2. Rezultaty zwracane przez zapytania
Jak dyskutowaliśmy przy okazji omawiania własności domkniętości, w naszym podejściu zapytania nigdy nie będą zwracać obiektów, lecz referencje do obiektów. Referencje do obiektów nie zamykają oczywiście kwestii rezultatów zwracanych przez zapytania, gdyż uwzględnimy także zapytania zwracające liczby, stringi, struktury, kolekcje itd. Istotną własnością naszego modelu rezultatów zapytań (nie spotykaną explicite w innych podejściach) jest to, że wyniki zapytań mogą być opatrzone nazwami. Wprawdzie fakt ten jest oczywisty wtedy, gdy zapytania zwracają struktury (w sensie języków C i C++), gdyż elementy tych struktur są nazwane, ale jest to raczej wyjątek. W naszym podejściu ten wyjątek podniesiemy do zasady: mianowicie oprócz referencji i wartości atomowych nasze zapytania mogą zwrócić omawiane wcześniej bindery.
|
Flagi struct, bag i sequence nie są konstruktorami typów, lecz konstruktorami wartości, czyli struktur danych zwracanych przez zapytania. W implementacji zestaw rezultatów { x1, x2, x3, ...} musi być opatrzony taką flagą, stając się w ten sposób strukturą, bagiem lub sekwencją. Ta unifikacja struktur, bagów
i sekwencji ma istotne znaczenie z punktu widzenia zwartości definicji języka, jego elastyczności i łatwości implementacji. Flaga pociąga za sobą oczywiście różnicę w operatorach, które mogą działać na takim zestawie rezultatów.
Nazwy użyte w nazwanych wartościach nie muszą być nazwami obiektów ze składu. W szczególności, mogą to być dowolne nazwy użyte przez twórcę zapytania, np. nazwy występujące po słowie kluczowym as w OQL, nazwy "zmiennych" związanych kwantyfikatorami, nazwa "zmiennej" użytej w iteratorze for each itd. Jak wynika z podanej definicji, rezultaty mogą być dowolnie zagnieżdżane za pomocą binderów oraz konstruktorów struct, bag i sequence. Przykłady elementów zbioru Rezultat są następujące:
Atomowe:
| P7.2. | 25 |
Złożone:
| P7.3. | struct{i1, i56} |
Jak widać, za pomocą podanych konstruktorów można tworzyć byty przypominające obiekty. Nie są one jednak obiektami, ponieważ nie można im przypisać własnych identyfikatorów i nie można ich związać z istniejącą lub nową klasą. Oczywiście, jeżeli referencja w pewnym rezultacie zapytania jest identyfikatorem obiektu należącego do pewnej klasy, wówczas można użyć wszelkich własności tej klasy przy zachowaniu podanych dalej reguł. Używając terminologii ODMG, rezultaty zapytań są literałami. Takiej terminologii nie będziemy stosować, gdyż tego terminu użyjemy do innych celów, a ponadto nasza definicja jest bardziej ogólna i ma inny cel oraz intencję.
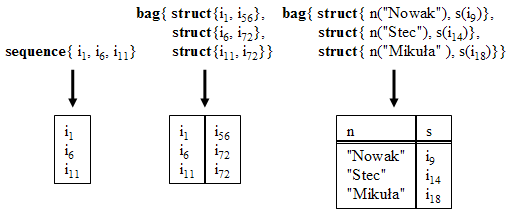
Rys.37. Rezultaty zapytań zapisane jako tablice
Niekiedy w przykładach będzie dla nas wygodnie posługiwać się tablicowym zapisem rezultatów zwracanych przez zapytanie. Sekwencje i bagi będziemy zapisywać jako tablice z elementami umieszczonymi od góry do dołu. Jeżeli wartości w krotkach tych tablic są nazwane tak samo, to nazwy te mogą być "wyciągnięte przed nawias" stając się nazwami kolumn. Rys.37 przedstawia rezultaty i odpowiadające im tablice.
Zwrócimy uwagę, że w definicji konstruktorów bag i sequence nie wymagamy, aby wszystkie elementy należące do kolekcji posiadały ten sam typ. Jakkolwiek tak będzie najczęściej, rezerwujemy sobie możliwość bardziej luźnego typowania, m.in. w związku z danymi półstrukturalnymi. Przykładowo, jeżeli podobiekt zarobek jest opcyjny, wówczas możliwe jest utworzenie następującego bagu dwóch struktur:
| P7.4. | bag{struct{ nazwisko("Abacki") zarobek(1900) } |
Generalnie, nie tworzymy na tym etapie jakichkolwiek ograniczeń - kolekcja może zawierać dowolny heterogeniczny zestaw elementów.
Podane założenia dotyczące rezultatów zwracanych przez zapytania są niezależne od konkretnego języka zapytań. Mogą być w szczególności użyte do zdefiniowania języka SQL lub OQL. Dalej zastosujemy je dokładnie w przedstawionej wyżej formie do definicji języka SBQL.
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.