1.1. Stos środowisk w językach programowania
Pojęcie środowiska (environment) działania programu oznacza zestaw wszystkich bytów programistycznych czasu wykonania (zmiennych, stałych, obiektów, funkcji, procedur, typów, klas itd.), które są dostępne w danym punkcie sterowania programu. Środowisko wykonania nie jest "płaską" strukturą i zmienia się w trakcie działania programu. Najwygodniejszym sposobem zarządzania zmianami środowiska jest przyjęcie założenia, że środowisko jest podzielone na podśrodowiska, które pojawiają się i znikają w miarę przesuwania się punktu sterowania programu. Okazało się, że z ergonomicznego punktu widzenia dobrze jest przyjąć pewne zasady, które mają wpływ na technikę i niezawodność programowania. Zasady te są następujące:
-
Środowisko lokalne danego bytu programistycznego ma priorytet w stosunku do środowiska bardziej globalnego. Np. programista koncentrujący się nad napisaniem pewnej procedury powinien mieć możliwość abstrahowania od wpływu globalnego środowiska na tę procedurę.
-
Zasada lokalnego kontekstu: programista piszący pewną procedurę nie może uwzględnić w niej tych (nieznanych) elementów środowiska wykonania, które pojawią się w momencie wywołania tej procedury.
- Zasada dowolnego zagnieżdżania wołań procedur: programista piszący procedurę może bez ograniczeń koncepcyjnych wołać w niej inne procedury. W szczególności, dopuszczalne są rekurencyjne wołania, pośrednie lub bezpośrednie.
Przyjęcie tych zasad prowadzi do pojęcia stosu środowisk (określanego także jako stos wołań, call stack), czyli struktury danych odpowiedzialnej za kontrolowanie zmian środowiska wykonania programów. W językach programowania cel, działanie i organizacja mechanizmu stosu środowisk jest dobrze rozpoznane. Stos ten jest odpowiedzialny za:
-
kontrolowanie zakresów nazw zmiennych i wiązanie tych nazw;
-
przechowywanie wartości lokalnych zmiennych funkcji, procedur lub metod;
-
przechowywanie wartości parametrów aktualnych funkcji i procedur;
- przechowywanie tzw. śladu powrotu, tj. adresu instrukcji, do której ma przejść sterowanie po zakończeniu działania funkcji, procedury lub metody.
Stos środowisk jest strukturą danych przechowywaną w pamięci operacyjnej (lub wirtualnej). Jest podzielony na części, które będziemy określać jako sekcje, przy czym kolejność tych sekcji jest istotna. Stos jest zarządzany zgodnie z wołaniami procedur, funkcji, metod itd. oraz w związku z wejściem sterowania w tzw. bloki programu. Nowa sekcja (tzw. zapis aktywacji, activation record) pojawia się na wierzchołku stosu w momencie wejścia sterowania programu w procedurę (funkcję, metodę) oraz w momencie wejścia sterowania w blok. Sekcja ta zawiera wartości lokalnych zmiennych, wartości parametrów oraz (dla procedur, funkcji i metod) ślad powrotu. Zatem nowa sekcja na stosie odpowiada każdemu wołaniu procedury, funkcji lub metody, lub wejściu sterowania w nowy blok. Sekcja ta jest usuwana z wierzchołka stosu w momencie zakończenia procedury (funkcji, metody) oraz w momencie wyjścia z bloku. Wszystkie lokalne zmienne zadeklarowane w aktualnie wykonywanej procedurze (funkcji, metodzie) oraz jej parametry są przechowywane na wierzchołku tego stosu.
1.2. Wiązanie nazw
Przykładowo, wiązanie zmiennej x oznacza zastąpienie tej nazwy przez adres pamięci operacyjnej, gdzie przechowywana jest wartość zmiennej x. Wiązanie nazw na stosie środowiskowym (m.in. nazw zmiennych i parametrów) odbywa się więc według prostej zasady:
-
poszukuje się wartości opatrzonej tą nazwą na wierzchołku stosu;
-
jeżeli na wierzchołku takiej nazwy nie ma, poszukuje się takiej wartości
w sekcji poniżej; -
proces ten jest kontynuowany aż do znalezienia wartości opatrzonej tą nazwą, ale z uwzględnieniem reguł zakresu (scoping rules), które nakazują omijanie pewnych sekcji stosu;
- jeżeli nazwa nie jest odnaleziona na stosie, wówczas poszukiwana jest ona wśród zmiennych globalnych (ew. tzw. zmiennych statycznych), bibliotek funkcji i zmiennych/stałych środowiskowych. Można uważać, że tego rodzaju globalne własności znajdują się na dole stosu środowisk.
Sytuacja ta została zilustrowana na Rys.33. Zakładamy, że sterowanie aktualnie znajduje się w bloku b, który znajduje się wewnątrz procedury p2, która została wywołana z procedury p1. Strzałki pokazują kolejność przeszukiwania stosu podczas wiązania nazwy x występującej wewnątrz modułu m.
Rys.33. Przykładowa sytuacja na stosie środowisk
Rys.33 ilustruje także regułę zakresu: zmienne i parametry procedury p1 są niewidoczne podczas wiązania nazw występujących w wywołanej przez nią procedurze p2 (oraz w dowolnych innych wywołanych przez nią procedurach). Reguła ta jest podyktowana koniecznością hermetyzacji lokalnych własności procedury. Programista programujący p1 i programista programujący p2 są to często dwie osoby; ich działania mogą być odległe w przestrzeni i czasie. Np. p2 może być procedurą biblioteczną zakupioną od innej firmy. Programista programujący p2 nie uwzględnia oczywiście tego, kto i z jakiego środowiska wywoła jego procedurę. Dzięki regule zakresu nie występuje sytuacja, że np. pewna zmienna globalna zostaje związana nie w dolnej sekcji stosu, lecz przypadkowo wewnątrz procedury p1. Zarówno programista programujący p1, jak i programista programujący p2 mogą dzięki temu używać dowolnych nazw, bez uzgadniania i bez możliwości konfliktu.
Sytuacja przedstawiona na Rys.33 jest bardziej skomplikowana dla języków wprowadzających moduły i klasy. W językach wprowadzających moduły należy uwzględnić fakt, że własności modułu są podzielone na publiczne i prywatne, oraz że moduł specyfikuje listę importową, tj. własności innych modułów dostępne z danego modułu. Rozpatrując podobny przykład jak wyżej przy założeniu, że procedura p1 znajduje się wewnątrz modułu m1, zaś procedura p2 znajduje się wewnątrz modułu m2, sytuacja na stosie środowisk jest przedstawiona na Rys.34. Na dole stosu znajdują się referencje do wszystkich dostępnych modułów (wiązane w przypadku, gdy programista użyje ich nazwy) oraz referencje do własności środowiska globalnego, m.in. nazw stałych i zmiennych środowiskowych. Sytuacja na stosie staje się jeszcze bardziej złożona dla języków obiektowych. Do tego zagadnienia wrócimy.
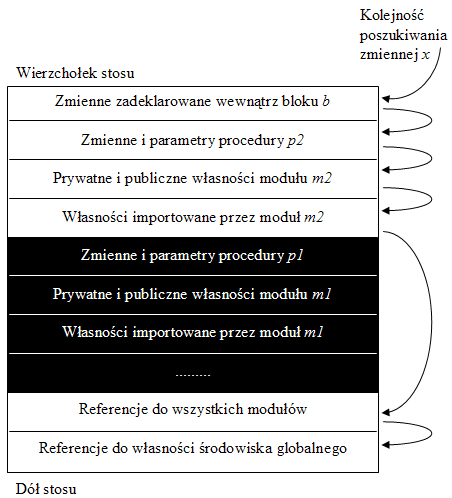
Rys.34. Przykładowa sytuacja na stosie środowisk dla języków modularnych
Mechanizm stosu środowiskowego pozwala zrealizować następujące własności języków programowania:
-
Abstrakcja i hermetyzacja: wnętrze napisanej procedury (funkcje, metody) zostaje ukryte przed programistami, którzy jej użyją. Procedura jest widoczna wyłącznie poprzez jej interfejs, na który składają się jej nazwa, jej parametry, jej wynik oraz jej skutki działania na zewnątrz.
-
Izolacja: programiści piszący różne procedury (funkcje, metody) nie muszą o sobie wiedzieć ani nie muszą między sobą uzgadniać nazw użytych przez nich lokalnych zmiennych.
-
Semantyczna niezależność i ponowne użycie: procedura o dobrze wyspecyfikowanym interfejsie i działaniu może być wielokrotnie wywołana z wielu miejsc danej aplikacji. Może być także używana w wielu aplikacjach.
-
Dowolne wywoływanie procedur z innych procedur, włączając wołania rekurencyjne. Dzięki temu, że sekcja stosu jest przypisana do wołania procedury, nie zachodzi konflikt przy wywołaniach procedur z procedur; w szczególności, procedura może bez ograniczeń wywołać samą siebie.
-
Spójne zarządzanie nazwami użytymi w programie. Przestrzeń użytych nazw jest ściśle kontrolowana, zaś nazwy są wiązane do bytów programistycznych czasu wykonania według ścisłych reguł.
- Realizacja metod transmisji parametrów: wartości parametrów oraz inne ich własności są odkładane w lokalnych sekcjach stosu, dzięki czemu możliwy jest spójny dostęp i zarządzanie parametrami oraz realizacja metod transmisji parametrów, takich jak wołanie przez wartość (call-by-value) lub wołanie przez referencję (call-by-reference).
Podane własności mają również znaczenie dla języków zapytań, pozwalając w spójny sposób zrealizować niektóre ich założenia, takie jak możliwość dowolnego zagnieżdżania zapytań, możliwość powoływania lokalnych nazw wewnątrz zapytań, możliwość używania nazw z bazy danych łącznie z nazwami zmiennych programistycznych, nazwami procedur, funkcji i metod. Nieuwzględnienie mechanizmu stosu środowiskowego w typowych podejściach do języków zapytań, takich jak algebra relacji, rachunek relacyjny, logika matematyczna, reguły dedukcyjne, obiektowe algebry, F-logika, komprehensje itd. z góry skazuje je na ułomność i ograniczenia.
1.3. Stos statyczny i dynamiczny
W językach z wczesnym (statycznym) wiązaniem nazwy występujące w programie są drugiej kategorii programistycznej, w związku z czym nie są dostępne i manipulowalne podczas wykonania programu. Dla takich języków stos środowiskowy musi istnieć w dwóch postaciach: stos zarządzany podczas kompilacji (stos statyczny) oraz stos czasu wykonania (stos dynamiczny). Wiązanie nazw odbywa się na stosie statycznym. Podczas kompilacji stos ten symuluje działanie stosu dynamicznego, tj. jest podwyższany lub skracany w miarę wchodzenia analizatora syntaktycznego w różne fragmenty tekstu programu. Stos ten przechowuje nazwy bytów programistycznych, ich typy lub sygnatury oraz informacje o ich reprezentacji. Wiązanie nazw nie jest bezwzględne (czyli z dokładnością do adresów pamięci), lecz relatywne, z dokładnością do odległości (mierzonej w bajtach) położenia reprezentacji danej wartości od wierzchołka stosu dynamicznego. Dopiero podczas wykonania następuje ostateczne obliczenie adresu ulokowania danego bytu programistycznego poprzez prostą operację arytmetyczną na adresie relatywnym i aktualnym rozmiarze stosu. W językach z dynamicznym wiązaniem nazw stos dynamiczny pamięta zarówno nazwy bytów programistycznych użyte w programie, jak i ich wartości. Dość często celem optymalizacji stosuje się rozwiązania hybrydowe, w którym część nazw jest wiązana podczas kompilacji, zaś część podczas wykonania.
Dla celów niniejszej pracy rozróżnienie pomiędzy wiązaniem statycznym i dynamicznym jest drugorzędne, tym bardziej że języki zapytań są z reguły wiązane dynamiczne. Z tego powodu dalszy wykład będziemy prowadzić przy założeniu, że wszystkie wiązania są dynamiczne, zaś wiązania statyczne oraz stos statyczny są elementami optymalizacji zapytań.
1.4. Stos środowisk w podejściu stosowym do języków zapytań
Konstrukcję stosu środowisk dostosujemy do wymagań precyzyjnej specyfikacji semantyki definiowanych przez nas języków zapytań oraz konstrukcji bazujących na języku zapytań, takich jak perspektywy, procedury bazy danych, i generalnie, programy. Definiowany przez nas stos będzie spełniał następujące założenia:
-
Będzie zgodny z określonym wcześniej modelem składu obiektów M0 - M3. Wszystkie założenia danego modelu składu będą odwzorowane w konstrukcji stosu oraz w jego działaniu. Zgodnie z tymi modelami, stos będzie w jednorodny sposób traktował zarówno dane indywidualne, jak i kolekcje.
-
Maksymalny rozmiar stosu nie będzie ograniczony od strony koncepcyjnej, jakkolwiek zawsze wystąpią pewne ograniczenia implementacyjne. Zakładamy, że te ograniczenia nie będą istotne dla programisty.
-
Stos będzie składał się z sekcji, gdzie każda sekcja będzie przechowywać informację o pewnym środowisku czasu wykonania, np. środowisku wywołania pewnej funkcji, procedury lub metody, środowisku wnętrza pewnego obiektu, środowisku wnętrza pewnej klasy, środowisku obiektów bazy danych itd. Rozmiar sekcji nie będzie ograniczony koncepcyjnie.
-
Sekcje najbardziej lokalnych środowisk (np. sekcja aktualnie działającej procedury) będzie umieszczona na wierzchołku stosu, zaś sekcje wcześniej wywołanych procedur (funkcji, metod) będą umieszczone odpowiednio coraz niżej.
-
Na dole stosu umieszczone będą sekcje globalne, do których należą globalne zmienne aplikacji, baza danych, wspólne biblioteki procedur i funkcji oraz zmienne środowiskowe systemu komputerowego. Stos będzie więc przechowywał pełną informację niezbędną do wiązania dowolnej nazwy, która może wystąpić w zapytaniu, perspektywie, procedurze bazy danych, trygerze lub programie aplikacyjnym. Dla uproszczenia przykładów będziemy zwykle pomijać nieistotne dla naszych rozważań sekcje globalne, pozostawiając jedynie sekcję bazy danych.
-
Stos będzie w jednakowy sposób traktował zarówno dane trwałe (persistent) przechowywane w bazie danych, dane chwilowe będące danymi lokalnymi wywoływanych procedur, funkcji i metod oraz dane chwilowe będące danymi globalnymi danej aplikacji.
-
Stos będzie także miejscem przechowywania (w zunifikowany sposób) informacji o definicjach wprowadzanych w zapytaniach lub w programach. Np. będzie przechowywał informację o tzw. "synonimach" lub "zmiennych korelacyjnych" (w SQL lub OQL), zmiennych związanych kwantyfikatorami, zmiennych używanych w iteratorach "for each" itd.
- W odróżnieniu od języków programowania, gdzie stos środowisk jest jednocześnie składem wartości zmiennych, będziemy zakładać, że stos jest strukturą danych odseparowaną od składu obiektów. Powodem tego podziału jest przede wszystkim to, że w budowanej przez nas semantyce języków zapytań odwołania do tego samego obiektu mogą pojawić się w różnych sekcjach stosu. Innym powodem jest objęcie zakresem mechanizmu stosu dowolnych własności środowiska aplikacji, takich jak baza danych, zmienne globalne, biblioteki, zmienne środowiskowe itd.
Podstawową strukturą przechowywaną na stosie środowisk jest binder. Binder jest parą <n, x>, gdzie n jest zewnętrzną nazwą (nazwą zmiennej, stałej, obiektu, funkcji, perspektywy, procedury, metody itd.), zaś x jest bytem czasu wykonania (zwykle referencją do obiektu). Parę <n, x> będziemy zapisywać n(x). Nieco dalej definicję tę uogólnimy. Koncepcja bindera jest bardzo prosta. Zadaniem bindera n(x) jest wiązanie, czyli zastąpienie nazwy n występującej
w zapytaniu lub programie na wartość x, będącą bytem programistycznym czasu wykonania. Dla dowolnej nazwy występującej w programie musi być obecny na stosie odpowiedni binder, który zamieni tę nazwę na byt czasu wykonania. Nazwa, dla której odpowiadający jej binder nie istnieje, nie może być związana, czyli jest błędna. Przy bardziej luźnych modelach składu (tzw. półstrukturalnych, semistructured) możemy alternatywnie uznać, że wiązanie takiej nazwy jest puste (jest np. pustym zbiorem).
W budowanej przez nas semantyce bindery będą miały także inne zastosowania, w szczególności, będą niekiedy zwracane jako rezultaty zapytań. Do kwestii tych dojdziemy w dalszych fragmentach tej książki.
Dla skrócenia wyjaśnień i dyskusji w dalszej części książki stos środowiskowy będziemy oznaczać ENVS (ENVironment Stack).
Rys.35 przedstawia przykładowy stan składu obiektów oraz stan stosu ENVS. Założyliśmy, że skład zawiera obiekty ulotne i obiekty trwałe. Stos środowisk zawiera sekcje z binderami. Wartościami binderów są identyfikatory (które w tym kontekście będą tradycyjnie nazywane referencjami) lub wartości atomowe, takie jak 5 lub "Maria". Dla większości zastosowań obiektowych języków zapytań takie założenia byłyby w zupełności wystarczające. Stanowiły podstawę implementacji systemu Loqis. Dla pewnych konstrukcji języków zapytań powinny jednak być rozszerzone dla uzyskania uniwersalności tych konstrukcji oraz czegoś, co można byłoby nazwać ich estetycznym domknięciem, czyli uniknięciem niejasnych ograniczeń i konieczności dodatkowych wyjaśnień.
PPojedyncza referencja jest szczególnym przypadkiem rezultatu zapytania, w związku z czym podana definicja przykrywa poprzednią. Podana wyżej generalna definicja okaże się użyteczna szczególnie wtedy, gdy będziemy chcieli przechowywać na ENVS rezultaty wcześniej obliczonych zapytań. Definicją rezultatu zapytania zajmiemy się w następnej sekcji.
W ten sposób, poprzez definicję składu obiektów i stosu ENVS uzyskaliśmy precyzyjną definicję wprowadzonego uprzednio pojęcia stanu.
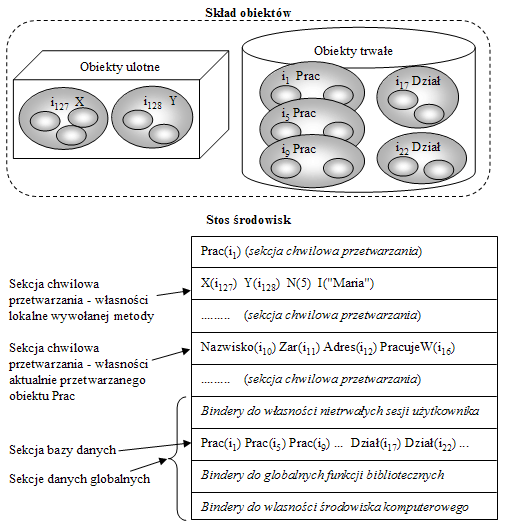
Rys.35. Przykładowy stan składu obiektów i stan stosu ENVS dla modelu M0 przedstawionego na Rys.23 i Rys.24
W podejściu stosowym pojęcie stanu (dziedzina Stan) jest definiowane jako stan składu obiektów plus stan stosu środowisk.
Brak pojęcia stanu jest bardzo poważną wadą wielu koncepcji i modeli obiektowych, w szczególności standardów SQL-99 i ODMG. Uważamy, że jest to powód, aby uważać, że standardy te nie będą zdolne wypełnić tych ról, które były motywem prac nad ich utworzeniem.
Zgodnie z wcześniejszymi definicjami, semantyka zapytania jest funkcją odwzorowującą stan, czyli stan składu obiektów oraz aktualny stan ENVS, w rezultat zapytania. To odwzorowanie będzie zdefiniowane rekurencyjnie, poprzez odpowiednie reguły semantyczne przyporządkowane do reguł syntaktycznych. Elementarnym odwzorowaniem, które będzie podstawą wszelkich dalszych definicji reguł semantycznych, jest semantyka pojedynczej nazwy występującej w zapytaniu lub w programie. Czynność ewaluacji takiej nazwy nosi nazwę wiązania. Wiązanie odbywa się na ENVS zgodnie z regułą stosu, która nakazuje przeszukiwanie stosu od jego wierzchołka w kierunku jego podstawy, z pominięciem niektórych sekcji, które zgodnie z regułami zakresu mają być w danym momencie niewidoczne.
1.5. Reguły wiązania nazw
Wprowadzone poprzednio zasady przeszukiwania stosu ENVS i wyznaczania rezultatu wiązania są zilustrowane na Rys.36. Dla przedstawionego stosu przykładowe rezultaty wiązania są następujące:
- Dla nazwy X rezultatem wiązania jest referencja i127;
- Dla nazwy I rezultatem wiązania jest string "Maria";
- Dla nazwy Zar rezultatem wiązania jest referencja i11;
- Dla nazwy Dział rezultatem wiązania jest zbiór referencji {i17, i22};
- Dla nazwy Prac rezultatem wiązania jest referencja i1;
W ostatnim przypadku bindery opatrzone nazwą Prac występują w dwóch sekcjach ENVS, ale oczywiście podane reguły każą zatrzymać wyszukiwanie na sekcji zawierającej binder Prac, która znajduje się najbliżej wierzchołka stosu. Mówimy w takiej sytuacji, że dla tej nazwy pewien binder znajdujący się w bardziej lokalnym środowisku przesłania identycznie nazwane bindery znajdujące się w bardziej globalnym środowisku. Koncepcja przesłaniania stanowi ważną zasadę zwiększającą stopień niezależności działania lokalnego programu (górne sekcje ENVS) od środowiska zewnętrznego, w którym ten program funkcjonuje (dolne sekcje stosu).
Podane wyżej reguły przeszukiwania stosu i wiązania nazw ulegną pewnej modyfikacji dla modeli składu M1-M3. Do tej kwestii wrócimy dalej przy omawianiu realizacji pojęcia dziedziczenia.
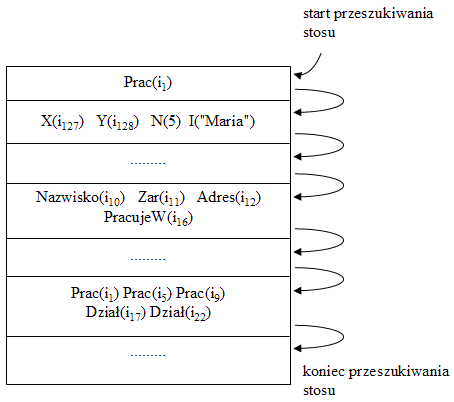
Rys.36. Kolejność przeszukiwania ENVS podczas wiązania nazwy
1.6. Otwieranie nowego zakresu na stosie środowisk
Pojęcie zakresu nazwy odnosi się do tekstu programu lub zapytania i oznacza ten fragment tekstu, w którym ta nazwa może być potencjalnie użyta. Jednakże naiwna interpretacja zakresów nazw na bazie analizy tekstu programu lub zapytania może prowadzić do nieporozumień, gdyż na ten tekst można nałożyć wiele zachodzących na siebie różnych zakresów, które mogą zmieniać się dynamicznie. Jedną z podstawowych funkcji stosu ENVS jest precyzyjne ich kontrolowanie, powoływanie nowych zakresów oraz usuwanie zakresów.
Pojedyncza sekcja stosu środowisk ustala pewien zakres nazw lub fragment środowiska wykonania zapytania/programu, w związku z czym pojęcia sekcja stosu, środowisko oraz zakres nazw będziemy uważać za równoważne.
W klasycznych językach programowania otwieranie nowego zakresu na wierzchołku ENVS następuje w momencie wywołania procedury (funkcji, metody) lub w momencie wejścia programu w nowy blok. Odpowiednio, skasowanie tej sekcji następuje w momencie zakończenia działania procedury (funkcji, metody) lub w momencie wyjścia sterowania z bloku.
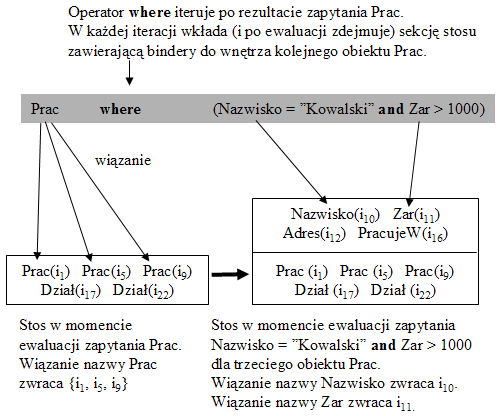
Rys.38. Wkładanie sekcji na ENVS dla ewaluacji podzapytania
Do powyższych klasycznych sytuacji otwierania nowego zakresu na ENVS dołączymy nową. Stanowi ona istotę podejścia stosowego do języków zapytań. Pomysł polega na tym, że pewne operatory występujące w zapytaniach (zwane niealgebraicznymi) działają na stosie podobnie do wywołań bloków programów. Na przykład, w następującym zapytaniu języka SBQL (który będzie wprowadzony dalej):
| P7.1. | Prac where (Nazwisko = "Kowalski" and Zar > 1000) |
część (Nazwisko = "Kowalski" and Zar > 1000) jest blokiem, który jest ewaluowany w nowym środowisku określonym przez "wnętrze" obiektu Prac aktualnie testowanego przez operator where. W związku z tym na stos ENVS jest wkładana nowa sekcja zawierająca bindery do wszystkich wewnętrznych własności (atrybutów, metod itd.) tego obiektu Prac. Po ewaluacji sekcja ta jest usuwana ze stosu. Biorąc pod uwagę bazę danych z Rys.23 i Rys.24, ewaluacja tego zapytania jest zilustrowana na Rys.38.
Powyższe podejście pozwala w jednorodny i spójny sposób uwzględnić cechy obiektowości, takie jak dziedziczenie, hermetyzację, polimorfizm i inne.
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.