przeciwnym razie trzebaPobraćDane = nie
}
trzebaPobraćDane = tak
wykonuj dopóki (trzebaPobraćDane) {
pisz "Podaj cenę płyty głównej"
czytaj cenaPłyty
jeżeli (cena
Płyty nie jest liczbą) to pisz "Wadliwe dane"
w przeciwnym razie trzebaPobraćDane = nie
}
...
cenaWynikowa = suma cen części
pisz cenaWynikowa
Na początku zmienna trzebaPobraćDane ma wartość tak i warunek w
wykonuj dopóki jest prawdziwy, zatem rozpoczyna się wykonanie instrukcji
w nawiasach klamrowych. Jeżeli wprowadzone dane (cenaProcesora) nie są liczbą,
to wypisywany jest komunikat "Wadliwe dane", wartość zmiennej trzebaPobraćDane
nie zmienia się i czynności zapisane w nawiasach klamrowych wykonywane są
ponownie (bowiem warunek w wykonuj dopóki nadal jest prawdziwy). W
przeciwnym razie (jeśli cenaProcesora jest liczbą), zmienna trzebaPobraćDane
przybiera wartość nie, wobec czego warunek w wykonuj dopóki
przestaje być prawdziwy i czynności w nawiasach klamrowych nie są kolejny
raz wykonywane, a algorytm kontynuuje działanie od miejsca po zamykającym
nawiasie klamrowym - rozpoczyna pobieranie danych dotyczących ceny płyty
głównej.
Drugi problem, związany z tym algorytmem polega na powielaniu bardzo podobnych
(niemal identycznych ) czynności. Zwróćmy uwagę: pobieranie cen dla procesora,
płyty, innych komponentów - wygląda praktycznie tak samo. Moglibyśmy więc
wyodrębnić te czynności i zapisać je jeden raz w postaci tzw. procedury
lub funkcji (inaczej zwanych też metodami), a jednokrotnie zapisane w niej czynności wykonywać
wielokrotnie dla różnych komponentów komputera.
Oznacza to, że dzielimy nasz problem obliczenia ceny komputera na dwa podproblemy:
podproblem wprowadzania i weryfikacji danych oraz główny problem właściwych
obliczeń. Każdy z tych problemów możemy rozwiązywać w dużym stopniu niezależnie,
skupiać się każdorazowo na specyficznych w danym kontekście cechach.
Ten sposób tworzenia algorytmów i programów nazywa się programowaniem
strukturalnym.
Podsumujmy:
- programy piszemy po to, by rozwiązywać jakieś problemy lub realizować jakieś zadania;
- zanim napiszemy program, który realizuje jakieś zadanie, musimy opracować
algorytm postępowania, prowadzącego do realizacji tego zadania;
- algorytm jest przepisem, zbiorem poleceń wykonywanych na danych,
opisem sposobu przekształcenia danych wejściowych w dane wyjściowe;
- program jest zapisem algorytmu oraz danych w konkretnym języku
programowania;
- po to by program mógł być wykonany przez komputer jego zapis w konkretnym
języku programowania musi być przetłumaczony na język instrukcji rozumianych
przez procesor; takiego tłumaczenia dokonują specjalne programy nazywane translatorami,
kompilatorami i interpreterami.
Zwróćmy szczególną uwagę na to, że w programach nie tylko odzwierciedlamy
kroki ( polecenia, czynności) algorytmów, ale również musimy w jakiś sposób
przedstawiać dane, których czynności te dotyczą. Dane mogą być obrazowane
w różny sposób - mogą być opisywane jako pojedyncze egzemplarze albo jako
zestawy, (powiązanych i/lub w określony sposób uporządkowanych) danych. W
tym kontekście mówimy o strukturach danych.
Możemy zatem podać inną od poprzedniej definicję programu (autorstwa N.
Wirtha).
PROGRAM - to skonkretyzowane sformułowanie
abstrakcyjnego algorytmu na podstawie określonej reprezentacji i struktury
danych.
Tekst programu zapisujemy w wybranym języku programowania.
Każdy język programowania posiada swój alfabet, czyli zbiór znaków
(liter i cyfr) z których mogą być konstruowane symbole języka (ciągi znaków).
Reguły składniowe definiują dopuszczalne sposoby tworzenia symboli
oraz dopuszczalne porządki ich występowania w programie, zaś semantyka
języka określa znaczenie wybranych symboli.
Np. w jakimś języku programowania
możemy się posługiwać alfabetem składającym się z liter, cyfr, znaków specjalnych
(alfabet języka); z liter i cyfr możemy tworzyć nazwy zmiennych, niektóre
ciągi znaków (np. if ) mogą być zarezerwowane i oznaczają instrukcje języka,
sposób łączenia ze sobą symboli jest określony (np. napis if (a == b) a =
0; będzie poprawny składniowo, a napis if a =b a =0 będzie niepoprawny);
znaczenie ciągów symboli jest określone np. a = 3 oznacza przypisanie zmiennej
a wartości 3).
Istnieje wiele (dziesiątki tysięcy) języków programowania. Można je klasyfikować
według różnych kryteriów.
Niewątpliwie najważniejszym jest logiczna struktura języka i sposób tworzenia programów w danym
języku.
Języki imperatywne wymagają od programisty wyspecyfikowania konkretnej
sekwencji kroków realizacji zadania, natomiast języki deklaratywne
- opisują relacje pomiędzy danymi w kategoriach funkcji (języki funkcyjne
) lub reguł (języki relacyjne, języki programowania logicznego
), a wynik działania programu uzyskiwany jest poprzez zastosowanie wobec
opisanych relacji określonych gotowych, wbudowanych "w język" algorytmów.
Podejście obiektowe polega przede wszystkim na łącznym rozpatrywaniu
danych i możliwych operacji na nich, dając możliwość tworzenia i używania
w programie nowych typów danych, odzwierciedlających dziedzinę problemu,
programowanie proceduralne (czasami kojarzone z imperatywnym) rozdziela
dane i funkcje i nie dostarcza sposobów prostego adekwatnego odzwierciedlenia
dziedziny rozwiązywanego problemu w strukturach danych, używanych w programie.
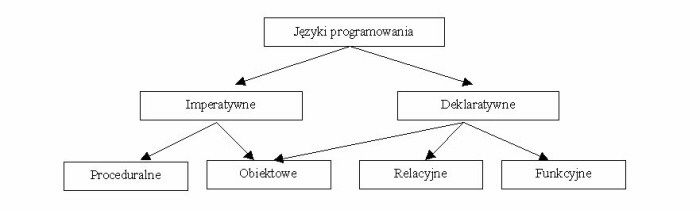
Przykładami języków proceduralnych są: ALGOL, FORTRAN, PL/I, C. Języki
obiektowe
to np. SmallTalk, Java, C++, C#. Najbardziej znanym językiem funkcyjnym
jest
Haskell, zaś językiem programowania logicznego - Prolog. Języki takie
jak Python, Ruby, Groovy czy Scala łączą podejście obiektowe z
elementami programowania funkcyjnego,
Inny podział dotyczy sposobu w jaki tekst programu przekształcany jest na
instrukcje dla procesora.
Mamy tu podział na języki kompilowane i interpretowane.
Kompilator tłumaczy program źródłowy na instrukcje, które mogą
być wykonane przez procesor i jednocześnie sprawdza składniową poprawność
programu, sygnalizując wszelkie błędy. Proces kompilacji jest więc nie tylko
procesem tłumaczenia, ale również weryfikacji składniowej poprawności programu.
W
językach kompilowanych tekst programu (program źródłowy)
tłumaczony jest na kod binarny (pośredni) przez specjalny program
nazywany kompilatorem. Zazwyczaj inny program zwany linkerem
- generuje z kodu pośredniego gotowy do działania binarny kod wykonywalny
i zapisuje go na dysku w postaci pliku typu wykonywalnego (np. z rozszerzeniem
EXE lub z nadanym atrybutem "zdolny do wykonywania"). W ten sposób działają
takie języki jak C czy C++. Czasem kompilator produkuje symboliczny kod
binarny, który jest wykonywany za pomocą interpretacji przez program
zwany interpreterem. Tak właśnie dzieje się w przypadku języka Java.
Interpreter wykonuje bezpośrednio tekst programu. Zatem składniowa
poprawność jest sprawdzana zazwyczaj dopiero w trakcie działania programu,
aczkolwiek niektóre języki interpretowane udostępniają fazę symbolicznej
kompilacji do kodu pośredniego, podczas której sprawdzana jest poprawność
źródła.
Niektóre interpretery wewnętrznie kompilują fragmenty kodu do postaci binarnej, aby przyspieszyć wykonanie.
W językach interpretowanych kod programu (źródłowy lub
pośredni) jest odczytywany przez specjalny program zwany interpreterem.
który na bieżąco - w zależności od przeczytanych fragmentów programu - przesyła
odpowiednie polecenia procesorowi i w ten sposób wykonuje program.
Przykładami języków interpretowanych są: REXX, ObjectREXX, Perl, PHP.
Reasumując, proces programowania można przedstawić na poniższym rysunku za pomocą następującego algorytmu.
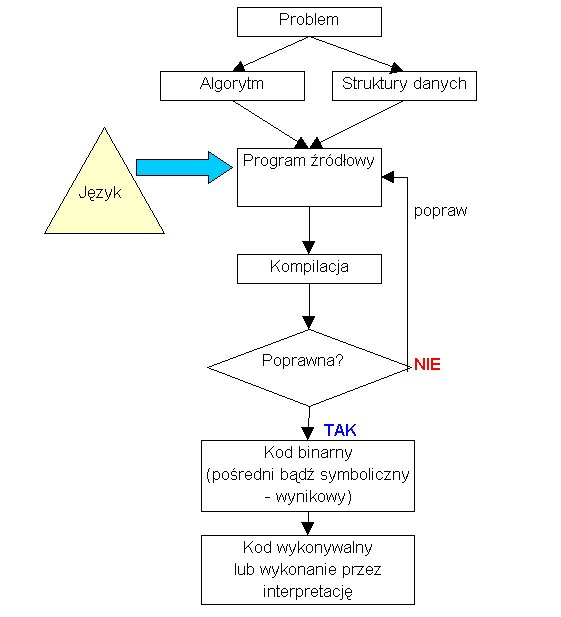
3. Czym jest Java?
3.1. Uniwersalny język programowania
Przede wszystkim Java jest uniwersalnym językiem
programowania.
Składniowe podobieństwo do C/C++ czyni ten język łatwy do opanowania przez
programistów znających te języki. Jednocześnie Java ma ambicje udoskonalania
swoich wzorców. Programista Javy w zasadzie nie musi martwić się zarządzaniem
pamięcią (w Javie funkcjonuje automatyczne odśmiecanie –"garbage
collection", polegające na automatycznym
usuwaniu przydzielonych wcześniej a nieużywanych obszarów pamięci). Java
nie dopuszcza arytmetyki wskaźnikowej, która pozwala na odwoływanie się do
dowolnych obszarów pamięci i jest częstą przyczyną błędów.
Ścisła kontrola zgodności typów na etapie kompilacji pozwala unikać prostych
błędów. Co więcej to tzw. statyczne typowanie
umożliwia zintegrowanym środowiskom programowania (IDE) przebogate wspieranie
programisty przy pisaniu i testowaniu programu (automatyczne
dopisywanie kodu i poprawianie błędów). Konwersje (rzutowanie) typów przeprowadzane w fazie wykonania są bezpieczne,
bowiem nigdy nie może powstać sytuacja przekształcenia danych do niewłaściwego
dla nich typu.
Wymuszana przez kompilator obsługa niektórych wyjątków (inaczej mówiąc - błędów) czyni programowanie w
Javie jeszcze bardziej bezpiecznym i niezawodnym, a wbudowane w język
podstawowe elementy współbieżności umożliwiają łatwe tworzenie i
synchronizowanie równolegle działających wątków (czyli równolegle wykonywanych fragmentów tego samego programu).
Wszystkie wymienione wyżej - teraz może dość tajemniczo brzmiące - pojęcia
będziemy szczegółowo omawiać w kolejnych wykładach.
Niewątpliwie jednak najważniejszą cechą Javy jako "czystego języka" jest
jej
obiektowość. Ogólnie, oznacza to, iż programy pisze się w Javie
łatwiej, bardziej uniwersalnie i niezawodnie niż w językach
nieobiektowych. Już w tym wprowadzającym wykładzie zaczniemy powoli
oswajać się z podejściem
obiektowym.
Większość innych ważnych cech Javy, o których była mowa wyżej, wynika z
wysokich wymogów bezpieczeństwa, stawianych językowi przez jego twórców. Coś za
coś – często oznacza to pewne ograniczenie swobody i elastyczności programisty,
a także (czasem nadmierne) zwiększanie pracochłonności pisania kodu.
Zalety Javy jako czystego języka programowania mogą być dyskusyjne. Ale
nie dlatego warto Javy się uczyć, że jest to język idealny (czy w ogóle są
takie?).
Dużo ważniejsza jest jej uniwersalność we wszelkich
zastosowaniach informatycznych. Uniwersalność, zapewniana przez
wieloplatformowość Javy oraz wynikającą stąd (zrealizowaną) możliwość stworzenia przebogatych
standardowych "bibliotek" na tyle zintegrowanych z samą Javą, że praktycznie
będących jej synonimem.
3.2. Wieloplatformowość i uniwersalność Javy
Java jest językiem interpretowanym, co umożliwia wykonywanie "binarnych" kodów
Javy bez rekompilacji praktycznie na wszystkich platformach systemowych.
Kod źródłowy (pliki z rozszerzeniem ".java") jest kompilowany przez
kompilator Javy (program javac) do kodu bajtowego (B-kodu, pliki z rozszerzeniem ".class"), ten
ostatni zaś jest interpretowany przez tzw. wirtualną maszynę Javy – JVM (jest
to program java wraz odpowiednimi dynamicznymi bibliotekami), zainstalowaną na danej platformie
systemowej.
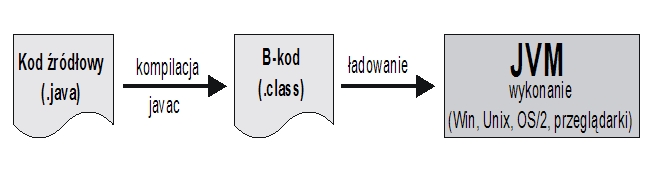
Oznacza to, teoretycznie, że raz napisany i skompilowany program będzie
działał tak samo na wszystkich platformach systemowych. Idea wręcz doskonała
(jak wiele wysiłku i kosztów pochłania przenoszenie programów z jednej
platformy na drugą).
Sama wieloplatformowość języka interpretowanego nie jest czymś
nadzwyczajnym. Ale twórcy Javy wyciągnęli z tej jej cechy bardzo konsekwentne
wnioski. Stworzyli mianowicie bogaty zestaw standardowych bibliotek i
narzędziowych interfejsów programistycznych (API), które umożliwiają w
jednolity, niezależny od platformy sposób programować:
- graficzne interfejsy
użytkownika (GUI),
- dostęp do baz danych,
- działania w sieci,
- aplikacje rozproszone,
- aplikacje WEB,
- oprogramowanie pośredniczące (middleware),
- zaawansowana grafikę, gry i multimedia,
- aplikacje na telefony komórkowe i inne "małe" urządzenia.
Zestaw standardowych
bibliotek - wraz z kompilatorem, debugerem, narzędziami tworzenia
dokumentacji i innymi narzędziami pomocniczymi - nazywa się JDK (Java Development Kit).
Oprócz tego wprowadzono prosty mechanizm "rozszerzeń", który umożliwia
rozszerzanie bazowego standardu o nowe (w sumie też standardowe)
biblioteki.
Podstawowy zestaw bibliotek uzupełniany jest - w zależności od
celów zastosowań - przez dodatkowe technologie. W całości środki te tworzą
platformę Java 2, podzieloną - ze względu na zastosowania i powiązane z nimi technologie - na edycje:
- standardową - Java Standard Edition (Java SE) - przeznaczoną głównie do standardowych zastosowań dla komputerów personalnych i serwerów, również połączonych w sieci,
- biznesową - Java Enterprise Edition (Java EE) - dla tworzenia rozbudowanych i zaawansowanych aplikacji biznesowych, w szczególności dla dużych firm,
- mikro - Java Micro Edition (Java ME) - dla programowania urządzeń
elektronicznych, takich jak telefony komórkowe, telewizja, procesory w samochodach
czy urządzeniach gospodarstwa domowego.
Ilustracyjnie architekturę i środki standardowej edycji Javy w wersji 6 przedstawia rysunek.
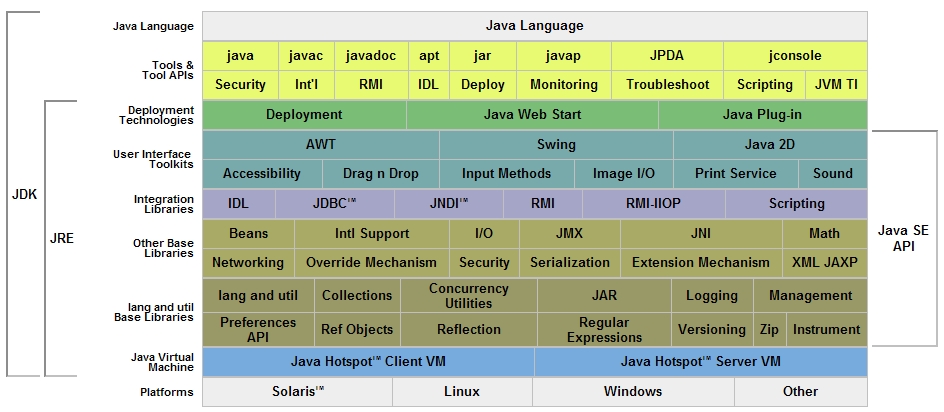
Źródło: JDK 6 Documentation, Sun 2006
Czy warto uczyć się Javy? Jeśli nawet
uznamy sam "czysty język" za nieco niekonsekwentny czy uciążliwy, to zachętą do
przezwyciężenia wszelkich obiekcji jest ogromna uniwersalność Javy. Jak
wspomniałem wcześniej - jest to jedyny język programowania tak naprawdę
zawierający standardowe i uniwersalne środki realizacji niemal wszelkich zadań
informatycznych.
To wielkie bogactwo możliwości niewątpliwie skłania do jego
poznania.
Oczywiście najpierw trzeba zaznajomić się z podstawami Javy. Na tej drodze –
pewnie – dużą trudnością będzie obiektowość Javy. Dlatego już za chwilę –
ogólnie, na poziomie koncepcyjnym – przyjrzymy się niektórym cechom podejścia
obiektowego.
4. Wprowadzenie do obiektowości
Języki obiektowe posługują się pojęciem obiektu i klasy.
Dokładne
definicje tych pojęć poznamy później. Teraz zamiast rozmyślania nad abstrakcyjnymi
sformułowaniami spróbujmy uruchomić wyobraźnię i intuicję, licząc się z tym
(i nie przerażając się tym), że niektóry rzeczy zostaną w pełni wyjaśnione
dopiero w toku dalszej nauki.
Cóż to jest "obiekt" ? Intuicyjnie czujemy, że to coś w rodzaju "przedmiotu",
czegoś co można wyodrębnić, nazwać, określić jego właściwości.
Na przykład obiektami będą: rower, samochód, pies, człowiek.
Każdy z tych obiektów ma inne właściwości. Np. człowiek ma imię, jest
w określonym wieku. Samochód ma kolor i może też np. być charakteryzowany
mocą silnika czy liczbą drzwi.
Dwa samochody mają ten sam zestaw właściwości (atrybutów) np. markę,
kolor i moc silnika. I choć marki i kolory mogą być różne i różna może być
moc silników - to w pewnym sensie samochody te są podobne (bo opisujemy je
za pomocą takich samych cech). Powiemy, że obiekty-samochody są obiektami
tej samej klasy.
A klasa stanowi opis takich cech grupy podobnych obiektów, które są dla
nich niezmienne.
Zauważmy dalej, że obiekty mogą wykonywać jakieś czynności. Powiemy: udostępniają jakieś usługi. Inne obiekty mogą "poprosić" je o wykonanie tych usług.
Np. obiekt-kierowca może "zlecić" obiektowi-samochodowi. by ten ruszył lub
zatrzymał się (poprzez włączenie silnika i naciśnięcie na pedał gazu lub
za pomocą wciśnięcia hamulca).
Powiemy, że do obiektów posyłane są komunikaty, żądające od nich wykonania określonych usług.
Obiekty nie mogą wykonywać dowolnych czynności (świadczyć dowolnych usług).
Samochód może ruszyć lub stanąć, ale nie będzie latać.
Można powiedzieć, że to, jakie usługi udostępniają obiekty, jakie komunikatu
możemy do nich posyłać, prosząc je o wykonanie jakichś czynności - również
jest jakąś ich cechą.
Zatem klasa będzie opisywać nie tylko takie wspólne cechy grupy podobnych
obiektów jak kolor, czy wiek, czy waga, ale również zestawy usług, które
obiekty tej klasy mogą świadczyć. A więc i komunikaty, które do tych obiektów
można posłać.
Rozumowanie powyższe stanowią abstrakcyjne odzwierciedlenie cech
rzeczywistości.
Gdybyśmy mieli w języku programowania podobne pojęcia, to moglibyśmy ujmować
projekt rozwiązania rzeczywistego problemu i jego oprogramowanie w języku
adekwatnym do problemu.
I to zapewniają języki obiektowe. Jest to ich bardzo
ważna cecha, znacznie ułatwiająca tworzenie oprogramowania.
Możemy mieć np. klasę urządzeń elektrycznych o następujących atrybutach:
szerokość, wysokość, stan (włączone-wyłączone) oraz udostępniających usługi:
włączania i wyłączania.
Tak jest w rzeczywistości. I tak samo możemy
to zapisać w (na razie wyimaginowanym) języku obiektowym, w którym za pomocą
definicji klasy opiszemy atrybuty urządzeń elektrycznych oraz zestaw usług,
przez nie udostępnianych - mający odzwierciedlenie w komunikatach, które
można posłać do tych obiektów. Ten ostatni - w wielu językach obiektowych
- nazywany jest zestawem metod klasy (metoda jest czymś bardzo podobnym do funkcji).
class ElDev {
width, height; <-- atrybuty: szerokość, wysokość, stan
isOn;
================= Interfejs komunikatów
method on()
isOn = true; <--- usługa on (włącz), inaczej: metoda o nazwie on
method off()
isOn = false; <--- usługa off (wyłacz),inaczej: metoda o nazwie on
}
Uwaga: powyższy zapis jest symboliczny, nie jest to zapis definicji klasy w Javie czy jakimkolwiek innym języku programowania.
Gdy mamy dwa obiekty – egzemplarze klasy urządzeń elektrycznych, oznaczane a
i b, to możemy symulować w programie sekwencję działań: włączenie urządzenia a,
właczenie urządzenia b, wyłączenie urządzenia a, za pomocą komunikatów
posyłanych do obiektów (inaczej wywołania metod na rzecz obiektów), np. w Javie (czy C++):
a.on(); // komunikat: obiekcie a włącz się
b.on(); // obiekcie b włącz się
a.off(); // obiekcie a wyłącz się
Oprócz odzwierciedlenia w programie "języka problemu" abstrakcja obiektowa
ma jeszcze jedną ważną przewagę nad ujęciami nieobiektowymi.
Mianowicie, zwykle atrybuty obiektu nie są bezpośrednio dostępne. W
programie z obiektami "rozmawiamy" za pomocą komunikatów, obiekty same "wiedzą
najlepiej" jak zmieniać swoje stany. Dzięki temu nie możemy nic nieopatrznie
popsuć, co więcej nie możemy zażądać od obiektu usługi, której on nie
udostępnia.
Dane (atrybuty) są (powinny być) ukryte i są traktowane jako nierozdzielna całość z
usługami - metodami.
Nazywa się to hermetyzacją i oznacza znaczne
zwiększenie odporności programu na błędy.
Podejście obiektowe umożliwia ponowne wykorzystanie już gotowych klas przy
tworzeniu klas nowych, co znacznie oszczędza pracę przy kodowaniu, a także
chroni przed błędami.
Jest to również odzwierciedlenie rzeczywistych sytuacji.
Np. komputer jest niewątpliwie urządzeniem elektrycznym. Jest obiektem klasy
ElDev. Ale komputery (oprócz określonych w klasie ElDev atrybutów: wysokość,
szerokość, stan: włączony-wyłączony) mają jakieś swoje specyficzne,
wyspecjalizowane cechy.
Stanowią więc podklasę klasy urządzeń elektrycznych.
Tak jest w rzeczywistości. A w programie możemy to odzwierciedlić za pomocą
koncepcji dziedziczenia klas. Klasa dziedzicząca inną przejmuje jej
właściwości i ew. dodaje własne, wyspecjalizowane. Dzięki temu w klasie
dziedziczącej możemy skupić się na specyficznych cechach jej obiektów, wiedząc,
że podstawowe atrybuty i funkcjonalność zostały już określone w klasie
dziedziczonej.
Np. tworząc klasę Komputer, dziedziczącą klasę urządzeń elektrycznych nie
musimy od nowa zapisywać wszelkich cech i operacji na urządzeniu elektrycznym
(np. nie musimy oprogramowywać metod on() czy off()). Musimy tylko dodać cechy
wyspecjalizowane np. dla komputera – usługę wykonania jakiegoś programu.
Oczywiście program będzie obiektem klasy Program, a w komunikacie do
obiektu-komputera powinniśmy podać jako argument obiekt-program do
wykonania.
Dziedziczenie klasy ElDev przez klasę Komputer i dostarczenie nowej usługi
(metody) run możemy zapisać (jeszcze nie w w Javie) tak (słowo extends oznacza tu
dziedziczenie):
class Komputer extends ElDev {
method run(Program p)
if (isOn()) wykonanie_programu_p;
}
a następnie użyć nowej klasy Komputer w programie:
Komputer a, b, c;
Program x, y, z;
...
a.on(); a.run(x); ... a.off();
Tyle wprowadzenia, o charakterze bardzo wstępnym i raczej intuicyjnym.
Chodziło w nim o to, by zrozumieć pewne ważne cechy podejścia obiektowego na
poziomie ogólnym, nie wchodząc jeszcze w szczegóły składni Javy. Dokładnie
cechy podejścia obiektowego będziemy omawiać w dalszych wykładach.
Już za chwilę jednak zobaczymy – przy okazji aplikacji powitalnych - w jaki
sposób w Javie operuje się na obiektach.
5. Aplikacja powitalna
W tym podpunkcie przedstawiony zostanie program "powitalny". Zawiera
on elementy, które szczegółowo będą omawiane znacznie później.
Proszę się więc nie zrażać, jeśli coś w opisie tego programu będzie niezrozumiałe.
Warto na niego jednak spojrzeć, choćby po to, by przekonać się, że programując
w Javie posługujemy się obiektami (mamy więc dodatkową ilustrację poprzednich
treści).
Jest to również zachęta do nauki. Zobaczymy tu bowiem, że w Javie bardzo
łatwo tworzy się znane, lubiane, codziennie "używane" elementy tzw. graficznego
interfejsu użytkownika - czyli sposobu komunikowania się z programami za
pomocą okienek, przycisków, itp.
Program w Javie jest zawsze zestawem klas. Czyli na pewno w pliku źródłowym musimy zdefiniować jakąś klasę.
Szczególnym rodzajem programu w Javie jest aplikacja
Działanie aplikacji zaczyna się od metody:
public static void
main(String[] args)
umieszczonej w jednej z klas pliku źródłowego.
Napiszemy szybko metodę main:
import javax.swing.*;
public class JavaWelcome {
public static void main(String[] args) {
JFrame frame = new JFrame("Powitanie"); // 1
String htmlText = "<html><FONT SIZE=+3>" + // 2
"Witaj<font color=red><b> Javo!</b></font><br>" +
"<font color=blue>... A witaj!</font></html>";
Icon icon = new ImageIcon("java_logo.png"); // 3
JLabel label = new JLabel(htmlText, icon, JLabel.CENTER); // 4
frame.add(label); // 5
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); // 6
frame.pack(); // 7
frame.setLocationRelativeTo(null); // 8
frame.setVisible(true); // 9
}
}Co tu się dzieje?
Po kolei, w kolejnych punktach zaznaczonych z prawej strony wydruku:
- Tworzymy okno frame - obiekt klasy JFrame - z tytułem "Powitanie"
- Tworzymy napis htmlText
- obiekt klasy String. - który będzie pokazany w oknie; tekst jest
formatowany (wielkość i kolor pisma) za pomocą znaczników HTML.
- Pobieramy obrazek z pliku java_logo.png; będziemy do niego mieli dostęp za pomocą zmiennej icon.
- Tworzymy etykietę label (klasa JLabel), w której będzie umieszczony obrazek i wycentrowany tekst.
- Do okna dodajemy etykietę.
- Dla okna frame ustalamy, że domyślnie jego zamknięcie ma spowodować zakończenie działania aplikacji.
- Pakujemy okno, tzn. prosimy o takie ustalenie jego rozmiarów, aby były ono optymalne dla pokazania umieszczonej w nim etykiety.
- Ustalamy położenie okna: wycentrowane w obszarze pulpitu.
- Pokazujemy okno.
Po uruchomieniu tego programu uzyskamy w centrum pulpitu taki oto obrazek:

Uwaga:
widoczne logo Javy nawiązuje do pochodzenia nazwy tego języka. James
Gossling nazwał go na cześć swojego ulubionego gatunku kawy - dlatego
niemal wszystkie loga ukazują filiżankę kawy.
Zobacz demo działania programu powitalnego:
A teraz pora zaczynać od podstaw. Zanim jednak zaczniemy - zainstalujmy
środowisko Javy i spróbujmy uruchomić w nim oba przedstawione wyżej programiki
oraz napisać najpierwszy, najprostszy, ale własny program.
6. Instalacja Javy, pierwszy program i kilka elementów składni
Najpierw należy pobrać aktualną wersję JDK ze strony java.sun.com (wybrać z prawej strony Popular Downloads: Java SE).
Aktualną finalną wersją (stan na koniec sierpnia 2008) jest "JDK 6 Update 7" i ten właśnie link należy wybrać (proszę nie wybierać JDK with NetBeans lub JDK with Java EE lub Java Runtime Environment).
Oddzielnie należy pobrać dokumentację - link: Java SE 6 Documentation.
Program
instalacyjny JDK poprowadzi nas za rękę. Po instalacji JDK powinniśmy
do katalogu instalacyjnego JDK rozpakować pobrane archiwum z
dokumentacją.
Gotowe, można przystępować do pracy.
Pisząc
programy możemy korzystać ze zintegrowanych środowisk programowania
(IDE) - takich jak Eclipse, NetBeans, IntelliJ czy JCreator - które
integrują edycję, kompilację i uruchamianie programów, służąc też
użytkownikowi pomocą w pisaniu tekstu programu (podpowiedzi,
autouzupełnianie) i wykrywani błędów.
Można też po prostu używać wybranego edytora tekstowego i w sesjach znakowych (terminalach, oknach
DOS) uruchamiać kompilator i maszynę wirtualną Javy.
Jeśli nie korzystamy z IDE to:
- powinniśmy zapewnić, by katalog, w którym program instalacyjny umieścił
kompilator Javy (javac.exe) oraz interpreter - maszynę wirtualną Javy (java.exe)
znajdował się na ścieżce dostępu (PATH),
- program źródłowy Javy zapisujemy w pliku źródłowym za pomocą dowolnego edytora (np. w pliku Test.java),
- plik źródłowy np. Test.java kompilujemy za pomocą polecenia javac (np. javac Test.java)
- w rezultacie kompilacji otrzymamy plik(i) klasowe (z rozszerzeniem .class) (np. Test.class)
- wykonanie programu uruchamiamy za pomocą polecenia java (np. java Test)
Uwagi.
- Program źródłowy może być zapisany w wielu plikach z rozszerzeniem
.java; w każdym pliku musi występować pełna definicja jednej lub kilku klas,
- Nazwa pliku powinna być dokładnie (a więc uwzględniając wielkie i małe
litery) taka sama jak nazwa publicznej klasy zdefiniowanej w tym pliku (czyli klasy ze specyfikatorem public; co
to jest klasa publiczna - dowiemy się później). W pliku źródłowym może wystąpić tylko jedna klasa publiczna.
- Uruchamiając maszynę wirtualną (polecenie java) podajemy jako argument nazwę klasy, w której jest
zdefiniowana metoda main. Nie podajemy rozszerzenia pliku (".class") czyli:
java Test a nie java Test.class
Nasz pierwszy program może wyglądać tak:
public class Test {
public static void main( String[] args ) {
System.out.println( "Dzień dobry!");
}
}
Komentarze:
- Słowa kluczowe języka (mające specjalne znaczenie i
zarezerwowane, czyli takie, których nie można używać poza ich
kontekstem np. dla nazywania zmiennych klas czy metod) zostały
pokazane na niebiesko.
- Na razie nie przejmujemy się dziwnymi słowami (public, void itp.). Dowiemy się o nich z następnych wykładów.
- Program w Javie zawsze składa się z definicji klas. Tu mamy zdefiniowaną
jedną klasę o nazwie Test. Do definiowania klas służy słowo kluczowe class.
Po nim podajemy nazwę klasy (tu nazywa się Test ale można nazwać ją
inaczej). Samą definicję klasy podajemy w następujących potem nawiasach
klamrowych. Nawiasy te zaznaczono na czerwono.
- W klasie Test została zdefiniowana metoda o nazwie main (czyli coś
bardzo podobnego do pojęcia funkcji lub procedury, znanego w innych językach).
- Kod metody zapisujemy w nawiasach klamrowych (zielone).
- Wykonanie programu zacznie się właśnie od metody main, ale musi ona
mieć dokładnie taki nagłówek jak podano (public static void main(String[]
args)), z tym wyjątkiem, że słowo args możemy zastąpić innym (jest to nazwa
zmiennej).
- Jak widać, metoda main ma parametr o nazwie args. Oznacza
on tablicę łańcuchów znakowych (obiektów typu String) - która zawiera argumenty
przekazane przy uruchomieniu programu (np. podane w wierszu poleceń sesji
znakowej). W naszym programie nie korzystamy z tych argumentów.
- W metodzie main wywołujemy metodę println (już dla nas
przygotowaną i znajdującą się w "bibliotece" standardowych klas języka;
zatem użyjemy tej własnej nazwy metody, a nie jakiejś dowolnej).
Metoda println wyprowadza przekazany jej argument na konsolę. Wywołanie
metody stanowi
wyrażenie. Kończąc je średnikiem przekształciliśmy je w instrukcję programu
"do wykonania". W Javie średniki obowiązkowo kończą instrukcje.
- Na razie nie przejmujemy się tym po co i dlaczego trzeba pisać System.out.println. Dowiemy się tego później.
- Argument podany w wywołaniu metody println - to literał łańcuchowy
(napis podany literalnie).
- Zapisany program musimy skompilować: javac Test.java (lub środkami IDE)
- W rezultacie otrzymamy plik Test.class
- Uruchamiamy program ( w IDE lub pisząc: java Test). Program wyprowadzi na konsolę napis "Dzień dobry!"
Trzeba jednak pamiętać, że obowiązuje nas przejrzysty styl programowania. Elementy stylu będziemy poznawać sukcesywnie przy omawianiu języka. W omawianym
przykładzie zastosowaliśmy wcięcia i odpowiednie rozmieszczenie nawiasów
klamrowych
Przy kompilacji programu znaki spacji, tabulacji, końca wiersza
(tzw. whitespaces) występujące pomiędzy konstrukcjami składniowymi
języka (takimi jak nazwy zmiennych, metod, słowa kluczowe, literały itp.)
są pomijane. Zatem możemy dowolnie "formatować" kod programu (dzielić na
wiersze, umieszczać dodatkowe spacje np. po nawiasie otwierającym listę argumentów
wywołania metody).
Przy kompilacji pomijane są również komentarze.
W Javie mamy trzy rodzaje komentarzy:
- teksty umieszczone w jednym wierszu programu po znakach // (komentarze jednowierszowe; cały tekst po znakach // do końca wiersza traktowany jest jako komentarz)
- teksty umieszczone pomiędzy znakami /* i */ (teksty te mogą obejmować kilka wierszy)
- teksty umieszczone pomiędzy znakami /** i */ (komentarze dokumentacyjne,
które są przetwarzane przez oprogramowanie tworzące dokumentację, np. javadoc;
mogą obejmować kilka wierszy),
Przykład:
/**
Klasa TestComm pokazuje
użycie komentarzy
(to jest komentarz dokumentacyjny)
*/
public class TestComm {
/*
to jest komentarz
wielowierszowy
*/
/* to też jest
komentarz */
// a to komentarz jednowierszowy
public static void main( String[] args ) {
// i tu też komentarz
System.out.println( "Zob. komentarze" ); // i tu też
}
}
Oczywiście, komentarze nie mogą rozdzielać jednolitych konstrukcji składniowych
(np. znajdować się "w środku" nazwy zmiennej czy metody).
Nazwy
zmiennych, metod, klas nie są całkiem dowolne. Mogą zawierać litery
(duże lub małe), cyfry oraz znaki _ i $. Przy czym nie mogą zaczynać
się do cyfry.
Najlepiej przyjąć, że nazwy klas, metod, zmiennych zaczynamy od litery, a także:
- nie używać w nazwach znaków _ oraz $,
- ograniczać użycie cyfr,
- stosować sensowne, coś znaczące nazwy.
W trakcie kompilacji programu sprawdzana jest jego składniowa poprawność.
Kompilacja może więc zakończyć się niepowodzeniem (wtedy nie dostaniemy pliku
.class), a kompilator powiadomi nas o tym gdzie i jakie błędy wystąpiły.
Np. gdybyśmy w naszym programie testowym zapomnieli zamknąć nawias okrągły w wywołaniu metody println:
System.out.println( "Dzień dobry!";
to kompilator wyprowadziłby następujący komunikat:
Test.java:4: ')' expected
System.out.println( "Dzień dobry!";
^
1 error
Mamy tu wyraźnie powiedziane, że błąd wystąpił w 4 wierszu pliku Test.java,
że oczekiwany był okrągły nawias zamykający (a zabrakło go), przy czym miejsce
w którym wystąpił problem wskazane jest znakiem ^.
Nie zawsze komunikaty z kompilacji będą tak klarowne. Czasami błąd nie będzie
dokładnie zlokalizowany (informacja będzie wskazywać na inny wiersz niż ten,
w którym wystąpił błąd). Musimy wtedy głębiej zastanowić się nad przyczyną
błędu i przeanalizować poprawność poprzedzających wierszy programu.
Program, który przeszedł etap kompilacji jest poprawny składniowo, ale jego
wykonanie niekoniecznie musi być poprawne. Mogą w nim bowiem wystąpić tzw.
błędy fazy wykonania.
Na przykład, poniższy program skompiluje się bezbłędnie
public class TestRTE {
static String napis;
public static void main( String[] args ) {
System.out.println( napis.length() );
}
ale przy jego wykonaniu wystąpi błąd:
Exception in thread "main" java.lang.NullPointerException
at TestRTE.main(TestRTE.java:7)
bowiem próbujemy pobrać długość łańcucha znakowego (napisu), który
nie istnieje. Zresztą przyczyna nie jest tu istotna, teraz ważne jest tylko
byśmy wiedzieli, że błąd wykonania może wystąpić mimo pomyślnej kompilacji.
Zwróćmy uwagę, że Java nazywa takie błędy wyjątkami (exception) i że JVM podaje jaki rodzaj wyjątku wystąpił, w jakiej klasie i w jakiej metodzie i który wiersz w programie go spowodował.
W końcu warto jeszcze raz podkreślić oczywistą prawdę, że nawet jeśli program
nie ma błędów składniowych (kompilacja pomyślna) i nie występują błędy fazy
wykonania - to jeszcze nie znaczy, że jest on poprawny.
Na przykład taki program przejdzie pomyślnie kompilację i wykona się bez błędów (zgłaszanych przez JVM):
public class TestBad {
public static void main( String[] args ) {
System.out.println("2 + 2 = " + (2 - 2) );
}
}
2 + 2 = 0
ale wyprowadzi (raczej) niepoprawny wynik, bo wygląda na to,
że programista pomylił się i zamiast operatora + użył operatora -.
Takie błędy są najtrudniejsze do wykrycia, a ich unikanie (czy walka z nimi) wymaga:
- tworzenia poprawnych algorytmów
- starannego ich zapisu w języku programowania
- pieczołowitego testowania gotowego programu, przy różnych danych wejściowych
i oceny czy wyniki podawane przez program są poprawne
7. Praca z Eclipse
Jednym z lepszych zintegrowanych środowisk programowania (IDE) jest Eclipse. Będziemy z niego korzystać w tym kursie.
Eclipse pobrać można ze strony eclipse.org. Pobrane archiwum wystarczy rozpakować na dysku i już będziemy gotowi do pracy.
Na starcie Eclipse wybieramy Workspace - czyli obszar roboczy. Jest to wybrany przez nas katalog, w którym będą nasze programy. Workspace zawiera projekty.
Programy umieszczane są w projektach. Jak już wiemy, programy to klasy,
Eclipse pomaga nam tworzyć klasy, generując pewne fragmenty kodu
automatycznie, kiedy wybieramy opcję "New Java class".
Zatem sekwencja działań jest następująca:
- uruchomić Eclipse,
- wybrać Workspace,
- utworzyć nowy projekt ("Java project"),
- w danym projekcie utworzyć nową klasę ("Java class").
Ilustrują to poniższe rysunki.
1. Wybór workspace (należy podać katalog):

2. Przycisk obrazkowy "Java project" - tworzenie nowego projektu:

3. Należy podać nazwę projektu i zaznaczyć zaznaczone na rysunku opcje;

4. Projekt utworzony, wybieramy przycisk obrazkowy "Java Class":

5. Podajemy nazwę klasy (dobrze jest też podać nazwę pakietu) oraz zaznaczamy opcję public static void main(...):

6. Gotowe. Możemy pisać program.

Co do szczegółów - można zobaczyć prezentację multimedialną:
PREZENTACJA TWORZENIA PROJEKTU
Szczegóły formatowania programów można zmienić w preferencjach (Window-Preferences) - zob. poniższy rysunek.
Jest również ważne, aby ustawić odpowiednią wersję kompilatora (jeśli nie jest ustawiona).
Eclipse posługuje się wewnętrznym kompilatorem i kod kompilowany jest, a błędy zgłaszane, "na żywo", w miarę pisania.
Ilustruje to poniższa prezentacja multimedialna, w której pokazano również jak uruchomić program.
PREZENTACJA PISANIA I URUCHAMIANIA PROGRAMU.
8. Podsumowanie
W wykładzie poruszono następujące kwestie:
- co to jest program?
- do czego służą programy?
- w jaki sposób programy reprezentowane są w komputerze i jak są wykonywane?
- do czego służą assemblery i dlaczego się pojawiły?
- czym różnią się języki "wysokiego poziomu" od assemblerów?
- na czym polega programowanie?
- co to jest algorytm?
- w jaki sposób możemy zapisywać i obrazować algorytmy?
- jak budować schematy blokowe?
- co to jest pseudo-kod i do czego służy?
- jak zapisywać algorytmy w pseudo-kodzie?
- jakie są rodzaje języków programowania?
- na czym polega kompilacja programu?
- na czym polega interpretacja programu?
- jak wygląda proces programowania - od sformułowania problemu do rozwiązania po uzyskanie działającego programu?
Niejako "z lotu ptaka" zapoznaliśmy się też z cechami środowiska Javy.
Ponieważ jest to język obiektowy zaczęliśmy również poznawać koncepcje związane z programowaniem obiektowym.
I wreszcie najważniejsze: mamy już zainstalowaną Javę, potrafimy skompilować
i uruchomić program - możemy wobec tego spokojnie przystępować do systematycznej
nauki.