 |
W niniejszym wykładzie zajmujemy się problemem synchronizacji współpracujących ze sobą procesów współbieżnych. Poznamy mechanizmy i techniki programistyczne służące do synchronizowania procesów.
Na początku przedstawiamy sam problem synchronizacji procesów. Dalej próbujemy rozwiązać go przy użyciu klasycznych konstrukcji programistycznych. Jest to możliwe, lecz bardzo skomplikowane i nieefektywne. Dalej poznajemy typowe mechanizmy synchronizacji procesów udostępniane przez systemy operacyjne. Ich wykorzystanie prześledzimy na typowych przykładach.
Analizując programy współbieżne zakładamy, że współbieżne wykonanie procesów może polegać na dowolnym przepleceniu wykonań poszczególnych procesów. Dodatkowo musimy pamiętać, że przeplatane nie są instrukcje języka programowania wysokiego poziomu, lecz instrukcje procesora w skompilowanym programie. Jeśli nasz program jest poprawny przy takim założeniu, to mamy pewność, że będzie działał poprawnie (niezależnie od realizacji systemu operacyjnego, parametrów technicznych komputera, zachodzących przerwań i innych procesów działających w systemie).
W przypadku programów współbieżnych testowanie programów ma bardzo ograniczone zastosowanie. Nie jesteśmy w stanie przetestować wszystkich możliwych przeplotów wykonań procesów. Siłą rzeczy testy są przeprowadzane na konkretnej platformie i konkretnym komputerze. Tak więc pomyślne wyniki testów wcale nie gwarantują, że program będzie działał poprawnie na innej platformie, czy np. na szybszym komputerze. Jesteśmy więc skazani na weryfikowanie poprawności programów współbieżnych. Już w przypadku programów sekwencyjnych jest to trudne zadanie, a w przypadku programów współbieżnych jest to bardzo trudne.
Nie jest to problem akademicki, lecz bardzo często spotykany w systemach operacyjnych. Choćby buforowanie znaków naciskanych na klawiaturze, czy wysyłanie wydruków na drukarkę to przykłady problemu producent-konsument.
Procesy producenta i konsumenta mają podobny schemat:
repeatwyprodukuj jednostkę produktu; wstaw wyprodukowaną jednostkę do buforauntil false
repeatpobierz z bufora jednostkę produktu; skonsumuj pobraną jednostkęuntil false
var
bufor: array [0..n-1] of produkt;
pierwszy: 0..n-1;
licznik: 0..n;
Początkowo zmienna pierwszy może mieć dowolną wartość
(z zakresu), a zmienna licznik powinna być równa 0.
Wstawianie i pobieranie jednostek produktu z bufora można zaimplementować
następująco:
repeatwyprodukuj jednostkę produktu; while licznik = n do; bufor [(pierwszy+licznik) mod n] :=wyprodukowana jednostka; licznik := licznik + 1 until false
repeat while licznik = 0 do;pobrana jednostka:= bufor [pierwszy]; pierwszy := (pierwszy + 1) mod n; licznik := licznik - 1;skonsumuj pobraną jednostkęuntil false
licznik := licznik + 1
i licznik := licznik - 1.
Instrukcje te mogą być zaimplementowane w języku maszynowym, na
przykład, w następujący sposób:
rejestr1 := licznik; rejestr1 := rejestr1 + 1; licznik := rejestr1i
rejestr2 := licznik; rejestr2 := rejestr2 - 1; licznik := rejestr2Załóżmy, że w buforze są trzy jednostki produktu, czyli
licznik = 3.
Współbieżnie wkładamy i pobieramy po jednej jednostce produktu do/z
bufora.
W rezultacie w buforze nadal powinny być trzy jednostki produktu.
Jeżeli instrukcje obu procesów przeplotą się w następujący sposób:
rejestr1 := licznik; rejestr2 := licznik; rejestr2 := rejestr2 - 1; licznik := rejestr2 rejestr1 := rejestr1 + 1; licznik := rejestr1to zmienna
licznik będzie równa 4!
Rozwiązaniem problemu jest "zatomizowanie" operacji pobierania i wkładania jednostek produktu z i do bufora. Należy zapewnić, aby w trakcie gdy jeden proces zmienia zawartość bufora drugi nie mógł robić tego równocześnie. Inaczej mówiąc, operacje wkładania i wyjmowania z bufora (z wyjątkiem pętli oczekujących) powinny tworzyć tzw. sekcję krytyczną.
Podstawowa własność, jaką powinna spełniać sekcja krytyczna, to wzajemne wykluczanie: tylko jeden proces na raz może przebywać w sekcji krytycznej. Gdyby było to jedyne wymaganie wobec sekcji krytycznej, to można by ją bardzo prosto zaimplementować: nie wpuszczać żadnych procesów do sekcji krytycznej. Oczywiście nie o to chodzi! Stąd też druga wymagana własność, to wykorzystanie sekcji krytycznej: jeśli jakiś proces chce wejść do sekcji krytycznej, to nie może ona pozostawać pusta.
Jeśli wiele procesów oczekuje na wejście do sekcji krytycznej, to nie jest określone w jakiej kolejności wejdą one do niej. Nie ma tu jednak zupełnej dowolności. Przyjęto najmniejsze wymagania zapewniające sensowne działanie sekcji krytycznej, brak zagłodzenia oczekujących procesów: każdy proces, który chce wejść do sekcji krytycznej ma gwarancję, że kiedyś do niej wejdzie.
Rozwiązanie problemu sekcji krytycznej polega na podaniu implementacji sekcji wejściowej i wyjściowej. Mając dane takie implementacje, moglibyśmy np. rozwiązań problem producenta-konsumenta w następujący sposób:
repeatwyprodukuj jednostkę produktu; while licznik = n do;sekcja wejściowa; bufor [(pierwszy+licznik) mod n] :=wyprodukowana jednostka; licznik := licznik + 1;sekcja wyjściowauntil false
repeat while licznik = 0 do;sekcja wejściowa;pobrana jednostka:= bufor [pierwszy]; pierwszy := (pierwszy + 1) mod n; licznik := licznik - 1;sekcja wyjściowa;skonsumuj pobraną jednostkęuntil false
var
k: array [1..2] of 0..1;
czyja_kolej: 1..2;
Początkowo komórki tablicy k są równe 1.
Każdy z procesów kontroluje jedną komórkę tej tablicy.
Gdy proces chce wejść do sekcji krytycznej, to ustawia
komórkę na 0, aż do chwili wyjścia z sekcji krytycznej.
Zmienna czyja_kolej jest początkowo równa 1.
Łamie ona symetrię między procesami.
W sytuacji, gdy obydwa procesy chcą wejść do sekcji krytycznej
zmienna ta rozstrzyga, który powinien ustąpić drugiemu.
Zakładamy, że procesy mają numery 1 i 2, i każdy proces pamięta
swój numer na zmiennej lokalnej p.
k [p] := 0;
while k [3 - p] = 0 do begin
if czyja_kolej ≠ p then begin
(* Ustąp drugiemu procesowi. *)
k [p] := 1;
while czyja_kolej ≠ p do;
k [p] := 0
end
end
k [p] := 1;
czyja_kolej := 3 - p;
var
wybieranie: array [1..n] of boolean;
numerek: arrzy [0..n-1] of integer;
Początkowo elementy tych tablic są równe odpowiednio
false i 0.
Procesy są ponumerowane od 1 do n.
Zakładamy, że każdy proces pamięta swój numer na zmiennej lokalnej
p.
Procesy chcące wejść do sekcji krytycznej "pobierają numerki".
W tablicy wybieranie proces zaznacza, iż jest właśnie
w trakcie pobierania numerka, a pobrany numerek zapamiętuje
w tablicy numerek.
Proces wchodzi do sekcji krytycznej, gdy upewni się, że jest
pierwszy w kolejce.
Po wyjściu z sekcji krytycznej proces "wyrzuca numerek", tzn.
zapisuje w tablicy numerek wartość 0.
Jest pewna różnica między algorytmem piekarnianym, a systemem numerków
stosowanym w urzędach pocztowych.
Może się zdarzyć, że dwa procesy otrzymają ten sam numerek.
Mamy gwarancję, że kolejne numerki tworzą ciąg niemalejący, możliwe
są w nim jednak powtórzenia.
Jeżeli dwa procesy otrzymają ten sam numerek, to pierwszeństwo ma
proces o niższym numerze (p).
Możemy więc powiedzieć, że procesy wchodzą do sekcji krytycznej
w porządku leksykograficznym par (numerek, numer procesu).
(Para (a, b) poprzedza w porządku leksykograficznym parę
(c, d), co oznaczamy przez (a, b) < (c, d),
gdy a < c, lub a = c oraz
b < d.)
wybieranie [p] := true;
numerek [p] := max (numerek [1], numerek [2], ..., numerek [n]) + 1;
wybieranie [p] := false;
for j := 1 to n do begin
while wybieranie [j] do;
while numerek [j] ≠ 0 and (numerek [j], j) < (numerek [p], p) do;
end
numerek [p] := 0;
for upewnia się/czeka aż proces nr j
nie stoi przed nim w kolejce do sekcji krytycznej.
Algorytm piekarniany jest bardziej ogólny niż algorytm Dekkera, lecz również nie jest wolny od wad: nadal mamy do czynienia z aktywnym oczekiwaniem, ponadto liczba procesów jest ograniczona przez stałą n. W kolejnym punkcie dowiemy się, jak pozbyć się aktywnego oczekiwania.
P --
Jeżeli semafor jest równy 0 (semafor jest opuszczony), to
proces wykonujący tę operację zostaje wstrzymany, dopóki
wartość semafora nie zwiększy się (nie zostanie on podniesiony).
Gdy wartość semafora jest dodatnia (semafor jest
podniesiony), to zmniejsza się o 1 (pociąg zajmuje jeden
z k wolnych torów).
V --
Wartość semafora jest zwiększana o 1 (podniesienie semafora).
Jeżeli jakiś proces oczekuje na podniesienie semafora, to
jest on wznawiany, a semafor natychmiast jest zmniejszany.
Rozwiązanie problemu sekcji krytycznej za pomocą semaforów jest
banalnie proste.
Wystarczy dla każdej sekcji krytycznej utworzyć odrębny semafor,
nadać mu na początku wartość 1,
w sekcji wejściowej każdy proces wykonuje na semaforze operację
P, a w sekcji wyjściowej operację V.
Wymaga to jednak od programisty pewnej dyscypliny:
Każdej operacji P musi odpowiadać operacja V
i to na tym samym semaforze.
Pomyłka może spowodować złe działanie sekcji krytycznej.
Jeżeli procesy mogą przebywać na raz więcej niż w jednej sekcji krytycznej, to musimy zwrócić uwagę na możliwość zakleszczenia. Problem zakleszczenia jest omówiony szczegółowo w następnym wykładzie. Wyobraźmy sobie, że mamy dwa semafory: S i Q, każdy związany z jedną sekcją krytyczną. Mamy też dwa procesy: P1 i P2 -- każdy z nich chce wejść równocześnie do obydwu sekcji krytycznych. Jeżeli są one zaimplementowane następująco:
P(S); P(Q);Sekcje krytyczneV(Q); V(S);
P(Q); P(S);Sekcje krytyczneV(S); V(Q);
Semafory są tak często stosowane do rozwiązywania problemu sekcji krytycznej, że spotyka się ich uproszczoną wersję: semafory binarne. Semafor binarny, to taki semafor, który może przyjmować tylko dwie wartości: 0 i 1. Próba podniesienia semafora równego 1, w zależności od implementacji, nie zmienia jego wartości lub powoduje błąd.
Zastosowanie semaforów nie ogranicza się do problemu sekcji
krytycznej.
Operacje P i V nie muszą być wykonywane
zgodnie z podanym wyżej schematem.
Przykładem innego zastosowania semaforów będzie podane niżej
rozwiązanie problemu producenta-konsumenta.
Możliwych jest wiele różnych implementacji kolejek komunikatów, różniących się zestawem dostępnych operacji i ew. ograniczeniami implementacyjnymi. Pojemność kolejki może być ograniczona. Wówczas próba włożenia komunikatu do kolejki powoduje wstrzymanie procesu w oczekiwaniu na pobranie komunikatów. Niektóre implementacje mogą udostępniać nieblokujące operacje wkładania/pobierania komunikatów -- wówczas zamiast wstrzymywania procesu przekazywana jest informacja o niemożności natychmiastowego wykonania operacji. Możliwe jest też selektywne pobieranie komunikatów z kolejki.
Kolejki komunikatów są równie silnym mechanizmem synchronizacji, co semafory. Mając do dyspozycji semafory można zaimplementować kolejki komunikatów -- przekonanie się o tym pozostawiamy jako ćwiczenie dla czytelnika. Odwrotna konstrukcja jest również możliwa. Rozważmy kolejkę komunikatów, do której wkładamy tylko puste, nic nie znaczące komunikaty. Wówczas kolejka taka będzie zachowywać się jak semafor. Chcąc zainicjować ją na określoną wartość, należy na początku włożyć do niej określoną ilość pustych komunikatów.
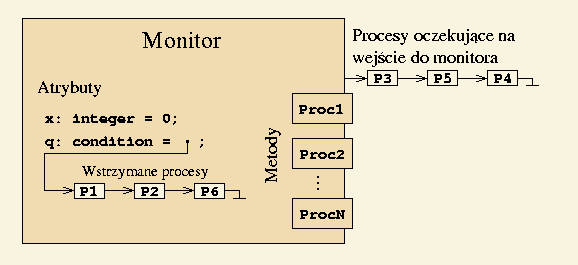
Monitory stanowią wygodniejsze rozwiązanie problemu sekcji krytycznej
niż semafory, ze względu na ich strukturalny charakter.
Stosując semafory można popełnić szereg błędów programistycznych:
zapomnieć o podniesieniu czy opuszczeniu semafora,
pomylić semafory, czy np. pomylić operacje P i
V.
W przypadku monitorów odpowiednie instrukcje synchronizujące są
realizowane przez język programowania.
Monitory nie sprowadzają się tylko do strukturalnej sekcji krytycznej.
Udostępniają one dodatkowo kolejki procesów typu
condition.
Kolejki takie mogą być używane tylko wewnątrz monitorów.
Są to kolejki FIFO.
Kolejki condition udostępniają dwie operacje:
wait --
powoduje wstrzymanie procesu i wstawienie go na koniec kolejki,
signal --
powoduje wznowienie pierwszego procesu z kolejki,
o ile kolejka nie jest pusta.
| |
signal na (niepustej) kolejce, to nagle w monitorze
mamy dwa procesy.
Z drugiej strony, w monitorze może przebywać tylko jeden proces
na raz.
Istnieją dwa rozwiązania tego problemu:
signal może być wykonywana tylko
jako ostatnia w monitorze.
Po jej wykonaniu proces natychmiast opuszcza monitor.
Rozwiązanie to jest o tyle ograniczone, że jeden proces
może wznowić tylko jeden inny proces.
signal.
Jednak wypychany proces jest wstawiany na początek
kolejki procesów oczekujących na wejście do monitora.
Dzięki temu jesteśmy w stanie prześledzić co się będzie
działo w monitorze do momentu ponownego wejścia wypchniętego
procesu.
Przypomnijmy, że w wykładzie poświęconym procesom poznaliśmy pojęcie wątku, sposób tworzenia wątków w Javie oraz podstawowe operacje na wątkach. Teraz zajmiemy się synchronizacją wątków.
W Javie zaimplementowano uproszczony mechanizm monitorów.
Każdy obiekt może być monitorem.
W tym celu, wszystkie udostępniane metody należy zadeklarować jako synchronized.
Efekt jest taki, że tylko jeden wątek na raz może wykonywać takie metody obiektu.
Każdy kolejny wątek zostanie wstrzymany i będzie oczekiwał w kolejce, aż wątek wykonujący
jedną z tych metod opuści obiekt.
Natomiast wątek, który już wykonuje metodę synchronized może bez przeszkód
wywołać kolejną taką metodę danego obiektu.
Obiekt zostanie zwolniony, gdy zakończy wykonywanie wszystkich tych metod.
Jeżeli tworzymy klasę monitorów, to dobrym zwyczajem jest, aby atrybuty obiektów
nie były bezpośrednio dostępne.
Zamiast tego możemy udostępnić metody służące do ich modyfikowania i badania ich wartości.
Ponadto, wszystkie udostępniane metody najlepiej zadeklarować jako synchronized.
W ten sposób mamy gwarancję że tylko jeden wątek na raz będzie wykonywał metody obiektu,
a dodatkowo żaden inny wątek nie będzie w tym samym czasie modyfikował wartości atrybutów.
Oto prosty przykład:
public class Counter {
private int c = 0;
public synchronized void inc() {
c++;
}
public synchronized void dec() {
c--;
}
public synchronized int val() {
return c;
}
}
Jeżeli nie chcemy tworzyć monitora, a chcemy na chwilę uzyskać wyłączny dostęp do jakiegoś
obiektu, to możemy skorzystać z instrukcji synchronized.
Jej składnia jest następująca: synchronized (wyrażenie) instrukcja.
Wynikiem wyrażenia jest obiekt (referencja do obiektu), który zajmujemy na wyłączność,
na czas wykonania (bloku) instrukcji.
Oto prosty przykład pokazujący tę konstrukcję.
Zachęcamy do przetestowania jej w podanej postaci, oraz z usuniętym synchronized.
import java.util.Random;
public class Sync extends Thread {
static Object sekcja = new Object();
static int n = 0;
Random gen = new Random();
public void run() {
int r;
for (int i = 1; i <= 12; i++) {
synchronized (sekcja) {
// Opóźnienie, w trakcie którego zmienia się wartość n
r = gen.nextInt(100000);
for (int j = 1; j <= r; j++) { n = n + i * j;}
for (int j = 1; j <= r; j++) { n = n - i * j;}
n = n+1;
System.out.println(n);
}
}
}
public static void main(String args[])
{
new Sync().start();
new Sync().start();
}
}
Java implementuje uproszczone monitory, ponieważ mamy do dyspozycji tylko jedną (niejawną)
kolejkę typu condition w obiekcie.
Jeżeli wątek wykona operację wait(), to zostaje zawieszony i umieszczony w tej kolejce.
Gdy inny wątek wykona operację notify(), to wątek, który najdłużej czeka budzi się.
Jest też dostępna operacja notifyAll(), która budzi wszystkie czekające wątki.
Jeśli żaden wątek nie czeka na obudzenie, to te dwie operacje nie przynoszą żadnych skutków.
Zwykle wątek wykonuje wait(), gdy czeka na spełnienie jakiegoś warunku,
a notify() lub notifyAll(), gdy warunek, na który ktoś może czekać
mógł się stać się prawdziwy.
W momencie gdy jakiś wątek wykona notify() lub notifyAll() mamy
potencjalnie trzy grupy procesów, które mogą chcieć wejść do monitora:
notify() lub notifyAll()
pozostaje w monitorze.
Po drugie, wątki obudzone i czekające na wejście do monitora konkurują na równych prawach
o wejście do monitora.
W praktyce oznacza to, że nie mamy żadnej gwarancji, że obudzony wątek wejdzie do monitora
bezpośrednio po opuszczeniu go przez wątek, który go obudził.
Może się zdarzyć, że między nie "wciśnie się" wątek, który jeszcze nie wszedł do monitora.
Utrudnia to wnioskowanie o kolejności, w jakiej wątki wchodzą do monitora. W praktyce oznacza to, że czekając na spełnienie jakiegoś warunku, zamiast prostej konstrukcji:
if (...) wait();należy raczej stosować konstrukcję:
while (...) wait();W ten sposób, nawet jeśli między wykonaniem
notify(), a wejściem obudzonego
wątku do monitora, dany warunek przestanie być prawdziwy, to wątek ponownie zacznie
oczekiwać na jego spełnienie.
Biorąc pod uwagę, że każdy obiekt dysponuje tylko jedną (niejawną) kolejką typu
condition, obudzony wątek i tak powinien się upewnić, czy to akurat
on powinien być obudzony.
Mimo wszystkich odstępstw od klasycznych monitorów, przedstawione mechanizmy synchronizacji
wątków wystarczają do rozwiązania wielu mniej skomplikowanych zadań.
Czytelników zainteresowanych bardziej zaawansowanymi mechanizmami synchronizacji w Javie
odsyłamy do pakietu java.util.concurrent.
W przypadku komputerów wieloprocesorowych blokowanie przerwań jest niewystarczające. Nawet przy zablokowanych przerwaniach kilka procesów może działać równolegle. Potrzebne jest wówczas inne wsparcie sprzętowe.
Przykładem takiego wsparcia może być instrukcja procesora
test-and-set (testuj i ustaw).
Działaniu tej instrukcji odpowiada następująca funkcja:
function TestAndSet (var x: boolean): boolean;
begin
TestAndSet := x;
x := true
end;
W wyniku jej wykonania zmienna x uzyskuje wartość
true, a wynikiem funkcji jest poprzednia wartość
zmiennej x.
Znaczenie tej instrukcji polega na tym, że jest ona wykonywana
w sposób niepodzielny, atomowy.
Między pobraniem wartości x, a ustawieniem jej na
true żaden inny proces nie ma dostępu do zmiennej
x.
Korzystając z instrukcji TestAndSet możemy
rozwiązać problem sekcji krytycznej:
while TestAndSet (S) do;
S := false;
Istnieją również inne instrukcje, równoważne TestAndSet,
np. instrukcja exchange (zamień).
Powoduje ona, że dwie podane komórki pamięci zamieniają się
wartościami.
Ponownie, istotne jest to, że operacja zamiany jest wykonywana
w sposób niepodzielny.
Przyjmijmy, że struktura danych reprezentująca bufor jest taka jak poprzednio.
var
bufor: array [0..n-1] of produkt;
pierwszy: 0..n-1;
licznik: 0..n;
Możemy użyć semafora (S) do stworzenia sekcji
krytycznej, w której umieścimy operacje wkładania i wyjmowania
jednostek produktu z bufora.
Nie wyeliminuje to jednak aktywnego oczekiwania na produkt lub
puste miejsce w buforze.
Aktywne oczekiwanie możemy wyeliminować używając dwóch dodatkowych
semaforów: jeden (pełne) będzie równy liczbie
jednostek produktu znajdujących się w buforze, a drugi
(puste) będzie równy liczbie pustych miejsc w buforze.
Początkowo semafor S jest równy 1,
pełne jest równy 0, a puste jest równy
n.
Procesy producenta i konsumenta wyglądają wówczas następująco:
repeatwyprodukuj jednostkę produktu; P(puste); P(S); bufor [(pierwszy+licznik) mod n] :=wyprodukowana jednostka; licznik := licznik + 1; V(S); V(pełne) until false
repeat P(pełne); P(S);pobrana jednostka:= bufor [pierwszy]; pierwszy := (pierwszy + 1) mod n; licznik := licznik - 1; V(S); V(puste);skonsumuj pobraną jednostkęuntil false
pełne i
puste.
Nie tworzą one sekcji krytycznych, lecz synchronizują pobieranie
i wstawianie elementów do bufora.
Widać na tym przykładzie, że semafory mają szersze zastosowanie,
niż tylko tworzenie sekcji krytycznych.
Rozwiązanie to ma jeszcze jedną zaletę.
Nawet jeżeli uruchomimy kilku producentów i konsumentów,
to będą oni poprawnie korzystać ze wspólnego bufora.
Uczciwość kolejności w jakiej budzone są procesy oczekujące na
podniesienie semafora gwarantuje, że nie wystąpi zagłodzenie.
Rozwiążemy teraz problem producenta-konsumenta za pomocą
monitorów.
Monitor będzie udostępniał dwie operacje:wstaw i
pobierz.
Użyjemy takiej samej struktury danych do zaimplementowania bufora.
Dodatkowo potrzebne będą nam dwie kolejki procesów:
pełne -- oczekujących na produkty i
puste -- oczekujących na puste miejsca w buforze.
monitor producent_konsument;
var
bufor: array [0..n-1] of produkt;
pierwszy: 0..n-1;
licznik: 0..n;
pełne, puste: condition;
procedure wstaw(p: produkt);
begin
if licznik = n then wait(puste);
bufor [(pierwszy+licznik) mod n] := p;
licznik := licznik + 1;
signal(pełne)
end;
function pobierz: produkt;
begin
if licznik = 0 then wait(pełne);
pobierz := bufor [pierwszy];
pierwszy := (pierwszy + 1) mod n;
licznik := licznik - 1;
signal(puste)
end;
begin
pierwszy := 0;
licznik := 0
end;
Oto rozwiązanie za pomocą monitorów.
Używamy w nim dwóch kolejek procesów: czytelnicy,
to czytelnicy oczekujący na wejście do biblioteki,
a pisarze, to pisarze oczekujący na wejście do
biblioteki.
Dodatkowo zmienna licznik jest równa liczbie
czytelników w bibliotece, lub -1, gdy jest w niej pisarz.
Monitor udostępnia cztery procedury, wejście i wyjście z
biblioteki odpowiednio dla czytelników i pisarzy.
monitor czytelnicy_i_pisarze;
var
licznik: integer;
czytelnicy, pisarze: condition;
procedure wejście_czytelnika;
begin
if (licznik = -1) or not empty(pisarze) then wait(czytelnicy);
licznik := licznik + 1;
signal(czytelnicy)
end;
procedure wyjście_czytelnika;
begin
licznik := licznik - 1;
if licznik = 0 then signal(pisarze)
end;
procedure wejście_pisarza;
begin
if licznik ≠ 0 then wait(pisarze);
licznik := -1
end;
procedure wyjście_pisarza;
begin
licznik := 0;
if empty(czytelnicy) then signal(pisarze) else signal(czytelnicy)
end;
begin
licznik := 0;
end;
Zwróćmy uwagę, w jaki sposób wszyscy oczekujący czytelnicy
wchodzą do biblioteki po wyjściu pisarza.
Pisarz budzi pierwszego oczekującego czytelnika, ten budzi
drugiego, który budzi trzeciego itd.
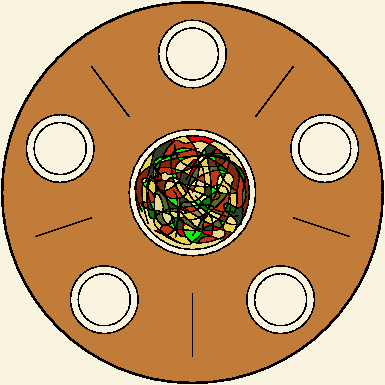 |
Czy można by uniknąć blokady, gdyby filozofowie brali pałeczki tylko po dwie naraz? Jeżeli jedna z pałeczek jest używana przez innego filozofa, to czeka on, aż obydwie będą leżeć na stole. Okazuje się, że wówczas możliwe jest zagłodzenie. Przypuśćmy, że jeden z filozofów siada do stołu i czeka na pałeczkę z prawej strony. W tym czasie z jego lewej strony siada jego kolega i zaczyna jeść, zabierając pałeczkę z lewej strony. Po chwili filozof z prawej strony odkłada pałeczkę, ale nasz filozof nie może jej wziąć, bo brak pałeczki po lewej stronie. Po chwili filozof z prawej strony wraca i zaczyna jeść, zabierając pałeczkę z prawej strony. Filozof z lewej strony kończy jeść i odkłada pałeczkę, ale teraz nie ma pałeczki z prawej strony, itd. Widzimy, że nasz filozof będzie czekał raz na pałeczkę z lewej, raz prawej strony, ulegając (dosłownie) zagłodzeniu.
Istnieje wiele rozwiązań tego problemu. Jedno z nich polega na ograniczeniu liczby równocześnie jedzących filozofów do 4. Powiedzmy, że każdy z filozofów zanim usiądzie, bierze talerz. Wystarczy, że w jadalni będą tylko 4 talerze. Każdą pałeczkę reprezentujemy jako semafor, początkowo równy 1. Wzięcie pałeczki, to opuszczenie semafora, a jej odłożenie, to podniesienie semafora. Talerzom odpowiada semafor, którego początkowa wartość, to 4. Podobnie, wzięcie talerza, to opuszczenie semafora, a odłożenie, to podniesienie semafora. Przyjmujemy, że filozofowie i pałeczki są ponumerowani od 0 do 4.
var paleczki: array [0..4] of semaphore; talerze: semaphore; procedure filozof(i: 0..4); begin repeatmyśl; P(talerz); P(paleczki[i]); P(paleczki[(i + 1) mod 5]);jedz; V(paleczki[i]); V(paleczki[(i + 1) mod 5]); V(talerz); until false end;
W niniejszym wykładzie przedstawiliśmy problematykę synchronizacji procesów współbieżnych, oraz podstawowe mechanizmy synchronizacji: semafory, kolejki komunikatów i monitory. Ich użycie zostało zilustrowane na klasycznych przykładach.
exchangeconditiontest-and-setexchange.