W wykładzie 2 będziemy kontynuować omawianie podstaw, na których jest zbudowana wiedza o systemach zarządzania bazami danych.
Wykład 2 składa się z dwóch części. Pierwsza część jest poświęcona dyskusji wspólnego poziomu fizycznego dla znanych modeli baz danych. Model poziomu fizycznego bazy danych jest oparty na pojęciach pola, rekordu i pliku. Jego zastosowanie zostanie przedstawione w odniesieniu do następujących modeli baz danych: sieciowego, hierarchicznego i relacyjnego.
W drugiej części są zebrane wymagania stawiane systemom zarządzania bazami
danych. W szczególności, przedstawiony jest postulat realizacji trzech poziomów abstrakcji
i niezależności logicznej i fizycznej danych oraz postulaty Codda.
Zarówno relacyjne, obiektowo-relacyjne jak i obiektowe bazy danych mają wspólną podstawę swojego modelu fizycznego opartą na rekordach i plikach rekordów. Wzorują się w tym na swoich historycznych poprzednikach: modelu sieciowym i hierarchicznym. Celem pierwszej części wykładu 2 jest przedstawienie koncepcji rozwoju modelu fizycznego baz danych w perspektywie historycznej, to znaczy wychodząc od koncepcji zawartych w modelu sieciowym i hierarchicznym.
Rozważmy problem przechowywania danych na dysku na poziomie programu aplikacyjnego - na razie bez brania pod uwagę użycia systemu zarządzania bazą danych (SZBD).
| Modelem podstawowej jednostki danych w bazie danych jest rekord składający się z pól określonych typów danych. |
|
|
Rys. 2.1 Rekord jako kolekcja pól danych.
Jest to prawdą zarówno w odniesieniu do danych w językach programowania jak i w bazach danych - z perspektywy historycznej od samego początku ich powstania. Rekordy o polach ustalonych typów danych są przechowywane i przetwarzane razem jako pliki. Założenie jest takie, że rekordy są trzymane na dysku - jako podstawowym trwałym nośniku danych zdolnym pomieścić większe ilości danych wymagane w zastosowaniach. Podstawową operacją na pliku jest jego przeszukanie w celu wyznaczenia potrzebnego rekordu lub rekordów, ewentualnie w celu dokonania modyfikacji w tym wstawienia nowych rekordów bądź usunięcia lub archiwizacji już na razie niepotrzebnych. W tym celu, rekordy są sprowadzane do pamięci wewnętrznej RAM, wykonywane są na nich operacje i ewentualne wynikowe rekordy zostają zapisane z powrotem na dysku. Do wykonywania tych operacji były i są używane standardowe języki programowania takie jak, dawniej Cobol czy PL/I, teraz C, C++, C# czy Java.
Aby szybko wyszukać rekord mając wartości w jednym lub więcej wybranych polach w pliku jest potrzebny indeks. Indeks może być połączony z plikiem rekordów i wtedy szybkie wyszukiwanie jest możliwe tylko względem jednego kryterium, albo indeks stanowi niezależny plik połączony z plikiem rekordów ale wtedy są potrzebne fizyczne wskaźniki od rekordów indeksu do rekordów z danymi. Budową indeksów zajmuje się jeden z następnych wykładów.
Problem jest bardziej skomplikowany, ponieważ zwykle istnieje więcej niż jeden plik rekordów z danymi np. zarówno plik pracowników jak i plik departamentów. Między tymi dwoma plikami nie są utrzymywane połączenia w samym systemie plików a tylko w programie aplikacyjnym - można więc założyć, że departament o numerze 10 raz jest opisywany w pliku departamentów za pomocą osobnego rekordu, a innym razem występuje jako wartość pola w rekordzie pracownika, wskazując na określony związek pracownika z departamentem o podanym numerze. Weryfikacja poprawności zarówno wartości pól rekordów jak i ich wzajemnych powiązań spoczywa na programie aplikacyjnym. Do połączenia rekordów w różnych plikach można też użyć fizycznych wskaźników (adresów miejsc na dysku). Mamy w ten sposób do czynienia z prymitywną bazą danych definiowaną i zarządzaną przez program lub programy aplikacyjne.
| Ważnym ogólnym spostrzeżeniem jest to, że schematem fizycznym bazy danych - zarówno w przypadku użycia SZBD jak i nie, jest zawsze zbiór typów rekordów (którym odpowiadają pliki rekordów) oraz zbiór związków jednoznacznych (jeden do wiele) między nimi, nazywanych też powiązaniami. Rekord po stronie jeden związku nazywa się nadrzędny, a rekord po stronie wiele związku nazywa się podrzędny. Jednemu rekordowi nadrzędnemu odpowiada kolekcja rekordów podrzędnych pozostających z nim w rozważanym związku. |
Pierwszym krokiem w kierunku budowy systemu zarządzania bazą danych jest wydobycie z programów aplikacyjnych i umieszczenie w jednym miejscu modułu składowania (przechowywania) danych na dysku i sprawdzania ich poprawności. Wzajemne związki miedzy rekordami są reprezentowane przez wskazane wspólne zbiory wartości (tak jak w modelu relacyjnym) bądź przez wskaźniki między rekordami (tak jak w modelu sieciowym i obiektowym oraz częściowo również hierarchicznym) - i spójność powiązań miedzy rekordami jest utrzymywana "centralnie" przez system.
W ten sposób w każdym z wymienionych modeli można łatwo zrealizować nawigację od rekordu podrzędnego do rekordu nadrzędnego - wskazywanego przez wskaźnik (lub wartość klucza obcego) znajdujący się w tym pierwszym rekordzie. W przypadku realizacji wskaźnika przez wartość - znalezienie tego rekordu może się odbywać albo przez sekwencyjne przejście pliku albo przez przejście przez indeks. Jeśli jest fizyczny wskaźnik - przejście jest bezpośrednie.
Bardziej skomplikowany przypadek ma miejsce gdy chcemy od rekordu nadrzędnego, przejść do pozostających z nim w związku zbioru rekordów podrzędnych. W przypadku realizacji powiązań przez wartość, albo sekwencyjnie przechodzimy rekordy w pliku w poszukiwaniu podanej wartości albo znowu przechodzimy indeks. W przypadku użycia fizycznych wskaźników, podobnie sekwencyjnie przechodzimy rekordy w pliku w poszukiwaniu wskaźnika do rekordu nadrzędnego (jedyną operacją na wskaźnikach jest operacja porównywania ich - w szczególności ze wskaźnikiem pustym). Wobec braku indeksów na wskaźnikach, aby przyśpieszyć operację wyszukiwania rekordów podrzędnych utrzymuje się je albo na wspólnej liście albo obok siebie na dysku. Metody te są wykorzystywane odpowiednio w bazie sieciowej i hierarchicznej.
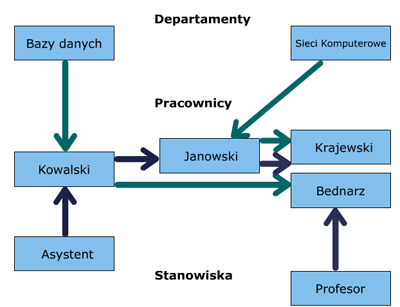
W modelu sieciowej bazy danych powiązanie reprezentujemy za pomocą listy cyklicznej rekordów podrzędnych, które mają ten sam rekord nadrzędny. Jeden rekord może się w ten sposób znajdować na wielu listach, gdzie każda odpowiada dokładnie jednemu powiązaniu.
|
Na przykład, rekord pracownika znajdzie się na liście pracowników pracujących w tym samym dziale co dany pracownik a także rekord pracownika znajdzie się na drugiej liście pracowników mających to samo stanowisko co dany pracownik. Przechodzenie po jednej liście rekordów nie jest zbyt efektywne, oznacza bowiem wczytywanie kolejno do pamięci RAM leżących niekoniecznie obok siebie bloków dyskowych.
W modelu hierarchicznym mamy do czynienia z próbą ograniczenia nieefektywnego chodzenia po listach. Dzieli się mianowicie sieć na zbiór struktur hierarchicznych, tworząc ewentualnie dodatkowe wirtualne typy dublujące rekordy występujące w różnych hierarchiach. Zestawia się jeden rodzaj list reprezentujących jedno powiązanie w hierarchię i zamiast zapisywać elementy tych list w osobnych blokach zapisuje się je w tych samych lub sąsiednich blokach na dysku. Przejście takiej hierarchii jest szybkie. Natomiast wszystkie powiązania inne niż powiązania definiujące hierarchie trzeba reprezentować przez zdublowane "wirtualne" rekordy i wskaźniki prowadzące od nich do faktycznych rekordów. Zatem w tym samym bloku dyskowym obok każdego departamentu, moglibyśmy zapisać rekordy pracowników pracujących w danym departamencie, natomiast, w tym samym bloku dyskowym obok każdego stanowiska, moglibyśmy zapisać wirtualne rekordy pracowników zawierających wskaźniki do miejsc gdzie są prawdziwe rekordy - co w efekcie oznacza konieczność sprowadzania, dla każdego wirtualnego rekordu pracownika, bloku dyskowego zawierającego prawdziwy rekord pracownika.
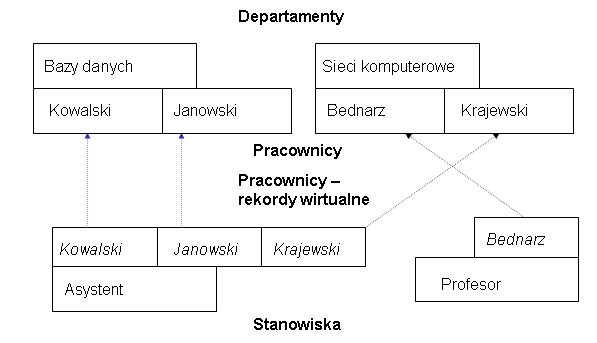
Rys. 2.3. Reprezentacja danych w modelu hierarchicznym. W naszym przykładzie mamy dwie hierarchie plus rekordy wirtualne (nazwiska zapisane kursywą) i ich powiązania z rekordami faktycznymi.
W sieciowych i hierarchicznych bazach danych zapytania były realizowane przez programy aplikacyjne (napisane w takich językach jak COBOL czy PL/I) tylko z niewielkim wsparciem systemu zarządzania bazą danych (odpowiedzialnego za składowanie i sprawdzanie poprawności danych).
Indeksy w modelach sieciowym i hierarchicznym są zakładane na zbiorach rekordów w odniesieniu do pól z danymi - ale nie pól wskaźnikowych.
Na rysunku 2.4 jest pokazana reprezentacja relacyjna. Mamy tu do czynienia z trzema niezależnymi plikami powiązanymi przez wartości kluczy obcych i głównych. Indeksy są zakładane zarówno na polach z danymi, jak i na polach kluczy obcych reprezentujących wskaźniki między rekordami.

Rys. 2.4 Relacyjna reprezentacja danych z kluczami obcymi i głównymi.
W relacyjnej bazie danych zapytania do bazy danych są realizowane przez sam
system zarządzania bazą danych i tylko wyniki są przekazywane do programu
aplikacyjnego.
Następujące cechy wskazuje się jako zalety systemów SZBD, które przemawiają za korzystaniem z nich przez aplikacje.
Niezależność danych – Programy aplikacyjne są niezależne od szczegółów reprezentacji danych i ich przechowywania na dysku. SZBD dostarcza abstrakcyjnej reprezentacji dla danych używanej w kodzie aplikacji bez odwoływania się do szczegółów technicznych reprezentacji na dysku.
Szybki dostęp do danych – SZBD używa wielu skomplikowanych metod przechowywania i wyszukiwania danych. Jest to szczególnie istotna cecha gdy jest bardzo dużo danych i gdy są one przechowywane w urządzeniach pamięci zewnętrznej.
Spójność i ochrona danych – Dostęp do danych odbywa się wyłącznie za pomocą SZBD. Zatem, poprzez SZBD można zdefiniować i wprowadzać w życie przestrzeganie jednolitych więzów spójności niezależnie od aplikacji przetwarzającej dane a także jednolity system kontroli dostępu do danych określający, jakie dane są dostępne dla jakich użytkowników.
Administracja danymi – Dane używane przez różnych użytkowników są centralnie administrowane. Można dopasować reprezentację danych tak aby zminimalizować redundancję ich zapisu (w szczególności aby te same dane nie były niepotrzebnie przechowywane w różnych miejscach przez różnych użytkowników). Można dopasować struktury przechowywania danych na dysku tak aby możliwie przyśpieszyć wyszukiwanie danych.
Współbieżny dostęp i odtwarzanie po awarii – SZBD umożliwia i kontroluje współbieżny dostęp do danych przez wielu użytkowników tak, że każdy z nich ma wrażenie, że tylko on używa tych danych w danej chwili. SZBD zabezpiecza dane przed utratą w sytuacji zaistnienia różnego rodzaju awarii.
Zmniejszony czas tworzenia aplikacji – SZBD dostarcza wspólnych funkcji dla aplikacji korzystających z danych w bazie danych; dostarcza interfejsu wysokiego poziomu do danych – prowadzi to do szybkiego tworzenia aplikacji baz danych, które też są bardziej odporne na sytuacje wyjątkowe.
Każdy system zarządzania bazą danych udostępnia trzy poziomy dostępu do bazy danych.
Trzy poziomy schematu bazy danych w SZBD
Uwaga: W tym podziale nie są uwzględnione etapy i produkty projektowania, które mają miejsce zanim powstanie schemat bazy danych (zbieranie wymagań i tworzenie modelu danych niezależnego od rodzaju bazy danych, która zostanie użyta, o czym była mowa w wykładzie 1).
Każda baza danych posiada powyższe trzy poziomy. SZBD udostępnia developerom, administratorom i końcowym użytkownikom odpowiednie narzędzia i usługi na każdym z tych trzech poziomów.
Każda baza danych ma dokładnie jeden poziom logiczny i jeden poziom fizyczny. Natomiast może mieć wiele poziomów zewnętrznych.
Rozważmy przykład.
|
Poziom logiczny - tabele: Studenci(sid: string, nazwisko: string, login: string, wiek: integer, gpa:real) Kursy(kid: string, nazwa:string, punkty:integer) Zapisany(sid:string, kid:string, stopień:string) Poziom zewnętrzny nr. 1 perspektywa: Course_info(kid:string, nazwa:string, punkty:integer, liczba_studentów:integer) Poziom zewnętrzny nr. 2 perspektywa: Student_info(sid:string, nazwisko:string, login: string, wiek: integer, gpa:real, liczba_kursów:integer) |
Z poziomami abstrakcji schematu bazy danych jest związana niezależność posługiwania się danymi na wybranym poziomie, którą to cechę implementują systemy SZBD.
Użycie przez użytkowników obiektów bazy danych na poziomie logicznym i zewnętrznym jest chronione od zmian zachodzących na niższych poziomach na mocy następujących własności niezależności:
Postulaty Codda
Specjalne postulaty dotyczące funkcjonowania systemu zarządzania bazą danych
sformułował Codd w 1985 roku w odniesieniu do relacyjnych baz danych. Postulaty
te można przeformułowywać dla każdego innego modelu baz danych formułując je w
kategoriach ich specyficznego modelu logicznego.
Postulaty Codda dla implementacji relacyjnych baz danych (1985)
|
W pierwszej części tego wykładu został przedstawiony wspólny poziom fizyczny dla znanych modeli baz danych. Model poziomu fizycznego bazy danych jest oparty na pojęciach pola, rekordu i pliku. Jego zastosowanie zostało przedstawione w odniesieniu do następujących modeli baz danych: sieciowego, hierarchicznego i relacyjnego.
W drugiej części zostały zebrane wymagania stawiane systemom zarządzania
bazami danych, w tym postulat realizacji trzech poziomów abstrakcji,
niezależności logicznej i fizycznej danych oraz postulaty Codda.
model bazy danych - ogólny sposób logicznej reprezentacji danych w bazie danych. Dane są fizycznie zapisane w rekordach w plikach, natomiast aplikacja widzi je jako tabele powiązane związkami klucz obcy - klucz główny (w modelu relacyjnym), jako hierarchie plików rekordów (w modelu hierarchicznym), jako sieci plików rekordów (w modelu sieciowym), jako zbiory obiektów powiązanych przez wskaźniki (w modelu obiektowym).
poziomy abstrakcji - baza danych jest udostępniana na trzech różnych poziomach abstrakcji: logicznym (operacje na tabelach), fizycznym (operacje na plikach rekordów), zewnętrznym (operacje na perspektywach użytkowników). Na każdym z poziomów zapewniona jest pełna obsługa operacji, bez przechodzenia na inny poziom.
niezależność danych - zmiany zachodzące na niższym poziomie abstrakcji nie wpływają na operacje na wyższym poziomie abstrakcji. Wiersze w tabeli mogą być zapisane na dysku za pomocą różnych struktur danych - nie zmienia to operacji na tabeli na poziomie logicznym. Tabele mogą zmieniać swoje schematy - natomiast z punktu widzenia użytkowników ich perspektywa na dane w bazie danych nie ulega zmianie.
Postulaty Codda - podstawowe wymagania stawiane
implementacjom systemu zarządzania relacyjną bazą danych.
|
1. Porównaj schematy bazy danych zamówień (obejmującej klientów, zamówienia, pozycje zamówień i towary) w modelu sieciowym, hierarchicznym i relacyjnym.
2. Jakie poziomy użytkowe (zewnętrzne) można wyróżnić w bazie danych zamówień.
Strona przygotowana przez Lecha Banachowskiego, PJWSTK, 08/05/06 .