W poprzednim wykładzie zostały omówione trzy podstawowe organizacje pliku rekordów: plik nieuporządkowany, posortowany i haszowany. Ze względu na różne sposoby dostępu do rekordów w danym pliku (np. ze względu na wartości różnych pól) potrzebne są osobne struktury danych wspomagające te sposoby dostępu. Obiekty bazy danych, które odpowiadają tym strukturom danym, nazywają się indeksami.
Wykład składa się z czterech części. W pierwszej części są omawiane podstawy struktur indeksowych w tym ich klasyfikacje.
W drugiej części są omawiane podstawowe struktury danych dla indeksów.
W trzeciej części jest rozważany centralny dla operacji na bazie danych problem sortowania danych zapisanych na dysku czyli tak zwany problem sortowania zewnętrznego.
W czwartej części, jako uzupełnienie do tematu budowy i wyboru indeksów w bazie danych, są przedstawione rodzaje indeksów realizowane w SZBD Oracle.
W przykładach są używane tabele Emp i Dept znajome z nauki SQL i PL/SQL.
Na początku tego wykładu przedstawimy ogólne definicje związane z indeksami oraz ogólne ich klasyfikacje.
Indeks jest to struktura danych na dysku umożliwiająca szybkie wyszukiwanie danych w bazie danych na podstawie wartości klucza wyszukiwania jak np. nazwisko osoby. Indeks w bazie danych ma takie samo znaczenie jak skorowidz (indeks) w książce!
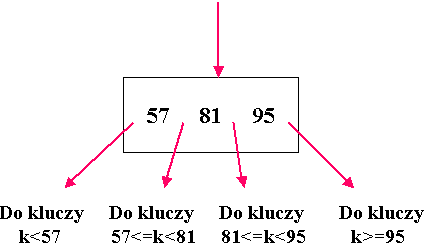
W najprostszej postaci wyszukiwanie polega na tym, że mając wartość poszukujemy rekordów, w których ta wartość występuje w danym polu.
Rys. 9.1 Wyszukiwanie rekordów według wartości w polu
Na przykład:
Operacja wyszukiwania może być nie trywialna do przeprowadzenia, gdy liczba rekordów w pliku jest bardzo duża np. gdy liczy kilkanaście milionów. Indeksy są strukturami danych, które wspomagają szybkie znajdowanie odpowiedzi na tego rodzaju zapytania. (Uwaga: Trochę inną rolę pełnią indeksy bitmapowe, w których chodzi o wyszukanie rekordów spełniających kombinację logiczną predykatów dla kolumn zawierających relatywnie małą liczbę różnych wartości. Ale nawet wtedy podstawą jest znalezienie wektora bitowego reprezentującego daną wartość, przy użyciu "klasycznego" indeksu.)
Klucz wyszukiwania dla indeksu jest to wybrane pole lub pola rekordu, względem których ma się odbywać wyszukiwanie rekordów w pliku.
Indeks jest to struktura danych składająca się z węzłów, w których są zapisywane rekordy indeksu następujących postaci:
Zawartość indeksu jest przechowywana w pliku nazywanym plikiem
indeksowym.
W skład pliku indeksowego wchodzą rekordy indeksu będące pozycjami danych lub pozycjami indeksu. Węzeł odpowiada na ogół stronie dyskowej i zawiera na ogół albo:
Indeks nazywamy wewnętrznym gdy plik indeksu zawiera w sobie plik danych tzn. pozycje danych k* indeksu pokrywają się z rekordami danych czyli gdy zachodzi przypadek 1i. w definicji pozycji danych. Indeks, który nie jest wewnętrzny nazywamy zewnętrznym.
Indeks nazywamy pogrupowanym (ang. clustered) gdy jest wewnętrzny oraz plik danych będący częścią pliku indeksowego jest posortowany według wartości klucza wyszukiwania tego indeksu (zobacz temat Plik posortowany). W rezultacie, rekordy o tej samej wartości klucza lub zbliżonej znajdują się na tej samej stronie lub tylko na kilku stronach dyskowych. Dla jednego pliku danych może być tylko jeden indeks pogrupowany, bo plik danych można posortować według wartości tylko jednego klucza wyszukiwania. Zauważmy, że z definicji każdy indeks pogrupowany jest wewnętrzny.
Rys. 9.2 Dwa typy indeksów
Indeks może być wewnętrzny i nie pogrupowany. Taką możliwość oferuje organizacja pliku haszowanego.
Reasumując, w przypadku indeksu wewnętrznego zachodzi:
W przypadku indeksu zewnętrznego zachodzi:
Gdy klucz wyszukiwania zawiera klucz główny, indeks nazywa się indeksem głównym. Gdy klucz wyszukiwania zawiera klucz jednoznaczny, indeks nazywa się indeksem jednoznacznym.
Złożone klucze wyszukiwania stanowią kombinację pól np. <sal,age>. Porównywanie wartości klucza złożonego jest oparte na porządku leksykograficznym.
Rys. 9.3 Pojedyncze i złożone klucze wyszukiwania
Na rysunku 9.3 oba indeksy ze złożonymi kluczami wyszukiwania wspomagają wykonanie zapytania z
klauzulą WHERE: age=20 AND sal=75
Natomiast tylko indeks z kluczem <age,sal> wspomaga
wykonywanie zapytań
zakresowych z klauzulami WHERE: age<20 oraz
age=20 AND sal>10
Pseudo-wartość NULL stanowi problem przy wyszukiwaniu przez indeks, ponieważ nie można o żadnej wartości powiedzieć czy jest równa NULL czy nie, również o samej NULL. Obsługa NULL jest potrzebna w indeksie, ponieważ za pomocą indeksu sprawdzane są więzy spójności klucza jednoznacznego a w składowych wartości klucza jednoznacznego są możliwe wartości NULL. Przyjmiemy założenie Oracle, że indeksowane są wszystkie wiersze, w których co najmniej jedna składowa klucza wyszukiwania indeksu nie jest NULL. Na przykład, za pomocą indeksu na kolumnie Comm nie można zrealizować wyszukiwania wierszy z nieokreśloną wartością w polu Comm:
SELECT Ename
FROM Emp
WHERE Comm IS NULL;(ale można gdy Comm IS NULL)
Jednak warto zwrócić uwagę na to, że powyższe założenie o braku obsługi NULL w indeksie nie dotyczy ani indeksów bitmapowych ani indeksów klastrowych, gdzie wszystkie składowe klucza wyszukiwania mogą być NULL.
W następnych punktach rozważymy kilka rodzajów indeksów umożliwiających szybkie wyszukiwanie rekordów w dużym pliku rekordów.
Popularną metodą wyszukiwania klucza w ciągu posortowanym jest zastosowanie wyszukiwania binarnego. Porównujemy poszukiwany klucz z kluczem rekordu znajdującym się w środku ciągu i w zależności od wyniku porównania poszukujemy klucza albo w lewej części albo w prawej – stosując rekurencyjnie opisywaną metodę.
Jak wskazaliśmy to na poprzednim wykładzie, trudno jest stosować wyszukiwanie binarne do dynamicznego ciągu uporządkowanego. Ponadto musimy brać pod uwagę fakt, że elementy ciągu czyli rekordy nie znajdują się w indeksowanej tablicy, gdzie łatwo wyliczyć środkowy indeks, a tylko na dysku.
W przypadku zapisu rekordów w postaci pliku posortowanego, wyszukiwanie binarne jest łatwiej zastosować - nie bezpośrednio do pliku rekordów - ale do pliku zawierającego same klucze rekordów k1< k2< … <kN: gdzie ki jest najmniejszym kluczem na stronie o numerze i. Plik z samymi kluczami stanowi plik indeksowy.
Rys. 9.4 Jednopoziomowy plik indeksowy
Wyszukiwanie binarne, zamiast na pliku rekordów, zostaje wykonane na znacznie mniejszym pliku indeksowym! Po wyznaczeniu najbliższego pasującego klucza wystarczy przejść do strony, na której znajduje się rekord o danym kluczu, o ile jest taki w pliku.
Nie ma przeszkód aby, tak jak dla posortowanego ciągu rekordów, tym razem do pliku indeksowego dobudować kolejny poziom sekwencyjnego indeksu z kluczami rekordów. Możemy tak postępować aż otrzymamy pojedynczy węzeł, a wszystkie poziomy sekwencyjnych indeksów dadzą nam strukturę drzewa. Dobieramy tak liczbę elementów w węźle aby jego zawartość była zapisywana na jednej stronie (ewentualnie w jednym ekstencie czyli na kilku sąsiednich stronach). Powstające w ten sposób drzewo nazywamy drzewem ISAM (skrót od ang. Indexed Sequential Access Method).
Zauważmy, że przy reprezantacji ciągu uporządkowanego za pomocą drzewa, element "środkowy" znajdujemy w korzeniu drzewa a ograniczenie wyszukiwania do podciągu realizujemy przez przejście krawędzią na kolejny, niższy poziom w drzewie.
Strona indeksu (węzeł drzewa)
Rys. 9.5 Strona indeksu
Strona indeksu składa się z pozycji indeksu <Ki,Pi>,
gdzie Ki jest
kluczem a Pi jest wskaźnikiem do węzła niższego poziomu.
Pierwszą pozycję na stronie stanowi wskaźnik P0 do węzła niższego poziomu.
|
Na rysunku 9.6 są pokazane zasady wyboru gałęzi w poszukiwaniu danego klucza.
|
|
Rys. 9.6 Zasady wyboru gałęzi przy wyszukiwaniu
Na rysunku 9.7 jest przedstawiona struktura drzewa ISAM.
Rys. 9.7 Struktura drzewa ISAM
Przykład drzewa ISAM na rysunku 9.8.
Rys. 9.8 Przykład drzewa ISAM
Wstawiamy 23*, 48*, 41*, 42* do drzewa na rysunku 9.8. Otrzymujemy drzewo ISAM na rys. 9.9:
Rys. 9.9 Drzewo ISAM po dokonanych wstawieniach
Ponieważ na stronach głównych nie było wolnego miejsca, utworzyły się doczepione do nich strony nadmiarowe - tworzące listy nieuporządkowane.
Struktura stron indeksu i stron głównych jest niezmienna. Gdy nie wystarczy miejsca na stronach głównych, doczepiane są strony nadmiarowe. Może się zdarzyć, że do jednej strony głównej trzeba doczepić długą listę stron nadmiarowych, co spowoduje, że wyszukiwanie rekordów na takiej liście będzie wymagać sprowadzenia do pamięci RAM wielu stron i może trwać długo.
Reasumując, drzewa ISAM dobrze nadają się do wyszukiwania rekordu na podstawie wartości jego klucza a także rekordów z zakresu wartości klucza: A<= klucz <=B lub A<= klucz lub klucz <=B. Gdy liczba rekordów w pliku jest mniej więcej stała, struktura ISAM jest dobra. Z powodu niebezpieczeństwa grupowania się kluczy w ciągi na stronach nadmiarowych nie jest strukturą pewną w przypadku ogólnym. Na szczęście, istnieje jej niewielka modyfikacja do tak zwanych drzew B+, która nie ma już tej wady.
Drzewo B+ (nazywane też B+ drzewem) jest to drzewo o strukturze drzewa ISAM, którego kształt dynamicznie zmienia się w zależności od liczby pozycji danych i w którym nie używa się stron nadmiarowych. Drzewo B+ jest wyważone względem wysokości (ang. height-balanced), to znaczy każdy liść znajduje się w nim na tej samej głębokości. Ponadto, wymagana zajętość każdej strony indeksu wynosi minimum 50% (z wyjątkiem korzenia).
Maksymalna długość ścieżki w drzewie B+ od korzenia do liścia jest co najwyżej clog N gdzie N = #liści a c jest stałą uzależnioną od średniej liczby pozycji indeksu na jednej stronie. Stąd wynika, że wyszukiwanie/wstawianie/usuwanie pozycji danych odbywa się w czasie rzędu logarytmicznego clog N.
Wyszukiwanie zaczyna się w korzeniu a porównania klucza wyszukiwania prowadzą do liścia tak jak dla drzewa ISAM.
Rys. 9.10 Drzewo B+ o wysokości 1
Do pozycji z kluczem 5 dochodzimy porównując w korzeniu 5 z 13 i wybierając skrajnie lewą gałąź.
Wyszukując 15, w korzeniu znajdujemy gałąź po której należy zejść, mianowicie leżącą między kluczami 13 i 17. W liściu znajdujemy tylko elementy 14 i 16. To znaczy elementu 15 nie ma w tym drzewie.
Aby przekonać się czy element znajduje się w drzewie czy nie, wystarczy przejść ścieżką zaczynającą się w korzeniu drzewa a kończącą się w jednym z jego liści. Każdą stronę indeksu na tej ścieżce należy sprowadzić do buforu w pamięci RAM.
Aby wyznaczyć wszystkie elementy większe lub równe 24, znajdujemy najpierw element 24 (w przypadku ogólnym najmniejszy element większy lub równy 24), następnie idąc w prawo po kolejnych liściach znajdujemy wszystkie elementy większe lub równe 24.
Przyjmujemy, że liście drzewa znajdują się na dwukierunkowej strukturze listowej - ułatwia ona wykonywanie zapytań zakresowych takich jak powyższe.
Tak jak opisaliśmy to powyżej indeks może być wewnętrzny i wtedy pozycje danych pokrywają się z rekordami danych – to znaczy rekordy danych są zapisywane w strukturze B+ drzewa zgodnie z porządkiem klucza wyszukiwania. Z tego powodu jest to wtedy indeks pogrupowany.
Albo indeks jest zewnętrzny i wtedy rekordy z danymi są przechowywane poza indeksem w dowolnym porządku (dla plików nieuporządkowanych, posortowanych i haszowanych).
|
Drzewa B+ w praktyce - przybliżone oszacowania
|
Indeks jest zapisywany w pliku i jego strony są sprowadzane do buforów w pamięci RAM tak jak strony rekordów z danymi. Dla pliku indeksowego:
LRU nie jest dobrą metodą!
Dla drzew B+ lepszą strategią jest następująca:
Wszystkie komercyjne systemy zarządzania bazą danych implementują B+ drzewa, z tym że na ogół pozostawiają w drzewie usunięte pozycje indeksu i danych. Na życzenie użytkownika lub w przypadku gdy ilość zajętego miejsca w drzewie spada poniżej pewnego progu – następuje wywołanie operacji REBUILD, która tworzy indeks od nowa lub COALESCE, która łączy ze sobą sąsiednie strony o zajętości poniżej 50%.
Gdy na samym początku mamy dany duży zbiór rekordów, to wtedy zamiast powtarzania kolejnych operacji INSERT opłaca się zastosować algorytm Bulk Loading, którego działanie polega na posortowaniu rekordów, a następnie dobudowaniu nad posortowanym ciągiem kolejnych poziomów indeksowych drzewa B+.
Dla pełności tematu pokazujemy na rys. 9.11 schemat węzła zwykłego B drzewa (bez plusa).
Rys. 9.11 Węzeł zwykłego B drzewa
Wyszukiwanie w zwykłych B drzewach jest nieco szybsze. Natomiast z powodu niejednolitości węzłów dla B drzew operacje INSERT i DELETE są bardziej skomplikowane. Dlatego w bazach danych preferuje się B+ drzewa.
Podsumowanie drzew
|
Indeks haszowany umożliwia szybkie wyszukiwanie rekordów w oparciu o wartość klucza wyszukiwania. Nie umożliwia wyszukiwania zakresowego. Indeks haszowany jest oparty na tej samej strukturze danych tablicy haszowanej co plik haszowany na poprzednim wykładzie.
Indeks haszowany to struktura danych oparta na rozłożeniu pozycji danych do segmentów (ang. bucket) na podstawie wartości funkcji haszującej zastosowanej do klucza wyszukiwania. Segment składa się ze strony głównej i ewentualnie listy stron nadmiarowych. Wartość funkcji haszującej określa adres strony głównej segmentu, gdzie należy szukać rekordu. W przypadku większej liczby rekordów tworzone są strony nadmiarowe doczepiane do strony głównej.
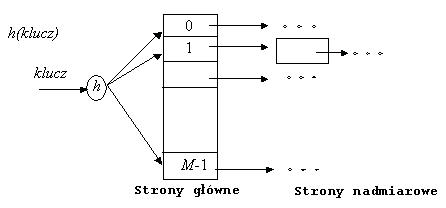
|
Rys. 9.12 Indeks haszowany
Przy prawidłowo dobranych: funkcji haszującej oraz wartości M prawie zawsze wszystkie pozycje danych znajdują się na stronie głównej i nie ma stron nadmiarowych (średnia długość listy stron dla jednej wartości funkcji haszującej wynosi 1.2). Stąd dla indeksu haszowanego średnia liczba operacji We/Wy przy wyszukiwaniu rekordu wynosi 1.2. (Używamy tu założenia, że adres segmentu dla danej wartości funkcji haszującej jest przechowywany bądź może być wyliczony w oparciu o informacje zapisane w buforze w RAM.)
Przykładowa funkcja haszująca:
h(k) = k mod M = numer segmentu, do którego należy pozycja danych o kluczu k (M = #segmentów).
Przykład indeksu haszowanego po wykonaniu ciągu operacji INSERT (przy założeniu 2 rekordów na stronie) jest pokazany na rys. 9.13.
Rys. 9.13 Przykład indeksu haszowanego
Mówimy o statycznym haszowaniu, gdy liczba segmentów jest ustalana na samym początku i nie zmienia się. Wraz ze wzrostem liczby pozycji danych (rekordów danych) zwiększa się rozmiar segmentów i co za tym idzie czas wyszukiwania, który jest proporcjonalny do liczby stron w segmencie. W przypadku dynamicznego haszowania liczba segmentów dopasowuje się dynamicznie do liczby pozycji danych. Oto dwie metody dynamicznego haszowania:
1. Okresowa (np. raz na dzień) przebudowa REBUILD pliku haszowanego przez zmianę liczby segmentów. Jest pożądane aby funkcja haszująca miała własność umożliwiającą łatwe podwojenie rozmiaru indeksu przez podział każdego segmentu na dwa (podobnie zmniejszenie rozmiaru indeksu o połowę przez scalenie parami segmentów). Wspomniana powyżej funkcja mod ma tę własność.
2. Metoda rozszerzalnego haszowania
Unika się stron nadmiarowych przez dynamiczną rozbudowę struktury segmentów. Wprowadza się pośredni katalog kierujący do stron. Gdy strona segmentu się przepełni, rozdziela się ją na dwie.
Tak jak w przypadku B+ drzew jest sens mówić o indeksie wewnętrznym (rekordy z danymi są zapisywane w indeksie) i indeksie zewnętrznym (w przeciwnym razie). Gdy warunek klucz wyszukiwania = wartość nie jest selektywny (tzn. w bazie danych spełnia go duża liczba rekordów), zastosowanie indeksu haszowanego wewnętrznego istotnie przyśpieszy wyszukiwanie, ponieważ rekordy z tą samą wartością klucza wyszukiwania znajdują się na tej samej stronie lub co najwyżej tylko kilku. W przypadku indeksu haszowanego nie ma sensu mówić o indeksie pogrupowanym ze względu na "losowe" względem wartości kluczy rozrzucanie rekordów do segmentów. Natomiast jest sens mówić o uporządkowaniu pozycji danych względem wartości klucza wyszukiwania w każdym segmencie indeksu haszowanego.
Dla jednej tabeli może być praktycznie zbudowany tylko jeden indeks wewnętrzny i wiele indeksów zewnętrznych względem różnych kluczy wyszukiwania.
W indeksie wewnętrznym zbudowanym na B+ drzewie rekordy z danymi są zapisywane na stronach reprezentujących liście drzewa. W indeksie haszowanym wewnętrznym rekordy z danymi są zapisywane na stronach segmentów. W obu przypadkach z definicji algorytmów wstawiania i usuwania wynika, że rekordy mogą być przesuwane między stronami. To znaczy, rekordy mogą zmieniać stronę a zatem nie może być do nich z zewnątrz bezpośrednich wskaźników używających identyfikatora strony. Za identyfikator rekordu używa się wtedy wartość jego klucza głównego a dostęp do rekordu jest zawsze realizowany poprzez indeks główny.
Są możliwe dwa przypadki. Często, konkretne SZBD wymagają aby indeks wewnętrzny był jednocześnie indeksem głównym. Wtedy wyszukiwanie rekordu według wartości klucza wyszukiwania indeksu zewnętrznego wymaga przejścia dwóch indeksów: najpierw zewnętrznego, w którym znajdujemy wartość klucza głównego szukanego rekordu, a następnie indeksu wewnętrznego głównego, w którym w oparciu o wartość klucza głównego znajdujemy szukany rekord.
Jest też możliwe, że indeks główny jest indeksem zewnętrznym, w którego pozycjach danych są zapisywane (zmienne) wskaźniki do rekordów. W tym przypadku, przy zmianie położenia rekordu w indeksie wewnętrznym jego adres w pozycji danych indeksu głównego też musi być uaktualniony. Reasumując, przy wyszukiwaniu rekordu przechodzimy tak jak poprzednio dwa indeksy: zewnętrzny i główny. Natomiast przy zmianach położenia rekordu w indeksie wewnętrznym wymagane jest znalezienie pozycji danych tego rekordu w indeksie głównym i zapisanie w niej nowego adresu tego rekordu.
Zatem, z jednej strony zbudowanie i użycie indeksu wewnętrznego przyśpiesza wyszukiwanie przez ten indeks - szczególnie w przypadku mało selektywnego wyszukiwania np. zakresowego dla indeksu wewnętrznego pogrupowanego - jednak z drugiej strony spowalnia on wyszukiwania przez pozostałe indeksy.
Rys. 9.14 Rodzaje indeksów wewnętrznych
|
Podsumowanie klasyfikacji indeksów Klasyfikacja indeksów obejmuje cztery ortogonalne wymiary:
Własności indeksu wynikają z zaliczenia go do odpowiedniej grupy uzyskanej przez wybór konkretnych czterech atrybutów z tych czterech wymiarów; na przykład: wewnętrzny pogrupowany zwykły indeks drzewowy czy wewnętrzny nie pogrupowany jednoznaczny indeks haszowany. |
Rozważane do tej pory struktury danych mają charakter jednowymiarowy – nawet jeśli są oparte na układach (wektorach) wartości. Oto trzy popularne, proste struktury indeksowe biorące pod uwagę wielowymiarowość danych.
(1) Siatka (ang. grid file) – podział obszaru wyszukiwań, powiedzmy leżącego na płaszczyźnie, poziomymi i pionowymi liniami na prostokąty. Punkty trafiające do jednego prostokąta są zapisywane w jednym segmencie. Gdy segmenty się przepełnią, można albo stosować strony nadmiarowe albo dzielić prostokąty na mniejsze zwiększając liczbę segmentów.
(2) Dzielona funkcja haszowana (ang. partitioned hash function):
H(v1,...,vn)=h1(v1)&h2(v2)&....&hn(vn)
Wartością funkcji haszującej dla układu wartości jest konkatenacja tekstowa wartości funkcji haszujących dla poszczególnych składowych.
(3) R drzewa
są uogólnieniem B drzew do n wymiarów. Pozycją danych w takim drzewie jest para złożona z n-wymiarowej kostki:
{(v1,...,vn): ai<=vi<=bi dla 1<=i<=n}
oraz adresu pewnego obiektu geometrycznego, który jest jednoznacznie ograniczony tą kostką. Podobnie pozycją indeksu jest taka kostka oraz wskaźnik do węzła niższego poziomu, w którego poddrzewie znajdują się wyłącznie obiekty zawarte w tej kostce i w żadnym innym poddrzewie takie obiekty nie występują.
Rozpatrzmy konkretny problem: posortować 2GB danych w buforze pamięci RAM rozmiaru 100MB. Klasyczne metody sortowania wewnętrznego w pamięci RAM nie dadzą się bezpośrednio zastosować.
W bazach danych tego typu problem sortowania pojawia się często. Oto przykłady:
Sortowanie zewnętrzne to problem sortowania pliku rekordów, który nie mieści się w pamięci wewnętrznej RAM.
Metodą stosowaną w bazach danych jest wielofazowe sortowanie zewnętrzne przez scalanie. Algorytm składa się z dwóch etapów:
Etap 1: Tworzenie początkowych uporządkowanych bloków rekordów (ang. run) – za pomocą jednej z metod sortowania wewnętrznego i dystrybucja ich do dwóch lub więcej obszarów dyskowych. Oznaczmy ich liczbę przez B.Etap 2: Wielofazowe odczytywanie obszarów dyskowych z danymi, scalanie kolejnych bloków z zapisywaniem ich do obszarów dyskowych – powtarzane dopóki nie otrzyma się pojedynczego, uporządkowanego bloku rekordów.
Rys. 9.15 Scalanie danych w puli buforów
W każdej fazie odczytujemy i zapisujemy każdą stronę w pliku.
Rys.9.16 Przykład wielofazowego sortowania zewnętrznego przez scalanie
Liczba operacji We/Wy przy wykonywaniu sortowania zewnętrznego jest <= 2N*#faz gdzie N jest liczbą stron w pliku rekordów a współczynnik 2 bierze się stąd, że każdą stronę trzeba odczytać i zapisać.
W praktyce średnio liczba faz scalania nie przekracza 3. Łącznie z fazą tworzenia początkowych bloków liczba wszystkich faz jest średnio co najwyżej 4. Zatem liczba operacji We/Wy potrzebnych do wykonania sortowania zewnętrznego jest co najwyżej 8N (N jest liczbą stron w pliku rekordów).
Załóżmy, że na pliku rekordów jest założony indeks na B+ drzewie z uporządkowaniem względem wartości klucza sortowania. Czy przejście po liściach tego drzewa od lewej strony do prawej z wypisywaniem kolejnych rekordów jest dobrą metodą sortowania względem wartości klucza sortowania (klucza indeksu)? Tak, ale tylko wtedy, gdy indeks jest pogrupowany!
Jeśli indeks nie jest pogrupowany trzeba ściągnąć do pamięci wewnętrznej tyle stron dyskowych ile jest rekordów (a nie tyle, na ilu stronach są zapisane rekordy w pliku!) – co przy dużej liczbie rekordów może dać czas większy niż czas wielofazowego sortowania przez scalanie ~ 8N operacji We-Wy, gdzie N jest liczbą stron w pliku rekordów.
Zaletą sortowania za pomocą B+ drzew jest interaktywny charakter wyznaczania wyników. W przeciwieństwie do sortowania wielofazowego wypisywanie wyników na ekran użytkownika może się rozpocząć prawie natychmiast bez konieczności obliczania całości. Gdy użytkownik ogląda pierwszą partię wyników, w tym czasie system może wyliczać następną ich część.
Pokażemy teraz jak przedstawione idee budowy i użycia indeksów stosują się w przypadku konkretnego SZBD, mianowicie firmy Oracle.
W Oracle rezultatem wyszukiwania w indeksie są identyfikatory wierszy będące wartościami specjalnego typu danych ROWID (wartości tekstowe mające 64 znaki). Są następujące rodzaje indeksów.
Pozycja danych składa się z wartości indeksowanych kolumn oraz z identyfikatora ROWID wiersza w tabeli - określającego fizyczne położenie danego wiersza na dysku. Umożliwia szybkie znalezienie wiersza w oparciu o daną wartość klucza wyszukiwania oraz realizację zapytań zakresowych. Odpowiada koncepcji indeksu zewnętrznego (nie pogrupowanego).
Przy wykonywaniu zapytania system używa indeksu opartego na B+ drzewie tylko wtedy gdy jest zapewniona wystarczająca selektywność wyszukiwania, powiedzmy zwracane zostaje co najwyżej 5 do 10% wszystkich rekordów w pliku.
Zwykły indeks oparty na B+ drzewie jest automatycznie tworzony dla każdego klucza głównego i jednoznacznego.
(tworzona za pomocą klauzuli ORGANIZATION INDEX w instrukcji CREATE TABLE)
Pozycjami danych indeksu głównego są rekordy pliku tzn. wiersze tabeli są trzymane w indeksie. Jest zapewniony bardzo szybki dostęp do wierszy przez wartości klucza głównego. Wiersze nie posiadają swoich identyfikatorów ROWID – identyfikacja wierszy przebiega wyłącznie przez wartości klucza głównego; w pozostałych indeksach wynikiem wyszukania jest wartość klucza głównego – a nie ROWID. Odpowiada to koncepcji indeksu pogrupowanego - ale budowanego tylko dla klucza głównego. Zauważmy, że budując osobno perspektywę zmaterializowaną można jej nadać inną organizację niż tabela źródłowa.
Przydatność tabeli połączonej z indeksem prześledzimy na następującym przykładzie. Załóżmy, że chcemy dokonywać analizy klientów wyszukując klientów mieszkających w określonym mieście. Załóżmy więc, że mamy dwie tabele:
Miasta(Id_miasta, Nazwa_miasta)Klienci(Id_miasta, Id_klien_w_miescie, Nazwisko, Hobby, Wiek)
z podkreślonymi kluczami głównymi. Jeśli tabela Klienci jest połączona z indeksem na swoim kluczu głównym, istotnie można przyśpieszyć wykonywanie zapytań w rodzaju:
SELECT Klienci.Nazwisko, Klienci.Hobby
FROM Klienci INNER JOIN Miasta ON Klienci.Id_miasta = Miasta.Id_miasta
WHERE Miasta.Nazwa_miasta = 'WARSZAWA'
AND Klienci.Wiek BETWEEN 18 and 25;
ponieważ po znalezieniu Id_miasta Warszawy wszyscy klienci z Warszawy będą zapisani razem tylko na kilku stronach a nie rozrzuceni po całym dysku, jak mogłoby się zdarzyć bez połączenia tabeli z indeksem.
Przykład ten jest interesujący i z tego powodu, że pokazuje zastosowanie złożonego klucza głównego.
Dla pełności prezentacji podajemy składnię instrukcji tworzącej tabelę Klienci:
CREATE TABLE Klienci(
Id_miasta INTEGER,
Id_klien_w_miescie INTEGER,
Nazwisko VARCHAR2(80),
Hobby VARCHAR(20),
Wiek INTEGER,
CONSTRAINT Klienci_pk PRIMARY KEY(Id_miasta,Id_klien_w_miescie),
CONSTRAINT Klienci_fk FOREIGN KEY(Id_miasta) REFERENCES Miasta
)
ORGANIZATION INDEX;
(klauzula REVERSE w instrukcji CREATE TABLE)
Jest stosowany tylko z predykatem równości – nie można w szczególności wypisywać wierszy wynikowych w kolejności uporządkowanej względem wartości klucza wyszukiwania. Bywa stosowany przy podziale tabeli i indeksu na partycje, gdzie równomierne rozłożenie wartości kluczy w poddrzewach B+ drzewa ma istotne znaczenie.
W klastrze wiersze kilku tabel są przechowywane razem, uporządkowane względem wartości wybranych kolumn - nazywanych kluczem klastra, np. zamówienie razem ze swoimi pozycjami (kluczem klastra jest numer zamówienia). Jest to dobra struktura w przypadku gdy aplikacje często używają złączenia dwóch lub więcej tabel wchodzących w skład klastra.
Na każdym klastrze jest zakładany indeks jednego z dwóch rodzajów:
Rozważmy przykładowe zapytanie liczące wartości zamówień złożonych przez klienta Kowalskiego.
SELECT z.Id_zam, SUM(p.Wartość*p.Ilość)
FROM (Zamówienia z INNER JOIN Pozycje_zam p ON p.Id_zam = z.Id_zam) INNER JOIN Klienci k ON z.Id_klienta = k.Id_klienta
WHERE k.Nazwisko = 'Kowalski'
GROUP BY z.Id_zam;
Wykonanie tego zapytania można istotnie przyśpieszyć korzystając z klastra zawierającego razem tabele Zamówienia i Pozycje_zam, ponieważ wszystkie pozycje zamówień znajdują się albo na tej samej stronie co samo zamówienie, albo tylko na kilku stronach na dysku.
CREATE CLUSTER Klast_zam(Id_zam INTEGER)
SIZE 2000;
Parametr SIZE określa ilość miejsca w bajtach przeznaczoną do zapisania rekordów z tą samą wartością klucza klastra, a więc w naszym przypadku, jednego zamówienia i jego pozycji. Domyślną wartością (gdy brak klauzuli SIZE) jest rozmiar strony dyskowej. Jeśli wszystkie wiersze dla danej wartości klucza klastra nie mieszczą się w jednym bloku, są zapisywane na liście nadmiarowych bloków.
Poprzez dobór odpowiedniej wartości SIZE można spowodować, że wszystkie rekordy z daną wartością klucza znajdą się na tej samej lub tylko na kilku stronach dyskowych. Oznacza to, że wyszukiwanie przez klaster może być szybkie nawet przy nie najlepszej selektywności wyszukiwania przez indeks klastra. Sztywne ustawienie wartości SIZE może jednak spowodować nie efektywne wykorzystanie miejsca na dysku – gdy zarezerwujemy więcej miejsca na rekordy z daną wartością klucza niż będzie to na ogół potrzebne.
Po utworzeniu tabel a przed wstawieniem do nich danych należy utworzyć indeks klastra.
CREATE INDEX Idx_zam ON CLUSTER Klast_zam;
Pełny przykład tworzenia klastra został podany na wykładzie 3.
W przykładzie z zamówieniami należałoby mieć założone także zwykłe indeksy na kolumnach Klienci.Nazwisko i Zamówienia.Id_klienta.
Podamy przykład zastosowania indeksu haszowanego dla klucza głównego Id_konta tabeli:
- Konta(Id_konta, Saldo, Imie, Nazwisko, Adres)
Zakładamy, że tabela Konta zawiera bardzo dużo wierszy oraz że często wielu kasjerów w banku równocześnie wykonuje zapytanie:
SELECT *
FROM Konta k
WHERE k.Id_konta = :numer;
Najpierw definiujemy klaster korzystając z opcji SINGLE TABLE, gdyż w klastrze ma być dokładnie jedna tabela:
CREATE CLUSTER Klast_konta(Id_konta INTEGER)
SIZE 512
SINGLE TABLE
HASHKEYS 100000
HASH IS mod(Id_konta, 100003);
(lub HASH IS Id_konta wtedy system sam dobierze odpowiednią funkcję
haszującą na kluczu Id_konta)
gdzie:
Liczbę wartości funkcji haszującej można odczytać z perspektywy słownika danych:
SELECT u.Hashkeys
FROM User_clusters u
WHERE u.Cluster_name = 'KLAST_KONTA';
Następnie definiujemy tabelę Konta:
CREATE TABLE Konta(Id_konta INTEGER PRIMARY KEY,
Saldo NUMBER,
Imie VARCHAR2(20),
Nazwisko VARCHAR2(50),
Adres VARCHAR2(70))
CLUSTER Klast_konta(Id_konta);
W przypadku klastra haszowanego nie trzeba explicite tworzyć indeksu na kolumnie klucza klastra.
Dostęp do informacji o koncie klienta jest teraz bardzo szybki – na ogół wystarczy sprowadzić dwie strony z dysku (jedną indeksu i jedną z pliku rekordów), aby odczytać wartości w wierszu. W przypadku pesymistycznym może się jednak zdarzyć, że wiele kluczy da tę samą wartość funkcji haszującej i wtedy po przekroczeniu rozmiaru SIZE kolejne rekordy będą umieszczane na stronach nadmiarowych.
Oto przykład posortowanych segmentów haszowanych dla aplikacji billingowej.
CREATE CLUSTER
call_detail_cluster
( telno NUMBER, call_timestamp NUMBER SORT, call_duration
NUMBER SORT )
SIZE 256
SINGLE TABLE
HASHKEYS 10000
HASH IS telno;
CREATE TABLE call_detail
( telno NUMBER, call_timestamp NUMBER SORT,
call_duration NUMBER SORT,
other_info VARCHAR2(30) )
CLUSTER call_detail_cluster
( telno, call_timestamp, call_duration );
Indeks zostanie użyty aby wyświetlić rozmowy wykonane z danego numeru w kolejności od najwcześniejszego.
SELECT *
WHERE telno = 6505551212
ORDER BY call_timestamp;
Kolumny indeksu mogą być wyrażeniami zawierającymi funkcje (z wyłączeniem funkcji agregujących). Na przykład, założenie indeksu
CREATE INDEX Uppercase_idx ON Emp(UPPER(Ename));
pomaga w realizacji wyszukiwania pracowników w oparciu o ich nazwiska - nie biorąc pod uwagę wielkości liter w nazwisku:
SELECT * FROM Emp e
WHERE UPPER(e.Ename)='KOWALSKI';
został omówiony w wykładzie na temat hurtowni danych.
W wykładzie tym zaznajomiliśmy się z budową indeksów oraz z sortowaniem zewnętrznym.
Dodatkowo zostały przedstawione rodzaje indeksów, które występują w systemie Oracle. Pokazuje to, jak ogólna teoria dotycząca indeksów jest realizowana w praktyce.
indeks - struktura danych na dysku umożliwiająca szybkie wyszukiwanie danych w bazie danych na podstawie klucza wyszukiwania rekordu np. nazwiska osoby. Indeks jest zapisywany w pliku nazywanym indeksowym.
plik indeksowy - plik, w którym jest przechowywany indeks.
indeks wewnętrzny - indeks, którego plik zawiera w sobie plik danych tzn. pozycje danych w indeksie pokrywają się z rekordami danych. Mówi się też, że tabela jest zorganizowana przez indeks. W przeciwnym razie indeks nazywamy zewnętrznym.
indeks zewnętrzny - indeks, którego plik jest zbudowany niezależnie od pliku danych tzn. pozycje danych w indeksie są niezależne od rekordów danych.
indeks pogrupowany - indeks, który organizuje pozycje danych i rekordy danych w kolejności uporządkowanej względem wartości klucza wyszukiwania. Oznacza to, że rekordy o tej samej wartości klucza lub zbliżonej znajdują się na tej samej stronie lub tylko kilku stronach dyskowych. W przeciwnym razie indeks nazywamy nie pogrupowanym. Może być tylko jeden indeks pogrupowany ale wiele nie pogrupowanych.
indeks główny - indeks, którego klucz wyszukiwania zawiera klucz główny. Może być tylko jeden indeks główny.
indeks jednoznaczny - indeks, którego klucz wyszukiwania zawiera klucz jednoznaczny. Może być wiele indeksów jednoznacznych.
drzewo ISAM - implementacja indeksu w postaci statycznego drzewa opartego na wyszukiwaniu binarnym.
drzewo B+ - implementacja indeksu w postaci dynamicznego drzewa opartego na wyszukiwaniu binarnym.
indeks haszowany - implementacja indeksu w postaci pliku haszowanego.
sortowanie zewnętrzne - sortowanie pliku danych, który nie mieści się w pamięci wewnętrznej RAM.
wielofazowe sortowanie zewnętrzne przez scalanie - podstawowa metoda sortowania zewnętrznego. Składa się z dwóch etapów: tworzenia początkowych, uporządkowanych bloków rekordów – za pomocą jednej z metod sortowania wewnętrznego oraz wielofazowego odczytywania uporządkowanych bloków rekordów i sukcesywnego ich scalania, dopóki nie otrzyma się pojedynczego uporządkowanego bloku rekordów.
1. Zaimplementuj algorytmy na strukturze B+ drzewa przy założeniach wprowadzonych na wykładzie (dwupoziomowe przechowywanie węzłów drzewa, węzeł drzewa równoważny stronie, opóźnione usuwanie).
2. Zaimplementuj algorytmy na posortowanym pliku rekordów z dwoma drzewowymi indeksami: jednym wewnętrznym głównym, drugim zewnętrznym.
3. Zaimplementuj algorytmy na strukturze tablicy haszowanej przy założeniach wprowadzonych na wykładzie (dwupoziomowe przechowywanie węzłów drzewa, węzeł drzewa równoważny stronie, opóźnione usuwanie).
4. Opracuj algorytmy dynamicznego haszowania rozwijając idee 1 i 2 naszkicowane w czasie wykładu.
5. Podaj przykład aplikacji gdzie warto zastosować tabelę połączoną z indeksem opartym na B+ drzewie (w wersji Oracle).
6. Podaj przykład aplikacji gdzie warto zastosować klaster tabel oparty na B+ drzewie z indeksem o kluczu złożonym (w wersji Oracle).
7. Podaj przykład aplikacji gdzie warto zastosować klaster oparty na tablicy haszowanej z indeksem o kluczu złożonym (w wersji Oracle).