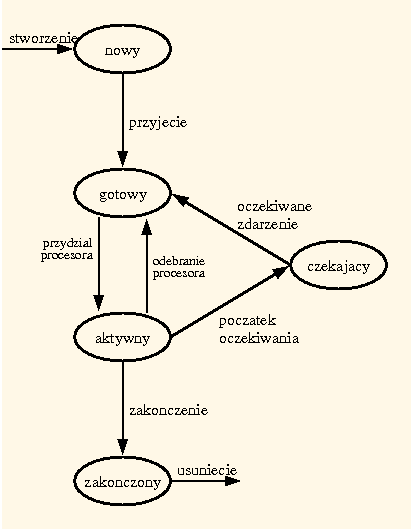
Zmiana wykonywanego procesu (gdy procesor jest przydzielany innemu procesowi z jakiegokolwiek powodu) wiąże się ze złożonymi operacjami zapisania stanu obliczenia poprzedniego procesu i odtworzenia stanu obliczeń nowego procesu. Jest to właśnie przełączenie kontekstu Stanowi ono istotny narzut na działanie systemu, ponieważ w tym czasie system nie wykonuje niczego pożytecznego, a jednie "czynności administracyjne". Planowanie procesów nie może więc zbyt często powodować zmiany wykonywanego procesu, ponieważ wówczas większość czasu pracy będzie poświęcona na ciągłe przełączanie kontekstu.
Szybkość przełączania kontekstu zależy też od wsparcia sprzętowego. W pewnych architekturach występuje po kilka zbiorów rejestrów. Wówczas przełączenie kontekstu polega po prostu na zmianie wskaźnika bieżącego zestawu rejestrów, nie trzeba ich natomiast zapamiętywać i odtwarzać z PCB.
Proces może zlecić utworzenie procesu potomnego. Ten pierwszy proces nazywamy wówczas procesem macierzystym, a drugi potomnym. W wyniku ciągu operacji tworzenia powstaje drzewo "genealogiczne", zwane drzewem procesów.
Proces potomny potrzebuje zasobów. W systemach operacyjnych spotykamy różne podejścia do przydzielania zasobów procesom potomnym. Jedno z podejść polega na tym, że proces potomny może współdzielić zasoby z procesem macierzystym. Proces macierzysty decyduje wówczas, który z potomków może korzystać z jego konkretnych zasobów. Ograniczenie procesów dostępnych dla procesu potomnego do zasobów przodka zapobiega nadmiernemu obciążeniu systemu, do którego mogłoby dojść w wyniku namnożenia procesów potomnych. Jeśli stworzenie procesu potomnego nie powiększa zasobów przydzielonych do realizacji zadania, tworzenie podprocesów często nie ma uzasadnienia. Inna możliwość polega na przekazaniu procesowi potomnemu niezbędnych zasobów bezpośrednio przez system operacyjny. Wówczas oba procesu nie mają wspólnych zasobów.
Proces macierzysty i potomny mogą wykonywać się współbieżnie. Często proces potomny jest przywoływany do życia w celu realizacji jakiegoś zadania potrzebnego procesowi macierzystemu. Wówczas proces macierzysty czeka na zakończenie procesu potomnego. Nota bene, tak właśnie wygląda wykonywanie poleceń przez bash-a. Interpreter poleceń tworzy proces potomny, który wykonuje zleconą operację, a proces macierzysty czeka na jego zakończenie. Po zakończeniu procesu potomnego, proces macierzysty jest gotowy do przyjęcia kolejnego polecenia.
W systemie Unix nowy proces jest tworzony w wyniku wywołania przez proces macierzysty
funkcji systemowej fork.
Powstaje wówczas nowy proces, który jest dokładną kopią macierzystego
(wykonuje ten sam program, jest w tym samym miejscu obliczeń i jego pamięć ma taką samą zawartość).
Procesy te mają oczywiście różne identyfikatory w systemie (gdyż każdy proces musi mieć unikatowy identyfikator),
a także mają różne identyfikatory procesów macierzystych (przodkiem nowego potomka jest proces,
który wywołał fork; przodkiem procesu, który wywołał fork,
jest jakiś inny proces, ponieważ on sam nie mógł się z siebie narodzić).
Różnią się one też wynikiem zwracanym przez funkcję fork -- proces macierzysty
otrzymuje w wyniku identyfikator procesu potomnego, a proces potomny otrzymuje liczbę 0.
W ten sposób, choć oba procesy wykonują ten sam program i są w tym samym miejscu obliczeń,
łatwo mogą odróżnić, który z nich jest macierzysty, a który potomny.
Proces potomny zwykle musi wykonać inny program niż ten wykonywany przez proces macierzysty.
Do tego celu służy polecenie exec, które powoduje załadowanie nowego programu do
przestrzeni adresowej procesu i przystąpienie do jego wykonywania.
Stan starego obliczenia jest zamazywany.
Nie jest to więc "wywołanie" jednego programu przez drugi, ale "przeistoczenie" się
wykonania jednego programu w wykonanie drugiego programu.
Zwróćmy uwagę na eleganckie rozdzielenie pojęć.
Tworzenie procesu i zmiana wykonywanego programu to odrębne czynności.
W Uniksie je rozdzielono, co doprowadziło do powstania naprawdę elastycznego mechanizmu.
Nie zrobiono tego na przykład w wielu innych bibliotekach, w których występuje polecenie
spawn będące połączeniem fork i exec.
Nie jest to dobre rozwiązanie, ponieważ między fork i exec
dzieje się bardzo dużo interesujących rzeczy, o których będzie mowa w następnych wykładach.
Po wykonaniu swojej ostatniej instrukcji proces informuje system o ukończeniu działań (exit).
System przekazuje informację o tym procesowi macierzystemu (jeżeli ten akurat na to oczekuje)
i zwalnia zasoby przydzielone potomkowi.
Do oczekiwania na zakończenie procesu potomnego służy funkcja systemowa wait.
Proces macierzysty i potomny wykonują się współbieżnie, i nie da się zagwarantować, że
proces macierzysty wywoła funkcję wait zanim proces potomny się zakończy.
Problem ten rozwiązano w ten sposób, że jeżeli proces potomny kończy działanie, a proces
macierzysty nie oczekuje na jego zakończenie, to proces potomny zamienia się w tzw.
zombie.
Wszystkie związane z nim zasoby systemowe zostają zwolnione, ale jego identyfikator jest nadal
obecny w systemie.
Gdy proces macierzysty wywoła funkcję wait, to wówczas zombie znika.
W ten sposób, bez względu na to, czy proces potomny zakończy się pierwszy, czy też proces macierzysty
pierwszy wywoła funkcję wait, proces macierzysty może czekać na zakończenie się procesu potomnego.
Proces macierzysty może też zażądać zakończenia procesu potomnego (kill).
Dzieje się tak na przykład, gdy ten drugi przekroczy limit przydzielonych mu zasobów albo
jego praca nie jest już potrzebna.
Ciekawa sytuacja występuje, gdy proces macierzysty kończy działanie, a pracują jeszcze procesy potomne.
System operacyjny może wówczas zakończyć wszystkie procesu potomne, albo też mogą one zostać
"adoptowane" przez inny proces, który od tej pory będzie ich przodkiem.
W Uniksie procesem, który adoptuje takie osierocone procesy jest proces o identyfikatorze 1 (tzw. init).
Proces jest bardzo złożoną i kosztowną strukturą (ma swój segment kodu, stos, stertę i segment danych). Utworzenie procesu potomnego wymaga stosunkowo dużo czasu i pamięci. Z tego powodu zwykłe procesy nazywamy ciężkimi.
W ramach procesu można powołać do życia kilka lżejszych struktur nazywanych wątkami albo procesami lekkimi. Wątki jednego procesu są wykonywane współbieżnie. (Tak więc stwierdzenie o sekwencyjnym wykonywaniu procesów odnosi się raczej do wątków niż do ciężkich procesów.) Każdy z nich ma oddzielne rejestry i stos wywołań, jednak współdzieli z innymi wątkami w ramach tego samego procesu segment danych, segment kodu, stertę, tablicę otwartych plików itp. Można powiedzieć, że proces to grupa wykonujących go wątków (przynajmniej jednego).
Korzyści ze stosowania wątków są rozmaite. Przede wszystkim wydajność: powołanie do życia wielu wątków jest znacznie tańsze niż stworzenie wielu ciężkich procesów. Wątki mogą bez ograniczeń współdzielić przestrzeń danych procesu. Gdybyśmy chcieli tak samo prosto skomunikować procesy (przez wspólny obszar pamięci), musielibyśmy skorzystać ze złożonej usługi systemu operacyjnego, jaką jest pamięć dzielona.
W Linuksie, do tworzenia wątków służy funkcja clone.
Jej dwa najważniejsze argumenty, to wskaźnik do procedury, która ma być wykonywana przez nowy wątek,
oraz wskaźnik na przestrzeń na stos dla nowego wątku.
W odróżnieniu do procedury fork, nowy wątek nie kontynuuje tego samego fragmentu kodu,
co wątek macierzysty.
Zamiast tego, wykonuje procedurę, na którą wskazuje wskaźnik przekazany do funkcji clone.
Gdy wykonanie tej procedury kończys się, lub wątek wykona operację exit, wątek kończy się.
Stos jest wykorzystywany do wywoływania procedur i funkcji.
Ponieważ wątki działają współbieżnie, każdy z nich musi mieć własny stos -- ten zasób nie może być dzielony.
Z drugiej strony wątki wykonują ten sam program i współdzielą obszar danych -- gdyby tak nie miało być,
to zamiast wątków lepiej jest utworzyć osobne procesy.
Jeśli chodzi o pozostałe zasoby (np. tablicę deskryptorów otwartych plików) to przekazując odpowiednie
opcje funkcji clone można określić, czy wątek potomny ma współdzielić te zasoby z wątkiem
macierzystym, czy też mieć ich własną kopię.
Na wątkach można wykonywać podobne operacje, jak na procesach, wait, kill itd.
W języku programowania Java jest możliwość tworzenia wątków. Pamiętajmy, że programy w Javie są wykonywane przez maszynę wirtualną Javy, która działa pod jakimś systemem operacyjnym. Zwykle, wątkom programu w Javie odpowiadają systemowe wątki maszyny wirtualnej, która je wykonuje.
Wątki można tworzyć w Javie na dwa, bliźniaczo podobne, sposoby.
Po pierwsze, należy utworzyć albo podklasę klasy Thread,
albo klasę implementującą interfejs Runnable.
(To drugie rozwiązanie stosuje się zwykle wtedy, gdy chcemy utworzyć podklasę innej klasy niż Thread.)
W obu przypadkach utworzona klasa musi udostępniać bezargumentową metodę run.
Każdy obiekt takiej klasy może być wątkiem.
Konstruktor takiego obiektu może skonfigurować wszystko co jest potrzebne do późniejszego działania wątku.
Wątek jest uruchamiany dopiero, gdy wykona się na nim bezargumentową metodę start.
Wykonuje on metodę run, a gdy skończy ją wykonywać, wątek kończy się.
Oto proste przykłady pokazujące jak tworzyć wątki w Javie:
public class MyThread extends Thread {
public void run() {
System.out.println("To mój pierwszy wątek!");
}
public static void main(String args[]) {
System.out.println("Ruszamy ...");
new MyThread().start();
System.out.println("Koniec.");
}
}
public class SomethingRunnable implements Runnable {
public void run() {
System.out.println("To mój pierwszy wątek!");
}
public static void main(String args[]) {
System.out.println("Ruszamy ...");
new Thread(new SomethingRunnable()).start();
System.out.println("Koniec.");
}
}
Jeśli uruchomimy któryś z tych programów, to zauważymy, że utworzony wątek nie musi wypisywać swojej wiadomości przed komunikatem "Koniec". Może to robić po nim, gdyż oba wątki działają współbieżnie.
Odpowiednikiem operacji wait na procesach, jest bezargumentowa metoda join
udostępniana przez wątki.
Jeżeli inny wątek wywoła tę metodę, to jego wykonanie zostaje wstrzymane, aż do momentu
zakończenia się wątku, którego metodę wywołano.
Nazwa tej operacji pochodzi stąd, że w pewnym sensie, przepływ sterowania z obu wątków
łączy się i biegnie dalej tylko w jednym z nich.
Poniższy przykład ilustruje użycie metody join.
Zachęcamy do eksperymentów i sprawdzenia co może się stać, gdy usuniemy jej wywołanie.
public class Join extends Thread {
String w;
Join (String s) {w = s;}
public void run() {
System.out.println("To mój " + w + " wątek!");
}
public static void main(String args[]) throws InterruptedException {
System.out.println("Ruszamy ...");
Thread t1 = new Join("pierwszy");
Thread t2 = new Join("drugi");
t1.start();
t2.start();
System.out.println("Jesteśmy w połowie.");
t1.join();
t2.join();
System.out.println("Koniec.");
}
}
Poniższy diagram przedstawia możliwe stany wątków w Javie, oraz ich zmiany.
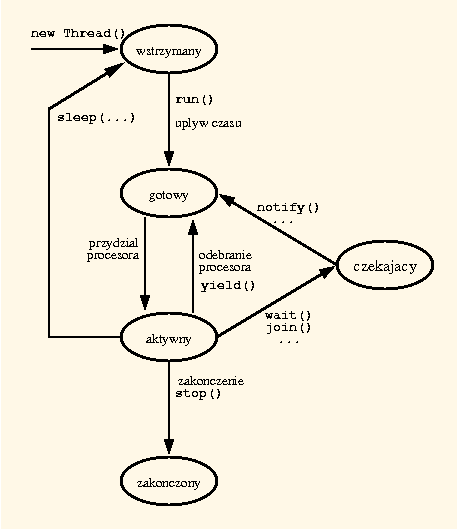
Przypomina on diagram możliwych stanów procesu.
Jest jednak parę różnic:
Nowo utworzony wątek pozostaje w stanie wstrzymany, aż nie zostanie jawnie uruchomiony.
Może on też powrócić do tego stanu (na pewien czas) jeżeli wykona operację sleep.
Wątek może też sam odebrać sobie procesor i zmienić stan na gotowy, jeśli wykona operację yeld.
Więcej o operacjach na wątkach powiemy w wykładzie poświęconym
synchronizacji procesów.
Celem planowania jest maksymalizacja czasu wykorzystania procesora przy wieloprogramowości. Większość procesów działa w cyklu złożonym na przemian z fazy procesora (okresu, w którym proces wykonuje obliczenia) i fazy wejścia-wyjścia (okresu, w którym proces czeka na ukończenie zleconej operacji wejścia-wyjścia). Planując przydział procesora, powinniśmy to przewidzieć tak, aby nie okazało się, że w wyniku strategii planowania np. wszystkie procesy czekają na wejście-wyjście i żaden nie jest gotowy do korzystania z procesora.
Planista wybiera spośród procesów gotowych ten, który ma być wykonywany, i przydziela mu procesor.
Jeśli decyzje planisty są podejmowane jedynie w następujących chwilach:
to planowanie nazywamy niewywłaszczeniowym (nie ma sytuacji, w której planista swoją decyzją
wstrzymuje proces aktywny).
Ekspedytor to proces egzekwujący wyroki planisty krótkoterminowego. Przekazuje wybranemu procesowi władzę nad procesorem, co wymaga przełączenia kontekstu, przejścia w tryb użytkownika i wykonania skoku do instrukcji, którą teraz należy wykonać (np. do tej instrukcji, przed którą ów proces poprzednio wywłaszczono). Niestety czas pracy ekspedytora nie jest zerowy i jest to czas poświecony na systemową biurokrację. W tym czasie żaden proces użytkownika nie wykonuje swoich instrukcji, więc prace nie posuwają się do przodu. Czas potrzebny na zatrzymanie procesu i uruchomienie innego nazywamy opóźnieniem ekspedycyjnym. Im jest ono mniejsze, tym lepiej. Wynika stąd, że planista nie może swych decyzji podejmować zbyt często, ponieważ wówczas narzuty systemowe będą ogromne ("biurokracja udusi gospodarkę").
Strategie planowania można oceniać z różnych punktów widzenia. Przyjęcie konkretnego kryterium może całkowicie zmienić naszą ocenę danej strategii. Oto możliwe kryteria:
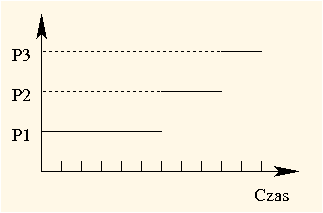
FCFS (First-Come, First-Served), czyli "pierwszy przyszedł pierwszy obsłużony", to strategia szeregowania bez wywłaszczania. Procesy są wykonywane od początku do końca w takiej kolejności, w jakiej pojawiły się w kolejce gotowych.
Przypuśćmy, że w chwili 0 trzy procesy P1, P2 i P3 pojawiły się w kolejce procesów gotowych, w tej właśnie kolejności, a ich wykonanie trwało odpowiednio 6, 3 i 2. Proces P2 rozpoczął więc działanie w chwili 6, a proces P3 w chwili 9 (po zakończeniu procesów P1 i P2). Proces P1 czekał 0, P2 czekał 6, a P3 czekał 9. Średni czas oczekiwania wynosił zatem (0 + 6 + 9) / 3 = 5: Czas obrotu procesów wynosi odpowiednio: 6, 9 i 11, co daje średni czas obrotu (6 + 9 + 11) / 3 = 8.33(3).
| 6 | 3 | 2 |
|---|---|---|
Gdyby planista ustawił te procesy w innej kolejności (np. P3, P2 a na końcu P1), to okresy oczekiwania wynosiłyby: dla P1 5, dla P2 2, a dla P3 0. Średni czas oczekiwania wynosiłby zatem (5 + 2 + 0) / 3 = 2,33(3). Można więc było osiągnąć ponad dwukrotnie krótszy czas średni czas oczekiwania! Analogicznie, czasy obrotu wynosiłyby wtedy: dla P1 11, dla P2 5, a dla P3 2, co daje średni czas obrotu (11 + 5 + 2) / 3 = 6.
| 2 | 3 | 6 |
|---|---|---|
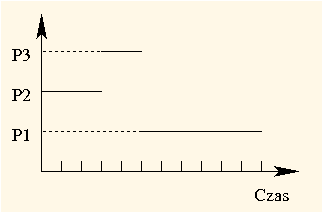
Widać więc, że FCFS nie jest najlepszą strategią. Jej zaletą jest za to prostota, co wiąże się z niskimi narzutami systemowi (planista nie ma zbyt wiele do roboty).
SJF (Shortest-Job-First), czyli "najpierw najkrótsze zadanie" to strategia, w której decyzje planisty zależą od przewidywanych długości następnych faz procesora gotowych procesów. Jest to strategia bez wywłaszczania. Gdy jakiś proces zwolni procesor, planista wybiera z kolejki gotowych ten proces, którego przewidywana długość następnej fazy procesora jest najkrótsza. Popatrzmy na następujący przykład:
| Proces | Czas przybycia | Przewidywana długość fazy procesora |
|---|---|---|
| P1 | 0 | 8 |
| P2 | 2 | 5 |
| P3 | 4 | 1 |
| P4 | 5 | 2 |
W chwili 0 jest tylko jeden proces gotowy (P1) i on właśnie jest wykonywany pierwszy. W chwili 8 (gdy P1 zwolni procesor) już wszystkie pozostałe procesy są gotowe, więc planista wybiera proces o najkrótszej przewidywanej następnej fazie procesora, czyli P3. Po jego zakończeniu planista wznawia kolejno P4 i P2:
| 8 | 1 | 2 | 5 |
|---|---|---|---|
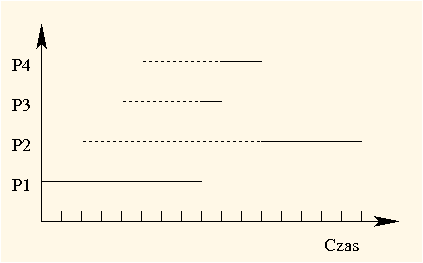
Proces P1 czeka 0, P2 czeka 9, P3 czeka 4 i P4 też 4. Średni czas oczekiwania wynosi zatem (0 + 9 + 4 + 4) / 4 = 4.25. Natomiast czasy obrotu wynoszą: dla P1 8, dla P2 14, dla P3 5, a dla P4 6. Tak więc, średni czas obrotu wynosi (8 + 14 + 5 + 6) / 4 = 8.25.
SRTF (ang. Shortest-Remaining-Time-First), czyli "najpierw zadanie o najkrótszym pozostałym czasie wykonania" to wersja strategii SJF z wywłaszczaniem. W strategii tej decyzja planisty jest oczywiście podejmowana w chwili zakończenia fazy procesora procesu aktywnego, ale również w chwili, gdy którykolwiek proces zmienia stan na gotowy. W takiej chwili wybiera się proces, którego pozostały przewidywany czas fazy procesora jest najkrótszy. Jeśli w trakcie wykonywania procesu pojawiły się inny gotowy proces, którego oczekiwany czas fazy procesora jest krótszy niż pozostały oczekiwany czas działania procesu aktywnego, to proces aktywny jest wywłaszczany a w jego miejsce procesor otrzymuje nowo przybyły proces. Rozważmy ten sam przykład, co poprzednio, ale dla strategii SRTF.
Gdy w chwili 2 przybywa proces P2, pozostały czas działania P1 wynosi 6, a oczekiwany czas dla P2 to 5. Proces P1 jest więc wywłaszczany, a procesem aktywnym staje się P2. Podobnie dzieje się, gdy pojawia się proces P3, który powoduje wywłaszczenie P2. W chwili 5, gdy kończy się P3, przybywa P4 z oczekiwanym czasem fazy procesora równym 2, więc to właśnie on a nie P1 albo P2 staje się aktywny. Po jego zakończeniu wznawiane są kolejno P2 i P1:
| Czas działania | 2 | 2 | 1 | 2 | 3 | 6 |
|---|---|---|---|---|---|---|
| Proces | ||||||
| Pozostały czas | 6 | 3 | 0 | 0 | 0 | 0 |
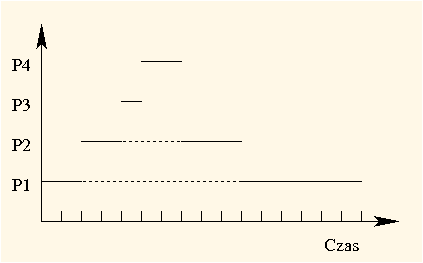
Okresy oczekiwania wynoszą: dla P1 0 + 8 = 8, dla P2 0 + 3 = 3, a dla P3 i P4 0. Średni czas oczekiwania wynosi zatem (8 + 3 + 0 + 0) / 4 = 2,75. Natomiast czasy obrotu wynoszą: dla P1 16, dla P2 8, dla P3 1 i dla P4 2. Tak więc, średni czas obrotu wynosi (16 + 8 + 1 + 2) / 4 = 6,75. Osiągnęliśmy więc znacznie lepszy wynik niż w wypadku strategii SJF.
Ktoś mógłby powiedzieć, że to tylko przykład, jednak można udowodnić, że SRTF jest strategią optymalną pod względem minimalizacji średniego czasu oczekiwania oraz minimalizacji średniego czasu obrotu. Istnieje jednak mały szkopuł. Dokładne określenie długości fazy procesora wymaga przewidywania przyszłości. Nie da się więc zaimplementować tej strategii. Zobaczymy jednak jak można, w przybliżeniu, oszacować długość fazy procesora.
Zastanówmy się, jak oszacować czas następnej fazy procesora, przybliżając strategię SRTF? Nie wiemy ile będzie trwała kolejna faza procesora, ale wiemy ile trwały poprzednie. Okazuje się, że kolejne fazy procesora są zwykle podobnej długości. Przy tym albo proces ma charakter bardziej interaktywny i jego fazy procesora są krótkie, albo ma charakter obliczeniowy i jego fazy procesora są długie.
Jedną ze stosowanych metod szacowania następnej fazy procesora na podstawie długości poprzednich faz jest uśrednianie wykładnicze. Stosując ją, długość kolejnej fazy procesora szacujemy jako średnią ważoną długości poprzednich faz procesora, przy czym wagi tworzą malejący ciąg geometryczny. Przyjmijmy następujące oznaczenia:
| a, | a*(1 - a), | a*(1 - a)^2, | a*(1 - a)^3, | ... |
| a | + | a*(1 - a) | + | a*(1 - a)^2 | + | a*(1 - a)^3 | + | ... | = | ||
| a * [ | 1 | + | (1 - a) | + | (1 - a)^2 | + | (1 - a)^3 | + | ... ] | = |
| a * [1 / (1 - ( 1- a))] = a * (1 / a) = 1 |
Dlaczego stosuje się taką skomplikowaną średnią, a nie np. średnią arytmetyczną? Ponieważ mimo skomplikowanej postaci wzoru, średnią tę można bardzo łatwo obliczać, co nie jest bez znaczenia. Stosuje się następujący wzór:
| o(n + 1) | = | r(n) | * | a | + | o(n) | * | (1 - a) |
Rozwijając ten wzór rekurencyjny otrzymujemy faktycznie naszą średnią ważoną:
| o(n) | = | r(n - 1) | * | a | ||
| + | r(n - 2) | * | a | * | (1 - a) | |
| + | r(n - 3) | * | a | * | (1 - a)^2 | |
... | ||||||
| + | r(n - i) | * | a | * | (1 - a)^(i - 1) | |
... | ||||||
| + | r(1) | * | a | * | (1 - a)^(n - 2) | |
| + | o(1) | * | (1 - a)^(n - 1) |
Jak widać współczynniki wagi czasów coraz starszych faz procesora maleją wykładniczo. Stąd nazwa "uśrednienie wykładnicze".
RR (Round-Robin), czyli planowanie rotacyjne, to strategia, w której każdy proces po kolei otrzymuje kwant czasu procesora do wykorzystania. Zwykle jest to około 20-100 milisekund. Żaden proces nie czeka więc dłużej na procesor niż długość kwantu razy liczba procesów.
Planowanie rotacyjne powoduje znacznie więcej przełączeń kontekstu jest więc dość kosztowną strategią. Kwant czasu musi być co najmniej o rząd wielkości większy niż czas przełączenia kontekstu. W przeciwnym wypadku prace administracyjne (biurokracja systemowa) zduszą rzeczywistą pracę wykonywaną przez system dla użytkowników.
Popatrzmy na zastosowanie planowania rotacyjnego w przykładzie, który wykorzystaliśmy przy okazji omówienia strategii SJF. Przyjmijmy, że kwant czasu wynosi 2. Oto jak wykonywałyby się te procesy (procesy gotowe są obsługiwane w takiej kolejności, w jakiej ustawiają się w kolejce procesów gotowych, a więc jest to kolejka FIFO):
| Czas działania | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 1 | 2 |
|---|---|---|---|---|---|---|---|---|---|
| Proces | |||||||||
| Pozostały czas | 6 | 3 | 4 | 0 | 1 | 0 | 2 | 0 | 0 |
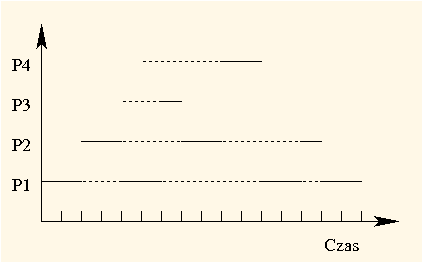
Okresy oczekiwania wynoszą: dla P1 2 + 5 + 1 = 8, dla P2 3 + 4 = 7, dla P3 2, a dla P4 4. Średni czas oczekiwania wynosi zatem (8 + 7 + 2 + 4) / 4 = 5,25. Osiągnęliśmy więc gorszy wynik niż w wypadku pozostałych strategii.
Jak widać z punktu widzenia średniego czasu oczekiwania jest to bardzo zła strategia. Tym, co sprawia, że często korzysta się z planowania rotacyjnego, jest mały czas reakcji, szczególnie ważny przy interakcyjnej pracy wielu użytkowników, oraz prostota tej strategii.
Przy strategiach tego typu każdy proces ma statycznie (albo dynamicznie) przydzielany priorytet. Procesor jest przydzielany procesowi, który ma największy priorytet. Tu również można mówić o strategiach niewywłaszczeniowych (gdy proces dobrowolnie opuszcza procesor) i wywłaszczeniowych (gdy proces jest pozbawiany procesora natychmiast po pojawieniu się procesu o wyższym priorytecie).
Na strategie SJF i SRTF można spojrzeć jak na szczególny przypadek strategii priorytetowych. Priorytetem jest w ich wypadku oszacowanie długości czasu obliczeń do końca fazy procesora, traktowane jako wartość ujemna (im mniejsze oszacowanie, tym większy priorytet).
Problemem przy stosowaniu strategii priorytetowych jest zagłodzenie, tzn. sytuacja, w której proces może czekać w nieskończoność na swoją kolej i nigdy się nie doczekać. Stanie się tak wówczas, gdy ciągle będą pojawiać się nowe procesy o priorytecie wyższym niż ów czekający proces. Będzie on im musiał cały czas ustępować im pierwszeństwa.
Rozwiązaniem tego problemu może być, na przykład, automatyczne podwyższanie priorytetu procesu w miarę jego starzenia (upływu czasu oczekiwania). Wówczas żaden proces nie czekałby w nieskończoność, bo miałby wówczas nieskończony priorytet, co jest niemożliwe.
Dotychczas wszystkie procesy traktowaliśmy tak samo. Nie jest to uzasadnione. Wskazaliśmy strategie dobre z punktu widzenia pracy wsadowej (SJF i SRTF) oraz dobre z punktu widzenia pracy interakcyjnej (RR). Jeśli odróżnimy w systemie procesy wsadowe od interakcyjnych, będziemy mogli zastosować do każdej z tych grup inną strategię planowania, odpowiednią dla danej grupy procesów.
Użytkownik może wskazać procesy tła (wsadowe) i czoła (interakcyjne). Procesy tła mogą być obsługiwane strategią SJF, ponieważ w przypadku pracy wsadowej zależy nam na minimalizacji średniego czasu oczekiwania, a procesy czoła mogą być obsługiwane strategią RR, ponieważ w przypadku pracy interakcyjnej zależy nam na minimalizacji czasu reakcji.
Pozostaje jeszcze rozstrzygnąć wzajemny stosunek obu tych grup procesów. Oczywiście procesy czoła powinny być uprzywilejowane (minimalizujemy czas reakcji w ich wypadku!). W jakim jednak stopniu? Można przyjąć, że zawsze wykonujemy procesy czoła przed wsadowymi w nadziei, że zawsze pojawiają się momenty bezczynności użytkowników. Jeśli jednak obawiamy się zagłodzenia procesów tła, można przyjąć np. podział czasu między kolejki procesów tła i czoła, np. 80% dla czoła i 20% dla tła.
Co zrobić, jeśli nie wiemy z góry, które procesy są interaktywne, a które nastawione na obliczenia, albo charakter procesu zmienia się w miarę jego działania. Możemy wówczas użyć kilku kolejek dopuszczając, aby procesy były między nimi przenoszone. Owe przenoszenie nazywamy sprzężeniem zwrotnym. Definicja strategii planowania z wieloma kolejkami i sprzężeniem zwrotnym musi obejmować:
Wyobraźmy sobie na przykład strategię z trzema kolejkami: Q0, Q1 i Q2, kierującą się następującymi zasadami:
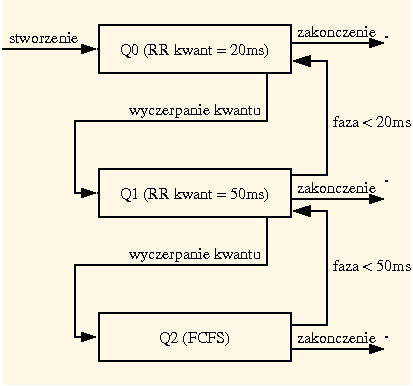
W ten sposób procesy, które często żądają wejścia-wyjścia, czyli procesy interakcyjne, są uprzywilejowane. To słuszne podejście, bo takie procesy i tak rzadko korzystają z procesora, a ta strategia pozwala ograniczyć czas ich przestoju do oczekiwania na wejście-wyjście. Dzięki temu takie procesy szybko opuszczą system, nie "przeszkadzając" przy tym specjalnie pozostałym (one rzadko zajmują procesor). Zwróćmy uwagę, że w ta strategia sama selekcjonuje procesy tła i czoła, uniezależniając tę decyzję od użytkownika (który może się mylić albo oszukiwać). Ponadto, jeżeli charakter procesu zmienia się w miarę upływu czasu, jest on automatycznie przenoszony do właściwej kolejki.
W wykładzie tym poznaliśmy pojęcie procesu, które jest bardzo istotne, ponieważ to właśnie procesy są jedynym mechanizmem realizacji programów w systemach operacyjnych.
W systemach wieloprogramowych naraz może równocześnie działać wiele procesów, które korzystają ze współdzielonych zasobów (w tym procesora, który zwykle jest tylko jeden). Istnieją rozmaite strategie szeregowania procesów. Ich ocena zależy od przyjętego kryterium.
Gdy chcemy jak najmniejszego czasu oczekiwania procesów, skorzystajmy z SJF albo SRTF. Gdy interesuje nas minimalny czas reakcji, użyjmy RR.
Te strategie można też mieszać, tworząc wiele kolejek procesów obsługiwanych różnymi strategiami. Można też dopuścić sprzężenie zwrotne, tzn. możliwość przenoszenia procesów między kolejkami.
wait, lub
też zakończy działanie.
Dana jest lista procesów wraz z ich czasami przybycia i czasami wykonania:
| Proces | Czas przybycia | Czas wykonania |
|---|---|---|
P1 | 0 | 3 |
P2 | 1 | 5 |
P3 | 2 | 2 |
P4 | 7 | 4 |
P5 | 8 | 1 |