System plików
W niniejszym wykładzie zajmujemy się systemem plików.
Przedstawiamy typowy interfejs plików, możliwe struktury katalogów,
a także sposób implementacji systemu plików.
System plików pełni w systemie operacyjnym rolę pamięci trwałej.
Informacje zapisane w pamięci trwałej nie są gubione między kolejnymi uruchomieniami systemu.
Zwykle pamięć trwała, to dyski magnetyczne (tak też przyjmiemy na potrzeby tego wykładu).
Informacje przechowywane w systemie plików są pogrupowane w pliki i katalogi.
Czytelnik zapewne bardzo dobrze zna te pojęcia.
Niemniej warto zapoznać się z tym, co system plików może nam udostępniać -- być może kryje nie znane nam jeszcze możliwości.
Implementacja systemu plików to ciekawy temat, choć zapewne większość czytelników nie będzie miała
okazji implementować żadnego systemu plików.
Warto jednak wiedzieć jakie są możliwe implementacje i jaki mają one wpływ na efektywność systemu plików.
Ta wiedza może być bardzo przydatna przy konfigurowaniu systemu komputerowego.
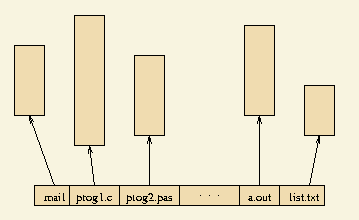
W systemie plików występują dwa podstawowe rodzaje obiektów: pliki i katalogi.
Pliki służą bezpośrednio do przechowywania informacji, a katalogi służą do grupowania plików i innych (pod)katalogów.
Pojęcie pliku jest zapewne doskonale znane czytelnikowi, niemniej przedstawmy pokrótce typowe cechy pliku:
- Nazwa -- symboliczna nazwa identyfikująca plik w obrębie katalogu, w którym się on znajduje.
W niektórych systemach plików, ten sam plik może występować pod wieloma nazwami i w wielu katalogach.
Nie zawsze więc plik ma jednoznacznie określoną nazwę, natomiast zawsze nazwa i katalog jednoznacznie określają plik.
- Typ -- określa rodzaj informacji przechowywanej w pliku.
W zależności od rodzaju systemu operacyjnego, typ pliku może być mniej lub bardziej kontrolowany przez system operacyjny.
Przykładowe typy plików to: program wykonywalny, plik tekstowy, dokument, grafika w określonym formacie, itd.
Jeśli system operacyjny ściśle kontroluje typy plików, to typ pliku określa sposób jego wykorzystania i
może określać strukturę pliku (np. program można tylko uruchomić, obrazek wyświetlić, a tekst przeczytać).
Z drugiej strony, jeżeli system operacyjny nie kontroluje ściśle typów plików, to typ pliku może mieć charakter konwencji
związanej z nazywaniem plików (np. programy wykonywalne mają nazwę kończącą się na .exe, a pliki
tekstowe na .txt).
(Oczywiście każdy system operacyjny określa strukturę plików stanowiących programy wykonywalne,
gdyż musi być w stanie je uruchamiać.)
Wówczas, z punktu widzenia systemu operacyjnego, wszystkie pliki mają jednolitą strukturę, a sposób ich interpretacji
określa konwencja.
Tak jest np. w systemie Unix, Linux i Windows.
- Treść -- informacje przechowywane w pliku.
W zależności od rodzaju systemu operacyjnego, treści plików mogą posiadać zróżnicowaną strukturę lub nie.
W systemach Unix, Linux i Windows pliki to ciągi bajtów określonej długości.
Ich interpretacja zależy od typu pliku.
Może też być tak, że system operacyjny określa bardziej złożoną strukturę plików, np. traktuje plik jak ciąg
rekordów określonej wielkości.
- Wskaźnik pliku -- wskazuje miejsce w pliku, którego będzie dotyczyć kolejna operacja czytania/pisania.
- Prawa dostępu -- w systemach zapewniających ochronę danych, z każdym plikiem (jak również z katalogiem) są
związane prawa dostępu, określające jakie operacje mają prawo wykonywać dani użytkownicy.
Dokładny zestaw praw dostępu i ich znaczenie zależy od konkretnego systemu operacyjnego.
Przykładowe prawa dostępu to: prawo do odczytu pliku, prawo do modyfikacji pliku, prawo do dopisywania
informacji na końcu pliku czy prawo do zmiany praw dostępu.
- Czas utworzenia/ostatniej modyfikacji/ostatniego dostępu
-- są to dane o charakterze administracyjnym, ułatwiające archiwizację, porównywanie wersji plików, zarządzanie plikami
tymczasowymi itp.
Wszystkie z tych atrybutów mają również odniesienie do katalogów, pod warunkiem, że za treść katalogu przyjmiemy listę
plików i podkatalogów znajdujących się w danym katalogu.
Pliki i katalogi możemy traktować jak trwałe obiekty pewnego abstrakcyjnego typu danych.
Z punktu widzenia użytkownika istotne jest, jakie operacje można wykonywać na nich.
Operacje te możemy podzielić na dwie grupy: operacje na całych plikach/katalogach oraz operacje
modyfikująca/odczytujące informacje z pojedynczego pliku/katalogu.
Typowe operacje na całych plikach/katalogach, to:
- zmiana nazwy pliku/katalogu,
- przeniesienie pliku/katalogu do innego katalogu,
- usunięcie pliku/katalogu,
- skopiowanie pliku,
- utworzenie nowego (pustego) katalogu,
- wypisanie treści pliku/zawartości katalogu.
Często dla procesów jest określony ich tzw. aktualny katalog roboczy.
Jest to katalog, który stanowi rodzaj kontekstu dla procesu.
Wszelkie nazwy plików i katalogów są domyślnie interpretowane względem tego katalogu.
Ułatwia to nazywanie plików, na których najczęściej operuje program.
W takim przypadku mamy w systemie dodatkową operację: zmianę aktualnego katalogu roboczego.
Chcąc wykonywać operacje na pojedynczym pliku, musimy najpierw otworzyć ten plik.
Otwierając plik musimy zidentyfikować go w strukturze katalogów.
W wyniku otwarcia uzyskujemy pewnego rodzaju "uchwyt" pliku, zwany deskryptorem.
Dalsze operacje są wykonywane za pośrednictwem tego uchwytu.
Operacja otwarcia pliku może również powodować utworzenie nowego, pustego pliku.
Pojęcie wskaźnika pliku dotyczy deskryptora pliku -- jeśli równocześnie kilka procesów otworzy dany plik, to każdy
z nich będzie miał własny wskaźnik pliku.
Deskryptor pliku jest niszczony w momencie wykonania operacji zamknięcia pliku.
Zwykle dane czytane z / pisane do pliku są buforowane.
Zamknięcie pliku wiąże się z zapisaniem danych oczekujących w buforze.
Zwykle plik, jako struktura danych, to ciąg bajtów, lub większych rekordów.
(Jeżeli system operacyjny kontroluje typy plików, to pliki niektórych typów mogą mieć bardziej skomplikowaną strukturę.)
W momencie otwarcia wskaźnik pliku jest ustawiony na początek pliku.
Operacja otwarcia pliku może określać, czy będziemy czytać z pliku, czy też pisać do niego.
W przypadku, gdy możemy pisać do pliku, możliwe jest też otwarcie pliku z jednoczesnym ustawieniem
wskaźnika pliku na koniec pliku -- tzw. otwarcie pliku w celu dopisywania (ang. append).
Dostępne operacje, to:
- odczytanie bajtu/rekordu (wskazywanego przez wskaźnik pliku) --
powoduje przesunięcie wskaźnika pliku do następnego bajtu/rekordu,
- odczytanie wielu bajtów/rekordu -- równoważne wielu operacjom odczytania jednego bajtu/rekordu, ale
efektywniejsze,
- zapisanie bajtu/rekordu (wskazywanego przez wskaźnik pliku) -- powoduje przesunięcie wskaźnika pliku do następnego
bajtu/rekordu; jeżeli wskaźnik pliku wskazuje na koniec pliku, to plik ulega wydłużeniu,
- zapisanie wielu bajtów/rekordu -- równoważne wielu operacjom zapisania jednego bajtu/rekordu, ale
efektywniejsze,
- przesunięcie wskaźnika pliku na zadaną pozycję.
Jeżeli po otwarciu pliku dostępna jest operacja przesunięcia wskaźnika, to mamy do czynienia z
plikiem o dostępie swobodnym.
W przeciwnym przypadku operacje na pliku, siłą rzeczy, przetwarzają kolejne bajty/rekordy.
Mówimy wówczas o dostępie sekwencyjnym do pliku.
Większość systemów operacyjnych wyróżnia typ plików tekstowych,
udostępniając zestaw operacji dostosowany do przetwarzania plików tekstowych.
Plik tekstowy to ciąg wierszy zakończony znakiem końca pliku, a wiersze to ciągi znaków zakończone znakami końca wiersza.
Typowe operacje na pliku tekstowym, to:
- wczytanie wiersza lub jego fragmentu,
- wypisanie wiersza lub jego fragmentu,
Ze względu na to, że wiersze mogą być różnej wielkości, dostęp do plików tekstowych jest sekwencyjny.
Stosując dostęp sekwencyjny wraz z ograniczeniem, że plik jest otwarty albo do czytania, albo do zapisu,
możemy ten sam interfejs programistyczny zastosować nie tylko do korzystania z plików zapisanych na dysku, ale
również niektórych urządzeń, czy potoków informacji przesyłanych między procesami.
Na przykład, możemy traktować klawiaturę jak plik tekstowy o dostępie sekwencyjnym, z którego możemy tylko czytać,
a drukarkę, jak plik tekstowy o dostępie sekwencyjnym, do którego możemy tylko pisać.
Ze względu na to, że pula plików dostępnych w systemie jest wspólna dla wszystkich procesów i
wiele procesów może jednocześnie korzystać z tych samych plików, należy określić semantykę operacji wykonywanych
współbieżnie przez wiele procesów na tym samym pliku.
W szczególności semantyka ta powinna określać kiedy zmiany dokonane w pliku przez jeden z procesów stają się widoczne dla
pozostałych procesów.
Poniżej przedstawiamy trzy podstawowe podejścia do określenia semantyki plików:
- Zmiany zawartości pliku wykonywane przez jeden proces są natychmiast widoczne dla pozostałych procesów.
Każdy proces w każdej chwili widzi dokładnie tę samą treść pliku.
W podejściu tym system operacyjny jest całkowicie odpowiedzialny za synchronizowanie dostępu do plików i
buforowanie danych.
- System gwarantuje, że po zamknięciu pliku wszystkie zmiany treści pliku będą widoczne dla procesów,
które otworzą plik po tym zamknięciu.
Zmiany te mogą być częściowo widoczne już wcześniej.
Jeżeli kilka procesów współbieżnie modyfikuje plik, to wynik tych operacji będzie pewnym przemieszaniem
dokonywanych modyfikacji.
W podejściu tym system operacyjny może ograniczyć się do synchronizowania jedynie operacji dyskowych,
a ew. buforowanie danych może być wykonywane przez każdy proces niezależnie.
Jest to podejście najprostsze do zaimplementowania, ale najmniej wygodne.
- Współdzielenie pliku przez kilka procesów wyklucza zapisywanie do pliku.
Jeżeli proces próbuje otworzyć plik do zapisu, to nie może on być otwarty przez inne procesy --
najpierw procesy, które wcześniej otworzyły plik muszą go zamknąć.
Plik otwarty do zapisu nie może być otwarty przez inne procesy, dopóki nie zostanie zamknięty.
Plik może być otwarty przez kilka procesów tylko do czytania.
Rozwiązanie to zapewnia spójną semantykę plików przy jednocześnie stosunkowo prostej implementacji --
synchronizacja dostępu do plików odbywa się na poziomie operacji otwierania i zamykania plików.
Katalogi służą do grupowania plików.
Struktury katalogów ewoluowały w miarę rozwoju systemów operacyjnych, odzwierciedlając pojawiające się potrzeby użytkowników.
Katalog jednopoziomowy to najprostsza struktura katalogów.
W systemie jest tylko jeden katalog, w którym zgromadzone są wszystkie pliki.
Każdy plik jest jednoznacznie identyfikowany przez swoją nazwę.
Taka prymitywna struktura realizuje jedynie podstawową potrzebę gromadzenia wielu plików w systemie.
Jeżeli z komputera korzysta wielu użytkowników, to wszyscy oni muszą korzystać ze wspólnego katalogu.
Powoduje to konflikty w nazywaniu plików między użytkownikami.
Problem ten rozwiązano wprowadzając dwupoziomową strukturę katalogów.
Katalog główny zawiera szereg podkatalogów, po jednym dla każdego użytkownika.
W podkatalogach znajdują się pliki -- bez możliwości tworzenia dalszych podkatalogów.
W takiej strukturze plik jest jednoznacznie identyfikowany przez podanie nazwy podkatalogu i nazwy pliku.
Rozwiązanie likwiduje konflikty między użytkownikami, jednak nie umożliwia grupowania jednego
użytkownika o podobnym przeznaczeniu.
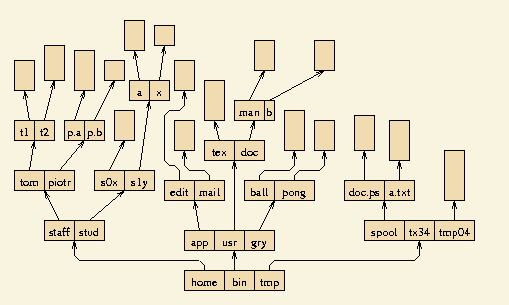
Pomysł grupowania plików użytkowników w podkatalogi łatwo uogólnić.
Katalog może zawierać pliki i podkatalogi, a cała struktura katalogów może mieć kształt drzewa,
którego korzeń stanowi główny katalog.
Każdy użytkownik może mieć swój katalog oraz dodatkowo może dowolnie grupować swoje pliki w podkatalogi.
Pliki są identyfikowane poprzez podanie ścieżki w drzewie (złożonej z nazw podkatalogów) oraz nazwy pliku.
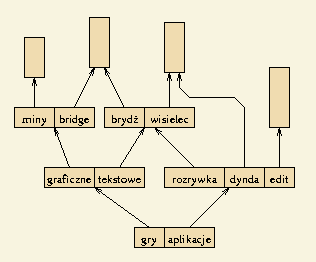
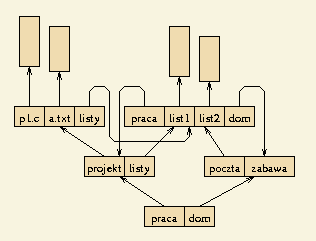
W strukturze tej dopuszczamy, aby katalogi i pliki tworzyły graf acykliczny.
Oznacza to, że każdy plik i podkatalog (ale nie katalog główny) występuje w jednym lub więcej katalogach.
Warunek acykliczności gwarantuje nam, że z katalogu głównego możemy dotrzeć do każdego katalogu i pliku.
Przy takiej strukturze katalogów mamy nową operację: wstawienie istniejącego pliku lub podkatalogu do określonego katalogu.
W wyniku wykonania takiej operacji mamy więcej niż jedno dowiązanie do danego pliku/podkatalogu.
Ponadto plik/katalog ten może w różnych katalogach pojawiać się pod różnymi nazwami.
Tak więc nazwa przestaje być atrybutem pliku/podkatalogu, lecz jest związana z katalogiem, w którym występuje.
Natomiast z każdym plikiem i podkatalogiem wiążemy nowy atrybut: licznik dowiązań.
W momencie utworzenia pliku lub podkatalogu licznik ten jest ustawiany na 1.
Każde wstawienie pliku/katalogu do kolejnego katalogu powoduje zwiększenie licznika dowiązań,
a każde usunięcie pliku/podkatalogu z określonego katalogu powoduje jego zmniejszenie o 1.
W momencie gdy wartość licznika spada do zera, plik/podkatalog jest faktycznie usuwany.
Ograniczenie się do grafów acyklicznych wynika wyłącznie z chęci zapewnienia osiągalności wszystkich podkatalogów.
Można więc od razu ograniczyć się do takich grafów, w których z głównego katalogu można dotrzeć do wszystkich
podkatalogów i plików.
Pliki przechowywane są (zwykle) na dyskach magnetycznych.
Struktura logiczna dysków jest o wiele prostsza niż systemu plików.
Dysk jest podzielony na sektory jednostki tej samej wielkości.
Wielkość sektorów jest (zwykle) potęgą 2 i przeważnie jest to 512B.
Z punktu widzenia systemu operacyjnego, pojedynczy dysk można traktować jak liniową tablicę sektorów.
Implementacja systemu plików ma architekturę warstwową, zbliżając stopniowo proste urządzenia,
jakimi są dyski, do złożonego systemu plików.
Wyróżniamy następujące warstwy:
- sterownik dysku,
- podstawowy system plików,
- moduł organizacji plików,
- logiczny system plików.
Sterownik dysku to prosty moduł, który tłumaczy podstawowe polecenia
odczytu/zapisu sektorów na odpowiednie polecenia przesyłane do odpowiedniego urządzenia dysku.
Podstawowy system plików łączy wiele sterowników dysków oraz tworzy pojęcie bloku dyskowego.
Blok dyskowy to podstawowa jednostka zapisu/odczytu z dysku.
Wielkość bloku jest wielokrotnością wielkości sektorów dyskowych, zwykle jest to 1, 2 lub 4 kB.
Podstawowy system plików, na podstawie identyfikatora dysku i numeru bloku przekazuje polecenie odczytu/zapisu
do odpowiedniego sterownika dysków.
Moduł organizacji plików jest odpowiedzialny za implementację pojęcia pliku.
Na tym poziomie pliki nie mają nazw i nie są pogrupowane w katalogi.
Pliki są identyfikowane na podstawie numerów.
Moduł ten jest odpowiedzialny za rozmieszczenie pliku na dysku.
Plik zajmuje zawsze całkowitą liczbę bloków.
Oznacza to, że (tak jak w przypadku pamięci ze stronicowaniem) mamy do czynienia z fragmentacją wewnętrzną --
ostatni blok zajmowany przez plik jest zajęty tylko częściowo.
Z grubsza rzecz biorąc, można przyjąć, że średnio tracimy 1/2 bloku dyskowego na plik.
Moduł organizacji plików, znając rozmieszczenie pliku na dysku, jest w stanie przetłumaczyć
numer kolejnego bloku w określonym pliku, na pozycję tego bloku na dysku.
Moduł ten zarządza też pulą wolnych bloków dyskowych i przydziela je plikom.
Logiczny system plików jest odpowiedzialny za implementację
katalogów i udostępnia użytkownikom opisany interfejs systemu plików.
Odpowiada on również za kontrolę praw dostępu do plików.
Przyjrzymy się teraz kilku przykładowym metodom przydziału miejsca na dysku.
Metody te przypominają trochę metody zarządzania pamięcią.
Przydział ciągły to najprostsza, ale i najgorsza metoda przydziału miejsca na dysku.
Każdy plik zajmuje na dysku spójny obszar złożony z kolejnych bloków.
Metoda ta jest zła, gdyż wielkość pliku może się zmieniać w czasie.
Jeżeli nie będziemy w stanie wydłużyć pliku, a na dysku będzie wolne miejsce,
to oznaczać to będzie konieczność przemieszczenia plików na dysku
(analogiczne do kompaktyfikacji segmentów pamięci).
Jest to bardzo czasochłonne.
Z drugiej strony informacja o rozmieszczeniu pliku na dysku jest
bardzo prosta: wystarczy pamiętać początek i rozmiar pliku.
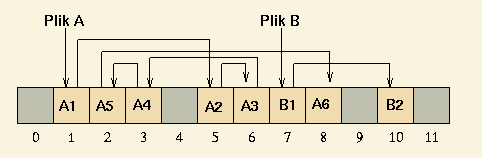
Przydział listowy polega na tym, że bloki tworzące jeden plik są połączone w listę jednokierunkową.
Każdy z bloków zawiera numer następnego bloku tworzącego plik.
Dzięki temu bloki pliku mogą być rozmieszczone dowolnie.
Plik jest identyfikowany przez pierwszy swój blok.
Wadą takiego rozwiązania jest bardzo wolny dostęp swobodny do pliku.
Zmiana pozycji w pliku może wymagać przejrzenia bloków tworzących plik od początku pliku.
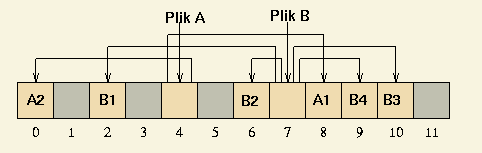
Pewnym usprawnieniem przydziału listowego jest zebranie wszystkich wskaźników tworzących listę razem, w jednej tablicy.
Tablicę taką nazywamy FAT (ang. file allocation table.
Co prawda nadal dostęp do dowolnego miejsca w pliku może wymagać liniowej liczby kroków,
ale liczba bloków dyskowych, które należy odczytać jest dużo mniejsza (zwłaszcza, jeśli plik zajmuje kolejne bloki na dysku).
Przykładowo, jeżeli bloki dyskowe mają po 4kB, a elementy FAT mają po 32 bity,
to jeden blok dyskowy jest w stanie pomieścić 1024 komórki FAT.
Jeżeli dodatkowo kolejne bloki pliku są rozmieszczone (w miarę) w kolejnych blokach dysku,
to odczytując jeden blok FAT-u możemy być w stanie przejść do 1024 elementów listy bloków tworzących plik.
W praktyce, obszary tablicy FAT dotyczące przetwarzanych właśnie plików są przechowywane w buforze,
co eliminuje operacje dyskowe związane z dostępem swobodnym.
Nadal pozostaje jednak liniowy koszt odnalezienia szukanego elementu na liście.
Blok dyskowy nie musi być jednostką przydziału miejsca na dysku.
Zwykle system operacyjny będzie dążył do umieszczania kolejnych bloków pliku w kolejnych blokach na dysku.
Tak więc jednostką przydziału może być ciąg kolejnych bloków na dysku (ang. extent).
(Jest tak np. w systemie plików NTFS.)
Przydział wielu ciągłych obszarów to modyfikacja przydziału listowego.
Rozmieszczenie pliku na dysku jest opisane jako lista extentów.
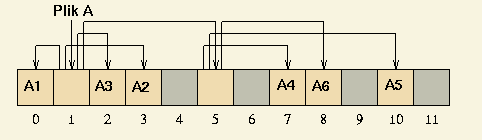
Przydział indeksowy polega na zebraniu numerów bloków tworzących plik w jednym bloku, tzw. bloku indeksowym.
Plik na dysku jest reprezentowany przez numer bloku indeksowego.
Przy zastosowaniu takiej strategii, dostęp do dowolnego miejsca w pliku wymaga co najwyżej dwóch operacji dyskowych.
Jednak wielkość pliku jest ograniczona.
Przykładowo, jeżeli bloki dyskowe mają po 4kB, a numer bloku zajmuje 32bity, to maksymalna wielkość pliku to 1024*4kB = 4MB.
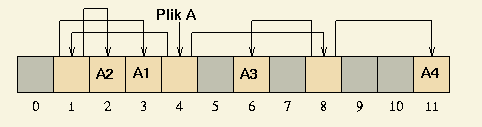
Przydział indeksowo listowy to połączenie podejścia listowego i indeksowego.
Numery kolejnych bloków dyskowych zawierających treść pliku są zebrane w bloku (lub blokach) indeksowych.
Jeżeli numery bloków tworzących plik nie mieszczą się w jednym bloku indeksowym,
to ostatni numer w tym bloku wskazuje na kolejny blok indeksowy itd.
Tak więc bloki indeksowe tworzą listę jednokierunkową.
Plik jest identyfikowany przez numer pierwszego bloku indeksowego.
Przykładowo, jeżeli bloki dyskowe mają po 4kB, a numer bloku zajmuje 32bity,
to jeden blok indeksowy może zawierać do 1023 numerów bloków z treścią pliku i jeden numer kolejnego bloku indeksowego.
Jeżeli mamy plik wielkości 42MB, to będziemy mieli 11 bloków indeksowych.
Dostęp do końcowych fragmentów pliku może wymagać nawet 12 operacji dyskowych.
Takie podejście w najgorszym przypadku będzie działało tak samo jak FAT.
Jeśli jednak plik nie jest zapisany w kolejnych blokach dyskowych, to numery bloków tworzących plik będą
zebrane razem w blokach indeksowych, a w tablicy FAT ich numery będą rozsiane.
Wielopoziomowy przydział indeksowy polega na tym, że bloki indeksowe wraz z blokami dyskowymi zawierającymi treść
pliku tworzą drzewo o określonej wysokości.
Na przykład, przy indeksowaniu dwupoziomowym, główny blok indeksowy (pierwszego poziomu) zawiera numery bloków indeksowych
drugiego poziomu, które z kolei zawierają numery bloków tworzących treść pliku.
Jeżeli bloki dyskowe mają po 4kB, a numer bloku zajmuje 32 bity, to stosując indeksowanie dwupoziomowe wielkość plików jest
ograniczona przez 4GB, a przy indeksowaniu trójpoziomowym przez 4TB.
Liczba odwołań do dysku potrzebnych do dostania się do dowolnego
miejsca na dysku jest równa liczbie poziomów indeksowania plus jeden.
Podstawową jednostką przydziału miejsca na dysku nie musi być pojedynczy blok.
Mogą to być większe liczby bloków, np. potęgi 2-ki, lub liczby Fibonacciego.
Oba te zbiory liczb mają następujące własności:
- Większy obszar można podzielić, w razie potrzeby, na dwa mniejsze obszary.
Obszary te można potem ponownie skleić w większy obszar.
- Dowolny spójny obszar bloków dyskowych można przedstawić jako logarytmiczną liczbę obszarów,
których wielkości są odpowiednio potęgami 2-ki lub liczbami Fibonacciego.
Przydział miejsca na dysku w postaci wielokrotności bloku będącej potęgą 2-ki jest stosowana np. w systemie plików NTFS.
W systemie Unix pliki są reprezentowane przez tzw. i-węzły (ang. i-node).
I-węzeł zawiera, powiedzmy, 13 numerów bloków dyskowych.
Pierwszych 10 z nich, to numery pierwszych 10 bloków treści pliku.
Jedenasty numer to numer bloku indeksowego (jednopoziomowego) do kolejnych bloków pliku.
Dwunasty numer to numer bloku indeksowego dwupoziomowego do kolejnych bloków pliku.
Ostatni (trzynasty) numer to numer do bloku indeksowego trójpoziomowego kolejnych bloków pliku.
Dzięki takiemu podejściu, liczba operacji dyskowych potrzebnych do dostania się do dowolnego
miejsca na pliku zależy od wielkości pliku i waha się od 1 do 4.
Sercem systemu plików NTFS jest główna tablica plików (ang. Master File Table, MFT).
Jest to tablica złożona z rekordów (zwykle wielkości 1KB).
Zawiera ona informacje o wszystkich plikach.
Opis każdego pliku zajmuje jeden lub więcej rekordów w MFT.
Każdy plik jest identyfikowany przez pozycję (pierwszego) opisującego go rekordu w MFT.
MFT zawiera również opis kilku tzw. meta-plików.
Meta-pliki, to sposób spojrzenia na wewnętrzne elementy NTFS, jak na pliki.
Do meta-plików zaliczają się m.inn.: MFT (sic!), mapa zajętych i wolnych bloków dyskowych, mapa złych sektorów na dysku,
tablica praw dostępu do plików i główny katalog.
Informacje o meta-plikach zajmują pierwsze 16 (lub 24) rekordy MFT.
Dzięki meta-plikom system NTFS jest bardziej elastyczny.
Na przykład, położenie MFT na dysku nie jest ustalone.
Dokładniej ustalone jest tylko położenie początku MFT.
Położenie reszty MFT jest opisane w meta-pliku MFT.
Każdy plik składa się z szeregu atrybutów.
Atrybutami są wszystkie typowe atrybuty plików (np. nazwa, czas modyfikacji), ale także treść pliku.
Generalnie, jeżeli tylko to możliwe, atrybuty są przechowywane w MFT, przy czym każdy atrybut musi
mieścić się w pojedynczym rekordzie MFT.
Jeżeli plik zajmuje więcej niż jeden rekord w MFT, to jednym z jego atrybutów jest lista kolejnych
rekordów w MFT opisujących plik.
Miejsce na dysku dla plików jest przydzielane w postaci spójnych obszarów złożonych z wielu bloków dyskowych (extent).
Liczba bloków dyskowych tworzących taki obszar jest potęgą 2-ki, przy czym numery początkowych bloków kolejnych
obszarów są "okrągłymi" liczbami w zapisie dwójkowym.
Na przykład, numer pierwszego bloku obszaru złożonego z 64 bloków jest liczbą podzielną przez 64.
Dla każdego takiego obszaru pamiętamy: jego wielkość, położenie na dysku oraz które z kolei bloki pliku są w nim przechowywane.
Tak więc, żeby zapamiętać rozmieszczenie całego pliku na dysku może być potrzebnych wiele atrybutów typu treść.
Katalogi są pamiętane podobnie do plików, przy czym zawartość katalogu jest pamiętana jako rodzaj uporządkowanego drzewa.
Nie wszystkie bloki na dysku są zajęte.
W jakiś sposób należy przechowywać informacje o wolnych blokach.
Stosowane są tu dwa rodzaje metod: albo tworzymy tablicę zajętości bloków, albo wolne bloki tworzą powiązaną strukturę.
Tablica zajętości bloków jest indeksowana numerami bloków i określa czy dany blok jest wolny, czy zajęty.
Ponieważ jest to tylko jeden bit informacji na blok, ma ona zwykle postać wektora bitowego.
Wadą takiego podejścia, jest to, że szukając wolnego bloku możemy być zmuszeni do sekwencyjnego przeglądania tablicy.
Pozwala ona jednak przydzielać wolne bloki w taki sposób, aby kolejne bloki pliku były (przeważnie) zgrupowane jako kolejne
bloki na dysku, co znacznie przyspiesza dostęp do pliku.
Łącząc wolne bloki w powiązaną strukturę możemy z nich utworzyć np. listę jednokierunkową.
Zaletą takiego podejścia jest to, że zarówno zwalnianie bloków, jak i pobieranie wolnych bloków ma stały koszt.
Nie mamy jednak wówczas wpływu na ich rozmieszczenie.
Jeżeli bloki na dysku są przydzielane plikom nie pojedynczo, ale w większej ilości -- potęgami 2-ki lub liczbami Fibonacciego,
to struktura opisująca zajęte i wolne bloki na dysku ma postać wyważonego drzewa binarnego.
Drzewo to odpowiada podziałowi większych obszarów dysku na mniejsze.
Liśćmi tego drzewa są albo obszary przydzielone konkretnym plikom, albo wolne obszary.
W wykładzie tym przedstawiliśmy podstawy budowy systemu plików.
Omówiliśmy interfejs systemu plików, z uwzględnieniem możliwych semantyk plików oraz struktur katalogów.
Przedstawiliśmy też sposób implementacji systemu plików,jej warstwową strukturę, sposoby rozmieszczenia plików na dysku
oraz zarządzania wolnymi obszarami.
- blok dyskowy
-
podstawowa jednostka przydziału pamięci dyskowej plikom; jest to wielokrotność sektora dyskowego, zwykle 1, 2 lub 4kB.
- blok indeksowy
-
blok dyskowy zawierający numery bloków tworzących treść pliku i/lub innych bloków indeksowych.
- deskryptor pliku
-
rodzaj uchwytu pliku będący wynikiem otwarcia pliku; pośredniczy w wykonywaniu kolejnych operacji na pliku.
- dostęp sekwencyjny do plików
-
ograniczenie dostępu do pliku polegające na uniemożliwieniu przesuwania wskaźnika pliku;
dostęp sekwencyjny pozwala traktować jak pliki potoki informacji i niektóre urządzenia.
- dostęp swobodny do plików
-
dostęp do pliku umożliwiający dowolne przesuwanie wskaźnika pliku.
- extent
-
obszar na dysku złożony z kolejnych bloków dyskowych, w których przechowywane są kolejne bloki danego pliku.
- pamięć trwała
-
informacje zapisane w pamięci trwałej nie są gubione między kolejnymi uruchomieniami systemu.
- pliki
-
podstawowy obiekt służący w systemie operacyjnym do przechowywania informacji w
pamięci trwałej; pliki są zwykle pogrupowane w katalogach;
jako struktura danych, plik stanowi ciąg bajtów lub bardziej złożonych rekordów.
- licznik dowiązań
-
w strukturze katalogów, która może być grafem, z każdym plikiem i podkatalogiem jest związany licznik dowiązań --
wystąpień tego pliku/podkatalogu w innych katalogach; służy on do stwierdzenia kiedy dany plik/podkatalog można usunąć.
- plik tekstowy
-
typ pliku;
plik tekstowy to ciąg wierszy zakończony znakiem końca pliku, a wiersze to ciągi znaków zakończone znakami końca wiersza.
- sektor dyskowy
-
podstawowa jednostka zapisu/odczytu z dysku, typowa wielkość sektora dyskowego to 512B.
- semantyka plików
-
semantyka współbieżnego dostępu do tego samego pliku przez kilka procesów;
w szczególności semantyka plików powinna określać kiedy zmiany
dokonane w pliku przez jeden z procesów stają się widoczne dla pozostałych procesów.
- (2p.)
Podaj przykłady urządzeń, które mogą być w systemie reprezentowane
odpowiednio przez plik o dostępie:
- sekwencyjnym tylko do czytania,
- sekwencyjnym tylko do pisania, oraz
- swobodnym, do czytania i pisania.
- (4p.)
Rozważamy system plików typu FAT na dysku wielkości 200GB.
Przyjmij, że tablica FAT jest zapisana na dysku w dwóch kopiach.
W systemie tym znajduje się ok. 500 000 plików.
Biorąc pod uwagę fragmentację wewnętrzną i wielkość tablicy FAT oblicz jaka powinna być wielkość bloków dyskowych:
1, 2, czy 4kB (tak aby łączna wielkość fragmentacji wewnętrznej i tablicy FAT była jak najmniejsza)?
Ile bitów mają numery bloków: 16, 32 czy 64?
- (4p.)
Zakładając, że i-węzeł zawiera 13 numerów bloków, bloki dyskowe mają wielkość 2kB, a numery bloków zajmują 32 bity,
oblicz największy możliwy rozmiar pliku.
Strona przygotowana przez Marcina Kubicę i Krzysztofa Stencla.