Ten wykład jest poświęcony architekturze serwera bazy danych w przypadku
konkretnego serwera, mianowicie, Microsoft SQL Server.
W odróżnieniu od serwera Oracle, na serwerze MS SQL Server jedna instalacja (instancja) serwera zawiera wiele baz danych. Bazy danych dzielą się na systemowe (jak np. master) i użytkownika. Do jednej bazie danych uprawnienia może mieć wielu użytkowników. Pełna referencja do obiektu na serwerze 2000 jest postaci:
Bazadanych.użytkownik.obiektUżytkownik to właściciel obiektu – w szczególnym przypadku, właściciel bazy danych jest dostępny zawsze pod nazwą dbo.
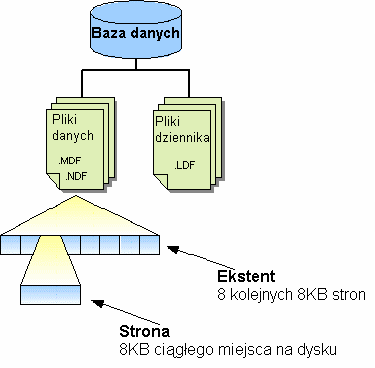
Dane w bazie danych są przechowywane w plikach, które odpowiadają fizycznym plikom na dysku. Domyślnie, przy tworzeniu bazy danych jest tworzony jeden plik danych oraz jeden plik dziennika (transakcji). Baza danych może się składać z wielu plików danych i wielu plików dziennika.
Pliki danych można grupować w grupy plików (odpowiadającym przestrzeniom tabel w Oracle), a obiekty bazy danych (tabele, indeksy) umieszczać w dowolnej grupie plików. Zaletą używania wielu plików jest to, że dane można umieścić na różnych dyskach fizycznych co prowadzi do poprawienia wydajności działania serwera. Z kolei zaletą używania grup plików jest możliwość kontroli położenia każdego obiektu bazy danych, np. tabeli w jednej grupie a jej indeksów w innej.
Szczególną bazą danych jest baza tempdb, w której tymczasowo przechowywane są dane przetwarzanych transakcji, dokonywane jest w niej sortowanie wyników zapytań przed wysłaniem odpowiedzi na zapytanie. Dlatego warto umieścić tę bazę na innym dysku fizycznym niż pozostałe bazy danych w celu podniesienia wydajności serwera (liczby operacji odczytu/zapisu w jednostce czasu).
|
|
Rys. 15.1 Podział bazy danych na pliki, plików na ekstenty, ekstentów na strony.
Rekordy danych i rekordy dziennika transakcji nigdy nie znajdują się razem w tym samym pliku. Każdy konkretny plik jest używany przez dokładnie jedną bazę danych.
Plik główny danych (ang. primary file) stanowi punkt startowy bazy danych i zawiera informacje o innych plikach w bazie danych. Każda baza danych ma dokładnie jeden plik główny danych - ma on zwykle rozszerzenie .mdf. Pozostałe pliki danych nazywają się niegłównymi (ang. secondary file) - mają zwykle rozszerzenie .ndf.
Pliki dziennika (ang. log files) zawierają informacje potrzebne do odtworzenia bazy danych po awarii. Musi być co najmniej jeden plik dziennika. Pliki dziennika mają zwykle rozszerzenie .ldf. Nie są nigdy częścią grupy plików - są zarządzane w inny sposób niż dane.
Położenia wszystkich plików w bazie danych są zapisywane zarówno w bazie danych master jak i w głównym pliku danych (tej bazy danych). Zazwyczaj system korzysta z informacji zapisanych w bazie danych master. W pewnych przypadkach jak: dołączanie nowej bazy danych, dokonywanie aktualizacji czy odtwarzanie bazy danych, system korzysta z informacji zapisanych w pliku głównym danych.
Pliki mają dwie nazwy:
Strony w pliku danych są ponumerowane kolejnymi numerami rozpoczynając od 0. Każdy plik ma swój jednoznaczny numer ID. Aby jednoznacznie zidentyfikować stronę w bazie danych trzeba podać zarówno ID pliku jak i numer strony.
Pierwsza strona w każdym pliku danych jest stroną nagłówka zawierającą informacje o atrybutach pliku. Poza tym w pliku znajduje się jeszcze kilka stron zawierających informacje systemowe, o których będzie mowa w dalszej części tego wykładu. Jedną ze stron systemowych, która występuje zarówno w pliku głównym danych jak i w pierwszym pliku dziennika jest strona startowa bazy danych - zawierająca podstawowe informacje o bazie danych.
Rozmiary plików bazodanowych mogą rosnąć automatycznie. Definiując plik, można określić przyrost wzrostu jego rozmiaru po zapełnieniu pliku. Jeśli w grupie plików jest więcej niż jeden plik, zwiększenie rozmiaru pliku następuje dopiero wtedy gdy wszystkie pliki w grupie zostaną zapełnione.
SQL Server używa proporcjonalnego wypełniania plików w grupie plików, zapisując w pliku ilość danych proporcjonalnie do ilości wolnego miejsca w danym pliku. Na przykład, jeśli w jednym pliku jest 50 MB wolnego miejsca a w drugim 100 MB to na każdy ekstent zaalokowany w pierwszym pliku zostaną zaalokowane 2 ekstenty w drugim. Ta strategia powoduje, że wszystkie pliki w grupie zostaną zapełnione w tym samym czasie. W przypadku zapełnienia plików zwiększany jest rozmiar jednego pliku (o ile ma ustawione automatyczne powiększanie) wg algorytmu round-robin.
Każdy plik może mieć określony maksymalny rozmiar. Gdy nie jest określony, rozmiar pliku będzie rosnąć aż użyje całe dostępne miejsce na dysku. Określenie maksymalnego rozmiaru jest szczególnie istotne, gdy baza danych jest osadzona w aplikacji i nikt jej nie monitoruje.
Są dwa typy grup plików:
1. główna - zawiera plik główny danych w bazie danych a także wszystkie inne pliki danych, które nie zostały przyporządkowane innym grupom plików.
2. definiowane przez użytkowników (przy użyciu słowa kluczowego FILEGROUP w instrukcji CREATE DATABASE lub ALTER DATABASE).
Jedna grupa plików jest wyróżniona jako domyślna. SQL Server alokuje strony w plikach tej grupy plików dla tabel i indeksów, dla których nie została określona grupa plików. W przypadku gdy nie została explicite wskazana, główna grupa plików staje się domyślną grupą plików.
SQL Server 2000 działa wydajnie bez podziału na grupy plików - w tym przypadku wszystkie pliki tworzą główną grupę plików.
Odtwarzanie danych można wykonywać zarówno na poziomie całej bazy danych, grupy plików jak i pojedynczego pliku.
Przykład
USE master
GO
-- Utwórz bazę danych z domyślną grupą plików danych i z plikiem dziennika.
-- Określ przyrost rozmiaru i maksymalny rozmiar dla głównego pliku danych.
CREATE DATABASE MyDB
ON PRIMARY
( NAME='MyDB_Primary',
FILE NAME='c:\Program Files\Microsoft SQL Server\MSSQL\data\MyDB_Prm.mdf',
SIZE=4,
MAXSIZE=10,
FILEGROWTH=1),
FILEGROUP MyDB_FG1
( NAME = 'MyDB_FG1_Dat1',
FILE NAME ='c:\Program Files\Microsoft SQL Server\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1MB,
MAXSIZE=10,
FILEGROWTH=1),
( NAME = 'MyDB_FG1_Dat2',
FILE NAME ='c:\Program Files\Microsoft SQL Server\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1MB,
MAXSIZE=10,
FILEGROWTH=1)
LOG ON
( NAME='MyDB_log',
FILE NAME ='c:\Program Files\Microsoft SQL Server\MSSQL\data\MyDB.ldf',
SIZE=1,
MAXSIZE=10,
FILEGROWTH=1)
GO
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT
GO
-- Utwórz tabelę w zdefiniowanej grupie plików.
USE MyDB
CREATE TABLE MyTable( cola int PRIMARY KEY,
colb char(8) )
ON MyDB_FG1
GO
Elementarną jednostką przechowywania danych przez SQL Server jest strona danych o rozmiarze 8192 bajtów (8 KB).
Nagłówek strony zawiera następujące informacje:
|
pageID - numer pliku i numer strony, nextPage - numer pliku i numer następnej strony w pliku, jeśli strona ta jest w łańcuchu stron (zgodnie z logicznym porządkiem), prevPage - numer pliku i numer poprzedniej strony w pliku, jeśli strona ta jest w łańcuchu stron (zgodnie z logicznym porządkiem), objID - identyfikator obiektu do którego należy dana strona, LSN - numer dziennika (ang. log sequence number) dotyczących ostatnich zmian na tej stronie, slotCnt - całkowita liczba wierszy zapisanych na tej stronie, level - poziom tej strony w indeksie (zawsze 0 dla liści). |
Maksymalny rozmiar pojedynczego wiersza danych wynosi 8060 bajtów. Wiersz danych musi być zapisany na jednej stronie (z wyjątkiem kolumn typu text lub image, które są zapisywane na osobnych stronach).
Tablica adresów wierszy jest ciągiem 2-bajtowych pozycji (określających adres wiersza na stronie nazywany jego offsetem). Kolejność w tablicy określa logiczny porządek wierszy na stronie. Pojedynczy wiersz jest jednoznacznie określony przez numer pliku, numer strony i adres (offset) na stronie.
Zwykle, dane typów LOB, czyli text, ntext i image, są zapisywane osobno - w samym wierszu jest zapisywany tylko 16-bajtowy wskaźnik do drzewa zbudowanego z wewnętrznych wskaźników, które wskazują na strony, w których są składowane fragmenty obiektu LOB. Gdy obiekty LOB są małe, używając opcji Text in row, można zapisywać je w wierszu razem z innymi danymi.
Strony danych są łączone po 8 kolejnych stron w jednostki organizacji nazywane ekstentami. Rozmiar ekstentu wynosi 8x8KB = 64KB. SQL Server posiada dwa rodzaje ekstentów:
Na samym początku po utworzeniu tabeli lub indeksu są alokowane strony pochodzące z ekstentów mieszanych. W chwili gdy tabela lub indeks osiągnie 8 stron, kolejne strony są alokowane już w ekstentach jednolitych. Przy tworzeniu indeksu dla istniejącej tabeli, jeśli od razu generowany indeks ma 8 stron lub więcej, wtedy od razu alokowane są dla niego ekstenty jednolite.
Ograniczenie wielkości danych w wierszu nie dotyczy danych typów text, ntext i image.
Dane tych typów mogą mieć wielkość 2 GB i w związku z tym mogą być zbyt duże do
przechowywania ich tak samo jak innych danych. Dane typu LOB mogą być przechowywane w innej grupie plików niż pozostałe dane tabeli
- tę grupę należy wskazać podczas tworzenia tabeli. Również takie oddzielenie danych LOB od pozostałych danych zwykle wpływa na wzrost wydajności
działania serwera baz danych.
Gdy w tabeli lub indeksie jest potrzebne więcej miejsca, system najpierw sprawdza czy ostatnio był alokowany ekstent mieszany i czy wielkość obiektu jest nie większa niż 8 stron, jeśli tak, alokujemy nową stronę w ekstencie mieszanym. Jeśli wielkość obiektu przekracza 8 stron lub mamy do czynienia już z ekstentami jednolitymi, alokowany jest kolejny ekstent jednolity.
SQL Server używa dwóch specjalnych typów stron (typu bitmap tj. wektorów bitów), na których jest zapisywane, które ekstenty w pliku zostały już zaalokowane i jakiego są typu: mieszanego czy jednolitego. Strony te są rozmieszczone wewnątrz pliku danych. Są to strony GAM tworzące Mapę globalną alokacji (ang. Global Allocation Map) oraz strony SGAM tworzące Mapę globalną współdzielonej alokacji (ang. Shared Global Allocation Map). Strony GAM i SGAM są przechowywane w każdym pliku danych i zawierają informacje o pliku, w którym się znajdują.
Strony GAM rejestrują, które ekstenty zostały zaalokowane. Każdy ekstent ma jeden bit go reprezentujący: 1 oznacza że ekstent jest wolny, 0 oznacza, że ekstent jest używany.
Na jednej stronie GAM jest do dyspozycji 8000 bajtów, tj. 64000 bitów - czyli opisuje ona 64000 ekstentów z danymi, co jest równe 4GB danych.
Strony SGAM rejestrują, które ekstenty są mieszane i jednocześnie zawierają jedną wolną stronę z danymi. Każdy ekstent ma jeden bit go reprezentujący: 1 oznacza, że ekstent jest mieszany i posiada wolne strony do alokacji, 0 w przeciwnym razie (albo jednolity ekstent albo mieszany bez wolnych stron).
Podobnie jak dla GAM, na jednej stronie SGAM jest do dyspozycji 8000 bajtów, tj. 64000 bitów - czyli opisuje ona 64000 ekstentów z danymi, co jest równe 4GB danych.
Tabela 15.1 reasumuje znaczenie bitów na stronach GAM i SGAM.
| Stopień zajętości ekstentu | Ustawienie bitu w GAM | Ustawienie bitu w SGAM |
| Cały wolny | 1 | 0 |
| Ekstent mieszany zajęty w całości lub ekstent jednolity | 0 | 0 |
| Ekstent mieszany z wolnymi stronami | 0 | 1 |
Tabela 15.1: Stopień zajętości ekstentu a ustawienie bitu w GAM i SGAM
Pierwsza strona GAM jest trzecią stroną w każdym pliku a pierwsza strona SGAM - czwartą w pliku.
Stąd wynika prosty algorytm zarządzania ekstentami. W celu zaalokowania jednolitego ekstentu, SQL Server przeszukuje strony GAM szukając pierwszego bitu 1 - ustawia go na 0. W celu zaalokowania mieszanego ekstentu, SQL Server przeszukuje strony GAM szukając pierwszego bitu 1 - ustawia go na 0 a następnie ustawia odpowiadający temu ekstentowi bit na stronach SGAM na 1. Przy zwalnianiu ekstentu SQL Server ustawia jego bit GAM na 1, jego bit SGAM na 0.
Strony PFS (ang. Page Free Space) rejestrują czy strony danych są elementem sterty (będzie o tym mowa za chwilę) lub kolumny typu LOB (ntext, text lub image) oraz także rejestrują ilość wolnego miejsca na stronie. Jedna strona PFS zawiera informacje o 8000 stronach. Na każdej stronie PFS jest następująca informacja o zapełnieniu każdej reprezentowanej strony:
SQL Server korzysta z tych informacji przy alokacji miejsca na wstawiane dane: czy należy alokować nową stronę, czy nowy ekstent, czy też dane zmieszczą się na jednej z używanych stron. W oparciu o te informacje serwer może sprawdzić dla już zaalokowanego ekstentu, które strony są w nim wolne oraz jeśli są używane, to ile jest w nich jeszcze wolnego miejsca.
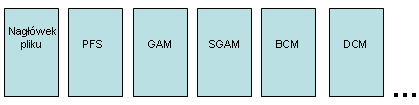
Strona PFS jest pierwszą stroną (z numerem 1) w pliku danych zaraz po nagłówku pliku. Kolejna strona to strona GAM (z numerem 2), po której następuje strona SGAM (z numerem 3).
Są jeszcze dwa rodzaje specjalnych stron w pliku danych.
Podsumowanie pomocniczych stron w pliku danych przedstawia rys. 15.2.
|
Rys. 15.2: Początek pliku - pomocnicze strony.
Tabela jest albo zapisywana w postaci niepogrupowanej (nazywanej stertą, ang. heap) albo w postaci pogrupowanej - w ramach jej indeksu pogrupowanego mającego postać B drzewa.
W Transact SQL rodzaj indeksu specyfikuje się za pomocą atrybutów CLUSTERED lub NONCLUSTERED - w więzach spójności związanych z daną tabelą lub przy tworzeniu jej indeksu. Natomiast, jeśli brak bezpośredniej specyfikacji, to:
Dla jednej tabeli może być zbudowany tylko jeden indeks pogrupowany.
Wartości klucza indeksu pogrupowanego są używane jako zakładki (ang. bookmarks) we wszystkich niepogrupowanych indeksach - dlatego lepiej najpierw utworzyć indeks pogrupowany, a dopiero potem wszystkie indeksy niepogrupowane.
Ponieważ wartości klucza indeksu pogrupowanego są używane jako zakładki, jak również klucz taki występuje często w warunkach wyszukiwania, więc wartości klucza pogrupowanego powinny mieć zwartą postać. Gdy nie istnieje naturalny zwarty klucz, należy użyć kluczy zastępczych stosując właściwość IDENTITY na kolumnie typu int.
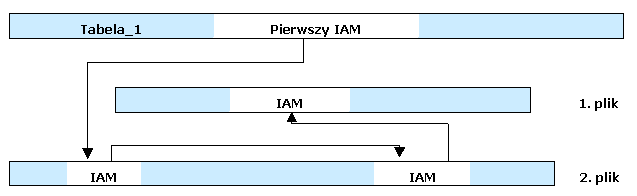
Mapa alokacji indeksów - strony IAM (ang. Index Allocation Map)
Mapa alokacji indeksów danego obiektu (tabeli lub indeksu) jest to zbiór stron przechowujących informacje, w których ekstentach znajdują się elementy danego obiektu. Dla każdego pliku w którym nastąpiła alokacja stron i ekstentów dla danego obiektu jest osobna mapa IAM. Strony IAM są alokowane gdy zachodzi tego potrzeba i są umieszczane wewnątrz pliku.
Na przykład, jeśli wzorzec bitów w pierwszym bajcie strony IAM jest 1100 0000, to oznacza, że pierwsze dwa ekstenty zawierają dane należące do danego obiektu, a ekstenty od 3 do 8 już nie.
Tabela systemowa Sysindexes zawiera informacje o wszystkich obiektach,
które zajmują miejsce na dysku. Każdy indeks, tabela i kolumna typu LOB posiadają wiersz
w Sysindexes ją
reprezentujący. Gdy tabela ma indeks pogrupowany, wiersz ją reprezentujący w
tabeli Sysindexes będzie miał wartość 1 w polu indid (identyfikator
indeksu). Gdy tabela nie ma indeksu pogrupowanego, wiersz ją
reprezentujący w tabeli Sysindexes będzie miał wartość 0 na pozycji indid. Oto znaczenie podstawowych czterech atrybutów tabeli
Sysindexes.
|
|
Rys. 15.3 Struktura stron IAM (wskaźnik Pierwszy IAM znajduje się w wierszu tabeli systemowej Sysindexes, który opisuje daną tabelę).
Strona IAM oprócz opisanego uprzednio wzorca bitów zawiera mały nagłówek oraz tablicę na osiem wskaźników do stron. Nagłówek zawiera adres pierwszego ekstentu w zakresie odwzorowywanym przez daną stronę IAM. Wskaźniki znajdujące się w tablicy kierują do stron danego obiektu zaalokowanych w ekstentach mieszanych.
W jednym pliku danych znajdują się ekstenty różnych obiektów, a więc także różne strony IAM należące do różnych obiektów.
Dane w tabelach nie posiadających indeksu pogrupowanego są przechowywane jako sterty danych. Oznacza to, że strony nie są połączone w żaden sposób ze sobą oraz, że są zapisane w pliku w przypadkowej kolejności. Mapa alokacji indeksów takiej tabeli dostarcza informacji, które ekstenty zawierają wiersze tej tabeli - umożliwiając przejście przez wszystkie jej wiersze.
Indeks pogrupowany (ang. clustered index)
Jeżeli tabela posiada indeks pogrupowany nazywamy ją pogrupowaną. Dane w takiej tabeli są przechowywane w postaci uporządkowanej, posortowane według wartości klucza indeksu pogrupowanego. Indeks ma strukturę B-drzewa a strony danych takiej tabeli (to jest liści B-drzewa) są połączone w listę dwukierunkową. Dla jednej tabeli może istnieć tylko jeden indeks pogrupowany, ponieważ dane w tabeli mogą być posortowane tylko w jeden sposób.
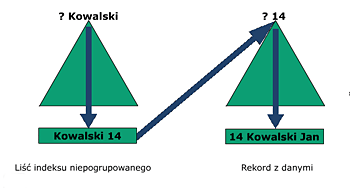
Indeks niepogrupowany (nonclustered index)
Indeks niepogrupowany może zostać założony na tabeli pogrupowanej jak i niepogrupowanej (stercie). Jest zorganizowany w postaci B-drzewa tak, jak indeks pogrupowany, jednak istnieją między nimi dwie podstawowe różnice:
|
Gdy trzeba wstawić nowy wiersz i nie ma miejsca na bieżącej stronie, serwer używa stron IAM i PFS w celu znalezienia strony z dostateczną ilością wolnego miejsca do pomieszczenia wiersza. Mianowicie, w oparciu o strony IAM, wyznaczane są ekstenty gdzie znajdują się elementy danego obiektu. Z kolei dla każdego takiego ekstentu w oparciu o strony PFS sprawdza się, czy na danej stronie jest dostatecznie dużo wolnego miejsca aby pomieścić wstawiany wiersz.
Każda strona IAM i PFS obejmuje swoim opisem dużą liczbę stron danych, zatem liczba stron IAM i PFS nie jest zbyt duża w bazie danych. Zwykle strony te są przechowywane w buforze w pamięci RAM a więc szybko można je przeszukać.
Gdy nie można szybko
znaleźć strony z dostateczną ilością wolnego miejsca, serwer alokuje nowy ekstent dla danych tego obiektu. Używany jest
opisany uprzednio algorytm proporcjonalnego
wypełniania istniejących plików z danymi w grupie plików.
15.5 Fizyczna architektura dziennika transakcji
Dziennik transakcji jest zapisywany w jednym lub więcej fizycznym pliku. Koncepcyjnie, dziennik jest sekwencyjnym ciągiem rekordów dziennika. Fizycznie, ciąg rekordów dziennika jest przechowywany w zbiorze fizycznych plików, które implementują dziennik transakcji. Każdy fizyczny plik dziennika jest dzielony na pewną liczbę wirtualnych plików dziennika. Rozmiar wirtualnych plików dziennika jest dobierany dynamicznie przez sam serwer. Serwer stara się ograniczyć do małej liczby wirtualnych plików. Rozmiar fizycznych plików dziennika powinien być dostatecznie duży (bliski przewidywanego końcowego rozmiaru), a także parametr wzrostu rozmiaru pliku powinien być względnie duży. Rysunek 15.5 wskazuje podstawowe punkty w dzienniku transakcji.
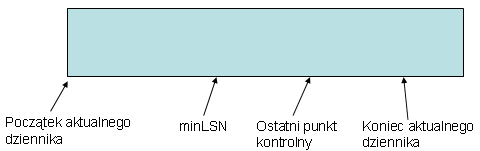
|
Rys. 15.5 Dziennik transakcji
Od punktu minLSN znajduje się część aktywna dziennika transakcji - tzn. część potrzebna do odtworzenia stanu bazy danych po awarii serwera. Część poprzedzająca minLSN jest potrzebna do odtworzenia bazy danych po awarii dysku i powinna być regularnie archiwizowana (backupowana). Po archiwizacji może zostać odcięta (ang. truncated) z dziennika logicznego transakcji udostępniając miejsce dla kolejnych zapisów dziennika.
Dziennik transakcji jest cykliczną strukturą: gdy koniec aktualnego dziennika
dojdzie do końca fizycznego pliku dziennika, nowe rekordy dziennika są
zapisywane na początku fizycznego pliku dziennika.
Podstawowymi dwoma częściami serwera baz danych SQL Server są:
Są one wyraźnie rozdzielone. Podstawową metodą komunikacji między nimi jest interfejs OLE DB. Część relacyjna obejmuje wszystkie składniki potrzebne do sparsowania i optymalizacji instrukcji SQL. Zarządza również sprowadzaniem zbiorów wierszy za pomocą OLE DB, które następnie przetwarza.
Część składowania danych obejmuje wszystkie składniki umożliwiające dostęp do
danych na dysku i ich modyfikację.
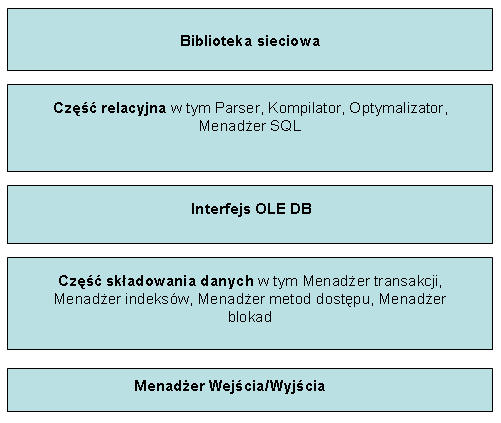
|
Rys. 15.6 Architektura serwera MS SQL Server
Poniżej znajduje się opis poszczególnych podstawowych składowych serwera.
ODS - Open Data Services
Przetwarza zlecenia klienta na odpowiednie wywołania funkcji realizowane przez parser poleceń.
Parser poleceń (command parser)
Sprawdza poprawność składniową i tłumaczy polecenia Transact SQL na wewnętrzną postać, mianowicie na drzewo zapytania. W przypadku nie rozpoznania składni, parser podnosi błąd identyfikując jego miejsce. Tylko parser ma dostęp do kodu źródłowego. Po optymalizacji - przy wykonywaniu polecenia - postać zapytania jest już inna i błędy jakie mogą powstać przy optymalizacji i wykonywaniu nie podają informacji o miejscu w instrukcji SQL, gdzie powstają.
Pobiera drzewo zapytania i przygotowuje jego wykonanie. Od razu obejmuje cały wsad poleceń. W rezultacie powstaje plan wykonania zapytania.
Optymalizator jest oparty na analizie kosztu realizacji zapytania (ang. cost-based). Bierze pod uwagę oszacowania wymagań na pamięć RAM, czas CPU i liczbę operacji We/Wy, jak również: typ zapytania, ilość danych w tabelach, dostępne indeksy dla każdej tabeli oraz szacunkowe rozkłady wartości w kolumnach tabel. W rezultacie optymalizator dobiera odpowiednią metodę dostępu do wierszy w tabeli, strategię złączania tabel, użycie dostępnych indeksów, kolejność dostępu do tabel i kolejność ich złączania. W efekcie wybiera plan wykonania o możliwie najmniejszym koszcie. Przy czym jednocześnie optymalizator zwraca uwagę na to, aby czas poświęcony na optymalizację nie był zbyt długi - odrzucając pewne alternatywy (ang. pruning), których analiza zajęła by zbyt dużo czasu.
Zarządza procedurami składowanymi i ich planami wykonania. Determinuje kiedy
procedura składowana powinna zostać rekompilowana z powodu zmian w obiektach
występujących w niej. Zarządza zapisywaniem planów wykonania procedur w pamięci cache tak aby inne procesy mogły z nich skorzystać. Dokonuje także
parametryzacji zapytań np. zastępuje zapytanie:
|
SELECT * FROM pubs.dbo.titles WHERE type = 'business' |
przez bardziej ogólne zapytanie zawierające parametr a nie konkretną wartość:
|
SELECT * FROM pubs.dbo.titles WHERE type = @param |
w celu wielokrotnego użycia tego samego planu wykonania.
Realizator zapytań
Jest częścią menadżera SQL. Realizuje wyznaczony plan wykonania zapytania w interakcji z częścią składowania danych serwera (sprowadzanie, modyfikowanie danych, zarządzanie transakcjami i blokadami).
W trakcie wykonywania kroków planu wykonania, gdy są potrzebne dane zostaje użyty interfejs OLE DB sprowadzania pojedynczych wierszy ze zdefiniowanego zbioru wierszy - który wcześniej zostaje otwarty przez część składowania danych. Część składowania danych przesyła dane z buforów danych do miejsc wskazanych przez część relacyjną serwera. Realizator zapytania przetwarza dostarczone dane do postaci zleconej przez użytkownika a następnie przekazuje je użytkownikowi.
Nie cała komunikacja odbywa się za pomocą zbiorów wierszy OLE DB. Na przykład, instrukcje DDL jak tworzenie tabeli, nie korzystają z tego interfejsu.
Zajmuje się:
Jego podstawowe moduły to:
Menadżer metod dostępu
ustawia odpowiedni sposób dostępu do danych, przygotowuje zbiory wierszy OLE DB do przekazania do części relacyjnej serwera. Zawiera serwisy otwierania tabeli, sprowadzania określonych danych i modyfikowania danych. Sprowadzanie danych jest realizowane przez inny moduł mianowicie przez menadżera buforów bazodanowych.
Menadżer stron
Menadżer stron alokuje i dealokuje wszystkie typy stron dyskowych, zestawiając je w ekstenty.
Menadżer transakcji
Zapewnia zachodzenie aksjomatów ACID. Współpracuje z menadżerem blokad, kiedy zwolnić blokadę w zależności od ustalonego dla transakcji poziomu izolacji.
Każda instancja serwera MS SQL Server dysponuje przestrzenią adresową składającą się z
dwóch części:
|
W puli pamięci są przechowywane struktury danych takie jak:
Przedstawiliśmy podstawowe informacje o organizacji MS SQL Server, które są
istotne dla osób, który chciałyby administrować SQL Serverem i rozumieć jak on
działa.
plik główny danych - stanowi punkt startowy bazy danych i zawiera informacje o innych plikach w bazie danych.
strona startowa bazy danych - zawiera podstawowe informacje o bazie danych. Występuje zarówno w pliku głównym danych jak i w pierwszym pliku dziennika.
strona danych - jest elementarną jednostką przechowywania danych przez SQL Server - ma rozmiar 8192 bajtów (8 KB).
ekstent (jednolity, mieszany) - połączenie 8 kolejnych stron. Jest albo jednolity - zajmowany przez jeden obiekt albo mieszany - współdzielony przez różne obiekty.
Mapa globalna alokacji (GAM) - rejestrują, które ekstenty zostały alokowane.
Mapa globalna współdzielonej alokacji (SGAM) - rejestrują, które ekstenty są mieszane i jednocześnie zawierają jedną wolną stronę z danymi.
strony PFS (Page Free Space) - rejestrują czy dana strona jest elementem sterty lub kolumny typu LOB: ntext, text lub image a także ilość wolnego miejsca na każdej stronie.
Mapa alokacji indeksów (IAM) - zbiór stron przechowujących informacje, w których ekstentach znajdują się elementy danego obiektu.
sterta - organizacja pliku danych polegająca na tym, że strony nie są łączone w żaden sposób ze sobą oraz, że są zapisane w pliku w przypadkowej kolejności.
indeks pogrupowany - ma strukturę B-drzewa a strony danych znajdujące się w liściach drzewa są połączone w listę dwukierunkową według porządku klucza indeksu.
indeks niepogrupowany - ma strukturę B-drzewa ale w liściach znajdują się nie same dane tylko wskaźniki do nich (dokładniej, albo identyfikatory wierszy RID w przypadku sterty albo wartości klucza indeksu pogrupowanego w przypadku tabeli posiadającej indeks pogrupowany).
część relacyjna serwera - obejmuje wszystkie składniki serwera potrzebne do sparsowania i optymalizacji zapytań (instrukcji SQL).
cześć składowania danych serwera - obejmuje wszystkie
składniki serwera umożliwiające dostęp do danych na dysku i ich modyfikację.
|
1. Zaznajom się z dokumentacją języka Transact SQL dostępną razem s MS SQL
Serverem.
Strona przygotowana przez Lecha Banachowskiego, PJWSTK, 08/09/06 .