2. Schemat i organizacja danych - nieodłączne cechy języka zapytań
Istotnym aspektem dowolnego języka komputerowego jest jego pragmatyka, wyznaczająca funkcje języka w komunikacji pomiędzy człowiekiem a maszyną. W przypadku języka zapytań pragmatyka oznacza związek pomiędzy rzeczywistą (biznesową) potrzebą a sformułowaniem tej potrzeby w języku zapytań przez użytkownika lub programistę. Pragmatyka jest podstawą użytkowych własności języka; pragmatyce podporządkowane są zarówno składnia, jak i semantyka. Użytkownik języka musi być w pełni świadomy celów formułowania zapytania, związków zapytania zarówno z jego celem (biznesowym), jak i strukturą danych. Musi być świadomy technicznych i biznesowych własności struktur danych oraz technicznych i biznesowych własności zwracanego przez zapytanie wyniku.
Warunkiem koniecznym umożliwiającym formułowanie zapytań jest informacja, co zawiera baza danych i jak jest zorganizowana. Ta informacja musi mieć algorytmiczną precyzję. Determinizm programów komputerowych (w tym zapytań) oznacza, że użytkownik lub programista posiada wiedzę o logicznej organizacji danych. Terminem "logiczna" określa się organizację danych wyrażoną w terminach precyzyjnego "zewnętrznego" modelu danych, abstrahującą od fizycznej reprezentacji danych. Rys.1 przedstawia zależności pomiędzy komponentami mechanizmu przetwarzania zapytań uwzględniające pragmatykę. Są one następujące:
- Model danych wyznacza reguły budowy oraz ograniczenia struktur danych, zatem pośrednio określa składnię i semantykę języka schematu danych oraz metamodelu ustalającego organizację danych.
- Schemat składu (lub bazy) danych powstaje w wyniku analizy dziedziny przedmiotowej (biznesu), zakresu aplikacji, które mają go wspomagać oraz projektu struktury (bazy) danych niezbędnej do działania tych aplikacji.
- Skład lub baza danych zawiera konkretne dane zgodne z modelem danych, kontrolowane przez metamodel i schemat składu danych. Bieżący stan składu danych zmienia się i zwykle jest nieznany dla użytkownika w momencie pisania zapytania. Z tego względu zapytanie jest formułowane
w odniesieniu do (zwykle nieskończonego) zbioru możliwych stanów składu. Zbiór ten jest określony semantyką schematu. Każdy stan składu danych może być przedstawiony na poziomie logicznym z algorytmiczną precyzją. Użytkownik jest w pełni świadomy potencjalnego zbioru możliwych struktur danych, na których działa jego zapytanie, mimo że nie zna konkretnego stanu tych struktur.
- Zapytanie jest formułowane przez użytkownika na podstawie rozpoznanej potrzeby w dziedzinie przedmiotowej oraz na podstawie wiedzy o strukturach danych. Wiedza ta jest wyznaczona schematem oraz związkiem schematu z dziedziną przedmiotową.
- Wynik zapytania powstaje jak skutek zapytania oraz bieżącego stanu składu danych. Wynik jest interpretowany przez użytkownika w dziedzinie przedmiotowej, w związku z czym może go poprawnie przetwarzać za pomocyą innych własności systemu.
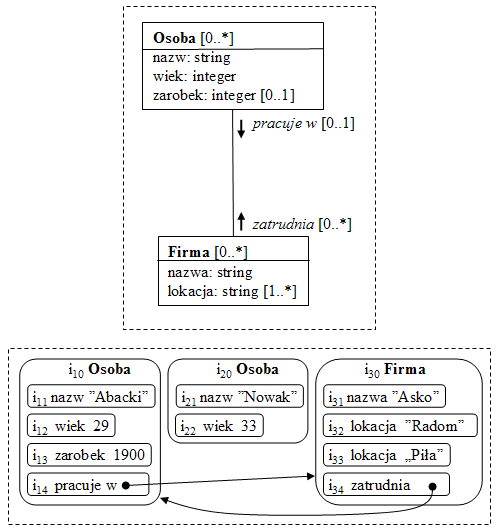
Rys.2. Schemat składu danych i przykładowy stan składu
Rys.2 przedstawia przykład schematu danych, z którego użytkownik widzi, z jakimi obiektami biznesowymi ma do czynienia (Osoba i Firma), rozumie ich znaczenie w dziedzinie biznesowej, wie, jakie mają atrybuty (wraz z typami) i jak są ze sobą powiązane (powiązania pracuje w/zatrudnia). Zna też liczności wszystkich elementów w dowolnym stanie składu, np. wie, że obiektów Osoba może być od zera do dowolnej liczby, atrybut zarobek może nie wystąpić, zaś firma może być zlokalizowana w jednym lub więcej miejsc. Rysunek przedstawia też przykładowy stan składu danych odpowiadający temu schematowi. Prawdziwego stanu użytkownik zwykle nie zna, ale na podstawie pewnych wyobrażeń odnośnie do własności logicznych struktur danych może poprawnie zbudować zapytanie. Przykładowo, użytkownik wie, że każda dana w składzie ma referencję (identyfikatory i10 - i34), wobec czego może stosować konstrukcje językowe wymagające referencji (np. operacje usuwania).
W powyższym modelu formułowania zapytań istotne jest to, że użytkownik/programista musi być w pełni świadomy zarówno formalnych struktur danych, jak i ich nieformalnego znaczenia w dziedzinie przedmiotowej. Świadomość ta powinna być doprowadzona do stanu algorytmicznej precyzji, tj. użytkownik formułując zapytanie ma precyzyjne wyobrażenie odnośnie do budowy logicznej struktur danych oraz wyniku zwracanego przez zapytanie.
Świadomość tę określa się zbiorczym terminem modelowanie pojęciowe, które oznacza, że zadający zapytanie rozumie dziedzinę biznesową, struktury danych, konstrukcję zapytania oraz znaczenie jego wyniku.
Wnioski z powyższej dyskusji są następujące:
-
Użytkownik formułujący zapytanie powinien posiadać i rozumieć opis danych zawartych w składzie (bazie) danych. W idealnym przypadku powinien to być schemat danych zapisany w odpowiednim precyzyjnym języku. Wzorcem takiego języka może być IDL standardu CORBA [OMG02], ODL standardu ODMG [ODMG00] lub DTD (lub XMLSchema) dla repozytoriów XML [XML04].
-
Schemat danych jest opisem nieskończonego zbioru stanów składu danych rozumianych na poziomie logicznym, ale z algorytmiczną precyzją. Użytkownik powinien dokładnie rozumieć te stany. Jest to jego model składu danych. Brak precyzyjnego modelu składu danych uniemożliwia zbudowanie języka zapytań. Przykładowo, diagram klas UML przypomina schemat składu (bazy) danych. Ten schemat odwołuje się do ludzkiej wyobraźni i w tym kontekście doskonale pełni swoją funkcję. Nie definiuje jednak pojęcia stanu składu danych (składu obiektów) odpowiadającego temu schematowi, m.in. nie ustala precyzyjnie, jakie struktury danych będą odpowiadać dziedziczeniu bądź asocjacji. Z tego względu precyzyjne zdefiniowanie języka zapytań dla UML nie jest możliwe. Możliwe jest natomiast zdefiniowanie takiego języka dla pewnego podzbioru diagramu klas UML, dla którego ustalony będzie precyzyjny model składu danych.
-
Podobnie do rozumienia stanów składu danych, użytkownik musi rozumieć wynik zapytania, na poziomie logicznym, ale z algorytmiczną precyzją. Z tego powodu konieczne jest dokładne ustalenie dziedziny tych wyników, zwykle różnej od dziedziny stanów składu, ale bazującej na tych samych pojęciach.
W niektórych propozycjach dotyczących tzw. półstrukturalnych danych (semistructured data) wprowadza się silne nieregularności w danych. Dla takich nieregularnych danych zdefiniowane są języki zapytań; przykładem jest system Lore [Abit97a] i jego język Lorel. Niekiedy w tym kontekście mówi się, że wprowadzany model danych nie posiada schematu (schemaless model). Niestety, tego rodzaju stwierdzenia dowodzą pewnej naiwności lub nadmiernych uproszczeń. Nawet dla nieregularnych danych użytkownik musi mieć wyobrażenie, co baza danych zawiera, i to zarówno od strony semantyki w dziedzinie biznesowej, jak i struktur danych. Użytkownik może oczywiście budować sobie to wyobrażenie w dowolny sposób - może np. przeczytać pewien opis w języku naturalnym i/lub obejrzeć kilka przykładowych stanów bazy danych. Tak czy inaczej, jeżeli ma później formułować zapytania, jego wyobrażenie musi przybrać ścisłą formę, chociaż być może nie zapisaną. Jeżeli wyobrażenie nie jest ścisłe, wówczas niemożliwe są precyzyjne zapytania. Przykładowo, jeżeli o stanie bazy danych wie, że jest to ciąg bajtów składający się na tekst w języku angielskim, to jego język zapytań zostanie zredukowany do słów kluczowych i, być może, specyficznych, niejawnie wywoływanych metod przetwarzania wykorzystujących reguły gramatyczne i semantyczne języka naturalnego. W tym wykładzie przyjmujemy, że zapytania odnoszą się do dobrze zestrukturalizowanych danych, a nie do dowolnych ciągów bajtów. Wiedza o regułach logicznej budowy takich struktur oraz o przyporządkowaniu tych struktur do dziedziny przedmiotowej jest niezbędna do formułowania zapytań.
Dowolne nieregularności w danych mogą mieć również formalny opis. Przykładowo, na Rys.2 atrybut zarobek może nie wystąpić, zaś atrybut lokacja może wystąpić dowolną liczbę razy. Mimo nieregularności, opis odpowiada wymogowi algorytmicznej precyzji. Możliwe są oczywiście inne środki do zapisu nieregularności w danych, np. znane z Pascala lub C warianty/unie lub definiowanie schematu struktur danych poprzez wyrażenia regularne lub gramatyki bezkontekstowe (ta metoda została zastosowana w systemie Loqis).
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.