Zastosowania analityczne. Budowa hurtowni danych.
Aplikacje operacyjne i aplikacje analityczne
Celem IT jest wspomaganie pracowników w ich codziennej pracy oraz pomaganie osobom podejmującym strategiczne decyzje (np. kierownikom, analitykom) w podejmowaniu szybszych i skuteczniejszych działań. I tak jak do realizacji pierwszego z tych celów w zupełności wystarczą systemy przetwarzania transakcyjnego, które, gromadząc informacje o bieżących działaniach firmy, znakomicie usprawniają codzienne funkcjonowanie przedsiębiorstwa, tak do realizacji drugiego z wymienionych zadań potrzebne są systemy, których główną siłą jest informacja historyczna – systemy wspomagania decyzji.
Stąd też w przedsiębiorstwach można znaleźć dwa typy aplikacji: aplikacje operacyjne usprawniające działania bieżące oraz aplikacje analityczne, mające za zadanie wspomóc proces podejmowania decyzji.
Po co hurtownia danych?
Współczesne firmy mają mnóstwo danych, gdziekolwiek by nie spojrzeć można znaleźć dane w różnej postaci. Jednakże współczesne firmy mają też jeden wspólny,
ale za to kluczowy problem:
“Dostępne są dane, nie zaś informacja - w każdym razie nie ta potrzebna informacja i nie wtedy, gdy chcemy ją uzyskać.”
Lekarstwem na tę bolączkę jest właśnie
hurtownia danych, pozwalająca na:Aspekty biznesowe
Stworzenie hurtowni danych jest przedsięwzięciem po pierwsze niełatwym, po drugie wysoce kosztownym. Toteż rozpoczynając je powinniśmy dokładnie określić cel, do którego dążymy, aby na koniec móc stwierdzić, czy cel ten osiągnęliśmy. Warto pamiętać, że hurtownię danych budujemy dla firmy i że sukces odnosimy wówczas, gdy firma osiągnie cel, który miała na uwadze, decydując się na budowę hurt
owni danych. Toteż jako projektanci hurtowni musimy dążyć do tego, aby kierownictwo firmy owe cele biznesowe sformułowało. Właściwie sformułowany cel biznesowy powinien być: mierzalny, ograniczony czasowo oraz zorientowany na klienta. Przykładowym celem biznesowym może być pozyskanie w bieżącym roku o 20% więcej dobrych klientów niż w zeszłym roku bądź też zwiększenie w bieżącym roku sprzedaży o 30% w stosunku do sprzedaży z zeszłego roku.CRM (Customer Relationship Management)
Hurtownia danych w znacznym stopniu ułatwia tzw. zarządzanie kontaktami z klientami (CMR, ang. Customer Relationship Management)
CRM jest strategią mającą na celu zoptymalizowanie całościowej wartości klientów
Rozumiemy przez to przede wszystkim lepsze poznanie klientów oraz odpowiednie kontaktowanie się z klientami.
Hurtownia danych w znacznym stopniu przyczynia się do usprawnienia tego, co składa się na CRM, czyli:
Systemy wspomagania decyzji - DSS
Systemy wspomagania decyzji ( DSS, ang. Decision Support Systems ) można scharakteryzować następująco:
Informacja strategiczna a informacja operacyjna
Informacja strategiczna w zasadniczy sposób różni się od informacji operacyjnej.
Pytania operacyjne dotyczą tu i teraz:
Pytania strategiczne poza tu i teraz znacznie wykraczają:
Te różnice w znacznym stopniu przyczyniły się do rozdzielenia tych dwóch typów info
rmacji.Dwa modele przetwarzania danych
Między tymi dwoma modelami przetwarzania występuje sporo różnic, począwszy od grup użytkowników korzystających z tych systemów, poprzez funkcjonalność, projekt bazy danych, rodzaj trzymanych danych, użycie, dostęp, wykonywane zadania, liczbę rekordów zwracanych w zapytaniach, liczbę korzystających z systemu użytkowników, a skończywszy na rozmiarze docelowej bazy dany
ch.|
OLTP |
OLAP |
|
|
użytkownicy |
urzędnicy, personel IT |
kierownicy, analitycy |
|
funkcja |
codzienna działalność firmy |
wspomaganie decyzji |
|
projekt BD |
zorientowany na działanie |
zorientowany na temat |
|
dane |
bieżące, aktualne, szczegółowe, znormalizowane |
historyczne, zagregowane, wielowymiarowe, zintegrowane, skonsolidowane |
|
użycie |
powtarzalne |
ad-hoc |
|
dostęp |
odczyt/zapis, indeks/hash na PK |
wielokrotne skanowanie |
|
zadania |
krótkie, proste transakcje |
złożone zapytania |
|
liczba rekordów zwracanych w zapytaniu |
dziesiątki |
miliony |
|
liczba użytkowników |
tysiące |
setki |
|
rozmiar BD |
100MB-GB |
100GB-TB |
Hurtownia danych - definicja
W 1992 roku Bill Inmon zdefiniował hurtownię danych jako bazę danych, mającą służyć wspomaganiu procesu podejmowania decyzji, która jest:
Zorientowanie na temat oznacza, że zbierane dane dotyczą tematu (np. sprzedaży) , a nie działań (np. zbierania zamówień).
Nieulotność oznacza, że dane, raz umieszczone w hurtowni, zazwyczaj pozostają nie zmienione. Każdy użytkownik bazy danych ma pewność, że zapytanie zawsze zwróci taki sam wynik, niezależnie od tego jak często jest wykonywane.
Zintegrowanie oznacza, że dane są jednolite, czyli na przykład daty przechowywane są zawsze w tym samym formacie, znaki kodowane są w ten sam sposób, pola zawierające tę samą informację mają tę samą postać
Zróżnicowanie czasowe oznacza, że gromadzone są dane historyczne. Prawie wszystkie zapytania kierowane do hurtowni danych wymagają prześledzenia jakiegoś odcinka czasu.
Dlaczego hurtownię danych oddziela się zazwyczaj od innych aplikacji
Hurtownię danych powinno oddzielać się od innych aplikacji z wielu powodów. Po pierwsze hurtownia danych jest zorientowana na temat, podczas gdy operacyjne bazy danych zorientowane są na działanie. I tak jak w hurtowni koncentrujemy się wokół sprzedaży (temat), tak w operacyjnych bazach danych koncentrujemy się wokół składania i realizacji zamówień (działanie). Po drugie, podczas gdy dane w hurtowni danych muszą być nieulotne, w operacyjnej bazie danych podlegają one nieustannym zmianom. Po trzecie istotą i siłą hurtowni danych jest informacja historyczna (zróżnicowanie czasowe), natomiast w operacyjnej bazie danych informacje historyczne stanowią, często niepotrzebne, obciążenie wydajnościowe, a nawet zdarza się, że bywają mylące (na przykład poprzedni, nieaktualny już adres klienta), toteż bardzo często są z bazy usuwane. Po czwarte schemat operacyjnej bazy danych jest z reguły wysoce skomplikowany. Zdarza się, że od jednej do drugiej tabeli prowadzi wiele ścieżek łączących. W hurtowni danych stawia się na prostotę schematu, dopuszczając jedną ścieżkę złączeń.
Poza omówionymi powyżej przyczynami istnieją jeszcze względy wydajnościowe oraz funkcjonalne. Do względów wydajnościowych należy choćby konieczność specjalnej dla zastosowań OLAP organizacji danych, metod dostępu oraz metod implementacyjnych. Ponadto złożone zapytania OLAP bardzo obniżałyby wydajność działań operacyjnych, a kontrola współbieżności i tryb odzyskiwania charakterystyczne dla OLTP nie współgrałyby z analizą OLAP.
Co do względów funkcjonalnych to wspomniana już konieczność gromadzenia danych historycznych, jak również konieczność konsolidacji danych pochodzących z różnorodnych źródeł oraz konieczność zintegrowania formatów i semantyki także przemawiają za oddzieleniem hurtowni od innych systemów.
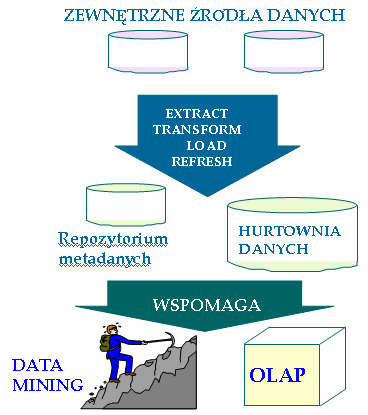
Architektura hurtowni danych
Na poniższym rysunku w sposób schematyczny została przedstawiona architektura hurtowni danych. Oczywiście konkretne rozwiązania mogą się różnić od poniższego, ale ten schemat ma za zadanie przybliżyć ogólną ideę. Jak widzimy, do hurtowni danych dane pobierane są z zewnętrznych źródeł danych. Zanim dane znajdą się w hurtowni muszą
zostać pobrane (ang. extract – ekstrakcja), poddane transformacji (ang. transform – transformacja, przekształcanie), czyli zwalidowane (ang. validation - walidacja), zintegrowane (ang. integration - integracja) i odwzorowane (ang. mapping – mapowanie, odwzorowanie), a w końcu załadowane do hurtowni (ang. load - ładowanie). Oczywiście poza ładowaniem początkowym, wykonywanym jednokrotnie na początku, dokonywane są ładowania przyrostowe w celu odświeżania hurtowni (ang. refresh - odświeżanie). Do ekstrakcji, transformacji i ładowania służy narzędzie ETL, które może być częścią hurtowni bądź też narzędziem zewnętrznym. Należy zdawać sobie sprawę z tego, że dane do hurtowni mogą być pobierane z wielu różnych źródeł (aplikacji transakcyjnych, plików itp.), przy czym nie ze wszystkich zastanych w firmie źródeł pobrać dane jest łatwo. To właśnie różnorodność źródeł, trudność dostępu do niektórych z nich, duża dezintegracja, czynią budowanie hurtowni danych zadaniem nietrywialnym i kosztownym.Hurtowni danych towarzyszy mocno rozbudowane repozytorium metadanych, w którym znajdują się wszystkie informacje z poziomu pojęciowego (opis zawartości, opis procesu integracji pojęciowej itp.), logicznego (nazwy tabel i kolumn, typy danych, rodzaje związków między tabelami, definicje perspektyw zmaterializowanych, definicje więzów integralności, definicje kostek danych i hierarchii wymiarów, opis logiczny procesu ładowania danych itp.) i fizycznego (definicja fizycznego rozmieszczenia danych i ich przepływu, informacje o lokalizacji fragmentów danych składających się na logiczne źródło danych, definicje wyzwalaczy, definicje procedur przeprowadzających ładowanie, czyszczenie i transformację itp.), statystyki danych i użycia oraz informacje administracyjne (zasady dostępu do danych, definicje użytkowników i ich grup, terminy wykonywania cyklicznych czynności w hurtowni danych, jak aktualizacja ze źródeł, czy backup itp.)
Z hurtowni danych natomiast korzystają aplikacje typu OLAP i aplikacje eksploracji danych, które w znacznym stopniu ułatwiają podejmowania strategicznych decyzji w firmie.
Projektowanie hurtowni danych
Projekt hurtowni danych w zasadniczym stopniu różni się od projektu operacyjnej bazy danych. Diagram związków encji, na którym opiera się znakomita większość aplikacji transakcyjnych jest normalizowany w celu uniknięcia anomalii podczas wstawiania danych, ich usuwania i aktualizacji. W hurtowni danych naszym nadrzędnym celem nie jest unikanie tych anomalii (choćby dlatego, że dane są do niej ładowane, nie zaś wst
awiane przez wielu użytkowników, a i to znacznie rzadziej), ale wydajne i skuteczne wykonywanie bardzo skomplikowanych, i zwracających nawet miliony rekordów, zapytań.Można by rzec, że podstawowy schemat, na którym opiera się hurtownia danych, tak zwany schemat gwiazdy, jest próbą przedstawienia czwartego, piątego itd. wymiaru podczas dokonywania analizy wymiarowej. Hurtownię danych budujemy bowiem dla firmy, a jak się okazuje, tym czego potrzebuje firma jest właśnie możliwość dokonywania analiz wymiarowy
ch. Weźmy bowiem standardowe zadanie stawiane w firmie:Przedstaw łączną sprzedaż każdego z produktów na przestrzeni czasu
(np. dla każdego miesiąca pierwszego kwartału roku 2005)Aby zobrazować wykonanie tego zadania wystarczy dwuwymiarowy układ z osią
produktu i osią czasu: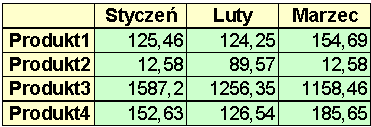
Jeszcze częściej stawia się takie zadanie:
Przedstaw łączną sprzedaż każdego z produktów dla każdego z klientów na przestrzeni czasu
(np. dla każdego miesiąca pierwszego kwartału roku 2005)Dla zobrazowania wykonania tego zadania wystarczy trzywymiarowy układ z osią produktu, osią klienta i osią czasu:
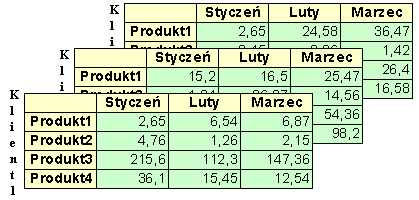
Stąd już tylko krok do następującego zadania:
Przedstaw łączną sprzedaż każdego z produktów dla każdego z klientów w każdym z obszarów sprzedaży na przestrzeni czasu
(np. dla każdego miesiąca pierwszego kwartału roku 2005)Dla zobrazowania wykonania tego zadania “wystarczy” czterowymiarowy układ z osią
produktu, osią klienta, osią obszaru sprzedaży i osią czasuNiestety tu kończą się możliwości percepcji przeciętnego człowieka. Czwarty wymiar tylko nieliczni potrafią sobie wyobrazić. Trzeba było jakoś ten czwarty wymiar zobrazować. I tak stworzono schemat, który nazwano właśnie schematem gwiazdy z uwagi na charakterystyczny gwieździsty kształt.
Schemat gwiazdy
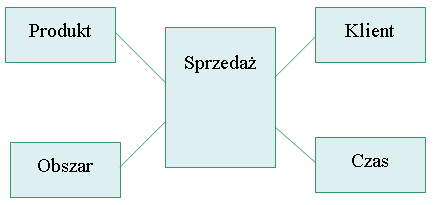
Przed omówieniem tego schematu spójrzmy jeszcze na pełny schemat z załączonymi atrybutami:
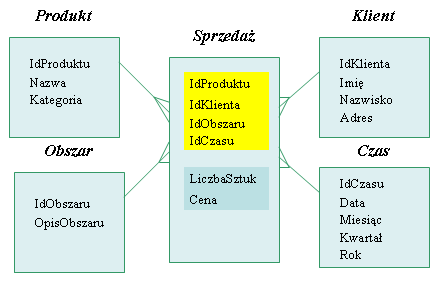
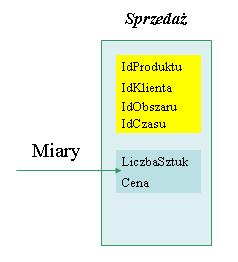
Centrum schematu gwiazdy tworzy tak zwana tabela faktów, czyli tabela gromadząca informacje o temacie, wokół którego skupia się hurtownia. Faktów tych będzie dotyczyła większość zapytań zadawanych hurtowni danych. Tabela faktów jest znormalizowana, jej klucz główny (obszar zaznaczony kolorem żółtym) stanowią klucze obce pochodzące z tabel: Produkt, Obszar, Klient i Czas, zaś kolumny niekluczowe, czyli tak zwane miary muszą być sumowalne. Patrząc od strony biznesowej, w tabeli faktów gromadzone są informacje dotyczące tego, co firmie przynosi zysk. Często zatem jest to właśnie sprzedaż, rozmowy telefoniczne, transakcje bankowe itp. Miary to w pewnym sensie wyznacznik tego zysku, czyli liczba sprzedanych sztuk, cena, liczba wydzwonionych sekund/minut, kwota operacji bankowej itp.
Tabelę faktów otaczają
tabele wymiarów, zawierające dane o wymiarach analizy, czyli o tym według czego będziemy analizowali dane z tabeli faktów, w naszym przypadku sprzedaż. Cechą charakterystyczną tabel wymiarów jest brak normalizacji. Na przykład w tabeli produkt znajdują się wszystkie potrzebne z punktu widzenia przyszłej analizy informacje o produkcie, łącznie z informacjami o kategorii produktu. Szczególnym wymiarem analizy jest wymiar Czasu. Jego wyjątkowość wynika z tego, że jest to wymiar występujący zawsze w hurtowni (czasem niejawnie), ponieważ każde zapytanie zadawane do hurtowni w jakiś sposób wiąże się z czasem. Niektóre systemy umożliwiają dodanie wymiaru czasu do kostki, nawet jeśli wymiar ten nie został jawnie zaprojektowany.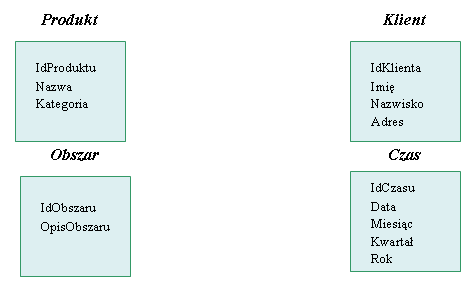
Wymiary analizy często mają strukturę hierarchiczną, np.
W schemacie gwiazdy każda taka pojedyncza hierarchia zawiera się w jednej tabeli i tabela ta jest bezpośrednio przyłączana do tabeli faktów. Jest jednak możliwość (choć nie obsługiwana przez wszystkie serwery) częściowego znormalizowania wymiarów poprzez tworzenie hierarchii w wielu tabelach.
Takim krokiem w kierunku normalizacji jest alternatywny schemat do hurtowni - schemat płatka śniegu.Schemat płatka śniegu
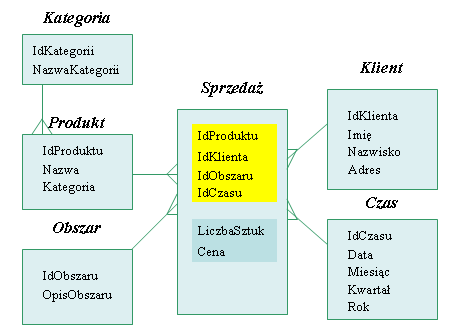
Jak widzimy kategoria produktu (i wszystkie dotyczące jej atrybuty) stanowi tu oddzielną tabelę.
Mimo licznych początkowych dyskusji, wątpliwości i niepokojów model wymiarowy zyskał w przypadku hurtowni danych przewagę nad modelem w 3NF (trzeciej postaci normalnej) stosowanym przy projektowaniu systemów transakcyjnych. Złożyło się na to wiele przyczyn:
Zdecydowanie mniejsze porozumienie osiągnięto w sprawie sporu, który z wyżej podanych schematów stosować – gwiazdę czy płatek śniegu. Zwolennicy czystej gwiazdy, np. Kimball (1996) nie polecają używania płatków śniegu, ponieważ odbija się to na wydajności, no a przede wszystkim użytkownicy mogą się przestraszyć złożonej hierarchii. Z kolei zwolennicy płatka śniegu uważają, że większość ludzi biznesu jest świadoma istnienia hierarchii i czuje się bez nich nieswojo. Przy okazji należy podkreślić, że nie wszystkie narzędzia umożliwiają tworzenie kostek OLAP, jeśli projekt hurtowni nie jest w postaci schematu gwiazdy. Do takich narzędzi należy na przykład OWB (Oracle Warehouse Builder).
Schemat konstelacyjny
Jeśli mamy więcej niż jeden temat, wokół którego koncentruje się nasze przedsiębiorstwo, możemy stworzyć tak zwany schemat konstelacyjny, w którym niektóre wymiary są współdzielone.
Wykład przygotowała Agnieszka Chądzyńska, na podstawie książek:
Zadanie domowe
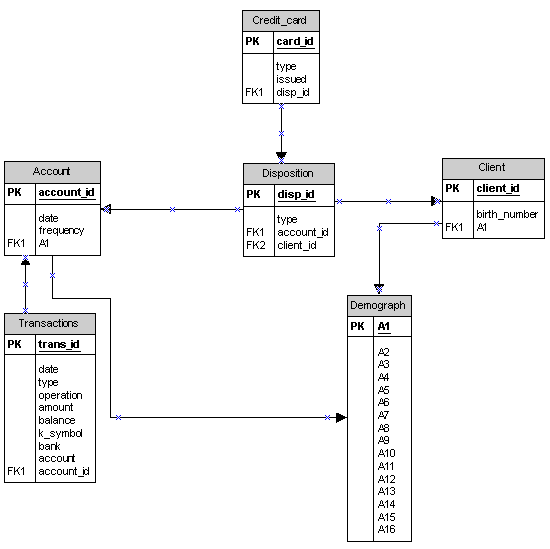
Mając dany schemat źródłowej bazy danych wraz z opisem
oraz wymagania stawiane przed przyszłą hurtownią danych, zaproponuj stosowny schemat gwiazdy, na którym mogłaby opierać się ta hurtownia.Schemat relacyjny bazy danych dotyczącej transakcji bankowych:
Opis:
|
Relacja Account: |
|
|
account_id |
id rachunku |
|
district_id |
lokalizacja od działu |
|
date |
data założenia rachunku (YYMMDD) |
|
frequency |
częstość przysyłania wyciągów z konta (miesięcznie, tygodniowo, po dokonaniu operacji) |
|
Relacja Client: |
|
|
client_id |
id klienta |
|
district_id |
miejsce zamieszkania |
|
birth_number |
data urodzenia + płeć (YYMMDD – jeśli kobieta, dzień urodzenia + 50) |
|
Relacja Demograph: |
|
|
A1 = district_id |
id regionu |
|
A2 = district_name |
nazwa regionu |
|
A3 = region |
region |
|
A4 = no_of_habitations |
liczba domostw |
|
A5 = no_of_municipalities_with_inhabitants_499 |
liczba miejscowości z odpowiednią liczbą mieszkańców |
|
A6 = no_of_municipalities_with_inhabitants_500_1999 |
|
|
A7 = no_of_municipalities_with_inhabitants_2000_9999 |
|
|
A8 = no_of_municipalities_with_inhabitants_10000 |
|
|
A9 = no_of_cities |
liczba miast |
|
A10 = ratio_of_urban_inhabitants |
procent mieszkańców miast |
|
A11 = average_salary |
średnia pensja |
|
A12 = unemloyment_rate_95 |
wskaźnik bezrobocia w 95 |
|
A13 = unemloyment_rate_96 |
wskaźnik bezrobocia w 96 |
|
A14 = no_of_enterpreneurs_per_1000_inhabitants |
liczba przedsiębiorców na 1000 mieszkańców |
|
A15 = no_of_commited_crimes_95 |
liczba popełnionych przestępstw w 95 roku |
|
A15 = no_of_commited_crimes_96 |
liczba popełnionych przestępstw w 96 roku |
|
Relacja Disposition: |
|
|
disp_id |
id dyspozycji |
|
account_id |
id rachunku |
|
client_id |
id klienta |
|
type |
rodz aj dyspozycji (właściciel/użytkownik – tylko właściciel ma prawo wystąpić o zlecenia stałe i pożyczki) |
|
Relacja Credit_card: |
|
|
card_id |
id karty kredytowej |
|
disp_id |
id dyspozycji do rachunku |
|
type |
typ karty (“junior”, “classic”, “gold”) |
|
issued |
data wydania karty (YYMMDD) |
|
Relacja Transaction: |
|
|
trans_id |
id transakcji |
|
account_id |
id rachunku |
|
date |
data dokonania transakcji |
|
type |
wpłata/wypłata |
|
operation |
rodz aj transakcji (pobranie z karty, wpłacanie, wybranie z innego banku, wypłata w gotówce, przekaz do innego banku) |
|
amount |
kwota |
|
balance |
saldo po dokonaniu transakcji |
|
k_symbol |
charakterystyka transakcji (opłata ubezpieczeniowa, pobory, odsetki, odsetki od debetu, opłaty stałe domowe, renta/emerytura, spłata pożyczki) |
|
bank |
bank |
|
account |
rachunek |
Wymagania biznesowe
Podczas zorganizowanego warsztatu analitycznego z udziałem kierownictwa banku zapytano, jakiego rodzaju informacji (odpowiedzi, raportów) oczekuje się od tworzonej właśnie hurtowni danych. Po burzliwej dyskusji ustalono, że niezbędna będzie możliwość uzyskania odpowiedzi na następujące pytania: