Przejście do pierwszej części wykładu
Przejdziemy teraz do omówienia bardziej skomplikowanych instrukcji SELECT obejmujących złączenia tabel, grupowanie wierszy i podzapytania.
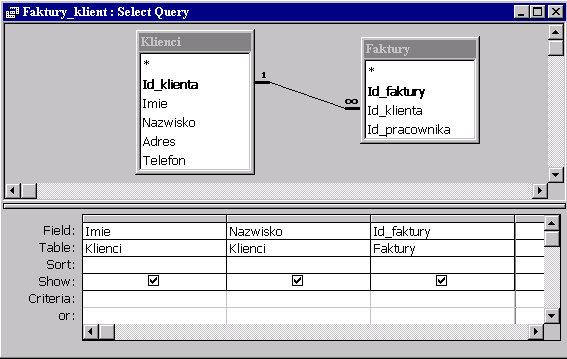
Oto typowe zadanie na złączenie.
| Wyświetl klientów załączając numery złożonych przez nich zamówień. |
Zastosujemy metodę, którą można stosować i w innych przypadkach. Mianowicie zaprojektujemy najpierw kwerendę wybierającą używając siatki kwerendy w widoku Projekt – tak jak to robiliśmy na wykładzie 2. Następnie przechodząc do widoku SQL otrzymamy szukaną instrukcję SQL.
|
|
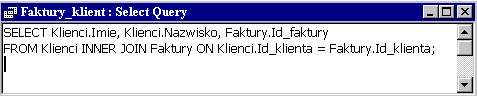
Widok SQL odkrywa nam odpowiadającą instrukcję SELECT:
|
Mamy do czynienia ze złączeniem wewnętrznym INNER JOIN tabel Klienci i Faktury - z warunkiem złączenia postaci klucz_główny=klucz_obcy. Oto konstrukcja złączenia dwóch tabel występująca w klauzuli FROM:
Tabela1 INNER JOIN Tabela2 ON Tabela1.kolumna1 =
Tabela2.kolumna2 |
Nazwy kolumn są poprzedzane nazwami tabel. W przypadku nazwy Id_klienta zapewnia to jednoznaczność, ponieważ ta sama nazwa jest użyta jako nazwa kolumny w dwóch tabelach.
Złączenie wewnętrzne można określić nie posługując się operatorem INNER JOIN. Mianowicie warunek złączenia dwóch tabel zapisujemy w klauzuli WHERE zamiast we FROM.
FROM Tabela1, Tabela2 |
Oto złączenie tabel Klienci i Faktury:
SELECT Klienci.Imie, Klienci.Nazwisko, Faktury.Id_faktury |
| Dla każdego towaru podaj jego nazwę, cenę oraz identyfikatory faktur, w których występuje wraz z zamówioną jego ilością. |
Kolejne zadanie:
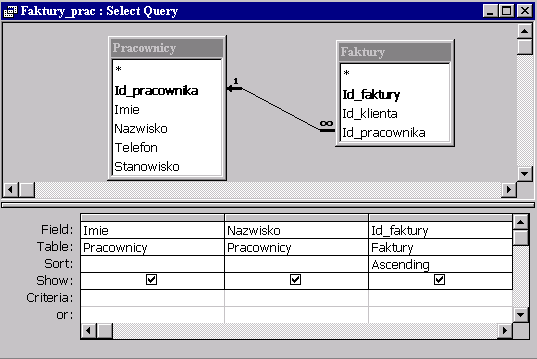
| Wyświetl pracowników razem z przyjętymi przez nich zamówieniami. |
Użyjemy, jak poprzednio, siatki kwerendy do zdefiniowania tego zapytania.
|
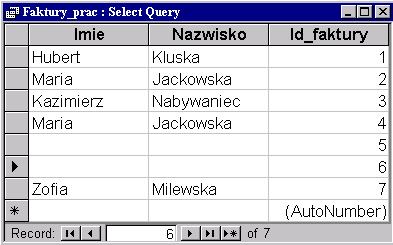
Złączenie między pracownikami i zamówieniami jest zewnętrzne tzn. przy złączaniu uwzględniamy też faktury, którym nie został przypisany żaden pracownik. Tym wierszom odpowiadają puste pola Imię i Nazwisko tabeli będącej wynikiem zapytania.
|
Widok SQL odkrywa nam odpowiadającą instrukcję SELECT:

|
Pojawia się słowo kluczowe RIGHT JOIN sygnalizujące złączenie zewnętrzne. Oto konstrukcja złączenia zewnętrznego dwóch tabel występująca w kaluzuli FROM:
Tabela1 RIGHT JOIN Tabela2 ON Tabela1.kolumna1 = Tabela2.kolumna2 |
Nazwy kolumn są poprzedzane nazwami tabel. W przypadku nazwy Id_klienta zapewnia to jednoznaczność, ponieważ ta sama nazwa jest użyta jako nazwa kolumny w obu tabelach.
Reasumując wyrażenie Tabela1 RIGHT JOIN Tabela2 określa, że mają być wypisane wszystkie wiersze tabeli Tabela2 (stojącej po prawej stronie) niezależnie od tego czy istnieją dla nich odpowiadające im wiersze tabeli Tabela 1. Analogicznie, dla LEFT JOIN są wypisane wszystkie wiersze tabeli Tabela1 (stojącej po lewej stronie)
DISTINCT, DISTINCTROW
Operator DISTINCTROW nie występuje w Standardzie SQL - omówimy go za chwilę. Operator DISTINCT występował w jednym z naszych pierwszych zapytań - oznacza on eliminację powtarzających się wierszy.
Aby zobaczyć różnicę działania, porównamy ze sobą wynik zapytania (tego samego złączenia wewnętrznego) w trzech wersjach: bez zastosowania operatorów DISTINCTROW i DISTINCT, z DISTINCTROW, z DISTINCT. W każdym z tych trzech przypadków otrzymujemy inny wynik!
1. Instrukcja:
SELECT Klienci.Imie, Klienci.Nazwisko |
zwraca wynik z powtórzeniami:
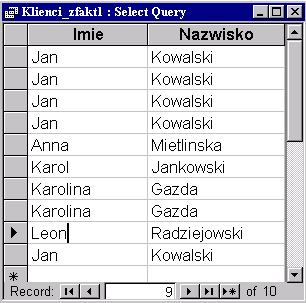
|
2. Instrukcja:
SELECT DISTINCTROW Klienci.Imie,
Klienci.Nazwisko |
zwraca wynik, w którym mamy do czynienia z jednym powtórzeniem:
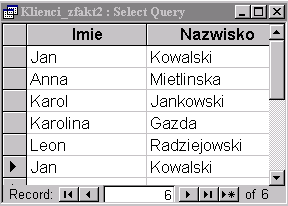
|
Mianowicie operator DISTINCTROW dla każdego wiersza tabeli Klienci tworzy osobny wiersz wyniku. W tabeli Klienci występuje dwóch różnych klientów nazywających się "Jan Kowalski" - o różnych identyfikatorach. Każdy z nich ma co najmniej jedną fakturę. Zatem w wyniku dostajemy dwa różne wiersze w zależności, o którego klienta chodzi.
3. Instrukcja:
SELECT DISTINCT Klienci.Imie,
Klienci.Nazwisko |
zwraca wynik w ogóle bez powtórzeń:
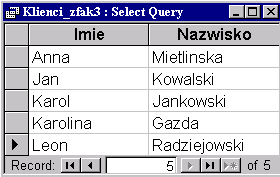
|
Teraz eliminujemy wszystkie powtarzające się wiersze wynikowe i dlatego dostajemy tylko jeden wiersz z Janem Kowalskim.
Gdybyśmy w wierszu wynikowym dołączyli kolumnę Id_klienta, wówczas operatory DISTINCT i DISTINCTROW dałyby ten sam rezultat – bez powtórzeń.
Jest jeszcze jeden specjalny rodzaj złączenia mianowicie samozłączenie tabeli czyli złączenie tabeli z nią samą przy pomocy związku klucz obcy-klucz główny (jest to związek rekurencyjny omawiany na wykładzie 3). Rozważmy związek pokrewieństwa między osobami reprezentowany przy pomocy tabeli, w której dla każdej osoby podajemy informację o jej ojcu i matce. Mamy więc do czynienia z dwoma kluczami obcymi Ojciec i Matka odwołującymi się do klucza głównego w tej samej tabeli. Na diagramie tabel w MS Access trzeba wprowadzić kopie tej samej tabeli, aby określić jej samozłączenia - inaczej niż w MS Visio.
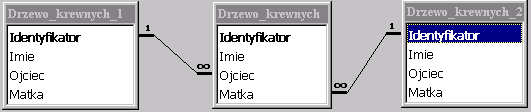
|
Interesuje nas tabelka, w której dla każdej osoby będą podane imiona jej ojca i matki.
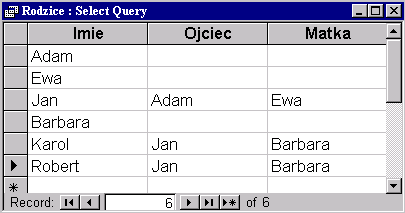
|
Aby zdefiniować takie zapytanie, wprowadzamy
trzy kopie tej samej tabeli:
D – oznacza wiersz osoby, dla której określamy
jej rodziców,
D1 – oznacza wiersz ojca,
D2 – oznacza wiersz matki.
Aliasy D, D1, D2 wprowadzamy w klauzuli FROM a nazwy Ojciec i Matka w klauzuli SELECT.

|
Zapytanie to moglibyśmy zdefiniować również w siatce kwerendy – wprowadzając trzy kopie tej samej tabeli i dwa związki – ze złączeniem zewnętrznym, aby uwzględnić osoby, które nie mają określonego ojca lub matki. Gdybyśmy zamiast operatorów RIGHT JOIN użyli operatorów INNER JOIN wypisana zostałaby informacja o osobach, które mają określonego zarówno ojca jak i matkę.
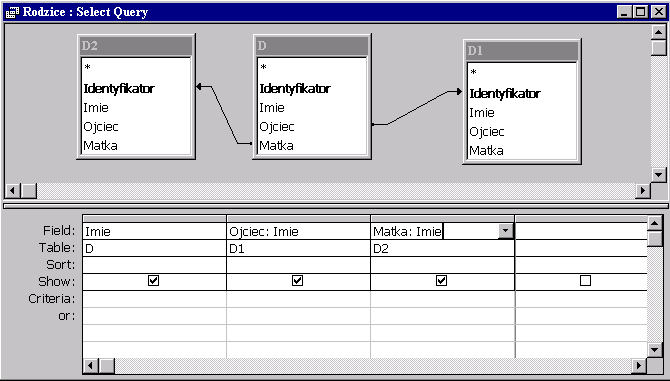
|
Teraz zadanie do rozwiązania dla czytelnika:
| Dla każdej osoby wyznacz jej dziadków. |
Specjalną rolę w zapytaniach pełnią funkcje sumaryczne takie jak COUNT(), MAX(), MIN(), SUM(), AVG() obliczające odpowiednio liczbę wartości, maksymalną wartość, minimalną wartość, sumę wartości, wartość średnią – z wartości wyrażenia będącego argumentem funkcji po wszystkich wierszach. Na ogół jako argumentu używamy nazwy kolumny. Na przykład instrukcja:
SELECT Count(Id_towaru), Min(Cena),
Max(Cena), Sum(Cena), Avg(Cena) |
wypisze w jednym wierszu: ile jest różnych towarów w tabeli Towary, jaka jest ich minimalna cena, jaka jest ich maksymalna cena, jaka jest suma cen i jaka jest średnia wartość cen towarów zapisanych w tabeli Towary.
| Wprowadź utworzone zapytanie do MS Access i zaobserwuj jaką postać przyjmie w widoku siatki zapytania. |
Kolejna omawiana przez nas klauzula instrukcji SELECT to GROUP BY. Umożliwia ona podział na grupy wierszy i podsumowywanie grup. Najpierw rozważmy zadanie:
| Dla każdego klienta wyznacz ile złożył zamówień. |
Skorzystajmy jak poprzednio z siatki zapytania rozszerzając ją o nowy wiersz z podsumowaniami - z menu "Widok -> Sumy" ("View -> Totals").
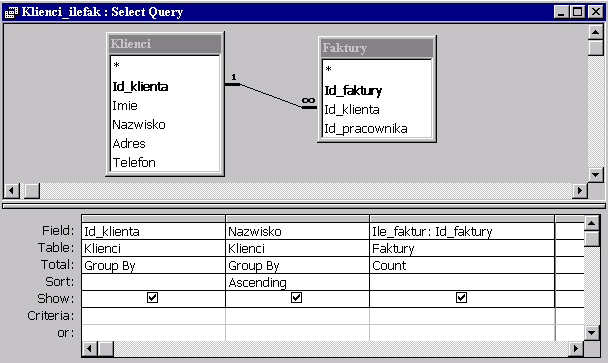
|
Dla kolumn Id_klienta i Nazwisko wybieramy "Grupuj" ("Group By") a dla kolumny Id_faktury wybieramy funkcję podsumowującą "Zlicz" ("Count") i poprzedzamy ją identyfikatorem Ile_faktur. W wyniku otrzymujemy dla każdego klienta, ile ma faktur:
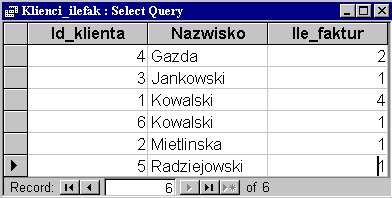
|
Odsłaniamy teraz widok SQL naszego zapytania:
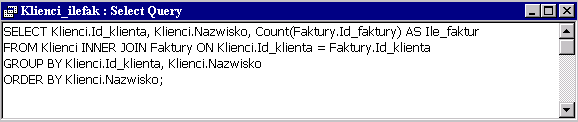
|
Zaraz po klauzuli FROM pojawiła się nowa klauzula GROUP BY nakazująca pogrupowanie wierszy uzyskanych w wyniku złączenia INNER JOIN i filtrowania WHERE. Specyfikacja wartości w klauzuli SELECT dotyczy podziału na grupy określonego w klauzuli GROUP BY. W klauzuli SELECT mogą występować kolumny z klauzuli GROUP BY, jak również funkcje podsumowujące dla kolumn, które nie występują w klauzuli GROUP BY.
GROUP BY kolumna, .... |
Teraz zadanie do rozwiązania dla czytelnika:
| Dla każdego towaru podaj jego nazwę, cenę oraz liczbę faktur, w których występuje wraz z łączną jego wartością we wszystkich zamówieniach. |
Kolejne zadanie:
| Dla każdego pracownika wyznacz ile wypisał faktur. |
Zastosujemy teraz złączenie zewnętrzne. Przy złączaniu tabeli Pracownicy i Faktury będziemy teraz uwzględniać również pracowników, którzy nie przyjęli żadnej faktury (ale nie będziemy brać pod uwagę faktur, do których nie został przypisany żaden pracownik). Zaczynamy od siatki zapytania:
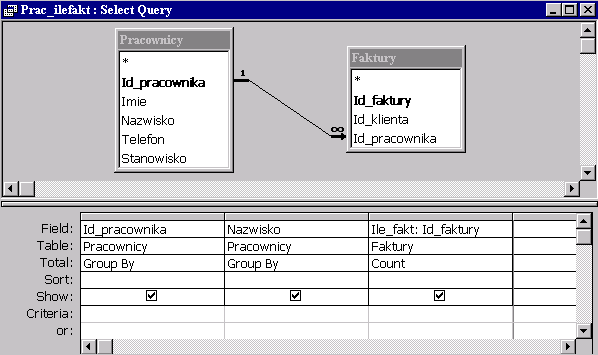
|
W tabeli wynikowej występuje nowo dodany dyrektor Sapieha, który nie przyjął żadnej faktury - w kolumnie Ile_faktur występuje 0.
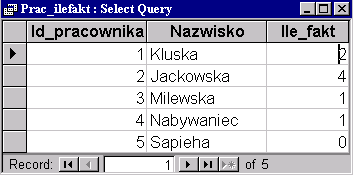
|
Wreszcie widok SQL:

|
Odpowiednikiem klauzuli WHERE ograniczającej zbiór rozpatrywanych wierszy – dla klauzuli GROUP BY jest klauzula HAVING.
GROUP BY kolumna, .... |
Warunek klauzuli HAVING dotyczy grup a nie samych wierszy z tabel. Mogą w nim występować kolumny grupujące z listy GROUP BY lub funkcje sumaryczne w zastosowaniu do pozostałych kolumn – nie występujących na liście GROUP BY. Na przykład w ostatnim przykładzie możemy ograniczyć wypisywane wiersze do grup, które dotyczą pracowników, którzy wydali co najmniej trzy faktury.
SELECT Pracownicy.Id_pracownika, Pracownicy.Nazwisko, Count(Faktury.Id_faktury) AS Ile_fakt |
Zasady wykonywania zapytania grupującego
1. Jeśli występuje operator algebraiczny UNION, to powtórz poniższe kroki 2-7 dla każdego
jego składnika.
2. Oblicz tabele w klauzuli FROM wykonując operacje INNER JOIN, LEFT JOIN i
RIGHT JOIN. Rozważ kolejno wszystkie kombinacje ich wierszy.
3. Do każdej kombinacji wierszy zastosuj warunek WHERE. Pozostaw tylko
kombinacje wierszy dające wartość
True
- usuwając wiersze dające False lub Null.
4. Podziel pozostające kombinacje wierszy na grupy.
5. Do każdej grupy zastosuj warunek w klauzuli HAVING. Pozostaw tylko grupy, dla których wartość warunku jest
True.
6. Dla każdej pozostającej grupy wierszy oblicz wartości wyrażeń na liście SELECT.
7. Jeśli po SELECT występuje DISTINCT (lub DISTINCTROW), usuń duplikaty wśród wynikowych wierszy.
8. Jeśli trzeba, zastosuj operator algebraiczny UNION.
9. Jeśli występuje klauzula ORDER BY, wykonaj sortowanie wynikowych wierszy zgodnie ze specyfikacją.
Przedstawiona semantyka zapytania ma charakter koncepcyjny. W rzeczywistości system
bazodanowy wykonuje zapytanie w bardziej efektywny sposób unikając na przykład liczenia wszystkich możliwych kombinacji wierszy tabel
obliczonych w klauzuli FROM. Na wykładach przedmiotu „Systemy baz danych” zostaną przedstawione algorytmy wykonywania zapytań przez system bazodanowy.