Wykład 16
Języki zapytań do XML
Autor: Krzysztof Stencel
16.1 Wprowadzenie
Format XML [XML04] coraz szerzej
rozpowszechnia się w Sieci. Z każdym dniem więcej i więcej dokumentów jest prezentowanych
i składowanych w tej właśnie postaci. Pojawiły się także bazy danych do
przechowywania dokumentów XML. To wszystko sprawiło, że zaproponowano wiele
nowatorskich języków służących do wydobywania informacji z dokumentów XML. Była
to odpowiedź świata nauki i przemysłu na wyłaniające się zapotrzebowanie na
język zapytań do przetwarzania dokumentów w formacie XML.
Dotychczas w ramach World Wide Web
Consortium (W3C) nie dopracowano się jeszcze standardu takiego języka zapytań.
Obecnie wciąż trwają nad nim prace. Największe szanse na uzyskanie rekomendacji
W3C ma XQuery [XQ03], który jest głównym tematem tego wykładu. Przestawimy
także krótki przegląd zaproponowanych dotychczas języków zapytań XML. W
kwietniu 2004 firma Oracle ogłosiła, że w jednej z następnych wersji bazy
Oracle 10g pojawi się implementacja XQuery jako podstawowy mechanizm
dostępu do zawartości dokumentów XML.
W ramach W3C opracowano język
transformacji XSLT [XSLT99], który można by uznać za język zapytań. Jedno
przekształcenie XSLT przetwarza jednak tylko jeden dokument XML, a w ramach
zapytań chcielibyśmy korzystać na przykład ze złączeń. Niezbędna jest więc
możliwość przetwarzania wielu dokumentów w jednym zapytaniu.
W punkcie 16.2 przedstawimy przykładowy
dokument XML, który posłuży do ilustracji naszych rozważań. W punkcie 16.3
dokonamy (niepełnego) przeglądu innych niż XQuery języków zapytań do XML. Punkt
16.4 jest poświęcony XPath. W następnych punktach omówiono XQuery: p. 16.5
zawiera podstawy; p. 16.6 to opis pętli FLWOR; tematem p. 16.7 są instrukcje
warunkowe i kwantyfikatory; p. 16.8 zawiera informacje o udogodnieniach do
definiowania funkcji, a w p. 16.9 opisano system kontroli typów XQuery. Ostatni
punkt (16.10) to spis literatury związanej z językami zapytań do XML.
16.2 Przykładowy dokument XML
Wszystkie wzmiankowane języki zapytań będą ilustrowane zapytaniami na następującym dokumencie XML.
<?xml version="1.0"
encoding="windows-1250" ?>
<książka>
<tytuł>
Bazy danych.
Projektowanie aplikacji na serwerze
</tytuł>
<autor>Lech Banachowski</autor>
<autor>Krzysztof
Stencel</autor>
<wydawnictwo>EXIT</wydawnictwo>
<rozdział
id="1">
<tytuł>Wprowadzenie
do tematyki baz danych</tytuł>
<porównaj
href="2.1"/>
<treść>Treść
rozdziału 1.</treść>
</rozdział>
<rozdział
id="2">
<tytuł>
SQL-język relacyjnych i
obiektowo-relacyjnych baz danych
</tytuł>
<punkt
id="2.1">
<tytuł>Podstawy</tytuł>
<punkt
id="2.1.standardowe">
<tytuł>Standardowe
typy danych</tytuł>
<treść>O
standardowych typach danych.</treść>
</punkt>
<treść>Podstawy SQL
są dość proste.</treść>
</punkt>
<treść>Structured
Query Language</treść>
</rozdział>
<rozdział
id="3">
<tytuł>Język SQL -
zaawansowane konstrukcje</tytuł>
<treść>Bardzo
zaawansowane konstrukcje.</treść>
</rozdział>
</książka>
Dokument ten jest zgodny z następującą
definicją typu dokumentu:
<!ELEMENT książka (tytuł, autor+, wydawnictwo, rozdział+)>
<!ELEMENT rozdział (tytuł, porównaj*, punkt*, treść))>
<!ELEMENT punkt (tytuł, porównaj*, punkt*, treść))>
<!ELEMENT autor (#PCDATA)>
<!ELEMENT treść (#PCDATA)>
<!ELEMENT tytuł (#PCDATA)>
<!ELEMENT wydawnictwo (#PCDATA)>
<!ELEMENT porównaj (EMPTY)>
<!ATTLIST
rozdział id ID #REQUIRED >
<!ATTLIST
punkt id ID #REQUIRED >
<!ATTLIST
porównaj href IDREF #IMPLIED >
16.3 Przegląd języków
W tym punkcie omówimy krótko kilka
interesujących języków zapytań dla XML oraz pokażemy, jak w każdym z tych
języków zapisać zapytanie o tytuły rozdziałów, które na dowolnym poziomie
zagnieżdżenia mają punkt o tytule Standardowe typy danych. Spodziewamy się odpowiedzi:
<tytuł>
SQL-język relacyjnych i
obiektowo-relacyjnych baz danych
</tytuł>
Zauważmy, że takiego zapytania nie da się wyrazić w standardowym SQL, ponieważ wymagałoby ono wykonania liczby złączeń, która nie jest znana w chwili pisania zapytania. Takie zapytania wymagają pewnych rozszerzeń, które pozwalają na wędrówki po drzewach (np. CONNECT BY w Oracle) lub na wyznaczanie punktów stałych (opcja WITH RECURSIVE z propozycji do standardu SQL).
W literaturze można znaleźć wiele artykułów z porównaniami języków zapytań dla XML (np. [BC00]). Dużo ciekawych informacji na temat tych języków można też znaleźć w książce wydanej w języku polskim [ABS01].
16.3.1 Lorel
Język Lorel [AQM97] opracowano w ramach
przedsięwzięcia LORE w Uniwersytecie Stanforda jako język zapytań dla danych
półstrukturalnych. Później dostosowano go także do przetwarzania dokumentów XML
[GMW99]. Prototypową implementację LORE, w którym działa Lorel można pobrać z
witryny http://www-db.stanford.edu/lore. Chociaż Lorel jest językiem składniowo
podobnym do SQL, ponieważ zawiera słynne frazy select-from-where, jednak
był on wzorowany na OQL ze standardu ODMG [ODMG00]. OQL jest językiem dla
strukturalnych obiektowych baz danych. Opracowując Lorela, jego autorzy musieli
dostosować się do półstrukturalnego modelu danych.
W Lorelu nasze przykładowe zapytanie zapisalibyśmy tak:
select
R.tytuł
from dokument.książka.rozdział R, R(.punkt)+.tytuł TP
where TP = "Standardowe typy danych";
Symbol dokument reprezentuje przykładowy dokument z p.
16.2.W tym zapytaniu zmienna R
przebiega wszystkie elementy rozdział będące potomkami elementu głównego książka. Dla ustalonego R wartość zmiennej TP przebiega wszystkie elementy tytuł, do których można dotrzeć przez ścieżkę
złożoną z dowolnej dodatniej liczby elementów punkt. Plus oznacza „jeden-lub-więcej”. Gdyby
użyto gwiazdki zamiast plusa, oznaczałoby to „zero-lub-więcej” i wtedy na
zmienną TP przypisano by także
element tytuł będący bezpośrednim
potomkiem elementu rozdział. To nie byłoby poprawne, ponieważ pytamy o tytuły rozdziałów a nie punktów. Lorel zawiera udogodnienia do pisania
dowolnych wyrażeń ścieżkowych. Element ścieżki może być też opcjonalny — stawia
się wówczas za nim pytajnik, który oznacza „zero-lub-jeden”.
16.3.2 XML-QL
Język XML-QL [DFF98] opracowano w
laboratoriach AT&T. Prototyp implementacji można ściągnąć z
http://www.research.att.com/sw/tools/xmlql/. Zapytania XML-QL składają się z
dwóch części: where i construct. W pierwszej części wskazuje się wzorce i
warunki, którym muszą odpowiadać wejściowe elementy dokumentu XML. Ta część
zawiera zmienne wolne, których wartości są określane w wyniku dopasowania tych
wzorców do zadanych dokumentów. Część where odgrywa w XML-QL taką samą rolę, jak w SQL from i where razem wzięte. Druga część zapytania (construct) odpowiada klauzuli select z SQL. Opisuje się w niej, jak
skonstruować odpowiedź na zapytanie na podstawie wartości zmiennych wolnych
ustalonych przez część where.
Zauważmy, że inaczej niż w wypadku SQL w XML-QL fraza construct występuje po where, co jest zgodne z intuicyjną kolejnością
wyliczania odpowiedzi na zapytanie.
W XML-QL nasze przykładowe zapytanie
zapisalibyśmy tak:
where
<książka>
<rozdział>
<tytuł> $TR
</>
<punkt+.tytuł> $TP
</>
</rozdział>
</książka> in
"dokument.xml",
$TP = "Standardowe typy
danych"
construct
<tytuł> $TR </tytuł>
Plik dokument.xml reprezentuje przykładowy dokument z p.
16.2.W tym dokumencie poszukujemy wzorca wymienionego w części where. Musi to by element rozdział w elemencie książka, który zawiera element tytuł i pewną gałąź złożoną z dowolnej
dodatniej liczby wystąpień elementu punkt i zakończoną elementem tytuł.
Gdy w dokumencie taki wzorzec zostanie znaleziony zmiennym $TP i $TR przypisuje się zawartości odpowiednich elementów tytuł. Następnie sprawdza się, czy zachodzi
podana równość. Jeśli tak, dla tych wartości zmiennych, generowany jest element
odpowiedzi zadany treścią klauzuli construct. Jeśli równość nie zachodzi, to oczywiście takie wartościowanie zmiennych
jest pomijane. Wykonanie zapytania polega na wyznaczeniu wszystkich możliwych
fragmentów pasujących wzorca i wygenerowaniu dla nich odpowiedzi za pomocą
klauzuli construct.
Zauważmy, że wyrażenie <punkt+.tytuł>
nie jest poprawnym znacznikiem
XML, ale dozwoloną w XML-QL specyfikacją wyrażenia regularnego, która definiuje
poszukiwaną ścieżkę w drzewie dokumentu XML. Podobnie jak w Lorelu (por. p.
16.3.1) plus oznacza „jeden-lub-więcej”, gwiazdka to „zero-lub-więcej” a
pytajnik to „zero-lub-jeden”. Warto zwrócić też uwagę na znacznik </>, który zamyka ostatnio otwarty znacznik
XML-QL. Do zamknięcia <punkt+.tytuł> możemy posłużyć się tylko </>, natomiast w wypadku zwykłego znacznika
(np. <tytuł>) mamy do
wyboru standardowe zamknięcie (</tytuł>) lub skrócone (</>). Tam, gdzie jest to możliwe, lepiej korzystać z postaci standardowej,
ponieważ dzięki niej zapytanie jest bardziej zrozumiałe.
16.3.3 XML-GL
XML-GL [CCP99] jest graficznym językiem
zapytań opracowanym na Politechnice Mediolańskiej. XML-GL jest próbą realizacji
języka przyjaznego ludziom na wzór QBE (Query-By-Example = zapytanie poprzez
przykład) opracowanego dla relacyjnych baz danych. W pewnym sensie można by
uznać, że XML-QL (por. p. 16.3.2) też jest wzorowany na QBE, bo przecież w
zapytaniu podajemy wzorzec (przykład) struktury elementu, który chcemy wydobyć.
Graficzna postać XML-GL daje jednak większą nadzieję na akceptację
użytkowników. Zapytania są przecież
złożonymi tworami a zwykle postać graficzna zwiększa czytelność prezentacji.
Zapytanie w XML-GL w swej istocie jest
podobne do zapytania w XML-QL. W obu tych językach zapytanie składa się ze
zbioru wzorców i warunków dla dokumentów źródłowych oraz szablonu odpowiedzi.
Wzorce i warunki są w XML-QL specyfikowane we frazie where a w XML-GL jest to lewa strona diagramu
zapytania. Szablon odpowiedzi określa się w XML-QL po słowie construct a w XML-GL jest to prawa strona diagramu.
Spójrzmy jak w XML-GL zapisalibyśmy nasze przykładowe zapytanie:
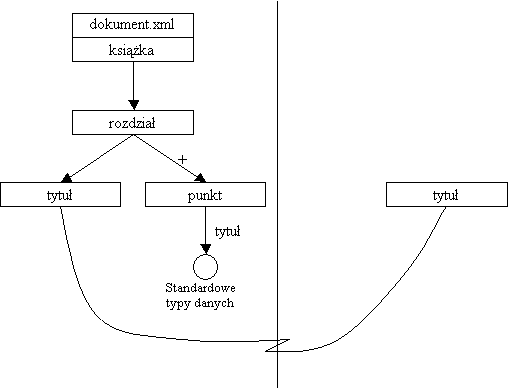
Zauważmy, że do tego zapytania możemy napisać prawie taki sam komentarz jak do zapytania z punktu 16.3.2 — w dokumencie poszukujemy wzorca podanego po lewej stronie diagramu. Musi to by element rozdział w elemencie książka, który zawiera element tytuł i pewną gałąź złożoną z dowolnej dodatniej liczby wystąpień elementu punkt i zakończoną elementem tytuł. Na tym rysunku element tytuł pojawia się w dwóch różnych postaciach (raz jest prostokątem a raz okręgiem). Okrąg służy do definiowania warunku (tu jest on równościowy), podczas gdy prostokąt to wzorzec elementu, który może mieć we wzorcu potomków.
Wykonanie zapytania polega na wyznaczeniu
wszystkich możliwych fragmentów pasujących wzorca i wygenerowaniu dla nich
odpowiedzi za pomocą wzorca podanego po prawej stronie diagramu. Kreska łącząca
obie części diagramu wskazuje element z lewej strony, na którego podstawie
należy wygenerować odpowiedni element prawej strony. Kreskę taką można pominąć
jeśli dla każdego elementu prawej strony po lewej występuje tylko jeden element
o takiej samej nazwie. Jeśli jest ich więcej (w naszym przykładzie dotyczy to tytułów), to trzeba jawnie wskazać skojarzenie
danego elementu prawej strony z elementem lewej strony.
16.3.4 XSLT
XSLT [XSLT99] jest rekomendowanym przez
W3C językiem do definiowania transformacji dokumentów XML w inne dokumenty (być
może również XML). Jedno przekształcenie XSLT przetwarza tylko jeden dokument
XML. XSLT jest przeznaczony raczej do formatowania i wyświetlania dokumentów.
Chociaż uznanie go za język zapytań jest dyskusyjne, jednak szablon XSLT jest
definicją pewnej funkcji działającej w zbiorze dokumentów XML, ma więc pewne
podstawowe cechy zapytania.
Szablon XSLT składa się z reguł. Każda z
tych reguł ma dwie części: wzorzec elementu, który ma być wyszukany w
dokumencie i przepis na to, co wygenerować w odpowiedzi na znalezienie takiego
wzorca. Wzorzec elementu jest definiowany przez wyrażenie XPath [Cl99]. Część
druga reguły to instrukcje określające sposób transformacji takiego pasującego
elementu. Obejmuje konstrukcje warunkowe, statyczne wzorce elementów oraz
bardzo często stosowane polecenie zejścia rekurencyjnego.
Przetwarzanie dokumentu szablonem XSLT
zaczyna się od znalezienie reguły pasującej do korzenia dokumentu. Taka reguła
jest uruchamiana i na podstawie jej treści jest generowany dokument będący
wynikiem transformacji. Każda reguła (w tym również ta dla korzenia) może
zawierać polecenie <xsl:apply-templates/>. Jest to najciekawsza instrukcja całego XSLT.
Oznacza ni mniej ni więcej, tylko „dokonaj transformacji moich potomków za
pomocą pasujących do nich reguł”. Jest to więc zlecenie zejścia rekurencyjnego
w dół drzewa dokumentu. Teraz dla każdego potomka poszukuje się odpowiedniej
reguły i stosuje się ją do tego potomka. Oczywiście transformacja dla takiego
elementu może zawierać kolejne wywołanie <xsl:apply-templates/> i tak dalej i tak dalej…
XSLT definiuje też reguły domyślne. Jeśli
dla danego węzła, który ma być przetworzony nie istnieje w transformacji
odpowiednia reguła, stosowana jest właśnie reguła domyślna. W uproszeniu można
powiedzieć, że reguła domyślna nakazuje wypisanie wszystkich węzłów tekstowych
i zejście rekurencyjne do wszystkich dzieci.
Oto jak moglibyśmy nasze przykładowe
zapytanie napisać za pomocą XSLT:
<?xml version="1.0" encoding="windows-1250" ?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template
match="/książka/rozdział">
<xsl:if
test="punkt//tytuł='Standardowe typy danych'">
<tytuł>
<xsl:value-of
select="tytuł"/>
</tytuł>
</xsl:if>
</xsl:template>
</xsl:stylesheet>
Realizacja tej transformacji zaczyna się
od korzenia dokumentu. Nie ma reguły dla korzenia, więc stosowana jest reguła
domyślna, czyli zejście rekurencyjne do dzieci. Podobnie jest dla elementu książka. Dopiero po natrafieniu na element rozdział stosowana jest reguła inna niż domyślna,
ponieważ w transformacji zdefiniowano regułę dla takiego elementu (tzn.
elementu rozdział w elemencie książka znajdującym się w korzeniu dokumentu —
wartość atrybutu match
zaczyna się od ukośnika). Następnie sprawdzamy, czy znaleziony element rozdział ma bezpośredniego potomka o nazwie punkt, który z kolei ma potomka (niekoniecznie
bezpośredniego) tytuł o
treści 'Standardowe typy danych'.
Jeśli ten warunek jest spełniony, to wypisujemy wartość elementu tytuł. Można spytać, który element tytuł jest wypisywany. Znacznik <xsl:value-of/> jest wykonywany w kontekście elementu
określonego przez atrybut match
znacznika <xsl:template>,
czyli w kontekście elementu rozdział. Znacznik <xsl:value-of/> wypisze więc tekst tytułu rozdziału. Aby ten
wynik był zgodny ze specyfikacją, musimy jeszcze otoczyć tekst tytułu
znacznikami <tytuł> i </tytuł> (znacznik <xsl:value-of/> nie wypisuje otaczającego znacznika, a
jedynie wnętrze elementu).
Ten szablon XSLT będzie dobrze działał dla
dokumentów o typie zgodnym z DTD z punktu 16.2. Jeśli element punkt zawierałby elementy inne niż punkt, które zawierałyby element tytuł, to warunek
="punkt//tytuł='Standardowe typy danych'" skorzystałby też z takich elementów. To jest
jednak niezgodne ze specyfikacją przykładowego zapytania. Szablon XSLT trzeba
doprecyzować tak, aby uwzględniał tylko takie elementy tytuł, które są potomkami gałęzi drzewa
dokumentu złożonej tylko z elementów punkt i zaczynającej się od elementu rozdział:
<?xml version="1.0"? encoding="windows-1250" >
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template
match="/książka/rozdział">
<xsl:apply-templates select="punkt"/>
</xsl:template>
<xsl:template
match="punkt">
<xsl:apply-templates
select="punkt|tytuł"/>
</xsl:template>
<xsl:template match="tytuł">
<xsl:if
test=".='Standardowe typy danych'">
<tytuł>
<xsl:value-of
select="ancestor::rozdział/tytuł"/>
</tytuł>
</xsl:if>
</xsl:template>
</xsl:stylesheet>
Ten arkusz wypisuje już dokładnie to,
czego potrzebujemy. Najpierw znajdujemy element rozdział w elemencie książka znajdującego się w korzeniu dokumentu.
Potem z tego elementu dokonujemy zejścia rekurencyjnego w drzewie dokumentu (<xsl:apply-templates/>), ale tylko dla elementów potomnych punkt (wskazuje na to wartość atrybutu select). Z kolei dla elementów punkt szablon również nakazuje zejście
rekurencyjne, ale tym razem dopuszczalne jest zejście do elementów tytuł i do elementów punkt. Gdy dotrzemy w końcu do elementu tytuł, sprawdzamy, czy jego treścią jest napis
'Standardowe
typy danych'. Jeśli ten
warunek jest spełniony, to wypisujemy wartość elementu tytuł, który pochodzi elementu rozdział będącego przodkiem (ancestor; por. p. 16.4 na temat XPath) aktualnie
przetwarzanego elementu tytuł.
16.3.5 XQL
XQL [RLS98] służy do wybierania i
filtrowania elementów oraz tekstu z dokumentów XML. Ma mniejszą siłę wyrazu niż
omówione dotąd języki, ponieważ nie pozwala na przykład na konstruowanie nowych
elementów w wyniku zapytania. Zapytanie XQL może zwrócić tylko pewien podzbiór
elementów i tekstów znajdujących się w dokumentach wejściowych. Jest to język
zapytań ścieżkowych podobny do XPath (por. p. 16.4). W zapytaniu XQL określamy
kolejne elementy poszukiwanej ścieżki i warunki logiczne, które mają być przez
nie spełnione.
Nasze przykładowe zapytanie mogłoby w XQL
wyglądać tak:
książka/rozdział[punkt//tytuł='Standardowe
typy danych']/tytuł
Wykonanie tego zapytania zaczyna się od
znalezienia elementu rozdział w elemencie książka. Nawiasy kwadratowe otaczają warunek, który musi być spełniony przez
poprzedzający je element. W tym warunku określono, że tenże element musi mieć
bezpośredniego potomka o nazwie punkt,
który z kolei ma potomka (niekoniecznie bezpośredniego) tytuł o treści 'Standardowe typy danych'. Jeśli ten warunek jest spełniony, to
przechodzimy dalej wzdłuż tego wyrażenia ścieżkowego. Idziemy do elementu tytuł, który jako ostatni element ścieżki staje
się składową wyniku zapytania. Ten ostatni krok wykonujemy ze znalezionego
elementu rozdział, który spełnił
warunek logiczny.
To zapytanie ma oczywiście tę samą wadę,
co pierwsza wersja arkusza XSLT z p. 16.3.4. Nie ograniczono w nim elementów,
które mogą znaleźć się na ścieżce od punkt do tytuł. Niestety w XQL
tego zapytania poprawić się nie da. Zapytanie, w które precyzyjnie określono by
zawartość tej ścieżki zgodnie ze specyfikacją zapytania, nie da się wyrazić w
XQL.
16.4 XPath
XPath [Cl99] jest deklaratywnym językiem
wykorzystywanym przez kilka innych technologii rekomendowanych przez konsorcjum
W3C. XPath jest używany do adresowania elementów dokumentów XML (m.in. w XSLT i
XLink/XPointer) oraz do wyszukiwania wzorców w dokumentach XML (m.in. w XSLT i
XQuery).
Zapytanie XPath to ścieżka
lokalizacyjna, która jest ciągiem kroków lokalizacyjnych.
Wynik ścieżki lokalizacyjnej jest
obliczany w pewnym kontekście, który jest zbiorem węzłów, od których
zaczynamy spacer po ścieżce lokalizacyjnej. Kontekstem dla kroku
lokalizacyjnego jest wynik obliczenia poprzedniego kroku w jego kontekście.
Kontekst początkowy, tzn. kontekst dla pierwszego kroku
ścieżki, może być zadany w rozmaity sposób i zależy od technologii, w której
ramach XPath jest używany.
Oto pierwszy przykład ścieżki:
child::rozdział[position()<3]/descendant::punkt/attribute::id
To zapytanie ma poszukać atrybutów id elementów punkt będących (niekoniecznie bezpośrednimi)
potomkami pierwszych dwóch elementów rozdział, które są dziećmi jakiegoś elementu kontekstu
początkowego. Jeśli kontekstem początkowym dla tego zapytania jest zbiór
złożony w jedynego elementu książka w przykładowym dokumencie z p. 16.2, to wynikiem tego zapytania będzie
zbiór wartości {"2.1 "2.1.standardowe"}.
16.4.1 Krok lokalizacyjny
Krok lokalizacyjny składa się z trzech
części:
oś ::
test-węzła [ predykat ]
Oś służy wstępnemu wyborowi węzłów drzewa dokumentu.
Jest wskazaniem, w którym, kierunku drzewa mamy się poruszać. Przykładami osi
są child (weź pod uwagę
dzieci węzła z bieżącego kontekstu), parent (rodzic węzła z bieżącego kontekstu), descendant (wszyscy potomkowie węzła z bieżącego
kontekstu) i attribute (atrybuty węzła
z bieżącego kontekstu). Wszystkie osie wymieniono i opisano w p. 16.4.2.
Test węzła to definicja prostego ale bardzo wygodnego filtru
wybierającego niektóre węzły danej osi. Może to być:
- nazwa elementu — wówczas wybieramy tylko węzły o tej nazwie,
- gwiazdka * — wszystkie węzły,
- text() — węzły tekstowe (PCDATA),
- comment() — komentarze,
- processing-instruction() — węzły z instrukcjami
przetwarzania,
- node() — wszystkie węzły oprócz atrybutów i
deklaracji przestrzeni nazw.
Predykat jest warunkiem logicznym, który służy do
ostatecznego odfiltrowania węzłów. Wynikiem obliczenia kroku lokalizacyjnego
jest zbiór węzłów zadanej osi, który przechodzi test węzła i spełnia predykat.
Przypomnijmy pierwszy krok lokalizacyjny
poprzedniego przykładu:
child::rozdział[position()<3]
Osią jest child, więc bierzemy pod uwagę wszystkie dzieci
bieżącego kontekstu. Spośród nich wybieramy węzły o nazwie rozdział (taki jest test węzła). Predykat nakazuje
na natomiast pozostawić jedynie te węzły, których pozycja jest mniejsza niż 3,
a więc pozostaje węzeł pierwszy i drugi. Wynikiem funkcji position() jest położenie rozważanego węzła w
zbiorze węzłów wskazanych przez oś i test węzła.
16.4.2 Osie
Przypomnijmy, że oś jest
wskazaniem, w którym, kierunku drzewa mamy się poruszać. Lista dostępnych osi jest
dość obszerna. Tu przytoczymy ją w całości, chociaż w praktyce używa się tylko
kilku z nich (por. dyskusja w p. 16.4.4).
Deklaracje przestrzeni nazw i atrybuty są
traktowane szczególnie, tzn. atrybuty są uwzględnione tylko na osi attribute a deklaracje przestrzeni nazw pojawiają
się tylko na osi namespace. Co więcej, te osie zawierają tylko takie rodzaje węzłów. Wszystkie inne
rodzaje węzłów pojawiają się na wszystkich pozostałych osiach.
Braćmi węzła nazywamy węzły, które mają tego samego
rodzica, co ten węzeł.
child Dzieci
węzła kontekstu.
descendant Potomkowie
węzła kontekstu (dzieci, wnuki, prawnuki itd.).
parent Rodzic
węzła kontekstu (zbiór pusty, gdy kontekst to korzeń).
ancestor Przodkowie
węzła kontekstu (rodzic, dziadek, pradziadek itd.)
following-sibling Bracia
węzła kontekstu leżący po jego prawej stronie.
preceding-sibling Bracia
węzła kontekstu leżący po jego lewej stronie.
following Następne węzły dokumentu z wyjątkiem potomków.
preceding Poprzednie węzły dokumentu z wyjątkiem przodków.
attribute Atrybuty węzła kontekstu.
namespace Deklaracje przestrzeni nazw obecne w węźle kontekstu.
self Sam węzeł kontekstu.
descendant-or-self Suma osi descendant i self.
ancestor-or-self
Suma osi ancestor i self.
Osi preceding i following korzystają z uporządkowania węzłów tak, jak one występują w tekście
dokumentu. Ten porządek jest też równoważny przejściu drzewa dokumentu w
porządku pre-order od lewej do prawej strony.
16.4.3 Predykaty
Predykat jest warunkiem logicznym,
który służy do ostatecznego odfiltrowania węzłów. Predykat jest rzutowany na
wartości logiczne. W szczególności dotyczy to zbiorów węzłów. Zbiór pusty jest
traktowany jak fałsz, podczas gdy wszystkie zbiory niepuste reprezentują
wartość logiczną prawda. Następująca ścieżka lokalizacyjna wyszukuje w książce węzły punkt, które mają co najmniej jednego potomka punkt:
/child::książka/descendant::punkt[child::punkt]
Wartością predykatu child::punkt jest zbiór dzieci o nazwie punkt. Jeśli jest on niepusty (istnieją dzieci
węzła noszące nazwę punkt),
to predykat prawdziwy. W przeciwnym przypadku jest on fałszywy.
W predykatach możemy używać standardowych
operatorów logicznych, takich jak or, and, =, !=, <, >, <=, >=, standardowych operatorów arytmetycznych,
jak +, –, *, div i mod. Możemy też korzystać z funkcji standardowych, które opisano poniżej.
last() Liczba
węzłów, które przeszły test węzła dla danego węzła kontekstu kroku.
position() Pozycja
przetwarzanego węzła w zbiorze węzłów, które przeszły test węzła dla danego
węzła kontekstu kroku.
count(zbiór) Liczba elementów zbioru.
name(zbiór) Napis
reprezentujący pierwszy element zbioru.
sum(zbiór) Suma
elementów zbioru.
string(wartość) Rzutowanie
wartości na typ napisowy.
boolean(wartość) Rzutowanie
wartości na typ logiczny.
number(wartość) Rzutowanie
wartości na typ liczbowy.
not(wartość) Negacja.
Spójrzmy jeszcze na przykład ścieżki
lokalizacyjnej, która wyszukuje w książce węzły punkt, które mają co
najmniej trzech potomków punkt.
W tym zapytaniu użyjemy funkcji count:
/child::książka/descendant::punkt[count(child::punkt)>=3]
16.4.4 Zapis skrócony
Nazwy osi są dość długie i konieczność ich
pisania za każdym razem stanowiłaby sporą niewygodę. Z tego powodu wprowadzono kilka
skrótów dla najczęściej wykorzystywanych osi i warunków logicznych. Niektóre
skróty przypominają składnię XQL (por. p. 16.3.5).
Te skróty są tak popularne, że większość
informatyków uważa je po prostu za istotę XPath nie zdając sobie sprawy z
istnienia pojęcia takiego jak oś. Wynika to z tego, że w praktyce korzysta się
niemal wyłącznie z osi, dla których istnieją skrócone notacje.
W poniższej tabeli wymieniono te skróty. W
lewej kolumnie jest zwykły zapis, a w prawej skrócony.
child:: nic
(child jest więc osią domyślną)
attribute:: @
/descendant-or-self::node()/ //
self::node() .
parent::node() ..
[ liczba ] [ position() = liczba ]
Spójrzmy na przykład skróconej notacji.
Zapytanie
/książka/rozdział[2]/punkt[3]/@id
jest równoważne:
/child::książka/child::rozdział[position()=2]/
child::punkt[position()=3]/attribute:id
i wybiera atrybut id trzeciego punktu drugiego rozdziału. Już na tym prostym przykładzie, że notacja
skrócona istotnie upraszcza zapis ścieżek XPath. Co więcej, zapis skrócony jest
zgodny z intuicyjnym pojmowaniem ścieżek przez programistów.
16.4.5 Przykłady
Popatrzmy jeszcze na kilka przykładów
zapytań XPath do dokumentu z p. 16.2. Oto zapytanie o tytuł punktu o atrybucie id równym "2.1":
//punkt[@id
= "2.1"]/tytuł
Wynikiem tego zapytania będzie element:
<tytuł>Podstawy</tytuł>
Następujące zapytanie podaje tekst tytułu ostatniego punktu rozdziału o id równym "2.1":
/książka/rozdział[@id="2.1"]/punkt[last()]/tytuł/text()
Wynikiem będzie napis:
Podstawy
Ostatni przykład to zapytanie wyszukujące
teksty tytułów rozdziałów, które mają co najmniej trzy węzły
potomne:
/książka/rozdział[count(child::node())>=3]/tytuł/text()
W dokumencie z p. 16.2 tylko pierwszy i drugi rozdział ma trójkę dzieci. Wynikiem tego zapytania jest więc treść ich tytułów, czyli napisy:
SQL-język
relacyjnych i obiektowo-relacyjnych baz danych
Wprowadzenie
do tematyki baz danych
16.5 Podstawowe elementy XQuery
XQuery [XQ3] jest językiem zapytań do XML,
nad którym pracuje specjalna grupa robocza konsorcjum W3C. Postawiono wiele
wymagań wobec takiego języka. Powinien być deklaratywny i zgodny z modelem
danych XML. Musi być zdolny do przetwarzania dokumentów zawierających odwołania
do różnych przestrzeni nazw. Ma umożliwiać kontrolę typów dla systemu typów XML
Schema [Fal01] ale powinien także poprawnie działać wtedy, gdy schematów nie
zdefiniowano albo są one niedostępne. Oczywiście powinien też umożliwiać
łączenie danych pochodzących z wielu dokumentów i liczenie agregacji.
Wydaje się, że XQuery spełnia te
wymagania. Prace nad nim ciągle jeszcze trwają a specyfikacja XQuery nadal ma
tylko status brudnopisu roboczego i nie jest jeszcze rekomendacją W3C.
Specyfikacja XQuery jest uzupełniona dość obszernym zestawem przykładów zapytań
[XQU03].
Podstawowymi postaciami zapytań XQuery są:
- wyrażenie ścieżkowe,
- konstruktor elementu,
- pętla FLWOR (por. p. 16.6),
- instrukcja warunkowa (por. p. 16.7),
- operacje na listach, takie jak distinct, i agregacja, np. sum i avg.
Zapytania XQuery można oczywiście dowolnie
zagnieżdżać według potrzeb, np. w instrukcji warunkowej można (a nawet trzeba)
użyć pewnego podzapytania, którego wynikiem jest wartość logiczna.
W zapytaniu XQuery mogą oprócz instrukcji
wystąpić także deklaracje:
- funkcji,
- przestrzeni nazw,
- importu definicji typów napisanej w XML Schema.
Wyrażenia ścieżkowe XQuery są zdefiniowane przez standard
XPath (por. p. 16.4). Specyficzny dla XQuery jest sposób zadawania kontekstu
początkowego ścieżki. Może to być:
- korzeń wskazanego dokumentu doc("dokument.xml")
- zbiór korzeni dokumentów z pewnej kolekcji collection("library")
- węzły przechowywane w zmiennej $zmienna
Zmienne XQuery są napisami poprzedzonymi
znakiem dolara. Komentarza wymaga druga pozycja tej listy (kolekcja). XQuery
jest językiem służącym też do przetwarzania danych przechowywanych w bazach
danych. W bazach danych XML dokumenty mogą być przechowywane w nazwanych
kolekcjach. Funkcja collection pozwala na przeszukanie dokumentów ze wskazanej kolekcji.
Jeśli przykładowy dokument z p. 16.2 jest
przechowywany pod nazwą "dokument.xml", to zapytanie XQuery, które wypisze z tego
dokumentu tytuł punktu o atrybucie id równym "2.1" może wyglądać tak:
doc("dokument.xml")//punkt[@id = "2.1"]/tytuł
Takie samo zapytanie występuje jako
przykład w p. 16.4 z tym, że tam nie podano kontekstu początkowego.
Ścieżki
XQuery pozwalają też na przechodzenie przez wskaźnik podany jako atrybut typu IDREF. Możemy napisać zapytanie o tytuły punktów, do których są w tekście odwołania. Zrobimy to za
pomocą operatora przejścia przez wskaźnik =>:
doc("dokument.xml")//porównaj/@href=>punkt/tytuł/text()
Wynikiem tego zapytania będzie tekst:
Podstawy
Konstruktor elementu to prostu para znaczników (otwierający i
zamykający). Wewnątrz konstruktora elementu można umieścić inne zapytania
XQuery, w tym również zestaw konstruktorów elementów. W szczególności wartością
zapytania złożonego z samych konstruktorów jest po prostu to zapytanie, np.
<autor>
<imię>Krzysztof</imię>
<nazwisko>Stencel</nazwisko>
</autor>
To zapytanie XQuery składa się z trzech
zagnieżdżonych konstruktorów elementów autor, imię i nazwisko. Wewnątrz konstruktora może znajdować się
dowolny węzeł tekstowy (#PCDATA) i dlatego jeśli chcemy umieścić podzapytanie XQuery wewnątrz konstruktora,
to musimy je jakoś wyróżnić. Służą do tego nawiasy klamrowe { }. Oto przykład zapytania ścieżkowego otoczonego konstruktorem elementu:
<wynik>
{ doc("dokument.xml")//porównaj/@href=>punkt/tytuł/text() }
</wynik>
Wynikiem tego zapytania będzie:
<referencje_do>
Podstawy
</referencje_do>
16.6 FLWOR
FLWOR (for-let-where-order-by-return) to podstawowa konstrukcja XQuery. Odpowiada konstrukcji SELECT-FROM-WHERE-ORDER-BY języka SQL. FLWOR to pętla for, która:
1. pozwala przejść po elementach zadanej kolekcji (fraza for),
2. zdefiniować zmienne pomocnicze (fraza let),
3. odfiltrować niepotrzebne elementy (fraza where),
4. uporządkować to, co pozostanie (fraza order by),
5. wypisać wynik w odpowiedniej postaci (fraza return).
Załóżmy, że w kolekcji dokumentów bib znajdują się dokumenty o typie zdefiniowanym przez DTD z p. 16.2. Następujące zapytanie wypisze listę autorów tych książek, a przy każdym autorze znajdzie się liczba książek, które napisał.
for $a in
distinct(collection("bib")/książka/autor)
let $k := collection("bib")/książka[autor = $a]/tytuł
return <autor>
{ $a/text() }
<liczba> { count($k) }
</liczba>
</autor>
Zmienna $a przebiega wszystkie elementy autor znajdujące się wewnątrz elementów książka w dokumentach kolekcji bib. Funkcja distinct usuwa duplikaty, więc każdy autor będzie wypisany tylko raz.
We frazie let zmiennej pomocniczej $k nadawana jest wartość będąca zbiorem wszystkich książek, których autorem (lub współautorem) jest osoba opisywana przez wartość zmiennej $a. Fraza let jest wykowana oddzielnie dla każdej wartości przypisanej zmiennej $a.
Dla zadanego wartościowania zmiennych $a i $k obliczanie jest wyrażenie występujące po słowie kluczowym return. Są tam dwa konstruktory elementów, między którym odpowiednio wpisywane są wartości wyrażeń, czyli tekst elementu przechowywanego w zmiennej $a i liczba elementów zbioru przechowywanego w zmiennej $k.
Gdyby kolekcja bib składała się tylko z dokumentu z p. 16.2, to wynik tego zapytania byłby taki:
<autor>
Lech Banachowski
<liczba> 1 </liczba>
</autor>
<autor>
Krzysztof Stencel
<liczba> 1 </liczba>
</autor>
Wypisywane dane można ograniczyć (za pomocą frazy where) i uporządkować (za pomocą frazy order by). Wynik tego zapytania moglibyśmy ograniczyć tylko do autorów, którzy opublikowali co najmniej pięć książek i uporządkować wynik alfabetycznie wg danych autorów. Zapytanie takie mogłoby wyglądać na przykład tak:
for $a in
distinct(collection("bib")/książka/autor)
let $k := collection("bib")/książka[autor = $a]/tytuł
where count($k) >= 5
order by $a
return <autor>
{ $a/text() }
<liczba> { count($k) }
</liczba>
</autor>
Frazy let, where i order by są opcjonalne, natomiast for i return są obowiązkowe.
16.7 Instrukcje warunkowe i kwantyfikatory
XQuery zawiera też instrukcję warunkową o
standardowym znaczeniu. Wyobraźmy sobie, że kolekcję bib chcemy wypisać w postaci listy pozycji
bibliografii składających się z listy autorów każdej książki oraz jej tytułu.
Jeśli książka ma jednak więcej niż dwóch autorów, zamiast ich listy należy
wypisać znacznik <praca-zbiorowa/>. Następujące zapytanie może być użyte do
wykonania tego zadania:
for $k in
collection("bib")/książka
order by $k/tytuł
return <pozycja>
{ if count($k/autor) <= 2
then $k/autor
else
<praca-zbiorowa/>
}
$k/tytuł
</pozycja>
Gdyby kolekcja bib składała się tylko z dokumentu z p. 16.2, to wynik tego zapytania byłby taki:
<pozycja>
<autor>Lech
Banachowski</autor>
<autor>Krzysztof
Stencel</autor>
<tytuł>
Bazy danych. Projektowanie aplikacji
na serwerze
</tytuł>
</pozycja>
Gdyby ta książka miała jednak więcej
autorów, to wynik tego zapytania wyglądałby tak:
<pozycja>
<praca-zbiorowa/>
<tytuł>
Bazy danych. Projektowanie aplikacji
na serwerze
</tytuł>
</pozycja>
W warunkach można korzystać z
kwantyfikatorów, zarówno ogólnego (every) jak i szczegółowego (some).
Oto zapytanie, które wypisze tytuły książek napisanych przez Krzysztofów:
for $k in
collection("bib")/książka
order by $k/tytuł
where some $a in $k/autor
satisfies
contains($a, ("Krzysztof"))
return $k/tytuł
Jeśli chcielibyśmy jednak wypisać książki, których wszyscy autorzy mają na imię Krzysztof, to trzeba by użyć kwantyfikatora ogólnego:
for $k in
collection("bib")/książka
order by $k/tytuł
where every $a in $k/autor
satisfies
contains($a, ("Krzysztof"))
return $k/tytuł
16.8 Funkcje i rekurencja
Zapytanie XQuery może zawierać definicje funkcji, które odgrywają tu taką samą rolę, jak w językach programowania. Funkcje umożliwiają pisanie bardziej czytelnego kodu mającego lepszą strukturę i pozwalają na wielokrotne użycie tego samego zestawu instrukcji. Dzięki nim możliwe jest stosowanie rekurencji, która ma bardzo duże znaczenie przy przetwarzaniu dokumentów XML. Po drzewiastej strukturze dokumentu XML najłatwiej poruszać się za pomocą rekurencji strukturalnej (por. p. 16.3.4 na temat XSLT). Język zapytań, który nie obejmuje udogodnień do posługiwania się rekurencją, z pewnością nie może być uznany za wystarczający do przetwarzania dokumentów XML.
W XQuery deklaracje funkcji są poprzedzane
słowami kluczowymi declare function. Potem następują nazwa funkcji, deklaracja jej argumentów, deklaracja typu
przekazywanych wartości i treść otoczona nawiasami klamrowymi. Obok nazwy
argumentu deklaruje się jego typ (por. p. 16.9). W tym punkcie skorzystamy
tylko z dwóch typów: element() i element()*, które
oznaczają odpowiednio jeden dowolny element dokumentu i dowolną listę takich
elementów.
Przyjrzyjmy się następującemu zapytaniu,
które przygotowuje płaską listę punktów dokumentu. Z każdego punktu
wypisywane są tylko jego atrybuty i tytuł.
declare function
local:krótkiPunkt($pkt as element())
as
element()
{
<punkt>
{ $pkt/@* }
{ $pkt/tytuł }
</punkt>
}
<lista>
{
for $p in
collection("bib")//punkt
return local:krótkiPunkt($p)
}
</lista>
Funkcja punkt pobiera element() jako argument i przekazuje pewien element(). Każda funkcja powinna znajdować się w jakiejś przestrzeni nazw. Tu zastosowano przedrostek local wskazujący na predefiniowaną lokalną przestrzeń nazwa dla funkcji lokalnych. Krok lokalizacyjny @* jest skrótem (por. p. 16.4.4) od attribute::*. Jego wartością są wszystkie atrybuty bieżącego kontekstu. Po deklaracji funkcji następuje wyrażenie, którego obliczenie daje wynik całego zapytania. W tym wyrażeniu można oczywiście wywoływać zadeklarowane funkcje
Gdyby kolekcja bib składała się tylko z dokumentu z p. 16.2, to wynik tego zapytania byłby taki:
<lista>
<punkt
id="2.1">
<tytuł>Podstawy</tytuł>
</punkt>
<punkt
id="2.1.standardowe">
<tytuł>Standardowe
typy danych</tytuł>
</punkt>
</lista>
Następny przykład zawiera już funkcję
rekurencyjną. Wypiszemy spis treści dokumentu (wszystkie rozdziały i punkty zachowując ich wzajemne zagnieżdżenie). Funkcja st zawiera wywołanie samej siebie. Tego
zapytania nie da się zapisać bez rekurencji, ponieważ pętla FLWOR daje płaski a
nie zagnieżdżony wynik. Zachowanie struktury jest możliwe tylko dzięki
rekurencji strukturalnej. Typem wyniku funkcji st jest lista elementów (element()*), ponieważ dla każdego punktu lub rozdziału funkcja może wypisać więcej niż jedną pozycję. Przecinek oddzielający frazy w nawiasach
klamrowych w funkcji st
oznacza sklejanie list (wynikiem każdego z wyrażeń $p/@id i $p/tytuł oraz local:st($p) jest lista).
declare function
local:st($elem as element()) as element()*
{
for $p in
$elem/*[name()="punkt" or name()="rozdział"]
return
<pozycja>
{ $p/@id, $p/tytuł, local:st($p)
}
</pozycja>
}
<spis-treści>
{
for $r in
doc("dokument.xml")/książka
return local:st($r)
}
</spis-treści>
Parametr $elem reprezentuje książkę, rozdział albo punkt wejściowego dokumentu. Wewnątrz funkcji st przebiegamy zbiór potomków parametru, których nazwą jest punkt lub rozdział (predykat [name()="punkt" or name()="rozdział"]). Tylko dla takich elementów wypisujemy pozycję wynikową i dokonujemy zejścia rekurencyjnego do ich dzieci.
Dla pliku dokument.xml z p. 16.2 wynik działania tego zapytania byłby taki:
<spis-treści>
<pozycja
id="1">
<tytuł>Wprowadzenie
do tematyki baz danych</tytuł>
</pozycja>
<pozycja
id="2">
<tytuł>
SQL-język relacyjnych i
obiektowo-relacyjnych baz danych
</tytuł>
<pozycja
id="2.1">
<tytuł>Podstawy</tytuł>
<pozycja
id="2.1.standardowe">
<tytuł>Standardowe
typy danych</tytuł>
</pozycja>
</pozycja>
</pozycja>
<pozycja
id="3">
<tytuł>Język SQL -
zaawansowane konstrukcje</tytuł>
</pozycja>
</spis-treści>
16.9 Kontrola poprawności typów
16.9.1 Dwa systemy typów
Kontrola typów w XQuery jest dość
skomplikowana, ponieważ opiera się na dwóch systemach typów. Jeden z nich jest
bardzo prosty i tak go nazwijmy: system prosty. Korzystaliśmy z niego do
tej pory (por. p. 16.8). Drugi jest natomiast niezwykle złożony, ponieważ jest
to system typów XML Schema [Fal01]. Ta podwójność wynika z dążenia do spełnienia
jednego z wymagań postawionych językowi zapytań do XML (por. p. 16.5). Chociaż
taki język ma umożliwiać korzystanie z systemu typów XML Schema, jednak
programiści powinni mieć warunki do pisania zapytań o dowolne dokumenty, tzn.
również takie, które nie mają narzuconego typu. Co więcej, zapytanie XQuery z
kontrolą typów ma działać także wtedy, gdy zdalne definicje typów są
niedostępne, np. z powodu awarii sieci komputerowej. Ta dwoistość celów jest
przyczyną istnienia dwóch trybów pracy systemu typów w XQuery.
Wszystkie obiekty przetwarzane przez
XQuery to ciągi. W XQuery nie ma pojedynczych wartości, są tylko
jednoelementowe ciągi. Nie ma też zagnieżdżania ciągów, czyli ciągów złożonych
z ciągów. Pozycjami ciągów są węzły i wartości atomowe. Węzłami są
elementy, atrybuty, komentarze i instrukcje przetwarzania. Wartości atomowe to
napisy, liczby, daty etc.
16.9.2 Schemat
przykładowego dokumentu
Poniżej znajduje się definicja schematu
dokumentu z p. 16.2 napisana w XML Schema.
<?xml
version="1.0" encoding="windows-1250" ?>
<schema targetNamespace="http://www.pjwstk.edu.pl/bib"
xmlns="http://www.w3.org/2001/XMLSchema"
xmlns:bib="http://www.pjwstk.edu.pl/bib">
<complexType name="TypPunktu">
<sequence>
<element name="tytuł"
type="string"/>
<element name="porównaj"
type="bib:TypOdnośnika"
minOccurs="0"
maxOccurs="unbounded"/>
<element name="punkt"
type="bib:TypPunktu"
minOccurs="0"
maxOccurs="unbounded"/>
<element name="treść"
type="string" minOccurs="0"/>
</sequence>
<attribute name="id"
type="string" use="required"/>
</complexType>
<complexType name="TypKsiążki">
<sequence>
<element name="tytuł"
type="string"/>
<element name="autor"
type="string"
minOccurs="1"
maxOccurs="unbounded"/>
<element
name="wydwnictwo" type="string"/>
<element name="rozdział"
type="bib:TypPunktu"
minOccurs="1"
maxOccurs="unbounded"/>
</sequence>
</complexType>
<complexType
name="TypOdnośnika">
<attribute name="href"
type="string" use="required"/>
</complexType>
<element name="książka" type="bib:TypKsiążki">
<key
name="PunktPK">
<selector
xpath=".//*[name='punkt' or name='rozdział']"/>
<field
xpath="@id"/>
</key>
<keyref name="porównajFK"
refer="bib:PunktPK">
<selector
xpath=".//porównaj"/>
<field
xpath="@href"/>
</keyref>
</element>
</schema>
Ten schemat jest definicją typu dla
elementów z przestrzeni nazw (targetNamespace) http://www.pjwstk.edu.pl/bib. Przykładowy dokument z p. 16.2 nie składa się jednak z elementów
należących do tej przestrzeni nazw. Można to poprawić na przykład poprzez
dodanie do znacznika elementu głównego deklaracji domyślnej przestrzeni nazw.
Znacznik początkowy wyglądałby wtedy następująco:
<książka
xmlns="http://www.pjwstk.edu.pl/bib">
Tak poprawiony dokument jest zgodny z
powyższym schematem XML Schema.
16.9.3 Badanie typu
Operator logiczny instance of służy do sprawdzenia, czy pewne wyrażenie jest zadanego typu. Jest to
operator binarny. Jego lewym argumentem jest wyrażenie, a prawym typ. Przyjmuje
on wartość logiczną prawda, wtedy i tylko wtedy, gdy to wyrażenie jest tego
typu. Specyfikacja typu ma postać:
element(elem, typ)
Przy czym elem jest nazwą elementu a typ jest nazwą typu XML Schema. Do tak
zdefiniowanego typu należą wszystkie elementy o nazwie elem i typie typ. Można pominąć każdy z argumentów. Samo element() oznacza typ, do którego należą wszystkie
elementy. Z tego typu korzystaliśmy już we wszystkich zapytaniach w p. 16.8.
Gdy pominiemy drugi argument, pisząc na przykład element(książka), określamy typ, do którego należą
wszystkie elementy książka, przy czym ich typ XML Schema jest dowolny.
Pominięcie pierwszego argumentu jest
kłopotliwe technicznie, bo jak tu podać drugi argument, a opuścić pierwszy? W
takiej sytuacji korzysta się z gwiazdki, która oznacza brak argumentu. Typ, do
którego należą wszystkie elementy zgodne z typem XML Schema o nazwie bib:TypPunktu (por. p. 16.9.2), zapiszemy tak:
element(*,
bib:TypPunktu)
Powróćmy na chwilę do ostatniego zapytania z p. 16.8. Wystąpił w nim dość sztuczny warunek:
[name()="punkt"
or name()="rozdział"]
Miał on ograniczyć zejście rekurencyjne
tylko do elementów opisujących strukturę dokumentu. Można to jednak zapisać
bardziej elegancko, ponieważ w schemacie z p. 16.9.2 oba te elementy są
jednakowego typu. Zapytamy więc o elementy typu bib:TypPunktu:
[.
instance of element(*, bib:TypPunktu)]
To rozwiązanie jest bardziej elastyczne,
ponieważ przy zmianie metody konstrukcji struktury dokumentu (np. wprowadzanie
podziału na części), musimy zmienić
tylko definicję schematu w XML Schema. Nie będziemy natomiast musieli zmieniać
zapytania (oczywiście pod warunkiem jest typem elementu część będzie bib:TypPunktu).
Na początku zapytania musimy jeszcze
wskazać definicję typów XML Schema, która ma być użyta w czasie obliczeń. Oto
poprawiona wersja ostatniego zapytania z p. 16.8:
declare schema namespace
bib="http://www.pjwstk.edu.pl/bib"
declare function
local:st($elem as element()) as element()*
{
for $p in $elem/*[. instance of
element(*,bib:TypPunktu)]
return
<pozycja>
{ $p/@bib:id, $p/bib:tytuł, local:st($p)
}
</pozycja>
}
<spis-treści>
{
for $r in
doc("dokument.xml")/bib:książka
return local:st($r)
}
</spis-treści>
Zamiast tego warunku możemy
też skorzystać z konstruktora elementu ścieżki, podając w pętli for wewnątrz funkcji ścieżkę:
$elem/element(*,bib:TypPunktu)
Ostatnim elementem tej ścieżki jest
dowolny element mający typ XML Schema o nazwie bib:TypPunktu.
16.9.4 Typ argumentu
funkcji
Typy opisane w p. 16.9.3 mogą być użyte
także do zdefiniowana typów argumentów funkcji. Wywołanie funkcji z argumentem
niewłaściwego typu powoduje zgłoszenie błędu. Zapytanie przedstawione w p.
16.9.3 można też zapisać w ten sposób, że w części wykonywalnej zapytania
wywołujemy funkcję local:st dla rozdziałów a nie książki. Taki zapis z pewnością będzie bardziej
intuicyjny, ponieważ w tej funkcji jest zapisany wynik przetwarzania jej
argumentu (wypisanie elementu pozycja), a nie tak jak w p. 16.9.3 wynik przetwarzania wartości, dla których
nastąpi zejście rekurencyjne.
declare schema namespace
bib="http://www.pjwstk.edu.pl/bib"
declare function
local:st($elem as element(*,bib:TypPunktu)) as
element()
{
<pozycja>
{ $elem/@bib:id,
$elem/bib:tytuł }
{ for
$p in $elem/element(*, bib:TypPunktu)
return local:st($p)
}
</pozycja>
}
<spis-treści>
{
for $r in
doc("dokument.xml")/bib:książka/bib:rozdział
return local:st($r)
}
</spis-treści>
W tym zapytaniu zadeklarowaliśmy, że
funkcja local:st pobiera jako
argumenty wartości o typie XML Schema bib:TypPunktu.
16.9.5 Instrukcja wyboru
dla typu
XQuery zawiera instrukcję wyboru dla typu
(typeswitch). Jej działanie zależy od typu wyrażenia
podanego jako argument. Każda gałąź tej instrukcji jest związana z pewnym
typem. W czasie realizacji zapytania, wykonana zostanie ta gałąź, która jest
etykietowana faktycznym typem argumentu instrukcji.
Wyobraźmy sobie, że zapytanie z p. 16.9.4
chcemy wykonać w kolekcji o nazwie bib, która zawiera dokumenty o korzeniu książka. Argumentem funkcji local:st będzie teraz książka, rozdział albo punkt. Jeśli argumentem jest element o typie XML Schema TypKsiążki, to wypisujemy znacznik <spis-treści> a w nim tytuł i autorów książki oraz pozycje jej spisu treści (zejście rekurencyjne).
Jeśli argumentem jest natomiast element o typie XML Schema TypPunktu, to wypisujemy znacznik <pozycja> a w nim tytuł punktu lub rozdziału i pozycje spisu treści jego wnętrza (zejście
rekurencyjne).
declare schema namespace
bib="http://www.pjwstk.edu.pl/bib"
declare function
local:st($elem as element()) as element()
{
typeswitch($elem)
case $ksiażka as
element(*, bib:TypKsiążki)
return
<spis-treści>
{ $książka/bib:tytuł, $książka/bib:autor }
{ for $p in $książka/element(*,bib:TypPunktu)
return local:st($p)
}
</spis-treści>
case $punkt as element(*,
bib:TypPunktu)
return
<pozycja>
{ $punkt/@bib:id, $punkt/bib:tytuł }
{ for $p in $punkt/element(*,bib:TypPunktu)
return local:st($p)
}
</pozycja>
default return
<błąd-w-dokumencie/>
}
for $r in
collection("bib")/bib:książka
return local:st($r)
Wartość zmiennej $ksiażka lub $punkt jest dokładnie taka sama jak zmiennej $elem. Te dwie nowe zmienne ($ksiażka, $punkt ) mają uwypuklić fakt, że w ramach instrukcji typeswitch następuje zmiana typu wyrażenia. Po tej
zmianie nie korzystamy już ze „starej” zmiennej („starego” typu), ale mamy do
dyspozycji „nową” zmienną („nowego” typu).
Sekcja default w powyższej instrukcji typeswitch to wynik zastosowania techniki
programowania defensywnego. Jeśli jakiś dokument w kolekcji bib nie będzie zgodny z typem dokumentu z p.
16.9.2, to w wyniku pojawi się znacznik <błąd-w-dokumencie/>.
Gdyby kolekcja bib składała się tylko z dokumentu z p. 16.2, to wynik tego zapytania byłby taki:
<spis-treści>
<tytuł>
Bazy danych.
Projektowanie aplikacji na serwerze
</tytuł>
<autor>Lech
Banachowski</autor>
<autor>Krzysztof
Stencel</autor>
<pozycja
id="1">
<tytuł>Wprowadzenie
do tematyki baz danych</tytuł>
</pozycja>
<pozycja
id="2">
<tytuł>
SQL-język relacyjnych i
obiektowo-relacyjnych baz danych
</tytuł>
<pozycja
id="2.1">
<tytuł>Podstawy</tytuł>
<pozycja
id="2.1.standardowe">
<tytuł>Standardowe
typy danych</tytuł>
</pozycja>
</pozycja>
</pozycja>
<pozycja
id="3">
<tytuł>Język SQL -
zaawansowane konstrukcje</tytuł>
</pozycja>
</spis-treści>
16.9.5 Typy podstawowe
W XML Schema zdefiniowano wiele typów
podstawowych. W zapytaniach XQuery można z tych typów korzystać. Są to m.in.
typ napisowy (xs:string), typ daty (xs:date), typ logiczny (xs:boolean) i typ liczbowy (xs:decimal).
Oto funkcja,
której wynikiem jest długość najdłuższej ścieżki w drzewie dokumentu, tzn.
poziom zagnieżdżenia najgłębszego elementu dokumentu. Przykład ten ilustruje
użycie typu standardowego xs:decimal.
declare function
local:głębokość($elem as element()) as
xs:decimal
{
if count($elem/*) = 0
then 1
else 1 + max( for $dziecko in $elem/*
return
local:głębokość($dziecko)
)
}
<głębokość-drzewa>
{
local:głębokość(doc("dokument.xml")/*) }
</głębokość-drzewa>
Zauważmy, że wywołanie local:głębokość(doc("dokument.xml")/*)
jest poprawne. Argumentem
funkcji musi być pojedynczy element, ale korzeniem każdego dokumentu XML też
jest dokładnie jeden element.
Dla przykładowego dokumentu z p. 16.2
wynikiem będzie:
<głębokość-drzewa> 5 </głębokość-drzewa>
16.10 Zadanie
Rozważmy dokumenty XML o następującym typie:
<!ELEMENT auto (marka, część+)>
<!ELEMENT część (nazwa, cena?, część*)>
<!ELEMENT marka (#PCDATA)>
<!ELEMENT nazwa (#PCDATA)>
<!ELEMENT cena (#PCDATA)>
<!ATTLIST część ilość PCDATA #REQUIRED
>
Elementem głównym tych dokumentów jest auto. W tych dokumentach opisano, z jakich części składają się poszczególne auta. Element cena oznacza cenę jednostkową, natomiast atrybut ilość to ilość danej części, która wchodzi w skład części nadrzędnej lub auta. Oto przykładowy dokument tego typu:
<?xml version="1.0"
encoding="windows-1250" ?>
<auto>
<marka>Moskwicz</marka>
<część
ilość="4">
<nazwa>koło</nazwa>
<część
ilość="1">
<nazwa>opona<nazwa>
<cena>100</cena>
</część>
<część
ilość="1">
<nazwa>felga<nazwa>
<cena>122</cena>
</część>
</część>
</auto>
Znajdź w Internecie jakąś darmową implementację XQuery. Może to być np. Galax, http://db.bell-labs.com/galax. Za pomocą tej implementacji napisz i przetestuj następujące zapytania.
1. Wypisz marki wszystkich samochodów.
2. Wypisz wszystkie nazwy użytych części.
3. Podaj marki samochodów, w których użyto felg aluminiowych.
4. Znajdź część, której jednorazowo użyto najwięcej (tzn. część z największą wartością atrybutu ilość).
5. Wypisz listę części, a przy każdej części podaj listę aut, w których tę część użyto.
6. Podaj długość najdłuższej ścieżki w drzewie dokumentu.
7. Podaj nazwę najbardziej „zagnieżdżonej” części.
8. Zakładając, że cena auta to łączna suma cen jego części, wyznacz cenę każdego auta.
9. Znajdź najdroższą (w sensie ceny jednostkowej) część każdego auta.
10. Wypisz skorowidz dziesięciu najczęściej (w sensie liczby wystąpień) używanych części. Pozycja takiego skorowidza zawiera nazwę części i nazwy wszystkich części oraz marki aut, w których tej części użyto.
Opracuj definicję schematu XML Schema dla tego typu dokumentu. Sprawdź, czy napisane przez Ciebie zapytania są poprawne z punktu widzenia systemu typów. W tym celu dodaj deklaracje typów do wszystkich powyższych zapytań i ponownie przetestuj te zapytania.
16.11 Literatura
[ABS01] A.
Abiteboul, P. Buneman, D. Suciu, Dane w sieci WWW, MIKOM, Warszawa 2001.
[AQM97] S.
Abiteboul, D. Quass, J. McHugh, J. Widom, J. Wiener, The Lorel Query Language
for Semistructured Data. w: International Journal od Digital Libraries,
1(1):68-88, Kwiecień 1997.
[BC00] A.
Bonifati, S. Ceri: Comparative Analysis of Five XML Query Languages. SIGMOD
Record 29(1): 68-79 (2000).
[CCF99] S.
Ceri, S. Comai, P. Fraternali, S. Paraboschi, L. Tanca, E. Damiani. XML-GL: A
Graphical Language for Querying and Restructuring XML Documents. SEBD 1999: 151-165.
http://www8.org/w8-papers/1c-xml/xml-gl/xml-gl.html.
[CDB00] R. G. G. Cattell, Douglas K. Barry, Mark Berler, Jeff Eastman, David Jordan,
Craig Russell, Olaf Schadow, Torsten Stanienda, and Fernando Velez, The
Object Data Standard: ODMG 3.0. Morgan Kaufmann Publishers, Styczeń 2000.
[Cl99] J. Clark: XML Path Language (XPath),
1999, http://www.w3.org/TR/xpath.
[DFF98] A.
Deutsch, M. Fernandez, D. Florescu, Alon Levy, D. Suciu, XML-QL: A Query
Language for XML. w: Proc. of the Query Languages Workshop (QL98),
Cambrigde, Massachussets, Grudzień 1998.
http://www.w3.org/TR/1998/NOTE-xml-ql-19980819/.
[Fal01] D.
Fallside, XML Schema Part 0: Primer, W3C Recommendation, Maj 2001,
http://www.w3.org/TR/xmlschema-0/.
[GMW99] R. Goldman,
G. McHugh, J. Widom. From Semistructured Data to XML: Migrating the Lore Data
Model and Query Language. w: Proceedings of the 2nd International Workshop
on the Web and Databases (WebDB '99), Filadelfia, Pensylwania, Czerwiec
1999.
[RLS98] J.
Robie, J. Lapp, D. Schach. XML
Query Language (XQL). w: Proc. of the query languages workshop. Cambrigde, Massachussets, Grudzień 1998.
http://www.w3.org/TandS/QL/QL98/pp/xql.html.
[XML04] Extensible
Markup Language (XML) 1.0 (Third Edition). W3C recommendation. Luty 2004.
http://www.w3.org/TR/REC-xml/.
[XQ03] XQuery
1.0: An XML Query Language. W3C working draft. Listopad 2003. http://www.w3.org/TR/xquery/.
[XQU03] XML
Query Use Cases. W3C working draft. Listopad 2003. http://www.w3.org/TR/xquery-use-cases/.
[XSLT99] XSL
Transformations (XSLT) Version 1.0. W3C recommendation. Listopad 1999. http://
http://www.w3.org/TR/xslt/.