2. Nieregularne dane w modelach składu
Wprowadzone przez nas modele składu M0-M3 z definicji są przygotowane do przechowywania dowolnych struktur nieregularnych. Podobnie jak w XML, nie wprowadzamy także wartości zerowych, uważając że jeżeli wartość pewnego (pod) obiektu jest nieznana lub nierelewantna, to taki (pod) obiekt może być w całości pominięty w danym składzie obiektów. Ponieważ, jak dotąd, nie wiążemy modeli składu z jakimkolwiek systemem typów, wobec tego nie jesteśmy niczym skrępowani jeżeli chodzi o odwzorowanie nieregularności w danych. Również mechanizmy wiązania na stosie środowiskowym nie zależą od tego, czy dane mają regularny format, czy są nieregularne.
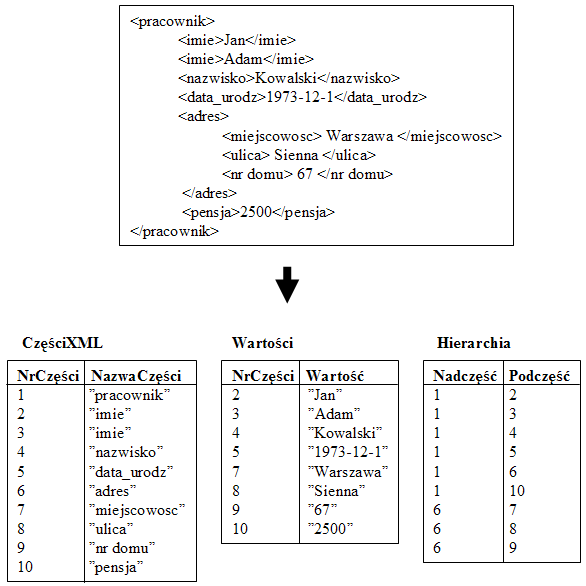
Rys.66. Spłaszczenie struktury nieregularnej XML w celu umożliwienia przetwarzania w SQL i/lub w języku programowania
W istocie jednak ta swoboda jest pozorna i wynika wyłącznie z faktu, że przy konstrukcji semantyki języka zapytań całkowicie pominęliśmy tę pragmatyczną stronę języka zapytań, o której mówiliśmy w podrozdziale 2.5. Mianowicie, nieodłączną własnością dowolnego języka zapytań jest rozumienie schematu danych, i to zarówno od strony znaczenia danych w dziedzinie przedmiotowej (dziedzinie biznesu) oraz od strony rozumienia wszelkich aspektów logicznej organizacji i reprezentacji danych.
Nie będziemy na razie zajmować się językiem schematu umożliwiającym specyfikację danych nieregularnych. Dobrym wzorcem w tym zakresie jest DTD oraz XMLSchema należące do technologii XML. W systemie Loqis zrealizowaliśmy nieco inny model oparty na gramatykach bezkontekstowych i wyrażeniach regularnych.
Materiały zostały opracowane w PJWSTK w projekcie współfinansowanym ze środków EFS.